本文基于
agent/stateless目录下的设计笔记与 Demo 项目,系统性地梳理无状态(Stateless)架构在大模型应用中的核心原理、工程演进路径及实践方案。
目录
- [引言:LLM 调用的本质是什么?](#引言:LLM 调用的本质是什么? "#1-%E5%BC%95%E8%A8%80llm-%E8%B0%83%E7%94%A8%E7%9A%84%E6%9C%AC%E8%B4%A8%E6%98%AF%E4%BB%80%E4%B9%88")
- 无状态架构深度解析
- [LLM 无状态运行机制](#LLM 无状态运行机制 "#3-llm-%E6%97%A0%E7%8A%B6%E6%80%81%E8%BF%90%E8%A1%8C%E6%9C%BA%E5%88%B6")
- 工程化三阶段演进
- [ChatHistory 的挑战与对策](#ChatHistory 的挑战与对策 "#5-chathistory-%E7%9A%84%E6%8C%91%E6%88%98%E4%B8%8E%E5%AF%B9%E7%AD%96")
- [实践:Demo 项目剖析](#实践:Demo 项目剖析 "#6-%E5%AE%9E%E8%B7%B5demo-%E9%A1%B9%E7%9B%AE%E5%89%96%E6%9E%90")
- 总结与展望
1. 引言:LLM 调用的本质是什么?
在讨论无状态架构之前,我们需要回到一个最根本的问题:调用大模型(LLM)接口的本质是什么?
答案出奇地简单:
ini
