最近终于抽出时间,和大家深度地分享一下我们研发协同文档 JitWord 的最新技术方案。

github: github.com/jitOffice/j...
文章有点长,但是干货很多,晦涩难懂的部分我尽量用图文代替,建议大家先赞再看。
作为一名在前端和架构领域深耕十年、做过万星 Star 的开源项目(H5-Dooring)的创业者,我始终认为:协同编辑不是简单的 "多人同时打字",而是分布式系统理论在文档场景的极致工程化落地。
从早期 Google Docs 引领的 OT 时代,到如今 Notion、Figma 普遍采用的 CRDT 方案,协同文档的技术路线已经历了两轮迭代。
而当 AI 能力深度注入编辑器之后,"人机协同" 又对传统协同架构提出了全新挑战。
下面就以我们团队自研的 JitWord 企业级智能协同文档为例,从产品和架构师的视角,和大家完整拆解:
一套工业级协同文档系统到底是如何设计的?
CRDT 算法在真实业务中如何落地?
AI 大模型又该如何与实时协作能力无缝融合?
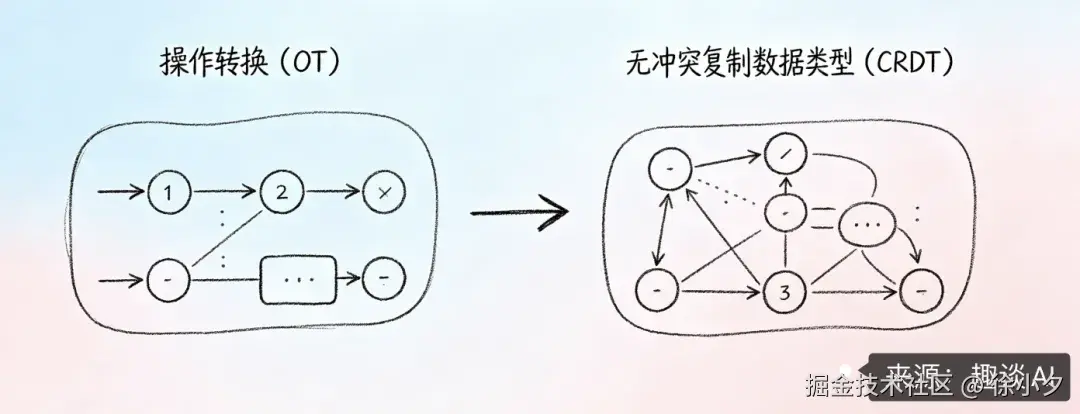
协同文档的两条技术路线:OT 与 CRDT 深度对比
在聊具体实现之前,我先把底层技术逻辑和大家讲透。
目前业界实现实时协同编辑主要有两大技术路线:
1. 操作转换(Operational Transformation, 也就是我们常说的OT算法)
2. 无冲突复制数据类型(Conflict-free Replicated Data Type, CRDT算法)
我画了一张图,帮助大家更好地理解:
下面和大家详细介绍一下这两种协同算法。
OT 算法:传统协同的经典方案
OT 算法在上世纪 80 年代在 Google Docs 中就已经大规模使用了。它的核心思想是:当多个用户同时对文档产生操作时,中央服务器对操作进行转换,确保最终一致性。
基本原理我借助AI画了一张图,方便大家理解:
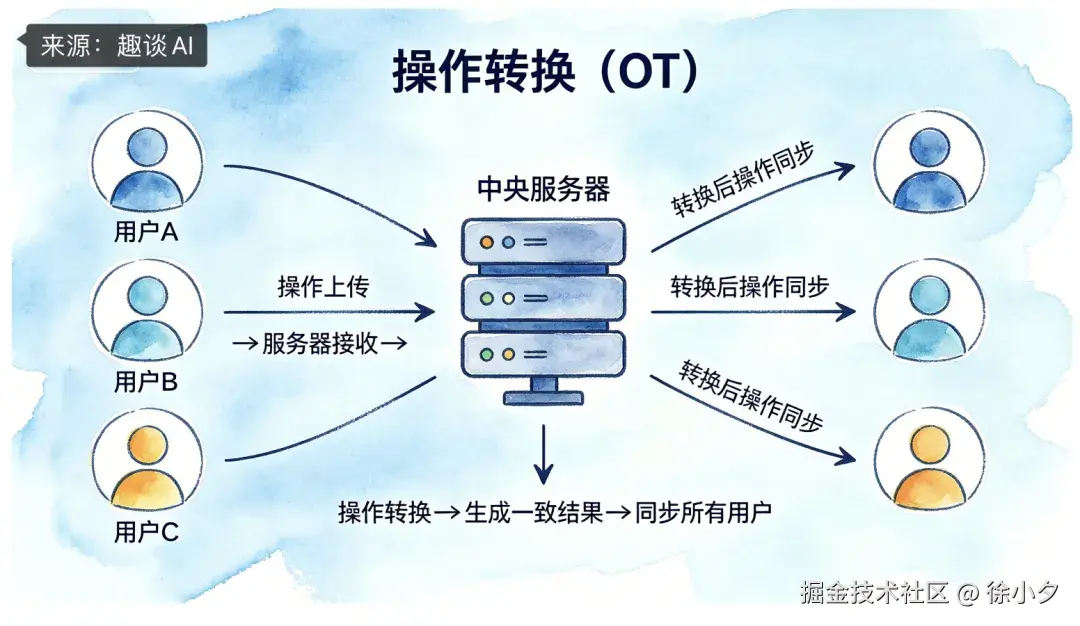
