Agent = LLM + Planning + Memory + Tools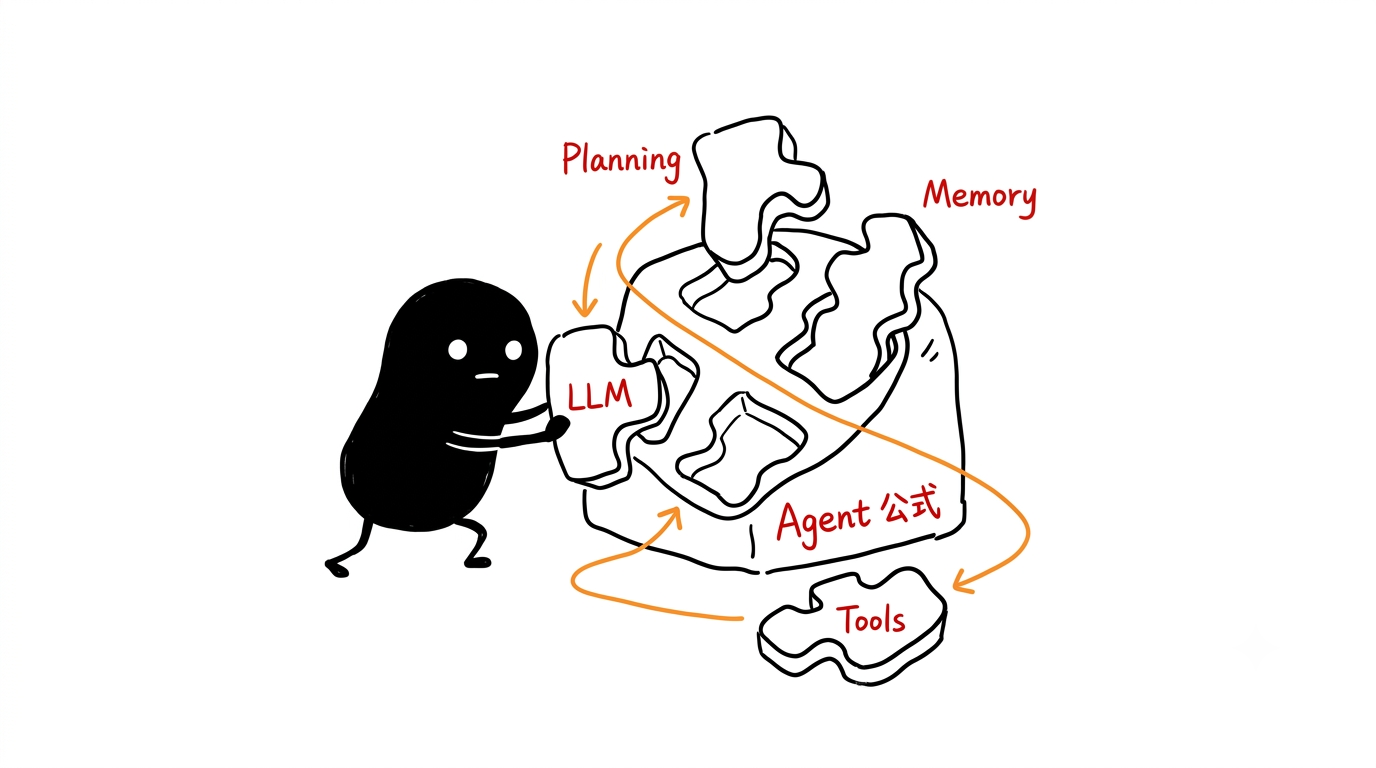
推理与规划(Reasoning / Planning):用 LLM 分析当前任务状态,拆目标,决定下一步怎么做。Chain-of-Thought(CoT)提示技术可以让模型逐步推理,减少直接拍脑袋给答案的概率。
记忆分两层。短期记忆通常是上下文历史,用来保持对话连续性;长期记忆一般是外部知识库,比如向量数据库或知识图谱。短期记忆解决"刚才说过什么",长期记忆解决"过去积累了什么"。
Tools(工具):让 LLM 能真正操作外部世界,比如查数据、调 API、读文件、执行代码。没有工具,Agent 很多时候只能停留在"建议你怎么做"。
工具执行后会返回结果,Agent 把这些结果放回上下文,再进入下一轮推理。这个反馈闭环就是 Observation(观察),也是 Agent Loop 能转起来的关键。Agent loop 就是 Agent 完成任务时不断重复的一套流程:先接收用户目标,然后观察当前上下文,思考下一步该做什么,如果需要就调用工具,拿到工具结果后再判断任务是否完成;如果没完成,就继续"思考 → 行动 → 观察",直到获得足够信息并生成最终答案。