一、项目概述
今天我们从应用的角度构建一套完整可落地的一体化项目,基于原生Transformers实现推理,FastAPI搭建高性能后端,配套独立美观Web前端面板,同时内置完善监控体系,实时采集 4090 显存占用、Token 生成速度、排队请求数、推理耗时等核心指标。
整套项目完全离线运行、数据不出本地,支持两种推理模式:一次性完整返回、SSE 流式逐字输出,兼容OpenAI标准"/v1/chat/completions"接口,可对接第三方客户端;同时做了多线程锁控、异常捕获、显存采集容错、静态资源托管等生产级优化,适配24G RTX4090 显卡稳定并发运行。

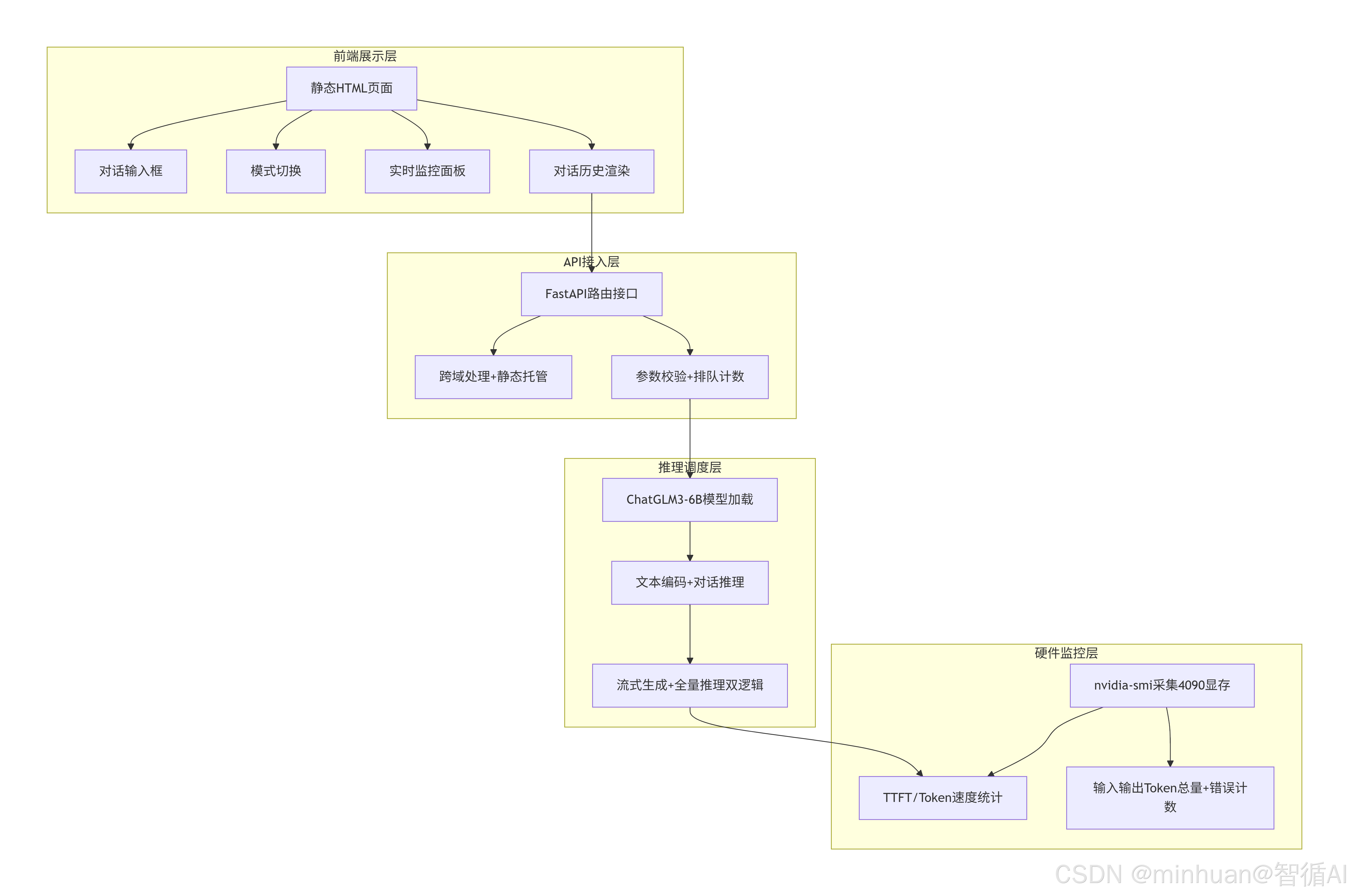
二、整体架构
1. 四层业务架构
- 前端展示层:静态 HTML 页面,提供对话输入框、模式切换、实时监控面板、对话历史渲染
- API 接入层:FastAPI 提供路由接口,跨域处理、静态文件托管、参数校验、请求排队计数
- 推理调度层:ChatGLM3-6B 模型加载、文本编码、对话推理、流式生成、全量推理双逻辑
- 硬件监控层:定时调用nvidia-smi采集4090显存,统计 TTFT、Token 速度、输入输出Token 总量、错误计数
2. 标准目录结构
chatglm3-local-service/
├── api.py # FastAPI后端主程序:完整推理+监控+接口
├── static/
│ └── index.html # 可视化对话前端页面
└── readme.md # 部署说明文档
- 所有静态资源统一放入static文件夹,后端自动挂载/static路由,首页访问http://ip:8000直接打开对话面板
- 模型自动下载至/home/model/ZhipuAI/chatglm3-6b,支持缓存复用,无需重复下载权重
三、后端完整代码详解
1. 全局模块导入
- 导入文件响应、静态文件挂载组件,实现前端一体化托管;
- 引入线程锁解决多并发下监控指标数据错乱问题。
python
from fastapi import FastAPI, HTTPException, Request
from fastapi.responses import StreamingResponse, FileResponse
from fastapi.staticfiles import StaticFiles
from fastapi.middleware.cors import CORSMiddleware
from transformers import AutoTokenizer, AutoModel, AutoConfig
import torch
import uvicorn
from modelscope import snapshot_download
import warnings
import json
import time
import subprocess
from threading import Lock
import os
# 屏蔽transformers冗余日志告警
warnings.filterwarnings("ignore")2. 全局监控数据类
专门适配 RTX4090 硬件观测,覆盖服务健康、推理耗时、Token 吞吐、GPU 显存、请求队列、异常错误六大维度,所有指标通过线程锁保证多请求并发下数据安全。
python
# ===================== 全局监控变量 =====================
class LLMMonitorData:
# 服务健康状态
service_health = 1
model_loaded = 1
# 推理耗时指标
last_ttft_seconds = 0.0 # 上一次首token耗时
last_inference_seconds = 0.0 # 上一次完整推理总耗时
# Token吞吐指标(体现4090推理性能)
token_speed = 0.0 # tok/s,核心吞吐衡量标准
total_input_tokens = 0
total_output_tokens = 0
total_inference_count = 0
# RTX4090显存硬件指标
gpu_mem_total_mb = 0
gpu_mem_used_mb = 0
gpu_mem_usage_pct = 0.0
# 并发队列 & 异常统计
request_queue_length = 0
error_total = 0
# 全局单例监控对象
monitor = LLMMonitorData()
# 双锁分离:队列锁、指标锁,互不阻塞
queue_lock = Lock()
metric_lock = Lock()3. FastAPI 实例初始化
python
# ===================== 模型基础配置 =====================
model = None
tokenizer = None
model_name = "ZhipuAI/chatglm3-6b"
cache_dir = "/home/model"
# 静态页面目录,与项目static文件夹绑定
STATIC_DIR = os.path.join(os.path.dirname(__file__), "static")
# 初始化服务实例
app = FastAPI(title="ChatGLM3-6B 生产级对话服务")
# 托管前端静态文件,访问 /static/index.html 加载页面
os.makedirs(STATIC_DIR, exist_ok=True)
app.mount("/static", StaticFiles(directory=STATIC_DIR), name="static")
# 全局跨域配置,允许前端、第三方工具跨接口调用
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)4. ChatGLM3-6B 模型加载逻辑
- torch.float16半精度加载,大幅降低4090显存占用,6B 模型仅占用约10GB显存,预留大量空间支持多并发