调用 LLM = HTTP 请求 → 消耗算力 → 生成结果这不是魔法,就是一次标准的 HTTP 调用。OpenAI、Claude、Gemini ------ 所有主流 LLM 服务商提供的都是基于 HTTP 协议的 RESTful API。理解了这一点,就理解了为什么无状态(Stateless)是 LLM 服务端架构的唯一正确选择。
核心需求:高并发 + 高可用 → 后端必须支持无状态(Stateless)
2. 无状态架构深度解析
2.1 什么是无状态?
无状态的概念最早来源于 HTTP 协议本身 。HTTP 是一个天然的无状态协议: 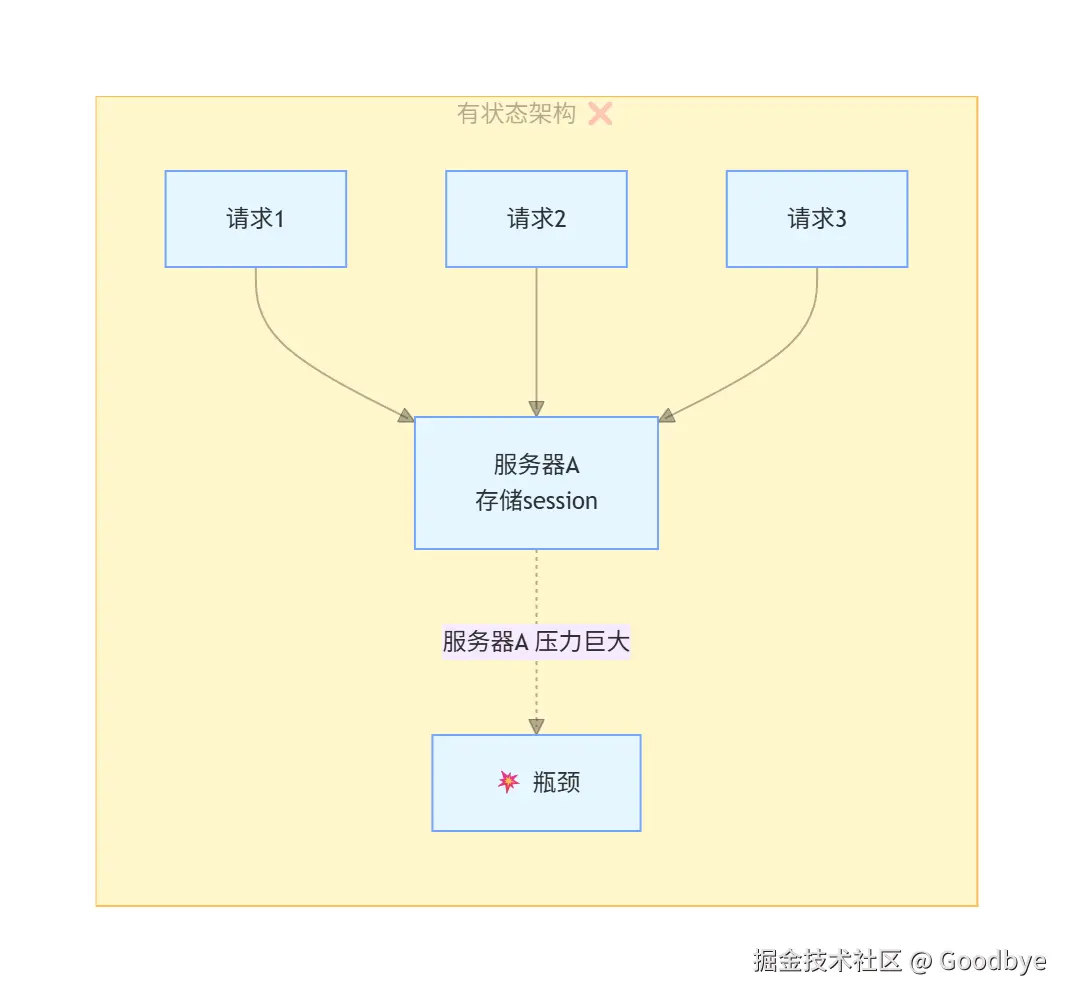
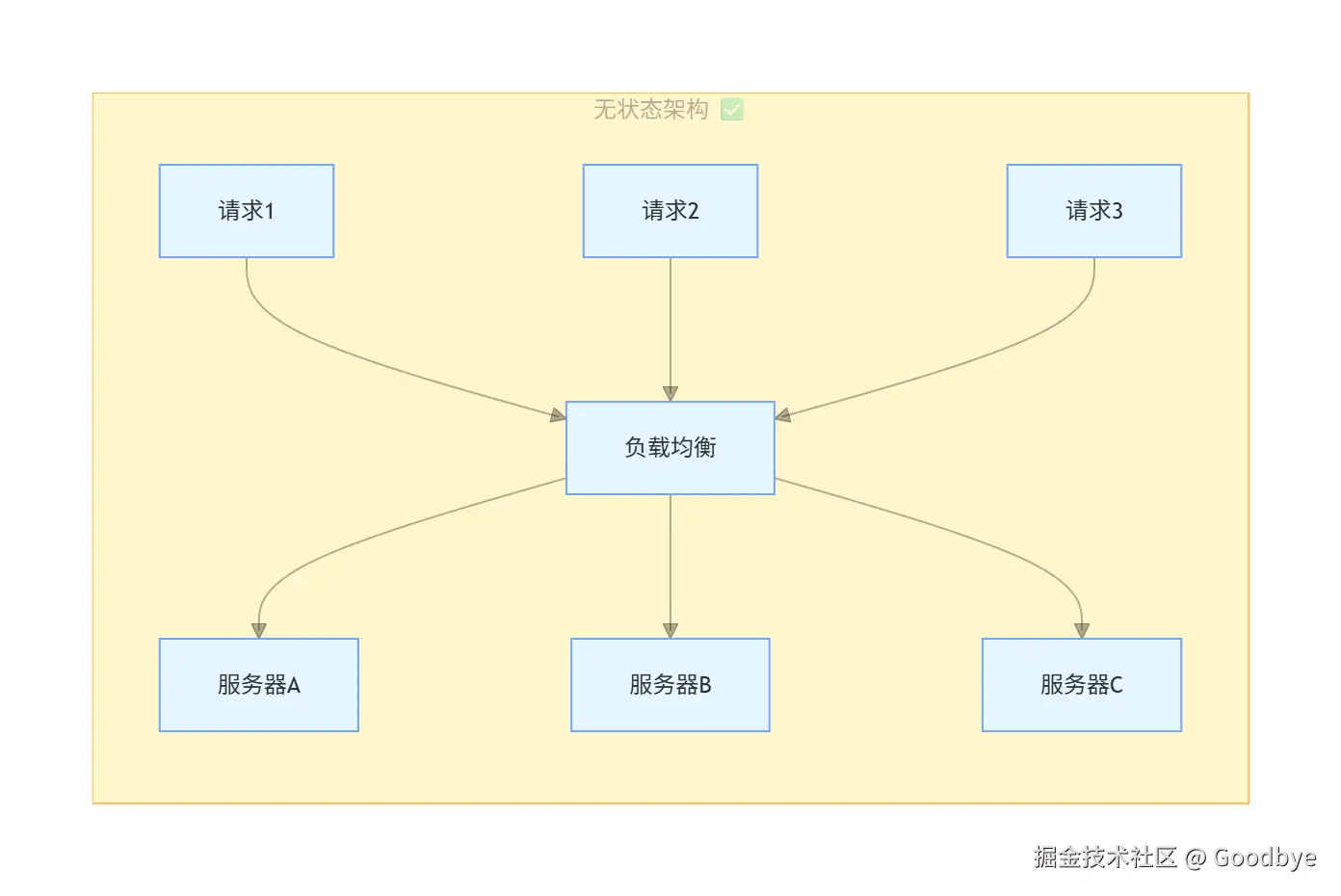 无状态的核心特征:
无状态的核心特征:
| 特征 | 说明 |
|---|---|
| 每次请求独立 | 不依赖于之前的请求 |
| 服务器不存储客户端状态 | 身份信息通过 Header 传递(Cookie / Authorization) |
| 所有人都公平 | 没有"特殊"的连接,每个请求被平等对待 |
| 水平扩展友好 | 任何服务器都可以处理任何请求 |
2.2 有状态 vs 无状态:为什么 LLM 不能有状态?
如果 LLM 服务采用有状态架构会发生什么?
css
有状态模式(不可行):
用户A → 始终路由到 GPU-01 → GPU-01 维护用户A的上下文
用户B → 始终路由到 GPU-02 → GPU-02 维护用户B的上下文
用户C → 始终路由到 GPU-01 → GPU-01 压力过大!
