后台订单列表这类接口很容易被低估。SQL 看起来通常不复杂:按用户过滤,按状态过滤,再按创建时间倒序取最新 20 条。页面上只是一个列表,代码里也只是一个 where + order by + limit,但数据量上来以后,慢的地方往往就藏在这三个关键词之间。
这次用 KingbaseES 跑一个订单列表场景。表里有 50000 行订单,目标用户 1001 下面有一批已支付订单。查询条件固定为:
sql
where user_id = 1001
and order_status = 'paid'
order by created_at desc
limit 20这个查询并不花哨,正因为普通,才值得拿来排。列表页一慢,第一反应往往是"是不是该加索引"。但索引加在哪里,先后顺序怎么放,能不能同时照顾过滤和排序,光靠猜很容易偏。
原始计划先看扫描和排序
先看没有业务索引时的计划。
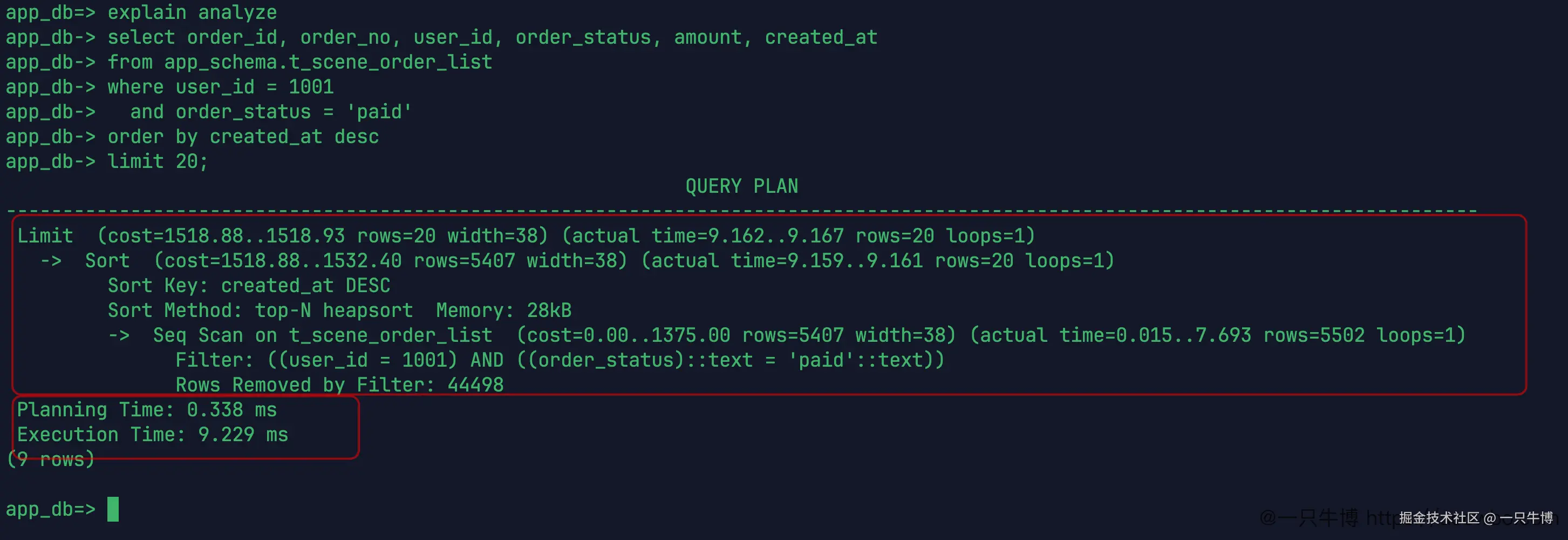
原始计划里有几个信息很直接:底层是 Seq Scan on t_scene_order_list,过滤条件是 user_id = 1001 和 order_status = 'paid'。实际返回给上层排序的是 5502 行,同时有 Rows Removed by Filter: 44498,说明大部分数据都被扫过以后再过滤掉。
过滤之后还要排序。计划里有 Sort Key: created_at DESC,排序方式是 top-N heapsort,最后 Limit 取 20 行。这个环境下执行时间是 9.229 ms,数字本身不算夸张,毕竟只是 50000 行实验数据。但计划形态已经很清楚:先扫表,再过滤,再排序,再取前 20 条。