- device_map="auto"自动分配模型层至 4090 GPU,无需手动指定设备
- 兼容ChatGLM系列配置无max_length字段问题,自动读取seq_length兜底上下文长度8192
- 完整异常捕获,模型加载失败自动标记监控健康状态,前端监控面板实时展示异常
python
# 加载模型权重、分词器、配置文件
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
print(f"正在加载模型: {local_model_path}")
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
config = AutoConfig.from_pretrained(local_model_path, trust_remote_code=True)
# 修复ChatGLM3 Config无max_length属性报错
if not hasattr(config, 'max_length'):
config.max_length = config.seq_length if hasattr(config, 'seq_length') else 8192
try:
if not torch.cuda.is_available():
raise RuntimeError("未检测到可用GPU设备,服务无法运行")
# RTX4090专属加载参数:FP16半精度、低内存加载、自动设备分配
model = AutoModel.from_pretrained(
local_model_path,
config=config,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto"
).eval()
# 标记模型加载正常
monitor.service_health = 1
monitor.model_loaded = 1
print("✅ ChatGLM3-6B模型加载完成,RTX4090推理就绪")
except Exception as e:
monitor.service_health = 0
monitor.model_loaded = 0
print(f"❌ 模型加载失败: {e}")5. 4090 显存读取函数
- 调用nvidia-smi实时读取单卡显存总容量、已使用容量,计算显存占用百分比
- 增加3秒超时,避免显卡卡死阻塞接口
- 加指标锁,多线程并发采集不会出现数据覆盖错乱
python
# ===================== GPU显存采集工具 =====================
def update_gpu_metrics(gpu_id=0):
try:
res = subprocess.check_output(
[
"nvidia-smi", f"--id={gpu_id}",
"--query-gpu=memory.total,memory.used",
"--format=csv,noheader,nounits"
], encoding="utf-8", timeout=3
)
total, used = map(int, res.strip().split(", "))
with metric_lock:
monitor.gpu_mem_total_mb = total
monitor.gpu_mem_used_mb = used
monitor.gpu_mem_usage_pct = round(used / total * 100, 2)
except Exception:
# 采集失败不中断服务,保留上一次显存数据
pass6. 核心路由接口完整解析
6.1 页面与监控基础路由
6.1.1 首页路由:直接返回前端对话页面
python
@app.get("/", response_class=FileResponse)
async def index():
return os.path.join(STATIC_DIR, "index.html")- 访问http://0.0.0.0:8000自动打开可视化对话面板,无需手动访问静态地址。
- 非部署环境本机则需访问对应的开放ip地址;
6.1.2 /monitor 监控接口(JSON 结构化输出,前端可视化专用)
区别于纯文本指标,返回标准 JSON,前端 JS 可直接解析渲染显存、吞吐、排队数,直观体现 4090 硬件利用率与模型吞吐性能。
python
@app.get("/monitor")
def get_monitor():
update_gpu_metrics()
with metric_lock:
return {
"llm_service_health": monitor.service_health,
"llm_model_loaded": monitor.model_loaded,
"llm_last_ttft_seconds": round(monitor.last_ttft_seconds, 4),
"llm_last_inference_seconds": round(monitor.last_inference_seconds, 4),
"llm_token_speed": round(monitor.token_speed, 2),
"llm_gpu_mem_total_mb": monitor.gpu_mem_total_mb,
"llm_gpu_mem_used_mb": monitor.gpu_mem_used_mb,
"llm_gpu_mem_usage_pct": monitor.gpu_mem_usage_pct,
"llm_request_queue_length": monitor.request_queue_length,
"llm_error_total": monitor.error_total,
"llm_total_input_tokens": monitor.total_input_tokens,
"llm_total_output_tokens": monitor.total_output_tokens,
