这篇文章摘要如下: 本文介绍了一种基于DNN的简单图像生成方法,用于生成MNIST数字图像。模型接收标签和随机噪声作为输入,通过嵌入层、全连接层和转置卷积层生成图像。文章详细阐述了模型架构设计思路,包括标签嵌入、潜在向量拼接等关键步骤,并提供了完整的PyTorch实现代码。模型训练采用MSE损失函数,通过可视化结果展示了生成效果。虽然DNN方法存在明显缺陷,但该实现为理解生成式模型提供了基础框架,演示了从条件输入到图像生成的基本流程。代码包含数据加载、网络定义、训练循环和结果可视化等完整模块。
1. 基本思路
用什么模型来生成图像呢?首先想到的肯定是最质朴的神经网络DNN。当然这个方法在实际中不会用到,因为它存在很大的缺陷,具体什么缺陷后面就可以看出来。这里只是为了展开思路。
现在梳理下整体的思路,我们需要输入一个标签(范围从0到9,表示我们想要生成的数字类别),然后需要输出一个对应标签的图像。自然而然就出现以下 工作流:
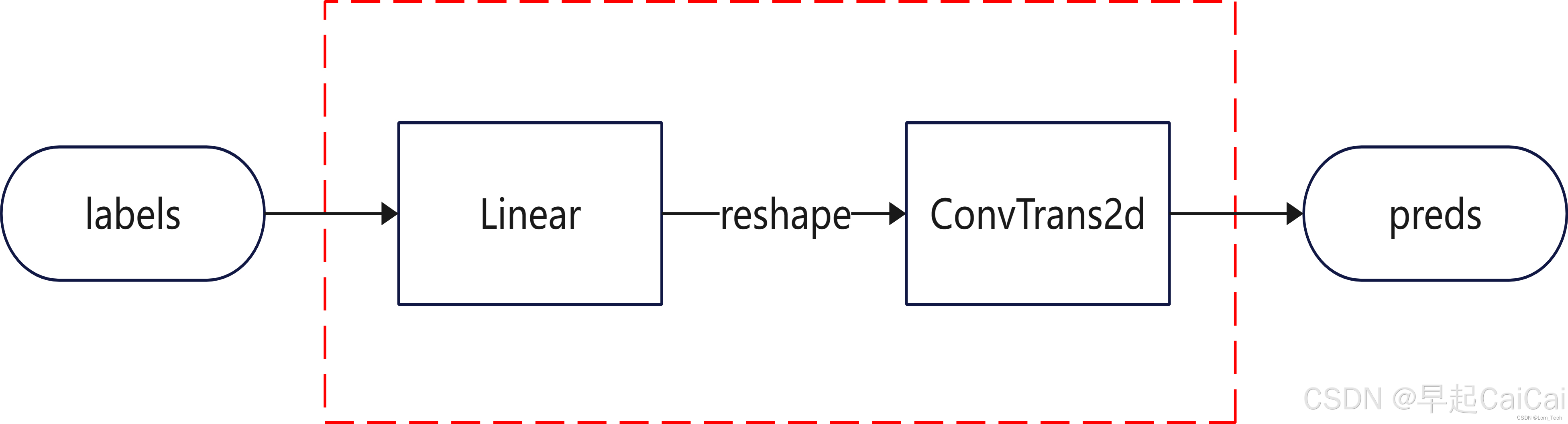
label 是标签;preds为图像
其中labels为数字的对应标签,通过embedding先转换为特征向量(这里的embedding可以使用最简单的ont_hot),然后使用Linear对特征进行提取和通道转换,最后经过reshape转换为二维后再输入进ConvTrans2d,生成最后的二维图像。
Embedding (One-Hot);把离散标签变成可计算的向量,且不引入虚假的数值大小关系。
为了对模型进行训练,我们使用对应的图像和preds输出基于MSE计算损失(最直观的损失计算方法,但存在弊端),同时为了提高生成图像的随机性,我们在输入端加入了随机latent,与labels的embedding向量进行拼接。因此,最终的模型pipeline如下:
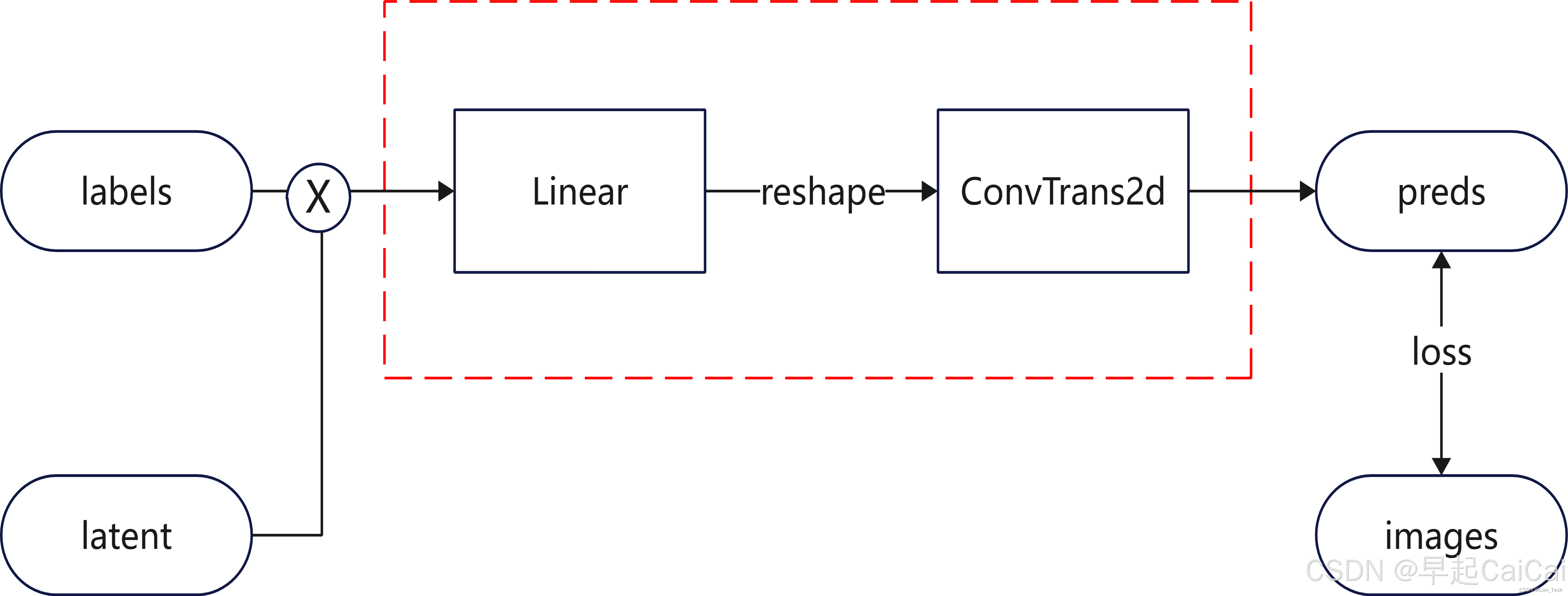
latent:潜在向量(随机噪声),比如从高斯分布采样的 100 维向量 0.23, -0.15, ...。这是随机种子,决定生成图像的细节变化(如笔迹粗细、倾斜角度)。
2. 代码实现
OK,接下来我们就用pytorch来实现以上工作流。
2.1 模型
首先我们实现DNN网络,变量概念和基本流程都已经在代码中给出。需要注意的是网络的输入应该是latent和labels embedding向量拼接后的维度,输出维度是1(单通道灰度图像),网络最后需要加上Sigmoid来使输出范围在0-1之间。同时Linear的输出和ConvTrans2d的输入需要设计和匹配来实现输出的图像大小与原图大小相同。
python
class DNN(nn.Module):
def __init__(self, input_dim=100, output_dim=1, class_num=10):
'''
初始化网络
:param input_dim:输入维度,也是latent维度