读这类计划时,不要只盯着最后的 Execution Time。时间会受缓存、机器规格、并发状态影响,同一条 SQL 连续跑几次也可能有波动。更稳定的信息在节点上:是不是 Seq Scan,过滤掉了多少行,排序发生在什么位置,Limit 是早早截断,还是等前面处理完一大批数据才截断。
这条原始 SQL 的问题不在写法复杂,而在数据库没有一条合适的路径直达"某个用户、某个状态下最新的 20 条"。没有这条路径时,只能从表里找,找到以后再排。数据量小的时候感觉还行,用户订单量一上来,列表接口就容易被这种计划拖住。
现有索引要先对一遍
接着确认一下表规模和现有索引。
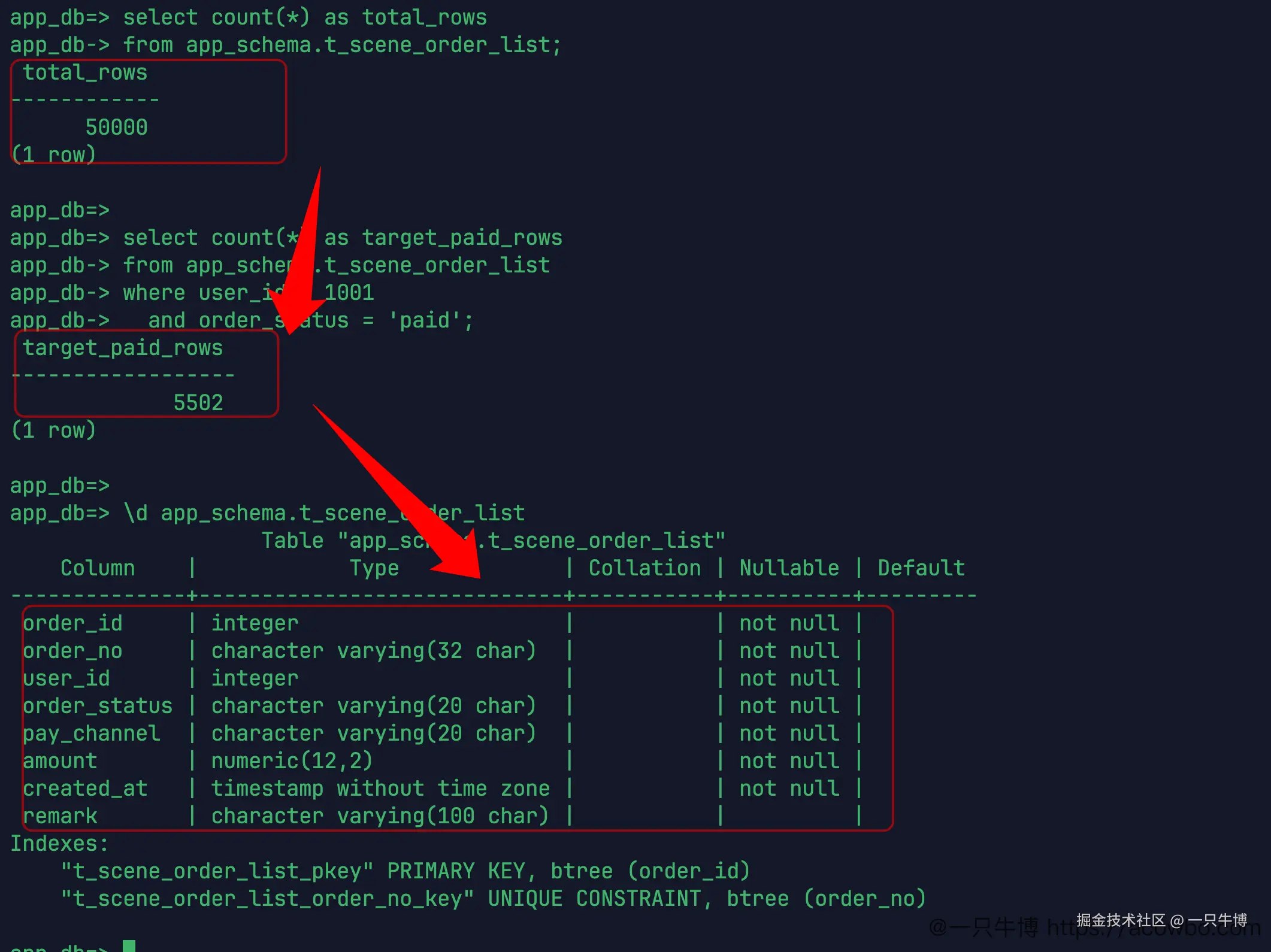
表里一共 50000 行,目标条件下的已支付订单是 5502 行。结构里能看到 order_id、order_no、user_id、order_status、pay_channel、amount、created_at、remark 这些字段。索引只有两个:主键 t_scene_order_list_pkey,以及订单号唯一约束 t_scene_order_list_order_no_key。
这两个索引对按主键查订单、按订单号查详情有用,但对这个列表查询帮不上太多。列表查询关心的是 user_id、order_status 和 created_at desc,现有索引没有覆盖这个路径。这个时候再去看原始计划里的 Seq Scan,就不奇怪了。
这个检查很有必要。很多慢查询排查一上来就改 SQL,或者直接补一个索引,但连表上已有索引都没看。主键和唯一键看起来也是索引,但它们服务的是另外两类访问方式:一个按 order_id,一个按 order_no。订单列表按用户和状态筛选,再按时间排序,访问路径完全不同。