问题:
1. 服务器需要记住"你是谁",内存压力巨大
2. GPU 资源无法弹性分配
3. 单点故障导致会话丢失
4. 无法水平扩展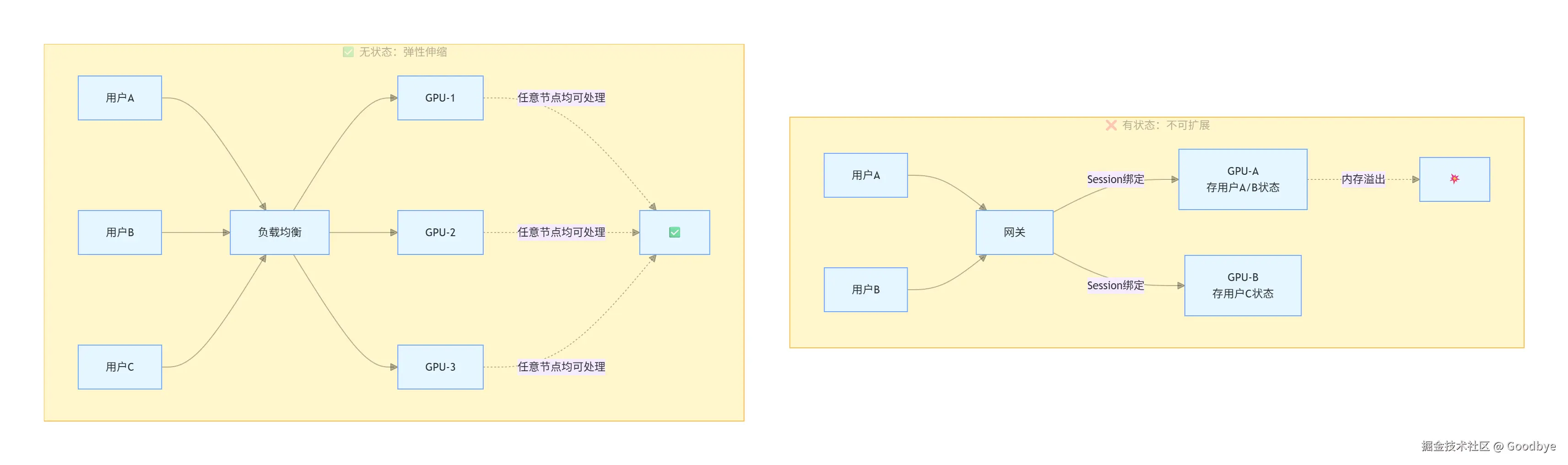
关键结论:LLM 服务器压力太大了,绝不能让它维护会话状态。无状态让服务器可以水平扩展,因为每个请求都是独立的。
3. LLM 无状态运行机制
3.1 核心规则
LLM 基于 HTTP 的无状态运行遵循两条简单规则:
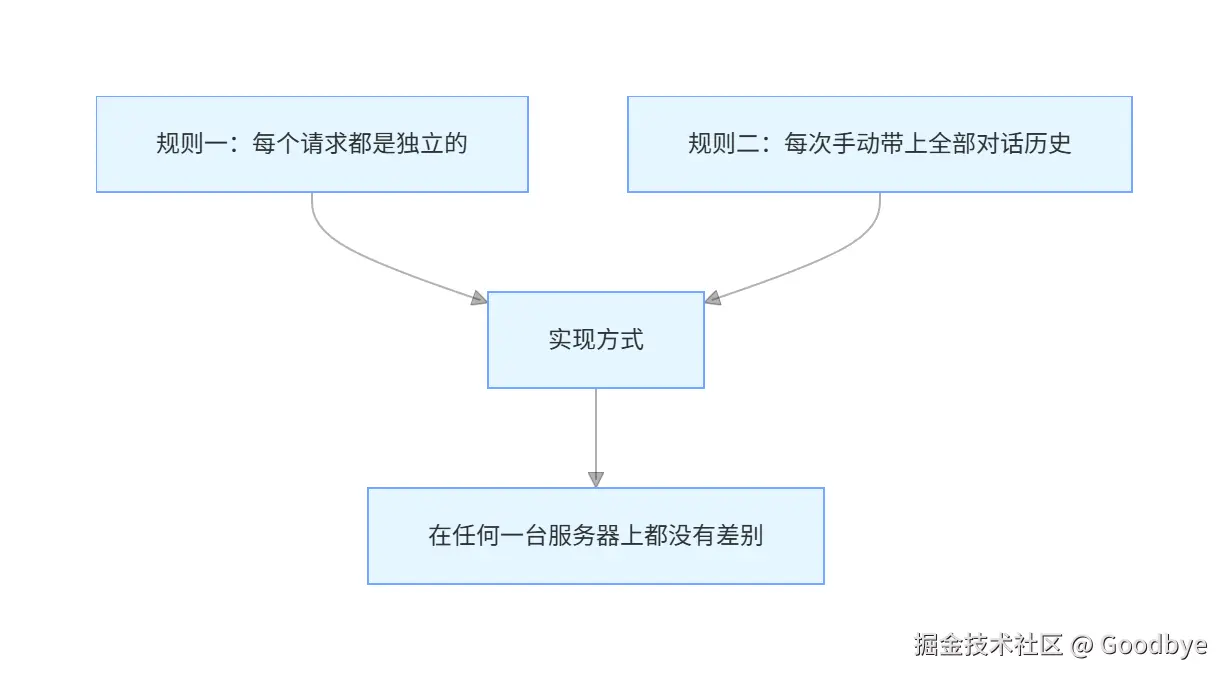
3.2 具体实现:把全部对话塞进一个请求
这是 LLM 无状态架构最精妙的设计 ------ 客户端负责维护对话历史,每次请求时把完整上下文发送给服务端:
json
// 第一次请求
{
"messages": [
{ "role": "user", "content": "解释什么是量子计算" }
]
}
// 第二次请求 ------ 把上一轮的回复也带上
{
"messages": [
{ "role": "user", "content": "解释什么是量子计算" },
{ "role": "assistant", "content": "量子计算是利用量子力学..." },
{ "role": "user", "content": "能用简单例子说明吗?" }
]
}
// 第 N 次请求 ------ 携带完整的上下文链
{
"messages": [