:param output_dim:输出维度,表示最终生成图片的通道数
:param class_num:图像种类,代表condition种类
'''
super(DNN, self).__init__()
# 网络的输入是latent的维度拼接上condition向量的维度
self.input_dim = input_dim + class_num
self.output_dim = output_dim
self.fc = nn.Sequential(
nn.Linear(self.input_dim, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * 7 * 7),
nn.BatchNorm1d(128 * 7 * 7),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Sigmoid(),
)
def forward(self, input):
x = self.fc(input)
x = x.view(-1, 128, 7, 7)
x = self.deconv(x)
return x
2.2 数据集
数据集直接从torchvision调用现成的MNIST数据集函数,并且通过dataloader进行包装。
python
def init_dataloader(self):
'''
初始化数据集和dataloader
'''
tf = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = MNIST('../datasets/mnist',
train=True,
download=True,
transform=tf)
self.train_dataloader = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True, drop_last=True)
val_dataset = MNIST('../datasets/mnist',
train=False,
download=True,
transform=tf)
self.val_dataloader = DataLoader(val_dataset, batch_size=self.batch_size, shuffle=False)
self.output_dim = self.train_dataloader.__iter__().__next__()[0].shape[1]2.3 训练
训练pipeline也是一个正常流程,将labels进行one_hot编码后与latent进行拼接输入网络,然后再将网络输出与原图计算损失
python
def train(self):
self.model.train()
print('训练开始!!')