目标用户已支付订单是 5502 行。第一页只要 20 行,但候选集有几千行。如果排序不能借助索引顺序,数据库就要先把这批候选行排出来,再取前 20。这里的"慢"不是因为返回 20 行太多,而是为了得到这 20 行,前面做了不少准备工作。
单列 user_id 索引只能减轻一部分
先加一个最常见的单列索引:user_id。
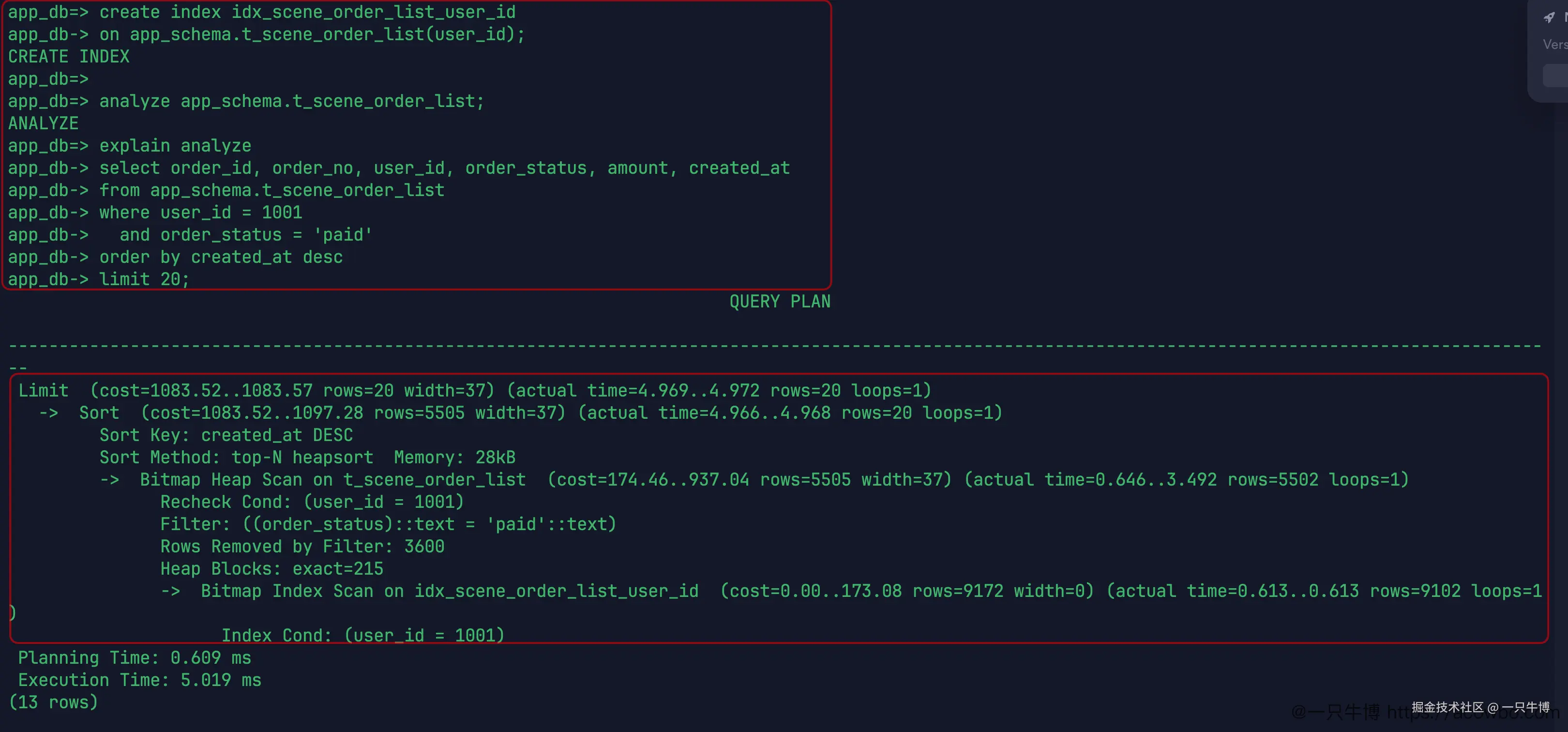
这次计划不再是全表顺序扫描,而是走了 Bitmap Index Scan on idx_scene_order_list_user_id,然后通过 Bitmap Heap Scan 回表。Index Cond: (user_id = 1001) 说明 user_id 索引确实用上了。
但这个索引只解决了一部分问题。计划里还能看到 Filter: (order_status = 'paid'),并且 Rows Removed by Filter: 3600。也就是说,索引先按用户找出一批订单,再从里面过滤已支付状态。后面仍然出现 Sort Key: created_at DESC,数据库还要把过滤后的结果按创建时间倒序排一遍。
执行时间从原始的 9.229 ms 降到 5.019 ms。这说明单列索引有帮助,但它没有把这个列表查询完全接住。用户过滤走了索引,状态过滤和排序还是在后面处理。
这个结果很适合提醒一件事:字段出现在 where 里,不代表只给它单独建索引就够了。列表查询一般不是只过滤,还要排序、分页。索引如果只服务其中一个条件,计划里通常还能看到剩下的工作。
