Spring Boot + LangChain4j Day 4:知识库持久化,从"一重启就没"到"落地生根"
🗄️ 读完本文你将收获:掌握 PGVector 持久化向量库的完整配置,学会 PDF 文档解析 + 动态上传入库,理解为什么生产环境的 RAG 知识库不能放内存。
一、问题:你会把自己写的文档存在内存里吗?
Day 3 我们实现了一个 Agent ------ AI 能调工具、能查知识库,看起来很完美。
但它藏了一个大坑:
启动服务 → 加载文档 → 存入 InMemoryEmbeddingStore(JVM 内存)
↓
服务重启(Ctrl+C)
↓
数据全部消失 😱InMemoryEmbeddingStore 就像草稿纸------一关机什么都没了。
正常的知识库应该是文件柜------存进去的东西,明天还在、下周还在、重启 N 次还在。
Day 4 要解决的就是这个:把草稿纸换成文件柜。
二、Day 3 → Day 4 变化一览
Day 3 Day 4
─────────────────────────────────────────────────
InMemoryEmbeddingStore → PgVectorEmbeddingStore
只支持 TXT → TXT + PDF + MD
classpath 固定文档 → 运行时上传 API
只读 → 可动态增删(上传)Agent 的逻辑没变,只换了"底座"。这也是 LangChain4j 最优雅的地方------你换存储引擎,Agent 接口一行不用改。
三、整体架构
┌──────────────────────────────────────────────────┐
│ AgentController │
│ GET /agent/chat?message=... │
└────────────────────┬─────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────┐
│ Agent (AiServices) │
│ │
│ ┌─────────────┐ ┌──────────┐ ┌─────────────┐ │
│ │ DeepSeek-V3 │ │ 工具集 │ │ 知识库(RAG) │ │
