请写出Scaled Dot-Product Attention的计算过程,并解释为什么要除以√d_k
缩放点积注意力(Scaled Dot-Product Attention)是Transformer架构的核心运算,其计算过程可以简洁地表述为以下公式:
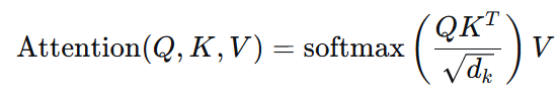
计算过程
假设输入为查询(Query)矩阵 Q、键(Key)矩阵 K和值(Value)矩阵 V,它们的维度如下:

计算过程分为四步:
1.计算注意力分数(Attention Scores)
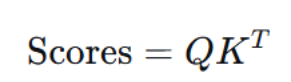
这是一个 n×m的矩阵。矩阵中的元素 Scoresij是第 i个查询 qi与第 j个键 kj的点积,即 qi⋅kj。这个原始分数衡量了查询与各个键之间的"相似度"或"匹配程度"。
2.缩放(Scaling)
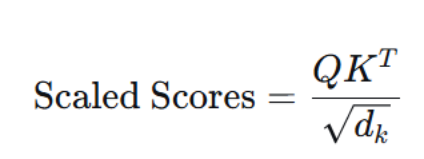
将第一步得到的原始分数矩阵,统一除以√d_k。dk是键向量的维度。这是整个机制被称为"缩放点积注意力"的原因。
3.计算注意力权重(Attention Weights)
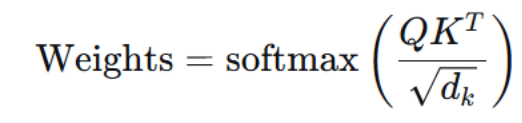
沿着键的维度(即矩阵的每一行)对缩放后的分数进行 softmax 归一化。归一化后,每一行的所有元素之和为 1,每个元素 αij可以解释为第 i个查询对第 j个值的"关注程度"。
4.加权聚合(Weighted Aggregation)
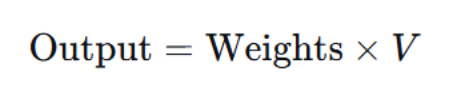
最终的输出矩阵是注意力权重矩阵与值矩阵 V的乘积,维度为 n×dv。对于每个查询,其输出是所有值向量的加权和,权重由注意力权重决定。这样,与查询更相关的值会得到更多保留。
为什么要除以√d_k
这个缩放操作是为了防止点积在 dk较大时变得过大,从而避免 softmax 函数进入梯度极小的饱和区,保证训练的稳定性。
1. 点积的方差会随维度增长
假设查询向量 q和键向量 k的各个分量是独立的随机变量,均值为 0,方差为 1。那么,它们的点积的均值为 0,方差为 dk。
当 dk很大时(Transformer中通常为64),点积的绝对值可能变得非常大。这意味着 softmax 的输入向量中某些分量会极端突出。
2. 大方差导致 softmax 梯度消失
softmax 函数在输入值很大时,其输出会非常接近一个独热向量(one-hot),即只在一个位置输出接近 1,其余位置输出接近 0。
softmax 的梯度公式中,当某个输出 yiy**i 接近 1 或 0 时,梯度 ∂yi/∂zj会非常接近于 0。这会导致反向传播时梯度变得极小,模型参数更新几乎停滞,训练难以进行。
3. 除以√d_k的效果
通过将点积除以√d_k,我们将缩放后的点积方差重新控制为 1。
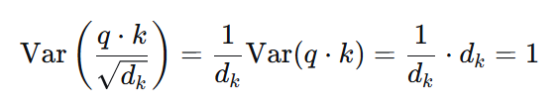
将输入方差稳定在 1,使 softmax 的输出分布相对平滑,不至于过于尖锐,从而让梯度能够有效回传。这样,模型在训练时就能稳定学习,尤其是在多头注意力中,这个缩放也防止了某几个头因极端分数而主导整体表示。
总结 :除以√dk本质上是一种方差归一化,它将点积的方差从随维度增长的趋势拉回到一个正常的尺度,使得 softmax 的梯度保持在有效范围,是保证深层 Transformer 模型能够成功训练的关键细节。
Transformer为什么需要位置编码?原始Transformer使用的正弦位置编码有什么特点?