简单说,它就是 Agent 的"循环工作机制"。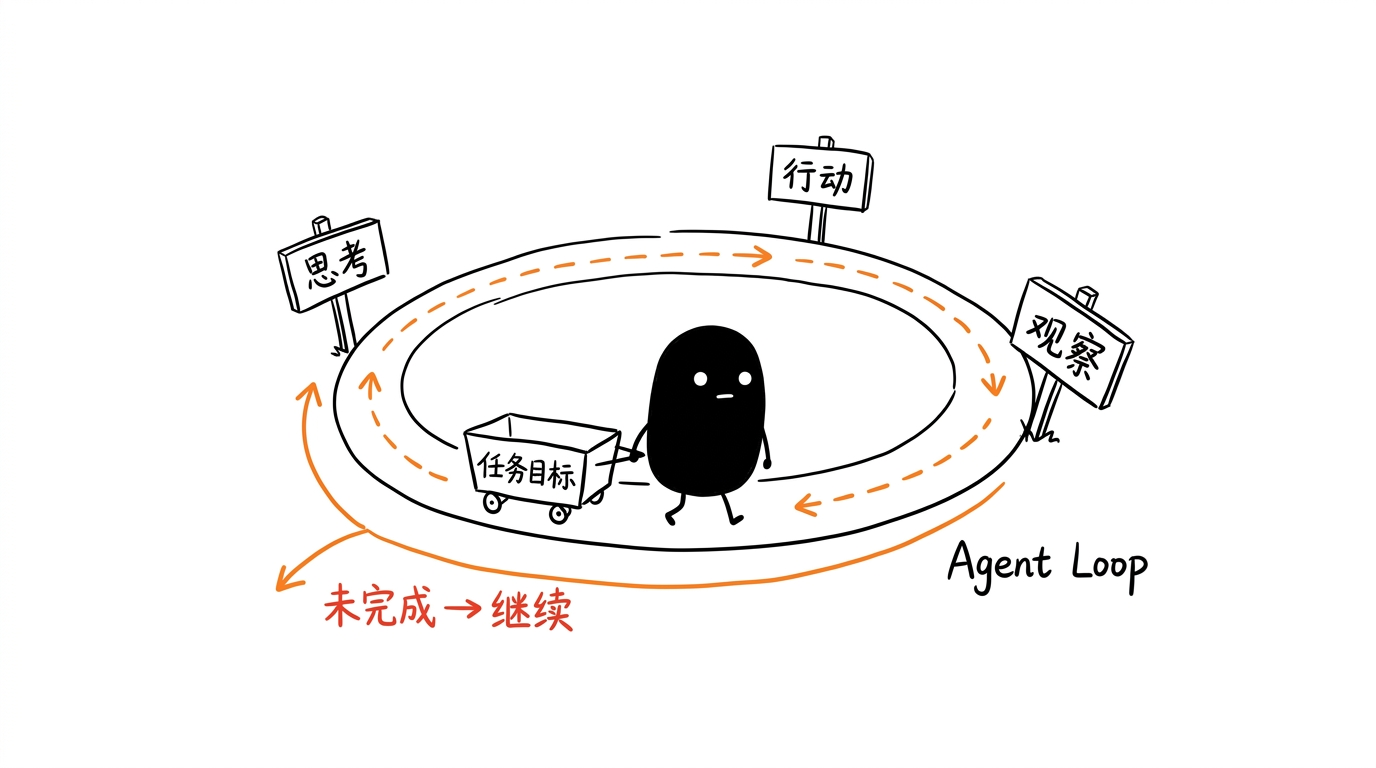
ReAct 落地时一般需要这几个组件配合:
1.历史上下文,保存推理步骤、执行动作、反馈观察
2.实时环境输入,比如系统告警、用户反馈等外部变量
3.LLM 推理模块:负责逻辑分析和下一步规划
4.工具集与技能库,包括原子工具和 Skills
5.反馈观察机制,采集工具响应并追加回上下文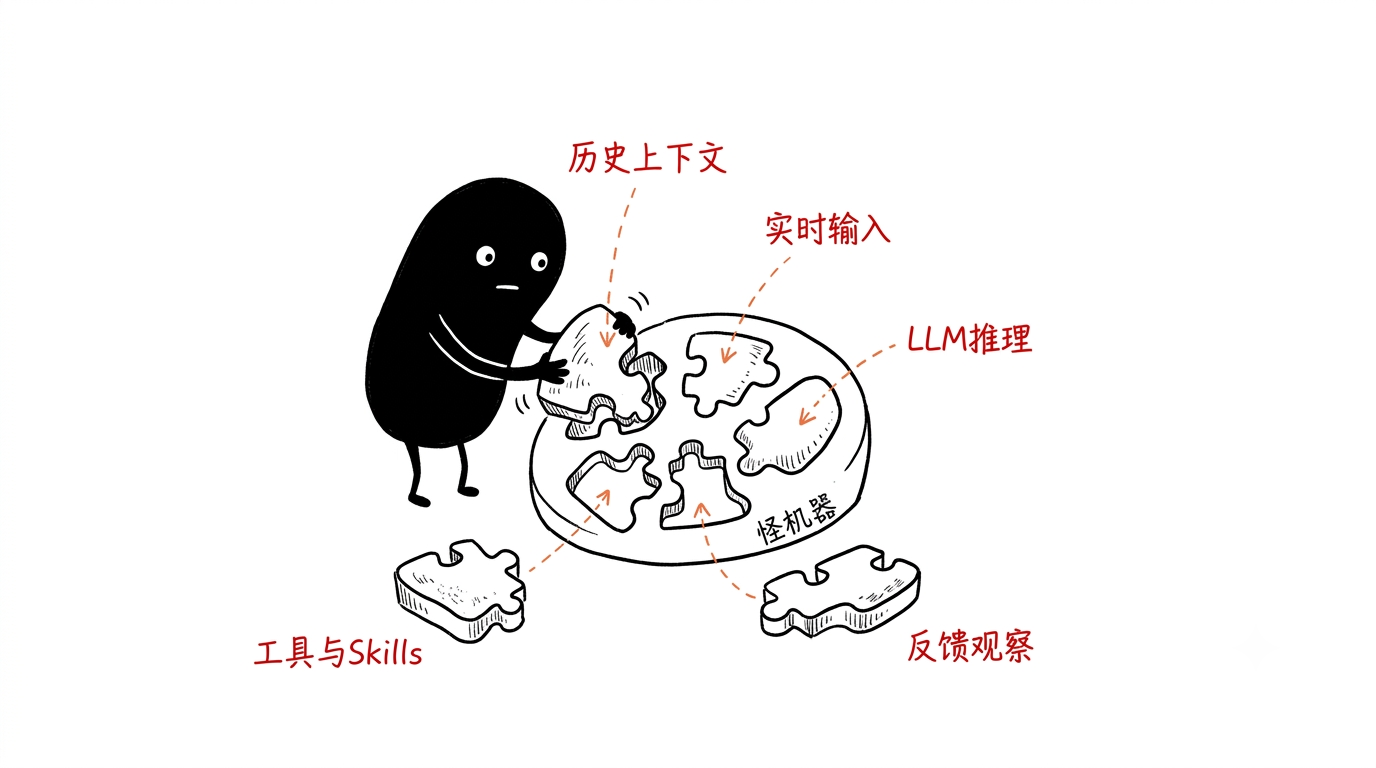
ReAct 流程就是 Agent 先根据用户任务进行 Thought(思考),判断下一步要做什么;如果需要外部信息或操作,就执行 Action(行动),比如调用搜索、数据库或工具;工具返回结果后,Agent 进行 Observation(观察),再根据观察结果继续思考。这个过程会反复循环,直到信息足够,最后输出 Final Answer(最终答案)。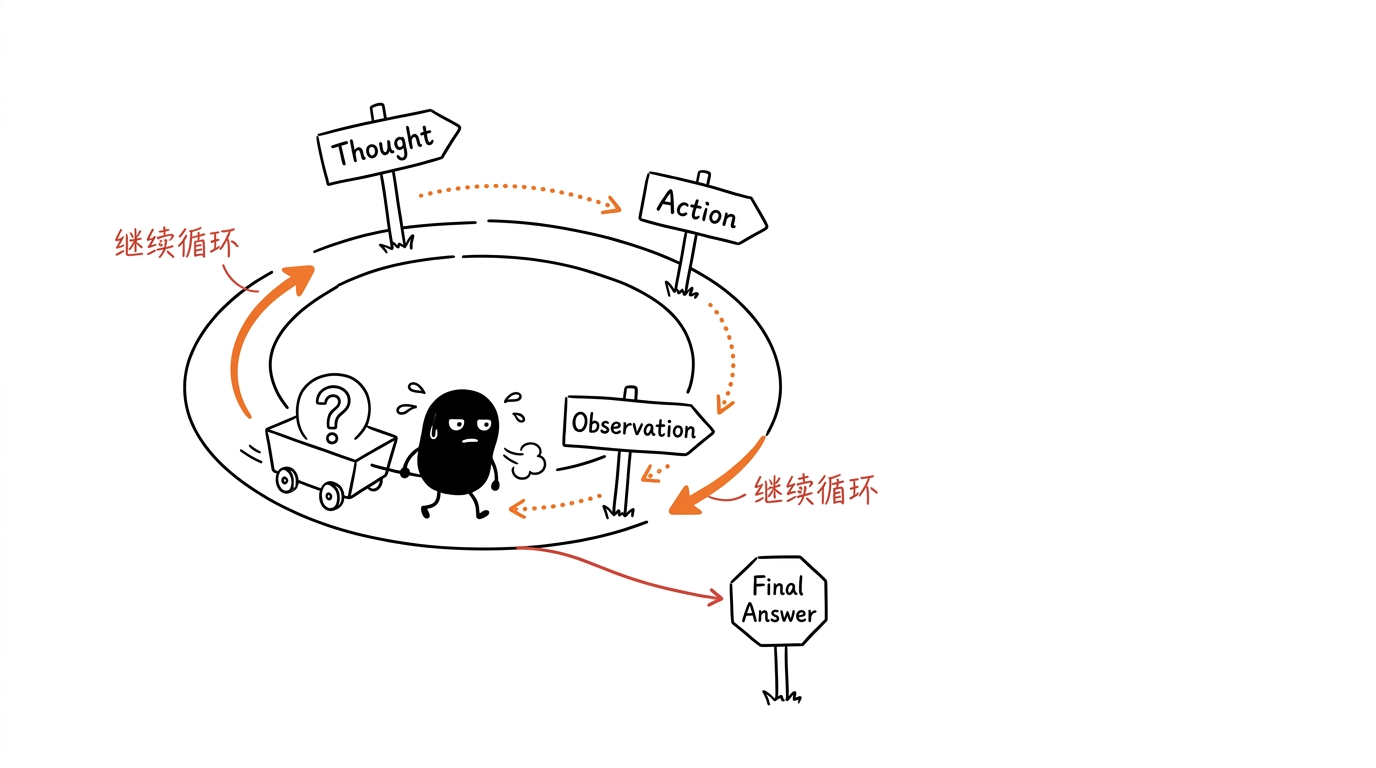
