目录
[一、YOLOv8 网络结构详解](#一、YOLOv8 网络结构详解)
[2、实例分割 Head 差异](#2、实例分割 Head 差异)
[1、ONNX 导出](#1、ONNX 导出)
[2、TensorRT 导出与构建](#2、TensorRT 导出与构建)
[3、INT8 量化流程](#3、INT8 量化流程)
[五、TensorRT 引擎构建与推理](#五、TensorRT 引擎构建与推理)
[1、Builder 与 Runtime](#1、Builder 与 Runtime)
前言
本文介绍 YOLOv8 及其目标检测/实例分割应用的完整知识体系:从网络结构(backbone、neck、anchor-free 分离式 Head 等)到训练流程(数据格式、增强、损失函数、指标、调参策略),再到实例分割细节(mask 表示、后处理、评价指标),最后讲解模型导出(ONNX、TensorRT)与部署优化(精度模式、量化、引擎构建、推理代码)。
一、YOLOv8 网络结构详解
1、YOLOv8网络结构
YOLOv8 是 Ultralytics 2023 年推出的新一代 YOLO 系列模型,主要改进在于:Anchor-free 分离式 Head 、改进的骨干网络和颈部结构、以及多任务支持(检测、分割、姿态等)。其整体结构仍采用常见的"Backbone--Neck--Head"三段式设计,如下所示:
-
Backbone (主干网络) :基于改进的 CSPDarknet53 结构,用以提取多尺度特征。YOLOv8 将输入图像先通过两个 3×3 步幅为 2 的卷积层(Stem),将分辨率从 640×640 降到 160×160,同时扩大通道;然后依次经过多个 C2f 模块(Cross-Stage Partial with 2 convolutions)和下采样,形成4个阶段特征。与 YOLOv5 的 C3 模块相比,C2f 更注重特征复用:它将特征图分两路,一路通过两次卷积并引入残差连接,最后拼接融合,从而提升表达力且参数更少。
-
Neck (颈部网络) :采用融合多尺度特征的策略,类似于 FPN+PAN 结构。YOLOv8 的颈部从 backbone 的最后一个阶段输出接入 SPPF (Spatial Pyramid Pooling-Fast) 模块(通过多尺度最大池化融合不同感受野特征);随后逐层上采样并与更浅层特征拼接(Concatenate),再经过一层 C2f 卷积进一步整合,如下图所示。这样做的好处是既保留了深层语义特征,也融合了浅层高分辨率信息,以同时检测大中小目标。
flowchart LR
A[Input Image 640×640×3] --> B1[Stem: 2×{Conv3×3, Stride2}]
B1 --> C1[C2f ×3 (Output 160×160×64)]
C1 --> C2[C2f ×6 (Output 80×80×128)]
C2 --> C3[C2f ×6 (Output 40×40×256)]
C3 --> C4[C2f ×3 (Output 20×20×512)]
C4 --> S[SPPF]
S --> U1[Upsample to 40×40]
U1 --> NC1[Concat with C3 \n→ C2f]
NC1 --> U2[Upsample to 80×80]
U2 --> NC2[Concat with C2 \n→ C2f]
NC2 --> HeadSmall[Small Obj Head (80×80)]
NC1 --> HeadMedium[Medium Obj Head (40×40)]
S --> HeadLarge[Large Obj Head (20×20)] -
Head (检测头) :采用 无锚点分离式 (anchor-free, decoupled) 结构 。无锚点意味着不用预定义锚框,直接回归目标中心位置和宽高,提高准确率并简化训练。Head 由三部分并行分支组成:目标度分支 (Objectness,用 sigmoid 输出是否有目标)、分类分支 (Classification,用 softmax 输出类别概率)和回归分支(Bounding-box,用 CIoU Loss 回归框参数并结合分布式焦点损失 DFL)。这种"解耦"设计使回归与分类互不干扰,收敛更快、更鲁棒。输出层对多尺度特征图(小中大三个尺寸)分别预测,适应不同大小目标。
-
损失函数:YOLOv8 综合了多种损失:
- CIoU Loss (包含 IOU、中心点距离和长宽比项) 用于盒子回归。
- Distribution Focal Loss (DFL):将边界框回归视为概率分布,增强定位精度。
- Binary Cross-Entropy (BCE):用于多标签分类(每个框判断该类的概率)。
- 总损失公式大致为:
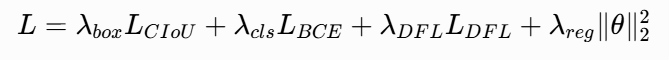
其中各分量根据类别数和正样本数加权平均。
-
NMS (Non-Maximum Suppression) :YOLOv8 的推理仍需要对预测框执行 NMS 或类似的后处理,以去除重复检测。这可以在导出模型时指定(见后文),或者在代码端使用如
ultralytics.utils.nms等函数处理。 -
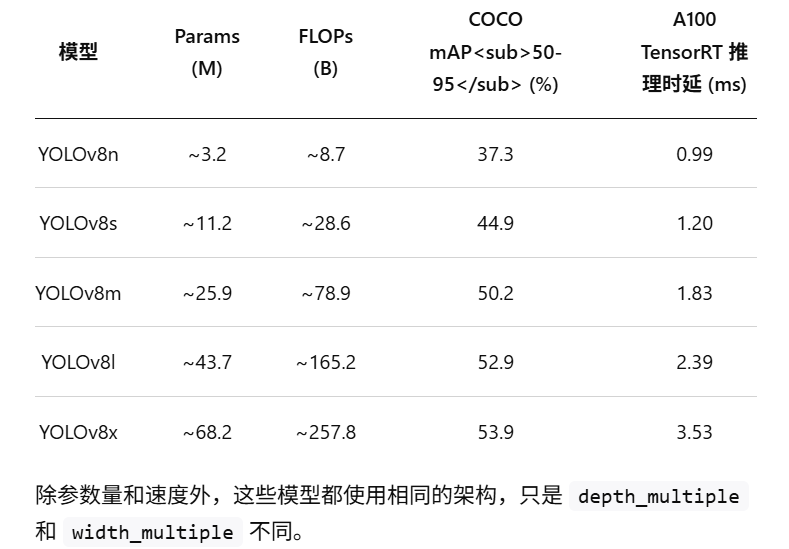
模型变体 :YOLOv8 提供多种规模的模型(Nano、Small、Medium、Large、Xlarge,后缀分别为
n/s/m/l/x),其主要区别在于深度(C2f 模块重复次数)和通道宽度(width_multiple)。例如,YOLOv8n ("nano") 极简设计参数少,适合部署;YOLOv8x ("extra large") 则通道更多,精度最高但计算量大。从官方指标看,随着模型增大,COCO 验证 mAP 提升,而参数量与 FLOPs 急增:
2、实例分割 Head 差异
YOLOv8-seg(实例分割版)在检测模型基础上增加了分割头,结构上参考了 YOLACT 。其核心区别是:在检测分支之外,增加两个用于生成实例掩码的分支:ProtoNet(原型网络)和Mask Coef 分支。ProtoNet 是一组卷积层(FCN),对顶层特征生成一系列 mask 原型(例如输出形状 32×h×w),Mask Coef 分支则为每个检测框预测一组系数。这些系数与 ProtoNet 的原型线性组合,就得到每个实例的 mask。
解释说:Seg 模型"增加了一个额外输出模块输出掩码系数,以及名为 Proto 的 FCN 层输出原型 masks"。最终,掩码是多原型加权叠加后的结果并裁剪到目标框。训练时使用二值掩码的 BCE/L1 损失使 mask 与真实多边形一致(可用 COCO RLE 或多边形格式表示)。
二、训练流程
1、数据格式与准备
- 检测任务 :YOLOv8 使用 YOLO 格式 数据集,即每张图有一个同名
.txt文件,每行格式class x_center y_center width height,坐标均归一化到[0,1]相对于图像宽高。Ultralytics 的data.yaml文件定义训练/验证图像列表和类别名,用于model.train(data="data.yaml")调用时加载数据。 - 实例分割任务 :标签可以是 COCO 格式的 JSON(多边形标注)或转换为 Ultralytics JSON2YOLO 工具生成的分割格式(mask 可存为 PNG 或多边形)。训练时需同时提供
mask信息。
2、数据增强
YOLOv8 训练时使用了丰富的数据增强以提高泛化能力。常用增强包括:
- Mosaic :将4张图随机拼接为一张,增大背景多样性。YOLOv8 默认
mosaic=1.0(全程开启)。可在后期关闭(close_mosaic参数),以免学习不稳定。 - MixUp:随机混合两张图,配合权重叠加标签,减少过拟合。
- Random Perspective :包括平移、缩放、旋转、裁剪等(Ultralytics 实现为
RandomPerspective),模拟相机视角变化。 - 颜色抖动 :HSV 颜色通道随机调整(
hsv_h,hsv_s,hsv_v)、随机亮度/对比度变化。 - 翻转 :随机左右翻转(
flipud,fliplr)。 - 其他:可能还有 Cutout、Copy-Paste 等高级变换。
通过多样化样本,模型更鲁棒地识别不同尺寸、遮挡和背景下的目标。
3、训练超参数
常用超参数包括:学习率、批大小、优化器、损失权重等。Ultralytics 提供自动超参/学习率功能,但基本原则如下:
- 批大小 (batch size):根据显存选取,如 16、32 等;较大批次提高稳定性,但需降低学习率(可采用线性缩放法)。
- 学习率 (LR):YOLOv8 默认用 AdamW 优化器,可设置初始 LR,如 1e-3。常用 Warm-up 预热(前数百步线性升高 LR)然后余弦退火或阶梯衰减。