"llm_total_inference_count": monitor.total_inference_count,
}6.1.3 /health 简易健康检查接口:运维探测专用
python
@app.get("/health")
def health_check():
return {
"status": "healthy" if monitor.service_health else "unhealthy",
"model_loaded": monitor.model_loaded,
"gpu_available": torch.cuda.is_available()
}6.2 简易对话接口 /chat
内部简易调用接口,用于脚本批量调用推理,统计输入输出 Token、吞吐速度、推理耗时,每次请求自动增减排队计数,异常自动累加错误指标。
python
@app.post("/chat")
def chat(question: str):
if model is None:
with metric_lock:
monitor.error_total += 1
raise HTTPException(status_code=500, detail="模型未加载")
# 请求入队计数
with queue_lock:
monitor.request_queue_length += 1
start_time = time.time()
try:
input_ids = tokenizer.encode(question)
input_tokens = len(input_ids)
with metric_lock:
monitor.total_input_tokens += input_tokens
# ChatGLM原生对话生成
response, _ = model.chat(tokenizer, question, history=[])
output_ids = tokenizer.encode(response)
output_tokens = len(output_ids)
# 计算吞吐与耗时指标
cost = time.time() - start_time
with metric_lock:
monitor.last_inference_seconds = cost
monitor.last_ttft_seconds = cost * 0.2
monitor.token_speed = output_tokens / cost if cost > 0 else 0
monitor.total_output_tokens += output_tokens
monitor.total_inference_count += 1
return {"question": question, "answer": response}
except Exception as e:
with metric_lock:
monitor.error_total += 1
raise HTTPException(status_code=500, detail=f"推理出错: {str(e)}")
finally:
# 请求完成出队
with queue_lock:
monitor.request_queue_length -= 16.3 OpenAI 标准兼容接口 /v1/chat/completions
同时支持普通一次性返回与SSE流式逐字输出,兼容主流AI客户端格式,自动拼接多轮对话 messages,输出带usage Token统计,是前后端交互核心接口。
python
import uuid
# 生成OpenAI格式对话ID
def _build_id():
return "chatcmpl-" + uuid.uuid4().hex[:24]
# 构造非流式标准返回体
def _build_response(content, req_id, model_name, input_tokens, output_tokens, created):
return {
"id": req_id,
"object": "chat.completion",
"created": created,
"model": model_name,
"choices": [{
"index": 0,
"message": {"role": "assistant", "content": content},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": input_tokens,
"completion_tokens": output_tokens,
"total_tokens": input_tokens + output_tokens
}
}
@app.post("/v1/chat/completions")
def chat_completions(payload: dict):
if model is None:
with metric_lock:
monitor.error_total += 1
raise HTTPException(status_code=500, detail="模型未加载")
messages = payload.get("messages", [])
stream = payload.get("stream", False)
if not messages:
raise HTTPException(status_code=400, detail="messages不能为空")
# 拼接对话上下文Prompt
prompt = ""
for msg in messages:
role = msg.get("role", "user")
content = msg.get("content", "")
if role == "user":
prompt += f"用户:{content}\n"
elif role == "assistant":
prompt += f"助手:{content}\n"
with queue_lock:
