文章目录
- [1.双目散斑 3D 相机概述](#1.双目散斑 3D 相机概述)
- 2.工作原理:从DOE到深度图
-
- [2.1 衍射光学元件(DOE)](#2.1 衍射光学元件(DOE))
- [2.2 红外成像与滤波](#2.2 红外成像与滤波)
- [2.3 深度计算](#2.3 深度计算)
- 3.三角测深几何原理
-
- [3.1 基本三角测量模型](#3.1 基本三角测量模型)
-
- [3.1.1 针孔相机模型基础](#3.1.1 针孔相机模型基础)
- [3.1.2 双目三角测量几何](#3.1.2 双目三角测量几何)
- [3.2 深度分辨率与精度的关系](#3.2 深度分辨率与精度的关系)
- [3.3 左右基线矫正](#3.3 左右基线矫正)
-
- [3.3.1 什么是基线矫正?](#3.3.1 什么是基线矫正?)
- [3.3.2 极线几何基础](#3.3.2 极线几何基础)
- [3.3.3 Bouguet 矫正算法](#3.3.3 Bouguet 矫正算法)
- [3.3.4 Hartley矫正算法](#3.3.4 Hartley矫正算法)
- [3.3.5 基线矫正的误差来源](#3.3.5 基线矫正的误差来源)
- [3.3.6 实际工程中的基线矫正流程](#3.3.6 实际工程中的基线矫正流程)
- 4.立体匹配流水线
- 5.RGB-Depth对齐的必要性
-
- [5.1 为什么具有挑战性?](#5.1 为什么具有挑战性?)
- 6.D2C(Depth-to-Color)算法详解
-
- [6.1 Deproject(深度图→ 3D点云)](#6.1 Deproject(深度图→ 3D点云))
- [6.2 Coordinate Transformation(坐标系变换)](#6.2 Coordinate Transformation(坐标系变换))
- [6.3 Reproject(投影到彩色图像平面)](#6.3 Reproject(投影到彩色图像平面))
- [6.4 关键问题:遮挡与空缺](#6.4 关键问题:遮挡与空缺)
- 7.RGB-D对齐方法全景
-
- [7.1 对齐方法分类总览](#7.1 对齐方法分类总览)
- [7.2 D2(Depth-to-Color)对齐](#7.2 D2(Depth-to-Color)对齐)
-
- [7.2.1 OpenCV 实现示例:](#7.2.1 OpenCV 实现示例:)
- [7.3 C2D(Color-to-Depth)对齐](#7.3 C2D(Color-to-Depth)对齐)
- [7.4 中间坐标系对齐](#7.4 中间坐标系对齐)
- [7.5 深度学习对齐方法](#7.5 深度学习对齐方法)
-
- [7.5.1 深度补全网络(Guided Depth Completion)](#7.5.1 深度补全网络(Guided Depth Completion))
- [7.6 对齐方法对比总结](#7.6 对齐方法对比总结)
- [7.7 工程实践建议](#7.7 工程实践建议)
- 8.分辨率不匹配的解决方案
- 9.学习资源与进阶路线
