【数学建模】SHAP 算法:从 Shapley Value 到机器学习模型可解释性
摘要
机器学习模型预测结果往往难以解释。尤其是在金融风控、医疗诊断、推荐系统、广告排序等场景中,我们不仅关心模型"预测了什么",更关心模型"为什么这样预测"。
SHAP ,全称为 SHapley Additive exPlanations,是一种基于博弈论 Shapley Value 的模型解释方法。它可以衡量每个特征对单个预测结果的贡献,也可以从整体上分析模型最关注哪些特征。
本文将系统介绍 SHAP 算法的核心思想、数学原理、常见解释图、Python 使用方法以及实际应用中的注意事项。
文章目录
- [【数学建模】SHAP 算法:从 Shapley Value 到机器学习模型可解释性](#【数学建模】SHAP 算法:从 Shapley Value 到机器学习模型可解释性)
-
- 摘要
- [1. 为什么需要模型可解释性?](#1. 为什么需要模型可解释性?)
- [2. SHAP 是什么?](#2. SHAP 是什么?)
- [3. SHAP 的理论基础:Shapley Value](#3. SHAP 的理论基础:Shapley Value)
- [4. Shapley Value 的数学定义](#4. Shapley Value 的数学定义)
- [5. SHAP 的核心思想](#5. SHAP 的核心思想)
- [6. SHAP 的三个重要性质](#6. SHAP 的三个重要性质)
-
- [6.1 局部准确性](#6.1 局部准确性)
- [6.2 缺失性](#6.2 缺失性)
- [6.3 一致性](#6.3 一致性)
- [7. SHAP 的常见解释器](#7. SHAP 的常见解释器)
-
- [7.1 TreeExplainer](#7.1 TreeExplainer)
- [7.2 KernelExplainer](#7.2 KernelExplainer)
- [7.3 DeepExplainer](#7.3 DeepExplainer)
- [7.4 LinearExplainer](#7.4 LinearExplainer)
- [8. SHAP 可视化图【重要】](#8. SHAP 可视化图【重要】)
-
- [8.1 Summary Plot:全局特征重要性图](#8.1 Summary Plot:全局特征重要性图)
- [8.2 Bar Plot:特征重要性柱状图](#8.2 Bar Plot:特征重要性柱状图)
- [8.3 Waterfall Plot:单个样本解释图](#8.3 Waterfall Plot:单个样本解释图)
- [8.4 Force Plot:单样本贡献力图](#8.4 Force Plot:单样本贡献力图)
- [8.5 Dependence Plot:特征依赖图](#8.5 Dependence Plot:特征依赖图)
- [8.6 Heatmap Plot:热力图](#8.6 Heatmap Plot:热力图)
- [9. SHAP的安装、使用SHAP解释机器学习模型的方法](#9. SHAP的安装、使用SHAP解释机器学习模型的方法)
-
- [9.1 SHAP 的安装方式](#9.1 SHAP 的安装方式)
- [9.2 例1:SHAP 在二分类任务中的应用](#9.2 例1:SHAP 在二分类任务中的应用)
- [9.3 例2:SHAP 在回归任务中的应用](#9.3 例2:SHAP 在回归任务中的应用)
- [9.4 SHAP 实战建议](#9.4 SHAP 实战建议)
-
- (1)不要只看全局重要性
- [(2)不要把 SHAP 当作因果分析](#(2)不要把 SHAP 当作因果分析)
- (3)注意数据泄露
- (4)注意敏感特征
- [10. SHAP 与传统特征重要性的区别](#10. SHAP 与传统特征重要性的区别)
- [11. SHAP 的优缺点](#11. SHAP 的优缺点)
-
- [11.1 SHAP 的优点:](#11.1 SHAP 的优点:)
- [11.2 SHAP 的缺点](#11.2 SHAP 的缺点)
- [12. SHAP 常见应用场景](#12. SHAP 常见应用场景)
-
- [12.1 金融风控](#12.1 金融风控)
- [12.2 医疗诊断](#12.2 医疗诊断)
- [12.3 推荐系统](#12.3 推荐系统)
- [12.4 广告点击率预测](#12.4 广告点击率预测)
- [12.5 工业故障预测](#12.5 工业故障预测)
- [13. 实际项目中如何使用 SHAP?](#13. 实际项目中如何使用 SHAP?)