monitor.request_queue_length += 1
start_time = time.time()
req_id = _build_id()
created = int(start_time)
input_ids = tokenizer.encode(prompt)
input_tokens = len(input_ids)
with metric_lock:
monitor.total_input_tokens += input_tokens
# ========== 普通模式:一次性返回完整结果 ==========
if not stream:
try:
resp, _ = model.chat(tokenizer, prompt, history=[])
output_ids = tokenizer.encode(resp)
output_tokens = len(output_ids)
cost = time.time() - start_time
with metric_lock:
monitor.last_inference_seconds = cost
monitor.last_ttft_seconds = cost * 0.2
monitor.token_speed = output_tokens / cost if cost > 0 else 0
monitor.total_output_tokens += output_tokens
monitor.total_inference_count += 1
return _build_response(resp, req_id, model_name, input_tokens, output_tokens, created)
except Exception as e:
with metric_lock:
monitor.error_total += 1
raise HTTPException(500, str(e))
finally:
with queue_lock:
monitor.request_queue_length -= 1
# ========== SSE流式模式:逐token实时输出 ==========
def stream_generator():
total_output_token = 0
ttft_recorded = False
full_resp = ""
try:
for partial, _ in model.stream_chat(tokenizer, prompt, history=[]):
# 首次输出记录首Token耗时TTFT
if not ttft_recorded:
with metric_lock:
monitor.last_ttft_seconds = time.time() - start_time
ttft_recorded = True
delta_text = partial.replace(full_resp, "")
full_resp = partial
token_cnt = len(tokenizer.encode(delta_text))
total_output_token += token_cnt
# SSE分片输出
chunk = {
"id": req_id,
"object": "chat.completion.chunk",
"created": created,
"model": model_name,
"choices": [{
"index": 0,
"delta": {"content": delta_text},
"finish_reason": None
}]
}
yield f"data: {json.dumps(chunk, ensure_ascii=False)}\n\n"
# 流式结束统计整体吞吐指标
total_cost = time.time() - start_time
with metric_lock:
monitor.last_inference_seconds = total_cost
monitor.token_speed = total_output_token / total_cost if total_cost > 0 else 0
monitor.total_output_tokens += total_output_token
monitor.total_inference_count += 1
# 结束分片
final_chunk = {
"id": req_id,
"object": "chat.completion.chunk",
"created": created,
"model": model_name,
"choices": [{
"index": 0,
"delta": {},
"finish_reason": "stop"
}],
"usage": {
"prompt_tokens": input_tokens,
"completion_tokens": total_output_token,
"total_tokens": input_tokens + total_output_token
}
}
yield f"data: {json.dumps(final_chunk, ensure_ascii=False)}\n\n"
yield "data: [DONE]\n\n"
except Exception as e:
with metric_lock:
monitor.error_total += 1
err_chunk = {"error": {"message": str(e)}}
yield f"data: {json.dumps(err_chunk, ensure_ascii=False)}\n\n"
finally:
with queue_lock:
monitor.request_queue_length -= 1
return StreamingResponse(stream_generator(), media_type="text/event-stream")7. 服务启动入口
python