-
- [9.1 入门基础](#9.1 入门基础)
- [9.2 深入实践](#9.2 深入实践)
- [10.3 进阶方向](#10.3 进阶方向)
1.双目散斑 3D 相机概述
双目散斑3D相机是一种基于主动红外结构光 的深度传感器。
其核心思想是:用一颗红外光源照射漫反射光学元件(DOE),产生随机但唯一的散斑图案投射到场景中;再由两颗经标定的红外摄像头从不同视角拍摄该散斑图案,通过立体匹配恢复深度信息。
相较于飞行时间(ToF)方案和被动立体视觉,双目散斑方案具备以下特点:
- 高精度:散斑具有极丰富的纹理特征,匹配亚像素级可达毫米级深度精度
- 抗环境光干扰:主动投射红外散斑 + 红外滤镜,可在明亮室内甚至户外部分场景工作
- 近距离优势:有效工作距离通常在 0.2 ~ 2m,非常适合人脸识别、手势交互等近场应用
- 暗色表面兼容性好:不依赖场景自身纹理,黑色吸光表面也能获得深度
2.工作原理:从DOE到深度图
2.1 衍射光学元件(DOE)
DOE(Diffractive Optical Element)是整个系统的起点。激光二极管发出的准直光束经过DOE 后,被微纳级的表面浮雕结构调制,发生衍射和干涉,在远场形成一幅随机但确定、高对比度的散斑图案。
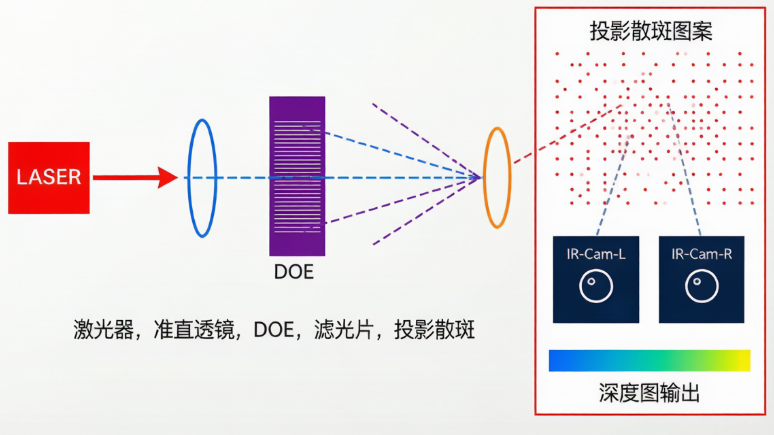
LASER → 准直透镜 → DOE(衍射)→ 散斑投射 → IR-Cam-L / IR-Cam-R → 深度图输出
2.2 红外成像与滤波
两颗红外摄像头前方均装有窄带红外滤镜(通常为850nm 或940nm中心波长),只允许投射激光的波长通过,从而抑制环境光的干扰。这保证了即使在强光环境下,散斑图案仍然清晰可辨。
2.3 深度计算
获得左右摄像头的两张红外散斑图像后,通过立体匹配算法找出每个像素在左右图中的对应点,进而利用三角几何关系计算出深度值。详见下文各节。
3.三角测深几何原理
3.1 基本三角测量模型
双目3D相机的核心数学模型是三角测量法(Triangulation)。
3.1.1 针孔相机模型基础
在针孔相机模型中,3D空间点 P(X, Y, Z) 通过透视投影映射到像平面上的2D点p(x, y):
bash
x = f × X / Z + cx
y = f × Y / Z + cy其中f为焦距(像素单位),(cx, cy)为主点(光轴与像平面的交点)。
3.1.2 双目三角测量几何
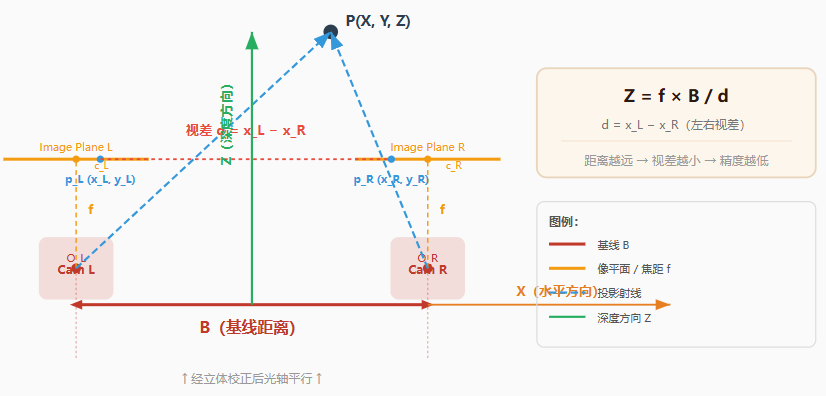
设两相机焦距均为 f ,基线距离为 B ,3D 点在左右图像上的水平像素坐标分别为 x_L 和 x_R,则视差(disparity)为:
bash
d = x_L − x_R深度值 Z 可通过以下公式计算:
bash
Z = (f × B) / d进一步恢复完整 3D 坐标 (X, Y, Z):
bash
X = (x_L − cx) × Z / f
Y = (y_L − cy) × Z / f其中(cx , cy) 为主点偏移(principal point),由相机内参标定获得。
3.2 深度分辨率与精度的关系
深度精度σ_Z与视差误差σ_d的关系为:
bash
σ_Z = (Z² / (f × B)) × σ_d关键推导:对Z = fB/d 求微分:
bash
dZ/dd = −fB/d² = −Z²/(fB)
|σ_Z| = (Z² / (fB)) × σ_d可见深度误差随 Z² 增长------即距离越远,深度精度下降越快。这也是为什么推荐散斑相机的工作距离在0.2~3m 的原因。
影响精度的关键因素:
| 因素 | 影响 | 改善方法 |
|---|---|---|
| 基线 B | B 越大,精度越高(但近距盲区增大) | 优化基线设计,典型值 40~100mm |
| 焦距 f | f 越大,精度越高(但 FOV 缩小) | 选择适中焦距,平衡FOV与精度 |
| 视差误差 σ_d | 受匹配算法、散斑质量、噪声影响 | 亚像素精化、时域多帧融合 |
| 工作距离 Z | Z 越远精度越差(Z² 关系) | 限制有效工作范围 |
3.3 左右基线矫正
cpp
原始标定向参数
│
▼
计算左右相机的平均旋转R_avg
│
▼
构造校正旋转矩阵R₁, R₂(满足共面共轴条件)
│
▼
生成透视变换映射表cv::initUndistortRectifyMap
│
▼
对左右图像进行重映射undistort + rectify
│
▼
同名点严格行对齐 → 一维极线搜索3.3.1 什么是基线矫正?
在实际双目系统中,两个相机的光轴不可能完全平行。制造公差、装配误差、温度形变等因素都会导致:
- 两相机光轴存在会聚/发散角(convergence/divergence angle)
- 两相机之间存在相对旋转(roll, pitch, yaw)
- 极线(epipolar line)不在同一水平线上
基线矫正的目的 :通过数学变换,将左右图像"虚拟地"旋转到光轴完全平行、像平面共面的状态,使得:
- 极线变为水平线(同一行)
- 对应点仅在水平方向(u 方向)有偏移
- 二维匹配简化为一维搜索
3.3.2 极线几何基础
双目系统的几何关系由极线约束(Epipolar Constraint)描述:
bash
p_R^T × F × p_L = 0其中:
- F为 3×3 基础矩阵,编码了两相机之间的全部几何关系
- p_L = u_L, v_L, 1^T 为左图齐次坐标
- p_R = u_R, v_R, 1^T 为右图齐次坐标
极线的含义:左图中的一点 p_L,在右图中的对应点 p_R 必然位于极线 l_R = F × p_L 上。这将搜索范围从二维平面压缩到一维直线。
当两相机光轴不平行时,极线是斜线,搜索效率低且容易出错。基线矫正的目标就是让极线变成水平线。
3.3.3 Bouguet 矫正算法
Bouguet算法是OpenCV中 cv2.stereoRectify() 的默认实现,核心思想是最小化图像重投影畸变:
Step 1:分解外参
从标定得到的旋转矩阵 R 和平移向量 T,分解为左右相机各自的旋转:
baash
R_L = R_half^T
R_R = R_half其中 R_half 将两相机旋转到"中间方向"------使得两相机光轴平行且指向正前方。