- 迭代周期 (epochs):常见为 300-500 epochs,具体视数据量而定。若数据量少,可减少 epoch;若继续提升,则增加 epoch。
- 损失权重:一般使用默认值(如 λ_box、λ_cls、λ_dfl等),无需手动调整;如果类别极不平衡,可增加正样本权重或使用 focal loss(YOLOv8 默认用 BCE,不同于 YOLOX 的 focal)。
- Freeze 层 :训练初期可冻结骨干层以加快收敛;自定义数据集时可用
freeze参数。
4、训练过程和命令
典型的训练命令(Python如下:
from ultralytics import YOLO
model = YOLO("yolov8n.pt") # 加载预训练模型(n/s/m/l/x)
results = model.train(data="mydata.yaml", # 数据集配置文件
epochs=100, # 训练轮数
imgsz=640, # 输入尺寸
batch=16, # 批大小
device=0, # GPU 设备
augment=True) # 是否开启数据增强这个过程会自动输出训练日志,包括每个 epoch 的损失、学习率、mAP 等指标,并保存在 runs/train/exp... 文件夹。
5、验证与指标
- 指标 :主要关注 COCO 风格的 mAP@0.5 和 mAP@.5:.95(即不同 IoU 阈值下的平均精度),以及 Precision、Recall 等。在训练过程,Ultralytics 会打印验证集上的 mAP 等统计数据,终训后也可通过
model.val()函数得到详细指标。 - AP 和 IoU:对于检测任务,标准是 COCO AP;对于分割任务则使用 COCO mask AP。AP是 precision-recall 曲线下面积,IoU(交并比)定义为衡量预测框/掩码与真值的重叠程度,常用 IoU 0.5 和更高门限评价。
- 常见问题:训练时可能出现过拟合(验证 mAP 停滞或下降)、小目标召回率低(可增大输入尺寸或数据增强)、标签错误(可检查重叠框)、LR 设置不当等。调参技巧包括:调整 lr、增加数据、多尺度训练、冻结层,或使用更大/更小模型等。
6、损失与优化
YOLOv8 内部使用的默认损失参见上一节网络部分,Ultralytics 包含所有细节,无需手动实现。但理解损失构成有助于调参。如若准确度不足,可调整目标框的 IoU 权重(放大 λ_box)或分类权重(λ_cls),也可尝试更大的模型。
三、实例分割实现细节
YOLOv8-seg 在训练时要求每个目标的精确轮廓(多边形)标注,输出相应的二值掩码(mask)或多边形坐标。推理输出为每个检测框对应的掩码。下面是关键步骤和知识点:
-
Mask 表示 :YOLOv8-seg 内部使用 原型掩码 (Prototype masks) 加掩码系数的方法,即类似 YOLACT。具体地,ProtoNet 输出一组原型特征图(如 32 个通道),Mask Coef 分支输出每个目标的一组系数。掩码 = sum(coef_i * prototype_i)(按元素相加),然后裁剪到目标框区域,并阈值化为二值。训练时计算每个掩码与真实多边形掩码之间的 BCE/L1 损失。
-
后处理:检测后得到的框做 NMS 去重,再应用其对应掩码。掩码区域可根据框坐标截取并膨胀裁剪,以获得精确分割。一般还会对掩码进行像素级阈值(如 0.5)以得到清晰轮廓。对于实例分割可视化,通常会将掩码转换为轮廓多边形 (COCO 格式) 或直接显示二值化 mask。
-
评价指标:除了目标检测的 mAP(盒子精度),实例分割额外看 Mask mAP(COCO 评估的 mask AP)。通常报告 mAP<sub>50:95</sub>(不同 IoU 阈值下平均)以及 mAP<sub>50</sub>。IOU 计算的是二值掩码重叠比例。高质量分割要同时关注框精度和掩码边界精度(精准分割边缘)。
-
应用场景举例:实例分割适用于需要精确目标轮廓的场景,如机器人抓取中精细物体提取、道路场景中行人与车辆分割、医学影像器官/病变分割、工业检测中缺陷定位(需要掩码)等。YOLOv8-seg 通过同时检测和分割提供"一步到位"的解决方案。
四、导出模型与部署前准备
在部署阶段,通常将训练好的 YOLOv8 模型导出成通用格式(ONNX、TorchScript、TensorRT 引擎等),以便在不同平台加速推理。关键步骤和注意事项如下:
1、ONNX 导出
-
基础 :使用 Ultralytics API,可直接从
.pt权重导出 ONNX:from ultralytics import YOLO
model = YOLO("best.pt")
model.export(format="onnx", imgsz=640, dynamic=True, simplify=True)
其中 dynamic=True 允许输入尺寸可变(需要建立合适的优化配置);simplify=True 会调用 onnx-simplifier 对图优化,提高兼容性和效率。
-
算子兼容:YOLOv8 导出 ONNX 时主要包含常见算子(Conv、Concat、Sigmoid、Upsample、Reshape 等)。Ultralytics 库已经对很多常用算子做了支持转换,大多数情况无需额外处理。但如果自定义层或算子(如自定义激活、特殊 NMS)未被支持,则需手动实现 Onnx Op 或后续在 TensorRT 中用 Plugin 替代。
-
NMS :导出 ONNX 时可选择是否内置 NMS 插件。Ultralytics export 提供
nms参数,若设nms=True会在模型中添加 NMS 层。但一般建议在代码端自行做 NMS,以便与业务逻辑灵活配合。注意:部分端到端模式的模型(如 YOLO6 等)用内置 NMS,可设置end2end=False以兼容常规 NMS 管道。 -
半精度/量化 :在导出 ONNX 时可加
half=True生成 FP16 网络(仅支持 GPU),减半模型体积并提升部分 GPU 性能。INT8 量化对于 ONNX 导出不直接支持 ,Ultralytics 文档中提到 INT8 主要在导出 TensorRT 时使用(ONNX 导出只允许half)。
2、TensorRT 导出与构建
Ultralytics 直接支持将模型导出成 TensorRT engine 文件(封装了 builder/runtime 流程)。常用方法:
from ultralytics import YOLO
model = YOLO("best.pt")
model.export(format="engine", imgsz=640, half=True, dynamic=True, workspace=4.0)format="engine"会生成如best.engine的序列化文件。- 可选参数包括
half=True(FP16 精度)、int8=True(启用 INT8 量化)、dynamic=True(动态形状)、workspace(显存限制,单位 GiB)。 - 导出过程中,Ultralytics 内部会先调用 ONNX,再使用 NVIDIA 的 Model Optimization (ModelOpt) 做量化(TensorRT 11+)或使用 TensorRT 自带校准(TensorRT 7-10)。
若不使用 Ultralytics API,可手动流程:
-
导出 ONNX(见上节)。
-
使用
trtexec或 TensorRT Python/C++ API 生成 engine。例如命令行:trtexec --onnx=best.onnx --saveEngine=best.engine --fp16 --workspace=4096这会自动调用 TensorRT Builder,将 ONNX 转为优化后的 engine。加
--int8需要提供校准数据集(参照下文)。 -
若 ONNX 中含 NMS,可以用 TensorRT 的内置 NMS 插件加速;若没有,则在后处理阶段自行执行 NMS。
3、INT8 量化流程
- 量化原理:将 32/16 位浮点转换为 8 位整数,大幅减小模型大小、提速但可能有微小精度损失。TensorRT 支持后训练量化(PTQ)方式,需要代表性校准数据。
- Ultralytics 接口 :在
export时设int8=True(仅支持 TensorRT 导出),并提供数据集 config (data="coco.yaml")。工具会自动选取data.yaml中的训练图片作为校准输入,用 ModelOpt 插件插入量化和去量化节点。 - 设备一致性:文档强调:导出时应使用与部署相同 GPU,以确保校准一致。
- 调优 :可以通过
