博主介绍:程序喵大人
- 35 - 资深C/C++/Rust/Android/iOS客户端开发
- 10年大厂工作经验
- 嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手
- 《C++20高级编程》《C++23高级编程》等多本书籍著译者
- 更多原创精品文章,首发gzh,见文末
- 👇👇记得订阅专栏,以防走丢👇👇
😉C++基础系列专栏
😃C语言基础系列专栏
🤣C++大佬养成攻略专栏
🤓C++训练营
👉🏻个人网站
上一章讲完了 std: :atomic 的基础保证:单个对象上的读、写、读改写都是原子的,不会被撕裂,不会丢更新。但在实际的多线程代码里,我们经常看到一种写法:一个线程先准备好一批普通数据,然后翻一个原子标志位;另一个线程轮询标志位,看到翻转后就去读那批数据。
cpp
int data = 0;
std::atomic<bool> ready{false};
void Producer() {
data = 42;
ready.store(true);
}
void Consumer() {
while (!ready.load()) {
}
Use(data);
}ready 是原子变量,并发读写它没问题。但 data 不是原子变量------它只是一个普通的 int。Consumer 在看到 ready == true 之后去读 data,凭什么能保证读到的是 42 而不是 0?std::atomic 只保护了 ready,它怎么连带着把 data 也保护了?
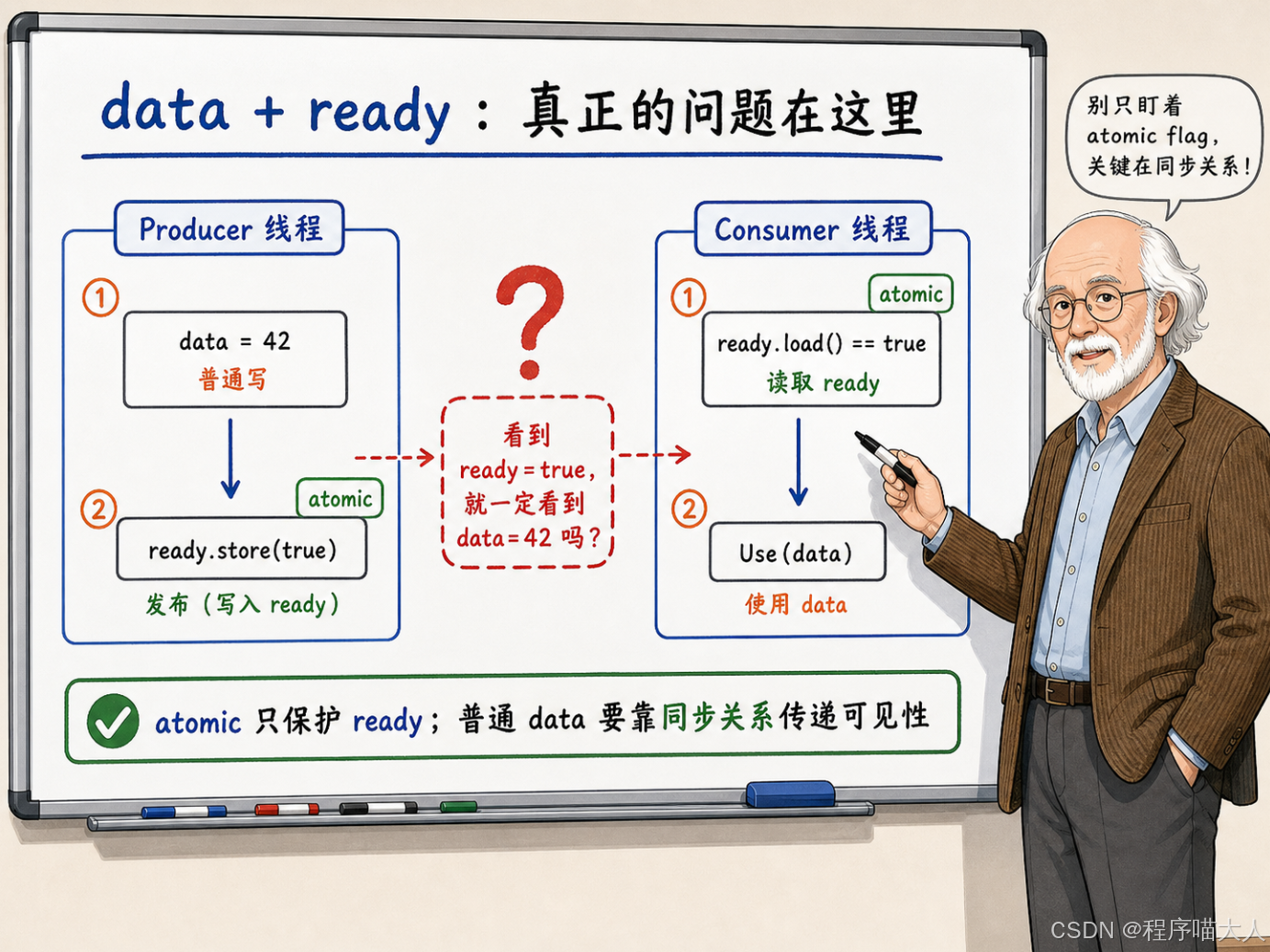
这个问题的答案不在 std::atomic 本身,而在 C++ 内存模型。内存模型定义了一套规则,告诉我们在什么条件下,一个线程的写入对另一个线程可见。atomic 的原子性只是这套规则的一部分;另一部分------线程间的可见性和顺序约束------靠的是 happens-before 这样的同步关系。
这一章就来拆这套规则的地基。
单线程里的顺序:sequenced-before
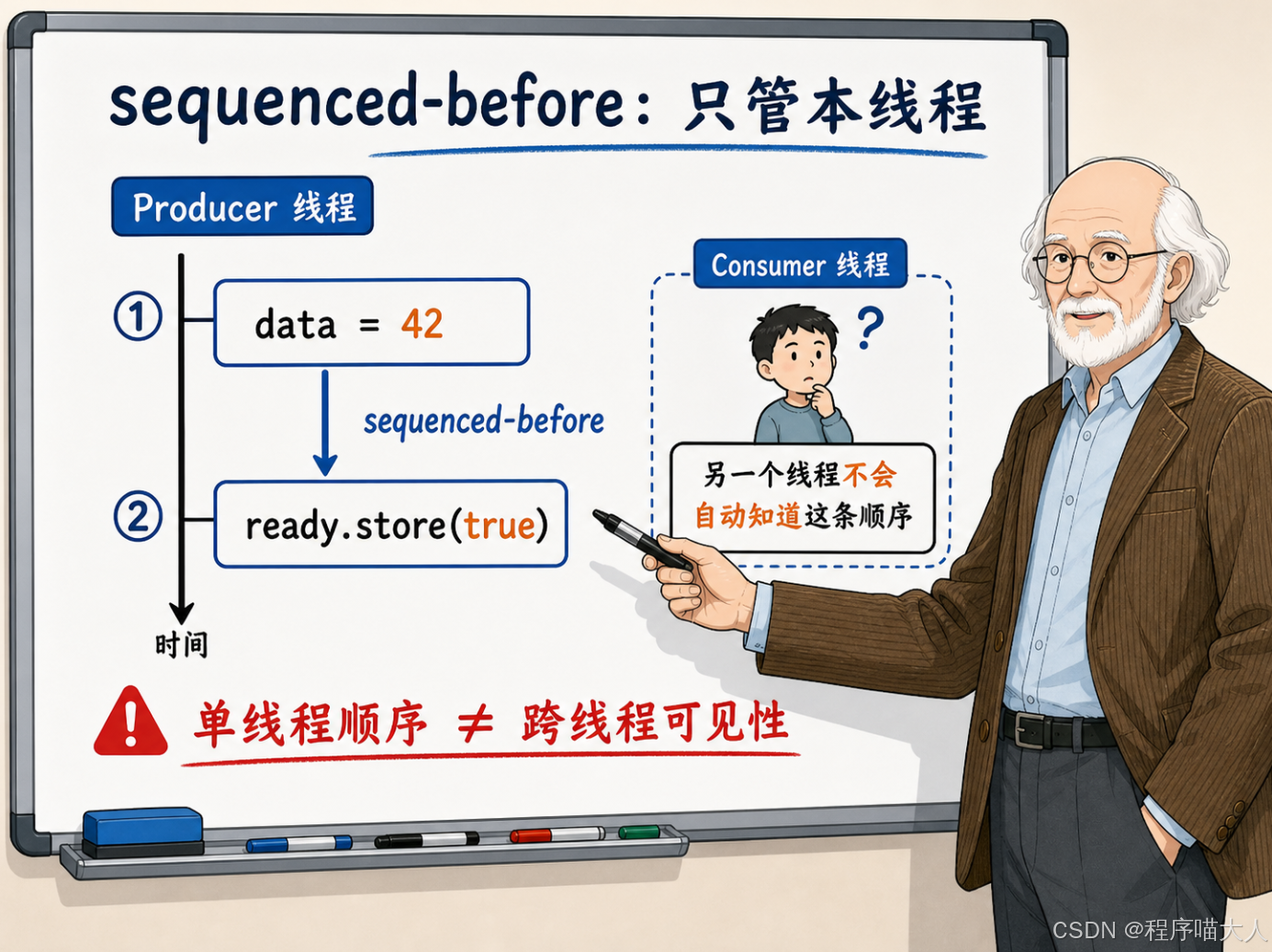
先从最简单的情况说起。在同一个线程内部,代码的执行顺序是确定的。C++ 标准用一个术语来描述这种顺序关系:sequenced-before(先序于)。
cpp
void Producer() {
data = 42; // (1)
ready.store(true); // (2)
}在 Producer 这个线程里,语句 (1) sequenced-before 语句 (2)。这意味着在这个线程的视角下,data = 42 一定在 ready.store(true) 之前完成。这是 C++ 语言对单线程执行顺序的基本承诺。