单列索引还有一个容易被忽略的细节:它先找到 user_id = 1001 的行,再把这些行拿回表里判断 order_status。计划里的 Rows Removed by Filter: 3600 就是这部分成本。也就是说,单列索引已经让数据库少扫了很多不相关用户,但在这个用户自己的订单里,仍然要再筛一次状态。
排序也没有消失。top-N heapsort 比完整排序更适合 limit 20 这种取前 N 条的场景,但它仍然是排序。只要计划里还有 Sort Key: created_at DESC,就说明索引没有直接提供最终需要的时间顺序。列表接口如果高频访问,这部分成本会反复出现。
联合索引贴着查询形状建
再换成更贴合这个查询形状的联合索引:
sql
create index idx_scene_order_list_user_status_created
on app_schema.t_scene_order_list(user_id, order_status, created_at desc);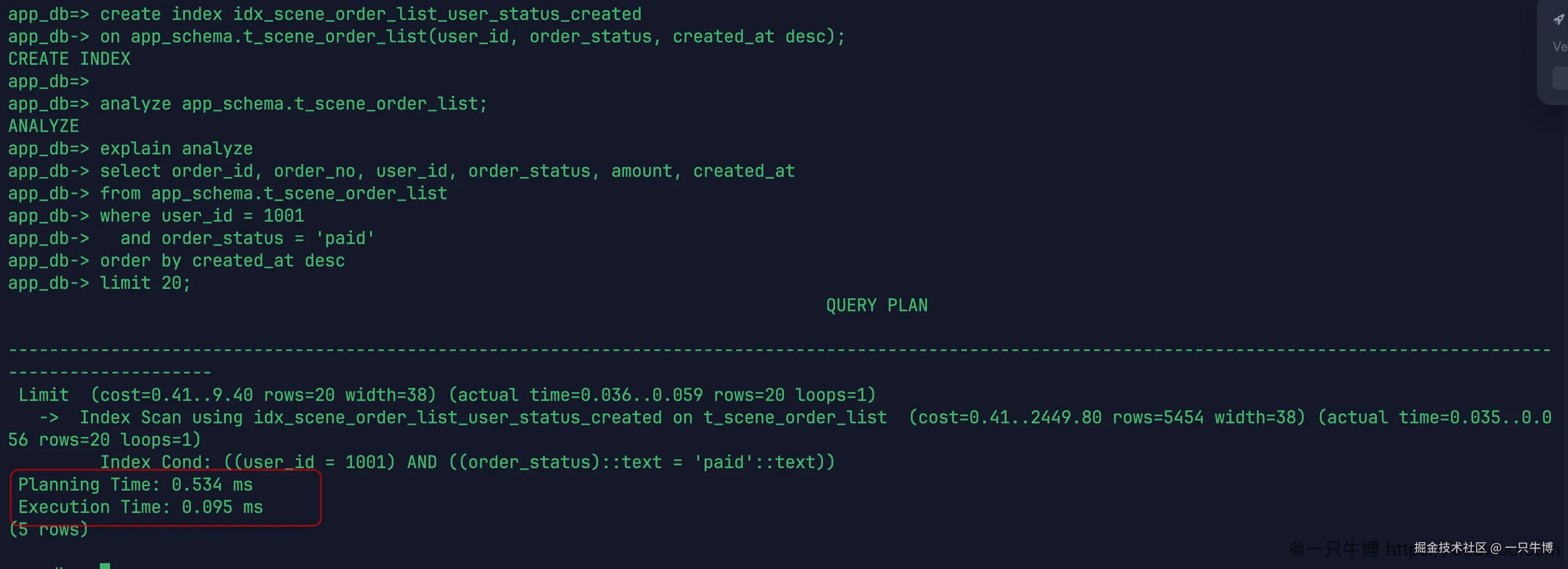
这次计划变化很明显。节点变成 Index Scan using idx_scene_order_list_user_status_created,条件里同时出现:
text
user_id = 1001
order_status = 'paid'计划里没有再出现 Sort。因为索引顺序已经按 user_id、order_status、created_at desc 组织,数据库可以沿着索引顺序拿到最新的 20 条,不需要先找出 5502 行再重新排序。
执行时间降到 0.095 ms。还是那句话,这个数字只代表当前机器、当前数据量和当前缓存状态,不能写成通用性能结论。但计划上的变化是确定的:联合索引同时服务了过滤和排序,Limit 20 可以很早停下来。