for epoch in range(self.epoch):
self.model.train()
loss_mean = 0
for i, (images, labels) in enumerate(self.train_dataloader):
# 生成对应batch和维度的latent
z = torch.rand((self.batch_size, self.z_dim)).to(self.device)
images, labels = images.to(self.device), labels.to(self.device)
# 将原始label做one hot后作为condition向量
labels = F.one_hot(labels, num_classes=10)
self.optimizer.zero_grad()
# 将latent和condition拼接后输入网络
generated_images = self.model(torch.cat((z, labels), dim=1))
loss = self.loss(generated_images, images)
loss_mean += loss.item()
loss.backward()
self.optimizer.step()
train_loss = loss_mean / len(self.train_dataloader)
val_loss = self.evaluation()
print('epoch:{}, training loss:{:.4f}, validation loss:{:.4f}'.format(epoch, train_loss, val_loss))
self.visualize_results(epoch)2.4 推理&可视化
最后我们使用训练好的模型进行推理和可视化。我们随机生成100个sample,然后10个类别每个类别分别占10个sample。最后生成的结果如下:
python
@torch.no_grad()
def visualize_results(self, epoch):
self.model.eval()
# 保存结果路径
output_path = 'results/DNN'
if not os.path.exists(output_path):
os.makedirs(output_path)
tot_num_samples = self.sample_num
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
z = torch.rand((tot_num_samples, self.z_dim)).to(self.device)
# 生成对应sample个condition向量,每十个sample为一类
labels = F.one_hot(torch.Tensor(np.repeat(np.arange(10), 10)).to(torch.int64), num_classes=10).to(self.device)
generated_images = self.model(torch.cat((z, labels), dim=1))
save_image(generated_images, os.path.join(output_path, '{}.jpg'.format(epoch)), nrow=image_frame_dim)这样的话每个类别都会生成对应的图片,但是有没有发现一个问题?就是每个生成的图片长得太像了。
我个人的理解而言,由于MSE损失计算的是基于像素间的差别,所以生成的图像只会与大部分的典型的图像相似,就算加入了随机latent,在模型不断的收敛过程中latent部分的输出会尽可能接近0,来保证输出结果对典型部分数据的相似性。所以说才会造成不同随机latent的生成图像都很相似的情况。

完整代码如下:
python
import torch, time, os
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import torch.nn.functional as F
class DNN(nn.Module):
def __init__(self, input_dim=100, output_dim=1, class_num=10):
'''
初始化网络
:param input_dim:输入维度,也是latent维度
:param output_dim:输出维度,表示最终生成图片的通道数
:param class_num:图像种类,代表condition种类
'''
super(DNN, self).__init__()
# 网络的输入是latent的维度拼接上condition向量的维度
self.input_dim = input_dim + class_num
self.output_dim = output_dim
self.fc = nn.Sequential(
nn.Linear(self.input_dim, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * 7 * 7),
nn.BatchNorm1d(128 * 7 * 7),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Sigmoid(),
)
def forward(self, input):
x = self.fc(input)
x = x.view(-1, 128, 7, 7)
x = self.deconv(x)
return x
class ImageGenerator(object):
def __init__(self):
'''
初始化,定义超参数、数据集、网络结构等
'''
self.epoch = 5
self.sample_num = 100
self.batch_size = 64
self.z_dim = 62
self.lr = 0.0001
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.init_dataloader()
self.model = DNN(input_dim=self.z_dim, output_dim=self.output_dim).to(self.device)
self.optimizer = optim.Adam(self.model.parameters(), lr=self.lr)
self.loss = nn.MSELoss().to(self.device)
def init_dataloader(self):
'''
初始化数据集和dataloader
'''
tf = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = MNIST('../datasets/mnist',
train=True,
download=True,
transform=tf)
self.train_dataloader = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True, drop_last=True)
val_dataset = MNIST('../datasets/mnist',
train=False,
download=True,
transform=tf)
self.val_dataloader = DataLoader(val_dataset, batch_size=self.batch_size, shuffle=False)
self.output_dim = self.train_dataloader.__iter__().__next__()[0].shape[1]
def train(self):
self.model.train()
print('训练开始!!')
