数据架构:数据源的注册,物理模型的设计
结束之后,才能在数据工厂进行数据的编排。数据工厂完全基于数据模型来集成作业的配置
以上可能没多大用
初始
点击+号,可创建目录,可在目录下创建集成作业,点击目录,在右侧会出现目录下的那些已有集成作业
点击新建作业,打开如图界面
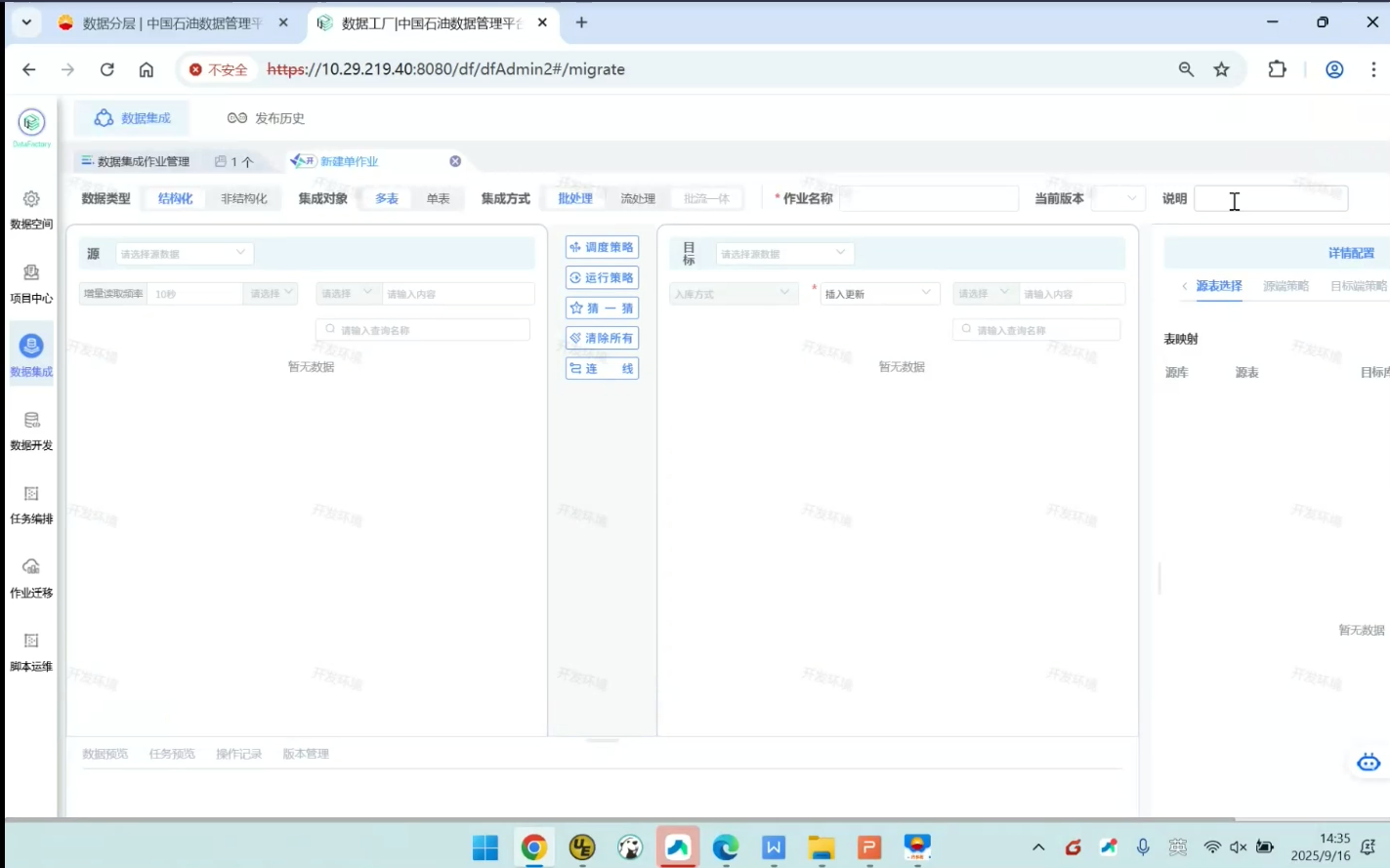
数据类型:结构化:有固定表结构的数据
非结构化:没有固定表格结构的数据。比如图片、PDF、word、excel、视频、音频
集成类型:多表
单表
集成方式:批处理
流处理
结构化数据在迁移系统里怎么用?
比如你要把源库的一张表:source_well_info
迁移到目标库:target_well_info
源表字段:
| 源字段 | 含义 |
|---|---|
| well_no | 井号 |
| well_name | 井名 |
| oilfield | 油田 |
目标表字段:
| 目标字段 | 含义 |
|---|---|
| well_id | 井ID |
| name | 井名称 |
| oilfield_name | 油田名称 |
那迁移系统里就会配置字段映射:
source_well_info.well_no → target_well_info.well_id
source_well_info.well_name → target_well_info.name
source_well_info.oilfield → target_well_info.oilfield_name
对应 SQL 思维就是:
sql
select
well_no as well_id,
well_name as name,
oilfield as oilfield_name
from source_well_info;非结构化数据迁移是什么?
非结构化迁移通常不是"字段映射",而是"文件搬运"。
比如:
从 A 文件服务器
迁移到 B 文件服务器
或者:
从源系统的附件目录
迁移到目标系统的对象存储 / 文件系统
它关心的可能是:
文件路径
文件名
文件大小
文件类型
创建时间
所属业务ID
举个例子:
| file_id | file_name | file_path | business_id |
|---|---|---|---|
| F001 | 井场照片.jpg | /upload/2024/01/a.jpg | W001 |
| F002 | 生产日报.pdf | /upload/2024/01/b.pdf | W002 |
这里有两层:
第一层,文件本身:
井场照片.jpg
生产日报.pdf
这是非结构化数据。
第二层,文件的登记信息:
file_id
file_name
file_path
business_id
这是结构化数据。
所以实际项目里经常是:
结构化数据 + 非结构化附件 一起迁移
比如迁移一口井的信息,同时迁移这口井相关的照片、PDF、附件。
集成类型:单表
- 什么是单表?
单表就是这次迁移只处理一张源表到一张目标表。
比如:
源表:well_info
目标表:t_well_info
只从一张源表取数据,不需要关联其他表。
例子:
sql
select
well_id as id,
well_name as name,
oilfield_name as oilfield,
status as state
from well_info;这里就只有一张表:well_info
这种就是单表集成 / 单表迁移。
单表适合什么情况?
适合字段基本都在一张表里的情况。
比如源表已经很完整:
| well_id | well_name | oilfield_name | status | create_time |
|---|---|---|---|---|
| W001 | 1号井 | 高升油田 | 正常 | 2024-01-01 |
| W002 | 2号井 | 高升油田 | 停产 | 2024-01-02 |
目标表也只是换一下字段名:
| id | name | oilfield | state | created_at |
|---|
那就可以单表迁移:
sql
select
well_id as id,
well_name as name,
oilfield_name as oilfield,
status as state,
create_time as created_at
from well_info;这就是最简单、最适合新手先掌握的迁移方式。
集成类型:多表
- 什么是多表?
多表就是这次迁移需要从多张源表取数据,经过关联、拼接、转换后,写入目标表。
比如目标表需要这些字段:
| 目标字段 | 来源 |
|---|---|
| well_id | 井基础表 |
| well_name | 井基础表 |
| oilfield_name | 油田表 |
| daily_oil | 日产表 |
| prod_date | 日产表 |
这些字段不在一张表里。可能来自三张表,那就需要多表关联。
多表集成通常要写 join
比如:
sql
select
a.well_id as well_id,
a.well_name as well_name,
c.oilfield_name as oilfield_name,
b.prod_date as prod_date,
b.daily_oil as daily_oil
from well_info a
inner join production_daily b
on a.well_id = b.well_id
inner join oilfield_info c
on a.oilfield_id = c.oilfield_id;集成方式:批处理
- 什么是批处理?
批处理就是按照某个时间点或周期,一批一批地搬数据。
比如:每天凌晨 2 点跑一次
每小时跑一次
手动点执行一次
一次迁移昨天的数据
一次迁移某个月的数据
它不是数据一变化就马上同步,而是按批次处理。
集成方式:流处理
什么是流处理?