{ "role": "user", "content": "解释什么是量子计算" },
{ "role": "assistant", "content": "量子计算是利用量子力学..." },
{ "role": "user", "content": "能用简单例子说明吗?" },
{ "role": "assistant", "content": "当然,想象一下硬币..." },
// ... 更多历史消息
{ "role": "user", "content": "这和传统计算机的区别是什么?" }
]
}这就是"尝试让大模型 LLM 懂我们"的底层机制 ------ 不是服务器记住了你,而是你每次都把"记忆"重新讲给它听。
4. 工程化三阶段演进
从调用 LLM 到构建生产级 AI 应用,工程化经历了三个阶段的演进:
4.1 第一阶段:Prompt Engineering(提示词工程)
早期的 AI 应用以单轮或简单多轮对话为核心。开发者通过精心设计的 Prompt 来引导模型行为:
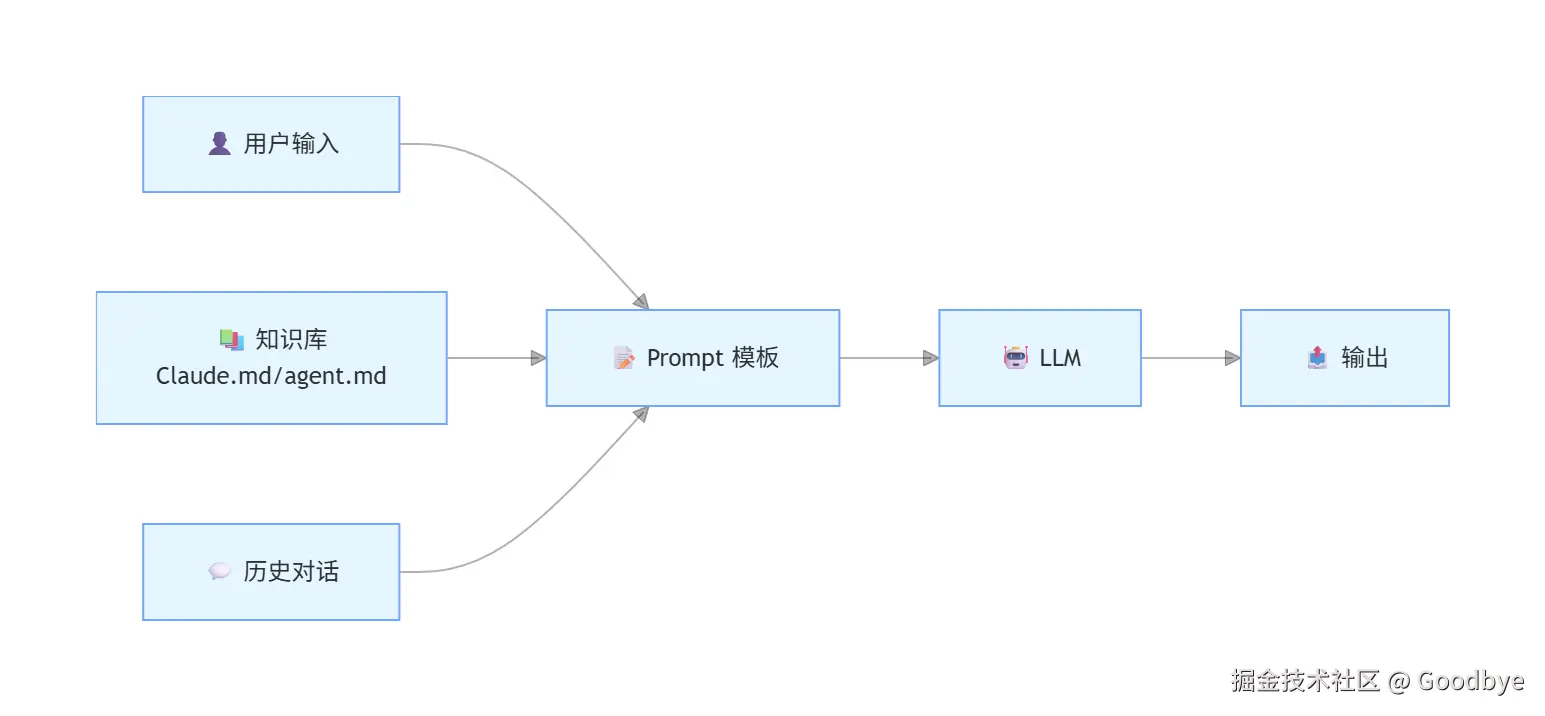
4.2 第二阶段:Context Engineering(上下文工程)
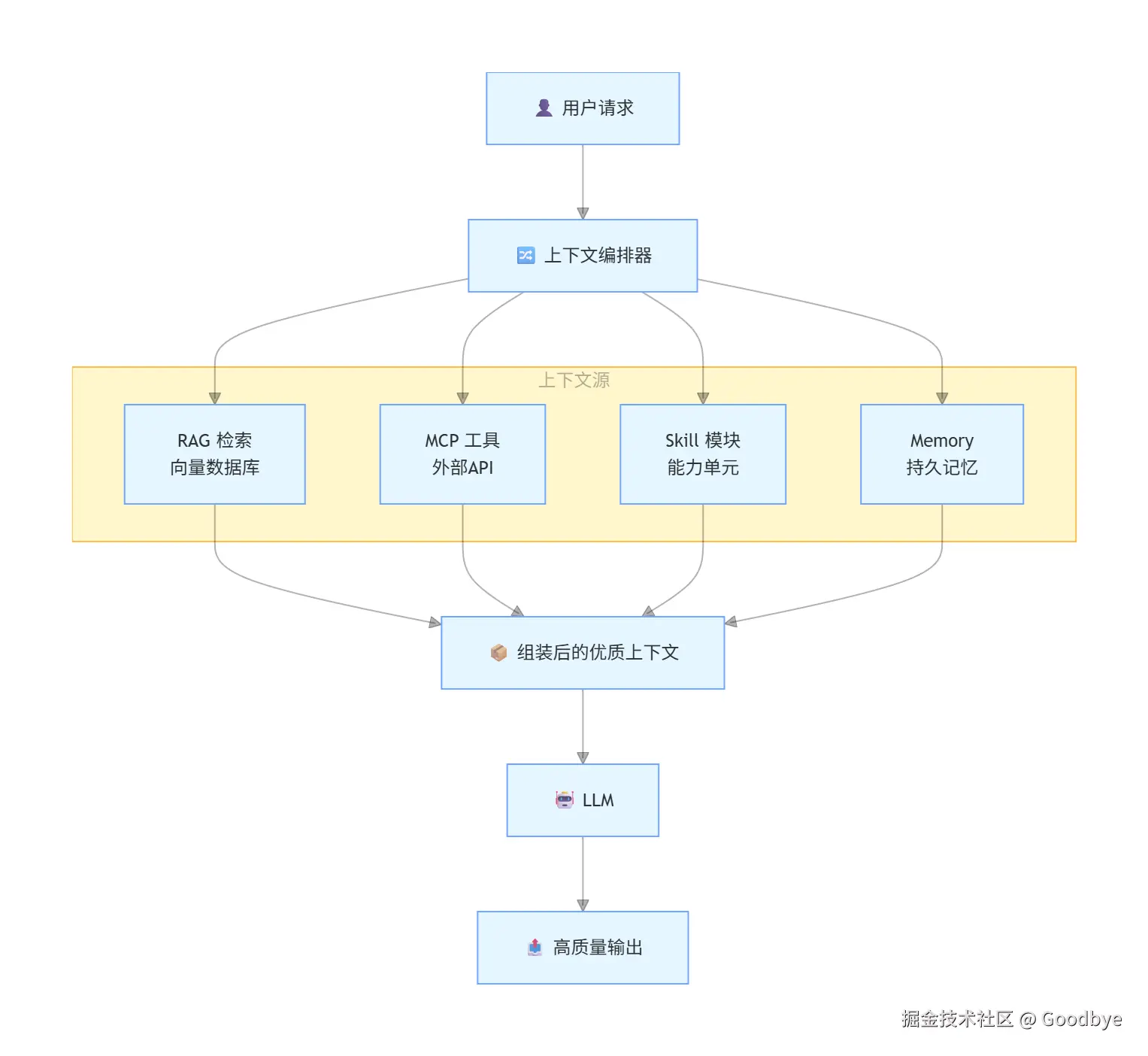
关键词:RAG、MCP、Skill
当 Prompt Engineering 的天花板逐渐显现,工程化的重心转向了上下文质量:
| 技术 | 解决的问题 | 说明 |
|---|---|---|