for epoch in range(self.epoch):
self.model.train()
loss_mean = 0
for i, (images, labels) in enumerate(self.train_dataloader):
# 生成对应batch和维度的latent
z = torch.rand((self.batch_size, self.z_dim)).to(self.device)
images, labels = images.to(self.device), labels.to(self.device)
# 将原始label做one hot后作为condition向量
labels = F.one_hot(labels, num_classes=10)
self.optimizer.zero_grad()
# 将latent和condition拼接后输入网络
generated_images = self.model(torch.cat((z, labels), dim=1))
loss = self.loss(generated_images, images)
loss_mean += loss.item()
loss.backward()
self.optimizer.step()
train_loss = loss_mean / len(self.train_dataloader)
val_loss = self.evaluation()
print('epoch:{}, training loss:{:.4f}, validation loss:{:.4f}'.format(epoch, train_loss, val_loss))
self.visualize_results(epoch)
@torch.no_grad()
def evaluation(self):
self.model.eval()
loss_mean = 0
for i, (images, labels) in enumerate(self.val_dataloader):
# 生成对应image batch和维度的latent
z = torch.rand((images.shape[0], self.z_dim)).to(self.device)
images, labels = images.to(self.device), labels.to(self.device)
# 将原始label做one hot后作为condition向量
labels = F.one_hot(labels, num_classes=10)
# 将latent和condition拼接后输入网络
generated_images = self.model(torch.cat((z, labels), dim=1))
loss = self.loss(generated_images, images)
loss_mean += loss.item()
return loss_mean / len(self.val_dataloader)
@torch.no_grad()
def visualize_results(self, epoch):
self.model.eval()
# 保存结果路径
output_path = 'results/DNN'
if not os.path.exists(output_path):
os.makedirs(output_path)
tot_num_samples = self.sample_num
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
z = torch.rand((tot_num_samples, self.z_dim)).to(self.device)
# 生成对应sample个condition向量,每十个sample为一类
labels = F.one_hot(torch.Tensor(np.repeat(np.arange(10), 10)).to(torch.int64), num_classes=10).to(self.device)
generated_images = self.model(torch.cat((z, labels), dim=1))
save_image(generated_images, os.path.join(output_path, '{}.jpg'.format(epoch)), nrow=image_frame_dim)
if __name__ == '__main__':
generator = ImageGenerator()
generator.train()OK我们知道了朴素DNN在【图像生成】这块并不好用,接下来将会介绍GAN是如何改进这个问题
3 GAN 基本思路
之前DNN的最大问题在于损失计算方法,如果用MSE计算loss的话生成图片将会失去随机性。那么有没有一种损失计算方法,又可以去确保生成图像的真实性,又可以确保生成图像的随机性呢?
GAN提出了这样一种方法,还是用之前的DNN来生成图像(生成器),然后让另外一个额外的DNN网络输入图片(判别器),去判断这张图片是否是真实的还是生成的(输出概率)。
怎么训练生成器和判别器可以使得生成器生成和真实图像相似的虚假图像呢?判别器的训练很好理解,把真实和虚假图像输入去训练就可以,但生成器的训练很难实现,因为它本身的输出(图像)没法与标签直接产生联系,而是需要输入进判别器后得到一个反馈才行。所以生成器的训练会很大程度上受到判别器的制约,这也是为什么GAN训练不稳定的原因。
根据以上不严谨的理解,我们可以大致得到一个工作流:
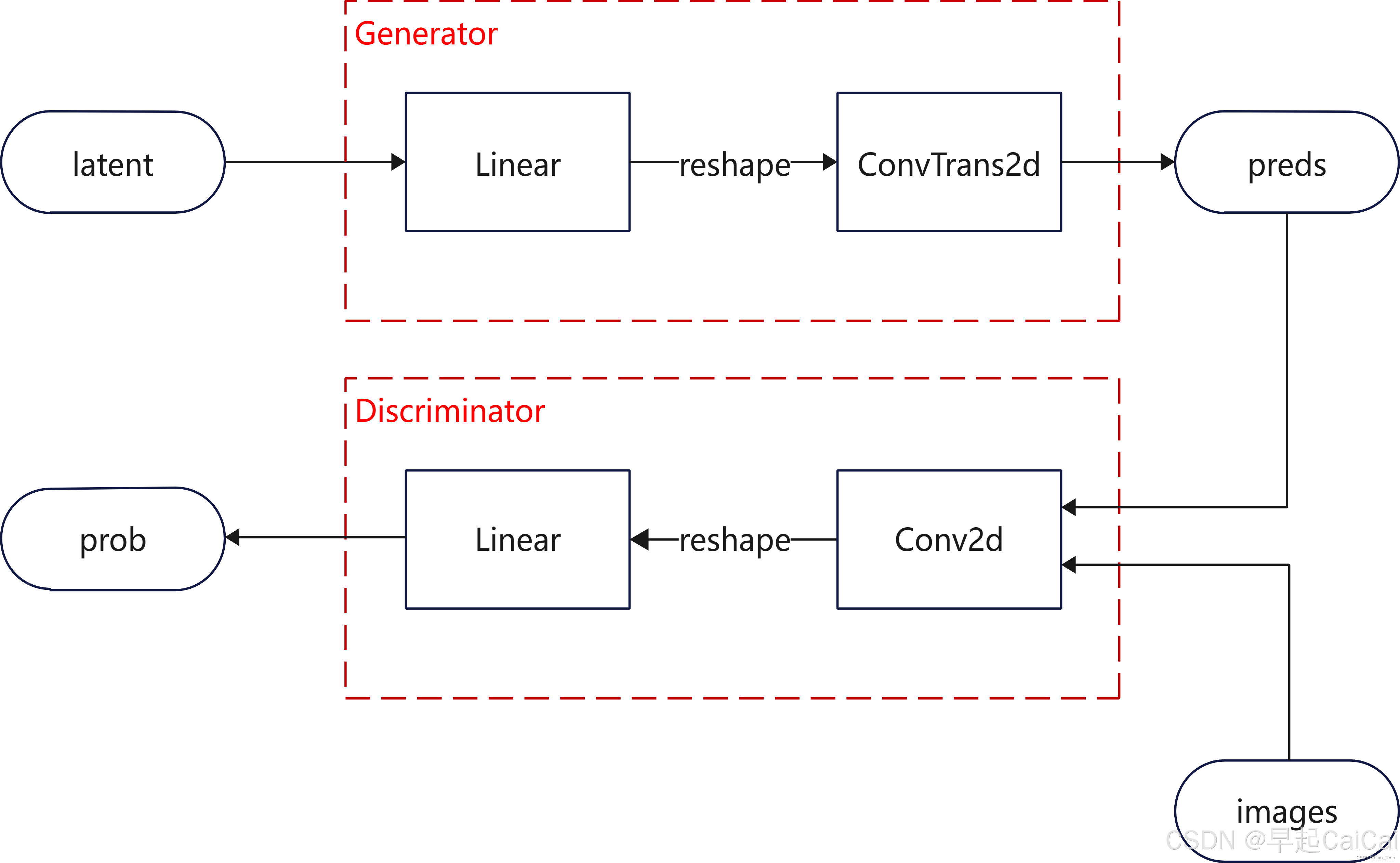
用什么loss训练呢?这个还是需要严谨的推导。


4. 代码实现
OK,接下来我们就用pytorch来实现GAN在MNIST数据集上的生成。需要注意的是数据集和推理 部分和之前DNN的没有区别,因此不再着重描述,主要对模型和训练方法上进行说明。
4.1 模型
我们在之前只有Generator的基础上加上了Discriminator(判别器),两个模型都采用了简单的全连接层和卷积层/反卷积层结构。
python
class Generator(nn.Module):
def __init__(self, input_dim=100, output_dim=1, class_num=10):
'''
初始化生成网络
:param input_dim:输入维度,也是latent维度
:param output_dim:输出维度,表示最终生成图片的通道数
:param class_num:图像种类,代表condition种类
'''
super(Generator, self).__init__()
# 网络的输入是latent的维度拼接上condition向量的维度
self.input_dim = input_dim + class_num