│ └─────────────┘ └──────────┘ └──────┬──────┘ │
│ │ │
│ ContentRetriever │
│ │ │
│ ┌───────────┴───────┐ │
│ │ PgVectorEmbedding│ │
│ │ Store (★持久化) │ │
│ └──────────┬────────┘ │
│ │ │
│ ┌────────────────────────┐ ┌───────┴───────┐ │
│ │ DocumentController │ │ PostgreSQL │ │
│ │ POST /documents/ │ │ + PGVector │ │
│ │ upload │ │ 扩展 (Docker) │ │
│ └────────────────────────┘ └───────────────┘ │
└──────────────────────────────────────────────────┘两条数据流入路线:
- 启动预加载 :
RagService把 classpath docs 文件写入 PGVector(首次) - 运行时上传 :
DocumentController→DocumentService→ 解析 → 向量化 → 写入 PGVector
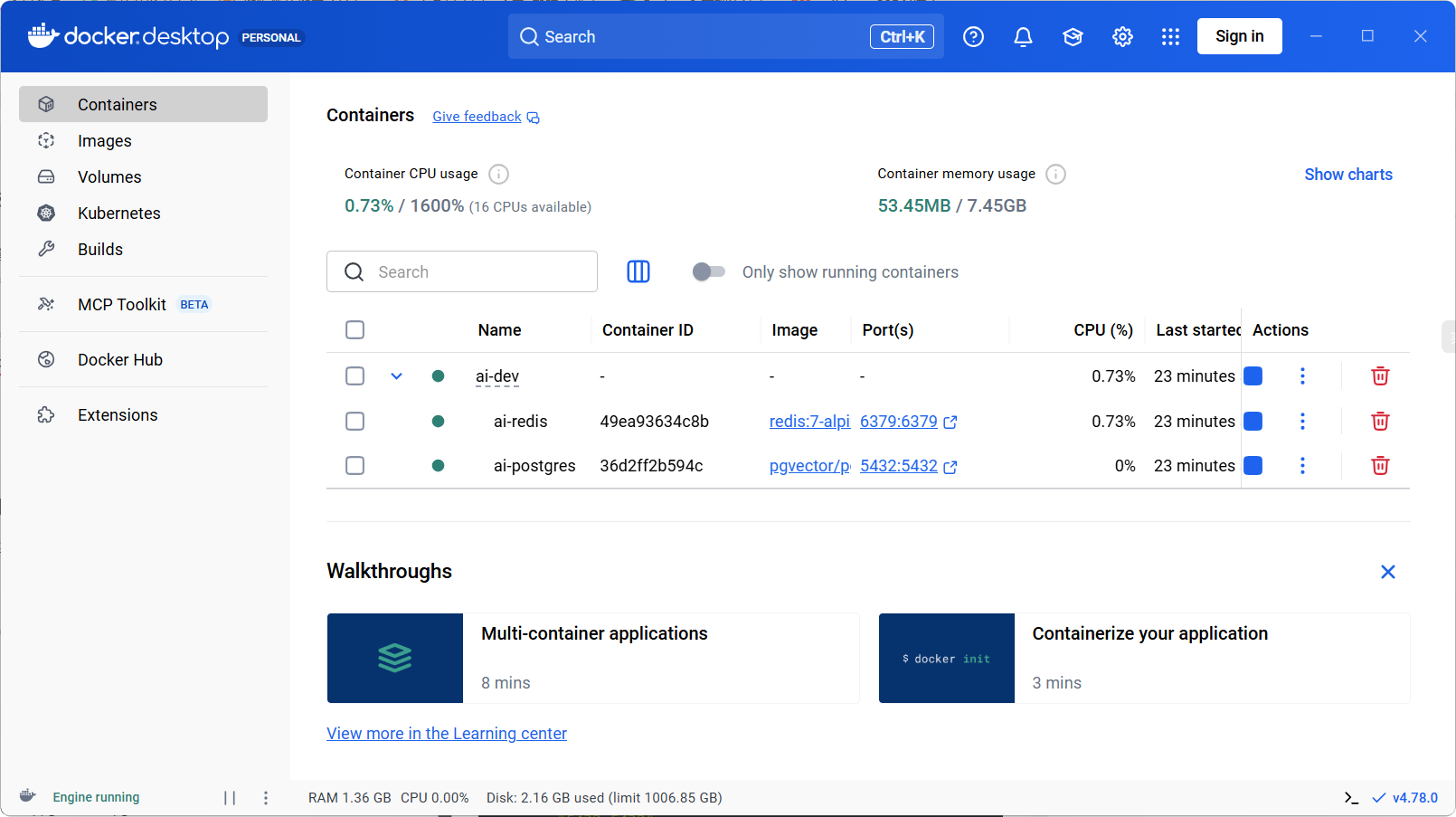
四、Docker 环境准备
docker环境准备的教程已经写好了,放在 day4/docs/windows-docker-wsl-setup.md
4.1 docker-compose.yml
yaml
version: "3.9"
services:
postgres:
image: pgvector/pgvector:pg17 # PGVector 扩展已内置
container_name: ai-postgres
restart: unless-stopped
ports:
- "5432:5432"
environment:
POSTGRES_DB: aidb
POSTGRES_USER: ai
POSTGRES_PASSWORD: password