但要注意一个关键限定:sequenced-before 只描述当前线程内部的顺序。它不对其他线程做任何承诺。Producer 线程自己知道 data = 42 先发生,但 Consumer 线程并不知道。Consumer 看到 ready == true 之后去读 data,如果没有额外的同步机制,它完全可能读到 0------因为 data = 42 这个写入可能还没有对 Consumer 所在的 CPU 核心可见。
为什么会这样?因为现代 CPU 有写缓冲区(Store Buffer)。核心执行写入时,数据先进入私有的写缓冲区,还没刷到公共缓存。另一个核心这时候去读,读到的是缓存里的旧值。而且编译器也可能对指令做重排------只要在单线程视角下结果不变,编译器有权把 data = 42 挪到 ready.store(true) 后面去执行。
所以,sequenced-before 管的是单线程内的事情。要让一个线程的写入对另一个线程可见,我们需要跨线程的同步关系。
跨线程同步:synchronizes-with
C++ 内存模型定义了一种跨线程的同步关系,叫做 synchronizes-with(同步于)。当一个线程的某个操作和另一个线程的某个操作之间建立了 synchronizes-with 关系,就等于在两个线程之间拉了一根同步的线,把它们的执行顺序接了起来。
最常见的建立 synchronizes-with 的方式是 release/acquire 配对:
cpp
#include <atomic>
int data = 0;
std::atomic<bool> ready{false};
void Producer() {
data = 42; // (1)
ready.store(true, std::memory_order_release); // (2)
}
void Consumer() {
while (!ready.load(std::memory_order_acquire)) { // (3)
}
Use(data); // (4)
}这段代码里发生了什么:
- Producer 用
release语义写入ready。release的意思是:在这次 store 之前的所有写入(包括普通变量的写入),都不允许被重排到这次 store 之后。它像一道单向栅栏,把前面的写入全部"封印"住。 - Consumer 用
acquire语义读取ready。acquire的意思是:在这次 load 之后的所有读取,都不允许被重排到这次 load 之前。它也是一道单向栅栏,保证后面的读取一定发生在 load 之后。 - 当 Consumer 的
acquire load读到了 Producer 的release store写入的值(true),两者之间就建立了 synchronizes-with 关系。