具体流程用大白话解释如下:
- 用户 A 和用户 B 几乎同时对同一文档发出操作 opA 和 opB
- 服务器接收到 opA 后先应用,再将 opB 进行 "转换",使其在 opA 已应用的文档状态上依然正确
- 转换后的操作广播给所有客户端,保证最终状态一致
OT 算法的优势在于:
- 数据传输量小,只传输操作指令而非完整内容
- 时间沉淀长,工程化案例丰富
- 对文本类场景适配成熟
但是也有缺点,下面分享一下 OT 的致命缺陷:
- 强依赖中央服务器做冲突裁决,服务器压力大
- 算法复杂度随操作类型指数级上升,每新增一种操作就要写对应的转换函数
- 离线编辑支持差,断网后重连需要复杂的状态对齐
- 扩展复杂组件(表格、图表、富媒体)成本极高
这也是为什么很多基于 OT 的协同产品,只能做纯文本协作,一旦引入复杂节点就容易出 bug。
对于当下多模态内容展现的时代,我们需要在文档里展现更复杂的元素和操作,所以需要采用更适配的方案来实现协同。
CRDT 算法:现代协同的主流选择
CRDT 是为分布式系统设计的数据结构,核心特性是不需要中央协调,多个副本可以独立更新,最终自动收敛到一致状态。
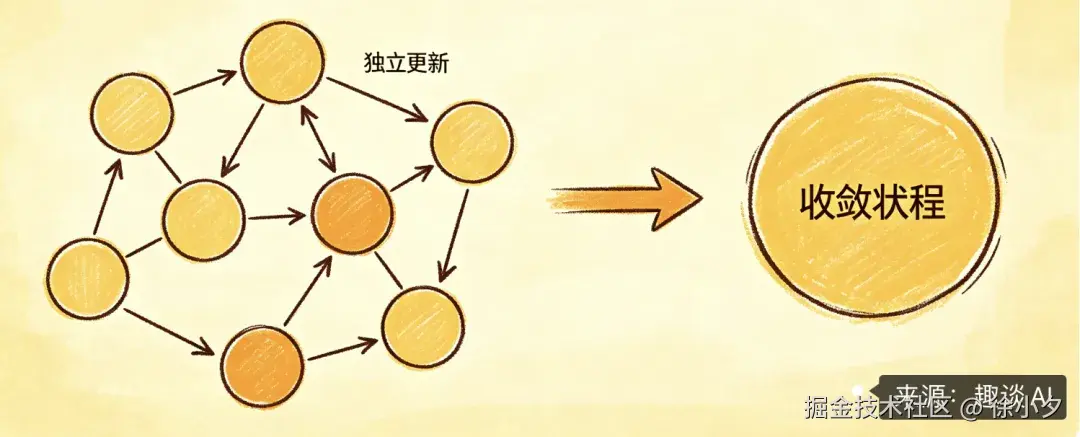
它的核心思想如下:
- 每个操作都附带唯一标识和时间戳
- 操作满足 "交换律"------ 无论以什么顺序应用,最终结果都相同
- 冲突通过预设规则自动解决,无需服务器做转换计算
CRDT 的优势在于:
- 天然支持离线编辑,断网后本地操作,重连自动合并
- 算法扩展性强,新增节点类型无需重写冲突逻辑
- 服务器压力小,只做转发和持久化,不做复杂计算
- 适合复杂富文本、块级文档、甚至设计工具场景
当然,它同样也会存在一些缺点,比如:
- 元数据开销相对更大,需要存储额外的 ID 和版本信息
- 算法理解门槛高,工程落地对团队技术能力要求高
- 垃圾回收(GC)策略设计复杂,长期运行的文档元数据会膨胀
那么,我们为什么会选择 CRDT 算法呢?