workspace增大搜索空间(注意耗时与显存),或改变校准算法 (ENTROPYvsMINMAX,Ultralytics 默认在 GPU 上用MINMAX)。若校准失败应缩小workspace或使用部分数据(通过fraction参数控制,默认为 1.0 全数据)。
4、导出示例
Ultralytics 文档给出完整流程示例:
from ultralytics import YOLO
# 1. 加载训练好的模型
model = YOLO("yolov8m.pt")
# 2. 导出为 ONNX(可选)
model.export(format="onnx", imgsz=640, dynamic=True, simplify=True)
# 3. 导出 TensorRT engine (FP16 & dynamic)
model.export(format="engine", imgsz=640, half=True, dynamic=True)
# 4. 推理:直接加载 engine
engine_model = YOLO("yolov8m.engine")
results = engine_model("test.jpg") # 类似原生 YOLO API 使用五、TensorRT 引擎构建与推理
1、Builder 与 Runtime
- Builder :TensorRT 提供 Builder 接口(C++/Python)读取 ONNX 网络,进行硬件相关优化(图层融合、选择最优 kernel),并生成序列化的 Engine (Plan)。整个过程通常通过
trtexecCLI 或代码调用IBuilder完成。 - Runtime :负责加载 Engine(
.engine文件)到 GPU 中,并执行推理。常见流程:ICudaEngine = runtime.deserialize_cuda_engine(...)得到引擎后,用上下文IExecutionContext在 GPU 上多线程执行前向推理。
2、插件与兼容性
大部分 YOLOv8 模型层都被 TensorRT 原生支持,但有几个注意点:
- NMS 插件 :TensorRT 自带 batched NMS Plugin,能在 GPU 上高效执行非极大抑制。如果导出时将 NMS 内置(见上文
nms=True),则模型中已有 NMS 算子;否则需在 CPU/Python 端或以 plugin 形式处理。 - Unsupported Ops :极少数算子(例如 PyTorch 特有的 ops)可能需 ONNX 匹配或自定义 Plugin。通过
trtexec或trt.OnnxParser时,会报告不支持操作(UNSUPPORTED)。若出现,则可使用 TensorRT 的 plugin 机制实现该算子,或修改网络结构(如把特殊归一化改为通用算子)来规避。 - Dynamic Shape :若导出时指定了
dynamic=True,需要在构建时设定最小/最优/最大 profile 以支持动态输入尺寸。提到要为 TensorRT 的 export 指定batch和device,但构建时也要用builder.build_serialized_network(network, config)并设置config.profiles。
3、性能调优
- 精度与速度 :使用 FP16(或 INT8)通常带来 2× ~ 4× 的吞吐提升。在导出或构建时开启
half或int8。使用 INT8 时请检查精度损失是否可接受。 - Workspace 大小 :
workspace参数控制 TensorRT 最大可用内存空间,用于搜索最优算法。较大 workspace 可能获得更快模型,但校准和构建时间更长。如构建失败(UNSUPPORTED_STATE),尝试降低此值或设None。 - Batch Size:引擎构建时可以指定最大 batch 大小。实际使用时,也可在 runtime 中多张输入一次推理,但要在构建时就设定上限。
- Profile 优化:若使用动态尺寸,确保建立了合理的张量动态范围(min/opt/max),以充分利用 INT8/FP16。
4、推理代码示例
Python(TensorRT API)示例:
import numpy as np
import tensorrt as trt
TRT_LOGGER = trt.Logger()
# 1. 解析 ONNX 并构建引擎
with trt.Builder(TRT_LOGGER) as builder, \