Step 2:计算矫正旋转矩阵
baash
R_rect = [r1^T; r2^T; r3^T]其中:
- r1 = T / ||T||(基线方向,即新的 x 轴)
- r2 = −T_z, 0, T_x^T / √(T_x² + T_z²)(与 r1 正交且在水平面内)
- r3 = r1 × r2(新的 z 轴方向,即光轴方向)
Step 3:合成最终旋转
bash
R_L_rectified = R_rect × R_L
R_R_rectified = R_rect × R_RStep 4:计算投影矩阵和重映射
利用新的旋转矩阵和原始内参,计算矫正后的投影矩阵 P_L、P_R,再生成重映射表(remap map)用于图像变换。
3.3.4 Hartley矫正算法
Hartley算法的核心思想是直接用单应性矩阵变换图像,不依赖标定参数:
Step 1:估计基础矩阵 F
通过匹配点对,使用八点法或RANSAC估计F矩阵。
Step 2:寻找最优单应性矩阵
对左右图像分别施加单应性变换H_L 和 H_R,使得变换后的极线变为水平线。
Step 3:最小化射影畸变
Hartley算法的关键创新是最小化变换后的图像畸变------通过优化 H_L 和 H_R 中的参数,使变换后图像尽可能接近原图(避免过度拉伸)。
与Bouguet 的对比:
| 维度 | Bouguet | Hartley |
|---|---|---|
| 输入要求 | 需要完整标定(内参+外参) | 仅需匹配点对(可估计 F) |
| 矫正质量 | 依赖标定精度 | 仅依赖匹配点质量 |
| 适用场景 | 标定完备的工程系统 | 未标定或标定不精确的场景 |
| OpenCV 实现 | cv2.stereoRectify() |
需自行实现或使用 cv2.stereoRectifyUncalibrated() |
3.3.5 基线矫正的误差来源
| 误差来源 | 影响 | 补偿方法 |
|---|---|---|
| 标定误差 | 矫正后极线仍有微小倾斜 | 高精度标定板 + 多帧平均 |
| 温度漂移 | 焦距和基线随温度变化 | 在线自标定、温度补偿表 |
| 机械振动 | 外参实时变化 | 定期重标定、IMU 辅助 |
| 镜头畸变残差 | 边缘区域极线弯曲 | 增加畸变模型阶数(k3, k4) |
| 图像量化 | 像素离散化导致亚像素误差 | 亚像素插值、超分辨率 |
3.3.6 实际工程中的基线矫正流程
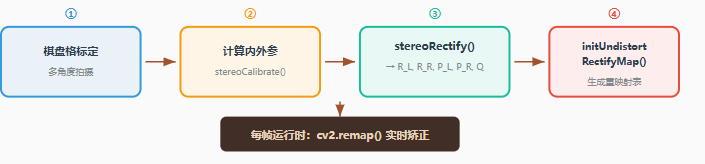
实际工程中的基线矫正流程(标定→参数计算→矫正矩阵→实时重映射 )
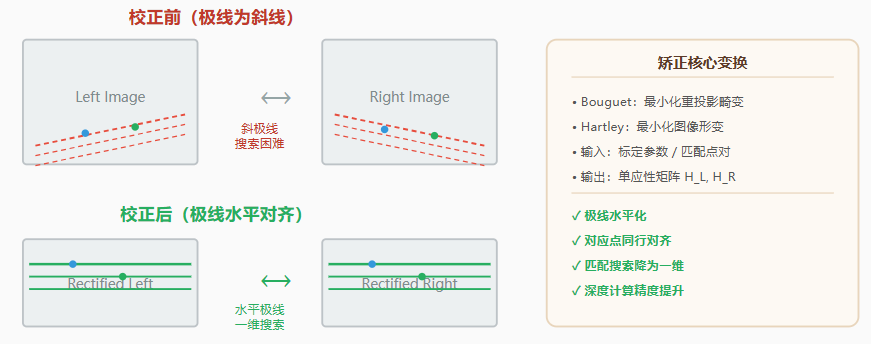
立体校正前后对比 --- 极线从斜线变为水平线,匹配搜索从二维降为一维
4.立体匹配流水线
从原始红外图像到可用的深度图,需要经过一系列处理步骤:

5.RGB-Depth对齐的必要性
在许多应用中(如3D人脸重建、机器人视觉),我们需要将深度图映射到彩色相机坐标系下,得到每个彩色像素对应的深度值。这就是RGB-Depth对齐问题。
5.1 为什么具有挑战性?