在 JitWord 立项之初,我们对两种方案做了完整的技术预研,最终选择 CRDT 路线,核心判断有下面三点, 大家也可以做个参考:
1. 产品形态决定 
JitWord 是块级多模态编辑器,支持图表、代码块、多媒体等复杂组件,OT 的扩展成本不可接受。
2. 企业场景刚需
企业用户对内网环境、离线编辑、弱网协作有强需求,CRDT 天然适配。
3. AI 融合需求
AI 生成内容是流式写入,本质上也是一个 "协作者",CRDT 的无冲突特性能更好地支持人机混编。
JitWord 协同架构全景设计
JitWord 采用经典的四层架构设计,自上而下分为前端层、网络层、后端层、存储层,如下图所示:
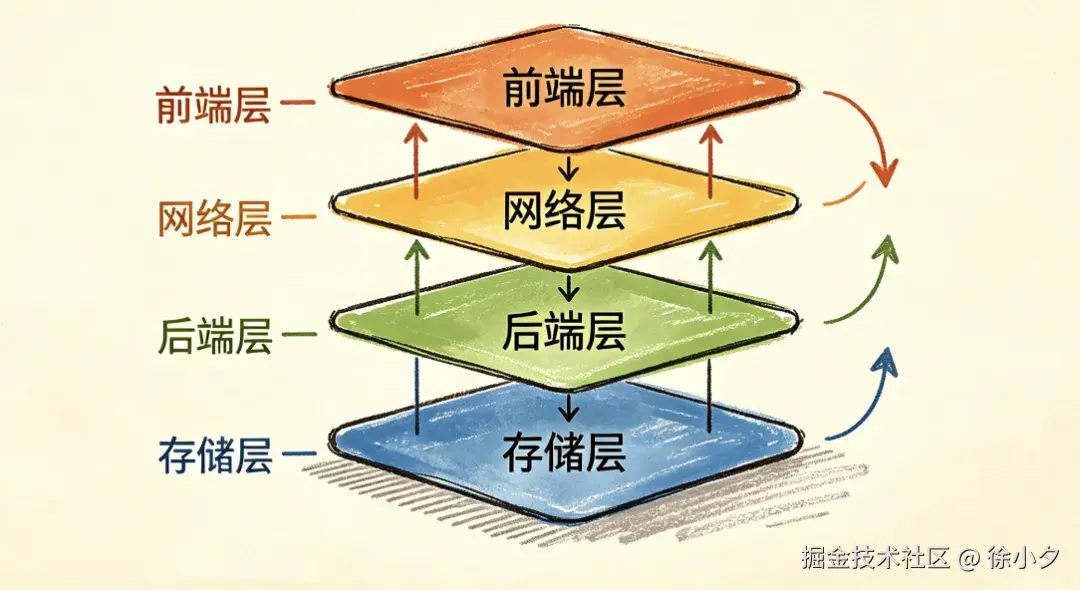
每一层都围绕 "低延迟协作" 和 "高可用扩展" 两个核心目标做了针对性优化。
核心架构如下:
做这样的架构设计,有很大的优点,比如:
- 职责分离清晰网络层区分普通 HTTP 请求、协作 WebSocket、AI 流式 SSE 三条链路,互不阻塞
- 计算前置CRDT 计算全部在客户端完成,后端只做转发和持久化,降低服务端瓶颈
- 缓存分层内存 LRU 缓存热点解析结果,文件系统存储全量数据,兼顾性能与成本
- 扩展友好组件系统与编辑器内核解耦,新增能力不影响核心协作逻辑
这些优点对于企业二次开发和维护来说非常方便,相当于为企业设计了一套可维护的架构工程体系。
