这里写自定义目录标题
- [SpringBoot AI 项目标准化分层架构:统一封装大模型请求层设计文档](#SpringBoot AI 项目标准化分层架构:统一封装大模型请求层设计文档)
-
- 一、先吐槽:市面上很多AI项目架构有多垃圾?
- 二、为什么传统SpringBoot分层架构,适配不了AI项目?
- [三、SpringBoot AI 专属标准化分层架构](#三、SpringBoot AI 专属标准化分层架构)
- 四、架构核心优势(为什么一定要这么分层?)
- 五、项目目录结构标准化落地
- 六、核心实战:统一大模型请求层完整封装
- 七、架构运行流程全景解析
- 八、这套架构解决的8大行业痛点
- 九、新手常见误区答疑
- 十、总结:AI项目架构的核心本质
SpringBoot AI 项目标准化分层架构:统一封装大模型请求层设计文档
哈喽各位后端小伙伴!
最近两年AI开发彻底爆火,不管是个人练手、公司新项目,还是毕设接单,SpringBoot + 大模型 已经成为后端必备技能。但我发现一个超级离谱的现象:大多数人写的AI项目,全是"一次性Demo代码"。
写测试接口的时候,直接在Controller里硬写API地址、拼接Prompt、处理返回结果、手写异常捕获。跑通了就万事大吉,一上线直接崩心态:改个模型要改十处代码、切换服务商直接重写、报错混乱没法排查、多轮对话逻辑耦合一坨。
很多小伙伴疑惑:为什么我的AI项目只能跑Demo,根本没法上线?
答案很简单:没有标准化分层架构,没有统一封装大模型请求层。
今天这篇文章,我不带大家写无聊的对话Demo,专门搞定SpringBoot AI项目生产级分层架构,手把手封装一套通用、可复用、可扩展、易维护的大模型请求层。看完这篇,你的AI项目直接从"玩具代码"升级为"企业级可上线架构",适配SpringAI、LangChain4j、Ollama、通义千问、DeepSeek所有大模型,一劳永逸!
一、先吐槽:市面上很多AI项目架构有多垃圾?
咱们先复盘一下大多数人写AI项目的通病,看看你是不是也中招了,句句真实,绝不空谈!
1.代码严重耦合,一锅炖
Controller层既要接收前端参数、又要拼接Prompt、调用大模型接口、处理流式返回、捕获异常、封装结果。一个接口几百行代码,改个需求心惊胆战。
2.模型硬编码,切换模型等于重写项目
写死OpenAI地址、Ollama接口、模型名称。今天用DeepSeek,明天换通义千问,后天切换本地私有化模型,每次都要改核心业务代码,极其低效。
3.没有统一请求、响应规范
不同模型返回格式不一样,有的是JSON、有的是流式分片、有的自带溯源信息。没有统一封装,代码到处是if-else判断,冗余又丑陋。
4.异常混乱,线上排查无解
超时异常、限流异常、模型报错、参数非法、网络异常全部混在一起。用户报错只知道"请求失败",开发者根本不知道问题出在哪。
5.无法扩展功能
后期想加日志记录、Token统计、接口限流、对话缓存、请求溯源,根本没有预留扩展位置,只能硬塞代码,越写越乱。
总结一句话:没有分层封装的AI项目,永远只能是本地Demo,绝对上不了生产!
二、为什么传统SpringBoot分层架构,适配不了AI项目?
很多小伙伴会说:我会MVC分层啊,Controller、Service、Dao三层架构不就行了?
实话实说:传统Web架构,完全适配不了大模型业务!
普通CRUD项目,请求逻辑非常简单:前端传参 → 校验参数 → 操作数据库 → 返回结果。流程固定、同步执行、逻辑单一。
但AI大模型请求,是复杂复合型业务,包含超多专属流程:
-
参数校验(Prompt长度、模型权限、用户配额)
-
Prompt模板动态拼接(系统提示词、用户问题、上下文)
-
大模型路由分发(动态选择不同厂商模型)
-
HTTP/流式SSE请求调用
-
响应数据解析、格式化、结构化映射
-
异常捕获、重试、降级、兜底处理
-
Token统计、日志埋点、请求溯源
-
对话上下文缓存、会话持久化
如果全部塞进普通Service层,架构直接崩塌。所以我们必须在传统MVC基础上,新增专属AI分层,剥离大模型相关所有逻辑,单独封装通用请求层!