这个联合索引的顺序不是随便排的。user_id 和 order_status 都是等值过滤,放在前面可以先把范围缩小;created_at desc 放在后面,对应列表的倒序排序。这样一来,符合用户和状态的记录在索引里已经按时间倒序排好,数据库沿着索引往下取,够 20 行就可以停。
如果把 created_at 放在最前面,或者只建 (created_at desc),情况就不一定一样。它可能对全站最新订单有帮助,但对"某个用户的已支付订单列表"未必合适。索引顺序要跟查询条件一起看,不能只看某个字段有没有出现在 SQL 里。
结果集也要确认没有跑偏
优化不能只看计划,还要确认返回结果没有跑偏。真实查询返回的是用户 1001 的 paid 订单,按 created_at 倒序排列。
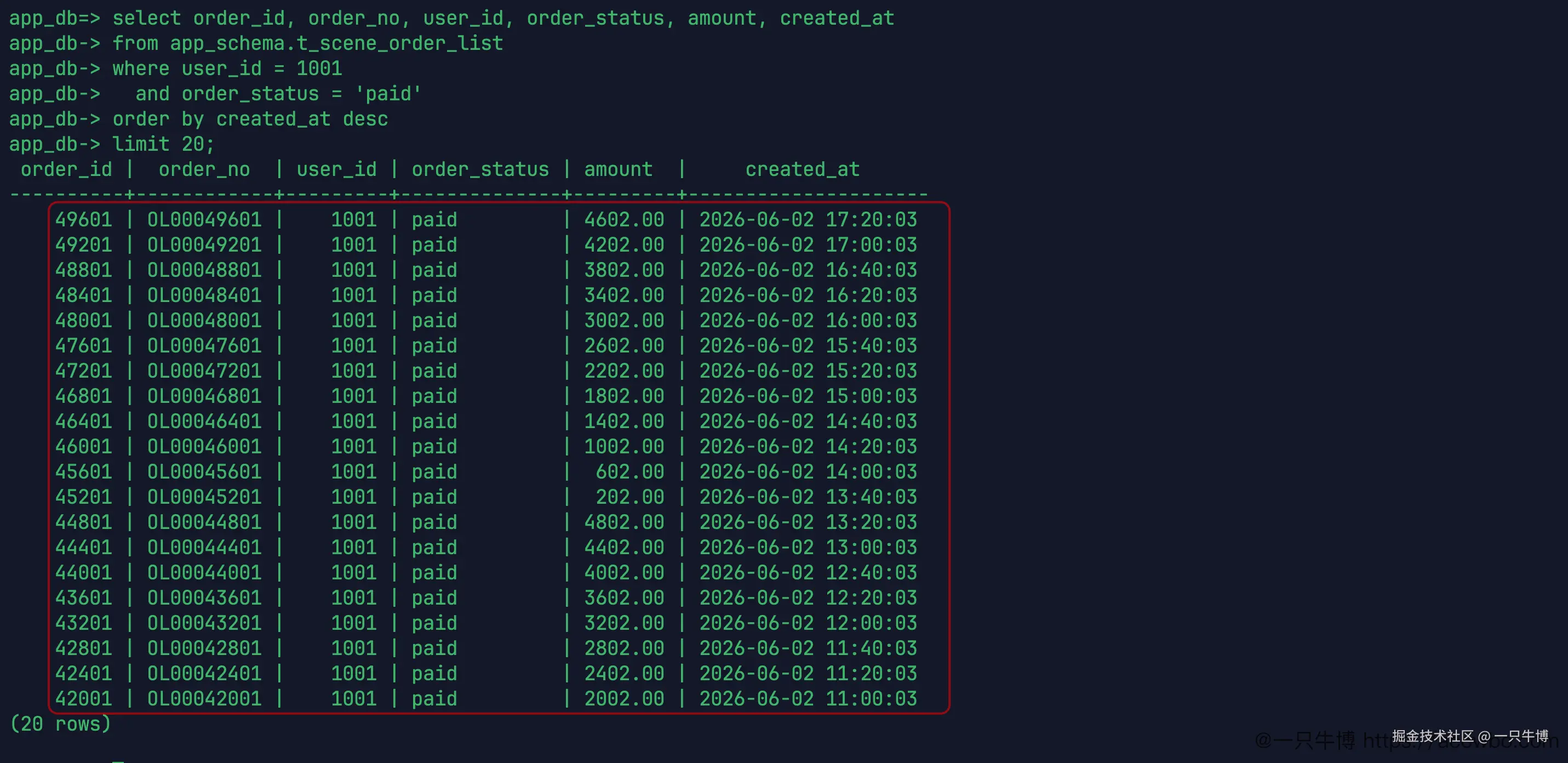
返回结果里能看到 created_at 从 2026-06-02 17:20:03 往下走,订单状态都是 paid,用户都是 1001。执行计划说明数据库怎么找数据,结果集则确认业务含义没有变。查询变快但排序错了,或者状态过滤漏了,都不能算修好。
到这里,第一页列表的问题基本清楚了。不过很多列表页真正麻烦的是深分页。第一页只取最新 20 条,索引能很快停下来;如果是第 151 页,写成 limit 20 offset 3000,情况就不一样了。
offset 深分页会把成本拉回来
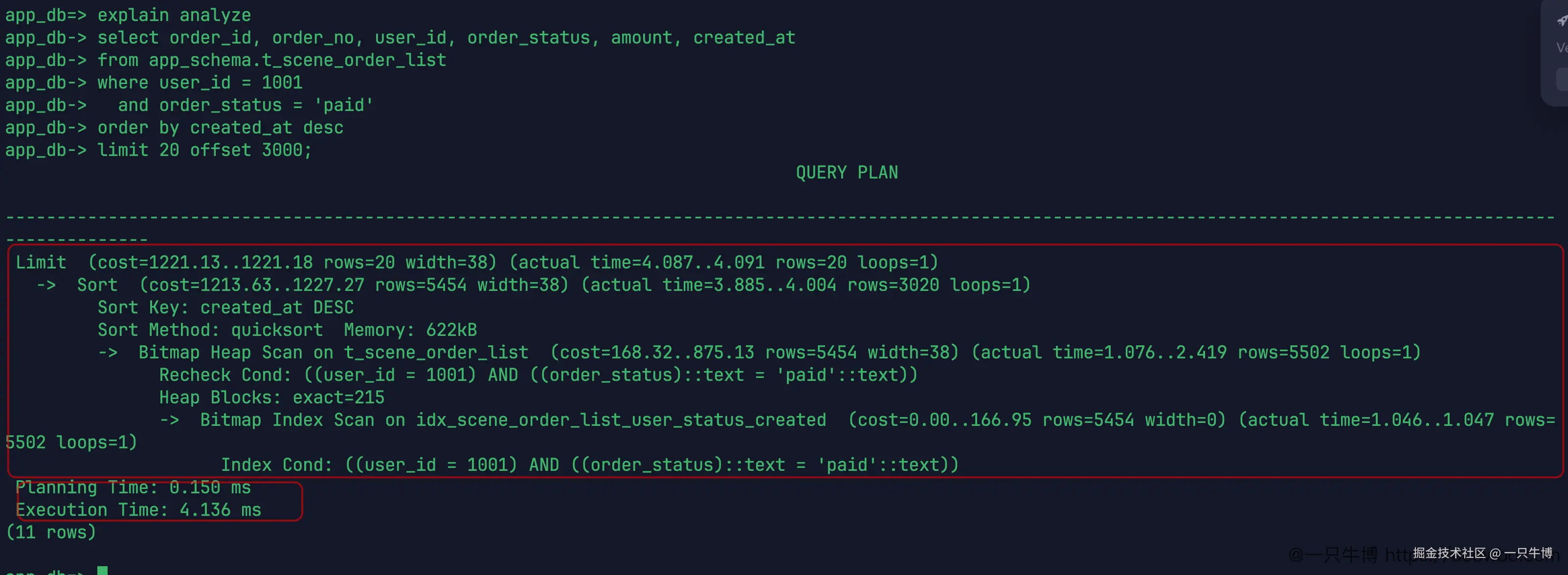