核心模块深度剖析
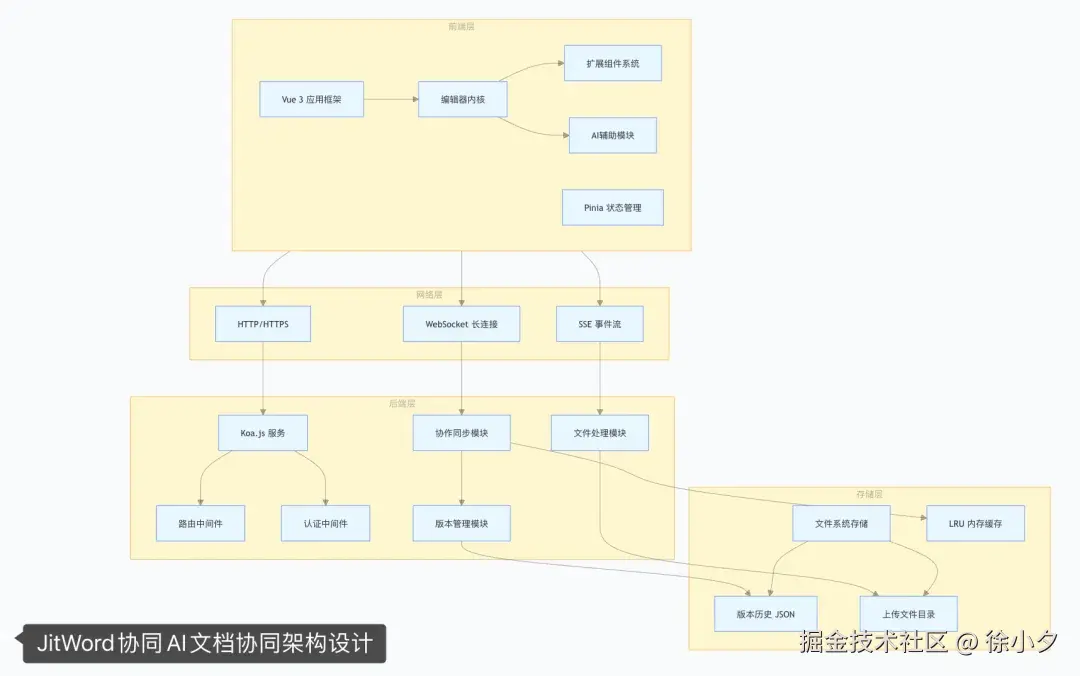
1. 协作同步模块
这是整个协同系统的心脏,负责管理所有实时连接和操作广播。下面我画了一个流程图,解释了 jitWord 协同同步的流程:
核心代码我也简单列一下,供大家参考:

版本管理模块实现
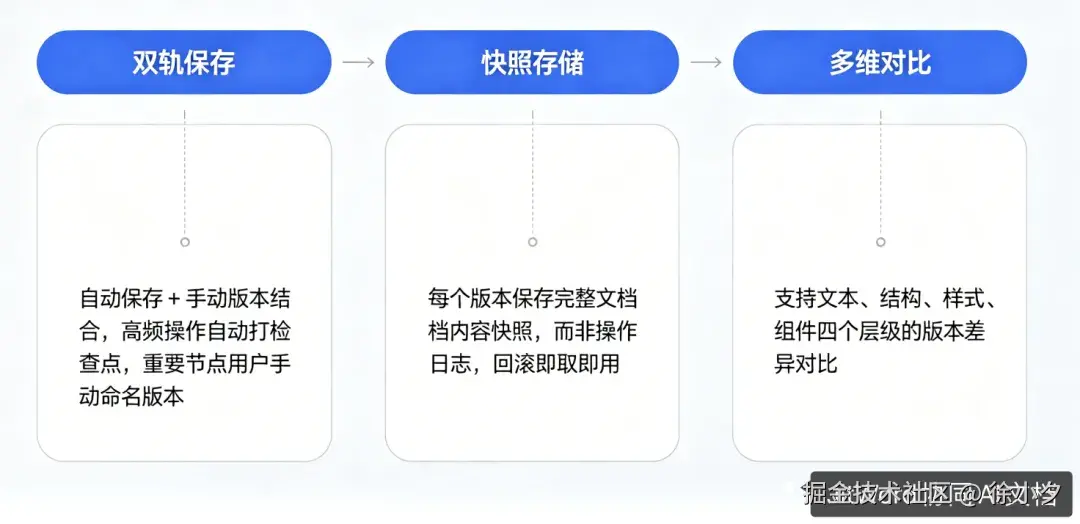
协作不是最终目的,一个可追溯、可回滚的协同文档系统, 才是企业的刚需。
所以我们设计了一套可靠的版本管理机制,通过双轨保存,快照存储,多维对比,来实现文档的可溯源模型,如下图所示:
文件处理模块
企业文档常常会涉及多格式导入导出,这是很多协同产品的薄弱环节。比如下面几个场景:
- 多格式解析支持 DOCX、TXT、Markdown 等主流格式的智能解析
- 图片提取DOCX 导入自动提取内嵌图片并转存到资源目录
- 格式转换外部格式统一转换为编辑器内部结构化 JSON 结构
- LRU 缓存相同文件重复解析直接命中缓存,大幅提升二次打开速度
当然文档解析是我们 JitWord 另一个核心模块,我之前文章中有详细的介绍,这里就不一一和大家分享了,大家可以参考我往期的文章。
核心协同技术的工程化落地
CRDT 冲突解决策略
很多文章讲 CRDT 只讲理论,不讲工程细节。实际上,CRDT 不是 "银弹",不同冲突场景需要设计不同的解决策略。