builder.create_network(1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH)) as network, \
trt.OnnxParser(network, TRT_LOGGER) as parser:
builder.max_workspace_size = 2 << 30 # 2 GB
builder.fp16_mode = True # FP16
with open("yolov8.onnx", "rb") as f:
parser.parse(f.read())
engine = builder.build_cuda_engine(network)
# 2. 推理
import pycuda.driver as cuda, pycuda.autoinit
context = engine.create_execution_context()
# 创建输入输出缓冲区
input_shape = (1, 3, 640, 640)
input_size = trt.volume(input_shape) * trt.float32.itemsize
d_input = cuda.mem_alloc(input_size)
h_input = np.ascontiguousarray(preprocess(img)) # letterbox + /255
cuda.memcpy_htod(d_input, h_input)
outputs = []
for binding in engine:
if not engine.binding_is_input(binding):
size = trt.volume(context.get_binding_shape(binding)) * trt.float32.itemsize
outputs.append(cuda.mem_alloc(size))
# 执行推理
bindings = [int(d_input)] + [int(o) for o in outputs]
context.execute_v2(bindings)
# 从 GPU 读取输出,后处理
for i, output in enumerate(outputs):
h_out = np.empty(context.get_binding_shape(engine.get_binding_index(binding)), dtype=np.float32)
cuda.memcpy_dtoh(h_out, output)
results = postprocess(h_out) # 解码 + NMS注意: 上例仅示意流程,实际按需调整数据类型(float16/32)、后处理逻辑(YOLOv8 decode 及 NMS)。
5、输入/输出预处理与后处理
- 输入预处理 :YOLOv8 采用 LetterBox 缩放:将原图调整到指定尺寸(如640×640)并保持长宽比,空白处填充。然后归一化像素值到
[0,1](除以255),通道顺序为 RGB(若模型训练时如此)。代码上可用 Ultralytics 提供的model.predict自动处理,也可手动实现以上步骤确保与训练一致。 - 输出后处理 :TensorRT 输出通常是模型最后一层的 raw scores 和 bbox 回归结果,可能需要执行以下步骤:
- 解码框 :将网络输出的相对坐标(
tx,ty,tw,th)转换为图片坐标(利用网格偏移 + 尺寸缩放)。Ultralytics 库里yolo_decode完成此步骤,如果自己实现要注意计算方法。 - 筛选置信度:对每个预测框,保留类别置信度大于阈值的框(通常 ≥0.25)。
- 非极大抑制:对剩余框按类别执行 NMS(IoU 门限典型为 0.45)。TensorRT 可使用专用插件或手工对 CPU 端输出做 NMS。
- 掩码提取(分割任务):对每个检测框,使用 Mask Coef 和 Proto 输出生成对应的二值掩码。
- 解码框 :将网络输出的相对坐标(
6、性能测试与优化
- 指标 :常用帧率 (FPS)、延迟 (ms)、吞吐 (ms/batch) 评估。可用
trtexec --shapes测试单张图速度。Ultralytics 文档中给出 YOLOv8 在不同框架下的速度对比。 - 工具 :除了官方
benchmark工具,还可手动用 Pythontime测量多次推理平均耗时。对于 INT8,要特别比较精度损失前后的 mAP;对于FP16,则要验证对小目标的性能影响。 - 部署限制 :确保显存足够(尤其动态 + batch 较大时),必要时减小