这条 synchronizes-with 关系建立之后,Producer 在 release store 之前做的所有写入------包括 data = 42 这个对普通变量的写入------都对 Consumer 在 acquire load 之后的读取可见了。
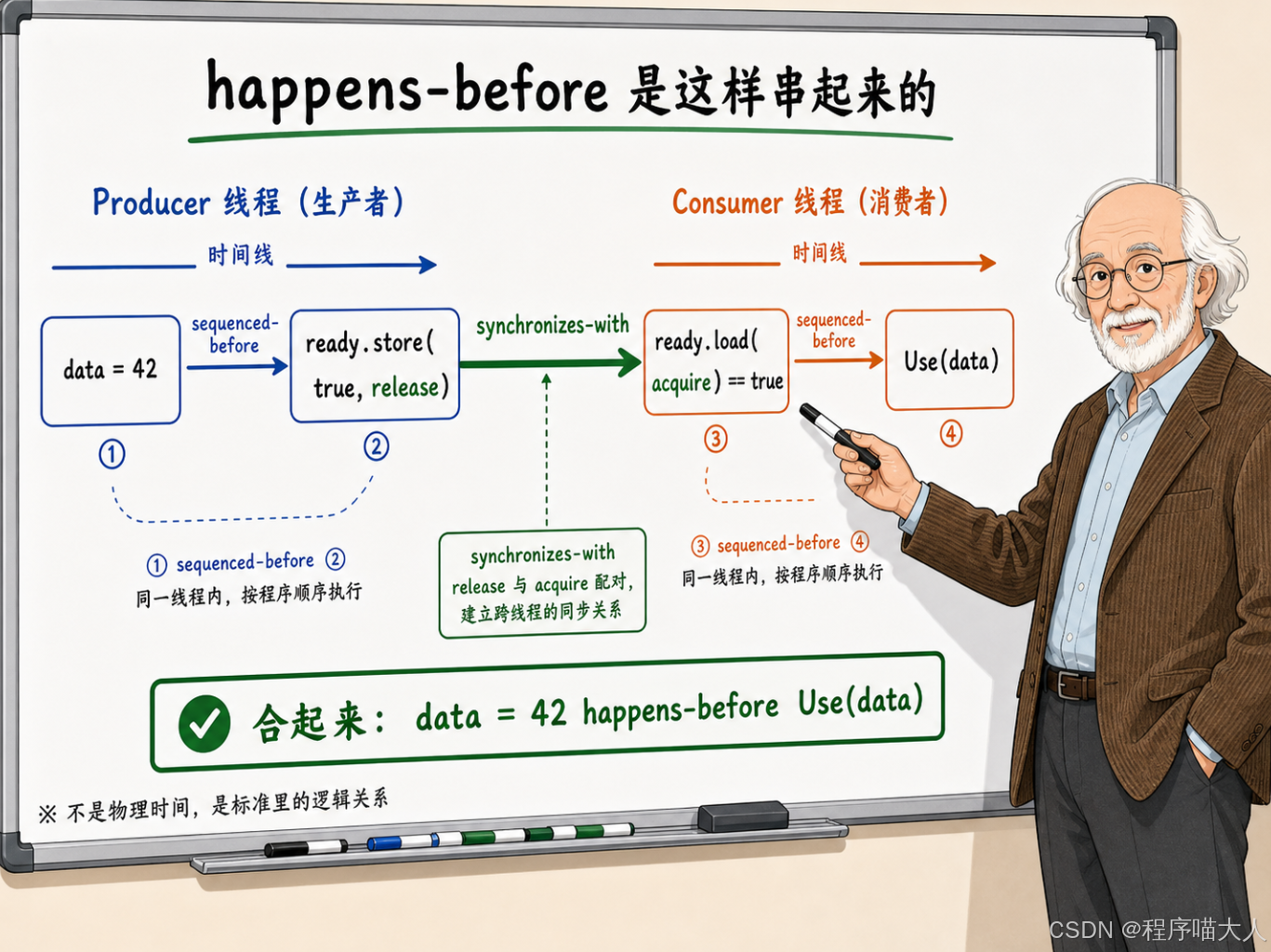
把整条链路画出来就很清楚:
text
Producer 线程:
data = 42 ─── sequenced-before ───▶
ready.store(true, release) ─── synchronizes-with ──▶
Consumer 线程:
ready.load(acquire) == true ─── sequenced-before ───▶
Use(data) // 此时 data 一定是 42data = 42 先序于 ready.store(release),ready.store(release) 同步于 ready.load(acquire),ready.load(acquire) 先序于 Use(data)。整条链串起来,data = 42 就 happens-before Use(data)。Consumer 读 data 的时候,一定能看到 42。
这就是"安全发布"的底层原理。data 本身只是个普通变量,但它搭了 ready 这个原子变量的 release/acquire 同步链的"顺风车",可见性就有了保障。
happens-before:内存模型的核心偏序
刚才反复提到 happens-before,现在正式说一下它的定义。
happens-before 是 C++ 内存模型里最核心的偏序关系。如果操作 A happens-before 操作 B,那么 A 的效果对 B 一定是可见的。反过来说,如果两个操作之间没有 happens-before 关系,那么它们的可见性就没有任何保证。
happens-before 的建立方式有两种:
第一种,同一个线程内的 sequenced-before。 在同一个线程里,前面的语句 happens-before 后面的语句。这是最基本的情况。
第二种,跨线程的 synchronizes-with 加上 sequenced-before 的传递。 上面那个例子就是典型:data = 42 sequenced-before ready.store(release),ready.store(release) synchronizes-with ready.load(acquire),ready.load(acquire) sequenced-before Use(data)。三段接起来,data = 42 happens-before Use(data)。
