Agent之Memory:TencentDB Agent Memory的简介、安装和使用方法、案例应用之详细攻略
目录
[TencentDB Agent Memory的简介](#TencentDB Agent Memory的简介)
[TencentDB Agent Memory的安装和使用方法](#TencentDB Agent Memory的安装和使用方法)
[1)OpenClaw 的短期记忆压缩配置](#1)OpenClaw 的短期记忆压缩配置)
[2)Hermes 的 Docker 全新部署](#2)Hermes 的 Docker 全新部署)
[3)Hermes 的"挂到已有实例"方式](#3)Hermes 的“挂到已有实例”方式)
[TencentDB Agent Memory的案例应用](#TencentDB Agent Memory的案例应用)
[1)OpenClaw 中的"零配置启用"案例](#1)OpenClaw 中的“零配置启用”案例)
[2)OpenClaw 中的短期记忆压缩案例](#2)OpenClaw 中的短期记忆压缩案例)
[3)Hermes 全新部署案例](#3)Hermes 全新部署案例)
[4)Hermes 现有实例增强案例](#4)Hermes 现有实例增强案例)
TencentDB Agent Memory的 简介
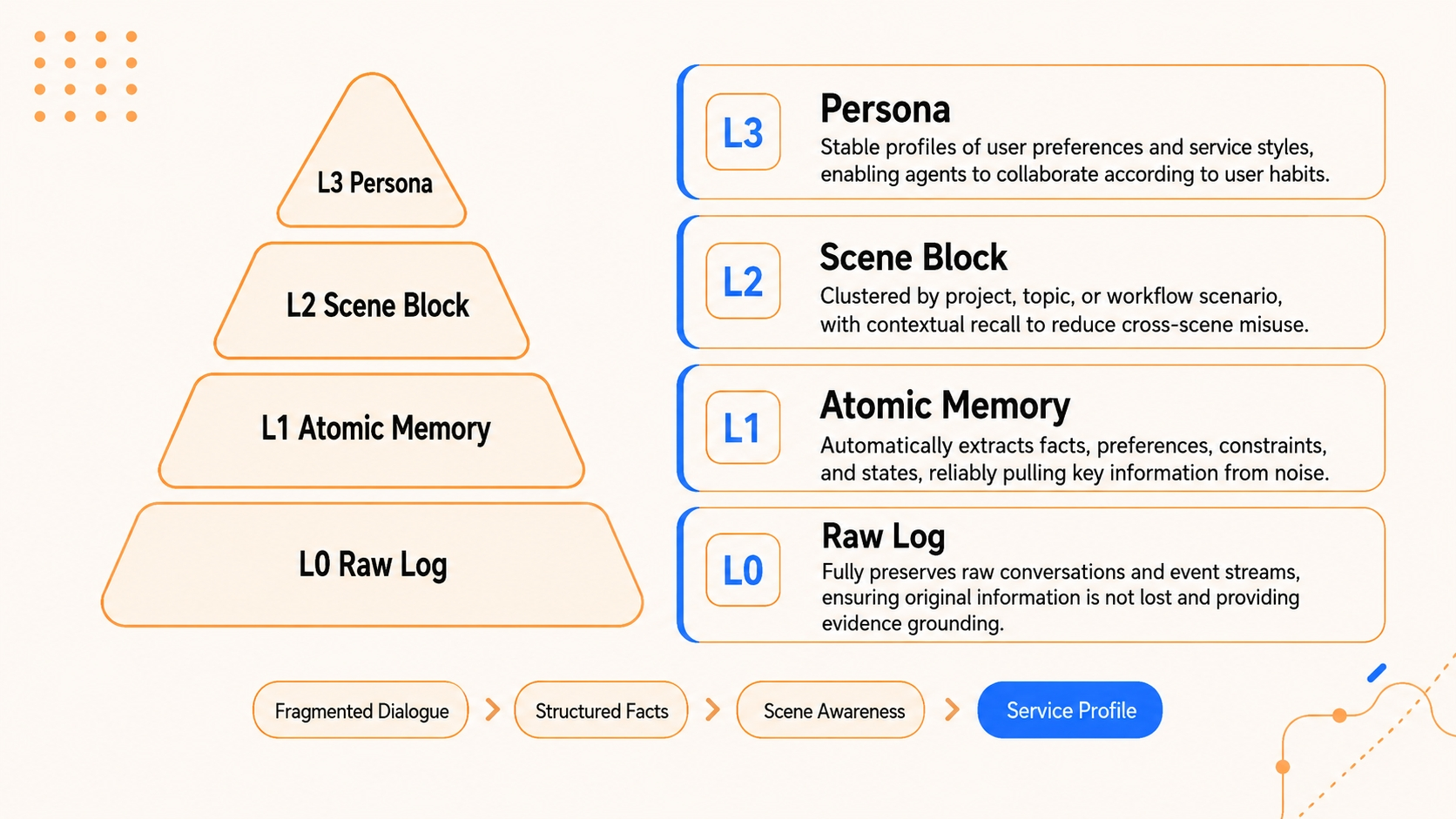
TencentDB Agent Memory 的定位,是给 AI Agent 提供一套"本地优先"的长期记忆能力。仓库首页直接把它概括为:通过一个"四层渐进式流水线",为 AI Agents 提供完全本地化的长期记忆,而且不依赖外部 API。
进一步说明,这个项目不想让 AI "存下所有东西",而是要让人不必反复解释固定 SOP、项目背景、工具习惯和输出格式。它把记忆设计成分层系统:短期层面用符号化记忆解决单次长任务中的信息过载,长期层面用分层记忆解决跨会话的经验沉淀。
从项目目标看,它强调"让 Agent 记住该记的,让人把注意力留给判断、创造和真正有价值的工作"。这也对应了它在 README 中反复强调的核心方向:不是平铺式堆历史,而是用更有结构的方式保存经验、场景和画像。
Github地址 :https://github.com/TencentCloud/TencentDB-Agent-Memory
1、特点
|------------------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| 符号化短期记忆,显著减少上下文开销 | 项目把短期记忆做成"上下文卸载"机制:厚重的工具日志会先保留原始层,再逐步提炼成步骤摘要,最终压缩为轻量级的 Mermaid 任务画布。官方在效果亮点中明确写到,这种方式能大幅降低 Token 消耗,同时提升任务成功率。 |
| 分层式长期记忆,避免扁平向量堆砌 | 长期记忆并不是简单把对话压成一段 summary,而是构建从 L0 Conversation、L1 Atom、L2 Scenario 到 L3 Persona 的语义金字塔。高层用于把握用户偏好和方向,底层用于回溯事实细节。 |
| 记忆可追溯、可恢复,不是黑盒 | 仓库强调它保留从高层摘要回到底层证据的链路,且所有摘要都可逆溯源。具体来说,可以沿着"Persona / 画布 → Scenario / JSONL → 原文 refs"的路径回查;短期任务也能通过 node_id 找到对应原始结果。 |