这个计划很有意思。它仍然用了联合索引,但不是上一段那种直接 Index Scan。这里走的是 Bitmap Index Scan on idx_scene_order_list_user_status_created,然后 Bitmap Heap Scan,再 Sort。Sort 节点实际处理了 3020 行,最后 Limit 才拿到 20 行。
原因不难理解:offset 3000 的意思是前 3000 行不要,从第 3001 行开始取 20 行。即使有索引,数据库也要把前面的候选位置处理掉,不能凭空跳到业务想要的那一页。这个实验里执行时间是 4.136 ms,比第一页的联合索引计划慢很多。
这就是很多后台列表后几页变慢的来源。第一页优化好了,不代表深分页也好了。order by created_at desc limit 20 和 order by created_at desc limit 20 offset 3000 看起来只差一个 offset,执行成本可能完全不是一回事。
这里还有一个计划选择上的细节:深分页并没有沿用第一页的直接索引扫描,而是选择了 bitmap 路径再排序。优化器会根据成本估算选择它认为更合适的方式,不能简单理解成"建了联合索引就一定按索引顺序一路扫到底"。SQL 形状变了,offset 变大了,计划也可能跟着变。
后台管理系统里经常有"跳到第几页"的需求,这种需求和数据库执行方式天然有点拧巴。用户看到的是页码,数据库看到的是跳过多少行。页码越靠后,跳过的行越多。即使每页只展示 20 条,数据库也要先处理前面的候选结果。
连续翻页可以换成边界条件
如果业务场景是"继续向下翻",可以换成游标式分页。先拿到上一页最后一条的 created_at,这里取到的边界是:
text
2026-06-02 11:00:03然后下一页查询不再写 offset 3000,而是从这个时间点继续往后取:
sql