| RAG | LLM "不懂"你的业务 | 检索增强生成,把相关知识注入上下文 |
| MCP | LLM 没有最新数据 | Model Context Protocol,标准化的工具/数据接入 |
| Skill | 复杂任务编排 | 将能力模块化,按需组合 |
4.3 第三阶段:Loop Engineering(循环工程)
关键词:Harness AI 工程、自主循环
这是当前的前沿阶段 ------ AI 不只是被动响应,而是进入自主循环 : 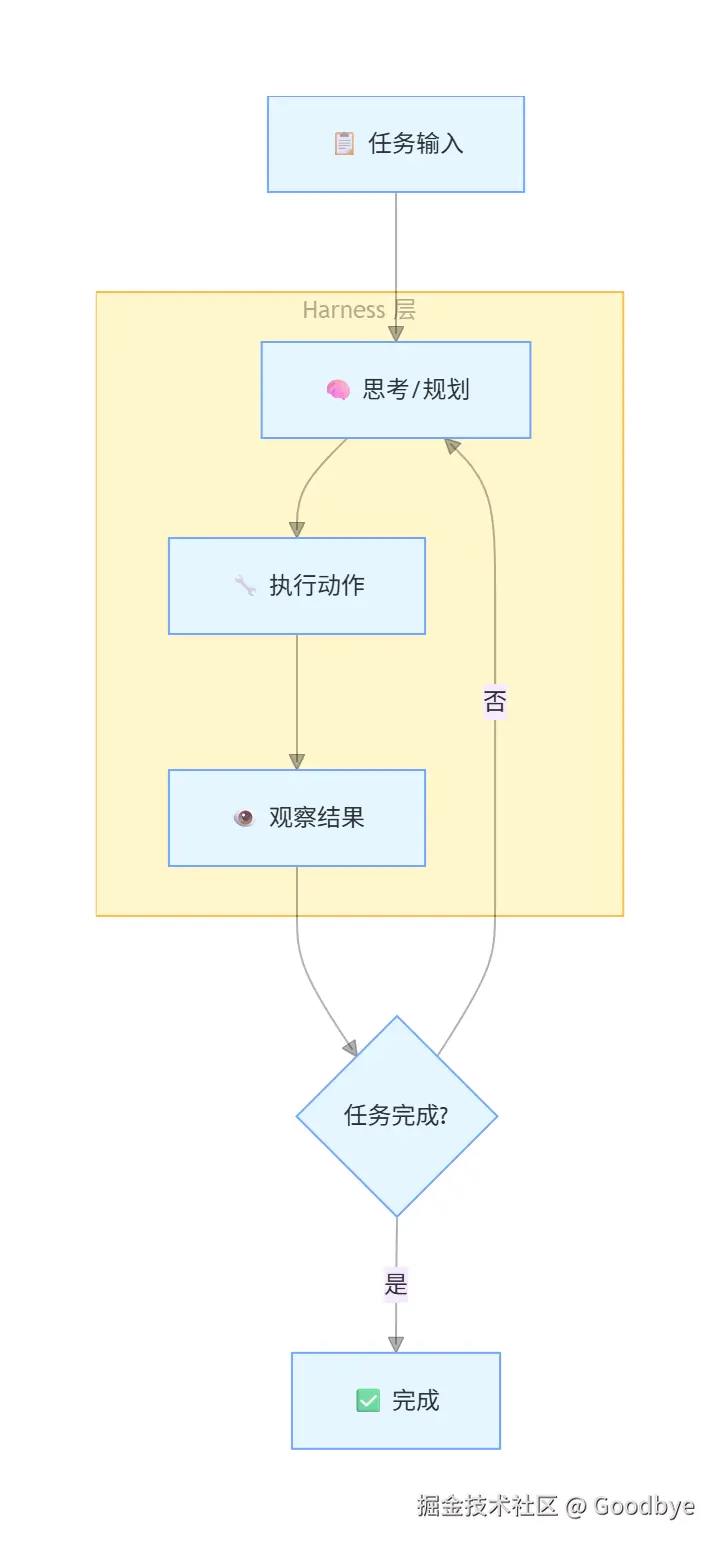
Loop Engineering 的核心思想:
- 🔄 自主迭代:AI 自己判断任务是否完成
- 🛠️ 工具调用闭环:思考 → 调用工具 → 观察结果 → 再思考
- 🏗️ Harness 层:提供运行循环的基础设施
5. ChatHistory 的挑战与对策
5.1 问题分析
虽然"每次带上全部对话"是无状态架构的基石,但它也带来了显著的挑战:
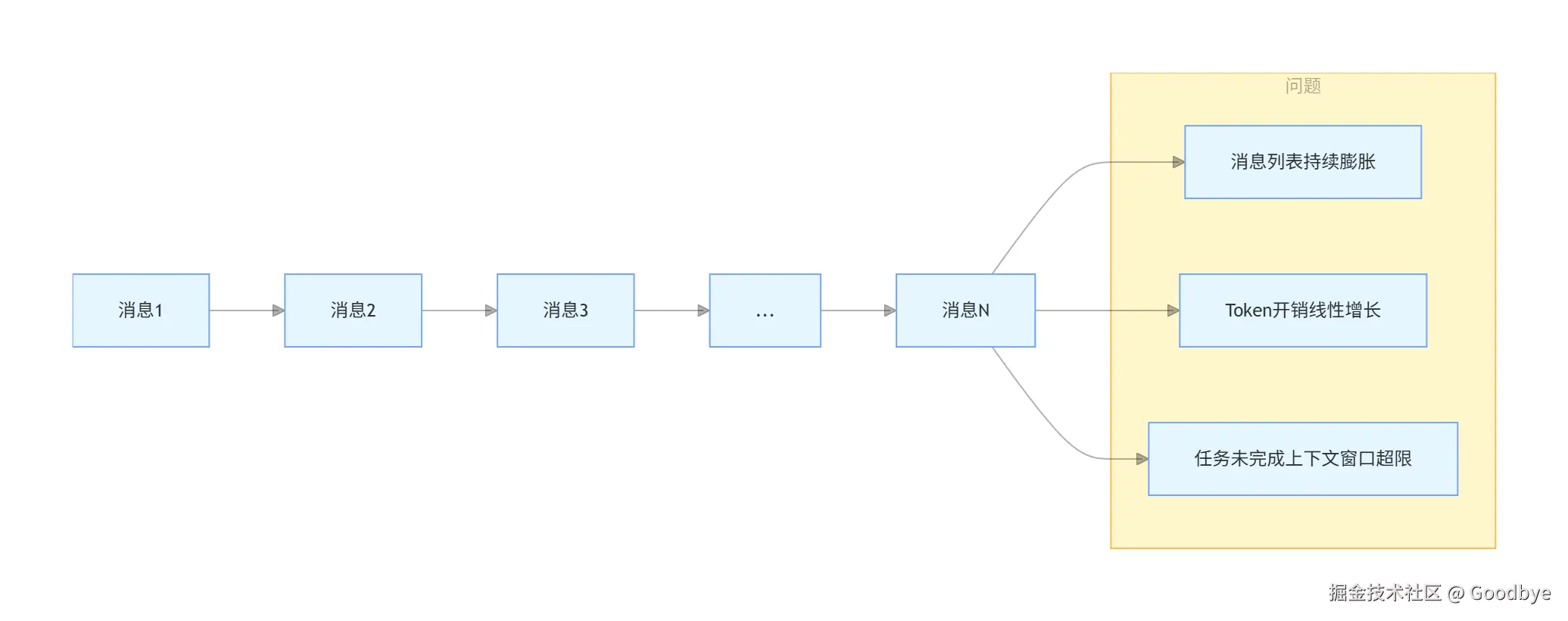
核心矛盾:
| 问题 | 描述 |
|---|---|
| 历史不完整 | 没有维护全部 history,但大模型的回复也是关键上下文,丢弃不得 |
| Token 膨胀 | messages 越来越大,token 开销呈线性甚至指数级增长 |
| 任务中断 | 一次长对话中,任务还没完成,上下文窗口已经不够用了 |
5.2 对策:LRU 策略 + Capacity 管理