三、SpringBoot AI 专属标准化分层架构
给大家设计一套企业级、通用、适配所有AI场景的七层架构 ,兼顾可读性、复用性、扩展性,个人项目、企业开发都能直接用。
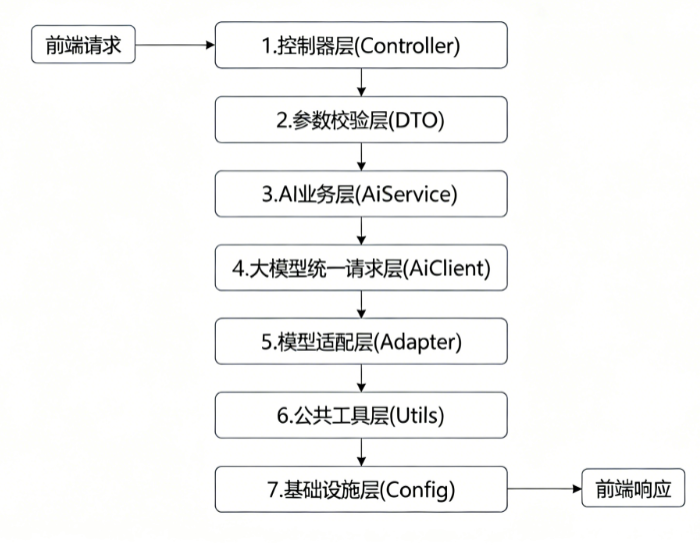
整体分层从上到下:
前端请求 → 控制器层 → 参数校验层 → AI业务层 → 大模型统一请求层(核心) → 模型适配层 → 公共工具层
1.控制器层(Controller):只做一件事,接收请求
职责极致单一:接收前端参数、统一返回结果、分发请求。不写任何业务逻辑、不拼接Prompt、不调用模型。彻底杜绝Controller臃肿问题。
2.参数校验层(DTO+Validator):拦截非法请求
统一校验用户输入、Prompt长度、模型参数、用户权限、请求配额,提前拦截无效请求,避免无效调用大模型,节省接口成本。
3.AI业务层(AiService):处理业务逻辑
处理多轮对话、上下文拼接、RAG知识库关联、用户业务权限、日志记录等业务相关逻辑。
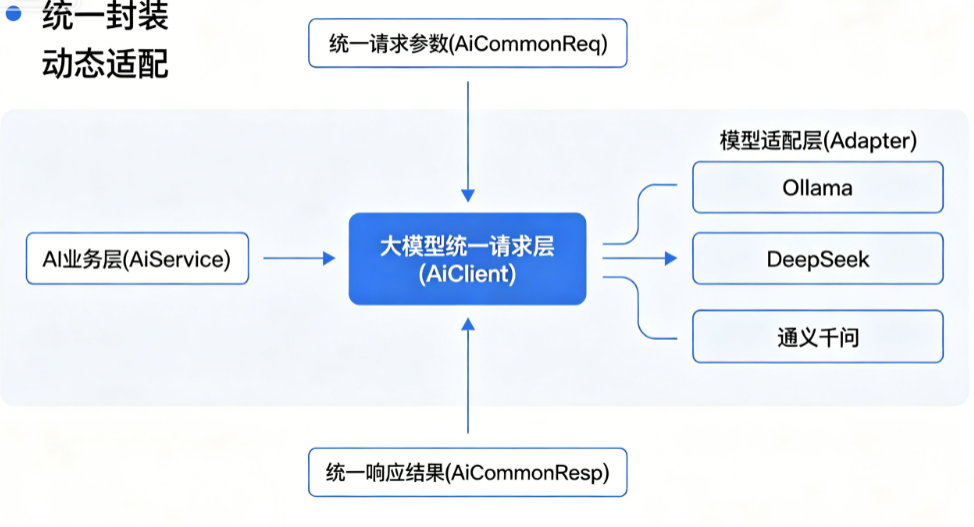
4.大模型统一请求层(AiClient,本文核心)
整个架构的灵魂!!!