happens-before 是可以传递的。如果 A happens-before B,B happens-before C,那么 A happens-before C。这个传递性非常重要------它意味着你可以把多段同步关系串成一条长链,链条起点的写入对链条终点的读取一定可见。
还有一点需要特别强调:happens-before 不是物理时间上的先后。它是 C标准定义的一种逻辑关系。操作 A 可能在物理时钟上比操作 B 先执行,但如果它们之间没有 happens-before 关系,A 的效果对 B 就不一定可见。C 标准不关心物理时钟,它只关心你有没有建立正确的同步关系。
mutex 也建立 happens-before
说到同步关系,很多人第一反应是 std::atomic 的 release/acquire。但其实最常用的同步工具------std::mutex------同样是内存模型的一部分,同样能建立 happens-before 关系。
cpp
#include <mutex>
std::mutex mtx;
int data = 0;
void Producer() {
std::lock_guard<std::mutex> lock(mtx);
data = 42;
}
void Consumer() {
std::lock_guard<std::mutex> lock(mtx);
Use(data);
}只要 Producer 先执行(先拿到锁、先释放锁),那 Consumer 后面拿到同一把锁的时候,Producer 在持锁期间做的所有写入对 Consumer 都可见。
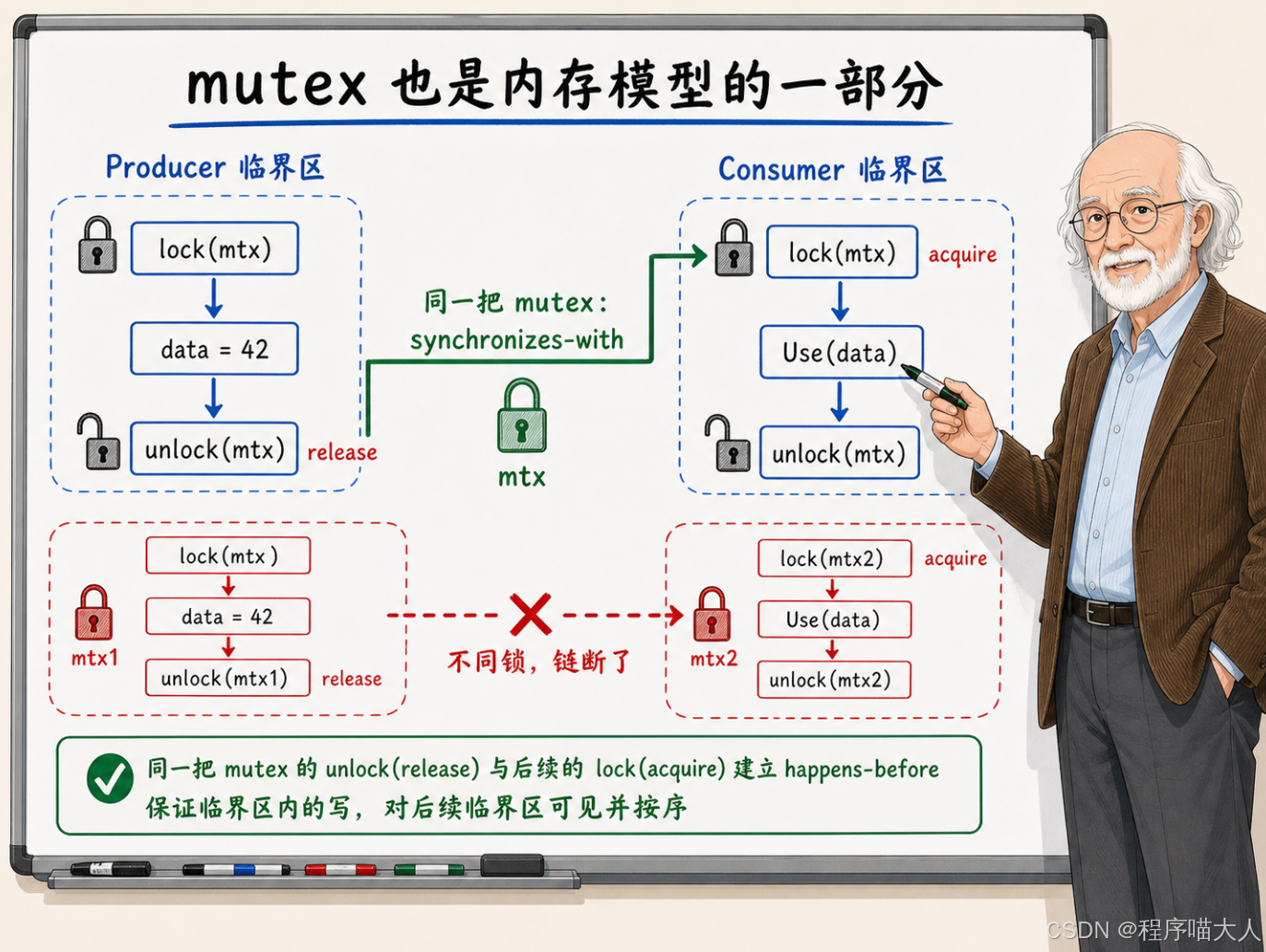
原理很直接:mutex 的 unlock 自带 release 语义,后续的 lock 自带 acquire 语义。Producer 的 lock_guard 析构时执行 unlock(release),Consumer 的 lock_guard 构造时执行 lock(acquire)。如果 Consumer 的 lock 发生在 Producer 的 unlock 之后(即 Consumer 拿到了 Producer 释放的那把锁),两者之间就建立了 synchronizes-with 关系。再加上各自线程内部的 sequenced-before,整条 happens-before 链就串起来了。
text
Producer 线程:
mtx.lock() (acquire)
data = 42
mtx.unlock() (release) ─── synchronizes-with ──▶
Consumer 线程:
mtx.lock() (acquire)
Use(data) // data 一定是 42
