Nginx Log Analysis 技能创建总结
本文档记录 nginx-log-analysis 技能的完整创建过程、架构设计和核心机制,不包含具体代码实现。
具体SKILL能力代码可查看:https://gitee.com/ops-mx/nginx-log-analysis
前言
本次试验主要是为了测试SKILL生成过程,如何编写Prompt,如何设计SKILL,如何管理SKILL目录。日志分析会消耗大量的token,请谨慎用于生产环境 。文章分为人工、AI两部分,人工部分主要是Prompt内容及编写心得,AI部分主要是按照Prompt的自动输出及能力介绍。
本次试验环境:windows11、qoder、python-3.13.14。
另外如果Qoder使用私有账号,可能需要付费购买credit。详情参考Qoder官网:https://qoder.com/pricing
人工部分
Prompt编写
1.首次编写
创建一个nginx日志分析的skill,具体要求:
①能够统计http各状态码的数量
②能够统计QPS等关键指标
③能够统计各代理的访问次数及时间
④能够统计访问来源,包括:浏览器,命令行等
⑤能够统计http请求类型及次数
⑥能够统计各IP地址的访问次数
nginx日志格式已给出,请参考D:\Project\SRE Agent SKILL\.qoder\skills\nginx-log-analysis\log_main.conf
日志分析用python语言
你还可以根据已给出的nginx日志格式补充其他的日志分析能力。
skill要有主入口文件,其他各统计能力需要单独生成,以免上下文太大。最后生成skill放在D:\Project\SRE Agent SKILL\.qoder\skills\nginx-log-analysis目录下,通过调用nginx-log-analysis就能实现日志分析
新建一个目录,名称为"log-format",主要是存放nginx日志格式配置文件,这个目录放在nginx-log-analysis下,并将现有的nginx日志配置格式文件全部迁移到这个目录下2.二次优化
入口skill文件补充内容如下:
①可根据自然语言要求执行对应的分析指令。
②nginx日志会有多种格式,需要人工维护,每个日志格式配置会有自己的名称单独存放在.log-format下。这一点非常重要,要提醒客户维护好nginx日志格式配置文件,日志格式配置名称由客户自己定义。
③在执行分析的时候需要列出格式名称供客户选择。
④在解析过程中如果日志格式跟日志文件不匹配,直接终止解析,说明终止原因并提醒客户选择正确的日志格式配置文件。
⑤如果客户使用的日志格式没有对应的解析脚本,那根据客户需要生成新的python解析脚本,并放在script目录下。
以上补充内容放在入口skill文件的合适位置。
根据nginx-log-analysis的整体能力、使用方法、注意事项,生成一个readme文件。为什么要分两次来写Prompt,因为第一次考虑不周到,这个算是一个入门的过程,也说明了SKILL是可以随时调整优化的。
Prompt的编写直接会反应出开发者对业务、环境、中间件配置的熟悉程度,所以提升技术还是很有必要的。
编写心得
明确需求
大模型喜欢有条理的明确需求,所以在编写Prompt的时候可以直接将所有需求按顺序罗列出来,且需要言简意赅。
安全管控
安全管控的整体思想:严进宽出。初期使用SKILL建议严格把控安全边界,以防止大模型出现幻觉、误操作等。具体措施可参考以下内容:
①所有命令行操作都应需要二次确认
②所有写操作都应需要二次确认
③生产环境的变更操作应需要二次确认,如果有审批流程需要接入对应的审批流
目录管理
Agent在调用SKILL的时候是全量读,为了防止上下文过大,应该将文件目录做成总---分 的结构,一个总入口SKILL文件,再路由到对应的脚本或者SKILL文件
异常处理
碰到异常或者能力不匹配时,要明确哪些直接停止工作,哪些可以优化。本次试验中在log_format和日志内容不匹配时,会进行对应的操作。对应章节:AI部分-5. 日志格式配置管理机制
可扩展
要求SKILL必须有自我迭代或者更新的能力,以适应复杂环境和需求
以上是自我总结的一点心得体会,如有异议可在评论区补充。
基本上按照这样的思路编写Prompt,总体问题不大
AI部分