ReAct 的好处是能减少幻觉,复杂任务成功率更高,也比较容易解释每一步为什么这么做。代价也明显:多轮迭代会增加响应延迟,效果还很依赖工具和 Skills 的质量。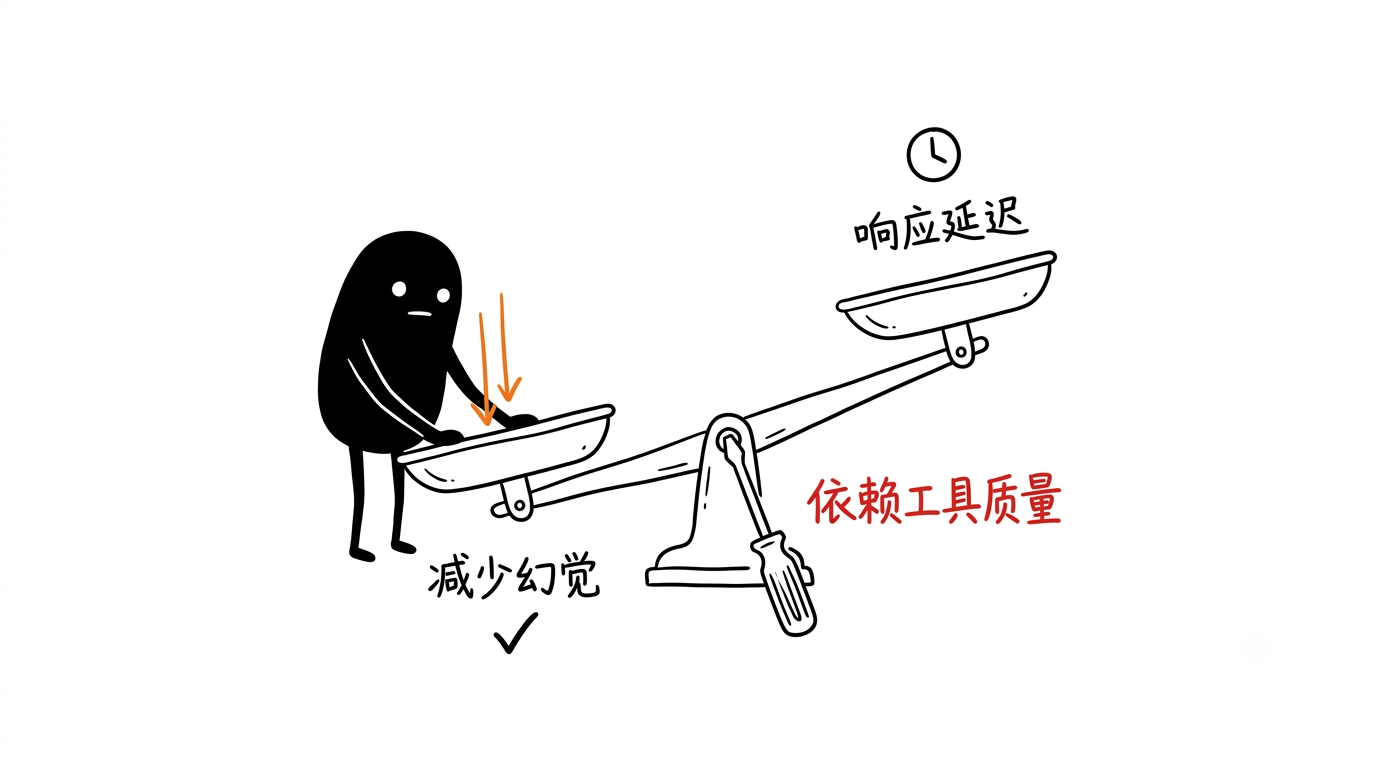
Reflection 给 Agent 加上自我纠错能力。
它不改模型权重,靠自然语言反馈来强化模型行为。
常见实现有三种:
1.Reflexion 框架:任务失败后进行口头反思,把结论存进记忆缓冲区,下次再遇到类似问题时参考。比如代码调试失败后,模型反思出"变量 count 在调用前没初始化",下一轮就能规避。
2.Self-Refine 方法:任务完成后,让模型审查自己的输出,再迭代改进。它通常用来提升回答、代码、文案这类输出质量。
3.CRITIC 方法:引入外部工具,比如搜索引擎或代码执行器,对输出做事实验证,再根据验证结果修正。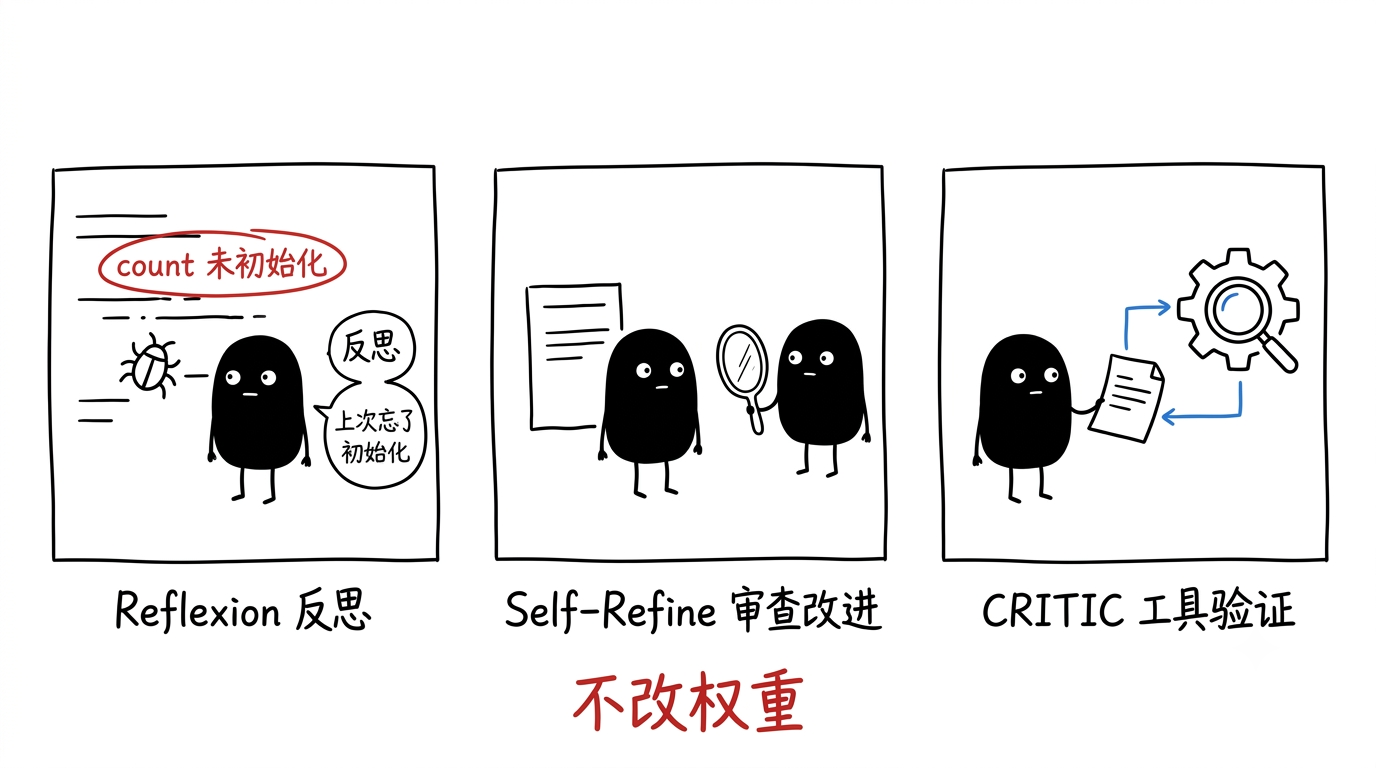
Reflection 很少单独用。更多时候,它会叠加在 ReAct 或 Plan-and-Execute 上,让 Agent 有一定自适应能力。