| 白盒可调试,便于排错和审计 | 项目把关键中间产物都保存在可读文件中:Scenario 是 Markdown,Persona 存在 persona.md,短期任务画布是 Mermaid,而且原文、摘要、节点之间通过 result_ref 和 node_id 关联。也就是说,调试时不是翻黑盒数据库,而是直接顺着层级定位。 |
| 工程化接入完整,不只是演示项目 | README 把它明确描述成可接入的插件,而不是 demo:它支持 OpenClaw 插件、Hermes Gateway、本地 SQLite + sqlite-vec 后端、BM25 + 向量 + RRF 的混合检索,以及 tdai_memory_search / tdai_conversation_search 这类工具接口。 |
| 兼容两类主流宿主:OpenClaw 与 Hermes | 仓库专门为 OpenClaw 和 Hermes 两条路径分别给出了接入方式。OpenClaw 可以零配置启用;Hermes 则既支持全新 Docker 部署,也支持把记忆能力挂到已有 Hermes 上。 |
| 对短期压缩和长期画像都有量化收益 | 官方效果页给出了明确指标:作为 OpenClaw 插件接入后,最高节省 61.38% Token,通过率相对提升 51.52%;PersonaMem 准确率从 48% 提升到 76%。这些数据说明它不仅强调概念,还做了实际评测。 |
TencentDB Agent Memory的安装和使用方法
1、安装
最直接的安装方式是运行:
openclaw plugins install @tencentdb-agent-memory/memory-tencentdb然后重启网关:
openclaw gateway 仓库还建议升级时优先使用 OpenClaw 原生更新命令:
openclaw plugins update @tencentdb-agent-memory/memory-tencentdb。安装后,默认使用本地 SQLite + sqlite-vec 后端。只要在 ~/.openclaw/openclaw.json 里把 "memory-tencentdb": { "enabled": true } 打开,系统就会自动完成对话录制、记忆提取、场景归纳、用户画像生成和下一轮对话前召回。
2、使用方法
1)OpenClaw 的短期记忆压缩配置
如果你想启用短期记忆压缩,仓库给出的配置是在 memory-tencentdb.config.offload.enabled 设为 true,并注明该能力要求版本不低于 0.3.4。
此外,如果你要把 OpenClaw 的上下文卸载请求路由到这个插件,还需要在插件配置中声明 slots.contextEngine = "memory-tencentdb",再执行 bash scripts/openclaw-after-tool-call-messages.patch.sh 注入消息钩子。官方说明这个 patch 每次 OpenClaw 安装只需执行一次,升级 OpenClaw 后建议重新执行。
2)Hermes 的 Docker 全新部署
仓库为 Hermes 提供了全新 Docker 部署路径,适合"从零启动一个带记忆能力的 Hermes"。Docker 镜像把 hermes-agent 和 memory_tencentdb provider 聚合在一起,网关监听 :8420。
官方示例中需要先进入 docker/opensource,然后执行:
docker build -f Dockerfile.再运行容器,并通过环境变量传入 MODEL_API_KEY、MODEL_BASE_URL、MODEL_NAME、MODEL_PROVIDER,最后用 curl http://localhost:8420/health 验证网关,再用 docker exec -it hermes-memory hermes 进入对话。仓库还说明,如果使用默认的腾讯云 DeepSeek-V3.2 组合,部分模型参数可以省略,只保留 API Key。
3)Hermes 的"挂到已有实例"方式
如果机器上已经装好了 hermes-agent,仓库也给出了无 Docker 的接入方式。流程包括:先把插件包下载到统一目录、安装 Gateway 依赖、再把插件符号链接到 ~/.hermes/hermes-agent/plugins/memory/memory_tencentdb,最后在 ~/.hermes/config.yaml 中声明 provider。
仓库特别提醒,这里的目录名必须是 memory_tencentdb(下划线),因为 Hermes 会把它当作 provider key;而 memory-tencentdb 只是配置层的别名,不能作为目录名。
4)版本与依赖提示
仓库还说明,Node.js 22.16+ 可原生支持 TypeScript type stripping,OpenClaw 会直接在运行时加载 .ts 源文件,因此从源码开发不需要额外 build 步骤。
TencentDB Agent Memory的案例应用
1)OpenClaw 中的"零配置启用"案例
README 最直接的落地案例,就是在 OpenClaw 中安装插件后,只要把 enabled 打开,系统就会自动进行对话录制、记忆提取、场景归纳、用户画像生成和下一轮召回。这个案例展示了它"开箱即用"的插件化能力。
2)OpenClaw 中的短期记忆压缩案例
当启用 offload 之后,工具调用日志不再全部塞进上下文,而是被层层压缩成 Mermaid 画布和 JSONL 摘要;需要回查时再顺着节点下钻到底层原文。这个案例对应的是长任务、长会话场景,重点是降低 Token 压力并保留可追溯证据。
3)Hermes 全新部署案例
仓库提供了一个"docker 一条命令部署带记忆 Hermes"的完整示例:配置模型环境变量、构建镜像、启动容器、健康检查、进入 Hermes 会话。这个案例说明该项目并不局限于某个 Agent 框架,而是可以作为独立记忆层接到 Hermes 上。
4)Hermes 现有实例增强案例
如果已经在使用 Hermes,仓库还提供了"只加记忆能力"的挂载方案,通过把插件目录链接到 Hermes 的 memory provider 路径来完成接入。这个案例适合已有 Agent 系统逐步增强记忆,而不是推倒重来。
5)官方评测案例:短期与长期记忆效果
仓库给出了多组 benchmark 结果,作为项目能力的直接案例:WideSearch 的成功率从 33% 提升到 50%,SWE-bench 从 58.4% 提升到 64.2%,AA-LCR 从 44.0% 提升到 47.5%,PersonaMem 从 48% 提升到 76%。这些结果用来说明它在短期任务和长期个性化记忆上都有效。
6)面向长会话和复杂任务的真实工作流案例
README 还说明,超长 Session 的评测方式不是单题清空上下文,而是把多个任务连续拼接在同一个 Session 中执行,例如 SWE-bench 一个 Session 连续执行 50 个任务,用来模拟真实长程 Agent 的上下文累积压力。这个案例非常贴合它的设计目标:面向复杂、持续、累积型工作流。