mtx.unlock() (release)很多人觉得 mutex"只是一把锁",没有把它和内存模型联系起来。其实 mutex 是 C++ 内存模型中最可靠的 happens-before 建立者之一。它在加锁和解锁的边界上自动提供了完整的内存屏障,不需要你手动指定 memory_order。这也是为什么大多数并发代码用 mutex 就够了------它把同步关系的建立完全封装起来了,你不用操心可见性的问题。
有一个常见的错误需要指出来:Producer 和 Consumer 必须锁同一把 mutex。如果两边锁的是不同的 mutex,就没有 synchronizes-with 关系,happens-before 链也断了。data 的可见性回到了"没有保证"的状态。这种 bug 在大型代码库里偶尔会出现------有人重构的时候不小心让两段代码锁了不同的 mutex,表面上代码还是"有锁保护"的,实际上同步关系已经断了。
数据竞争:内存模型画的红线
C++ 内存模型对并发代码画了一条硬边界:数据竞争(Data Race)直接判定为未定义行为(UB)。
什么是数据竞争?标准的定义很精确:两个不同线程对同一个内存位置进行访问,其中至少有一个是写操作,而且两个操作之间没有 happens-before 关系------这就构成数据竞争。
注意几个关键点:
必须是不同线程。 同一个线程里前后两次访问不算数据竞争,sequenced-before 关系保证了它们的顺序。
至少一个是写。 两个线程同时读同一个变量不是数据竞争。只有"至少一方在写"的并发访问才构成竞争。
没有 happens-before。 如果两个访问之间有 happens-before 关系(不管是通过 mutex、atomic release/acquire、还是其他同步手段建立的),就不算数据竞争。
一旦程序触发了数据竞争,后果不是"偶尔读到旧值"这么简单。未定义行为意味着编译器可以做任何事情。实际上编译器做的事情往往比你想象的更离谱------它会在优化时假设你的程序不存在数据竞争,然后基于这个假设做推理。
cpp
bool stop = false;
void Worker() {
while (!stop) {
DoOneRound();
}
}如果另一个线程直接写 stop = true,没有任何同步保护,这就是数据竞争。编译器在分析 Worker 的时候,会按照"程序没有数据竞争"这个前提来推理:既然没有数据竞争,那在 Worker 内部就不会有其他线程修改 stop,所以 stop 在整个循环里都是 false。于是编译器可能直接把循环优化成 while (true),死循环。
这不是编译器故意捣乱,而是它按照标准允许的规则做了合理推断。你违反了规则(引入了数据竞争),编译器的推理前提就错了,后果自然不可预测。