流处理就是数据一产生、一变化,就尽快同步或处理。适合对实时性要求高的场景。
| 名称 | 你可以怎么理解 | 典型例子 |
|---|---|---|
| 结构化 | 数据库表,有行有列 | 井信息表、日产表、组织机构表 |
| 非结构化 | 文件,没有固定行列 | 图片、PDF、Word、视频、附件 |
| 单表 | 只从一张表取数据 | well_info → t_well |
| 多表 | 多张表关联后取数据 | 日产表 join 井表 join 油田表 |
| 批处理 | 一批一批处理 | 每天凌晨同步昨天数据 |
| 流处理 | 来一条处理一条 | 设备实时数据、实时报警 |
当前版本
不用填写
五层数据
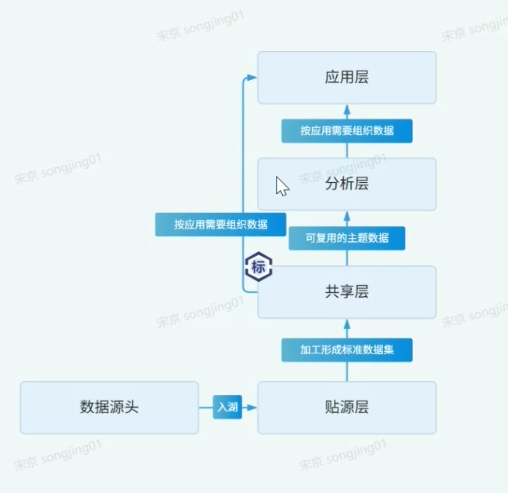
这五个选项:数据源头、贴源层、共享层、分析层、应用层,不是普通数据库名字,而是数据平台里的"五个数据层级"。
数据通常从下往上流动:
数据源头 → 贴源层 → 共享层 → 分析层 → 应用层。
教程选的是:
源端:共享层
目标端:分析层
意思就是:
从"已经标准化、可复用的公共数据"里取数据,再加工成"面向分析场景的数据"。
| 数据层级 | 类比做饭 | 数据状态 |
|---|---|---|
| 数据源头 | 菜市场、原材料产地 | 最原始的数据 |
| 贴源层 | 把菜买回来,原样放进厨房 | 尽量保持原样的数据 |
| 共享层 | 洗菜、切菜、去重、统一标准 | 标准化、可复用的数据 |
| 分析层 | 按菜谱加工成半成品菜 | 面向分析主题的数据 |
| 应用层 | 最终端上桌的菜 | 给具体系统、报表、页面用的数据 |
数据源头
数据源头就是数据最开始产生的地方。
比如油田业务里,数据可能来自:
生产系统,井控系统,设备采集系统,作业管理系统
这些系统就是"数据源头"。
举个例子:某个采油厂每天在业务系统里录入日产数据:
这个数据最开始是在业务系统里产生的,那么那个业务系统就是数据源头。
数据源头一般有这些特点:
原始,分散,格式不统一,字段命名不统一,质量不一定好,可能有脏数据,可能来自不同厂商系统
比如不同系统里,井号可能叫:well_id,well_no,jh
同一个含义,不同系统字段名不一样。
这就是为什么后面要有贴源层、共享层、分析层。
贴源层
贴源层可以理解成:
把数据源头的数据,尽量原样复制一份到数据平台里。
也就是说,源系统里字段是什么样,贴源层尽量就是什么样。
贴源层主要做:抽取源数据,保留原始字段,保留原始记录,少量清洗,增加采集时间、批次号等技术字段
为什么不直接从数据源头进共享层或分析层?
原因是:要保留原始数据,方便追溯。
比如后面分析结果错了,你需要查:到底是源系统数据就错了?还是贴源时错了?还是共享层清洗错了?还是分析层加工错了?
共享层
共享层是把贴源层的数据清洗、统一、标准化之后,形成大家都能复用的数据。
共享层解决什么问题
比如不同源系统里都有"井"的信息:同一个东西,字段名和写法都不一样。共享层要把它统一成标准形式
为什么叫"共享层"
因为它不是只服务某一个报表或某一个应用。
它可以被多个下游使用:分析层可以用,应用层可以用,报表可以用,接口可以用,其他项目也可以用
分析层
分析层是面向具体分析主题加工出来的数据。
从共享层到分析层会发生什么
共享层里可能有很多标准表:分析层会根据某个分析目的,把这些表组合起来。
例如,要做"单井日产分析",目标表可能需要:
| 字段 | 来源 |
|---|---|
| well_id | 井基础表 |
| well_name | 井基础表 |
| oilfield_name | 油田表 |
| plant_name | 组织机构表 |
| prod_date | 日产表 |
| daily_oil | 日产表 |