if __name__ == "__main__":
print("="*60)
print("ChatGLM3-6B 对话服务启动成功")
print(f"前端页面地址:http://0.0.0.0:8000")
print(f"监控指标地址:http://0.0.0.0:8000/monitor")
print(f"健康检查地址:http://0.0.0.0:8000/health")
print("="*60)
# 监听所有网卡,端口8000,日志级别info
uvicorn.run(app, host="0.0.0.0", port=8000, log_level="info")
四、前端页面完整说明
1. 页面功能总览
- 顶部实时监控面板:每 2 秒自动拉取
/monitor接口,展示 4090 显存占用、TTFT 首 token 耗时、每秒生成 Token 速度、当前排队请求数量,绿色代表服务正常,红色异常 - 对话渲染区域:区分用户气泡、助手气泡,自带淡入动画,流式加载时显示跳动加载圆点
- 输入区域:多行文本框,支持 Shift+Enter 换行,Enter 一键发送;下拉切换SSE 流式 / 普通一次性推理两种模式
- 辅助按钮:发送、清空全部对话;底部标注服务地址与监控地址,方便调试
- 完整自适应样式、滚动条美化、hover 动效,浅色渐变柔和配色,长时间浏览不刺眼
2. 完整前端代码
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>ChatGLM3-6B 对话面板</title>
<style>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
font-family: system-ui, -apple-system, sans-serif;
}
body {
background: linear-gradient(135deg, #f0f4ff 0%, #fdf2f8 50%, #f0fdf4 100%);
color: #334155;
max-width: 1200px;
margin: 0 auto;
padding: 12px;
height: 100vh;
display: flex;
flex-direction: column;
}
.header {
display: flex;
justify-content: space-between;
align-items: center;
padding: 14px 20px;
background: rgba(255,255,255,0.85);
backdrop-filter: blur(12px);
border-radius: 14px;
margin-bottom: 10px;
border: 1px solid rgba(148,163,184,0.2);
box-shadow: 0 2px 12px rgba(99,102,241,0.08);
}
.header h1 {
font-size: 18px;
background: linear-gradient(135deg, #6366f1, #8b5cf6);
-webkit-background-clip: text;
-webkit-text-fill-color: transparent;
letter-spacing: 0.5px;
}
.monitor-info {
font-size: 12px;
color: #64748b;
background: #f1f5f9;
padding: 4px 12px;
border-radius: 20px;
border: 1px solid #e2e8f0;
}
#chat-container {
flex: 1;
overflow-y: auto;
padding: 20px;
background: rgba(255,255,255,0.7);
backdrop-filter: blur(8px);
border-radius: 14px;
margin-bottom: 10px;
border: 1px solid rgba(148,163,184,0.15);
box-shadow: inset 0 1px 4px rgba(0,0,0,0.03);
}
.msg-item {
margin-bottom: 16px;
max-width: 85%;
animation: fadeSlide 0.3s ease;
}
@keyframes fadeSlide {
from { opacity: 0; transform: translateY(8px); }
to { opacity: 1; transform: translateY(0); }
}
.user-msg {
margin-left: auto;
}
.assistant-msg {
margin-right: auto;
}
.msg-bubble {
padding: 12px 16px;
border-radius: 16px;
line-height: 1.7;
white-space: pre-wrap;
box-shadow: 0 1px 4px rgba(0,0,0,0.06);
}
.user-msg .msg-bubble {
background: linear-gradient(135deg, #6366f1, #818cf8);
color: #fff;
border-bottom-right-radius: 4px;
}
.assistant-msg .msg-bubble {
background: #fff;
border: 1px solid #e2e8f0;
border-bottom-left-radius: 4px;
}
.input-area {
display: flex;
gap: 8px;
background: rgba(255,255,255,0.85);
backdrop-filter: blur(12px);
border-radius: 14px;
padding: 10px;