self.output_dim = output_dim
self.fc = nn.Sequential(
nn.Linear(self.input_dim, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * 7 * 7),
nn.BatchNorm1d(128 * 7 * 7),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Tanh(),
)
def forward(self, input):
x = self.fc(input)
x = x.view(-1, 128, 7, 7)
x = self.deconv(x)
return x
class Discriminator(nn.Module):
def __init__(self, input_dim=1, output_dim=1):
'''
初始化判别网络
:param input_dim:输入通道数
:param output_dim:输出通道数
'''
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.output_dim),
nn.Sigmoid(),
)
def forward(self, input):
x = self.conv(input)
x = x.view(-1, 128 * 7 * 7)
x = self.fc(x)
return x4.2 训练
训练时对D和G分别更新,对D更新需要计算
python
def train(self):
print('训练开始!!')
for epoch in range(self.epoch):
self.G.train()
self.D.train()
loss_mean_G = 0
loss_mean_D = 0
for i, (images, labels) in enumerate(self.train_dataloader):
# 生成对应batch和维度的latent
z = torch.rand((self.batch_size, self.z_dim)).to(self.device)
images, labels = images.to(self.device), labels.to(self.device)
### 更新D ###
self.optimizerD.zero_grad()
# 真实图像输入D
D_real = self.D(images)
D_real_loss = self.loss(D_real, self.y_real)
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
D_fake_loss = self.loss(D_fake, self.y_fake)
# 整合并更新
D_loss = D_real_loss + D_fake_loss
D_loss.backward()
self.optimizerD.step()
loss_mean_D += D_loss.item()
### 更新G ###
self.optimizerG.zero_grad()
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# G想要D认为虚假图像是真的,所以与y_real做loss
G_loss = self.loss(D_fake, self.y_real)
# 更新
G_loss.backward()
self.optimizerG.step()
loss_mean_G += G_loss.item()
train_loss_G = loss_mean_G / len(self.train_dataloader)
train_loss_D = loss_mean_D / len(self.train_dataloader)
print('epoch:{}, training loss G:{:.4f}, loss D:{:.4f}'.format(
epoch, train_loss_G,train_loss_D))
self.visualize_results(epoch)4.3 推理&可视化
最后我们使用训练好的模型进行推理和可视化。噪声我们使用了固定的随机噪声,最后生成的结果如下:
可以看到结果并不好,训练的时候G的loss也在不断上升,这就是GAN训练不稳定造成的。
5. Wasserstein改进及代码实现

5.1 判别器
这里把判别器最后一层的Sigmoid去掉,意味着我们不再把输出范围限制在0-1,而是负无穷到正无穷。越接近正无穷表示输入图像越真实,越接近负无穷表示输入图像越虚假。
python
class Discriminator(nn.Module):
def __init__(self, input_dim=1, output_dim=1):
'''
初始化判别网络
:param input_dim:输入通道数
:param output_dim:输出通道数
'''
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.output_dim),
# nn.Sigmoid(),
)
def forward(self, input):
x = self.conv(input)
x = x.view(-1, 128 * 7 * 7)
x = self.fc(x)
return x5.2 loss
由于判别器的输出范围改变,我们也改变了loss的计算方式,用单纯的输出大小来表示loss,从而满足越接近正无穷表示输入图像越真实,越接近负无穷表示输入图像越虚假的条件。
python
### 判别器更新 ###
# 真实图像输入D
D_real = self.D(images)
# 想要真实图像的D输出尽可能大
D_real_loss = -torch.mean(D_real)
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# 想要虚假图像的D输出尽可能小
D_fake_loss = torch.mean(D_fake)
python
### 生成器更新 ###
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# 想要虚假图像的D输出尽可能大
G_loss = -torch.mean(D_fake)5.3 参数截断
在训练 GAN 时,尤其是早期使用 WGAN(Wasserstein GAN) 及其改进版 WGAN-GP 之前,原始 WGAN 为了强制满足"Lipschitz 连续性"(一种数学约束,为了保证训练稳定),采用了一种非常简单粗暴的方法:每次更新完判别器(Discriminator)的梯度后,直接把它的所有参数值裁剪(Clamp)到一个极小的区间内,比如 -0.01, 0.01。