| daily_water | 日产表 |
| water_cut | 计算字段 |
SQL 思路可能是:
sql
select
a.well_id,
b.well_name,
c.oilfield_name,
d.plant_name,
a.prod_date,
a.daily_oil,
a.daily_water,
case
when a.daily_liquid = 0 then null
else a.daily_water / a.daily_liquid
end as water_cut
from shared_production_daily a
inner join shared_well_info b
on a.well_id = b.well_id
inner join shared_oilfield_info c
on b.oilfield_id = c.oilfield_id
inner join shared_org_info d
on b.org_id = d.org_id;应用层
应用层就是最终给具体应用、页面、接口、报表使用的数据。
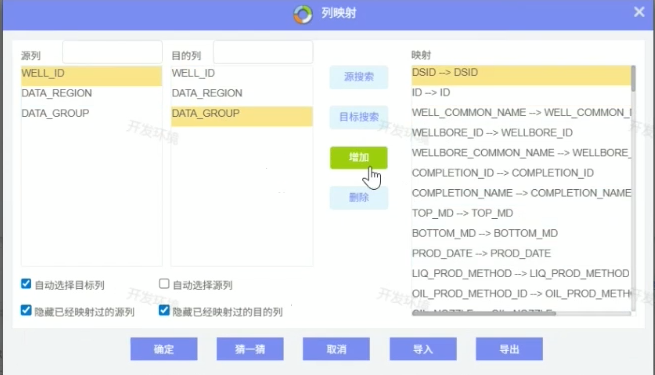
表映射
哪张源表的数据要写到哪张目标表
字段映射
一般点进"详细配置"后,会配置:
源字段 → 目标字段
比如:
WELL_ID → WELL_ID
WELL_NAME → WELL_NAME
PROD_DATE → STAT_DATE
DAILY_OIL → OIL_QTY
共享层转分析层案例
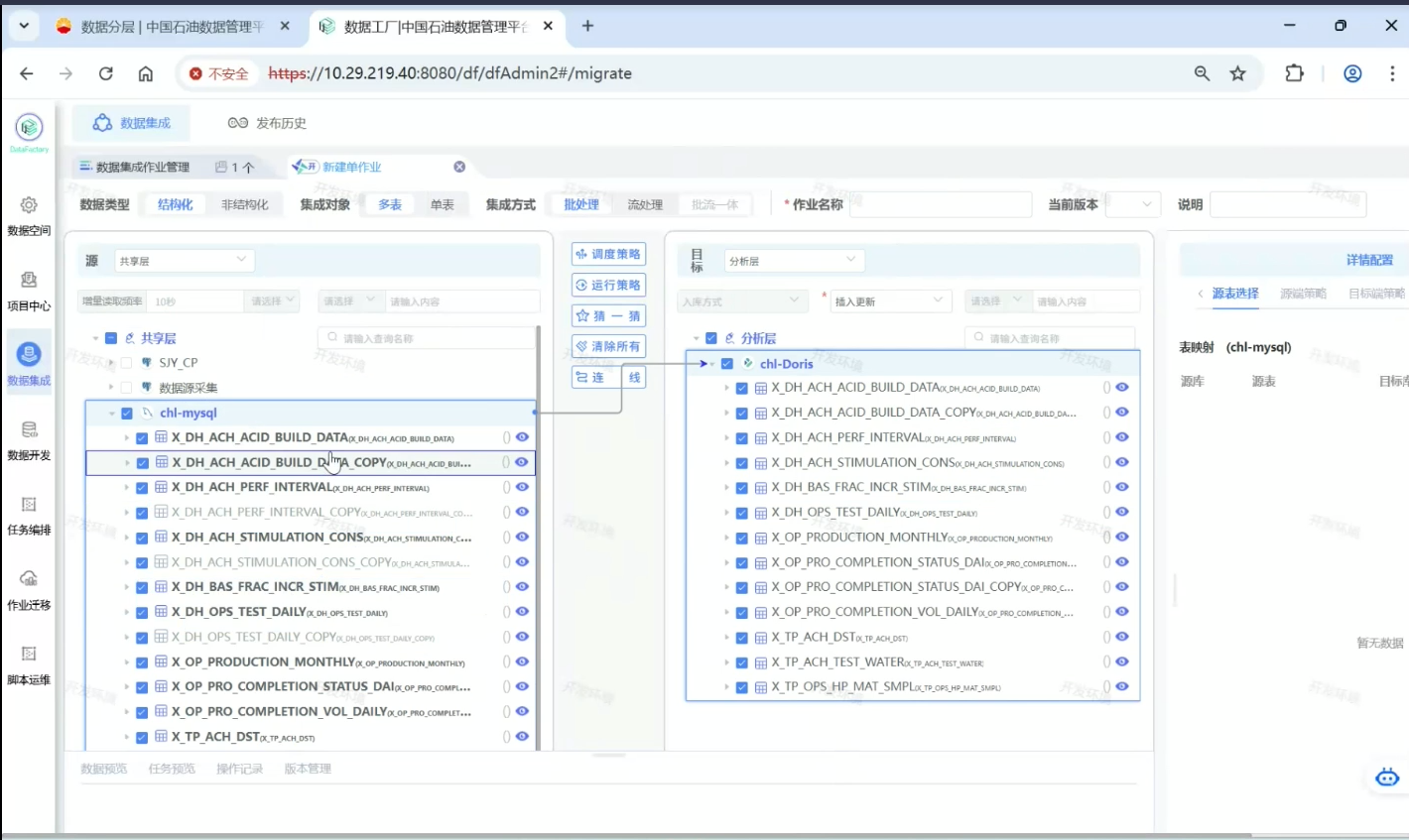
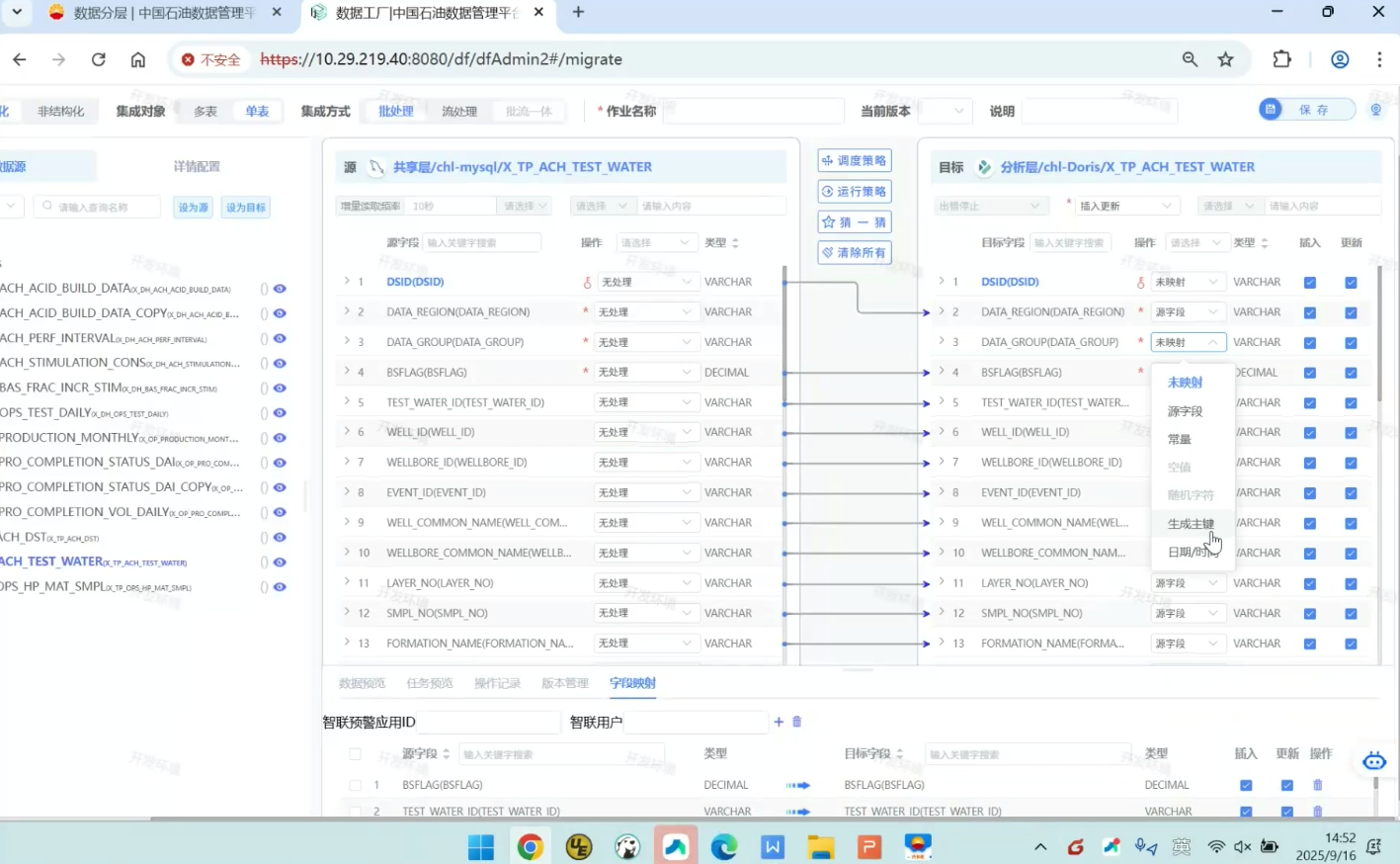
如图,选择共享层的一个库,分析层的一个库,然后把源端库和目标库连线。