- 空间异构:RGB相机与深度相机通常是两个独立的传感器,物理位置不同,视角存在视差。即使场景是平面的,同一物体在两张图中的像素位置也会偏移。
- 分辨率不同:典型配置中,RGB分辨率可能为1280×720或更高,而红外散斑深度图仅为640×480甚至 320×240。一个 RGB像素可能对应多个深度像素。
- 视场角差异:RGB相机的FOV通常大于红外相机,导致深度图的视场覆盖不了整个RGB图像边缘区域。
- 时序差异:如果RGB和深度帧不是严格同步采集的,运动场景中会出现错位。
6.D2C(Depth-to-Color)算法详解
D2C是将深度图转换到彩色相机坐标系的标准流程,包含三个核心步骤:
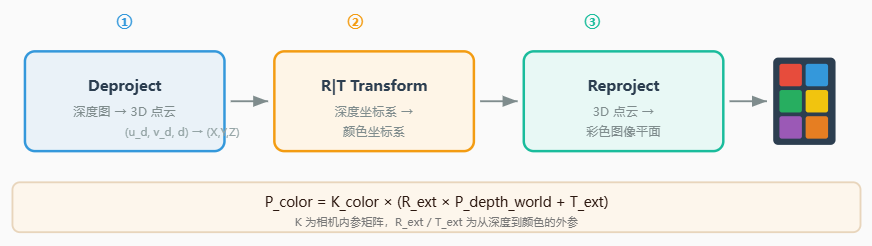
D2C(Depth-to-Color)对齐流水线
6.1 Deproject(深度图→ 3D点云)
对于深度图中的每个有效像素(u_d, v_d)及其深度值 d,利用深度相机内参矩阵K_d反投影到深度相机坐标系下的 3D 点:
python
# 归一化坐标
nx = (u_d - cx_d) / fx_d
ny = (v_d - cy_d) / fy_d
# 3D 点(深度相机坐标系)
X_d = nx * d
Y_d = ny * d
Z_d = d6.2 Coordinate Transformation(坐标系变换)
将深度相机坐标系下的3D点变换到颜色相机坐标系下:
python
P_color_frame = R_transform × P_depth_frame + T_transform
# R_transform: 3×3 旋转矩阵 (标定得到)
# T_transform: 3×1 平移向量 (标定得到)6.3 Reproject(投影到彩色图像平面)
利用颜色相机内参矩阵 K_c将3D点重新投影到彩色图像的像素坐标:
python
scale = 1.0 / Z_color
u_c = (fx_c * X_color + cx_c) * scale
v_c = (fy_c * Y_color + cy_c) * scale6.4 关键问题:遮挡与空缺
由于RGB相机和深度相机的视角不完全重合,以及对物体的自遮挡,对齐后会产生空洞。解决方法包括:
- 双向投影验证:同时将深度→颜色和颜色→深度投影,交叉验证一致性
- 最近邻插值:当一个RGB像素对应多个深度像素时,取最近的深度值
- 空洞填充:使用形态学膨胀、边沿传播或深度学习模型修复缺失区域
7.RGB-D对齐方法全景
7.1 对齐方法分类总览
RGB-D对齐方法可按处理阶段 和技术路线进行分类:
bash
RGB-D 对齐方法
├── 硬件级对齐(出厂前)
│ ├── 精密机械对准
│ └── 联合标定 + 固化参数
├── 软件级对齐(运行时)
│ ├── D2C(Depth-to-Color)--- 深度映射到彩色坐标系
│ ├── C2D(Color-to-Depth)--- 彩色映射到深度坐标系
│ └── 中间坐标系对齐 --- 映射到统一的世界坐标系
└── 深度学习对齐
├── 端到端深度-彩色联合估计
└── 深度补全网络(Guided Depth Completion)7.2 D2(Depth-to-Color)对齐
核心思想:将深度图中的每个像素反投影到3D空间,再投影到彩色相机的图像平面。
适用场景:大多数消费级RGB-D相机(RealSense、Orbbec)的默认模式。
优点:
- 保留完整的RGB分辨率
- 深度值与彩色像素一一对应
- 适合需要高分辨率彩色 + 深度的应用(如人脸重建)
缺点:
- 深度图分辨率损失(从深度分辨率映射到RGB分辨率,产生空洞)
- 边缘区域深度缺失(RGB FOV > 深度FOV)
- 计算量较大(需逐像素反投影+变换+投影)
7.2.1 OpenCV 实现示例:
python
import cv2
import numpy as np
def depth_to_color_align(depth_frame, depth_intrin, color_intrin, extrin):
"""D2C: 将深度图对齐到彩色坐标系"""