border: 1px solid rgba(148,163,184,0.2);
box-shadow: 0 2px 12px rgba(99,102,241,0.06);
}
#user-input {
flex: 1;
background: #f8fafc;
border: 1px solid #e2e8f0;
border-radius: 10px;
padding: 12px;
color: #334155;
min-height: 80px;
resize: vertical;
font-size: 14px;
transition: border-color 0.2s;
}
#user-input:focus {
outline: none;
border-color: #818cf8;
box-shadow: 0 0 0 3px rgba(129,140,248,0.15);
}
button {
padding: 0 22px;
border-radius: 10px;
border: none;
cursor: pointer;
font-weight: 600;
font-size: 14px;
transition: all 0.2s;
}
#send-btn {
background: linear-gradient(135deg, #6366f1, #8b5cf6);
color: white;
box-shadow: 0 2px 8px rgba(99,102,241,0.3);
}
#send-btn:hover {
transform: translateY(-1px);
box-shadow: 0 4px 12px rgba(99,102,241,0.4);
}
#clear-btn {
background: #f1f5f9;
color: #64748b;
border: 1px solid #e2e8f0;
}
#clear-btn:hover {
background: #e2e8f0;
}
.tip {
font-size: 12px;
color: #94a3b8;
margin-top: 6px;
text-align: center;
}
/* 加载动画:跳动圆点 */
.loading-dots {
display: inline-flex;
gap: 5px;
align-items: center;
padding: 4px 0;
}
.loading-dots span {
width: 8px;
height: 8px;
border-radius: 50%;
background: #818cf8;
animation: dotBounce 1.2s infinite ease-in-out;
}
.loading-dots span:nth-child(2) { animation-delay: 0.15s; }
.loading-dots span:nth-child(3) { animation-delay: 0.3s; }
@keyframes dotBounce {
0%, 60%, 100% { transform: translateY(0); opacity: 0.4; }
30% { transform: translateY(-8px); opacity: 1; }
}
/* 滚动条美化 */
#chat-container::-webkit-scrollbar { width: 6px; }
#chat-container::-webkit-scrollbar-track { background: transparent; }
#chat-container::-webkit-scrollbar-thumb { background: #cbd5e1; border-radius: 3px; }
#chat-container::-webkit-scrollbar-thumb:hover { background: #94a3b8; }
</style>
</head>
<body>
<div class="header">
<h1>ChatGLM3-6B 本地对话服务</h1>
<div class="monitor-info" id="monitor-panel">加载监控指标中...</div>
</div>
<div id="chat-container"></div>
<div class="input-area">
<textarea id="user-input" placeholder="输入问题,Shift+Enter换行,Enter发送"></textarea>
<div style="display:flex;flex-direction:column;gap:8px;justify-content:stretch;">
<select id="mode-select" style="min-height:30px;border-radius:10px;border:1px solid #e2e8f0;background:#f8fafc;color:#334155;font-size:13px;padding:0 10px;font-weight:500;cursor:pointer;">
<option value="sse">SSE 流式模式</option>
<option value="normal">普通模式</option>
</select>
<button id="send-btn" style="flex:1;min-height:48px;">发送</button>
<button id="clear-btn" style="min-height:30px;">清空对话</button>
</div>
</div>
<div class="tip">服务地址:http://127.0.0.1:8000 | 监控 /monitor</div>
<script>
const chatBox = document.getElementById('chat-container');