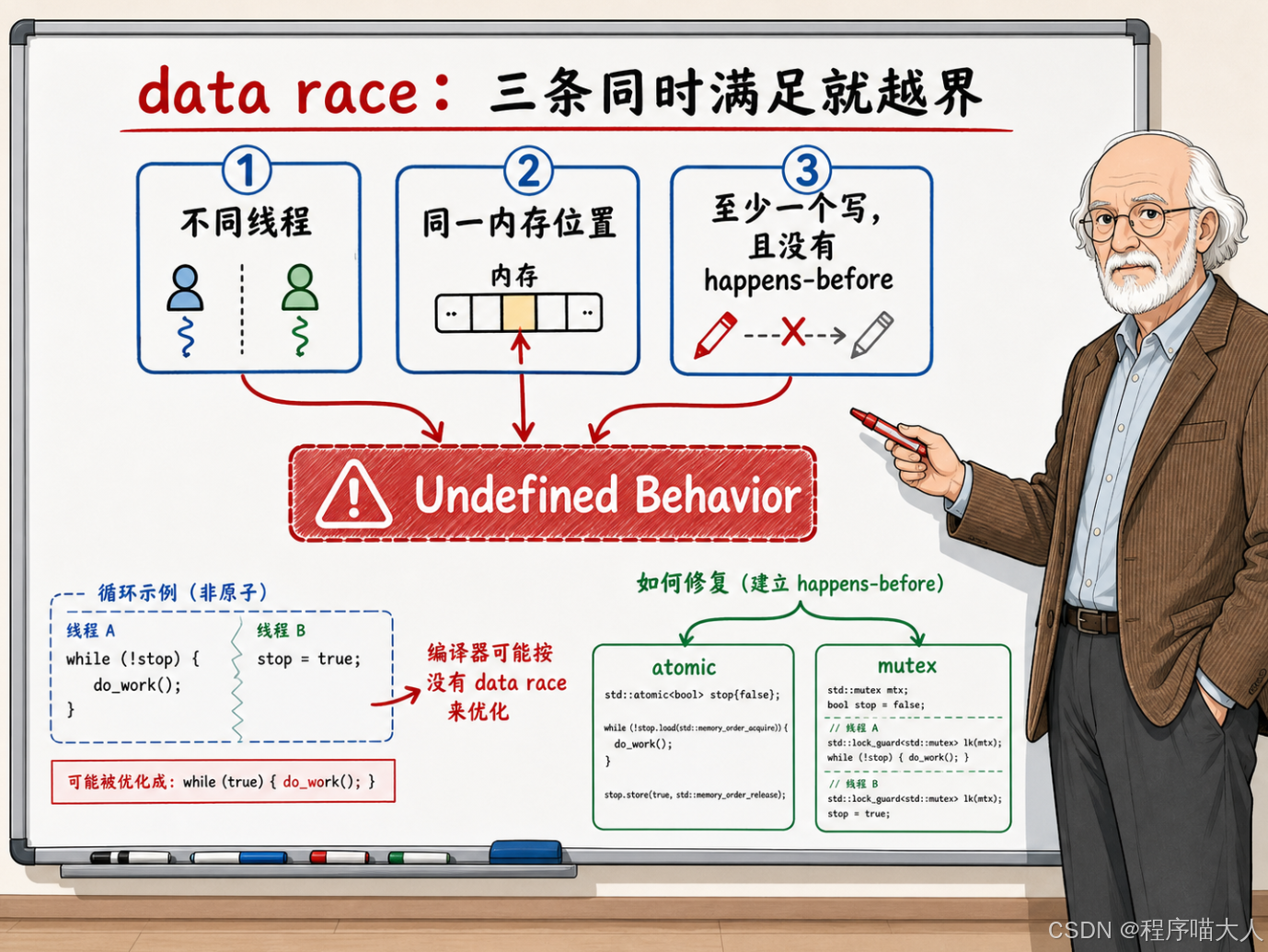
避开数据竞争的方法很直接:要么用 std::atomic 包装共享变量(原子变量的并发读写不构成数据竞争),要么用 std::mutex 保护访问路径(锁提供了 happens-before 关系)。两者的共同点是:它们都在读写操作之间建立了 happens-before 关系,让并发访问脱离了"无序"的状态。
修改顺序:每个原子对象有自己的时间线
C++ 内存模型里还有一个概念叫修改顺序(Modification Order)。每个原子变量都有自己独立的修改顺序------所有线程对这个变量的写入,会排成一条确定的、所有线程都认可的顺序。
cpp
#include <atomic>
std::atomic<int> x{0};
void A() { x.store(1, std::memory_order_relaxed); }
void B() { x.store(2, std::memory_order_relaxed); }
void C() { x.store(3, std::memory_order_relaxed); }三个线程分别往 x 里写 1、2、3。最终 x 的修改顺序可能是 1→2→3,也可能是 3→1→2,或者其他任意排列------取决于硬件调度。但不管最终排成什么顺序,这个顺序是确定的,所有线程看到的是同一个顺序。
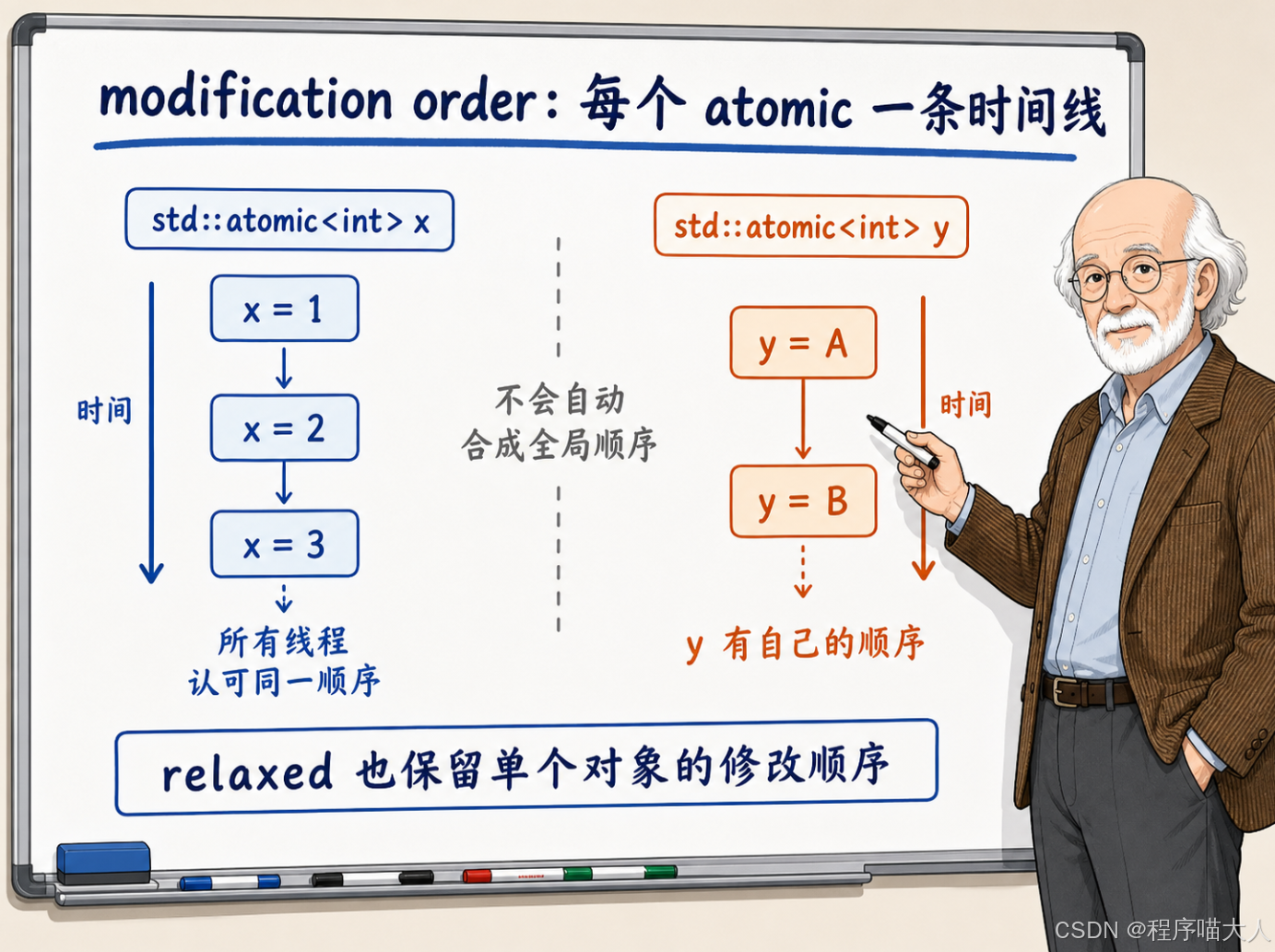
修改顺序有几个重要性质:
它是按对象隔离的。 x 有自己的修改顺序,y 也有自己的修改顺序。两条时间线是独立的。x 的修改顺序不会自动和 y 的修改顺序对齐。
即使是 relaxed 操作也尊重修改顺序。 relaxed 放弃了跨变量的全局顺序(后面几章会详细讲),但它仍然保证每个原子变量自己的修改顺序是一致的。不会出现线程 A 看到 x 的修改顺序是 1→2→3,线程 B 看到的是 3→1→2 这种矛盾。
读取操作会看到修改顺序中的某个值。 对一个原子变量做 load,读到的一定是修改顺序中某次写入的值,而且一旦读到了某个值,后续的 load(在同一线程内)不会读到修改顺序中更早的值。时间不会倒流。
修改顺序的概念为后面理解不同内存序的差异打下了基础。relaxed 只保证每个变量各自的修改顺序一致;release/acquire 在此基础上加了跨变量的可见性保证;seq_cst 更进一步,把所有原子变量的操作合并成一条全局顺序。约束越强,推理越容易,代价也越高。
可见性和顺序性是两件不同的事
在内存模型的语境下,"可见性"和"顺序性"经常被混在一起说,但它们其实是两个不同层面的问题。
可见性(Visibility) 问的是:一个线程写入的值,另一个线程能不能看到。这是最基本的问题。如果写入对另一个线程不可见,那什么顺序都没意义。