按照论文设置的c=0.01对判别器参数进行截断
python
for p in self.D.parameters():
p.data.clamp_(-self.c, self.c)5.4 判别器
把优化器从"带动量"的版本(如 Adam、SGD with Momentum)换成"不带动量"的版本(如纯 SGD),意味着模型在更新参数时,不再参考历史梯度的方向,只根据当前这一批数据的梯度来决定怎么走。
优化器改为非动量优化器
python
self.optimizerG = optim.RMSprop(self.G.parameters(), lr=self.lr)
self.optimizerD = optim.RMSprop(self.D.parameters(), lr=self.lr)5.5 完整代码及结果
以下是完整的Wasserstein GAN代码及结果:
python
import torch, time, os
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import torch.nn.functional as F
class Generator(nn.Module):
def __init__(self, input_dim=100, output_dim=1, class_num=10):
'''
初始化生成网络
:param input_dim:输入维度,也是latent维度
:param output_dim:输出维度,表示最终生成图片的通道数
:param class_num:图像种类,代表condition种类
'''
super(Generator, self).__init__()
# 网络的输入是latent的维度拼接上condition向量的维度
self.input_dim = input_dim + class_num
self.output_dim = output_dim
self.fc = nn.Sequential(
nn.Linear(self.input_dim, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * 7 * 7),
nn.BatchNorm1d(128 * 7 * 7),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Tanh(),
)
def forward(self, input):
x = self.fc(input)
x = x.view(-1, 128, 7, 7)
x = self.deconv(x)
return x
class Discriminator(nn.Module):
def __init__(self, input_dim=1, output_dim=1):
'''
初始化判别网络
:param input_dim:输入通道数
:param output_dim:输出通道数
'''
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.output_dim),
# nn.Sigmoid(),
)
def forward(self, input):
x = self.conv(input)
x = x.view(-1, 128 * 7 * 7)
x = self.fc(x)
return x
class ImageGenerator(object):
def __init__(self):
'''
初始化,定义超参数、数据集、网络结构等
'''
self.epoch = 50
self.sample_num = 100
self.batch_size = 64
self.z_dim = 100
self.lr = 0.0002
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.init_dataloader()
self.G = Generator(input_dim=self.z_dim, output_dim=self.output_dim, class_num=0).to(self.device)
self.D = Discriminator(input_dim=self.output_dim, output_dim=1).to(self.device)
self.initialize_weights(self.G)
self.initialize_weights(self.D)
self.optimizerG = optim.RMSprop(self.G.parameters(), lr=self.lr)
self.optimizerD = optim.RMSprop(self.D.parameters(), lr=self.lr)
self.c = 0.01
self.n_critic = 5
self.fixed_z = torch.rand((self.sample_num, self.z_dim)).to(self.device)
def initialize_weights(self, net):
for m in net.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.ConvTranspose2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
def init_dataloader(self):
'''
初始化数据集和dataloader
'''
tf = transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = MNIST('../datasets/mnist',
train=True,
download=True,
transform=tf)
self.train_dataloader = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True, drop_last=True)
val_dataset = MNIST('../datasets/mnist',
train=False,
download=True,
transform=tf)
self.val_dataloader = DataLoader(val_dataset, batch_size=self.batch_size, shuffle=False, drop_last=True)
self.output_dim = self.train_dataloader.__iter__().__next__()[0].shape[1]
def train(self):
print('训练开始!!')