Prompt编写完后,Qoder会自动生成SKILL、python脚本等文件。生成的文件可以直接在Qoder-Editor 模式下调用,如下图:
分析QPS测试
命令行执行等待确认执行
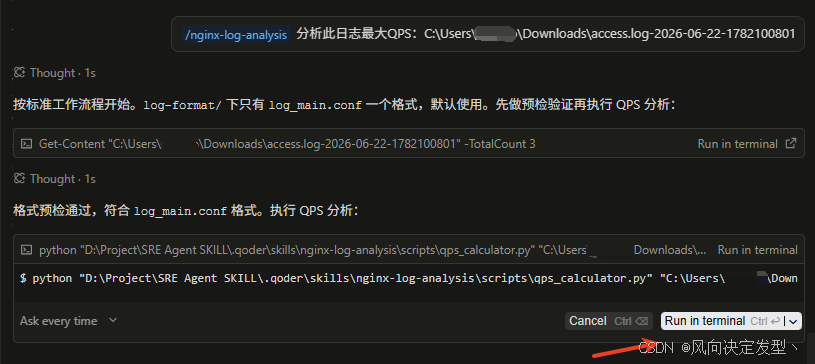
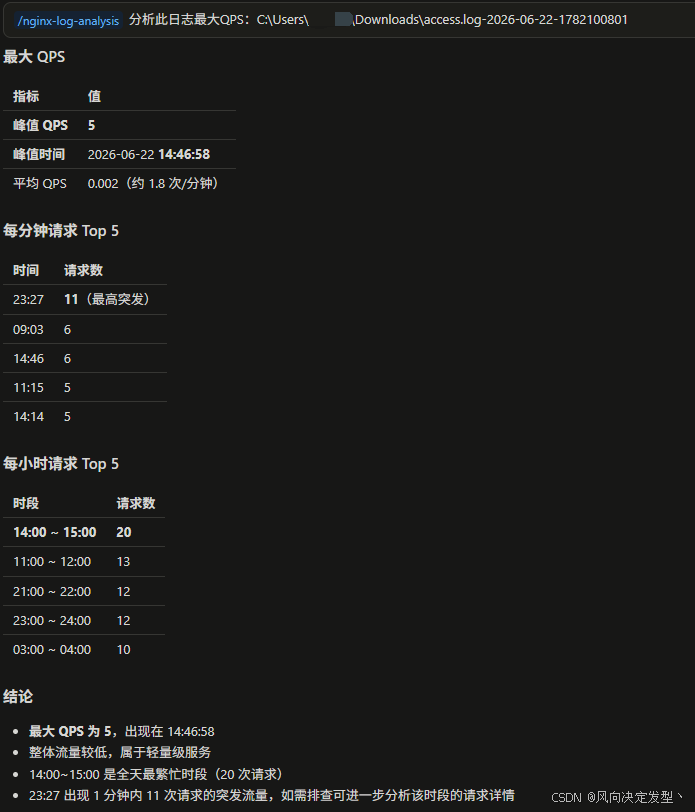
分析结果输出如下:
生成的SKILL内容下面进行详细介绍
1. 核心功能概述
nginx-log-analysis 是一个 Qoder Agent 技能,用于分析 Nginx 访问日志并提取关键运维指标。
核心能力:
- HTTP 状态码分布统计(200/404/500 等,按 2xx/3xx/4xx/5xx 分类)
- QPS 性能指标计算(平均 QPS、峰值 QPS、每分钟 Top10、每小时分布)
- User-Agent 访问排行
- 客户端类型分类(浏览器/移动端/命令行/爬虫/移动应用)
- HTTP 请求方法分布(GET/POST/PUT/DELETE 等)
- IP 地址访问频率与疑似攻击源识别
- 响应体大小统计(带宽、P50/P95/P99 百分位)
- Referer 流量来源分析(直接访问/搜索引擎/社交媒体/外部站点)
- 全量分析(一次遍历输出所有指标)
设计原则:
- 零外部依赖:所有脚本仅使用 Python 标准库
- 模块化架构:每项分析能力独立为一个脚本,按需加载
- 自然语言驱动:用户用自然语言描述需求,Agent 自动路由到对应脚本
- 多格式支持:通过配置文件管理不同业务/环境的日志格式
2. 目录结构说明
nginx-log-analysis/
├── SKILL.md # 技能入口文件(Agent 加载的主文件)
├── README.md # 面向用户的完整使用文档
├── log-format/ # 日志格式配置文件目录
│ └── log_main.conf # 示例:nginx log_format main
└── scripts/ # 分析脚本目录
├── log_parser.py # 共享解析模块
├── full_analysis.py # 全量分析入口
├── status_code_analyzer.py # 状态码统计
├── qps_calculator.py # QPS 计算
├── user_agent_analyzer.py # User-Agent 排行
├── client_type_analyzer.py # 客户端分类
├── http_method_analyzer.py # 请求方法分布
├── ip_analyzer.py # IP 分析
├── response_size_analyzer.py # 响应体大小
└── referer_analyzer.py # Referer 来源各目录职责:
| 目录/文件 | 职责 | 维护者 |
|---|---|---|
SKILL.md |
Agent 加载的主入口,定义技能描述、工作流程、指令路由表 | 开发者 |
README.md |
面向用户的完整使用文档 | 开发者 |
log-format/ |
存放 nginx 日志格式配置文件,每个文件对应一种日志格式 | 用户 |
scripts/ |
所有 Python 分析脚本,每项能力独立一个文件 | 开发者/Agent(动态生成) |
scripts/log_parser.py |
共享解析模块,所有分析脚本依赖此模块 | 开发者 |
3. 各脚本文件功能介绍
共享模块
| 文件 | 功能 |
|---|---|
log_parser.py |
核心解析模块。根据日志格式配置中的变量定义,构建正则表达式,将每行日志解析为结构化字典。提供 parse_line()、iter_log()、get_top_n() 等公共函数,被所有分析脚本导入使用 |
分析脚本
| 文件 | 功能 | 输出格式 |
|---|---|---|
full_analysis.py |
全量分析入口。一次遍历日志文件,同时计算所有指标,避免多次 I/O。适用于首次分析或全面了解日志状况 | JSON,包含 summary/qps/status_codes/http_methods/top_ips/client_types/referer/response_size 等字段 |