-
- [13.1 第一步:训练模型](#13.1 第一步:训练模型)
- [13.2 第二步:计算 SHAP 值](#13.2 第二步:计算 SHAP 值)
- [13.3 第三步:做全局解释](#13.3 第三步:做全局解释)
- [13.4 第四步:做局部解释](#13.4 第四步:做局部解释)
- [13.5 第五步:结合业务验证](#13.5 第五步:结合业务验证)
- [13.6 一个完整的 SHAP 分析模板](#13.6 一个完整的 SHAP 分析模板)
- [14. SHAP 使用中的常见问题](#14. SHAP 使用中的常见问题)
-
- [问题 1:SHAP 值越大,特征越重要吗?](#问题 1:SHAP 值越大,特征越重要吗?)
- [问题 2:SHAP 值为正一定代表好事吗?](#问题 2:SHAP 值为正一定代表好事吗?)
- [问题 3:SHAP 能解释因果关系吗?](#问题 3:SHAP 能解释因果关系吗?)
- [问题 4:为什么 SHAP 图中有些特征影响方向不明显?](#问题 4:为什么 SHAP 图中有些特征影响方向不明显?)
- [问题 5:SHAP 计算很慢怎么办?](#问题 5:SHAP 计算很慢怎么办?)
- 总结
1. 为什么需要模型可解释性?
在传统机器学习中,线性回归、逻辑回归、决策树等模型相对容易解释。例如在线性回归中,某个特征的系数越大,通常说明该特征对预测结果影响越强。
但随着模型复杂度提升,例如:
- Random Forest
- XGBoost
- LightGBM
- CatBoost
- 神经网络
- Transformer 模型
模型预测性能提升的同时,可解释性往往下降。很多时候这类模型甚至被称为 黑盒模型。它们可以给出很准确的预测结果,但很难直接回答:
- 哪些特征影响了模型预测?
- 某个样本为什么被判定为高风险?
- 某个特征是正向影响还是负向影响?
- 模型是否学到了不合理的偏见?
- 不同特征之间是否存在复杂交互?
SHAP 的出现,就是为了解决这些问题。
2. SHAP 是什么?
SHAP 是一种模型解释方法,它的核心目标是将模型的某一次预测结果,拆解为每个特征的贡献之和。
假设模型对某个样本的预测结果为:
text
f(x)SHAP 会将其拆解为:
text
f(x) = base_value + shap_value_1 + shap_value_2 + ... + shap_value_n其中:
base_value:模型在整个数据集上的平均预测值,也可以理解为基准值;shap_value_i:第 i 个特征对当前样本预测结果的贡献;f(x):模型对当前样本的最终预测结果。
如果某个特征的 SHAP 值大于 0,说明它将预测结果往更高方向推动。
如果某个特征的 SHAP 值小于 0,说明它将预测结果往更低方向推动。
3. SHAP 的理论基础:Shapley Value
SHAP 的理论基础来自合作博弈论中的 Shapley Value。
一个简单例子:假设有三个人 A、B、C 合作完成一个项目,项目最终收益为 100 万元。
问题是:这 100 万元应该如何公平分配?
如果直接平均分,每人 33.3 万,看似公平,但可能并不合理。因为三个人的贡献可能不同:
- A 提供了核心技术;
- B 负责市场资源;
- C 负责项目管理。
Shapley Value 解决的问题就是:
如何根据每个参与者在不同合作组合中的边际贡献,公平地分配总收益?