A2A 协议就是一种让不同 Agent 之间能够互相发现、通信和协作的标准协议:一个 Agent 可以把任务交给另一个更擅长的 Agent,传递上下文、请求能力、接收结果,并继续完成后续流程。简单说,A2A 解决的是"多个 Agent 怎么像团队一样协同工作"的问题。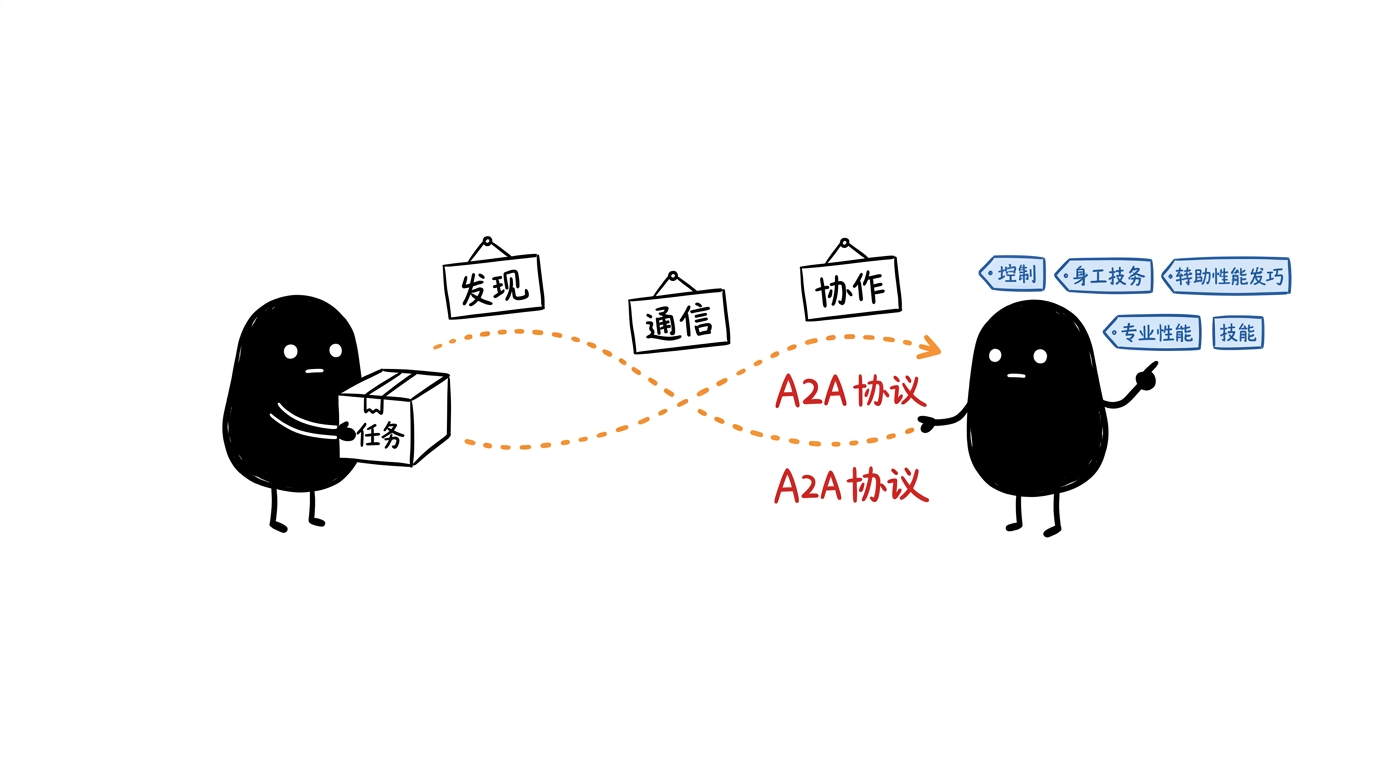
记忆系统通常分两层:短期记忆和长期记忆。短期记忆是 Session 级的,服务当前任务;长期记忆是跨 Session 的,负责把用户偏好、历史决策、过往经验沉淀下来。
|----------|----------------------|------------------------|
| 存储形式 | 说明 | 典型实现 |
| Token级记忆 | 以自然语言或离散符号形式存储在外部数据库 | 向量库中的文本块、结构化JSON |
| 参数化记忆 | 将信息编码进模型参数中 | 预训练知识、LoRA适配器、SFT微调 |
| 潜在记忆 | 以隐藏形式承载在模型内部表示中 | KV Cache、Hidden States |