JitWord 针对下面四类典型冲突做了精细化处理, 如果大家也在做协同类产品,不妨参考一下:
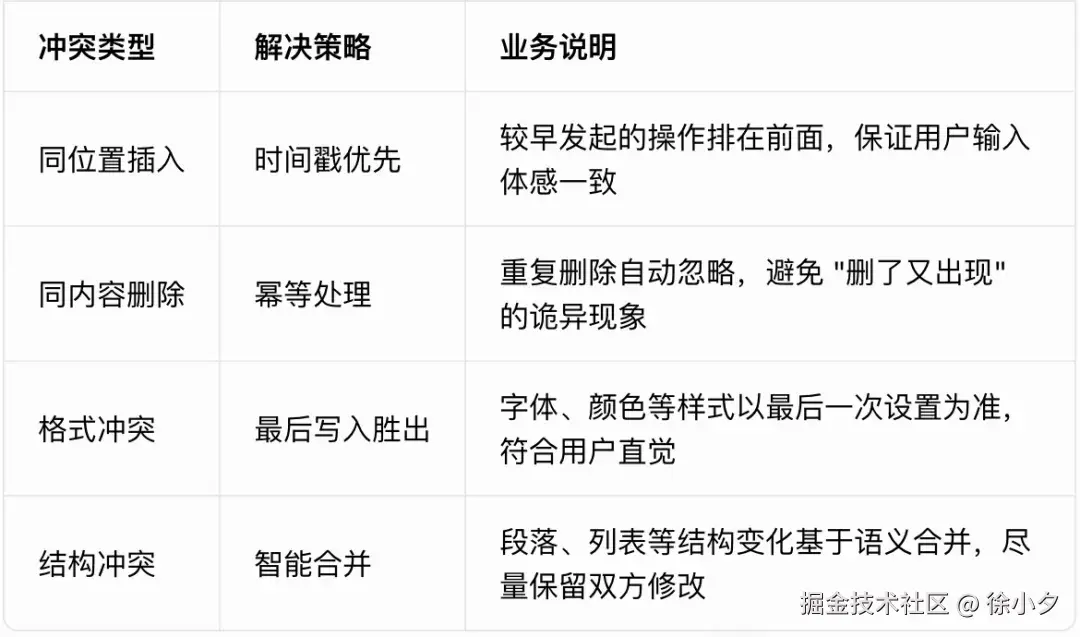
这里不得不说一点我个人的看法:CRDT 的 "最终一致性" 不等于 "用户满意"。算法正确是底线,让用户觉得 "合理" 才是产品级实现方案。
比如,同位置插入,纯算法可能按 ID 排序,但用户感知上应该是 "谁先打字谁在前",这就需要时间戳校准。
协同编辑完整的数据流架构
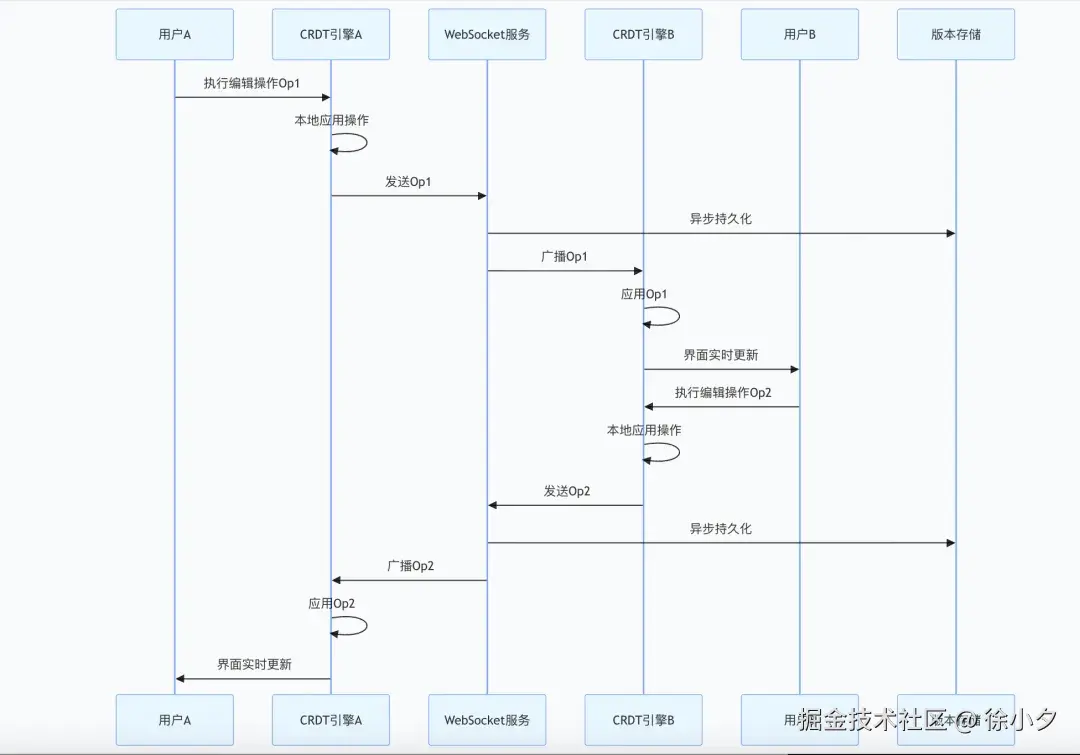
上面是我们设计的协同架构数据流方案,整个协作链路的延迟控制在30-100ms(常规文档测试下,超大文档比如500-1000页延迟可能会变高) ,用户基本感知不到对方输入的延迟。能做到这个水平,我们核心靠三个优化:
- 本地优先操作先本地渲染再发网络,用户输入零等待
- 操作合并短时间内连续输入合并为一个操作包发送,减少网络 IO
- 二进制传输操作数据采用二进制编码,包体积比 JSON 减少 60% 以上
版本对比算法
版本管理的核心是 "差异可视化",JitWord 采用 Myers 差分算法做多维度对比,具体对比的维度包括:
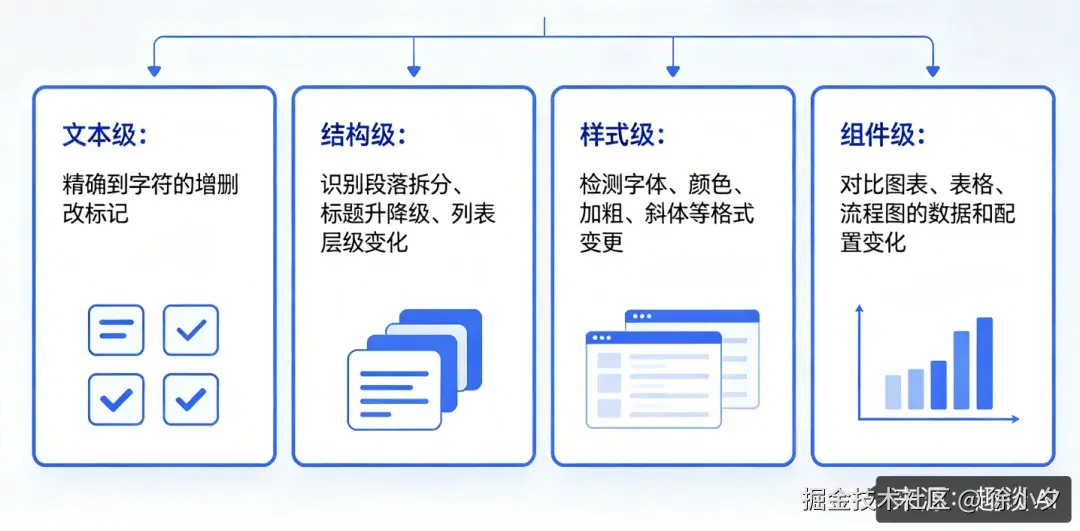
这也是企业场景的痛点 ------ 很多协同产品只能对比纯文本,一旦涉及表格修改、图表数据更新,版本对比就完全失效。