and created_at < timestamp '2026-06-02 11:00:03'
order by created_at desc
limit 20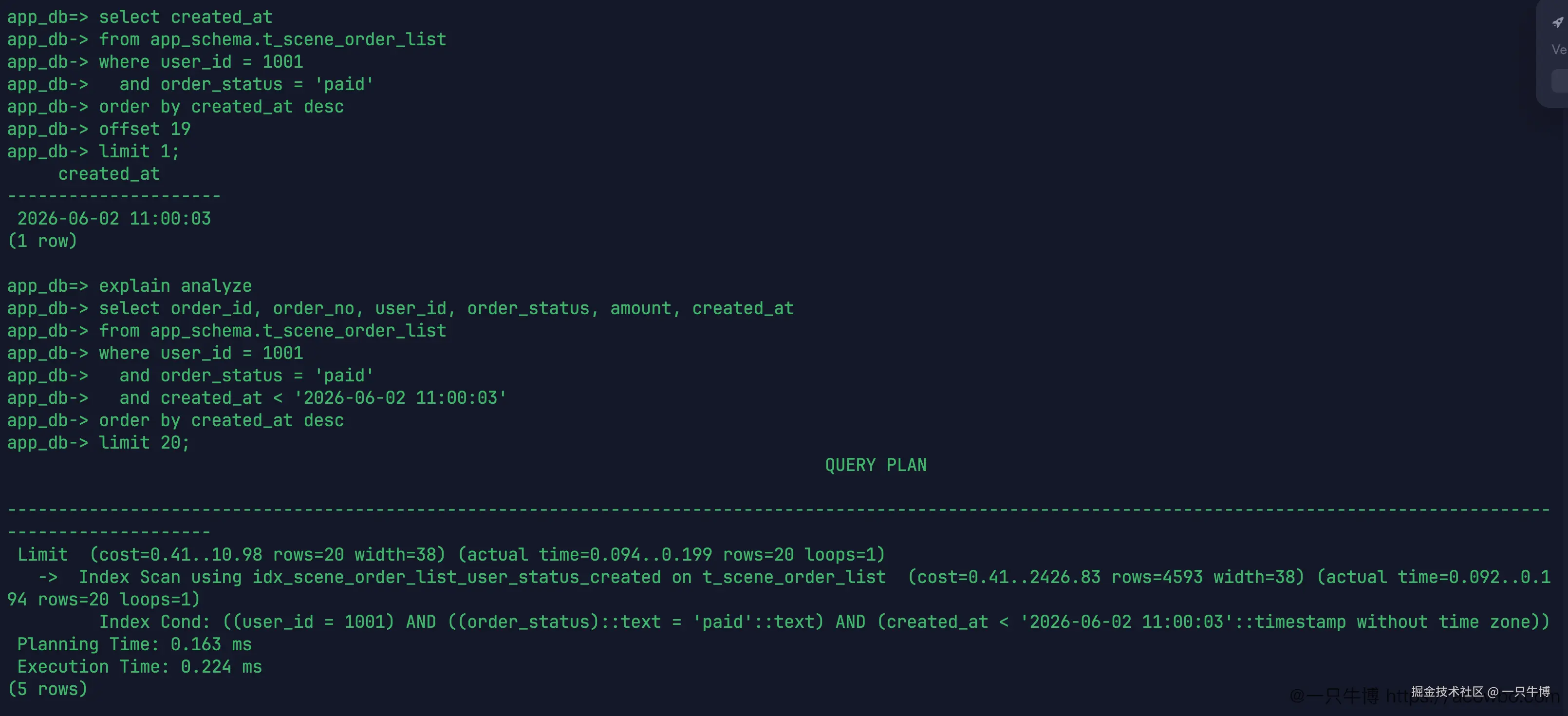
这次又回到了 Index Scan using idx_scene_order_list_user_status_created。索引条件里除了 user_id 和 order_status,还多了 created_at < '2026-06-02 11:00:03'。执行时间是 0.224 ms,比 offset 3000 那个计划轻很多。
这种写法不是万能替代。它适合"下一页、继续加载"这种路径,不适合用户在页面上直接跳到第 200 页。后台管理系统如果必须支持任意跳页,仍然要面对 offset 的成本;如果只是按时间向后翻,游标式分页更贴合索引。
游标式分页还有一个现实问题:只用 created_at 做边界时,如果多条订单的创建时间完全相同,翻页边界可能不够稳。这个实验数据里的时间间隔比较规整,足够展示思路。正式业务里常见写法会把 created_at 和一个唯一字段一起作为边界,例如再带上 order_id,让排序和下一页条件都更确定。
所以这里不是简单说 offset 不能用。小数据、浅分页、后台偶尔查询,offset 很方便;连续滚动、移动端列表、接口高频调用,就更适合考虑游标式分页。选择哪种写法,要看产品交互和查询压力。
最后看索引是不是各有用途
最后看一下表上的索引清单。
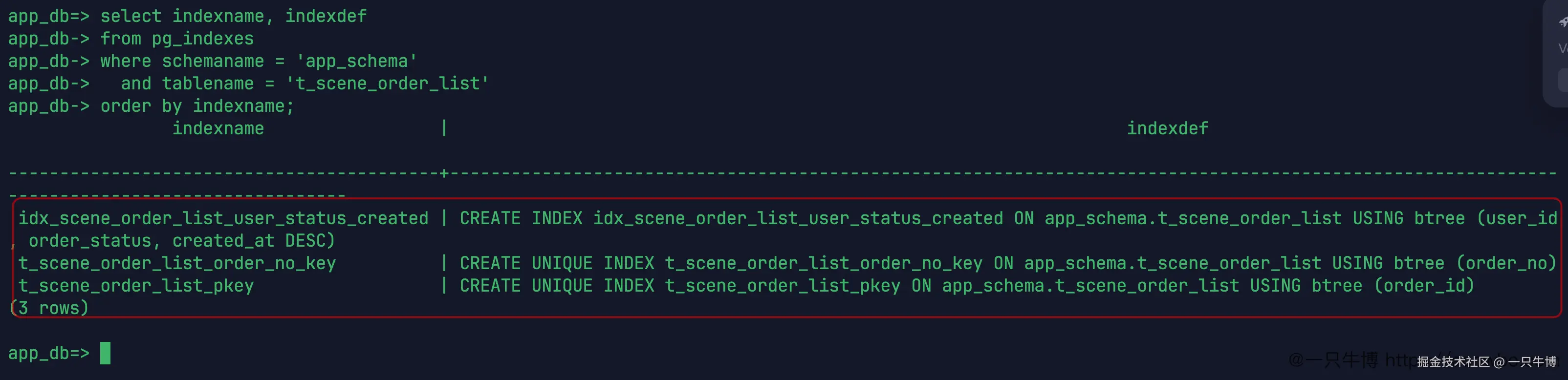