记忆操作的生命周期
|----|-------------------|-----------------------|
| 操作 | 说明 | 工程实现 |
| 编码 | 将原始交互转化为可存储的结构化信息 | LLM提取事实三元组、生成摘要 |
| 存储 | 将编码后的信息持久化 | 写入向量库/图数据库/参数 |
| 提取 | 根据上下文检索相关记忆 | 向量检索+BM25+图遍历 |
| 巩固 | 将短期记忆转化为长期记忆 | 异步任务:对话摘要->实体库 |
| 反思 | 主动回顾评估记忆内容,优化决策 | 任务完成后提取Meta-Knowledge |
| 遗忘 | 淘汰低价值或过时记忆 | 权重衰减+冲突标记废弃 |
控制短期记忆膨胀方法
第一种是上下文缩减(Context Reduction)。当对话历史达到预设 Token 阈值时,框架自动丢弃最早的 N 轮消息,也就是滑动窗口;或者调用轻量模型把历史对话压缩成摘要,用信息损耗换上下文空间。
第二种是上下文卸载(Context Offloading)。工具或 Skill 调用可能返回很大的数据,比如完整网页 HTML、CSV 文件内容。这时可以把重型结果放到外部临时存储里,Prompt 里只保留一个短引用,比如 UUID 或文件路径。模型需要深挖细节时,再通过强制关联的 Function Calling 调内部工具读取。这里一定要配防雪崩策略:读取超时或文件超限时,工具要主动返回截断或降级结果。
第三种是上下文隔离(Context Isolation)。多智能体架构里,主 Agent 给子 Agent 分配任务时,只传递精简任务指令和必要上下文片段,不要把完整对话历史广播给每个子 Agent。这是控制多 Agent 系统总 Token 消耗的关键做法。
记忆反思与合成
第一类是自我反思(Self-Reflection)。任务完成后,Agent 启动异步任务,复盘本次任务的成败原因,把"教训"提取成一条 Meta-Knowledge。
第二类是精细化反思闭环(Reflect Loop)。2025-2026 年的一些前沿框架,比如 MUSE,已经把反思机制演化成更细的"规划-执行-反思-记忆"闭环。反思不再只发生在任务完成后,而是在每个子任务结束时触发。