协同 + AI:JitWord 的差异化创新
如果说 CRDT 解决了 "人与人协作" 的问题,那么 AI 能力的加入,就让 JitWord 进入了 "人机协同" 的新维度。这也是我们认为下一代文档编辑器的核心方向。
下面我会基于几个核心维度,来和大家分享一下。
AI 处理数据流设计
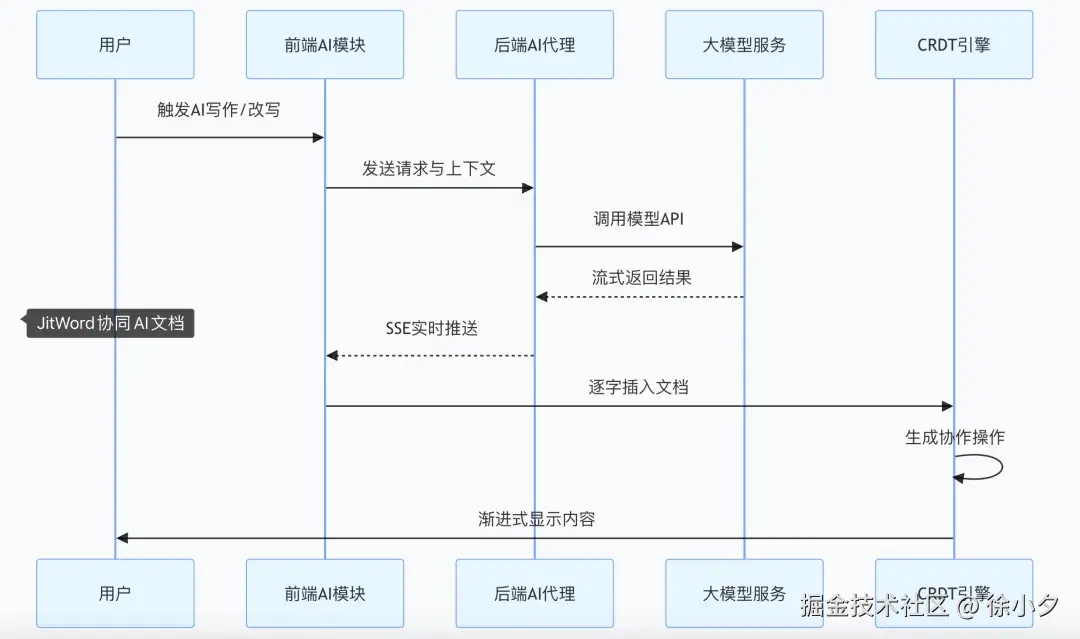
关键设计如下:
- AI 生成的每一段文字,都通过 CRDT 引擎作为一次 "协作操作" 插入文档
- 其他协作者可以实时看到 AI 的写入过程,就像另一个人在打字
- AI 操作带有特殊标识,版本历史中可以区分人工修改和 AI 生成
- 支持 AI 边写、用户边改,两者不会冲突,自动合并
AI 集成架构
JitWord 的 AI 模块采用 Provider 适配器架构,不绑定任何一家大模型服务商, 代码参考如下:

这种设计的好处:
- 灵活切换企业可以接入自己的私有模型,也可以用公有云模型
- 成本可控不同场景调度不同模型,写作调用大模型,润色调用小模型
- 故障降级某家服务商故障时自动切到备用线路,保证业务可用
- 私有化部署支持本地部署大模型,数据完全不出内网
扩展能力与工程实践
组件扩展系统
协同文档的生命力在于扩展。JitWord 设计了完整的组件扩展机制,开发者可以像写普通 Vue 组件一样开发编辑器插件。
代码我列举一个扩展组件的代码案例:

性能优化策略