单独抽离通用大模型请求逻辑,统一封装:同步对话、流式对话、参数封装、通用异常、请求重试、结果解析。所有模型共用这一层,完全解耦业务。
5.模型适配层(Adapter):多模型无缝切换
针对Ollama、通义千问、DeepSeek、SpringAI、vLLM做适配封装,统一入参、统一出参,上层完全不用关心底层模型差异,实现插拔式切换模型。
6.公共工具层(Utils):通用能力封装
Prompt工具、Token计算、脱敏工具、时间工具、缓存工具,全局复用。
7.基础设施层(Config):全局配置
AI模型配置、限流配置、SSE流式配置、全局异常配置、线程池配置。
四、架构核心优势(为什么一定要这么分层?)
很多小伙伴觉得分层麻烦,不如直接写接口快。但我告诉你,前期偷懒,后期加班!这套架构的优势,用过的人都说香:
-
彻底解耦:业务代码和AI模型调用完全分离,改模型不动业务,改业务不动请求层
-
极高复用:全局所有AI接口,统一使用一套请求层,零冗余代码
-
无缝扩展:新增模型、新增AI功能,只需新增适配器,不用改核心代码
-
便于维护:报错精准定位,是参数问题、网络问题、模型问题还是业务问题,一目了然
-
适配生产:天然支持限流、重试、降级、日志、监控,直接上线不用重构
-
适配团队协作:架构统一,新人接手不用读垃圾代码,上手即会
五、项目目录结构标准化落地
给大家整理了可直接用于生产的目录结构,告别乱七八糟的文件排布,强迫症狂喜!
java
com.xxx.ai
├── config // AI全局配置类
├── controller // 前端接口控制器
├── dto // 请求/响应数据封装
│ ├── req // 请求参数
│ └── resp // 统一返回体
├── service // AI业务层
│ ├── impl
│ └── context // 对话上下文管理
├── aiClient // 核心:大模型统一请求层
│ ├── core // 通用请求封装
│ ├── stream // 流式SSE封装
│ └── retry // 重试机制
├── adapter // 多模型适配层
│ ├── ollama
│ ├── deepseek
│ └── springai
├── util // AI专属工具类
├── exception // 自定义AI异常
└── constant // AI常量配置重点强调:aiClient 包是整个项目的核心灵魂,所有大模型调用全部收敛在这里,全局唯一入口,这就是标准化架构的精髓!
六、核心实战:统一大模型请求层完整封装
废话不多说,直接上可上线的完整代码,每一行都是生产级写法,轻松替换所有Demo代码。
1.统一AI请求参数实体(通用所有模型)
摒弃各模型杂乱参数,统一封装通用请求体,适配同步、流式、多轮对话。
java
@Data
@NoArgsConstructor
@AllArgsConstructor
public class AiCommonReq {
// 模型名称
private String modelName;
// 用户提问
private String userPrompt;
// 系统提示词
private String systemPrompt;
// 温度参数(随机性 0-1)
private Double temperature = 0.7;
// 最大生成长度
private Integer maxTokens = 2048;
// 是否开启流式输出
private Boolean stream = false;
// 对话唯一ID(多轮上下文使用)
private String sessionId;
}2.统一AI响应结果封装
统一所有模型返回格式,彻底解决不同模型返回结构不统一的问题。
java
@Data
public class AiCommonResp {
// 是否成功
private Boolean success;
// 模型返回内容
private String content;
// 本次消耗token
private Integer usageTokens;
// 错误信息
private String errorMsg;
// 响应时间
private Long responseTime;
}3.核心:大模型统一请求客户端(AiClient)
全局唯一调用入口,封装通用请求逻辑、异常捕获、耗时统计,所有业务层统一调用此类。
java
@Component
public class AiModelClient {
private final OllamaAdapter ollamaAdapter;
private final DeepSeekAdapter deepSeekAdapter;
// 构造器注入所有模型适配器
public AiModelClient(OllamaAdapter ollamaAdapter, DeepSeekAdapter deepSeekAdapter) {
this.ollamaAdapter = ollamaAdapter;
this.deepSeekAdapter = deepSeekAdapter;
}
/**
* 统一同步对话请求
*/