volumes:
- pgdata:/var/lib/postgresql/data
redis:
image: redis:7-alpine
container_name: ai-redis
ports:
- "6379:6379"
volumes:
- redisdata:/data
volumes:
pgdata:
redisdata:4.2 启动
bash
docker compose up -d
docker ps | grep ai-postgres # 确认在跑⚠️ 关键 :
pgvector/pgvector:pg17镜像自带 PGVector 扩展,不需要手动CREATE EXTENSION vector;
五、核心代码解析
5.1 Maven 依赖 ------ Day 4 新增的三个
xml
<!-- PGVector 集成 -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-pgvector</artifactId>
<version>0.36.2</version>
</dependency>
<!-- PG 驱动 -->
<dependency>
<groupId>org.postgresql</groupId>
<artifactId>postgresql</artifactId>
</dependency>
<!-- PDF 解析 -->
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>3.0.3</version>
</dependency>5.2 ChatModelConfig ------ 核心变化
java
@Bean
public EmbeddingStore<TextSegment> embeddingStore() {
return PgVectorEmbeddingStore.builder()
.host("localhost") // PG 地址
.port(5432)
.database("aidb")
.user("ai")
.password("password")
.table("day4_rag_store") // 向量表名
.dimension(1024) // bge-large-zh-v1.5 输出 1024 维
.createTable(true) // 首次启动自动建表
.dropTableFirst(false) // 不删旧数据
.build();
}这就是 Day 4 最核心的一行代码变化。
对比 Day 3:
java
// Day 3
return new InMemoryEmbeddingStore<>();
// Day 4
return PgVectorEmbeddingStore.builder()...build();其余 ChatLanguageModel、StreamingChatLanguageModel、EmbeddingModel 三个 Bean 完全不变。
5.3 DocumentService ------ PDF 解析 + 动态入库
java
@Service
@RequiredArgsConstructor
public class DocumentService {
private final EmbeddingModel embeddingModel;
private final EmbeddingStore<TextSegment> embeddingStore;
/**
* 处理上传文件:解析文本 → 切片 → 向量化 → 入库
*/
public int ingest(MultipartFile file, String title, Path saveDir)
throws IOException {
// 1. 根据文件类型提取文本
String text = extractText(file);
// 2. 切片(与 Day 3 策略一致)
List<TextSegment> chunks = splitIntoChunks(title, text);
// 3. 批量向量化 + 写入 PGVector
var response = embeddingModel.embedAll(chunks);
embeddingStore.addAll(response.content(), chunks);
// 4. 保存原始文件到磁盘(便于追溯)