前端方面我列举几个我们核心的优化方案,大家可以参考一下:
- 组件懒加载图表、思维导图等重型组件首次使用时才加载
- 虚拟渲染长文档只渲染可视区域,DOM 节点数量减少 90%
- 防抖节流用户输入防抖,避免频繁触发重渲染
- 增量更新CRDT 操作只更新受影响的节点,不整树重绘
后端核心优化如下:
- 连接池管理WebSocket 连接复用,减少握手开销
- LRU 内存缓存热点文档解析结果缓存,重复打开毫秒级响应
- 异步持久化协作操作先广播再落盘,不阻塞实时链路
- 多实例部署支持横向扩容,通过 Redis 同步房间状态
企业级安全设计
安全是企业选型的一票否决项。JitWord 从三个层面构建安全体系,下面给大家详细介绍一下:
认证安全:
- JWT 无状态认证,支持分布式部署
- Token 自动刷新机制,兼顾安全与体验
- 基于角色的细粒度权限控制
数据安全:
- HTTPS/WSS 全链路加密传输
- 敏感数据加密存储
- 完整操作审计日志,所有修改可追溯
接口安全:
- 严格的输入参数校验
- XSS 过滤与 CSRF 防护
- 文件上传类型与大小双重限制
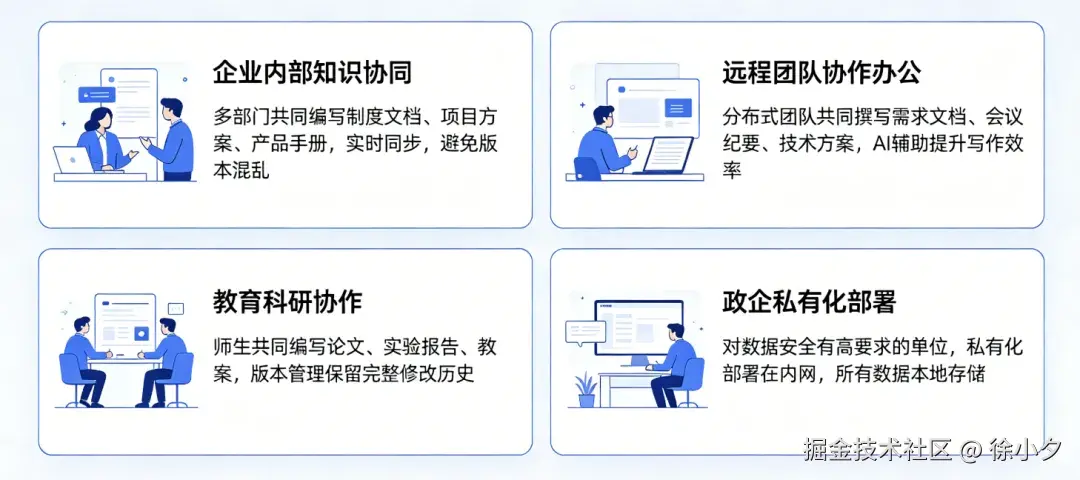
下面我列举了几个应用场景,供大家参考:
部署架构设计
目前我们采用的是单体部署方案,具体的部署架构如下:
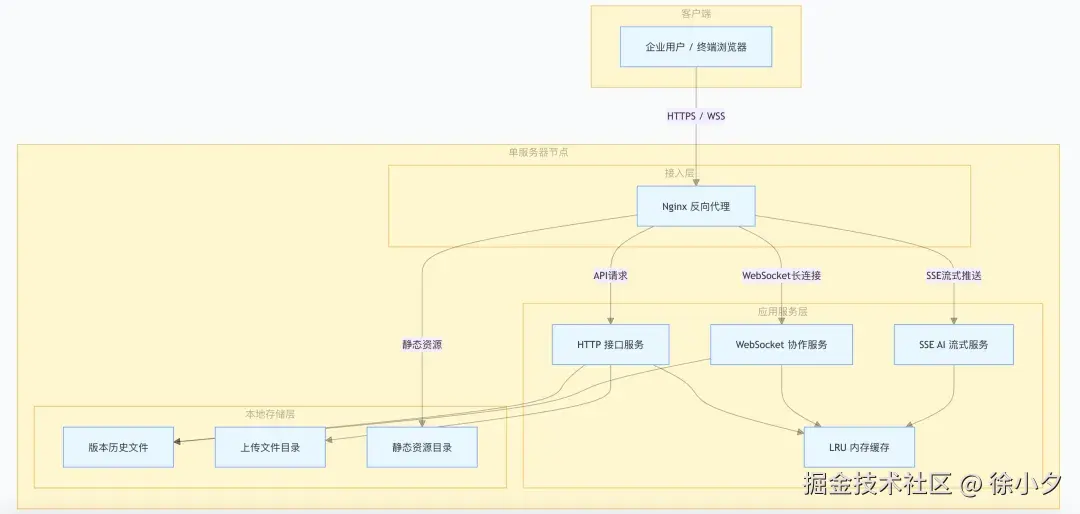