public AiCommonResp chat(AiCommonReq req) {
long startTime = System.currentTimeMillis();
try {
// 根据模型名称动态路由适配层
AiCommonResp resp = switchModel(req.getModelName()).chat(req);
resp.setSuccess(true);
resp.setResponseTime(System.currentTimeMillis() - startTime);
return resp;
} catch (AiException e) {
AiCommonResp resp = new AiCommonResp();
resp.setSuccess(false);
resp.setErrorMsg(e.getMessage());
resp.setResponseTime(System.currentTimeMillis() - startTime);
return resp;
}
}
/**
* 动态匹配模型适配器
*/
private BaseModelAdapter switchModel(String modelName) {
if (modelName.startsWith("ollama")) {
return ollamaAdapter;
} else if (modelName.startsWith("deepseek")) {
return deepSeekAdapter;
} else {
throw new AiException("暂不支持当前模型类型");
}
}
}4.模型适配器抽象层(核心解耦设计)
定义统一接口,所有模型适配器实现该接口,完美符合开闭原则,新增模型无需修改核心代码。
java
public interface BaseModelAdapter {
/**
* 统一对话方法
*/
AiCommonResp chat(AiCommonReq req);
}5.自定义AI全局异常
精准区分AI业务异常和系统异常,线上排查问题效率翻倍。
java
public class AiException extends RuntimeException {
public AiException(String message) {
super(message);
}
}七、架构运行流程全景解析
我用大白话给大家捋一遍完整请求流程,看完彻底懂这套架构的精髓:
第一步:前端发起提问请求
前端传递问题、模型类型、会话ID,请求后端接口。
第二步:DTO层参数校验
自动校验参数合法性,空参数、超长Prompt直接拦截,不进入后续逻辑。
第三步:AI业务层处理业务逻辑
拼接系统提示词、读取Redis上下文、组装完整请求参数。
第四步:调用统一AiClient请求层
业务层不直接调用模型,统一交给AiClient处理。
第五步:动态路由模型适配器
AiClient根据模型名称,自动匹配对应的模型适配层。
第六步:适配器发起真实模型调用
适配层完成HTTP请求、参数适配、结果解析,返回统一格式数据。
第七步:统一封装结果返回前端
统一响应格式、耗时统计、异常封装,前端无需适配多模型格式。
整个流程层层隔离、职责清晰、完全解耦!
八、这套架构解决的8大行业痛点
很多人不知道标准化架构的价值,我直接说落地痛点,句句扎心:
-
解决模型切换繁琐问题:改配置即可切换模型,无需改代码
-
解决代码耦合混乱问题:层级清晰,各司其职,告别一坨代码
-
解决返回格式不统一问题:所有模型统一返回体,前端适配一次永久通用
-
解决异常无法排查问题:自定义AI异常,精准定位报错源头
-
解决无法扩展问题:新增模型、新增功能只加代码不改旧逻辑
-
解决重复代码冗余问题:全局统一请求层,杜绝重复造轮子
-
解决线上不可控问题:可快速叠加限流、重试、监控、日志能力
-
解决项目无法迭代问题:架构规范统一,长期迭代不崩塌
九、新手常见误区答疑
误区1:小项目没必要分层,多此一举?
正解:大错特错! 所有烂项目,都是从"小项目不用规范"开始的。项目越做越大,代码越堆越乱,最后完全不敢改、不敢动,只能重构重写,浪费更多时间。规范分层是最低成本的长期投资。
误区2:直接用SpringAI封装好的工具类不就行了?
正解:框架封装是基础,业务封装是架构! SpringAI只帮你调接口,不会帮你做分层、解耦、统一异常、多模型适配、业务隔离。框架是工具,分层架构是工程思想,完全不是一个东西。
误区3:分层太多会不会影响开发速度?
正解:前期慢一点,后期快十倍! 第一次搭建架构需要半小时,后续开发新AI接口,只需要写业务逻辑,不用重复处理请求、解析、异常,开发效率直接拉满。
十、总结:AI项目架构的核心本质
看完整篇文章,相信大家已经明白:真正的工程化AI项目,不是会调用大模型接口,而是会合理分层、统一封装、解耦扩展。
市面上99%的教程,只教你"怎么调通AI接口",而这篇文章教你"怎么把AI项目做成企业级架构"。
当你掌握了这套标准化分层架构,你就彻底脱离了"只会写Demo的初级开发者",迈入了AI后端工程化、架构师级的行列。
后续所有RAG知识库、AI智能体、多模型调度、私有化大模型项目,全部可以基于这套架构快速迭代!