saveOriginal(file, saveDir);
return chunks.size();
}
/**
* PDF 文本提取(Apache PDFBox 3.x)
*/
private String extractPdfText(byte[] pdfBytes) throws IOException {
try (PDDocument document = Loader.loadPDF(pdfBytes)) {
PDFTextStripper stripper = new PDFTextStripper();
stripper.setSortByPosition(true); // 按坐标排序保持阅读顺序
return stripper.getText(document);
}
}
}PDFBox 为什么需要?
PDF 是二进制格式,不能当文本直接读。用记事本打开 PDF 看到的是乱码。PDFBox 负责解析 PDF 内部结构,提取出人类可读的文字。
⚠️ PDFBox 3.x 变化 :
Loader.loadPDF()替代了旧版PDDocument.load()。如果搜到旧教程用PDDocument.load(),那是 PDFBox 2.x 的写法,3.x 编译不通过。
5.4 DocumentController ------ 上传接口
java
@RestController
@RequestMapping("/documents")
@RequiredArgsConstructor
public class DocumentController {
private final DocumentService documentService;
@PostMapping("/upload")
public Map<String, Object> upload(
@RequestParam("file") MultipartFile file,
@RequestParam(value = "title", required = false) String title) {
int chunks = documentService.ingest(file, docTitle, Path.of(uploadDir));