for epoch in range(self.epoch):
self.G.train()
self.D.train()
loss_mean_G = 0
loss_mean_D = 0
for i, (images, labels) in enumerate(self.train_dataloader):
# 生成对应batch和维度的latent
z = torch.rand((self.batch_size, self.z_dim)).to(self.device)
images, labels = images.to(self.device), labels.to(self.device)
### 更新D ###
self.optimizerD.zero_grad()
# 真实图像输入D
D_real = self.D(images)
# 想要真实图像的D输出尽可能大
D_real_loss = -torch.mean(D_real)
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# 想要虚假图像的D输出尽可能小
D_fake_loss = torch.mean(D_fake)
# 整合并更新
D_loss = D_real_loss + D_fake_loss
D_loss.backward()
self.optimizerD.step()
loss_mean_D += D_loss.item()
# 截断
for p in self.D.parameters():
p.data.clamp_(-self.c, self.c)
### 更新G ###
# 每隔一定间隔再更新G
if (i+1) % self.n_critic == 0:
self.optimizerG.zero_grad()
# 虚假图像输入D
images_fake = self.G(z)
D_fake = self.D(images_fake)
# 想要虚假图像的D输出尽可能大
G_loss = -torch.mean(D_fake)
# 更新
G_loss.backward()
self.optimizerG.step()
loss_mean_G += G_loss.item()
train_loss_G = loss_mean_G / len(self.train_dataloader) * self.n_critic
train_loss_D = loss_mean_D / len(self.train_dataloader)
print('epoch:{}, training loss G:{:.4f}, loss D:{:.4f}'.format(
epoch, train_loss_G,train_loss_D))
self.visualize_results(epoch)
@torch.no_grad()
def visualize_results(self, epoch):
self.G.eval()
# 保存结果路径
output_path = 'results/GAN'
if not os.path.exists(output_path):
os.makedirs(output_path)
tot_num_samples = self.sample_num
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
z = self.fixed_z
generated_images = self.G(z)
# generated_images = (generated_images + 1) / 2
save_image(generated_images, os.path.join(output_path, '{}.jpg'.format(epoch)), nrow=image_frame_dim)
if __name__ == '__main__':
generator = ImageGenerator()
generator.train()
如果训练正常,那么G的loss会是正数,并随着训练不断接近于0,D的loss会是负数,也不断接近于0。这表示判别器越来越分不清生成器生成的虚假图像和真实图像,也就是两个分布越来越接近。
需要注意的是,我们最后没有采用将输出结果(x+1)/2的操作。之所以有这个操作是因为tanh的输出范围是-1到1,所以最终可视化的时候需要将范围调整到0到1,但是经过尝试之后发现调整至0到1之后图像会发白。我分析可能是对真实图像预处理时是将范围调整至0到1而不是-1到1,因此训练使得两个概率分布相似,导致生成器输出的范围也是0到1。
5.5 condition代码及结果
如果我们要生成condition条件下的图像,那么我们按照上一篇DNN的做法,直接把labels进行热编码后与网络输入拼接。注意的是不光生成器,判别器也需要拼接。完整的代码和结果如下:
python
import torch, time, os
import numpy as np
import torch.nn as nn
import torch.optim as optim
from torchvision.datasets import MNIST
from torchvision import transforms
from torch.utils.data import DataLoader
from torchvision.utils import save_image
import torch.nn.functional as F
class Generator(nn.Module):
def __init__(self, input_dim=100, output_dim=1, class_num=10):
'''
初始化生成网络
:param input_dim:输入维度,也是latent维度
:param output_dim:输出维度,表示最终生成图片的通道数
:param class_num:图像种类,代表condition种类
'''
super(Generator, self).__init__()
# 网络的输入是latent的维度拼接上condition向量的维度
self.input_dim = input_dim + class_num
self.output_dim = output_dim
self.fc = nn.Sequential(
nn.Linear(self.input_dim, 1024),
nn.BatchNorm1d(1024),
nn.ReLU(),
nn.Linear(1024, 128 * 7 * 7),
nn.BatchNorm1d(128 * 7 * 7),
nn.ReLU(),
)
self.deconv = nn.Sequential(
nn.ConvTranspose2d(128, 64, 4, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.ConvTranspose2d(64, self.output_dim, 4, 2, 1),
nn.Tanh(),
)
def forward(self, input, labels):
x = torch.cat((input, labels), dim=1)
x = self.fc(x)
x = x.view(-1, 128, 7, 7)
x = self.deconv(x)
return x
class Discriminator(nn.Module):
def __init__(self, input_dim=1, output_dim=1, class_num=10):
'''
初始化判别网络
:param input_dim:输入通道数
:param output_dim:输出通道数
'''
super(Discriminator, self).__init__()
self.input_dim = input_dim
self.output_dim = output_dim
self.conv = nn.Sequential(
nn.Conv2d(self.input_dim, 64, 4, 2, 1),
nn.LeakyReLU(0.2),
nn.Conv2d(64, 128, 4, 2, 1),
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2),
)
self.fc = nn.Sequential(
nn.Linear(128 * 7 * 7 + class_num, 1024),