h_d, w_d = depth_frame.shape
h_c, w_c = color_intrin.height, color_intrin.width
aligned_depth = np.zeros((h_c, w_c), dtype=np.uint16)
# 构建深度图的像素网格
u_d, v_d = np.meshgrid(np.arange(w_d), np.arange(h_d))
depth_vals = depth_frame.astype(np.float64)
# Step 1: Deproject (深度图 → 3D点云,深度坐标系)
X_d = (u_d - depth_intrin.ppx) / depth_intrin.fx * depth_vals
Y_d = (v_d - depth_intrin.ppy) / depth_intrin.fy * depth_vals
Z_d = depth_vals
# Step 2: Transform (深度坐标系 → 彩色坐标系)
points_depth = np.stack([X_d, Y_d, Z_d], axis=-1) # (H, W, 3)
R = extrin.rotation.reshape(3, 3)
T = extrin.translation
points_color = points_depth @ R.T + T # (H, W, 3)
# Step 3: Reproject (3D点 → 彩色像素坐标)
X_c, Y_c, Z_c = points_color[..., 0], points_color[..., 1], points_color[..., 2]
valid = Z_c > 0
u_c = np.zeros_like(X_c)
v_c = np.zeros_like(Y_c)
u_c[valid] = (X_c[valid] * color_intrin.fx / Z_c[valid] + color_intrin.ppx).astype(int)
v_c[valid] = (Y_c[valid] * color_intrin.fy / Z_c[valid] + color_intrin.ppy).astype(int)
# 写入对齐后的深度图
mask = valid & (u_c >= 0) & (u_c < w_c) & (v_c >= 0) & (v_c < h_c)
aligned_depth[v_c[mask], u_c[mask]] = depth_vals[mask].astype(np.uint16)
return aligned_depth7.3 C2D(Color-to-Depth)对齐
核心思想:将彩色图像中的每个像素反投影到3D空间(需要深度信息辅助),再投影到深度相机的图像平面。
适用场景:当深度图是主要数据源、彩色仅作辅助时(如 SLAM、机器人导航)。
优点:
- 保留完整的深度分辨率
- 无深度空洞(所有深度像素都有对应彩色值)
- 计算量相对较小
缺点:
- 彩色分辨率损失
- 需要先有深度值才能进行反投影
- 边缘彩色信息缺失
7.4 中间坐标系对齐
核心思想:将RGB和深度图都映射到一个统一的世界坐标系或虚拟相机坐标系。
方法:
- 分别将 RGB 和深度图反投影到各自的 3D 坐标系
- 通过外参变换统一到世界坐标系
- 选择一个虚拟相机(可以是RGB相机、深度相机或全新的视角)进行投影
优点:
- 灵活性最高,可以选择任意输出视角
- 适合多传感器融合场景
缺点:
- 两次投影引入两次插值误差
- 计算量最大
7.5 深度学习对齐方法
近年来,深度学习方法在RGB-D对齐中展现出强大能力:
7.5.1 深度补全网络(Guided Depth Completion)
代表方法:NLSPN、MSG-CHN、ACMNet
原理:以低分辨率深度图为输入,以高分辨率RGB图为引导,通过神经网络预测高分辨率密集深度图。
bash
输入:稀疏/低分辨率深度图 + 高分辨率 RGB 图
↓
编码器:提取 RGB 图像特征
↓
引导模块:利用 RGB 边缘信息指导深度上采样