最终清单里有三条:联合索引 idx_scene_order_list_user_status_created,订单号唯一索引 t_scene_order_list_order_no_key,主键索引 t_scene_order_list_pkey。前面实验过的 user_id 单列索引没有留在最终清单里。
这个结果也说明,索引不是按字段逐个堆上去。订单号唯一索引服务订单详情查询,主键索引服务主键访问,联合索引服务这个订单列表场景。至于单列 user_id 索引,要看系统里有没有其他只按用户过滤、不按状态和时间排序的查询。如果没有,它很可能被联合索引覆盖掉,保留反而增加写入和维护成本。
最终要不要删单列索引,不能只看这一条 SQL。还要查其他接口有没有按 user_id 做统计、导出、后台筛选。如果还有别的高频查询只靠 user_id,单列索引可能仍然有价值;如果主要查询都走 user_id + order_status + created_at,保留联合索引更贴近这个列表场景。
索引清单最好和业务查询清单放在一起看。每条索引都应该能说清楚服务哪个入口,按什么条件访问,是否还被执行计划使用。说不清楚用途的索引,时间久了就会变成写入成本和维护成本。
这次排查可以收成几条很具体的判断。原始计划慢在扫表和排序;单列索引减少了扫描范围,但排序还在;联合索引贴合 where user_id + order_status 和 order by created_at desc 后,第一页查询变成直接索引扫描;深分页仍然会因为 offset 处理大量候选行;游标式分页把"跳过 N 行"改成"从边界时间继续取",更适合连续翻页。
遇到列表慢查询,先别急着给每个字段都建索引。把 SQL 里的过滤条件、排序字段、分页方式摊开,再看执行计划里到底是扫表、回表、过滤、排序还是 offset 拖慢了。索引要服务查询形状,不是服务某个孤立字段。