迁移到机器学习中:
- "参与者"就是特征;
- "收益"就是模型预测结果;
- "边际贡献"就是某个特征加入模型后,对预测结果造成的变化。
4. Shapley Value 的数学定义
设模型有 N 个特征,特征集合为:
text
F = {1, 2, 3, ..., N}对于某个特征 i,它的 Shapley Value 定义为:
text
φ_i = Σ [ |S|! (N - |S| - 1)! / N! ] × [ f(S ∪ {i}) - f(S) ]其中:
φ_i:特征 i 的 Shapley Value;S:不包含特征 i 的特征子集;f(S):只使用特征集合 S 时模型的预测结果;f(S ∪ {i}) - f(S):特征 i 加入后的边际贡献;|S|! (N - |S| - 1)! / N!:不同特征排列下的权重。
简单来说,Shapley Value 会考虑特征 i 在所有可能特征组合中的平均边际贡献。
这也是 SHAP 解释结果相对公平、稳定的重要原因。
5. SHAP 的核心思想
SHAP 可以理解为:对于一次模型预测,计算每个特征在所有可能特征组合中的平均贡献。
例如有三个特征:
text
年龄、收入、负债率模型预测某个用户违约风险为 0.82,而模型平均预测风险为 0.50。
那么 SHAP 可能解释为:
text
base_value = 0.50
年龄贡献 +0.05
收入贡献 -0.08
负债率贡献 +0.35
最终预测值 = 0.50 + 0.05 - 0.08 + 0.35 = 0.82这说明:
- 负债率显著提高了违约风险;
- 收入降低了违约风险;
- 年龄略微提高了违约风险。
这种解释方式非常直观。
6. SHAP 的三个重要性质
SHAP 之所以被广泛使用,是因为它具备几个重要理论性质。
6.1 局部准确性
局部准确性指的是:所有特征的 SHAP 值加起来,必须等于模型当前样本的预测值与基准值之间的差。
公式为:
text
f(x) = E[f(X)] + Σ φ_i其中:
E[f(X)]是模型的平均预测值;φ_i是第 i 个特征的 SHAP 值。
6.2 缺失性
如果某个特征对模型预测没有贡献,那么它的 SHAP 值应该为 0。
也就是说,无用特征不会被强行赋予贡献。
6.3 一致性
如果一个模型中某个特征的边际贡献变大,那么该特征的 SHAP 值也不应该变小。
这保证了 SHAP 在解释不同模型时具有较好的稳定性和公平性。
7. SHAP 的常见解释器
SHAP 针对不同类型的模型提供了不同解释器。
7.1 TreeExplainer
适用于树模型,例如:
- XGBoost
- LightGBM
- CatBoost
- Random Forest
- Decision Tree
TreeExplainer 是 SHAP 中非常常用的解释器,因为它针对树模型做了优化,计算速度较快。
7.2 KernelExplainer
KernelExplainer 是一种模型无关解释器。
也就是说,它不关心模型内部结构,只要模型可以输入数据并输出预测结果,就可以进行解释。
适用于:
- 任意黑盒模型;
- 自定义模型;
- 不方便访问内部结构的模型。
缺点是计算速度通常比较慢。
7.3 DeepExplainer
DeepExplainer 主要用于深度学习模型,例如 TensorFlow、Keras、PyTorch 模型。
它结合了 DeepLIFT 和 Shapley Value 的思想,用于解释神经网络。
7.4 LinearExplainer
LinearExplainer 适用于线性模型,例如:
- Linear Regression
- Logistic Regression
- Lasso
- Ridge
它的计算效率较高,也比较容易理解。
8. SHAP 可视化图【重要】
SHAP 最强大的地方之一就是可视化能力。其 GitHub 仓库:https://github.com/shap/shap。下面介绍几种常用图形。