return Map.of(
"success", true,
"title", docTitle,
"chunks", chunks,
"message", "文档入库成功,共 " + chunks + " 个切片"
);
}
}六、测试验证
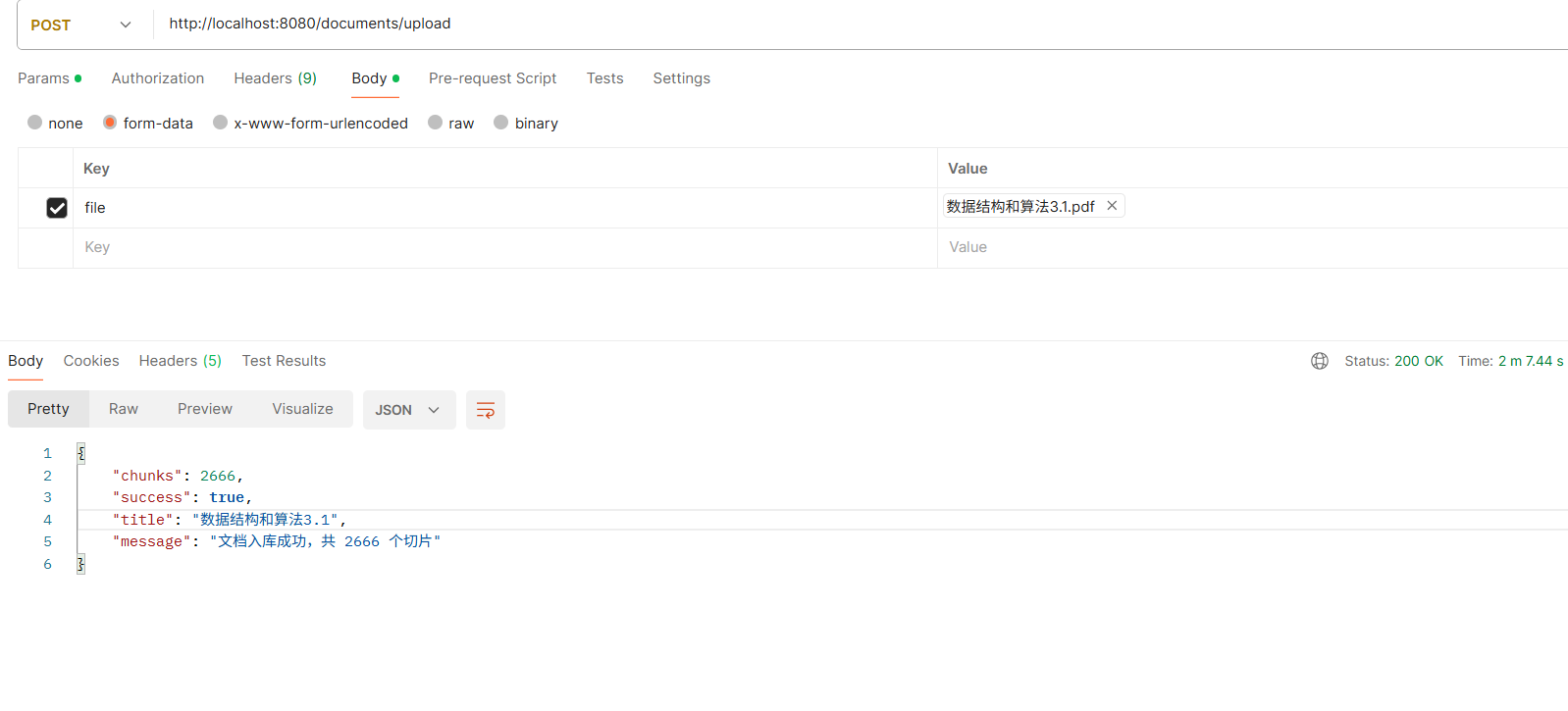
6.1 上传 文档
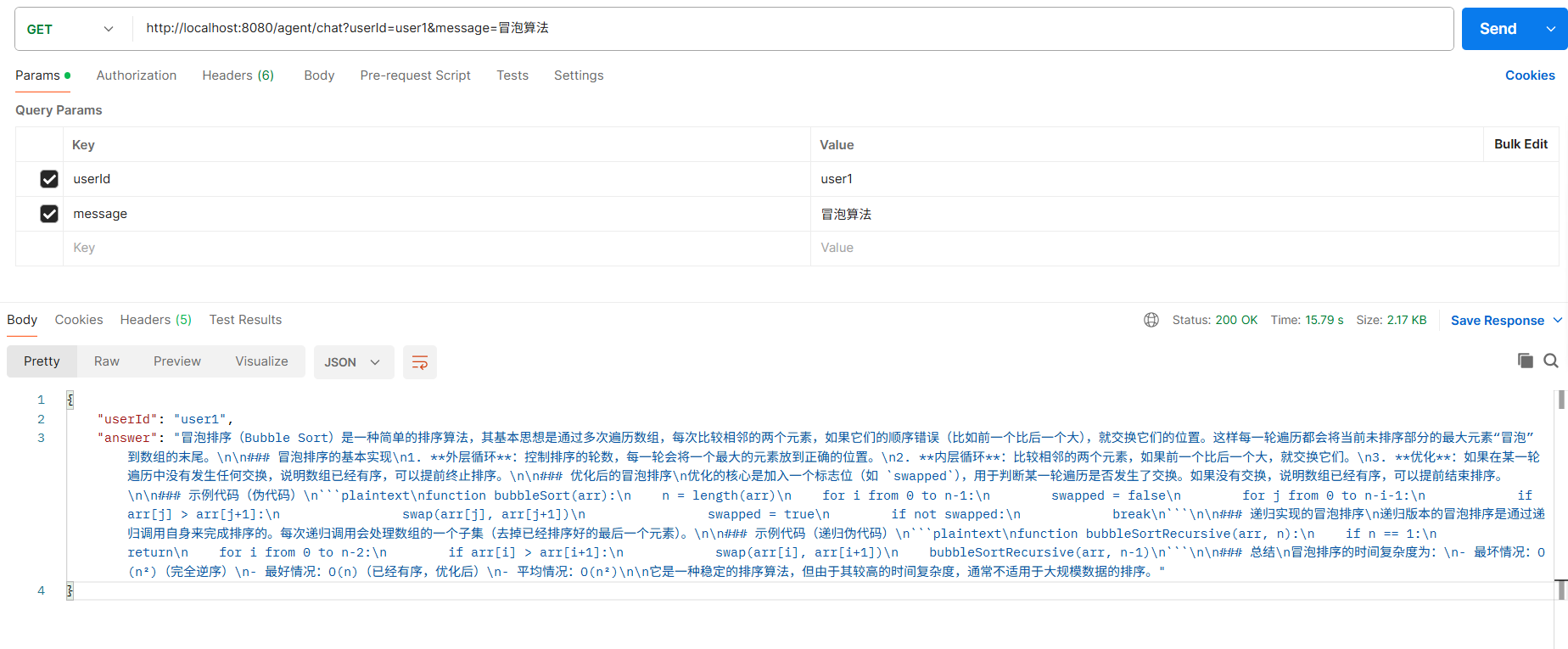
6.2 验证知识库已生效
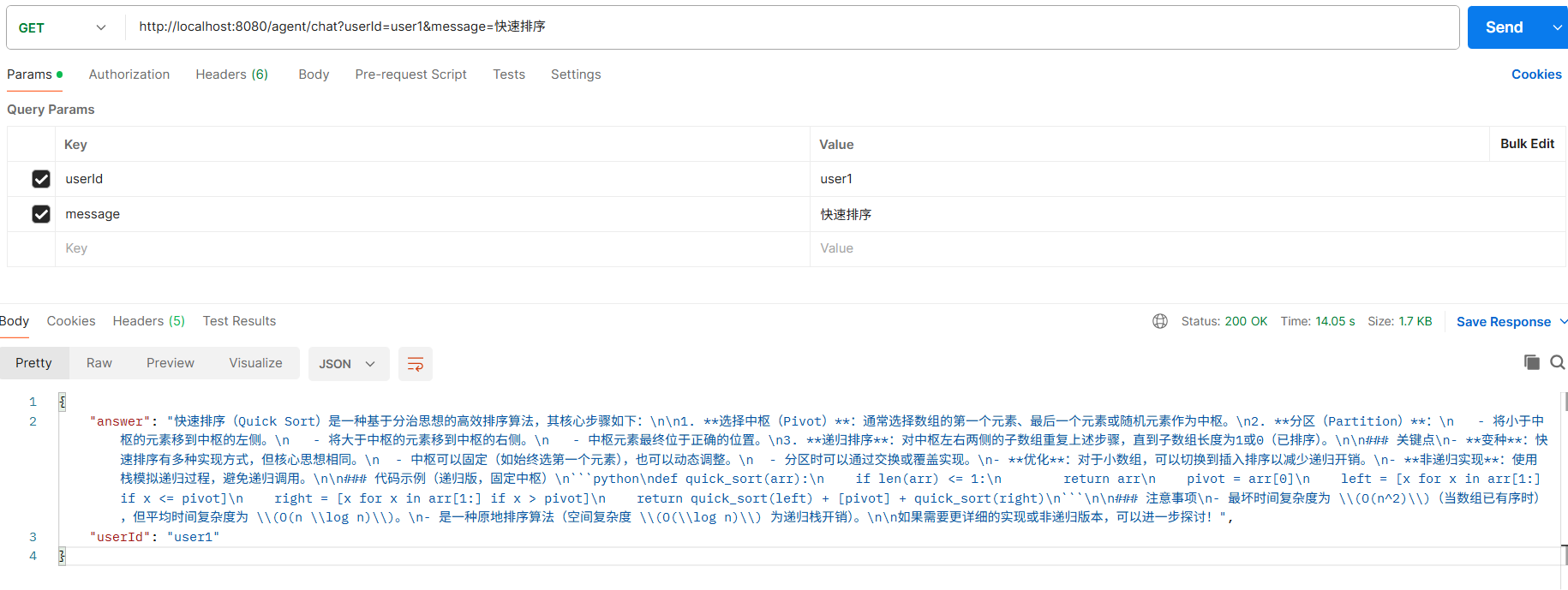
6.3 关键验证:重启后数据还在!
6.4 直接查数据库验证
bash
docker exec -it ai-postgres psql -U ai -d aidb
# 查看向量表结构
\d day4_rag_store
# 查看数据条数
SELECT COUNT(*) FROM day4_rag_store;
# 查看某条记录的文本
SELECT text FROM day4_rag_store LIMIT 1;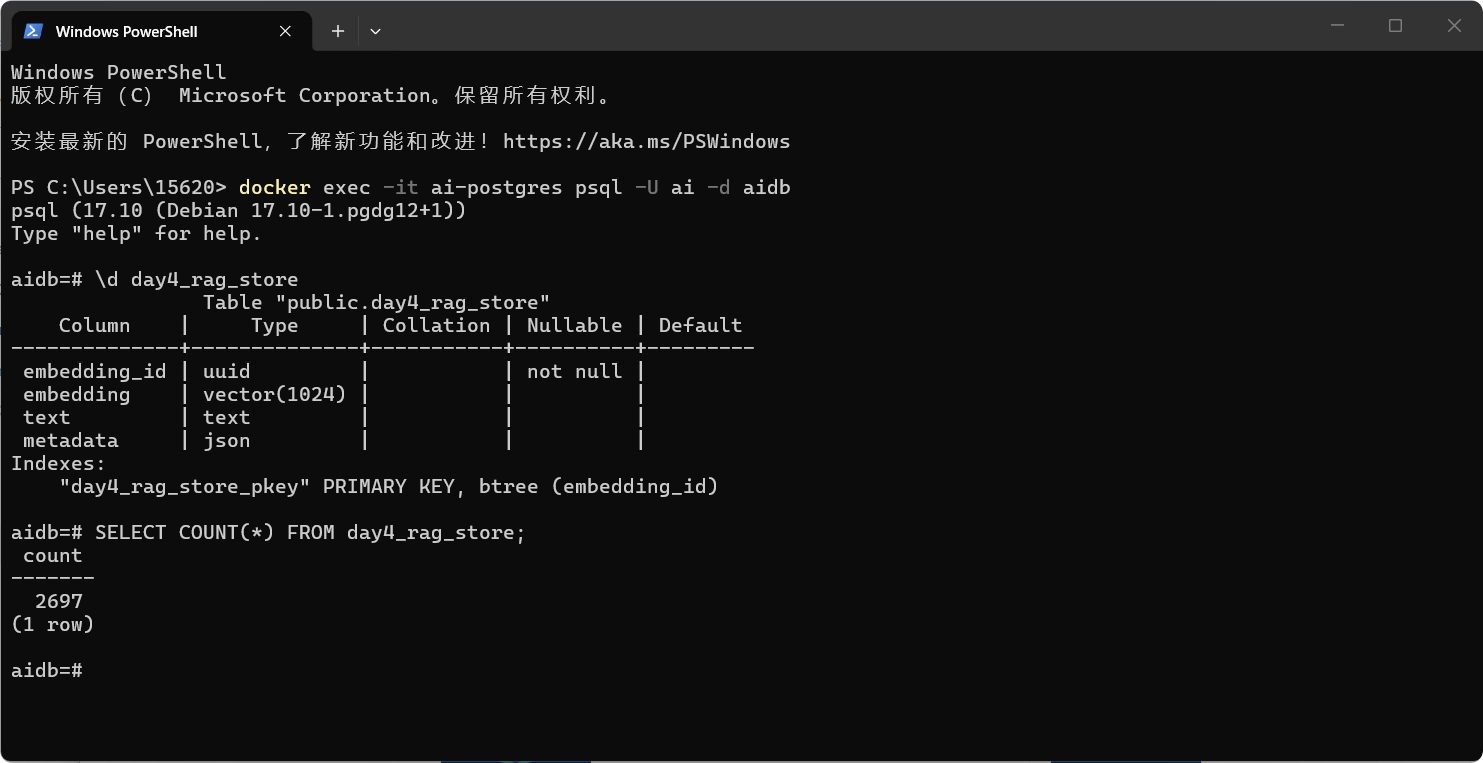
七、为什么 PGVector 比 InMemory 好?
| 维度 | InMemory | PGVector |
|---|---|---|
| 持久化 | ❌ 重启丢失 | ✅ 数据落地 |
| 并发 | 单机内存 | 数据库级 ACID |
| 备份 | 无 | pg_dump / WAL 归档 |
| 扩容 | 受限于 JVM 堆大小 | 磁盘空间 |
| 开发体验 | 零配置,开箱即用 | 需要 Docker |
| 适合场景 | PoC / 本地调试 | 生产环境 |
生产环境铁律:敏感数据不能靠内存。PGVector 让你从 Demo 到上线只改一行配置。
八、踩坑实录
坑 1:PGVector 扩展未启用
现象 :启动报 type "vector" does not exist
原因:普通 PostgreSQL 镜像没有安装 PGVector 扩展。
解决 :使用 pgvector/pgvector:pg17 镜像,扩展已内置。或者手动执行:
sql
CREATE EXTENSION IF NOT EXISTS vector;坑 2:dimension 不匹配
现象:入库报错,提示向量维度不一致。
原因 :配置文件写的 embedding-model-name 对应的模型输出维度与 dimension(1024) 不匹配。
解决 :BAAI/bge-large-zh-v1.5 输出 1024 维。如果换模型(如 bge-small-zh 是 512 维),对应改 dimension 参数,并删旧表重建。
坑 3:PDF 中文乱码
现象:PDF 解析出的中文是乱码。
原因:部分 PDF 使用了非标准字体编码。
解决 :PDFBox 的 PDFTextStripper 对大多数标准 PDF 处理良好。复杂排版建议加 OCR 流程(不在本文范围)。
坑 4:忘记先把 Docker 跑起来
现象 :启动服务报 Connection refused: localhost:5432
解决 :先 docker compose up -d,等 docker ps 确认容器 healthy 再启动服务。
九、总结
| Day | 知识库状态 | 能做什么 |
|---|---|---|
| Day 3 | 内存中,重启丢失 | 演示 Agent + RAG |
| Day 4 | PostgreSQL 持久化 | 生产可用,重启保留,动态上传 |
Day 4 最重要的三件事:
- Persistence > Memory:数据要落地,不能靠运气
- Dynamic > Static:知识库要在运行时活起来,不能只靠 classpath
- Abstraction wins:LangChain4j 的接口设计让你换存储引擎只改一行配置
📦 完整代码:https://gitee.com/jackXUYY/java-ai-learn/tree/master/day4
🐳 PGVector 镜像:https://hub.docker.com/r/pgvector/pgvector
📚 LangChain4j PGVector 文档:https://docs.langchain4j.dev/integrations/embedding-stores/pgvector