源端一些数据集的名字会变得加粗,是因为源库和目标库有同名的表,点击猜一猜就会连线,但连线有时看得不清晰,所以右侧表映射可以较清楚地看出。
疑惑:但是你看这个图里,选择共享层和分析层,那我的理解就是共享层数据是存在的,分析层数据是不存在的,可是如图这个图里,为什么会共享层和分析层连接起来的两个库下面有很多同名数据集
解答:
共享层和分析层下面出现很多同名数据集很正常,因为它们不是同一个东西。
左边是:
共享层 / chl-mysql / 源表
右边是:
分析层 / chl-Doris / 目标表
表名一样,只代表系统可能在做:
共享层的表 → 分析层的同名表
目标端分析层下面有同名数据集,通常说明:
-
目标表结构已经提前建好了;
-
系统自动按源表名生成了目标表名;
-
之前可能已经同步过,所以目标表也存在;
-
同名不代表里面一定有数据。
关键区别是:
表存在 ≠ 表里有数据。
要判断分析层表里有没有数据,要看数据预览或执行:
select count(*)
from 目标表;所以你的理解要改成:
共享层是这次读取数据的源端,分析层是这次写入数据的目标端。目标端可以提前有同名表,用来接收同步/迁移后的数据。
映射
如果有不是同名的也想做映射,把同名映射连线删除,把想做映射的两个数据源连线
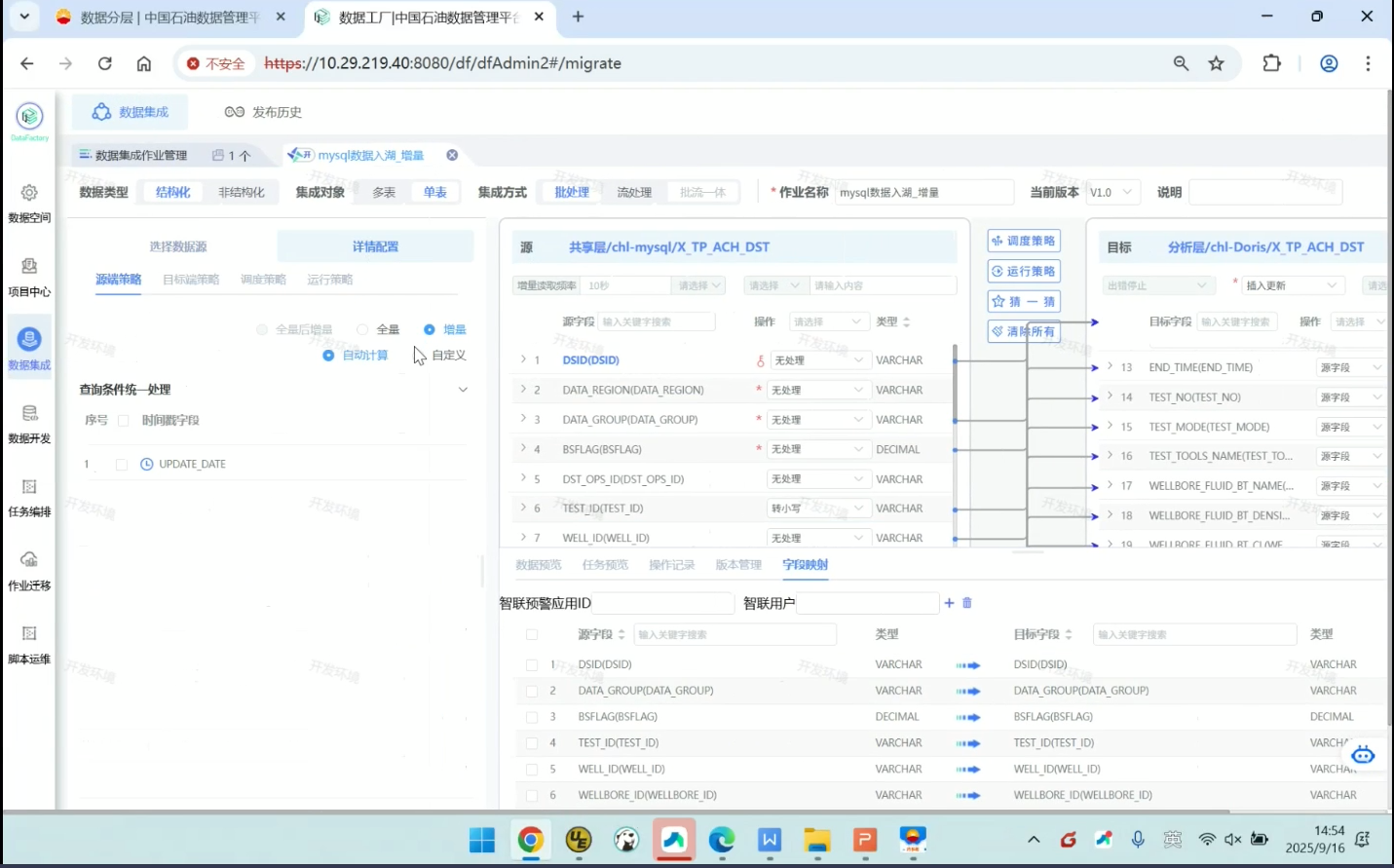
详情配置
源端策略
加一些统一的查询条件,新增条件-生成脚本,如果所有原表都有update_date字段,可以写一个统一的查询条件,就会新增一个where条件加在原表所有select语句后面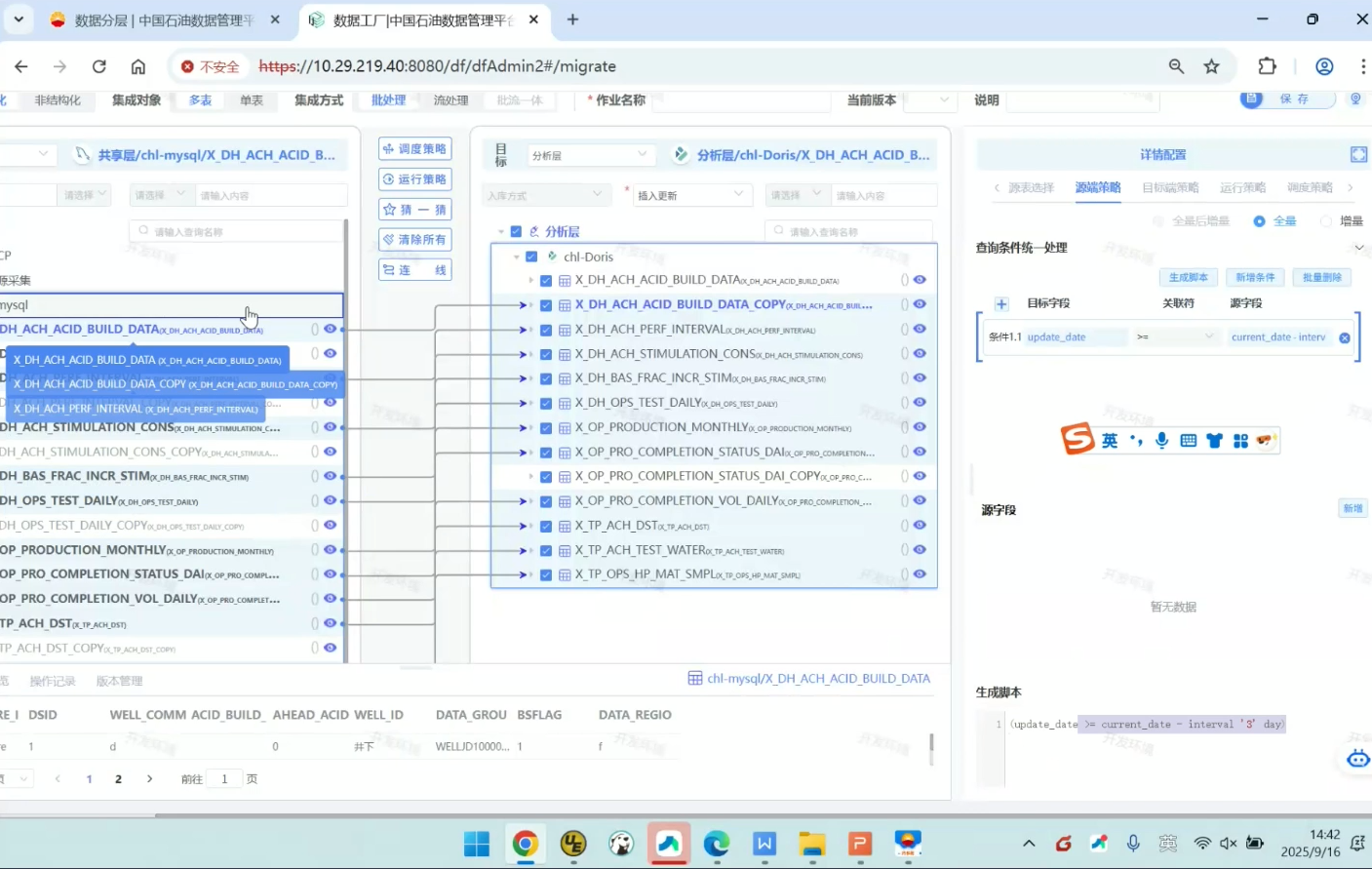
还可以新增源字段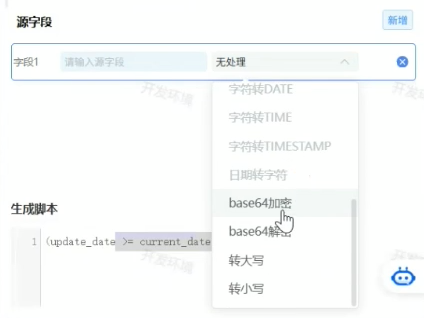
即所有表都必须有的字段
目标端策略
1.目标字段统一处理
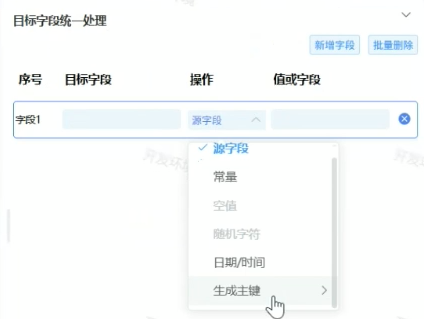