注:图片来自于:https://github.com/shap/shap,因此下文中很多关于图片含义的解读也可以去参考仓库中的相关信息。更多可视化方式也可以参考这个 SHAP 的官方的仓库中的信息。
8.1 Summary Plot:全局特征重要性图
python
shap.summary_plot(shap_values, X_test)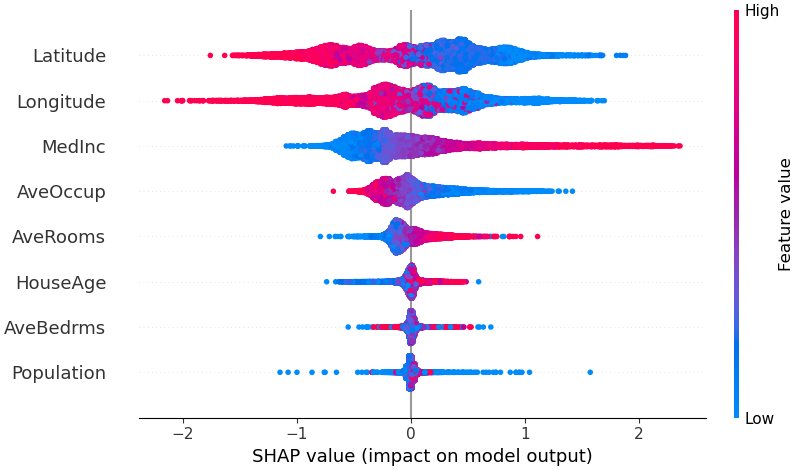
Summary Plot 是最常用的 SHAP 图之一。
它可以同时展示:
- 哪些特征最重要;
- 特征值大小如何影响预测结果;
- 特征影响方向是正向还是负向;
- 特征影响是否存在非线性。
在图中:
- 每一行代表一个特征;
- 每一个点代表一个样本;
- 横轴表示 SHAP 值,SHAP 值 > 0:这个特征把预测结果往高推,SHAP 值 < 0:这个特征把预测结果往低拉(你可以类比为线性回归分析中每个变量的系数的±);
- 点的颜色表示这个特征的原始特征值大小,红色代表大,蓝色代表小(你可以类别为你用来做回归的那些原始数据的大和小);
- 越靠上的特征整体影响越大。
下面举例几种典型情况:
1. 红色点集中在右侧,蓝色点集中在左侧
通常说明这个特征值越高,模型预测越高;特征值越低,模型预测越低。也就是一种比较清晰的 正向关系 。
例如图里的 MedInc:高收入区域是红色点,主要在右侧;低收入区域是蓝色点,主要在左侧。说明模型认为收入越高,房价预测越高;收入越低,房价预测越低。
2. 红色点集中在左侧,蓝色点集中在右侧
通常说明这个特征值越高,模型预测越低;特征值越低,模型预测越高。也就是一种比较清晰的 负向关系 。
比如图里的 Latitude 大致有这种趋势:高纬度的红色点更多在左边,低纬度的蓝色点更多在右边。说明模型认为纬度较高时,会降低预测房价;纬度较低时,会提高预测房价。
(P.S. 不过对于经纬度这种变量,不要简单理解成"纬度导致房价变化"。它其实是在代表地理位置、城市、海岸距离等隐藏因素。)
此外,如果红蓝分布没有明显规律,可能说明几件事:
- 第一,这个特征和预测结果关系不强。如果红蓝点都混在 0 附近,说明这个特征对模型预测影响较弱。
- 第二,这个特征的影响不是单调的。也就是说,不是"越高越好"或"越高越差",而是中间值、高值、低值在不同情况下效果不同。
- 第三,这个特征和其他特征有交互作用。比如 AveRooms 对房价的影响可能取决于收入、位置、人口密度。如果单独看 AveRooms,红蓝可能混在一起;但在某些地段,房间多会提高预测,在另一些地段,房间多未必提高预测。
- 第四,这个特征可能和其他特征高度相关。比如 AveRooms 和 AveBedrms 可能相关。模型把一部分解释分配给了其中一个变量,另一个变量的 SHAP 分布就可能变得不清晰。
- 第五,模型可能没有学到这个特征的稳定规律。如果数据噪声大、样本少、变量本身质量差,也会导致红蓝混杂。
- ......
8.2 Bar Plot:特征重要性柱状图
python
shap.plots.bar(shap_values)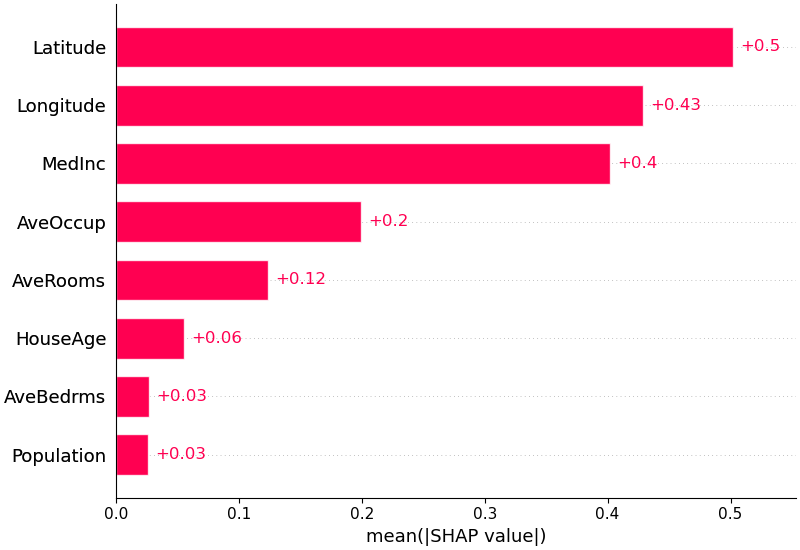
Bar Plot 展示的是平均绝对 SHAP 值。平均绝对 SHAP 值越大,说明该特征对模型预测影响越大,对模型最重要。
需要注意的是,Bar Plot 只能说明特征重要程度,不能说明影响的方向(对 SHAP 值取了绝对值)。例如,某个特征很重要,但它可能对部分样本是正向影响,对另一部分样本是负向影响。
8.3 Waterfall Plot:单个样本解释图
python
shap.plots.waterfall(shap_values[0])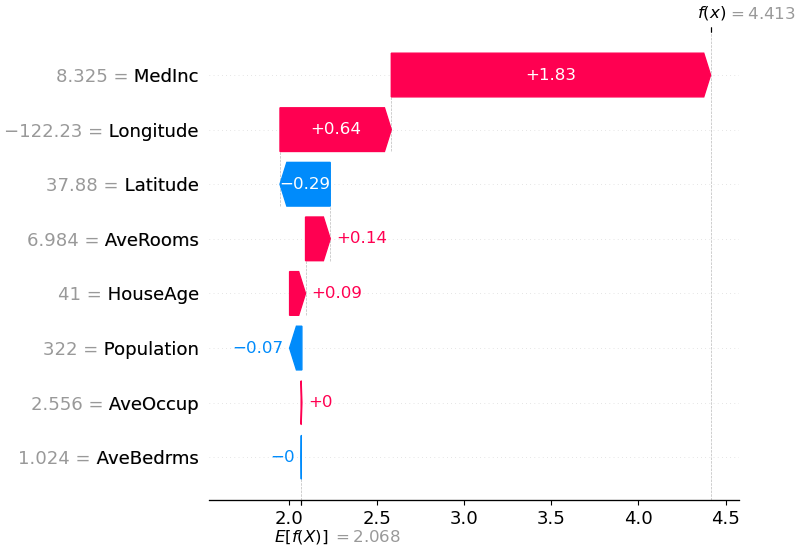
Waterfall Plot 用于解释单个样本的预测过程。它会展示模型如何从基准值一步步加上各个特征贡献,最终得到预测结果。
