我试用过很多iOS端的HTTP抓包工具,都不支持捕获静态资源文件,或者说请求或响应Body大于某个阈值时请求就会被丢弃了。有时候想排查一个文件上传无权限问题,想抓包查看请求的完整url,看看用的哪个域名,找出对应的项目,但这都做不到。
我们在做ApiCatcher的过程中才了解,原来iOS操作系统会限制网络扩展进程的内存,从一些资料看,系统限制网络扩展进程最大只能使用50MB内存,超过的话进程会被系统kill掉。不过这个阈值可能跟操作系统版本有关,实际测试发现在用到80MB内存时,进程仍在正常工作。
因为存在内存限制,所以很多抓包工具都做了限制,都实现了各自的丢包策略,当请求Body或响应Body超过多大时就把请求丢掉了。
ApiCatcher是如何解决这个问题的呢?
考虑到一般静态资源文件都不会有重写请求/响应Body、以及执行脚本修改请求/响应Body的需求, 所以对于静态资源文件,没必要将请求/响应Body缓存到内存中, 我们用文件来存储请求/响应Body,只要是静态资源的请求或响应都把Body存到文件中。 将从NIO接收缓冲区读取到的字节数据直接写入文件,并转发出去,不做内存暂存。
因为一个大的HTTP数据包,到TCP层是会被拆包的,假设一个HTTP请求传输的文件是1MB, 但一个TCP数据包可能只有64KB,所以一个请求通过边读边写文件的方式,只会占用64KB的内存,而不是1MB。 当请求发送完毕,或响应接收完毕后,往数据库存入请求记录时,将这个文件的路径作为Body字段存储即可。
使用这个方案需要确保用户在删除请求记录时,找出请求/响应Body对应的文件删除,需要自己解决数据一致性问题。 这也是为什么ApiCatcher删除数据会慢一些,因为是一条条记录遍历删除的。 这也是一种取舍,但我们认为这种取舍是值得的,因为删除功能并不经常使用,一次删除的数据也不会很多,一万条数据5秒就能完成。
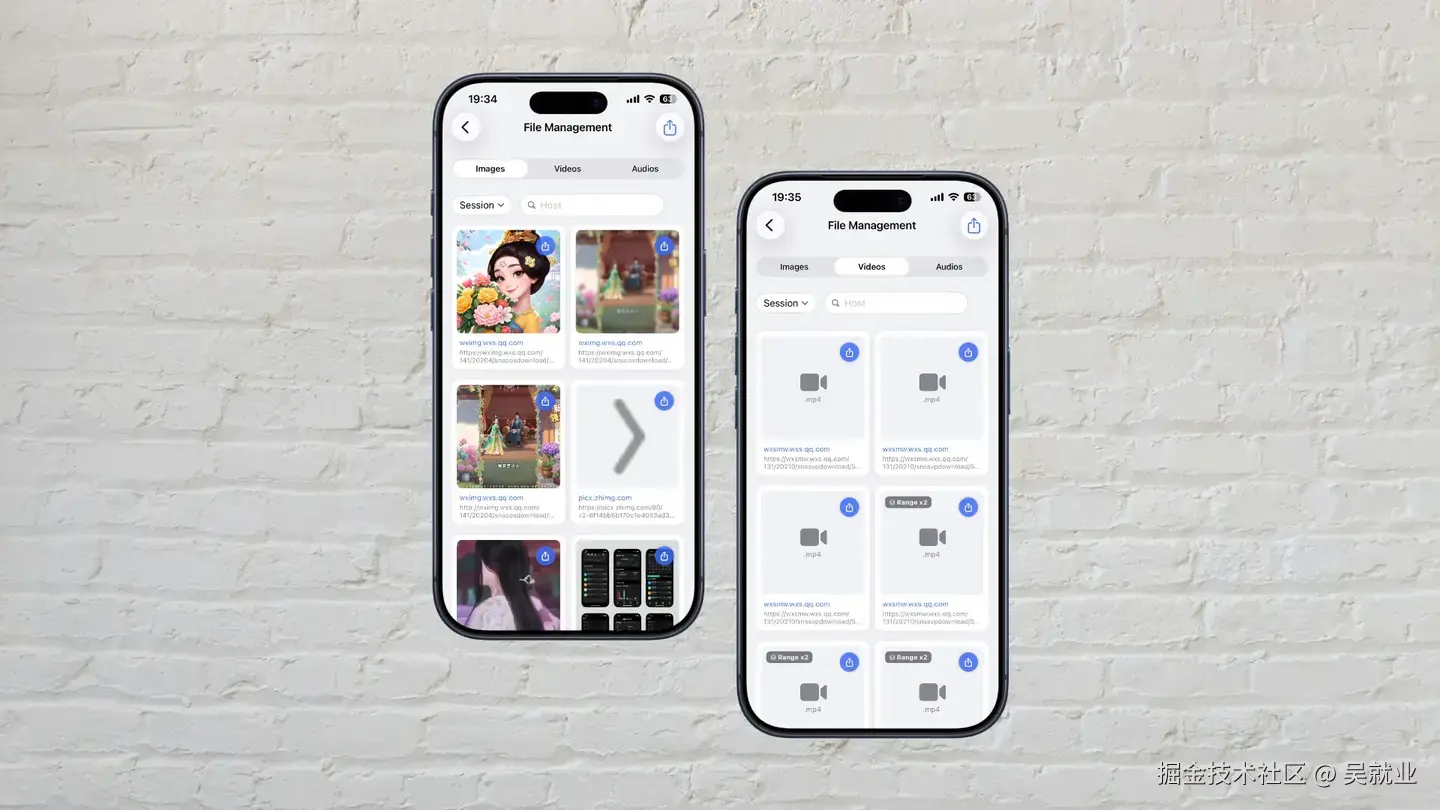
在支持捕获图片、视频、音频等文件之后,为了快速识别请求传输的内容, ApiCatcher支持图片、视频、音频的渲染,可以直接点击播放, 我们也专门为预览图片、视频、音频做了预览和批量导出页面, 方便提取导出测试素材文件。
我们在iOS、Windows & macOS三端上都应用了相同的实现原理,即便桌面端没有内存限制,更这样能获得更好的性能。