2.插入更新配置
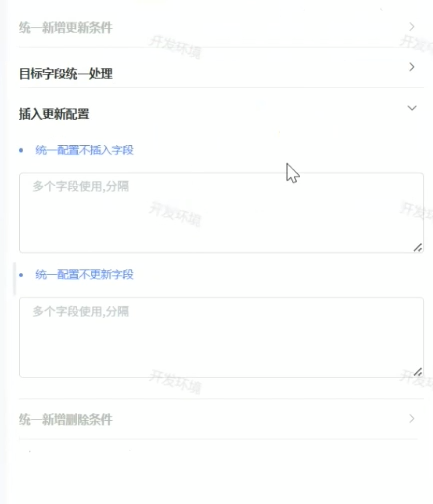
3.统一新增删除条件(选择删除后插入的情况可使用)
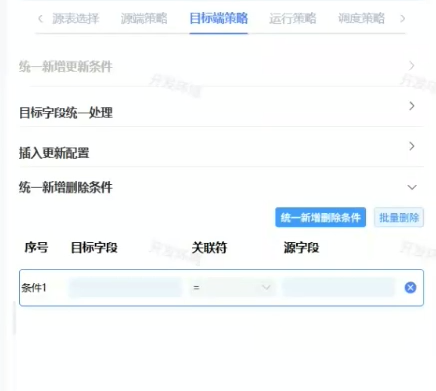
先执行delete操作,把符合条件的数据删除,然后再执行源端数据插入目标端数据的操作
运行策略
调度策略
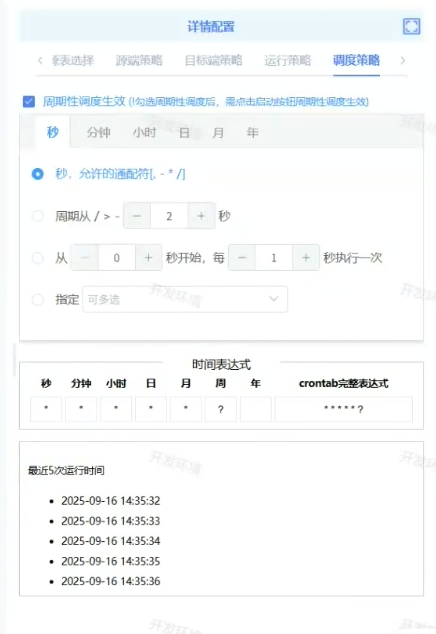
需要周期性调度就必须勾选-周期性调度生效
秒、分钟、小时、天、月、年,可以联动设置。例:在日里设置:从1号开始,每1日执行一次,此时默认每天0:00执行,可去小时里指定1和5(可多选),就变成了每天1:00和5:00执行一次。
所有的配置完后点击保存
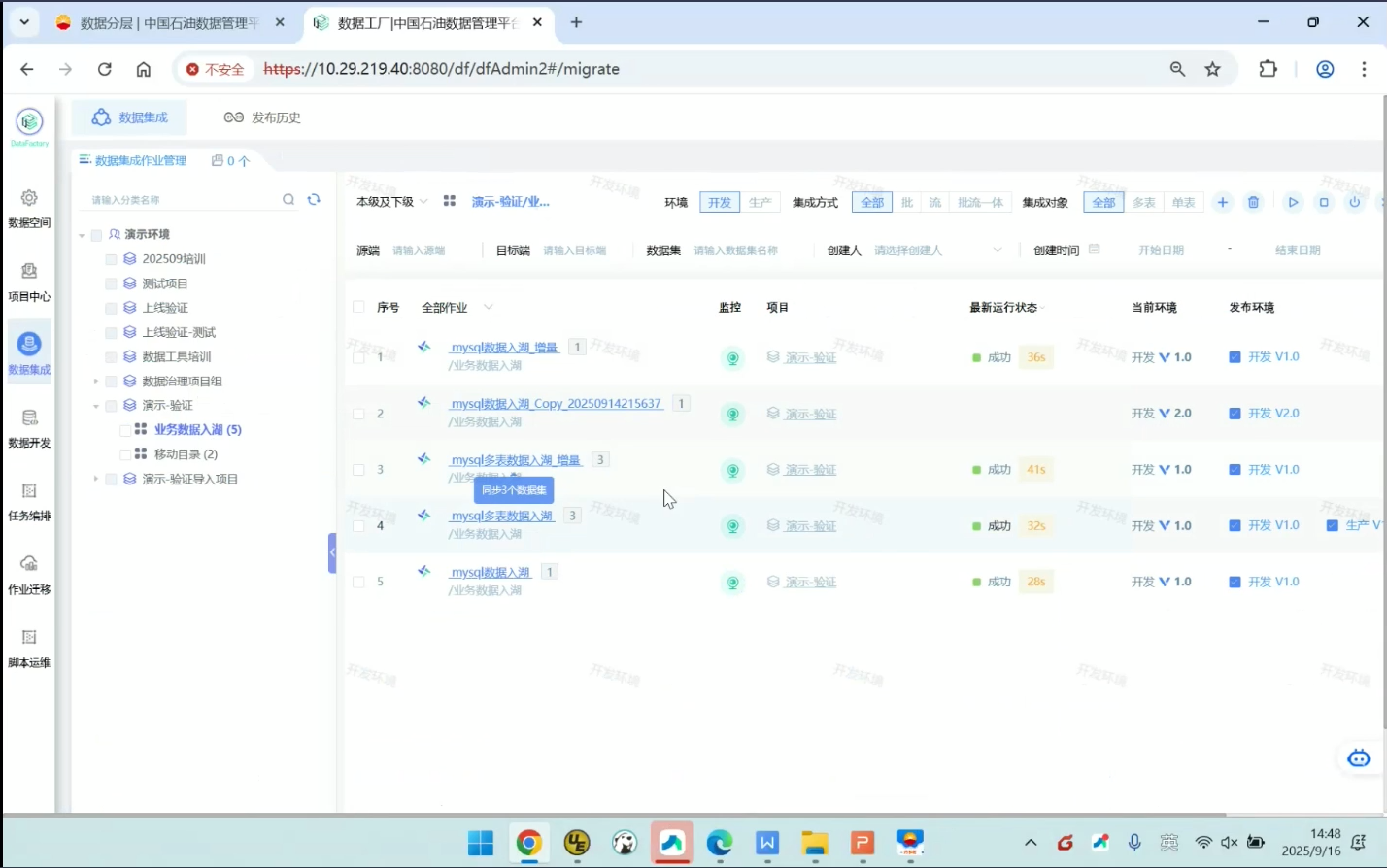
来到这个界面,每个作业名称后面的数字就代表这个作业下面有几个表,多张表就是多表作业
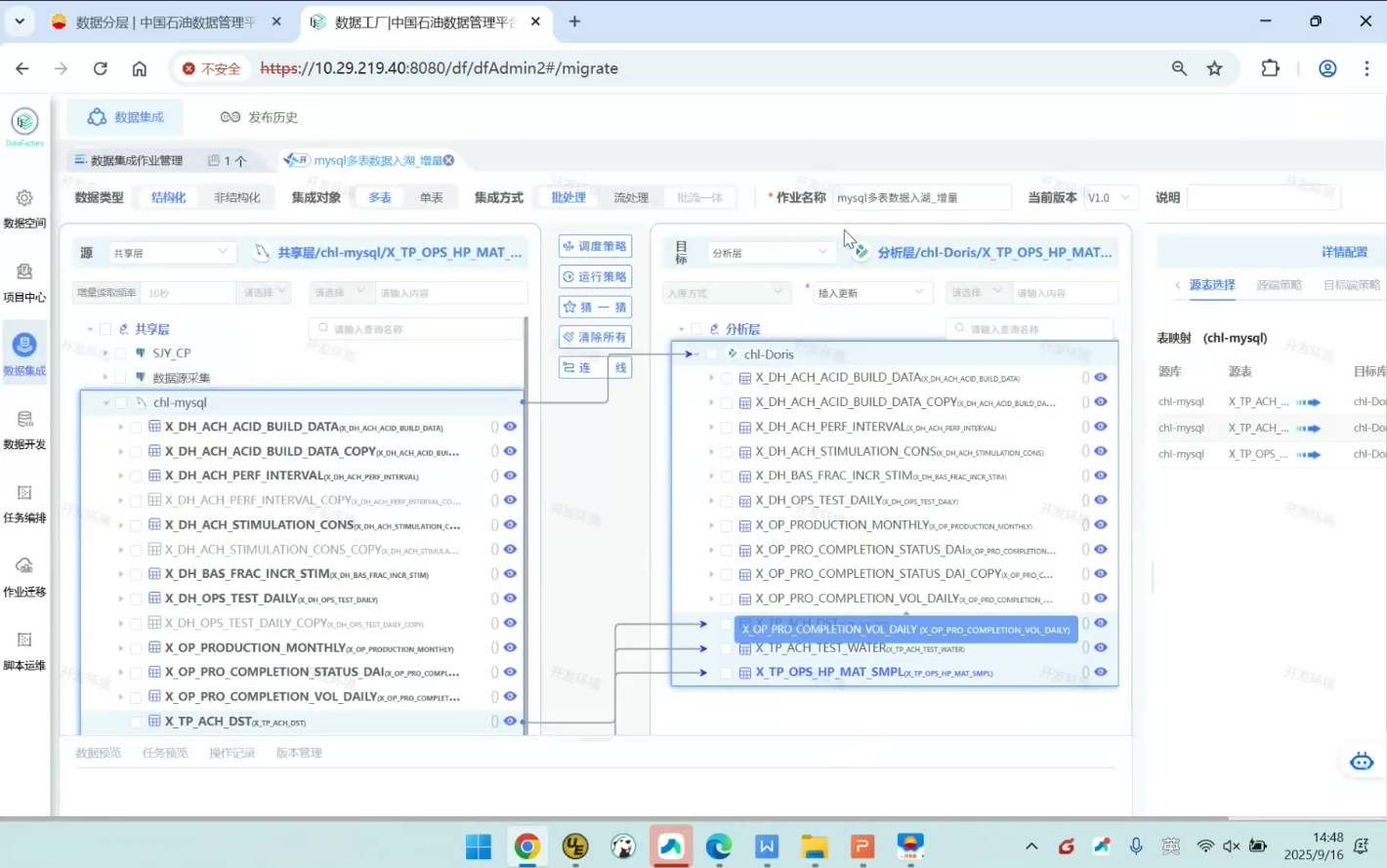
打开3张表的作业如图
单表模式
某些场景,源表和目标表是异构的,做字段映射,这时候就用到单表模式
新建作业
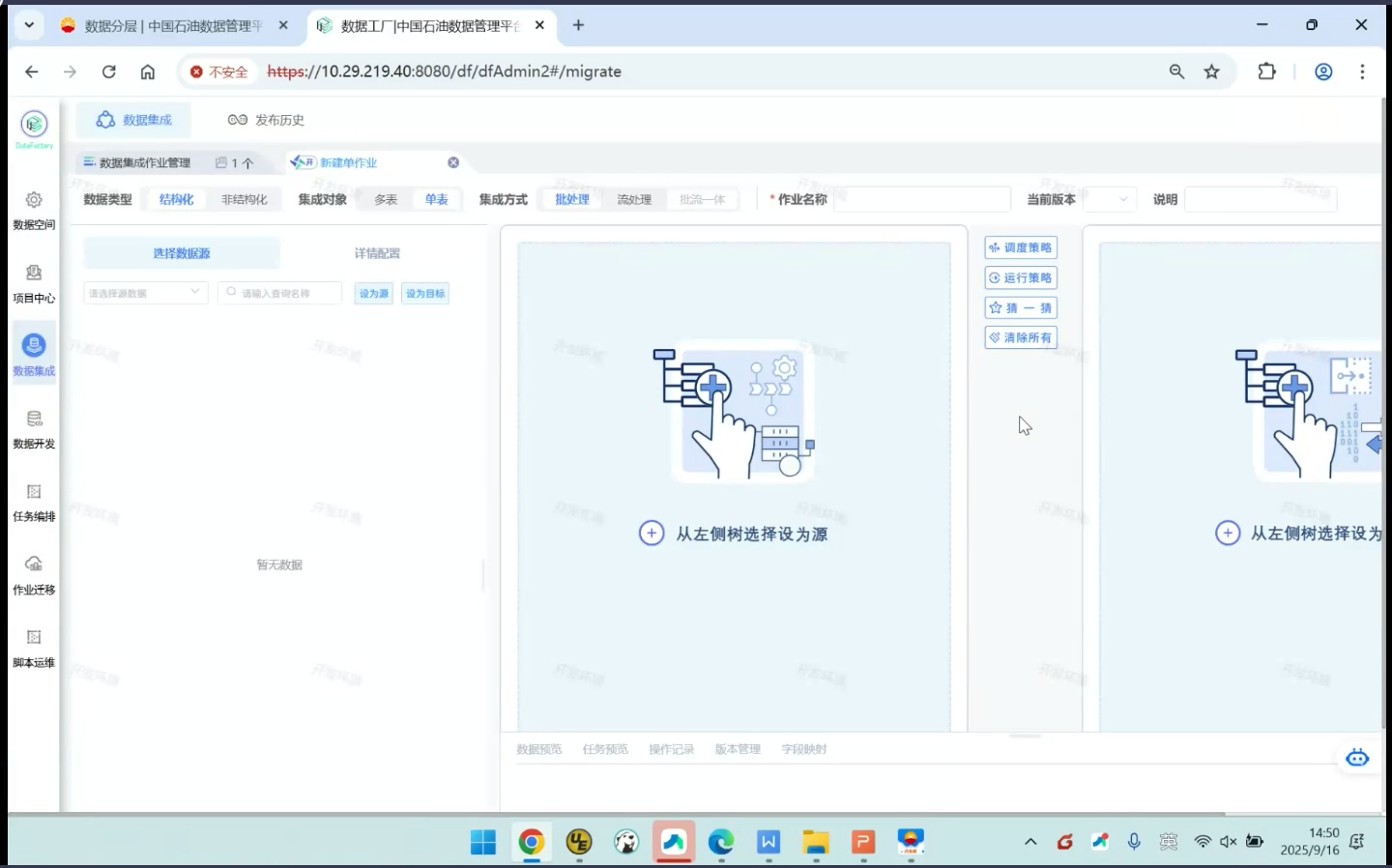
单表模式,源端和目标端就都只能选一张表。先在源端选择一张表,点击设为源,再在目标端选择一张表,点击设为目标
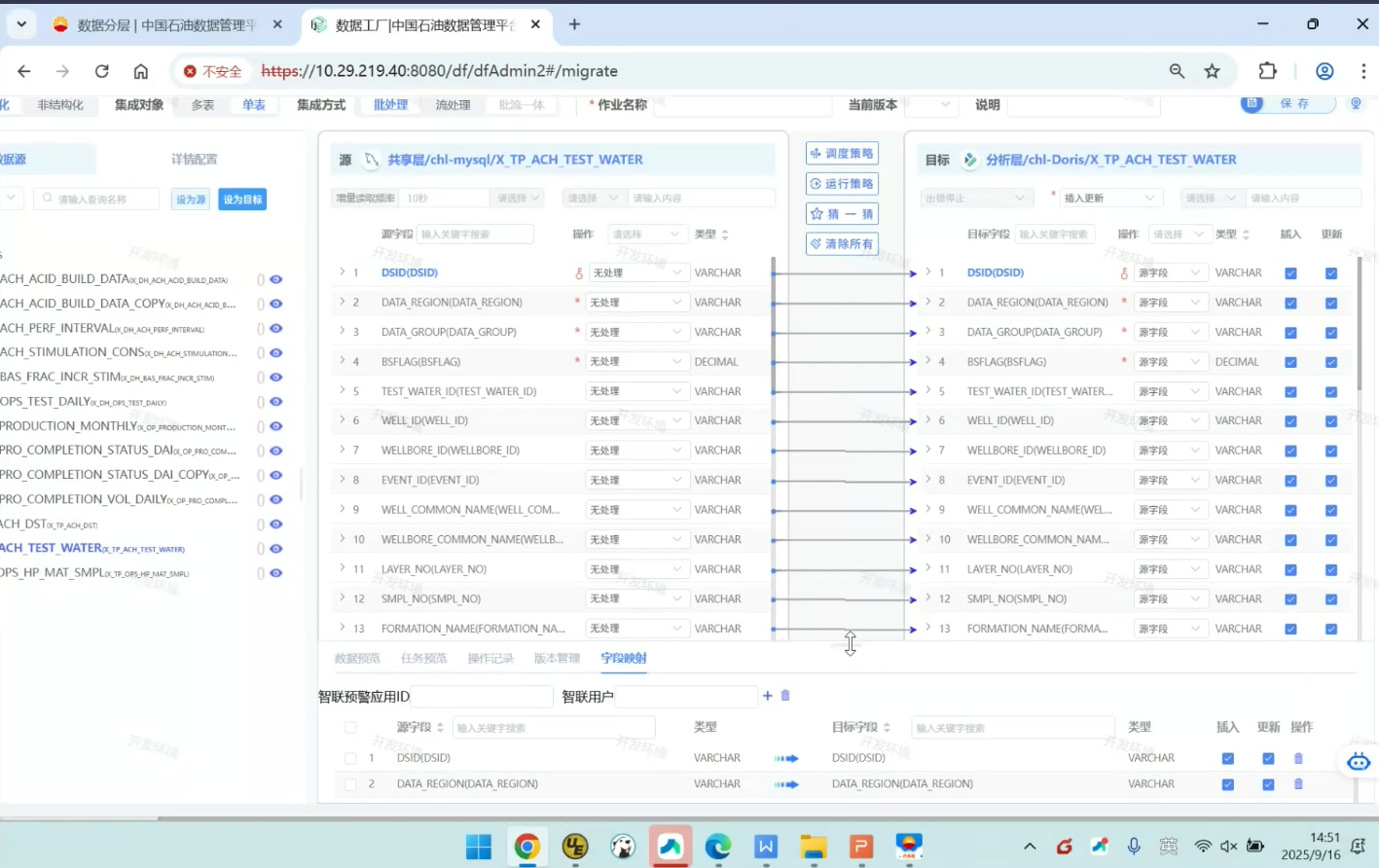
字段不想做映射可以点击连线删掉,可以通过拉线的方式给不同名的字段作映射
详情设置-源端策略
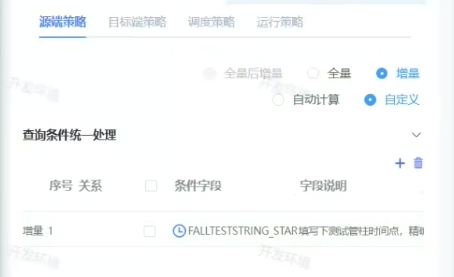
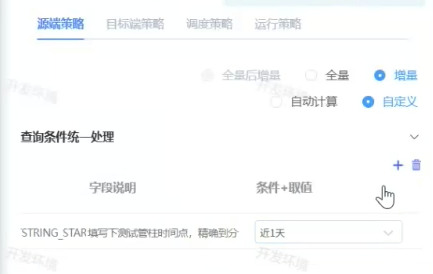
全量和增量
在数据迁移/数据同步里,全量 和增量是在问:
这次从源表里取多少数据?
1. 全量是什么意思
全量 = 每次都把源表所有数据都取出来。
比如源表 X_TP_ACH_DST 里有 100 万条数据。
选择全量时,任务每次执行都会读:
select *
from X_TP_ACH_DST;也就是:
不管这些数据以前有没有同步过,都重新取一遍。全量适合什么情况
适合:
第一次迁移
数据量不大
目标表需要整体重刷
源表没有更新时间字段
不方便判断哪些是新增/修改数据比如第一次把 MySQL 的表同步到 Doris,通常会先跑一次全量。
2. 增量是什么意思
增量 = 只取新增或变化的数据。
比如昨天已经同步过 100 万条,今天源表新增/修改了 500 条。
选择增量时,任务只同步这 500 条。
常见 SQL 思路是:
select *
from X_TP_ACH_DST
where UPDATE_DATE > 上次同步时间;你图里左侧出现了:
UPDATE_DATE这个就很像增量字段。
它的作用是告诉系统:
根据 UPDATE_DATE 判断哪些数据是后来新增或修改的。
3. 用一个例子理解
源表:
| ID | NAME | UPDATE_DATE |
|---|---|---|
| 1 | A | 2025-09-15 10:00:00 |
| 2 | B | 2025-09-15 11:00:00 |
| 3 | C | 2025-09-16 09:00:00 |
假设上次同步时间是:
2025-09-15 23:59:59如果选全量:
同步 ID=1、2、3,全都同步如果选增量:
只同步 ID=3因为只有 ID=3 的 UPDATE_DATE 晚于上次同步时间。
4. 图里的"自动计算"和"自定义"是什么
你图里增量下面还有:
自动计算
自定义一般含义是:
自动计算
系统自己记录上次同步到哪里了。
比如系统记住:
上次同步到 UPDATE_DATE = 2025-09-15 23:59:59下次自动拼条件:
where UPDATE_DATE > '2025-09-15 23:59:59'自定义
你自己指定增量条件。
比如:
where UPDATE_DATE >= '2025-09-16 00:00:00'或者指定某个时间范围。
后面的三个策略和多表模式一样
作业配置完成之后,点击监控按钮
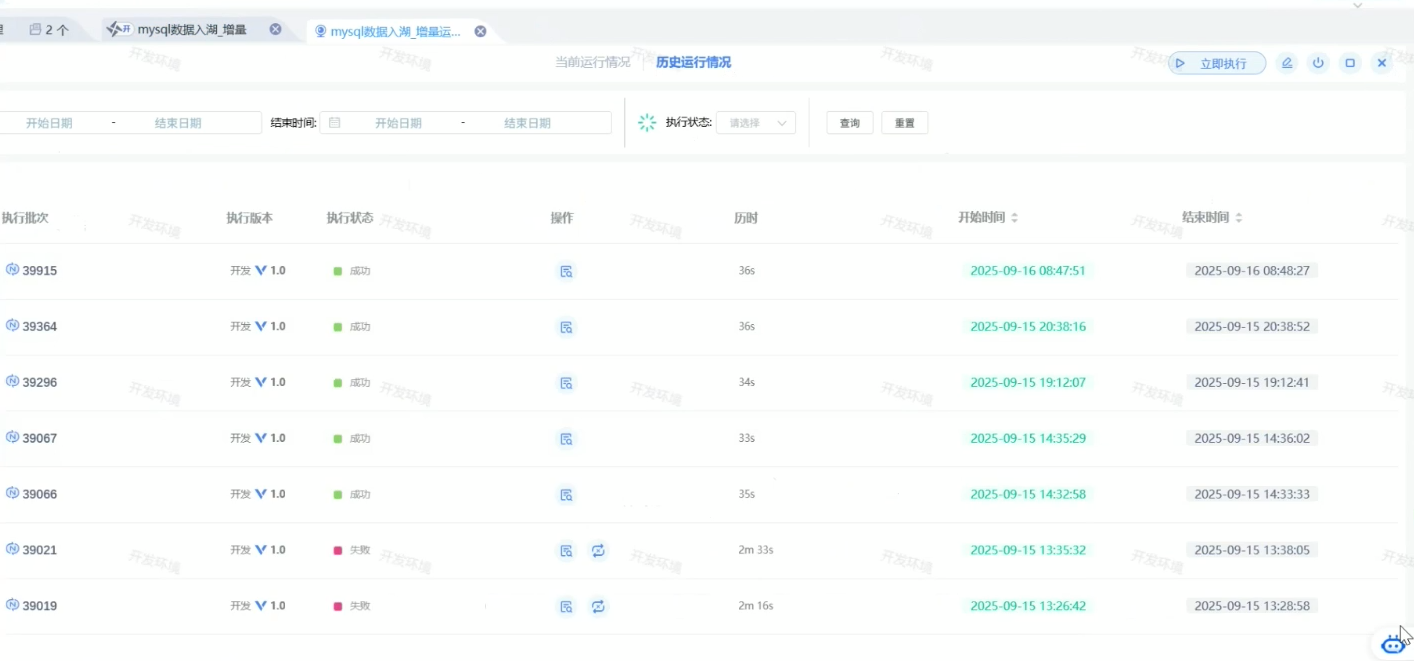
点击立即执行。注意列表不是实时刷新,点击查询刷新
运行成功后,操作-查看详情
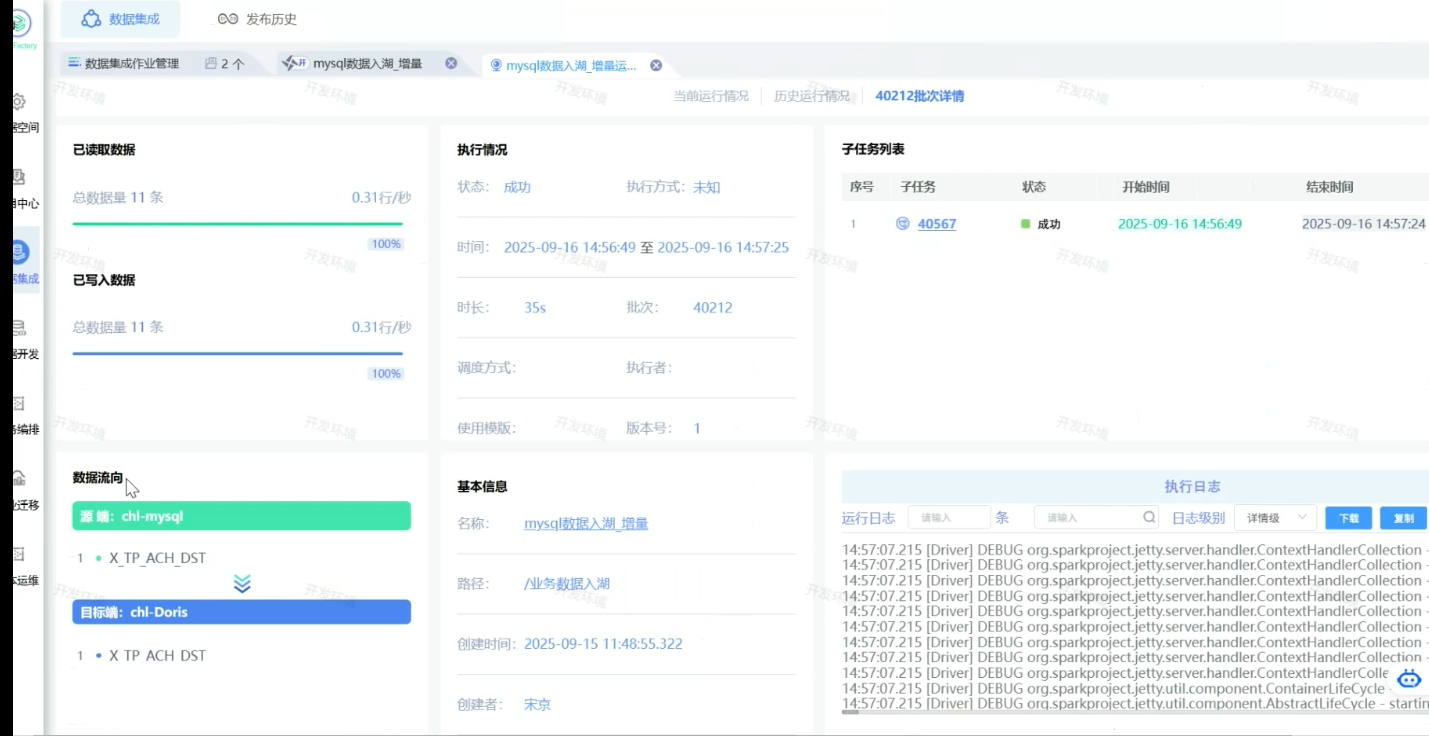
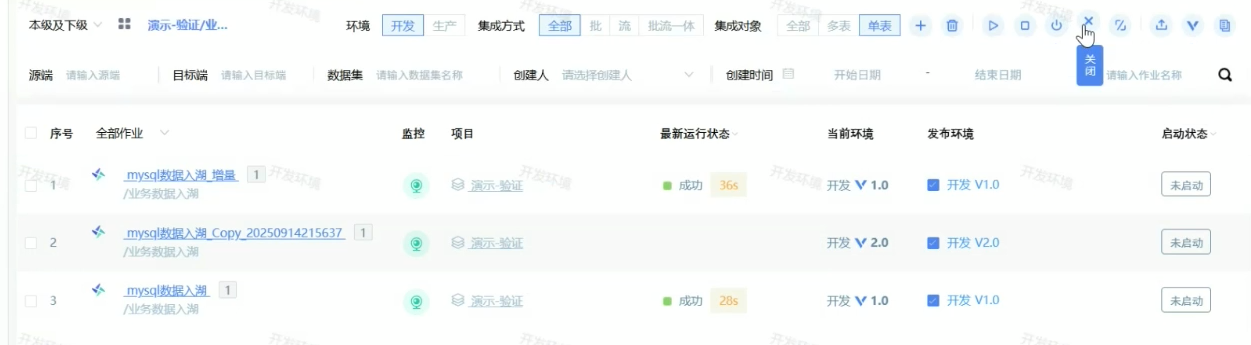
来到这里给作业执行,作业才会开始周期性调度
数据开发
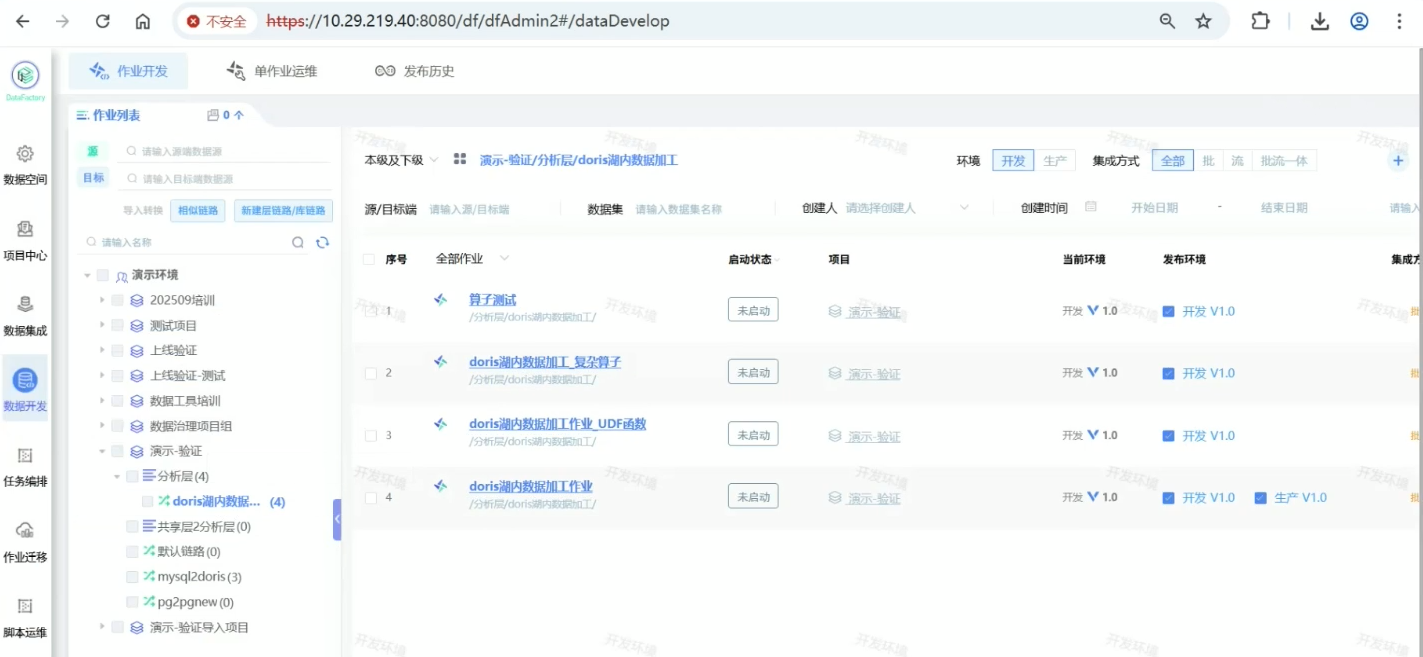
点击 +
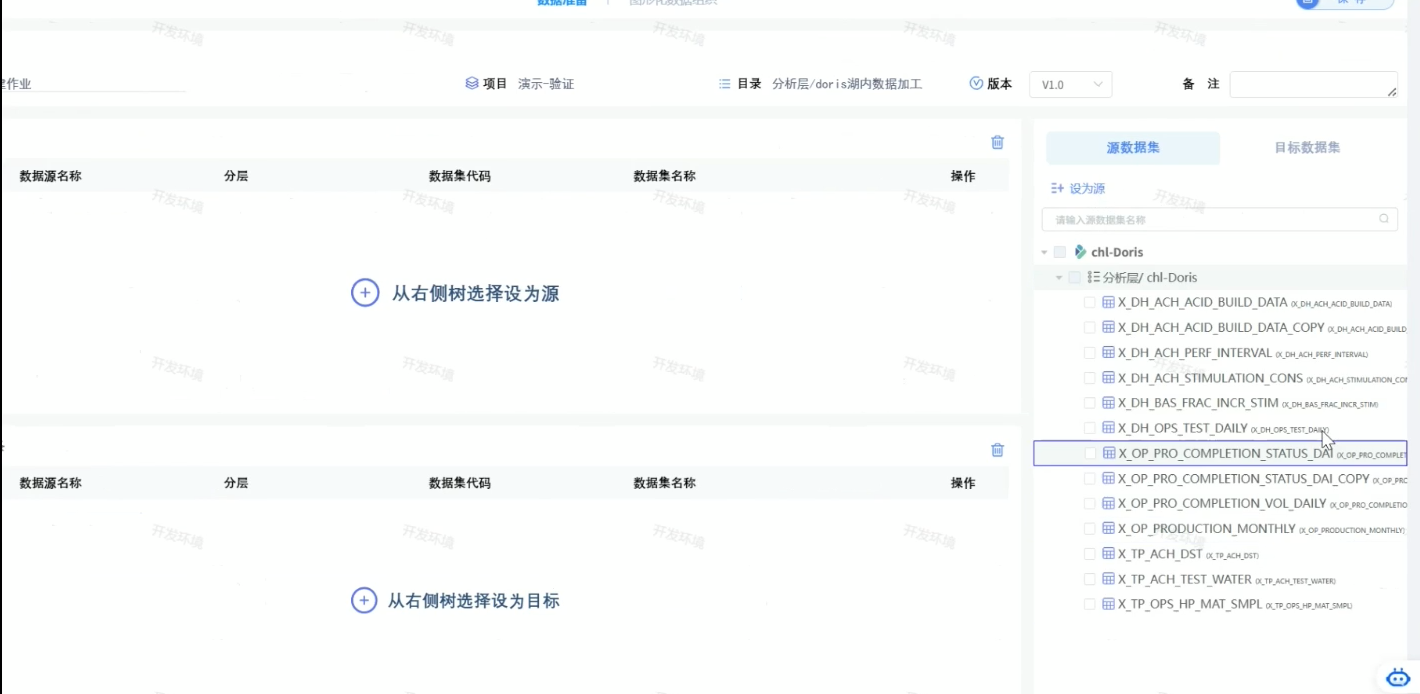
到此界面,按照地面工程建设.xlsx 填写项目名称和源数据集,目标数据集。
项目名称就是表里的作业这一列,源数据集选择后设为源,目标数据集同理。
保存-直接按默认的点击确定-数据准备阶段结束
来到图形化数据组织界面
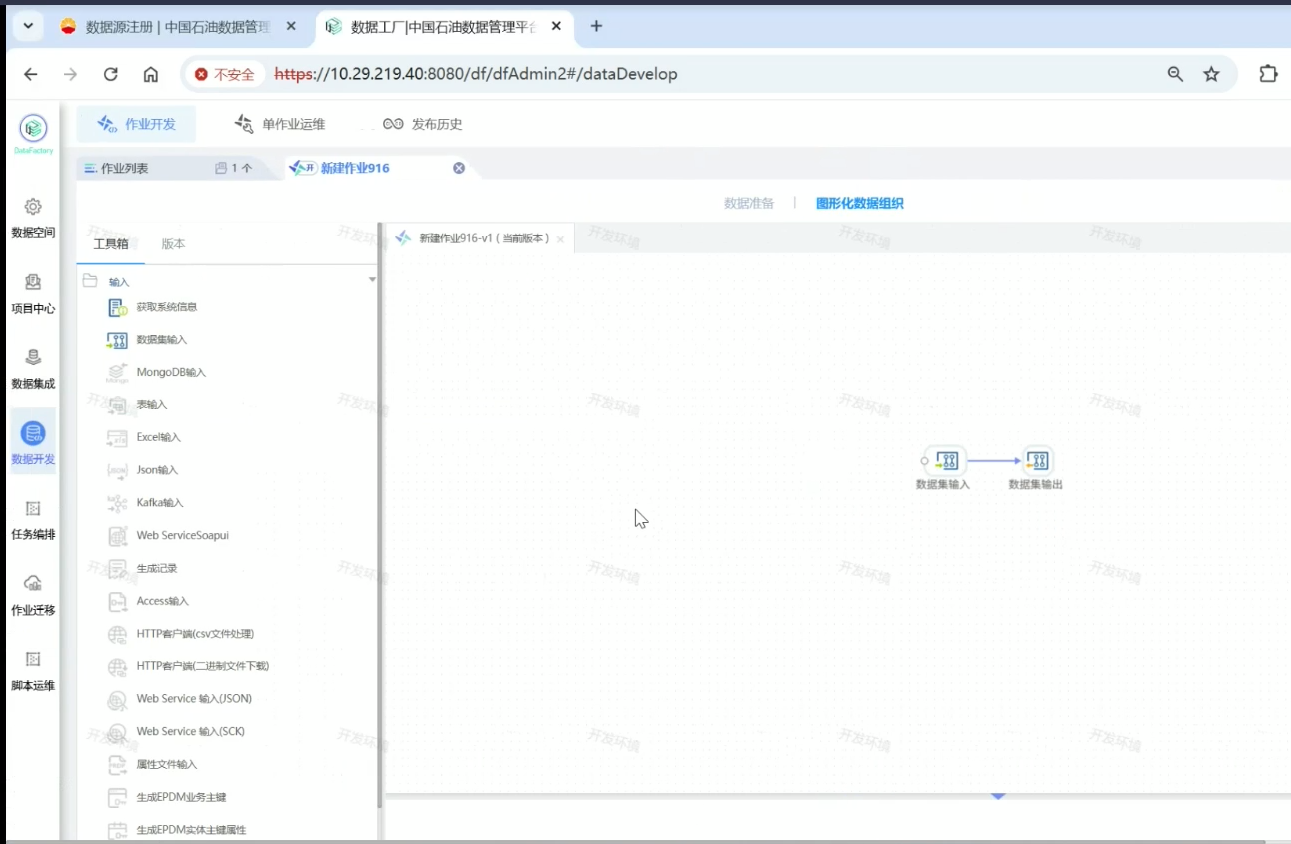
双击数据集输入-下方出现源数据集信息
数据集详情
SQL编辑界面写上文档给的sql代码,按要求改,点击sql校验
双击数据集输出-更新字段-获取更新字段-字段映射-确定-猜一猜-确定-保存
单作业运维-选中正在做的作业的序号-立即执行-确定
点进该作业-历史运行情况
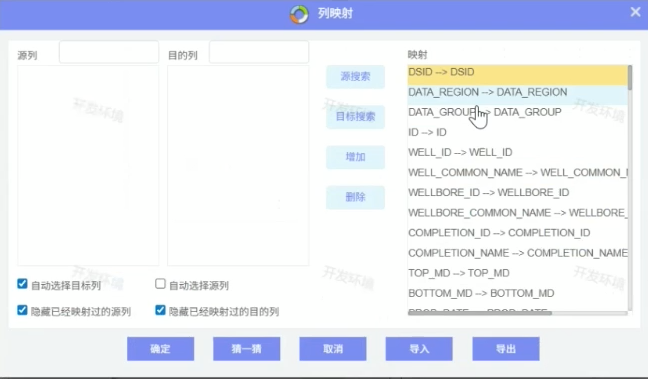
同名映射已经默认进行了猜一猜,不满意的就点删除,删除的就会去左边两个地方。