例如:
text
base_value = 0.45
特征 A +0.20
特征 B -0.10
特征 C +0.15
最终预测值 0.70这类图非常适合用于业务解释,例如:
- 为什么这个用户被判为高风险?
- 为什么这个客户推荐分数很高?
- 为什么这个病人被模型判断为阳性?
8.4 Force Plot:单样本贡献力图
python
shap.initjs()
shap.force_plot(
shap_values[0].base_values,
shap_values[0].values,
X_test.iloc[0]
)
Force Plot 通过类似"拉力"的方式展示各特征对预测结果的推动作用。
通常:
- 红色表示推动预测值升高;
- 蓝色表示推动预测值降低;
- 特征贡献越大,显示区域越宽。
Force Plot 很适合用于演示单个样本的预测逻辑。
8.5 Dependence Plot:特征依赖图
python
shap.plots.scatter(shap_values[:, "mean radius"])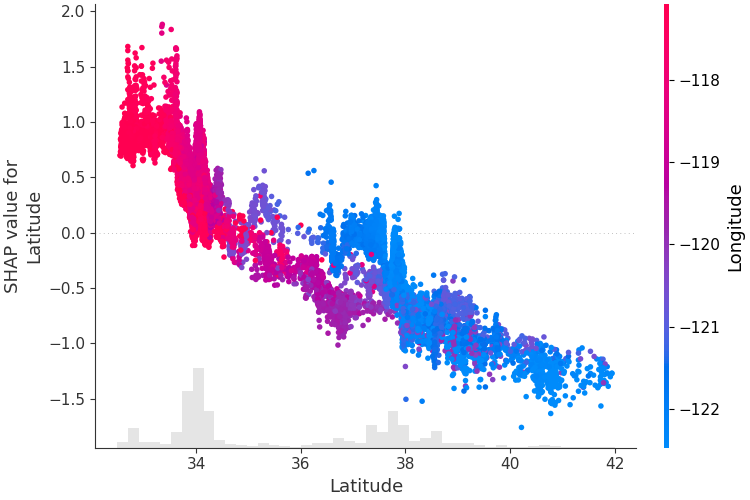
Dependence Plot 用于观察某个特征的取值与 SHAP 值之间的关系。它可以帮助我们分析:
- 特征与预测结果是否线性相关;
- 是否存在阈值效应;
- 是否存在非线性关系;
- 是否存在特征交互。
例如,在风控场景中,可能会发现:
- 当负债率低于 30% 时,对风险影响较小;
- 当负债率高于 60% 时,违约风险明显上升。
这种信息对业务规则制定非常有价值。
8.6 Heatmap Plot:热力图
python
shap.plots.heatmap(shap_values)Heatmap Plot 可以展示多个样本在多个特征上的 SHAP 值分布。
适合用于观察:
- 样本之间是否存在分组;
- 某些样本是否有相似解释模式;
- 某些特征是否在特定样本群体中影响更强。
9. SHAP的安装、使用SHAP解释机器学习模型的方法
9.1 SHAP 的安装方式
SHAP 的 GitHub 仓库:https://github.com/shap/shap
可以直接使用 pip 安装:
bash
pip install shap如果使用树模型,还可以安装对应依赖:
bash
pip install xgboost lightgbm catboost scikit-learn pandas matplotlib9.2 例1:SHAP 在二分类任务中的应用
下面以一个二分类任务为例,演示如何使用 SHAP 解释模型。
1. 导入依赖
python
import shap
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report2. 加载数据集
python
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
print(X.head())
print(y[:5])3. 划分训练集和测试集
python
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
stratify=y
)4. 训练模型
python
model = RandomForestClassifier(
n_estimators=200,
max_depth=5,
random_state=42
)
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))5. 创建 SHAP 解释器
python
explainer = shap.Explainer(model, X_train)
shap_values = explainer(X_test)这里的 shap_values 中保存了每个样本、每个特征对应的 SHAP 值。
注:SHAP 在分类任务中的注意事项:
在分类模型中,SHAP 的解释结果可能对应不同的输出空间,例如概率空间、log-odds 空间、margin 空间等。
对于二分类模型,如果模型输出的是概率,那么 SHAP 值加和后对应概率预测;如果模型输出的是 log-odds,那么 SHAP 值加和后对应 log-odds,而不是概率。
这一点非常重要。否则可能会出现这样的困惑:
base_value + shap values 之和为什么不是 predict_proba 的结果?
解决方法是查看解释器使用的模型输出类型,必要时显式指定参数。
例如在某些场景下可以使用:
python
explainer = shap.Explainer(model.predict_proba, X_train)
shap_values = explainer(X_test)这样解释的是 predict_proba 的输出结果。
9.3 例2:SHAP 在回归任务中的应用
SHAP 同样可以用于回归任务。
示例代码如下:
python
import shap
import pandas as pd
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error
data = fetch_california_housing()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42
)
model = RandomForestRegressor(
n_estimators=200,
max_depth=8,
random_state=42
)
model.fit(X_train, y_train)
pred = model.predict(X_test)
print("MSE:", mean_squared_error(y_test, pred))
explainer = shap.Explainer(model, X_train)
shap_values = explainer(X_test)
shap.plots.bar(shap_values)
shap.plots.waterfall(shap_values[0])在回归任务中,SHAP 值的单位通常与预测目标一致。例如,如果预测房价,那么 SHAP 值可以理解为某个特征让房价预测值增加或减少了多少。
9.4 SHAP 实战建议
在真实业务中使用 SHAP 时,建议注意以下几点。
(1)不要只看全局重要性
全局重要性只能告诉我们模型整体关注什么,但不能解释某一个具体样本。
如果业务人员问:
text
为什么这个用户被拒绝?这时应该使用 Waterfall Plot 或 Force Plot 做局部解释。
(2)不要把 SHAP 当作因果分析
SHAP 只能解释模型,不等于解释真实世界。
如果要做因果推断,需要使用因果推断方法,例如:
- 倾向得分匹配;
- 双重差分;
- 工具变量;
- 因果图;
- DoWhy;
- EconML。
(3)注意数据泄露
如果某个特征 SHAP 值异常高,需要检查它是否存在数据泄露。
例如,在贷款违约预测中,如果存在类似:
text
逾期天数
催收状态
是否进入坏账流程这些特征可能已经包含了目标变量之后的信息。
模型虽然表现很好,但不能用于真实预测。
(4)注意敏感特征
在金融、招聘、保险等场景中,需要谨慎处理敏感特征,例如:
- 性别;
- 年龄;
- 地域;
- 民族;
- 婚姻状况。
即使模型没有直接使用敏感特征,也可能通过其他相关特征间接学习到敏感信息。
10. SHAP 与传统特征重要性的区别
很多机器学习模型本身也提供特征重要性,例如 XGBoost、LightGBM、Random Forest 中的 feature importance。
但传统特征重要性存在一些问题:
| 方法 | 特点 | 局限 |
|---|---|---|
| 模型自带 feature importance | 计算快,使用方便 | 只能看全局重要性,不能解释单个样本 |