status_code_analyzer.py |
状态码统计。统计各 HTTP 状态码的精确数量,按 2xx/3xx/4xx/5xx 分组,计算 4xx 和 5xx 错误率 | JSON,包含 status_codes/status_classes/error_rate_4xx/error_rate_5xx |
qps_calculator.py |
QPS 计算。计算平均 QPS(总请求/时间跨度)、峰值 QPS(每秒最大请求数)、每分钟 Top10、每小时分布 | JSON,包含 avg_qps/peak_qps/peak_qps_time/per_minute_top10/per_hour_distribution |
user_agent_analyzer.py |
UA 排行。统计各 User-Agent 字符串的访问次数,输出 Top N 排行 | JSON,包含 unique_user_agents/top_user_agents |
client_type_analyzer.py |
客户端分类。通过正则规则将 User-Agent 分类为 browser/mobile_browser/cli_tool/crawler/mobile_app/unknown | JSON,包含 client_types 各类别的 count 和 percentage |
http_method_analyzer.py |
请求方法分布。统计 GET/POST/PUT/DELETE 等 HTTP 方法的数量和占比 | JSON,包含 http_methods 各方法的 count 和 pct |
ip_analyzer.py |
IP 分析。统计各 IP 访问次数,识别疑似攻击源(占比 >5% 或请求 >1000 次) | JSON,包含 unique_ips/top_ips/suspicious_ips |
response_size_analyzer.py |
响应体大小。统计 body_bytes_sent 的总带宽、平均值、最大值、P50/P95/P99 百分位、按大小桶分布 | JSON,包含 total_bandwidth/avg_size/percentiles/size_distribution |
referer_analyzer.py |
Referer 来源。将流量分类为 direct/search_engine/social_media/external_site,统计 Top 来源域名 | JSON,包含 referer_types/top_referer_domains |
公共参数
所有脚本接受以下参数:
- 必需:日志文件路径(第一个参数)
- 可选 :
--top N(默认 20)控制输出条目数
所有脚本输出 JSON 格式到 stdout。
4. 主要部署步骤总结
Step 1: 创建目录结构
nginx-log-analysis/
├── SKILL.md
├── log-format/
└── scripts/Step 2: 编写 SKILL.md 入口文件
SKILL.md 是 Agent 加载的主文件,包含:
- YAML frontmatter(name + description):Agent 通过 description 决定何时激活此技能
- 目录结构说明
- 日志格式配置管理规则
- 自然语言指令路由表
- 标准工作流程(6 个 Step)
- 动态脚本生成规则
- 分析能力索引表
Step 3: 实现共享解析模块 log_parser.py
log_parser.py 是整个系统的核心:
- 根据 nginx
log_format指令中的变量顺序,构建正则表达式 - 提供
parse_line(line)函数:将单行日志解析为结构化字典 - 提供
iter_log(filepath)函数:逐行迭代解析日志文件(内存友好) - 提供
get_top_n(counter, n)工具函数
Step 4: 逐个实现分析脚本
每个分析脚本遵循统一模式:
- 导入
log_parser模块 - 定义
analyze(filepath, top_n)函数 - 遍历日志条目,使用
Counter统计目标指标 - 组装结果字典
if __name__ == '__main__'中处理命令行参数并输出 JSON