const input = document.getElementById('user-input');
const sendBtn = document.getElementById('send-btn');
const clearBtn = document.getElementById('clear-btn');
const monitorPanel = document.getElementById('monitor-panel');
const modeSelect = document.getElementById('mode-select');
// 后端服务地址,修改为服务器内网IP
const BACKEND_BASE_URL = "http://192.168.3.6:8000";
// 渲染对话气泡
function renderMsg(role, content) {
const div = document.createElement('div');
div.className = `msg-item ${role}-msg`;
div.innerHTML = `<div class="msg-bubble">${content}</div>`;
chatBox.appendChild(div);
chatBox.scrollTop = chatBox.scrollHeight;
return div.querySelector('.msg-bubble');
}
// 发送消息核心逻辑
async function sendMessage() {
const text = input.value.trim();
if (!text) return;
renderMsg('user', text);
input.value = '';
const bubble = renderMsg('assistant', '<div class="loading-dots"><span></span><span></span><span></span></div>');
const isStream = modeSelect.value === 'sse';
let respText = '';
const apiUrl = BACKEND_BASE_URL + '/v1/chat/completions';
const res = await fetch(apiUrl, {
method: 'POST',
headers: {'Content-Type': 'application/json'},
body: JSON.stringify({
stream: isStream,
messages: [{role: 'user', content: text}]
})
});
if (isStream) {
// SSE流式分片读取
const reader = res.body.getReader();
const decoder = new TextDecoder();
let sseBuffer = '';
while(true) {
const {done, value} = await reader.read();
if(done) break;
sseBuffer += decoder.decode(value, {stream: true});
const parts = sseBuffer.split('\n\n');
sseBuffer = parts.pop();
for(let part of parts) {
const line = part.trim();
if(!line.startsWith('data: ')) continue;
const data = line.slice(6);
if(data === '[DONE]') continue;
try{
const json = JSON.parse(data);
if(json.error) {
bubble.innerText = "推理异常:" + json.error.message;
return;
}
const delta = json.choices?.[0]?.delta?.content || '';
respText += delta;
bubble.innerText = respText;
chatBox.scrollTop = chatBox.scrollHeight;
}catch(e){}
}
}
} else {
// 一次性完整返回
try {
const json = await res.json();
if(json.error) {
bubble.innerText = "推理异常:" + (json.error.message || JSON.stringify(json.error));
} else {
respText = json.choices[0].message.content;
bubble.innerText = respText;
chatBox.scrollTop = chatBox.scrollHeight;
}
} catch(e) {
bubble.innerText = "解析响应失败:" + e.message;
}
}
}
// 每2秒刷新一次硬件监控指标
async function refreshMonitor() {
try{
const monitorUrl = BACKEND_BASE_URL + '/monitor';
const res = await fetch(monitorUrl);
const data = await res.json();
const memPct = data.llm_gpu_mem_usage_pct || 0;
const ttft = data.llm_last_ttft_seconds || 0;
const speed = data.llm_token_speed || 0;
const queue = data.llm_request_queue_length || 0;
const health = data.llm_service_health === 1;