| Permutation Importance | 通过打乱特征观察性能下降 | 计算成本较高,不能直接解释单个预测 |
| LIME | 局部线性近似解释模型 | 结果可能不稳定 |
| SHAP | 基于 Shapley Value,兼具局部和全局解释 | 计算成本相对较高 |
SHAP 最大的优势是:
- 可以解释单个样本;
- 可以分析整体特征重要性;
- 可以观察特征正负影响;
- 理论基础较强;
- 适用于多种模型。
LIME 和 SHAP 都是常见的模型解释方法。
| 对比项 | LIME | SHAP |
|---|---|---|
| 理论基础 | 局部线性近似 | Shapley Value |
| 稳定性 | 相对较弱 | 相对较强 |
| 是否满足加性解释 | 不严格 | 满足 |
| 计算成本 | 通常较低 | 通常较高 |
| 解释类型 | 局部解释 | 局部解释 + 全局解释 |
| 使用场景 | 快速局部解释 | 更严谨的模型解释 |
简单理解:LIME 更像是在某个样本附近训练一个简单模型来模拟复杂模型;SHAP 更像是从公平分配贡献的角度解释每个特征的影响。
11. SHAP 的优缺点
11.1 SHAP 的优点:
(1)理论基础扎实
SHAP 基于博弈论中的 Shapley Value,具有较强的数学理论基础。
(2)同时支持局部解释和全局解释
局部解释关注单个样本:
text
为什么这个样本预测为 A?全局解释关注整体模型:
text
模型整体上最依赖哪些特征?SHAP 同时支持这两种解释方式。
(3)适用于多种模型
SHAP 可以解释:
- 线性模型;
- 树模型;
- 神经网络;
- 任意黑盒模型。
(3)可视化丰富
SHAP 提供了多种可视化方式,适合数据分析、模型诊断和业务汇报。
11.2 SHAP 的缺点
虽然 SHAP 很强大,但也不是万能的。
(1)计算成本较高
精确计算 Shapley Value 需要遍历所有特征组合。如果有 N 个特征,那么组合数量是指数级的。因此在高维数据中直接计算非常困难。
SHAP 通常使用近似算法或针对特定模型的优化算法来提高效率。
(2)对特征相关性敏感
如果特征之间高度相关,SHAP 的解释结果可能会比较复杂。
例如:
text
收入
月消费
信用额度这些特征之间可能存在较强相关性。
模型可能同时使用这些特征,SHAP 在分配贡献时可能会出现分散贡献的情况。
(3)SHAP的解释不等于因果关系
SHAP 只能说明在当前模型中,某个特征对预测结果有多大贡献,但不能直接说明某个特征导致了结果变化。毕竟数据的相关性并不代表因果性,如反向因果、共同原因、传递因果、纯属巧合等等。
例如,模型发现"购买高端手机"和"信用风险低"有关,这并不代表购买高端手机会导致信用风险降低。
SHAP 解释的是模型行为,不是现实世界的因果关系。是否存在事实上的因果关系需要进一步验证
12. SHAP 常见应用场景
12.1 金融风控
在信贷审批中,SHAP 可以解释:
- 为什么用户被拒贷?
- 哪些因素提高了违约风险?
- 哪些因素降低了风险?
- 模型是否过度依赖某些敏感特征?
12.2 医疗诊断
在医疗模型中,SHAP 可以解释:
- 哪些指标导致模型判断为高风险?
- 某个病人的关键风险因素是什么?
- 模型判断是否符合医生经验?
12.3 推荐系统
在推荐系统中,SHAP 可以解释:
- 为什么推荐这个商品?
- 用户行为中哪些特征影响最大?
- 价格、品牌、历史点击是否影响推荐结果?
12.4 广告点击率预测
在 CTR 预估中,SHAP 可以分析:
- 哪些用户特征影响点击概率?
- 哪些广告特征更重要?
- 是否存在某些异常特征主导预测?
12.5 工业故障预测
在设备故障预测中,SHAP 可以解释:
- 哪些传感器指标导致故障风险升高?
- 是否存在温度、电流、压力等异常模式?
- 模型是否捕捉到了真实的故障信号?
13. 实际项目中如何使用 SHAP?