imgsz或引擎的 Batch 大小。
六、常见问题与排查
- 精度下降:常发生在量化(FP16/INT8)或 ONNX/TensorRT 导出后,原因可能是:预处理不一致(比如颜色归一化差异)、IOU阈值不一样、NMS实现差异,或者 INT8 校准数据不足代表性。解决方法:检查数据流每一步是否匹配(如 RGB/BGR 顺序、0-1范围),尝试更换校准算法/数据,或退到 FP16 精度。
- 算子不支持 :如果
trtexec提示 UNSUPPORTED , 检查 ONNX 模型是否含有非标准算子(GatherND、自定义算子等)。可以尝试升级 TensorRT 版本,或修改网络(如用等效算子替代)。对于 Mask 原型操作,通常支持良好,但自定义损失等仅训练时用到。 - 内存/延迟瓶颈 :若模型太大或 batch 太大,可能 OOM。可减小
workspace、imgsz或批次;或者在创建 Engine 时设定较小max_batch_size。对于延迟高,尝试开启 pipelining 或多流推理,或更换更快的 GPU
七、面试准备建议
1、核心考点清单
- YOLOv8 vs 早期 YOLO:Anchor-free (vs anchor-based YOLOv3/v5)、新的 C2f 模块、分离头、支持分割/姿态等。
- 网络结构:CSPDarknet53 变体、C2f 模块原理(分裂+残差+融合)、SPPF 和 PAN 融合。
- Head 设计:目标度/分类/回归三分支、CIoU+DFL+BCE 损失、无锚框回归中心。
- 训练数据:YOLO 格式标签、COCO 规范、增强方法(Mosaic、MixUp、RandomPerspective 等)。
- 实例分割:YOLACT 原型掩码思想、输出 mask/coefficient 机制、输出格式 (RLE/polygon)。
- NMS:非极大抑制的原理和作用(去除重复框)。
- 评价指标:AP、mAP、IoU 概念和计算方法、Precision/Recall/F1。
- ONNX/TensorRT :导出步骤(model.export)、量化(FP16/INT8)流程、Builder/Runtime 概念、插件、常用 API、
trtexec。 - 部署优化:半精度加速、Batch 大小/Workspace 设置、算法融合、异步推理等。
- 常见问题:量化误差、输入处理不一致、导出失败常见原因及解决思路。
2、可能面试问答示例
-
问 :YOLOv8 为什么不用锚框?
答:YOLOv8 采用 Anchor-free 设计,直接回归目标中心位置和宽高,省去了预定义多个比例锚框和复杂匹配的步骤。这简化了超参数,提升了训练效率,同时在不同数据集上更具鲁棒性。
-
问 :YOLOv8 的 C2f 模块有何作用?
答:C2f 是一种改进的 CSP 模块。它把输入特征图一分为二,一部分直接跳过,另一部分经过两次卷积和残差,最后拼接融合。这样可以增加网络宽度和多分支特征复用,使模型在增加通道利用率的同时控制计算成本。
-
问 :如何从 YOLOv8 模型获得实例掩码?
答:YOLOv8-seg 模型在检测头之外有 ProtoNet 和 mask coefficient 头。ProtoNet 输出若干原型掩码,mask coefficient 头为每个检测框预测一组系数。将系数与原型线性组合并阈值化后,就得到每个实例的分割掩码。
-
问 :导出 TensorRT 引擎时半精度和 INT8 的区别?
答:半精度 (FP16) 是对浮点精度降一半,通常可加速约 2 倍且几乎无精度损失(适用于支持 FP16 的 GPU)。INT8 则进一步量化权重和激活到 8 位,速度可以更高,但需要用校准数据衡量量化误差。使用 INT8 需要保证质量损失在可接受范围内。
-
问 :TensorRT 构建引擎过程是什么?
答:首先将训练模型导出为 ONNX 或其他中间格式,然后用 TensorRT Builder 解析 ONNX、优化图和内核、应用精度模式生成序列化引擎(engine)。之后在 Runtime 中加载该 engine,在目标 GPU 上执行推理。
-
问 :NMS 的作用是什么?
答:非极大值抑制 (NMS) 用于去除重叠度很高的重复检测框。它按照置信度排序,对重叠 IoU 超过阈值的较低置信度框进行抑制,只保留一个预测,避免同一对象被多次检测。