顺序性(Ordering) 问的是:多个写入之间的先后关系,是否能被其他线程正确感知。一个线程先写了 a = 1,再写了 b = 2,另一个线程能不能保证在看到 b == 2 的时候,一定也能看到 a == 1?
cpp
#include <atomic>
int a = 0;
int b = 0;
std::atomic<bool> ready{false};
void Producer() {
a = 1; // (1)
b = 2; // (2)
ready.store(true, std::memory_order_release); // (3)
}
void Consumer() {
while (!ready.load(std::memory_order_acquire)) { // (4)
}
// 此时 a == 1 且 b == 2 都有保证
Use(a, b); // (5)
}release store 解决了两个问题:可见性------a = 1 和 b = 2 的写入对 Consumer 可见了;顺序性------Consumer 在看到 ready == true 的时候,a 和 b 的写入一定已经完成,不会出现"看到了 b == 2 但 a 还是 0"的情况。
如果这里不用 release/acquire,而是用 relaxed:
cpp
void Producer() {
a = 1;
b = 2;
ready.store(true, std::memory_order_relaxed);
}
void Consumer() {
while (!ready.load(std::memory_order_relaxed)) {
}
Use(a, b); // a 和 b 的值没有保证!
}relaxed 只保证 ready 这个原子变量本身的原子性。它不管 a 和 b。Consumer 看到 ready == true 之后去读 a 和 b,可能读到 0------因为 relaxed 没有建立任何跨变量的可见性保证。CPU 可能先把 ready = true 刷出写缓冲区,a = 1 和 b = 2 还在缓冲区里排队。Consumer 这时候去读 a 和 b,读到的就是旧值。
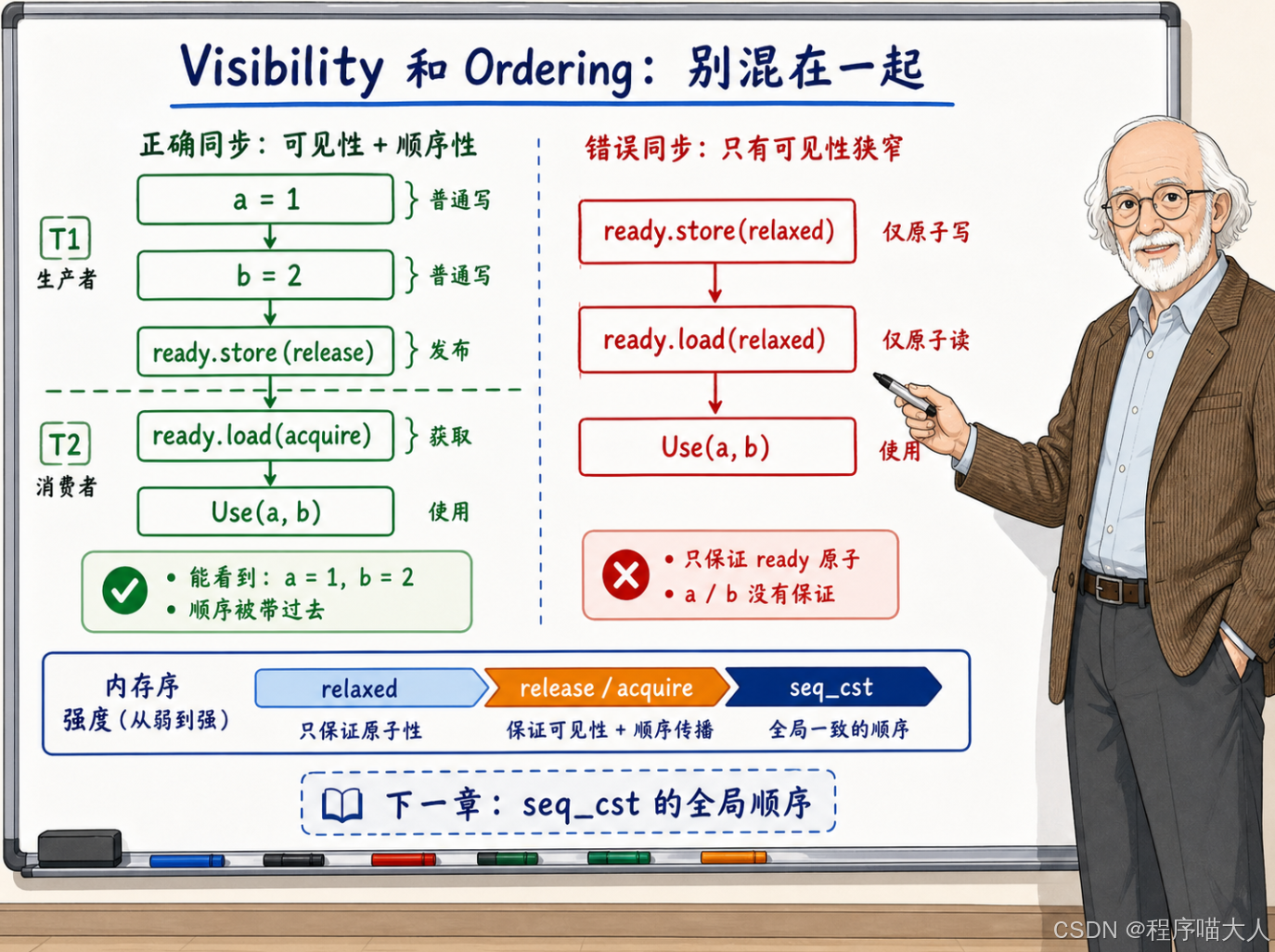
这个对比非常直观地说明了为什么内存序的选择很重要:同样的代码结构,release/acquire 下是安全的,relaxed 下就可能出错。差别就在于有没有建立跨变量的可见性和顺序性保证。
为什么需要这么复杂的模型
到这里你可能会想:为什么不直接规定所有写入立即对所有线程可见、所有操作严格按程序顺序执行?那就不需要什么 happens-before、什么 release/acquire 了,代码也好写多了。