这是一个非常关键的问题,它触及了 Transformer 架构与 RNN 类模型的根本区别。
Transformer 为什么需要位置编码
核心原因在于:Transformer 的自注意力机制本身是"位置无关"的。
让我们从两个方面来理解这一点:
1. 自注意力机制的置换不变性
在 Scaled Dot-Product Attention 的计算公式中,整个运算实质上是矩阵乘法与加权求和。
- 矩阵乘法没有"顺序"概念:查询 Q与键 K的转置做点积,计算的是所有查询和所有键两两之间的相似度。这个操作与序列中元素的排列顺序完全无关。
- 置换等价性:假如你打乱输入序列中词的顺序,模型输出的内容也会以同样的方式被打乱。对模型来说,句子"狗咬人"和"人咬狗",只要词元集合相同,它看到的原始特征就没有区别。
2. 与 RNN 的对比
传统的 RNN(循环神经网络)是"天然有序"的。它通过逐步处理序列,隐状态 ht本身就直接编码了位置和时间信息,因此不需要额外的位置信号。
Transformer 用并行计算取代了这种串行方式,获得了极高的训练效率,但却丧失了感知顺序的能力。为了让 Transformer 理解"词序",就必须设法把位置信息"注入"到输入中,这就是位置编码的作用。
原始正弦位置编码的特点
原始 Transformer 论文("Attention is All You Need")中提出的正弦位置编码(Sinusoidal Positional Encoding),是一种设计精巧的确定性编码方案,它有以下几个显著特点:
1. 确定性
这些编码不是通过训练学来的,而是由一个固定的数学公式直接生成。位置 pos和维度 i决定了编码的值:
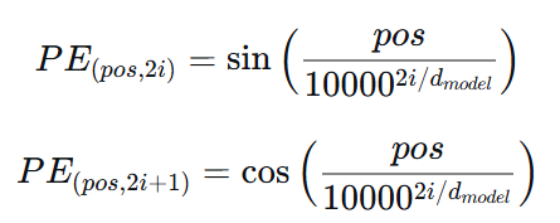
这为模型提供了一种无需额外参数的位置信息。
2. 波长随维度递增,模拟多尺度结构
这是它最精妙的设计思想:编码的每个维度,都对应不同频率的正弦波。
- 低维度(高频率) :变化快,用于捕捉局部、邻近词之间的相对位置关系。
- 高维度(低频率) :变化慢,用于捕捉全局、远距离的绝对位置关系。
3. 能够表达相对位置信息
正弦位置编码的一个被广泛认为很有价值的特性是,它允许模型轻松学习并关注相对位置。
对于任意固定的偏移量 k,位置 pos+k处的编码向量,总可以表示为位置 pos处编码向量的一个线性变换。这意味着,网络的注意力机制在计算"查-键"相似度时,有可能通过学习,直接捕捉到"这两个词距离为 k"这种关系。
4. 理论上支持外推
因为是确定性函数,在推理时,即使遇到比训练数据中所有序列都更长的序列,也可以直接按公式计算出新位置、更靠后位置的编码值。这一点是早期许多可学习位置编码不具备的能力。
Pre-Norm和Post-Norm分别把LayerNorm放在哪里?两者对训练稳定性有什么影响?
Pre-Norm 与 Post-Norm 是 Transformer 中两种不同的 Layer Normalization 放置策略,深刻影响着训练的稳定性和模型行为。
分别把 LayerNorm 放在哪里
以 Transformer 的一个子层(自注意力或前馈网络)为例,令输入为 x,子层函数为 Sublayer(x)。
Post-Norm(原始Transformer论文的做法)
归一化放在残差连接 之后。

即先加残差,再对整个结果做归一化。
Pre-Norm(现代大模型的主流做法)
归一化放在子层 之前,残差连接保持不变。
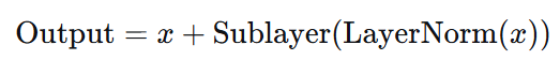
即先对输入做归一化,再送入子层,最后加残差。
两者对训练稳定性的影响
差异的核心在于:残差通路是否被归一化打断,以及梯度如何回传。
Post-Norm:训练不稳定,但效果潜力略高
- 不稳定性来源 :在 Post-Norm 中,残差相加后的整体被归一化。当模型很深时,未经约束的残差分支输出可能与主路径 xx 尺度不匹配,相加后容易产生数值量级波动。更关键的是,反向传播时,梯度必须穿过 LayerNorm 才能到达浅层。LayerNorm 本身会改变梯度的范数,多层堆叠下极易导致梯度爆炸或消失,这使得训练对学习率极其敏感。
- 典型问题 :原始 Transformer 论文发现,若不使用学习率预热(warmup),模型在训练初期极易发散。因为初始阶段参数随机,残差输出很大,直接导致整个训练崩溃。
- 优势:归一化放在最后,保证了每一层的输出在进入下一层前都处于稳定分布。这使得整个网络各层的输入分布被严格规范化,理论上最终的模型表示能力会稍好一些。
Pre-Norm:训练极其稳定,已成默认选择
- 稳定性来源 :在 Pre-Norm 下,残差通路是"纯净"的,即从输出到输入有一条直接的 xx 直连通道,梯度可以无损地传递到浅层。而 LayerNorm 仅作用于进入子层的分支,即便子层参数初始化不良,其输出也会被残差连接摊薄,不会立刻破坏主路径的数值流。
- 实际效果 :
- 无需学习率预热:训练从一开始就非常平稳,大幅降低了调参难度。
- 支持更深网络:这一特性使得训练数百甚至上千层的 Transformer 成为可能。
- 适应更大学习率:即便学习率设置较大,也不容易发散。
- 代价:因为每层的输入分布没有被强制标准化,网络浅层和深层的输入尺度可能存在差异。一些研究指出,这可能会让模型最终的极限效果比调参完美的 Post-Norm 略低一点点,但这个差距在工程实践中几乎可以被忽略,远不如训练稳定性带来的收益大。