Step 5: 实现全量分析脚本 full_analysis.py
full_analysis.py 将所有分析逻辑合并到一次遍历中:
- 在同一个
for entry in iter_log()循环内同时更新所有 Counter - 避免多次 I/O 读取,大幅提升大文件分析效率
- 输出包含所有指标字段的完整 JSON
Step 6: 配置日志格式管理
- 创建
log-format/目录 - 放入示例配置文件
log_main.conf - 在 SKILL.md 中定义命名规范和管理规则
Step 7: 编写 README.md
生成面向用户的完整使用文档,覆盖功能说明、使用方法、常见问题、最佳实践。
5. 日志格式配置管理机制
设计背景
Nginx 日志格式因业务和环境不同会有多种变体。硬编码单一格式会导致兼容性问题。因此引入配置文件机制,将格式定义与解析逻辑解耦。
管理机制
| 要素 | 说明 |
|---|---|
| 存储位置 | log-format/ 目录,所有 .conf 文件集中存放 |
| 命名规范 | {业务线}_{环境}_{格式名}.conf,如 mse_production_log_main.conf |
| 文件内容 | 包含完整的 nginx log_format 指令 |
| 维护责任 | 由用户负责维护,需与实际 nginx 配置保持一致 |
运行时流程
- Agent 读取
log-format/目录,列出所有.conf文件 - 用户选择本次使用的格式配置
- Agent 读取配置文件,提取
log_format中的变量定义 - 与
log_parser.py的正则进行匹配校验 - 用日志文件前 5 行做预检:匹配则继续,不匹配则终止并提示
格式不匹配处理
如果预检失败,Agent 立即终止解析,输出:
- 所选格式名称
- 实际日志样本(前几行)
- 终止原因
- 建议用户重新选择或新增格式配置
动态脚本生成
如果用户的格式配置在 log-format/ 中存在,但 scripts/ 下没有适配的解析脚本:
- Agent 读取格式配置,提取变量列表
- 根据变量顺序构建对应的正则表达式
- 基于
log_parser.py的模式生成新的解析脚本 - 自动保存到
scripts/目录
6. 自然语言指令路由机制
设计目标
用户无需记忆脚本名称和参数,只需用自然语言描述需求,Agent 自动路由到对应分析脚本。
路由表
| 用户自然语言 | 自动匹配脚本 |
|---|---|
| "分析访问量最高的 IP" | ip_analyzer.py |
| "统计 404 错误页面" | status_code_analyzer.py |
| "查看 QPS 趋势" | qps_calculator.py |
| "看看都是什么浏览器在访问" | client_type_analyzer.py |
| "统计 GET 和 POST 请求占比" | http_method_analyzer.py |
| "分析流量来源" | referer_analyzer.py |
| "看看响应体大小分布" | response_size_analyzer.py |
| "哪些 User-Agent 访问最多" | user_agent_analyzer.py |
| "全面分析这个日志" / "看看整体情况" | full_analysis.py |
路由流程
用户输入自然语言
│
▼
Agent 识别关键词(IP/状态码/QPS/浏览器/方法/来源/响应体/UA/全部)
│
▼
匹配路由表,确定目标脚本
│
▼
执行标准工作流程(确认路径 → 选择格式 → 预检验证 → 执行脚本 → 展示结果)扩展机制
路由表定义在 SKILL.md 中,新增分析能力时只需:
- 在
scripts/下添加新脚本 - 在 SKILL.md 的路由表和分析能力表中补充对应条目
- Agent 即可自动识别并路由
附录:标准工作流程
Step 1: 收集日志文件路径 → 确认文件存在
Step 2: 列出 log-format/ 下可用格式 → 用户选择
Step 3: 读取格式配置 → 构建解析器
Step 4: 格式匹配验证 → 前 5 行预检(不匹配则终止)
Step 5: 识别用户意图 → 路由到对应脚本执行
Step 6: 结果展示 → JSON 解析后以表格/列表呈现