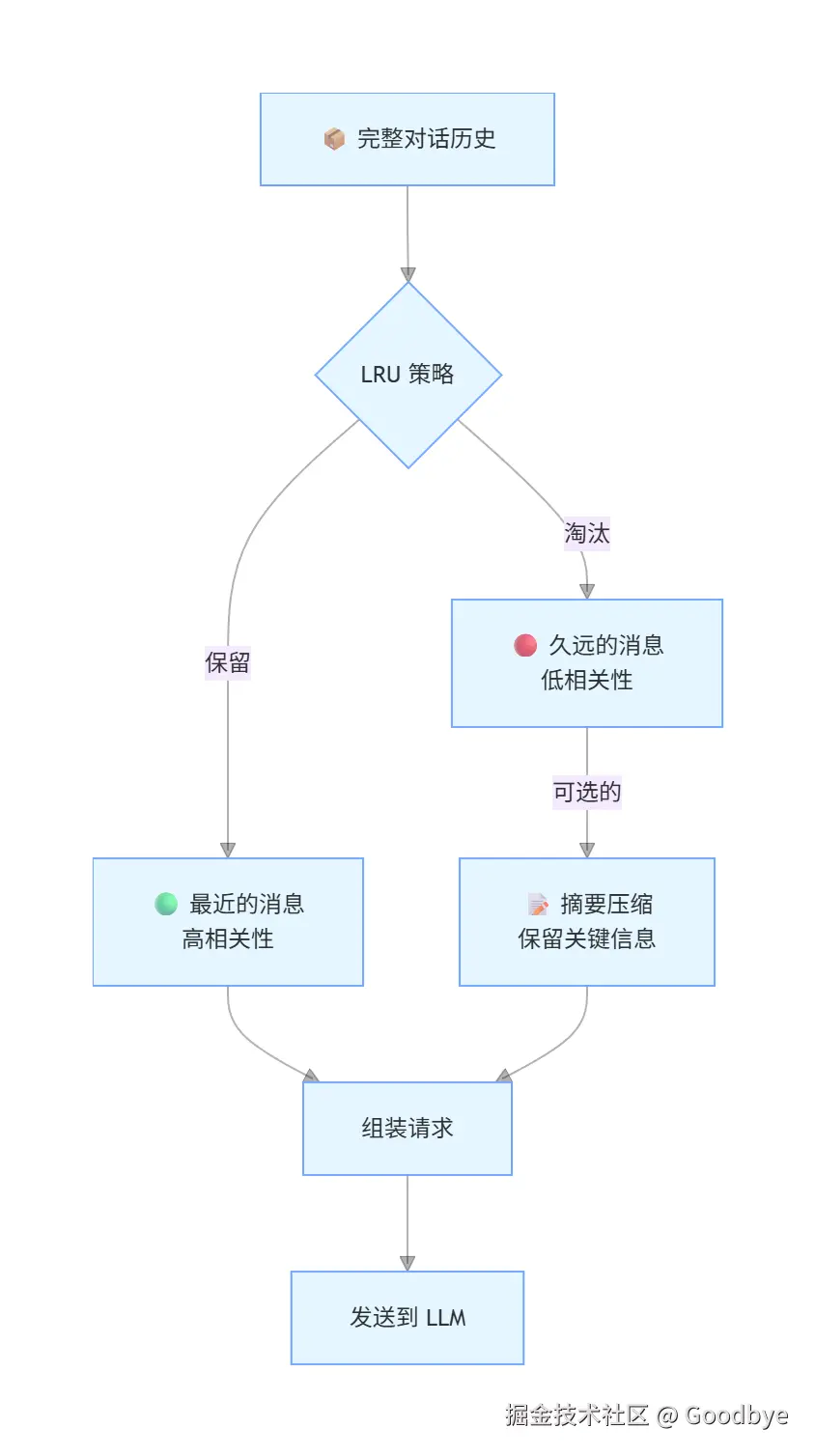
LRU(Least Recently Used)策略在对话管理中的应用:
markdown
核心原则:
最近在聊的内容 → 保留(相关性高)
久远的历史消息 → 适当删除(相关性衰减)
配合手段:
1. 摘要压缩:对久远对话做摘要,保留关键信息但大幅减少 Token
2. Capacity 限制:为每次请求设定最大 Token 预算
3. 滑动窗口:只保留最近 N 轮对话的完整内容平衡之道:既要让 LLM "懂"我们(足够上下文),又要控制成本(合理 Token 用量),这是一门需要在实践中不断调优的工程艺术。
6. 实践:Demo 项目剖析
agent/stateless/demo/ 目录下是一个最小化的 LLM 调用示例项目,展示了无状态架构的落地方式。
6.1 项目结构
bash
demo/
├── package.json # 项目配置
├── node_modules/ # 依赖(openai SDK)
└── (index.js) # 入口文件6.2 依赖解析
从 package.json 可以看到两个核心依赖:
| 依赖 | 版本 | 作用 |
|---|---|---|
openai |
^6.44.0 |
OpenAI 官方 SDK,封装了 Chat Completions API |
dotenv |
^17.4.2 |
环境变量管理,安全管理 API Key |
6.3 无状态调用的代码模式
Demo 项目体现了无状态架构的核心模式:
 伪代码示例(体现无状态核心模式):
伪代码示例(体现无状态核心模式):
javascript
import OpenAI from 'openai';
import 'dotenv/config';
const client = new OpenAI({ apiKey: process.env.OPENAI_API_KEY });
// 🔑 核心:客户端维护 messages 数组
const messages = [
{ role: 'system', content: '你是一个有帮助的助手。' }
];
async function chat(userInput) {
// 1️⃣ 追加用户消息到历史
messages.push({ role: 'user', content: userInput });
// 2️⃣ 发送完整历史(无状态请求)
const response = await client.chat.completions.create({
model: 'gpt-4o',
messages: messages, // ← 每次都带上全部上下文
});
// 3️⃣ 将回复也追加到历史
const reply = response.choices[0].message;
messages.push(reply);
return reply.content;
}
// 多轮对话 ------ 每次都把完整历史发给服务器
await chat('解释量子计算');
await chat('能用简单例子说明吗?');
await chat('这和传统计算机的区别是什么?');这就是无状态的实践:服务端不存储任何会话状态,客户端全权负责维护对话历史。每次 HTTP 请求都是自包含的、独立的。
7. 总结与展望
7.1 核心要点回顾
7.2 关键洞察
| 层次 | 洞察 |
|---|---|
| 本质 | LLM 调用就是一次 HTTP 请求,消耗算力并返回结果 |
| 架构 | 无状态 = 服务端不存状态,客户端每次带上全部上下文 |
| 优势 | 高并发、高可用、水平扩展、任意节点无差别处理 |
| 代价 | Token 开销随对话增长,需要 LRU / 摘要等策略管理 |
| 演进 | Prompt → Context → Loop,从单轮对话到自主智能体 |
7.3 未来方向
随着 Loop Engineering(Harness AI)的成熟,无状态架构将进入新阶段:
- 🤖 自主 Agent:AI 在无状态基础设施上实现有状态的"幻觉"------通过循环和自我管理模拟连续性
- 🔗 多 Agent 协作:多个无状态 Agent 通过消息传递协同工作
- 📡 协议标准化:MCP 等协议让上下文工程更加标准化
- ⚡ 边缘推理:无状态特性天然适合边缘部署
一句话总结:LLM 无状态架构不是限制,而是解放 ------ 它让 AI 服务像 Web 服务一样可伸缩、可维护、可进化。从 Prompt 到 Context 再到 Loop,每一次工程化升级都建立在"无状态"这块基石之上。