↓
解码器:预测高分辨率密集深度图
↓
输出:与 RGB 对齐的高分辨率深度图优势:
- 能够推断合理的几何结构(不只是简单插值)
- 边缘对齐质量高
- 可处理深度缺失区域
劣势:
- 需要大量配对训练数据
- 推理延迟较高(不适合实时低功耗场景)
- 泛化性受训练数据分布限制
7.6 对齐方法对比总结
| 方法 | 输入要求 | 输出分辨率 | 深度精度 | 计算量 | 适用场景 |
|---|---|---|---|---|---|
| D2C 投影 | 标定参数 | RGB 分辨率 | 原始精度(有空洞) | 中 | 3D 重建、AR |
| C2D 投影 | 标定参数 + 深度 | 深度分辨率 | 原始精度 | 中 | SLAM、导航 |
| 中间坐标系 | 标定参数 | 可选 | 原始精度(两次插值) | 高 | 多传感器融合 |
| 导向滤波上采样 | RGB + 深度 | RGB 分辨率 | 略有平滑 | 低 | 实时应用 |
| 深度补全网络 | RGB + 稀疏深度 | RGB 分辨率 | 网络推断(可能失真) | 高 | 离线处理、高质量需求 |
| 端到端估计 | RGB(+可选稀疏深度) | RGB 分辨率 | 绝对精度较低 | 高 | 无深度传感器时 |
7.7 工程实践建议
- 实时应用(30fps+):优先使用D2C 投影 + 硬件加速(GPU),配合导向滤波上采样
- 高质量离线处理:使用深度补全网络,结合D2C投影作为稀疏监督信号
- 多传感器融合:使用中间坐标系对齐,统一到世界坐标系后融合
- 标定质量保障:无论使用哪种方法,标定精度是基础------建议使用高精度棋盘格 + 多角度多距离标定
8.分辨率不匹配的解决方案
当RGB分辨率(如1280×720)高于深度分辨率(如640×480)时,需要通过上采样 + 对齐策略来弥合差距:
| 方法 | 原理 | 优点 | 缺点 |
|---|---|---|---|
| 最近邻插值 | 每个深度像素的值均匀分配到对应RGB区域 | 速度快,保留原始深度值 | 块状伪影,边界锯齿 |
| 双线性插值 | 在相邻4个深度像素之间做线性插值 | 过渡平滑,实现简单 | 高频细节模糊 |
| 双三次插值 | 利用周围16个像素进行三次卷积插值 | 比双线性更锐利 | 计算量更大 |
| 导向滤波上采样 | 以RGB图为引导图,将低分辨率深度图平滑地提升到高分辨率 | 保持边缘对齐,伪影少 | 需要调参,边界附近仍可能有偏差 |
| Census + 多尺度匹配 | 在深度图上构造Census变换描述子,通过稠密匹配提升到RGB分辨率 | 精度最高 | 计算量大,适合离线处理 |
| 深度学习超分辨率 | 使用CNN/Transformer从低分辨率深度图中预测高分辨率深度 | 能推断合理的几何结构 | 需要大量训练数据,推理延迟 |
在实际产品中,Intel RealSense SDK 使用了基于相机外参映射的方法:为每个彩色像素查找其在深度图坐标系中的对应位置,然后从最近的深度像素取值或插值。这种方法被称为 "per-pixel reprojection",在精度和性能之间取得了较好的平衡。
9.学习资源与进阶路线
9.1 入门基础
- OpenCV 教程 :
cv2.stereoCalibrate(),cv2.stereoRectify(),cv2.StereoSGBM官方文档与实践示例 - PCL(Point Cloud Library):点云数据处理的标准库,用于体素降采样、配准、分割等操作
9.2 深入实践
- Intel RealSense SDK:提供了从原始IR帧到RGB-D对齐的完整pipeline,源码开源,适合深入学习
- ORB-SLAM3:支持RGB、单目、立体和RGB-D输入的SLAM系统,了解完整的视觉定位管线
10.3 进阶方向
- RGB-D 点云配准:ICP算法及其变种(Point-to-Plane ICP, GO-ICP)
- 深度图超分辨率:导向滤波、联合双边滤波、CNN驱动的联合上采样
- 神经辐射场NeRF with RGB-D:引入深度先验 improving NeRF的几何重建质量