很多人都觉得,大模型的核心是算法。但真正亲手训练过模型的人都清楚:大模型的本质,是依靠海量数据和海量算力,搭建出来的一套超大规模预测系统。
算法固然重要,但真正耗费巨额成本、消耗大量时间的,其实是数据处理和GPU算力。
今天我们就从宏观层面,完整走一遍大语言模型的预训练流程,这里以GPT类模型常用的自回归(Auto-Regressive)训练方式为例讲解。

1、准备训练数据
训练大模型,最先要搞定的不是GPU,而是数据,而且是量级极大的海量数据。像GPT、LLaMA、Qwen这类主流大模型,训练数据的来源基本集中在这些渠道:网页、书籍、论文、代码、问答社区、Wiki、GitHub。
最终汇总的训练数据,规模普遍达到数TB、数十TB,甚至是PB级别。正规的大模型训练,往往会用到数万亿Token的数据。
数据之所以这么关键,核心原因是模型所有的语言规律,都是从数据里学来的。如果原始数据质量差,模型学出来的效果就会跑偏、出错。
所以在正式开启训练之前,团队要做海量的数据工程工作:数据去重、清除乱码、剔除广告内容、过滤低质量文本、删除违规内容、清理重复网页。
毫不夸张地说,很多团队做模型训练,最耗时间的环节就是数据清洗。
再重申一遍:大模型本质上,就是靠海量数据和海量算力,训练出的一套超大规模预测系统。

2、文本处理:Tokenization&Embedding
大模型本身不认识我们日常的文字,所有文本都要经过预处理才能被计算。一句完整的话输入模型后,首先会被拆分切割成一个个Token。
举个例子:人工智能改变世界,会被模型拆解为:人工、智能、改变、世界。
每一个Token,都会对应一个专属的Token ID,大家可以把这个ID理解成这个Token在词表里的专属索引。模型接收不到"人工""智能"这类文字,只能识别一串数字ID。
比如:人工 → 2331、智能 → 5168。
不过单纯的数字ID无法直接参与运算,所以模型还会把每一个Token转化为向量形式。
比如:苹果 → 0.21, -0.53, 1.42, ...