这也是 JitWord 单机私有化部署的标准架构,单台服务器即可承载完整的协同文档服务。
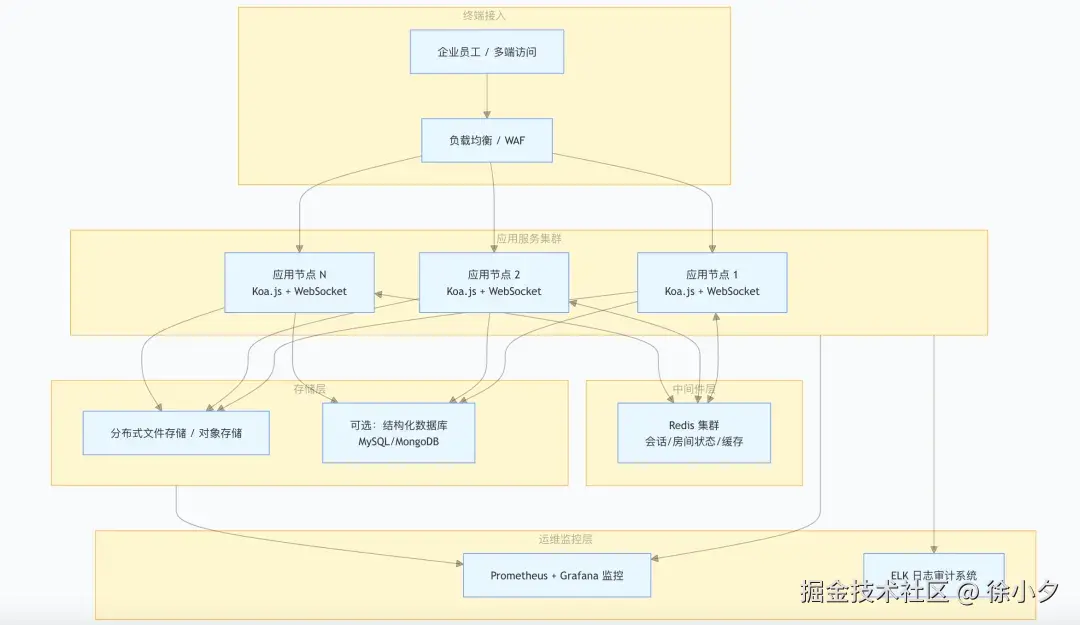
当企业用户规模超过百人、对系统可用性、并发能力有严格要求时,可平滑升级为集群部署架构,实现横向扩容、故障自愈与容灾备份,下面分享一下集群部署架构设计:
最后:创业者的技术思考
做协同文档这两年,我最深的体会是:难的从来不是算法本身,而是算法与产品、工程、场景的结合。
CRDT 论文谁都能读,但要做到复杂组件不冲突、大文档不卡顿、弱网不掉线,需要无数工程细节的打磨,我们光设计协同架构,就花了接近3个月时间。
同时要做到 AI 写入不打断协作、流式输出不破坏一致性、生成内容可追溯,需要对协同架构有深刻的理解。
JitWord 从第一天起就定位为 "企业级协同 AI 文档",我们不追求功能数量的堆砌,而是聚焦三个核心价值:
- 协同的极致体验低延迟、无冲突、全组件支持
- AI 的深度融合不是外挂式 AI,而是原生嵌入协作流
- 企业的可控性支持私有化、支持定制扩展、数据安全可靠
未来,协同文档的形态还会继续演进。从 "人与人协作" 到 "人机协同",再到 "多 Agent 自动协作",编辑器的角色会从 "书写工具" 变成 "智能工作空间"。我们也会沿着这个方向持续迭代,让每一家企业都能拥有自己的智能协同文档平台。
github开源版: github.com/jitOffice/j...