独立的 Reflect Agent 会对子任务输出做三重验证:真实性验证,检查输出是否符合客观事实;交付物验证,检查是否完成用户指定目标;数据保真性验证,检查关键数据在传递中有没有丢失或变形。这种细粒度反思能减少错误在多轮推理里持续放大。不过它也会带来额外成本,不适合所有任务都开满。对低风险、低价值任务来说,过度反思反而可能得不偿失。
第三类是记忆聚类与合并(Clustering & Consolidation)。当长期记忆里出现大量碎片化、重复记录时,比如用户 10 次提到同一个项目背景,系统可以自动触发合并任务,把这些碎片整理成更完整的"实体百科"。这样既能减少向量库冗余,也能提升检索一致性。
一个完整的 Markdown 记忆体系通常会分成几个层级:
-
用户级记忆:存个人偏好和长期习惯,放在
~/.claude/CLAUDE.md,比如 2-space 缩进、先写测试再写代码、不喜欢用 emoji。 -
项目级记忆:存项目规范、技术栈、目录结构,放在仓库根目录的
CLAUDE.md,团队成员共享,通过 Git 同步。 -
子目录级记忆:存局部模块的专属规则,放在子目录的
CLAUDE.md,比如backend/下的 API 设计规范、docs/下的写作风格要求。 -
团队共享记忆:需要提交到仓库的共同约定,通常是项目级
CLAUDE.md和.claude/rules/目录下可版本化的规则文件。 -
私有记忆:不应该提交的个人工作流,比如
CLAUDE.local.md,加入.gitignore后只留在本地。
维度 Markdown 记忆 向量库记忆 RAG 知识库 数据库型框架(Mem0 等) 检索精度 全量注入,无检索机制,启动时全部加载 高,语义相似度 高,语义检索 高,混合策略 上下文成本 与文件大小线性相关,大文件会挤占空间 按需检索,上下文高效 按需检索,上下文高效 按需检索,上下文高效 调试体验 极佳,直接读写文件 中等,需向量查询工具 中等,需检索日志 复杂,需理解框架逻辑 部署成本 极低,只需文件读写 高,需维护向量服务 高,需 RAG pipeline 高,需框架运行时 版本控制 原生集成 Git 需额外同步机制 需额外同步机制 需额外同步机制 迁移成本 零,复制文件即可 高,锁定专有格式 高,锁定 pipeline 极高,绑定框架 适用场景 偏好、约定、踩坑记录 多样化记忆检索 共享知识查询 复杂多源记忆管理