这个转化过程就是Embedding(向量化),完成这一步后,Transformer或者各类改良架构才能开展后续的核心计算工作。
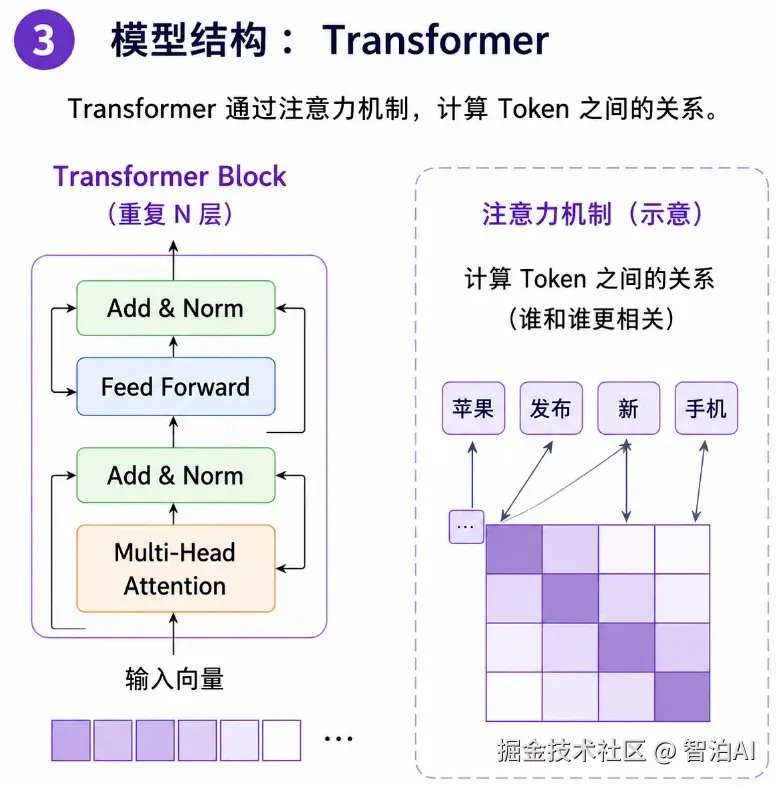
3、Transformer:核心计算架构
Transformer以及基于它改良的各类架构,是大模型真正的核心所在。它最核心的能力,就是精准计算不同Token之间的关联关系。
举两个简单的例子:
句子一:苹果发布了新手机。这句话里,"苹果"和"手机"的关联度最高;
句子二:苹果很好吃。这句话里,"苹果"和"好吃"的关联度最高。
实现这种精准关联判断的,就是Attention(注意力机制)。模型会自主动态判断:哪些词汇信息更关键、需要重点关注、如何融合各类文本信息。
之后文本数据会经过多层Transformer Block,层层提炼、拆解,逐步学习到更复杂、更精细的语言规律。
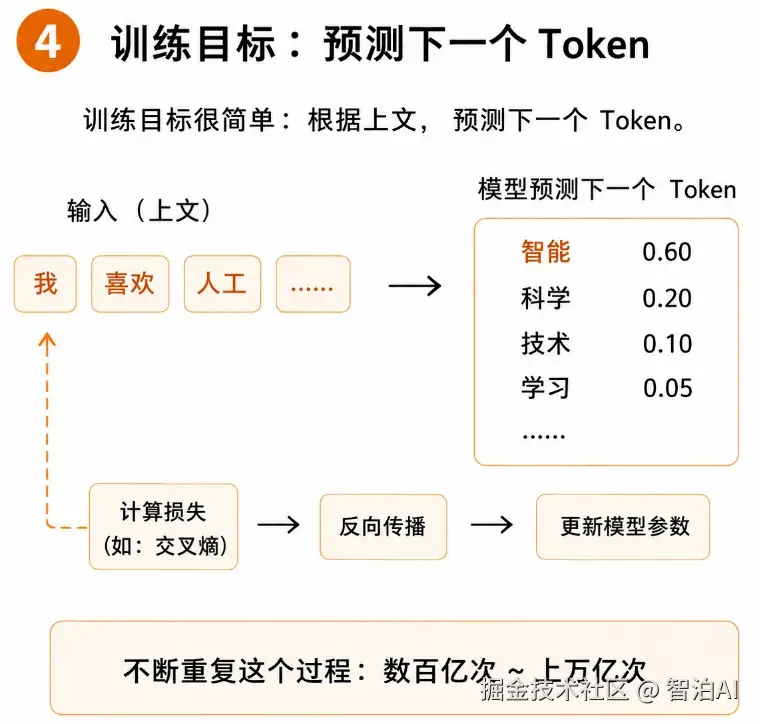
4、训练核心目标:预测下一个Token
GPT类模型的训练逻辑其实特别简单,核心目标就一个:预测下一个即将出现的Token。
举个例子:我喜欢人工****,模型需要精准预测出空缺的内容是"智能"。
预测过程中,模型会给出多个候选词汇的概率:智能:0.60、科学:0.20、技术:0.10。
如果模型预测出错,就会自动完成一系列修正操作:计算损失值、反向传播数据、更新模型参数。
这套训练流程会重复运行几百亿次、几千亿次,甚至上万亿次。大模型就是通过这样无数次的迭代学习,慢慢掌握完整的语言规律、语义逻辑。
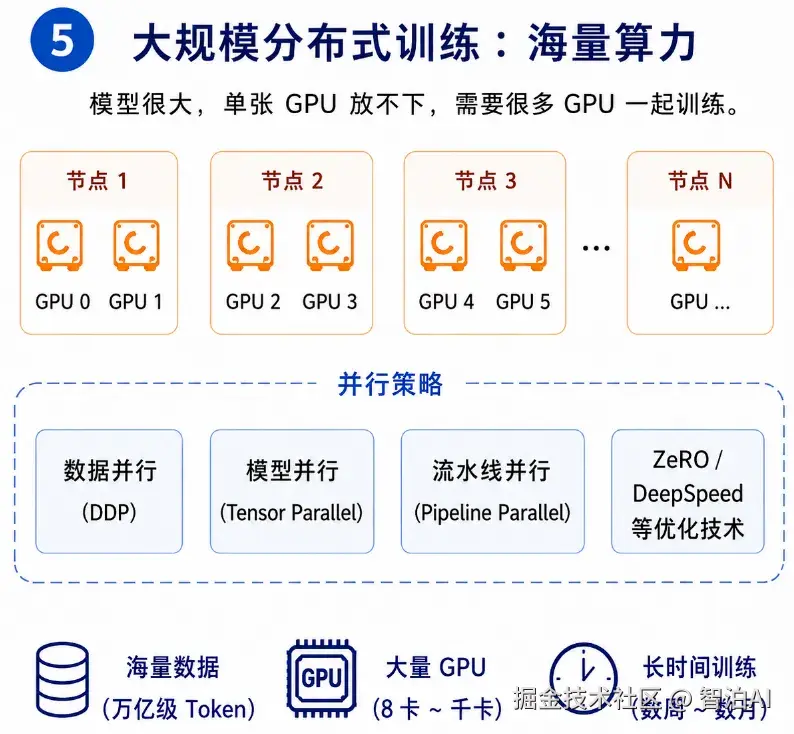
5、大规模分布式训练:海量GPU协同运算
大模型训练真正烧钱的地方,就是GPU算力。根本原因是模型的参数量过于庞大。
给大家普及下参数量级:7B代表70亿参数,70B代表700亿参数,GPT-4、GPT-5这类顶级模型,参数量更是远超这个级别。
每一次完整的模型训练,都要完成前向计算、Attention计算、反向传播、参数更新等一系列操作,模型参数越多,整体的计算量就越恐怖。