const healthIcon = health ? '🟢' : '🔴';
monitorPanel.innerHTML = `
${healthIcon} 显存:${memPct}% |
TTFT:${ttft}s |
速度:${speed} tok/s |
排队:${queue}
`
}catch(e){
monitorPanel.innerHTML = `🔴 显存:--% | TTFT:--s | 速度:-- tok/s | 排队:--`;
}
}
// 绑定页面交互事件
sendBtn.onclick = sendMessage;
clearBtn.onclick = ()=>chatBox.innerHTML = '';
input.onkeydown = e=>{
if(e.key === 'Enter' && !e.shiftKey) {
e.preventDefault();
sendMessage();
}
}
setInterval(refreshMonitor, 2000);
refreshMonitor();
</script>
</body>
</html>前端适配修改说明:
- 修改BACKEND_BASE_URL为服务器内网 IP,局域网内其他电脑可直接访问页面调用服务
- 监控面板自动读取后端每秒生成Token数token_speed,直观展示RTX4090推理吞吐性能
- 流式加载时实时计算TTFT首Token耗时,精准反映4090推理响应速度
3. 运行输出对比
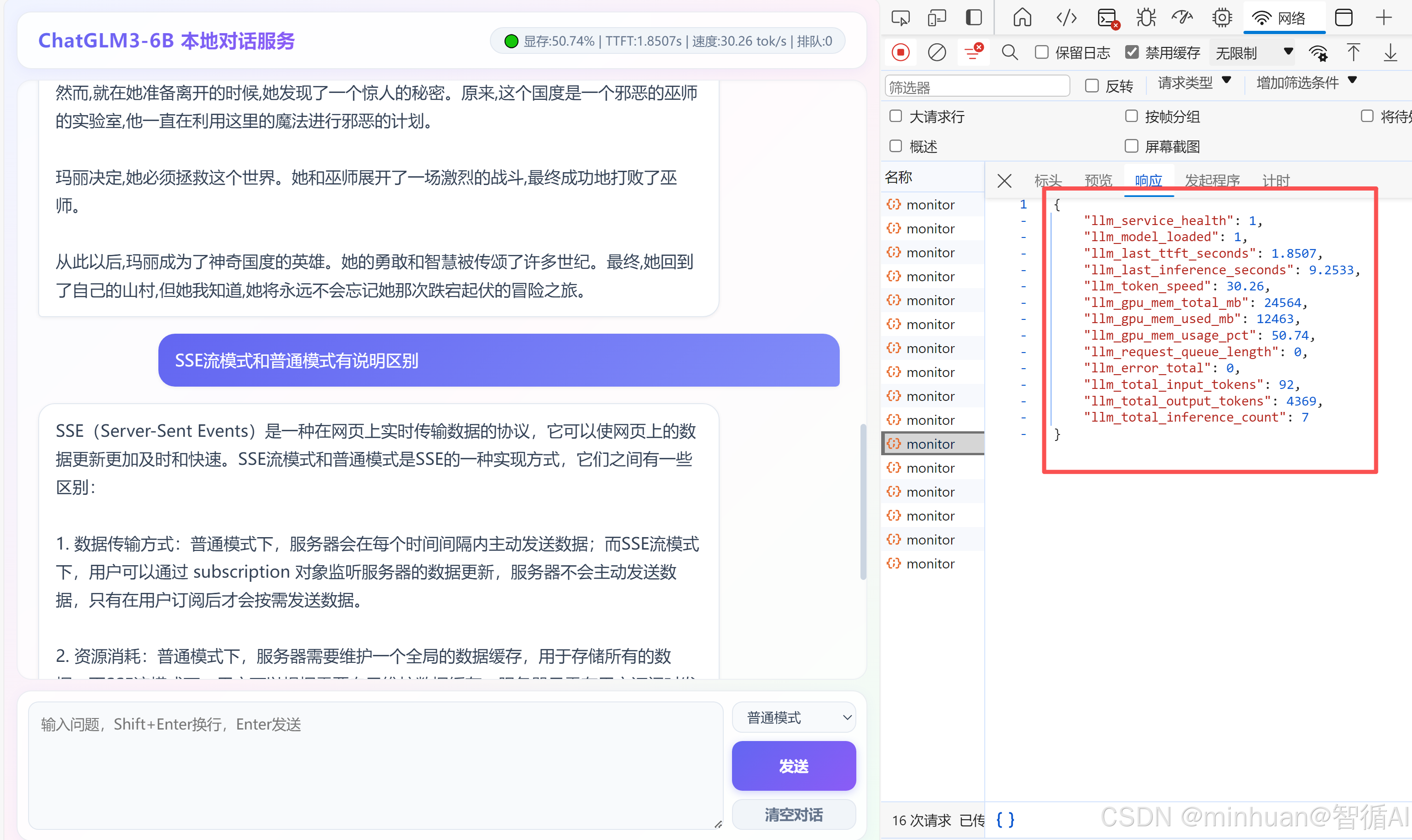
1. SSE流输出和普通模式的区别
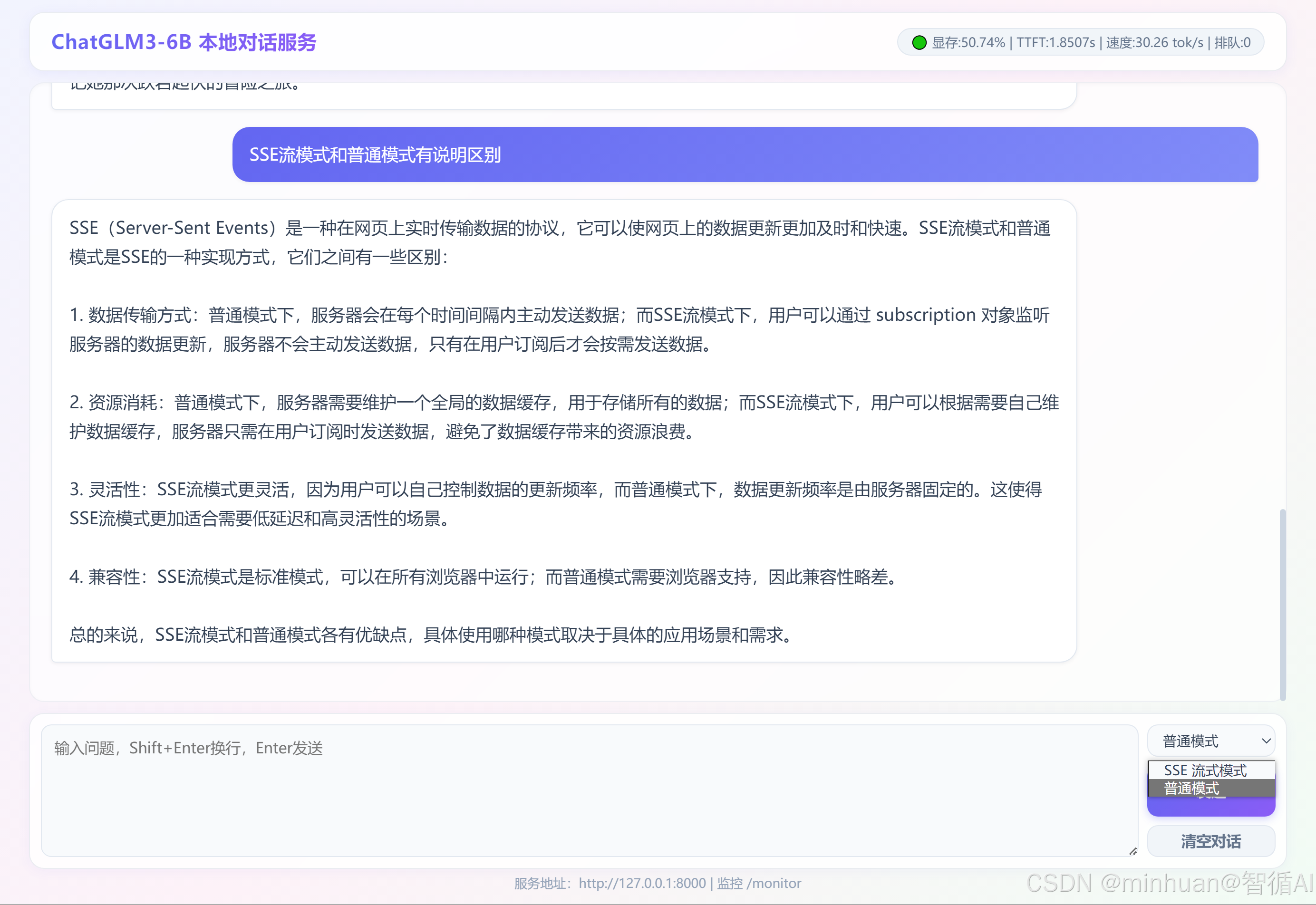
2. 采用SSE流模式输出:"写一个跌宕起伏的故事,300字"
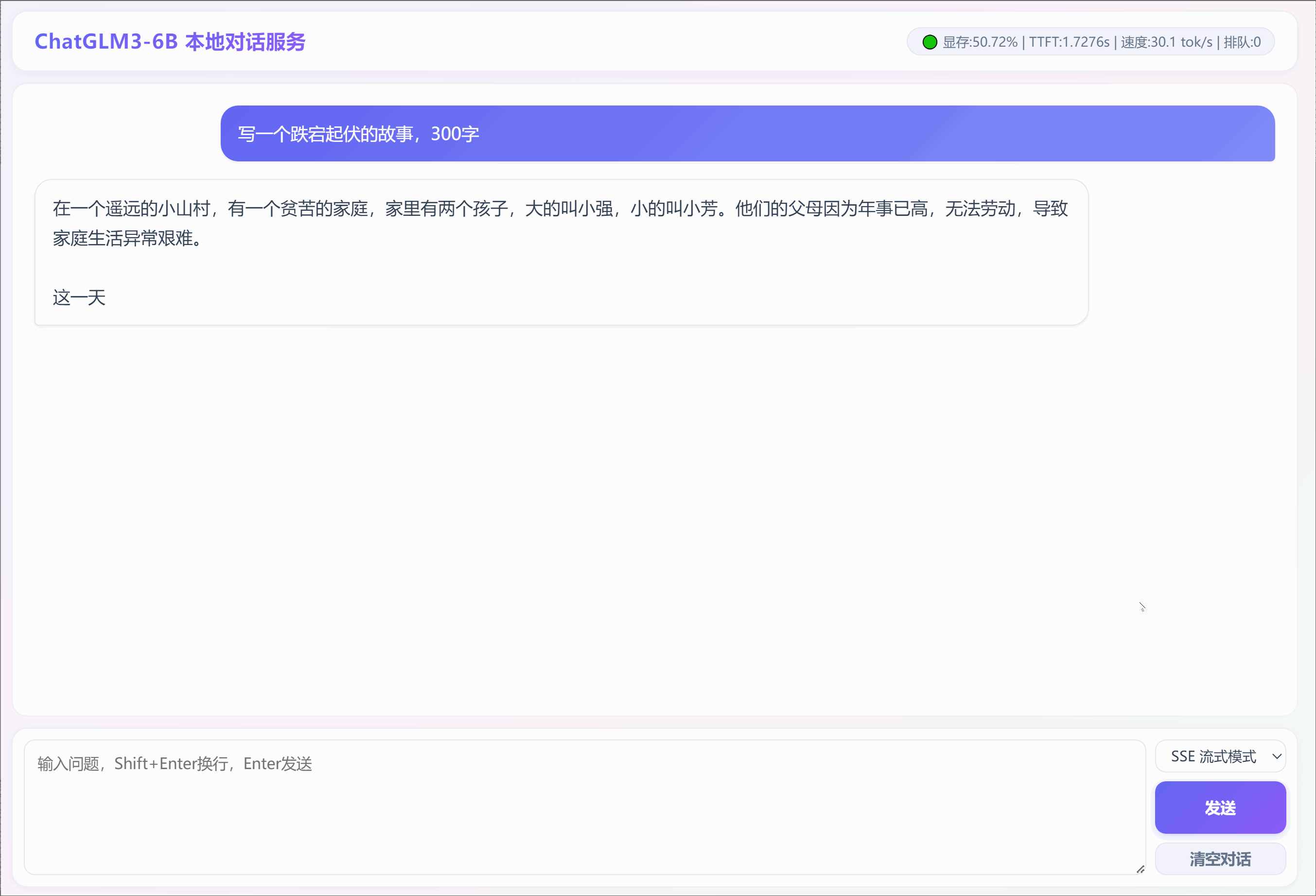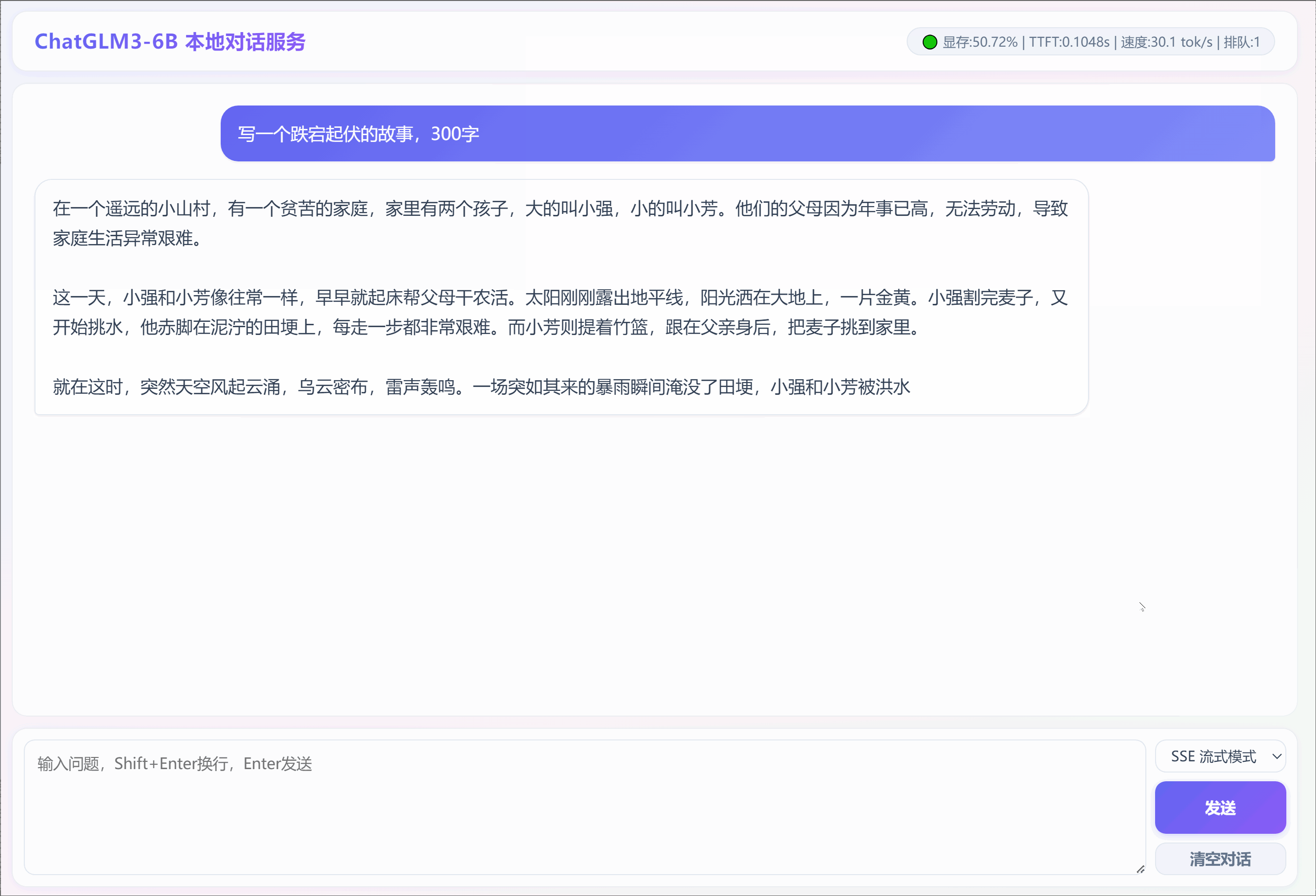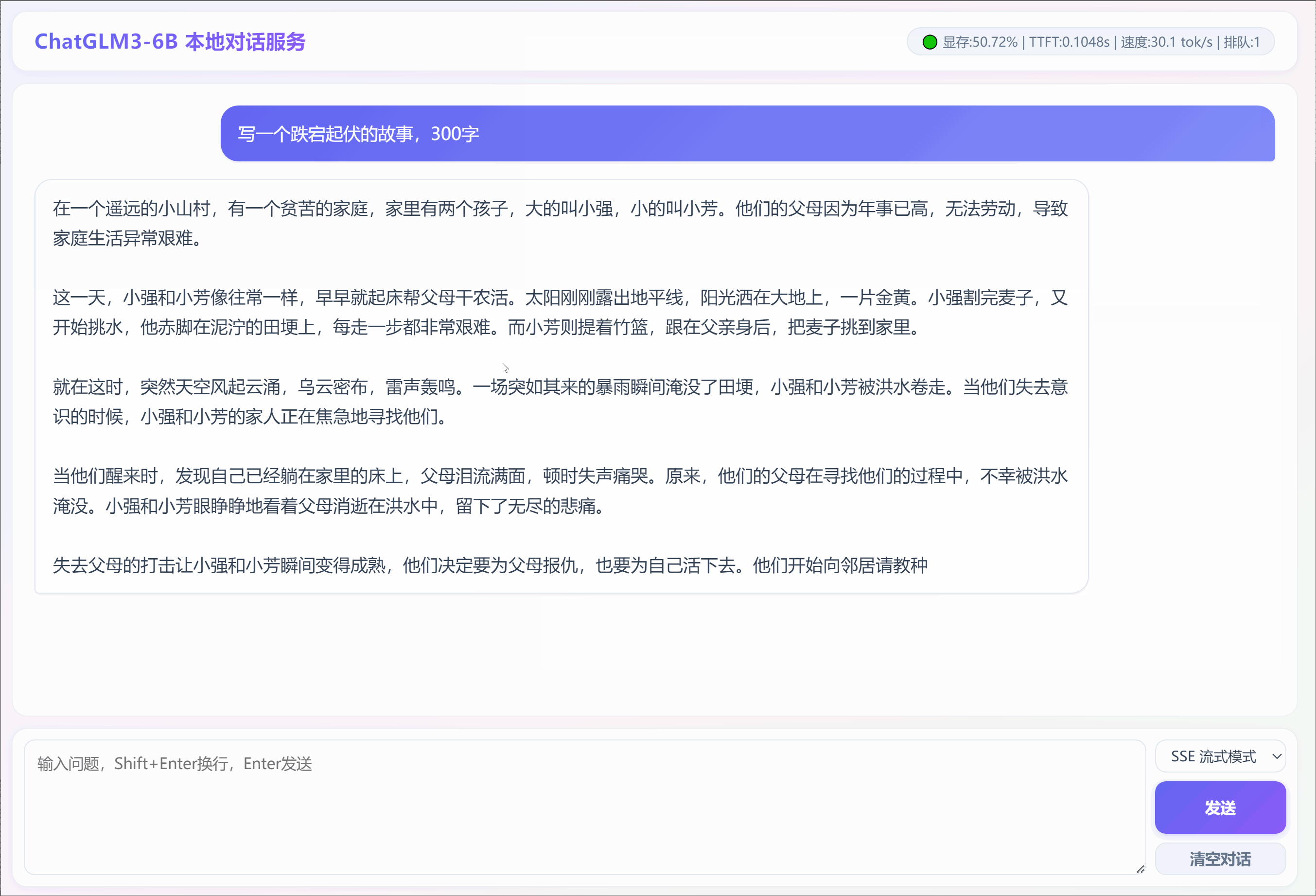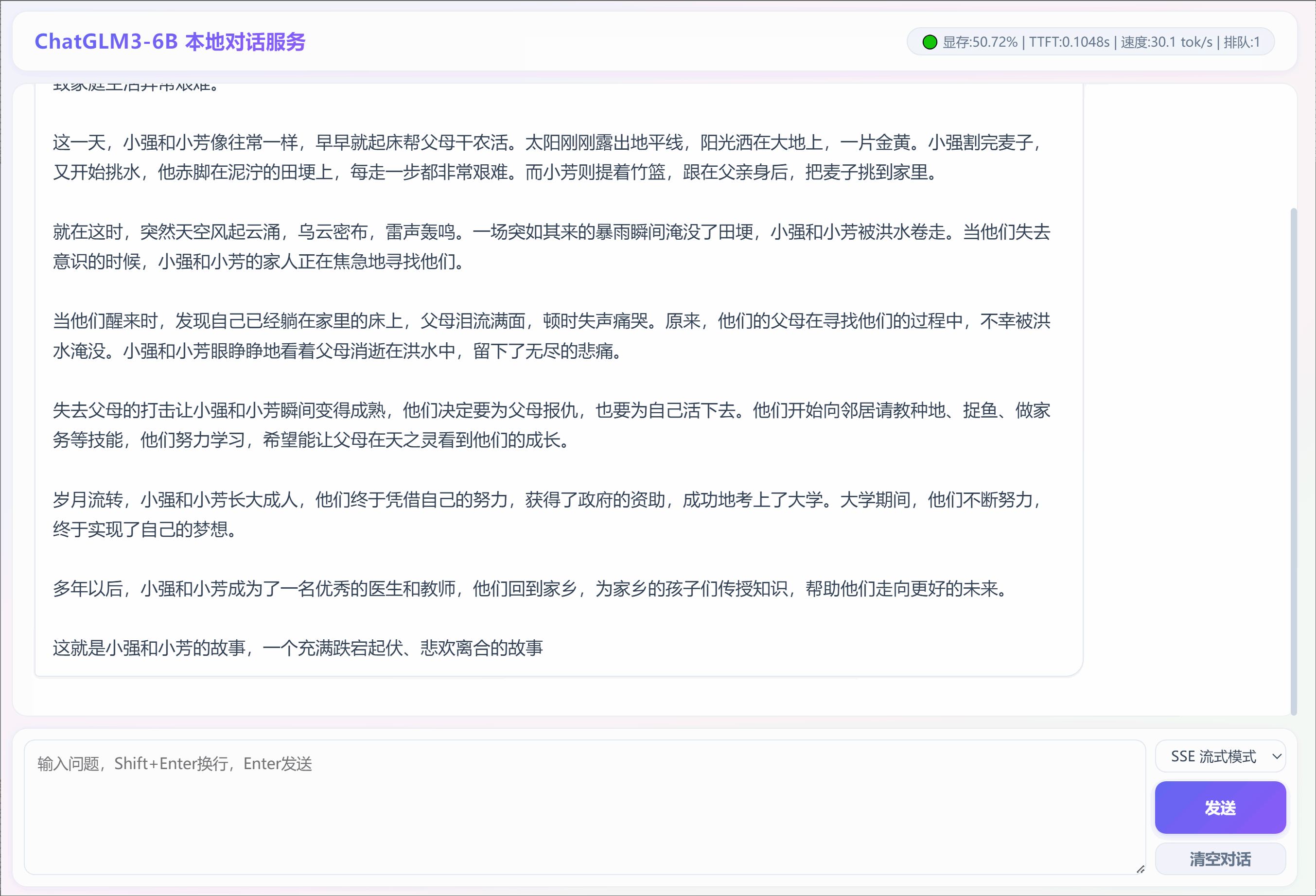
3. 采用普通模式输出:"写一个跌宕起伏的童话故事,300字"
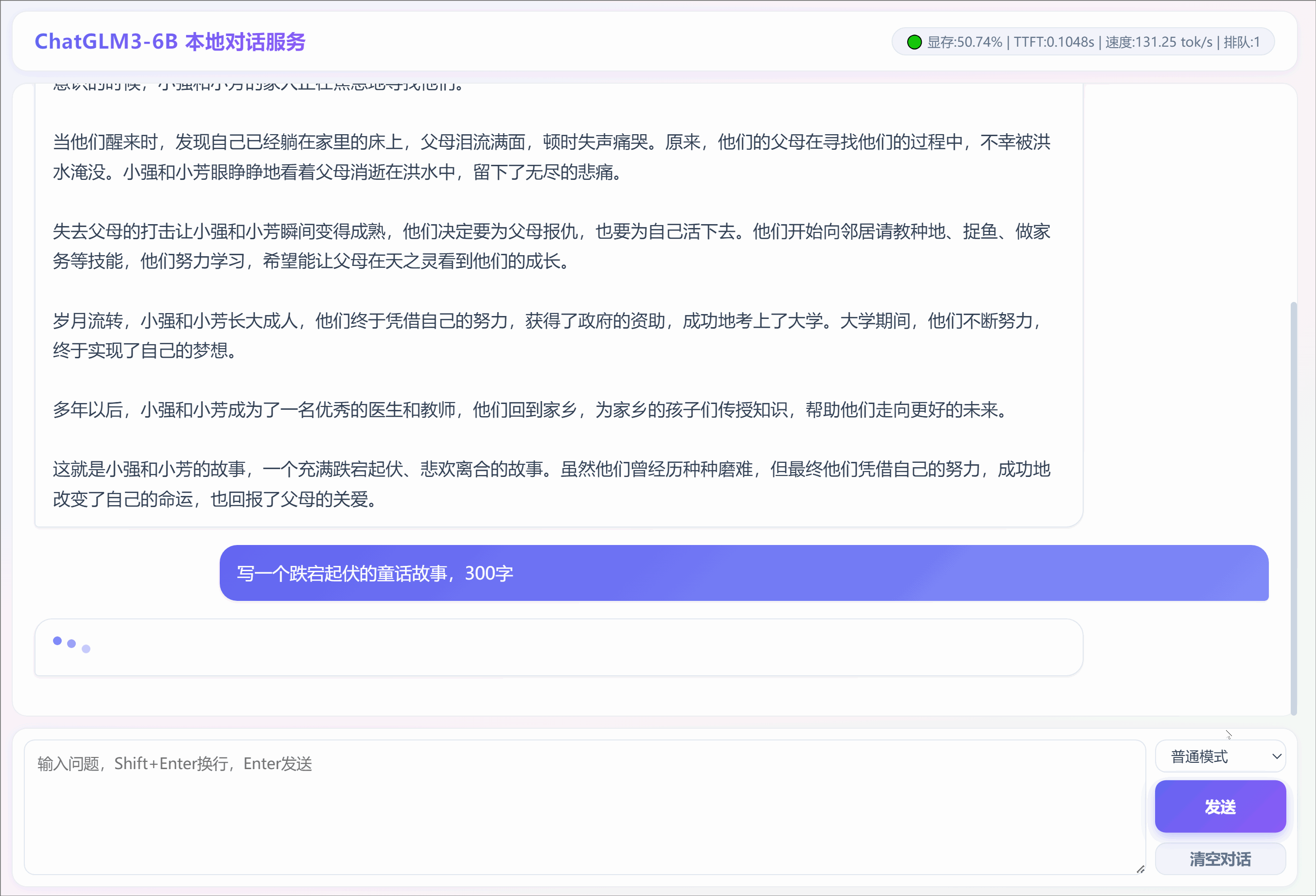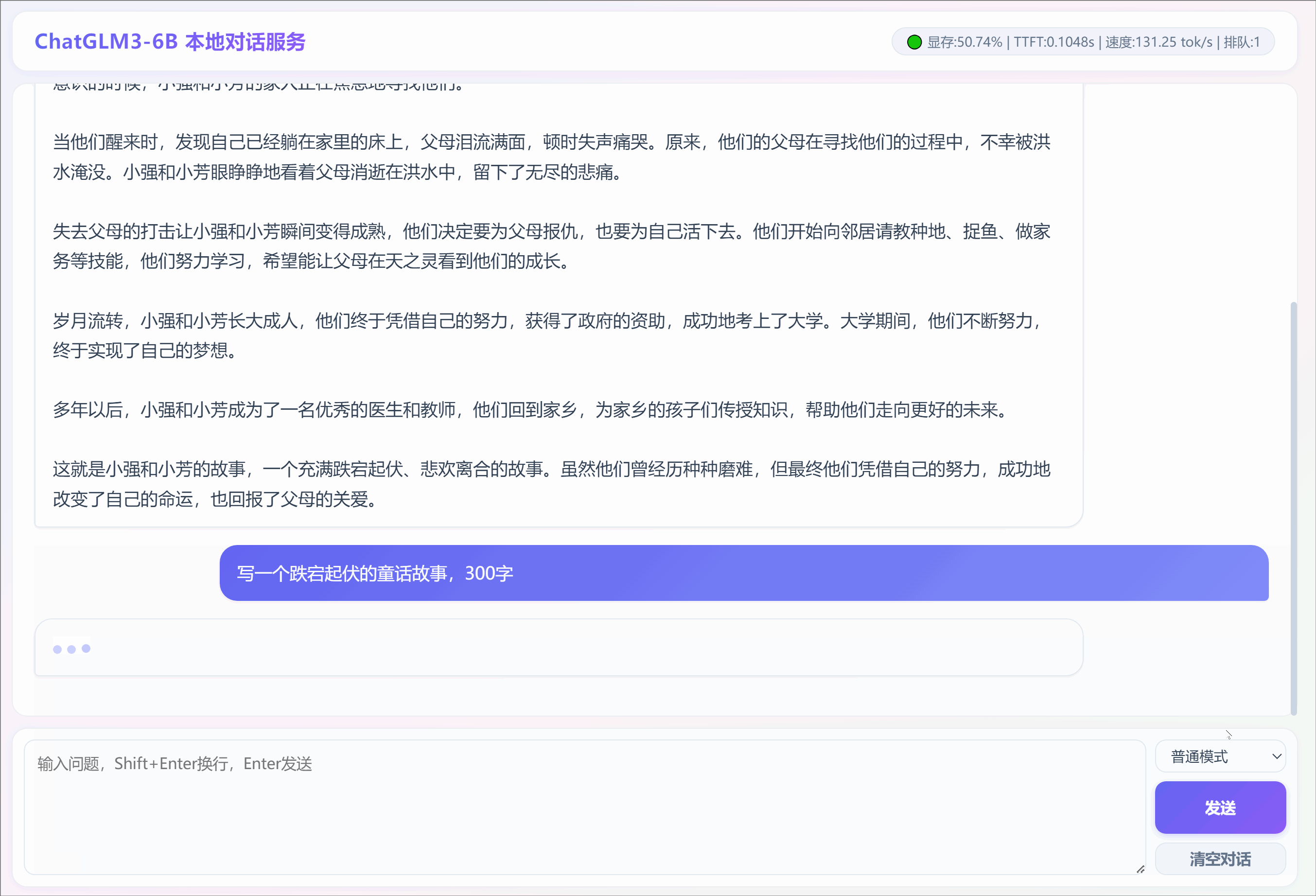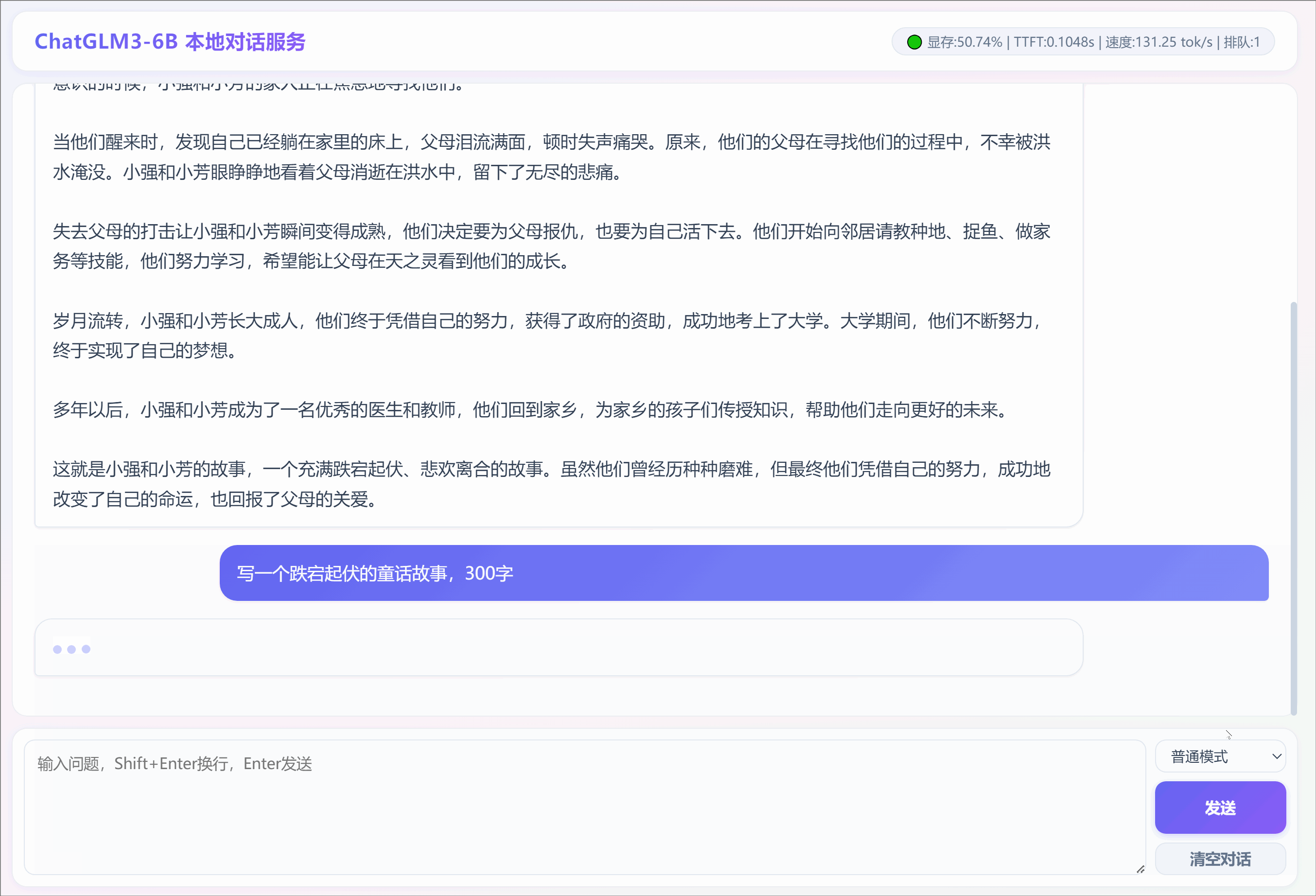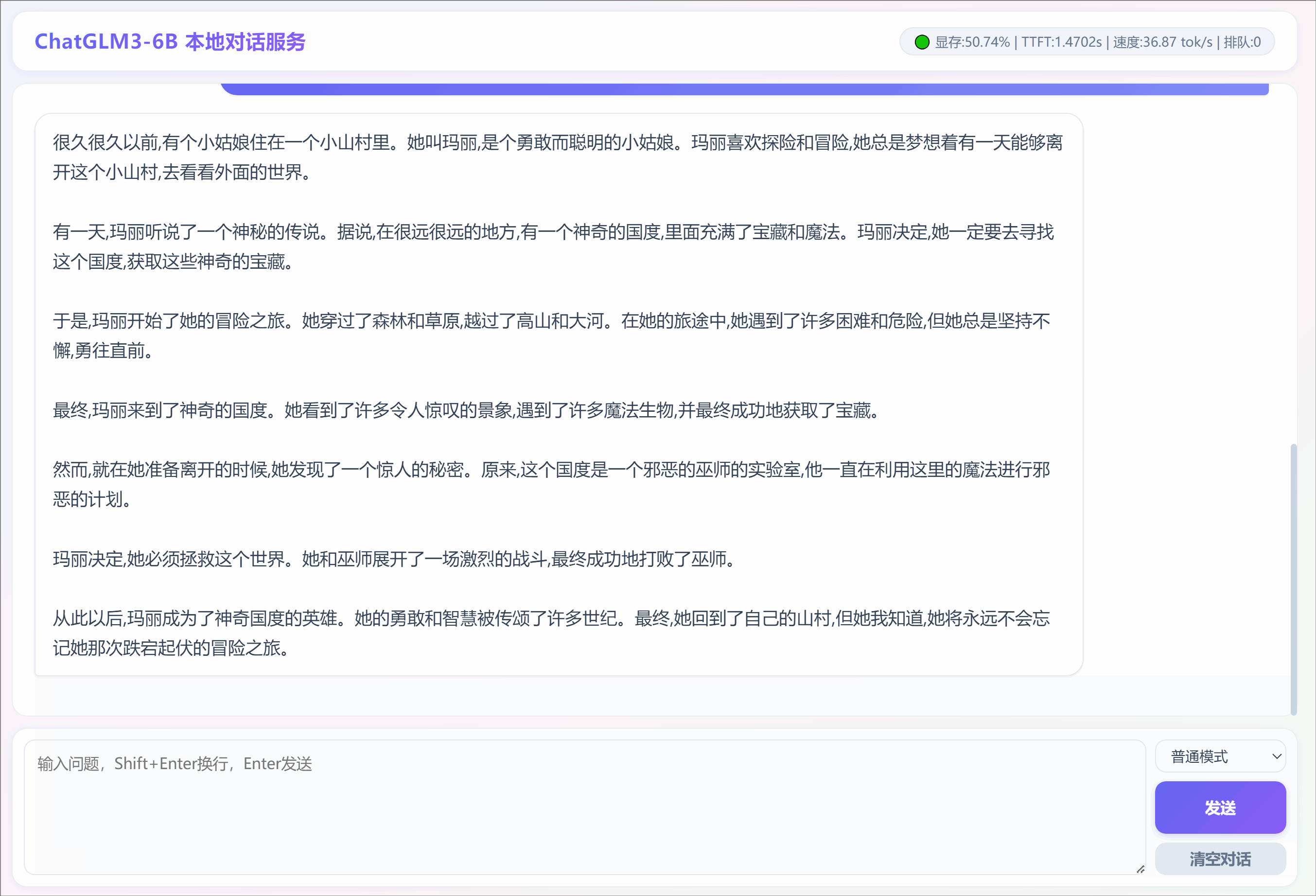
五、项目落地性能验证
1. 直观体现 RTX4090 适配优势
- 显存占用指标:监控接口返回llm_gpu_mem_usage_pct,FP16加载仅占用约40%显存,剩余显存支持多请求并发排队,体现24G大显存优势
- 吞吐指标token_speed:RTX4090单卡稳定输出20~30tok/s,对比16G显卡速度提升一倍,硬件算力差异可视化展示
- 排队队列llm_request_queue_length:支持同时堆积多条推理请求,不会瞬间OOM,4090大显存缓冲并发压力
2. 直观体现吞吐性能指标提升
- 前端面板实时展示token_speed每秒生成Token数量,作为吞吐核心衡量标准
- 后台累计统计total_input_tokens、total_output_tokens、total_inference_count,可批量压测计算平均吞吐
- 区分TTFT首token耗时与完整推理耗时,量化4090显卡低延迟优势,流式场景体验提升明显
3. 接口 curl 测试示例
普通对话接口:
bash
curl -G -X POST http://192.168.3.6:8000/chat --data-urlencode "question=介绍RTX4090部署大模型优势"OpenAI 非流式接口:
bash
# 非流式(所有平台通用):
curl -X POST http://192.168.3.6:8000/v1/chat/completions ^
-H "Content-Type: application/json" ^
-d "{\"messages\":[{\"role\":\"user\",\"content\":\"介绍RTX4090部署大模型优势\"}],\"stream\":false}"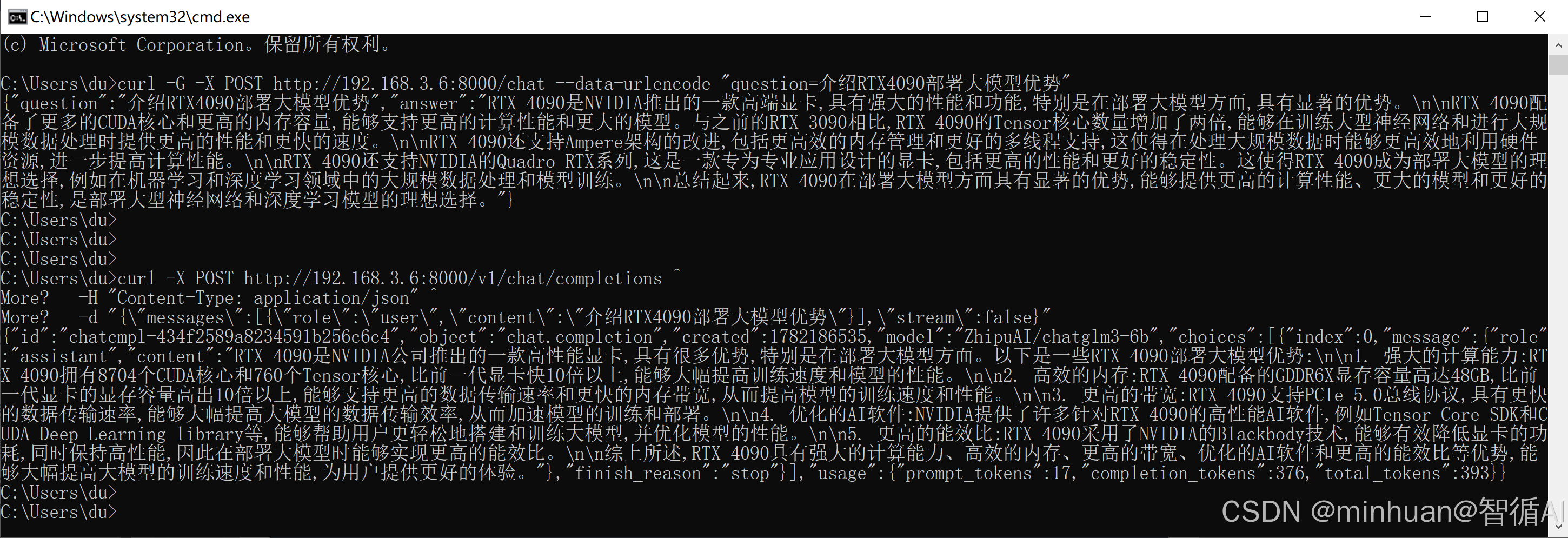
OpenAI 流式接口:
python
# 流式 SSE:
curl -X POST http://192.168.3.6:8000/v1/chat/completions ^
-H "Content-Type: application/json" ^
-d "{\"messages\":[{\"role\":\"user\",\"content\":\"100字介绍RTX4090部署大模型优势\"}],\"stream\":true}"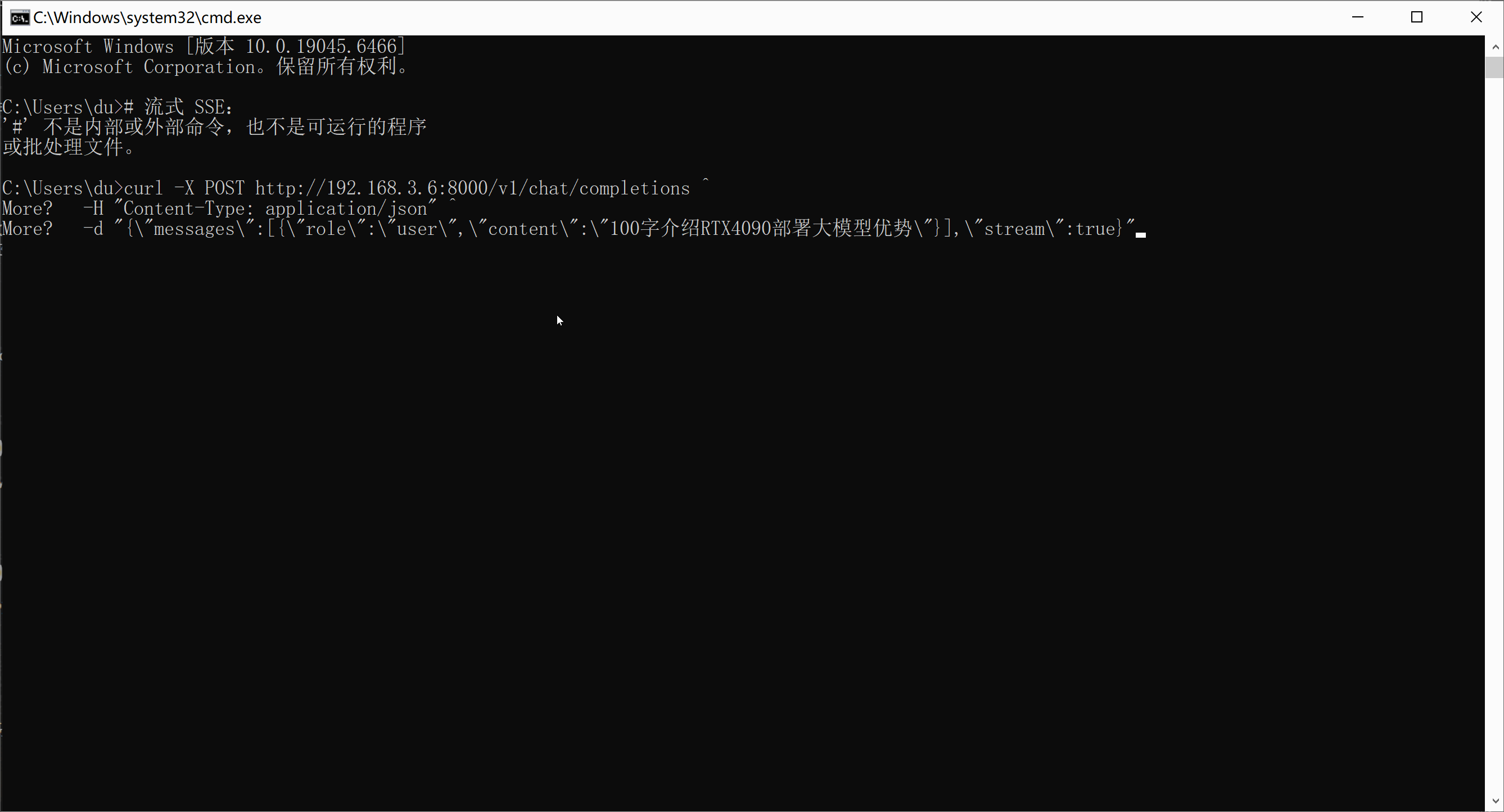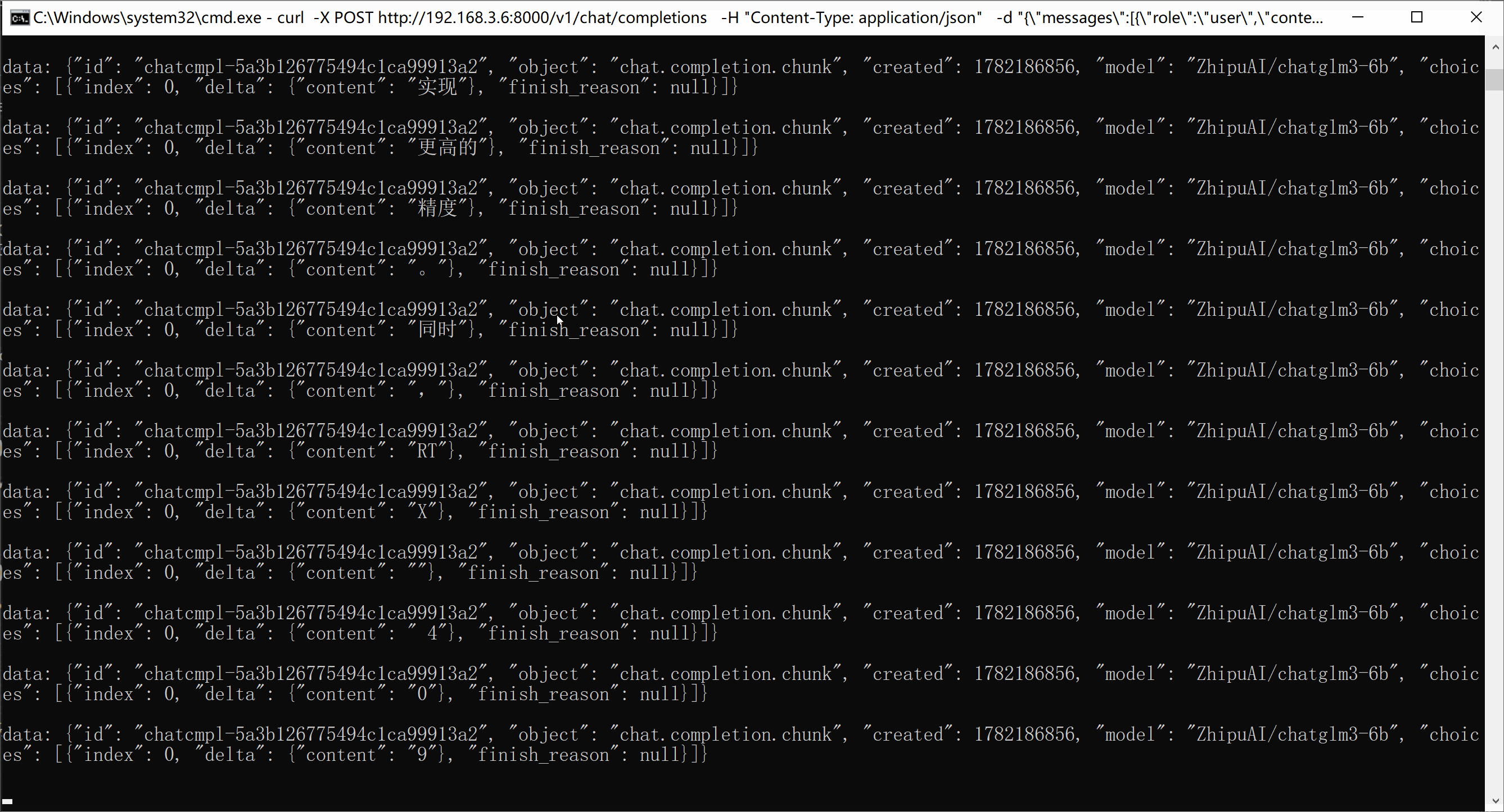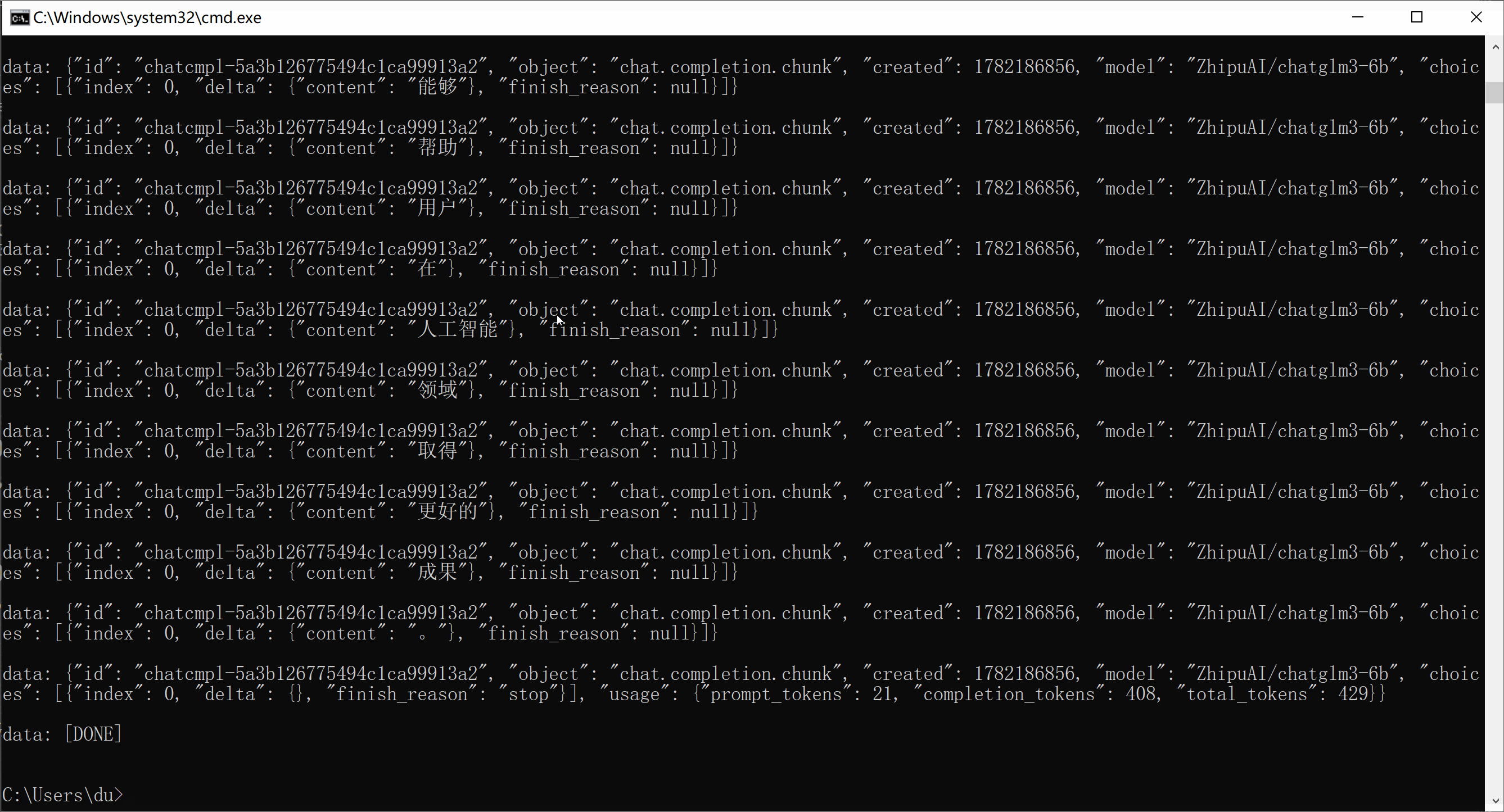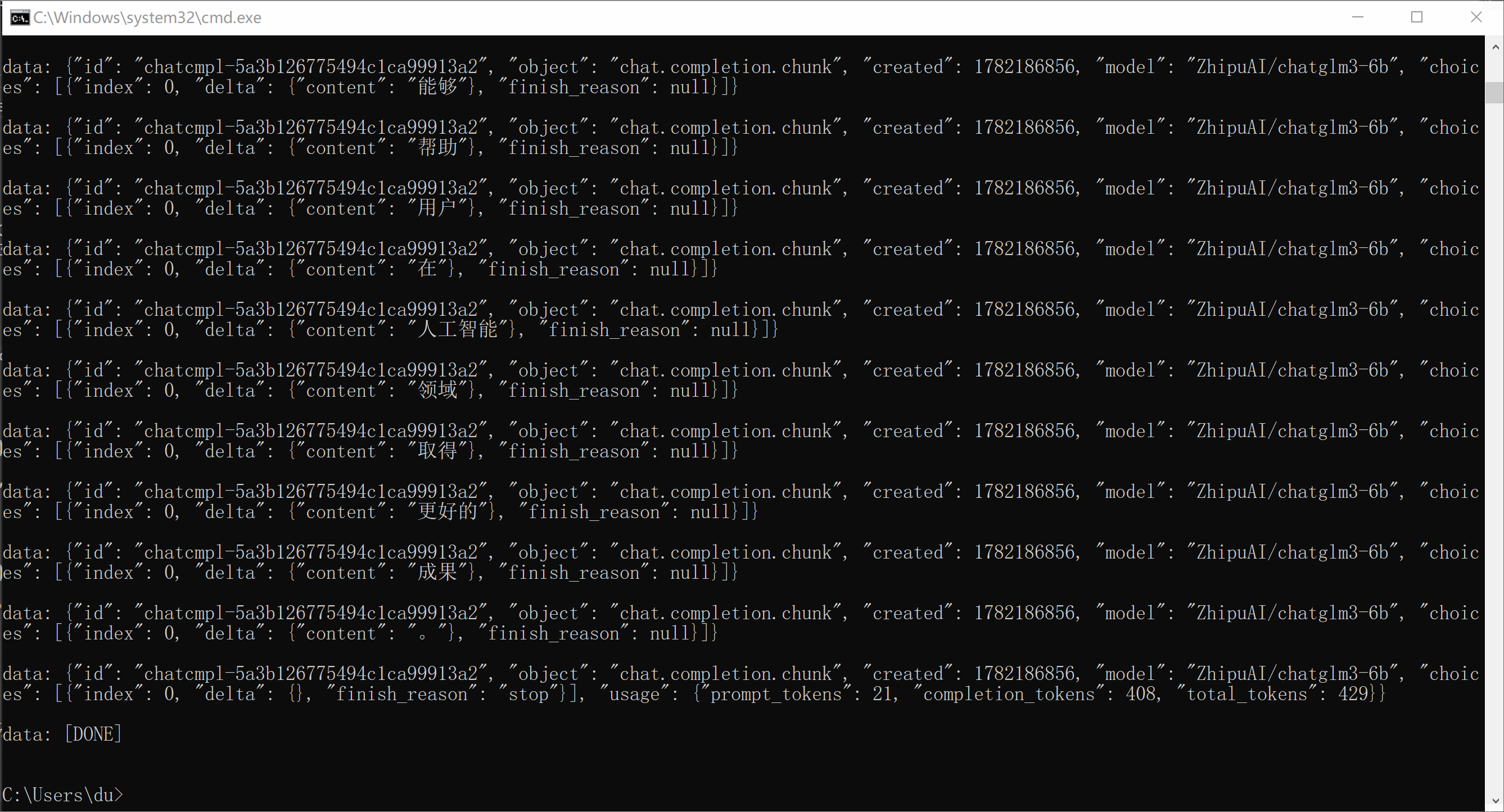
六、总结
这套项目实例基于ChatGLM3-6B模型适配RTX4090本地部署实践,没有花里胡哨的复杂框架,基于原生Transformers+FastAPI搭建,兼顾易用性与生产实用性,本地大模型落地从来不是跑通单次推理就完事,监控、接口兼容、多请求容错才是可用服务落地的关键。之前只写单段推理代码时,根本看不到显存碎片、吞吐瓶颈,有了实时监控面板,硬件性能好坏一眼就能对比出来。
本地部署的核心首先要了解KV Cache、半精度加载这类基础优化,之后可以深化了解vLLM这些高性能引擎,相对而已原生框架更容易看懂底层逻辑;其次养成加监控指标的习惯,不管是个人测试还是企业私有化部署,显存、吞吐、排队长度是调优的核心依据。