nn.BatchNorm1d(1024),
nn.LeakyReLU(0.2),
nn.Linear(1024, self.output_dim),
# nn.Sigmoid(),
)
def forward(self, input, labels):
x = self.conv(input)
x = x.view(-1, 128 * 7 * 7)
x = torch.cat((x, labels), dim=1)
x = self.fc(x)
return x
class ImageGenerator(object):
def __init__(self):
'''
初始化,定义超参数、数据集、网络结构等
'''
self.epoch = 50
self.sample_num = 100
self.batch_size = 64
self.z_dim = 100
self.lr = 0.0002
self.device = 'cuda' if torch.cuda.is_available() else 'cpu'
self.init_dataloader()
self.G = Generator(input_dim=self.z_dim, output_dim=self.output_dim, class_num=10).to(self.device)
self.D = Discriminator(input_dim=self.output_dim, output_dim=1, class_num=10).to(self.device)
self.initialize_weights(self.G)
self.initialize_weights(self.D)
self.optimizerG = optim.RMSprop(self.G.parameters(), lr=self.lr)
self.optimizerD = optim.RMSprop(self.D.parameters(), lr=self.lr)
self.c = 0.01
self.n_critic = 5
self.fixed_z = torch.rand((self.sample_num, self.z_dim)).to(self.device)
def initialize_weights(self, net):
for m in net.modules():
if isinstance(m, nn.Conv2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.ConvTranspose2d):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.02)
m.bias.data.zero_()
def init_dataloader(self):
'''
初始化数据集和dataloader
'''
tf = transforms.Compose([
transforms.ToTensor(),
# transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = MNIST('./data/',
train=True,
download=True,
transform=tf)
self.train_dataloader = DataLoader(train_dataset, batch_size=self.batch_size, shuffle=True, drop_last=True)
val_dataset = MNIST('./data/',
train=False,
download=True,
transform=tf)
self.val_dataloader = DataLoader(val_dataset, batch_size=self.batch_size, shuffle=False, drop_last=True)
self.output_dim = self.train_dataloader.__iter__().__next__()[0].shape[1]
def train(self):
print('训练开始!!')
for epoch in range(self.epoch):
self.G.train()
self.D.train()
loss_mean_G = 0
loss_mean_D = 0
for i, (images, labels) in enumerate(self.train_dataloader):
# 生成对应batch和维度的latent
z = torch.rand((self.batch_size, self.z_dim)).to(self.device)
images, labels = images.to(self.device), labels.to(self.device)
labels = F.one_hot(labels, num_classes=10)
### 更新D ###
self.optimizerD.zero_grad()
# 真实图像输入D
D_real = self.D(images, labels)
# 想要真实图像的D输出尽可能大
D_real_loss = -torch.mean(D_real)
# 虚假图像输入D
images_fake = self.G(z, labels)
D_fake = self.D(images_fake, labels)
# 想要虚假图像的D输出尽可能小
D_fake_loss = torch.mean(D_fake)
# 整合并更新
D_loss = D_real_loss + D_fake_loss
D_loss.backward()
self.optimizerD.step()
loss_mean_D += D_loss.item()
# 截断
for p in self.D.parameters():
p.data.clamp_(-self.c, self.c)
### 更新G ###
# 每隔一定间隔再更新G
if (i+1) % self.n_critic == 0:
self.optimizerG.zero_grad()
# 虚假图像输入D
images_fake = self.G(z, labels)
D_fake = self.D(images_fake, labels)
# 想要虚假图像的D输出尽可能大
G_loss = -torch.mean(D_fake)
# 更新
G_loss.backward()
self.optimizerG.step()
loss_mean_G += G_loss.item()
train_loss_G = loss_mean_G / len(self.train_dataloader) * self.n_critic
train_loss_D = loss_mean_D / len(self.train_dataloader)
print('epoch:{}, training loss G:{:.4f}, loss D:{:.4f}'.format(
epoch, train_loss_G,train_loss_D))
self.visualize_results(epoch)
@torch.no_grad()
def visualize_results(self, epoch):
self.G.eval()
# 保存结果路径
output_path = 'results/GAN'
if not os.path.exists(output_path):
os.makedirs(output_path)
tot_num_samples = self.sample_num
image_frame_dim = int(np.floor(np.sqrt(tot_num_samples)))
z = self.fixed_z
labels = F.one_hot(torch.Tensor(np.repeat(np.arange(10), 10)).to(torch.int64), num_classes=10).to(self.device)
generated_images = self.G(z, labels)
save_image(generated_images, os.path.join(output_path, '{}.jpg'.format(epoch)), nrow=image_frame_dim)
if __name__ == '__main__':
generator = ImageGenerator()
generator.train()