之所以需要大量GPU协同工作,是因为单张GPU的显存根本承载不了完整的大模型。就拿70B模型来说,采用bf16精度训练时,仅模型参数就需要数百GB的显存。
所以行业内训练大模型,都会用到各类并行技术:数据并行(DDP)、模型并行、Pipeline并行,同时搭配DeepSpeed、ZeRO、FlashAttention等优化方案。
所有技术手段的核心目的,都是让大量GPU可以协同完成训练任务。
常规的大模型训练,硬件规模基本都是8卡、64卡、256卡,甚至上千张GPU同时运行。
很多人好奇大模型训练为什么耗时这么久?核心是训练数据体量太大。
举个具体例子:训练10万亿tokens的数据,即便搭载128张H100、开启BF16和FlashAttention优化,也需要数周甚至数月才能完成。
从工程角度来看,大模型训练的成本,本质是数据规模、训练时长、GPU算力三者叠加的结果。
模型参数量越大、训练数据越多、上下文长度越长,整体的训练成本就越高。尤其是上下文长度增加后,Attention的计算量会大幅攀升,显存占用和训练耗时也会同步上涨。
因此现在很多行业研究,不再一味追求做大模型的参数量,而是聚焦新的方向:如何在保障更长上下文能力的同时,最大限度降低训练和推理的成本。
基于这个需求,各类优化架构和训练策略不断问世,比如:更高效的Attention机制、稀疏注意力、滑动窗口注意力、状态空间模型、MoE架构、FlashAttention、序列并行、上下文扩展训练等。
这些优化技术的核心目标,都是在模型性能、上下文长度、计算成本三者之间,找到最优的平衡状态。
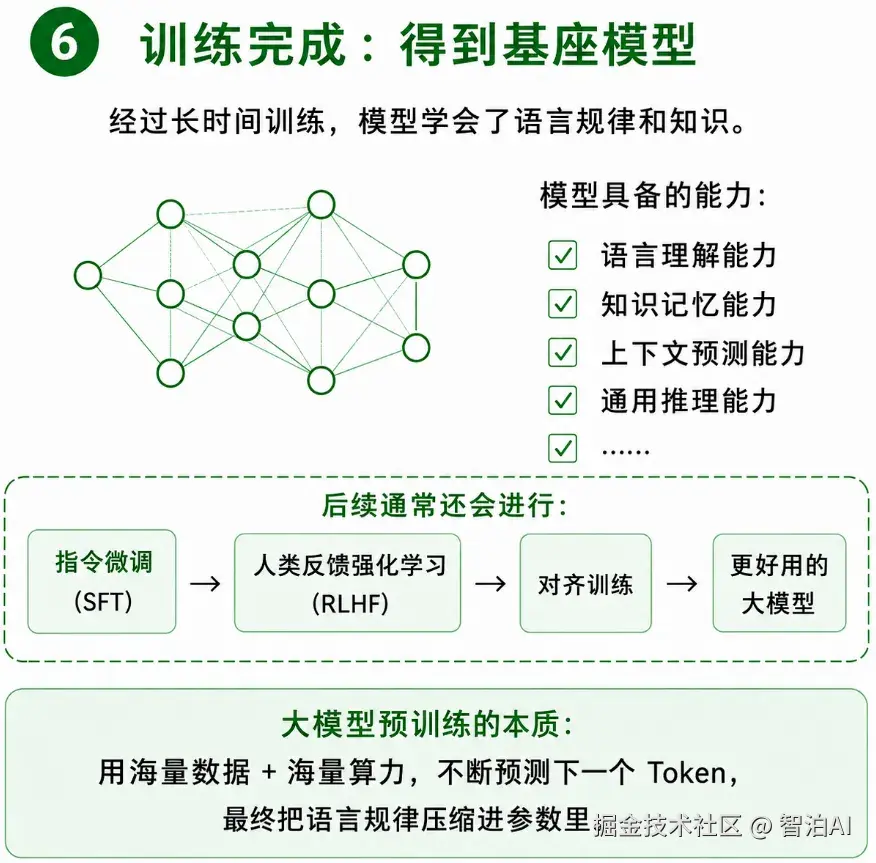
6、训练收尾:得到基座大模型
经过漫长的全量训练后,最终产出的是一个基础的基座模型。这个模型已经掌握了基础的语言规律、上下文续写能力、基础知识库内容和简单的推理能力。
但此时的基座模型,还不具备流畅对话的能力。所以训练结束后,还需要后续的优化流程:指令微调(SFT)、人类反馈强化学习(RLHF)、对齐训练。经过这些步骤优化后,才是我们日常使用的成熟大语言模型。