在实际项目中,推荐按照以下流程使用 SHAP。
13.1 第一步:训练模型
先完成常规建模流程:
text
数据清洗 → 特征工程 → 模型训练 → 模型评估13.2 第二步:计算 SHAP 值
根据模型类型选择合适解释器:
- 树模型优先使用 TreeExplainer;
- 深度学习模型可以考虑 DeepExplainer;
- 黑盒模型可以使用 KernelExplainer;
- 通用场景可以直接使用 shap.Explainer。
13.3 第三步:做全局解释
使用:
python
shap.plots.bar(shap_values)
shap.summary_plot(shap_values, X_test)分析模型整体特征重要性。
13.4 第四步:做局部解释
使用:
python
shap.plots.waterfall(shap_values[0])解释单个样本的预测结果。
13.5 第五步:结合业务验证
SHAP 的解释结果不能只从技术角度看,还要结合业务经验。
需要判断:
- 重要特征是否符合常识?
- 是否存在数据泄露?
- 是否存在不合理偏见?
- 是否使用了敏感特征?
- 是否存在异常样本?
13.6 一个完整的 SHAP 分析模板
下面给出一个较完整的分析模板。
python
import shap
import pandas as pd
import numpy as np
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# 1. 加载数据
data = load_breast_cancer()
X = pd.DataFrame(data.data, columns=data.feature_names)
y = data.target
# 2. 划分数据集
X_train, X_test, y_train, y_test = train_test_split(
X,
y,
test_size=0.2,
random_state=42,
stratify=y
)
# 3. 训练模型
model = RandomForestClassifier(
n_estimators=200,
max_depth=5,
random_state=42
)
model.fit(X_train, y_train)
# 4. 模型评估
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
# 5. 构建解释器
explainer = shap.Explainer(model, X_train)
# 6. 计算 SHAP 值
shap_values = explainer(X_test)
# 7. 全局特征重要性
shap.plots.bar(shap_values)
# 8. 全局分布解释
shap.summary_plot(shap_values, X_test)
# 9. 单样本解释
shap.plots.waterfall(shap_values[0])
# 10. 单特征依赖关系
shap.plots.scatter(shap_values[:, X.columns[0]])14. SHAP 使用中的常见问题
问题 1:SHAP 值越大,特征越重要吗?
如果看单个样本,SHAP 绝对值越大,说明该特征对该样本预测影响越大。
如果看整体模型,通常使用平均绝对 SHAP 值衡量全局重要性。
问题 2:SHAP 值为正一定代表好事吗?
不一定。
SHAP 值为正,只代表该特征把模型输出往更高方向推动。
在不同任务中,"更高"含义不同:
- 如果预测违约风险,更高可能代表风险更大;
- 如果预测购买概率,更高可能代表更可能购买;
- 如果预测房价,更高代表预测价格更高。
问题 3:SHAP 能解释因果关系吗?
不能。
SHAP 解释的是模型预测逻辑,不是现实世界因果关系。
问题 4:为什么 SHAP 图中有些特征影响方向不明显?
可能原因包括:
- 特征与目标关系非线性;
- 特征和其他特征存在交互;
- 特征本身噪声较大;
- 不同样本群体中该特征影响方向不同。
问题 5:SHAP 计算很慢怎么办?
可以尝试:
- 对背景数据进行采样;
- 减少解释样本数量;
- 优先使用树模型专用解释器;
- 对高维稀疏特征做筛选;
- 只解释代表性样本。
例如:
python
background = shap.sample(X_train, 100)
explainer = shap.Explainer(model, background)
shap_values = explainer(X_test.iloc[:200])总结
SHAP 是当前机器学习模型可解释性中非常重要的方法之一。它基于博弈论中的 Shapley Value,将模型预测结果拆解为各个特征的贡献,从而帮助我们理解模型的预测逻辑。
本文主要介绍了:
- 为什么需要模型可解释性;
- SHAP 的基本概念;
- Shapley Value 的数学原理;
- SHAP 的核心性质;
- SHAP 常见解释器;
- SHAP 的可视化方法;
- SHAP 在分类和回归任务中的使用;
- SHAP 与 LIME 的区别;
- SHAP 在实际业务中的应用和注意事项。
SHAP 不是告诉我们现实世界为什么这样,而是告诉我们模型为什么这样预测。在实际项目中,SHAP 非常适合用于模型诊断、业务解释、风险分析、特征筛选和模型汇报。但在使用时,也要注意计算成本、特征相关性、数据泄露以及因果误读等问题。