答案是性能。
如果硬件要保证每次写入立即对所有核心可见,CPU 的写缓冲区就没有存在的意义了------每次写入都得等缓存一致性协议跑完一圈,确保所有核心都看到了新值,才能继续往下执行。这在多核系统上代价极高。写缓冲区存在的意义,就是让核心把写入暂存起来,不必等其他核心确认就能继续执行后面的指令。这大幅提升了单核心的吞吐量。
如果编译器不能对指令做任何重排,很多优化就做不了了。编译器把一个循环里的不变量提到循环外面、把不相关的内存访问调换顺序以提高缓存命中率------这些优化在单线程下完全正确,而且对性能有显著提升。如果因为"可能有其他线程在看"就禁止这些优化,单线程性能会大幅下降。
C++ 内存模型的设计思路是:不强迫硬件和编译器放弃这些优化,而是把选择权交给程序员。默认情况下,编译器和 CPU 可以自由重排和缓存延迟;程序员通过 memory_order 参数告诉编译器"这里需要同步",编译器才会在对应位置插入屏障。这样,只有真正需要同步的地方才付出性能代价,其他地方继续享受优化带来的速度。
这也是为什么 C++ 提供了多种内存序选择,而不是只有"全部同步"或"全不同步"两个极端。seq_cst 约束最强,最好推理,代价最高;relaxed 约束最弱,只保证原子性,代价最低;release/acquire 居中,保证定向的可见性传递,代价适中。程序员根据场景选择合适的强度。
内存模型的全景
把这一章的内容汇总一下,C++ 内存模型的核心可以概括成几条规则:
规则一:sequenced-before 管单线程。 同一个线程内,前面的语句 happens-before 后面的语句。这是基础。
规则二:synchronizes-with 管跨线程。 通过 release/acquire 配对、mutex 的 lock/unlock、以及其他同步原语,可以在不同线程之间建立 synchronizes-with 关系。
规则三:happens-before 是可见性的保证。 如果 A happens-before B(不管是通过 sequenced-before 还是 synchronizes-with 传递得来),A 的写入对 B 可见。
规则四:没有 happens-before 就没有保证。 如果两个操作之间没有 happens-before 关系,且至少一方是写操作,那就是数据竞争,属于未定义行为。
规则五:每个原子变量有自己的修改顺序。 所有线程对同一个原子变量的写入排成一条确定的顺序。不同原子变量的修改顺序彼此独立。
这五条规则就是内存模型的骨架。后面几章讲的 seq_cst、relaxed、release/acquire 等不同内存序,本质上都是在这五条规则的框架内做选择:你愿意付出多少同步开销,来换取多强的顺序和可见性保证。
下一章看 memory_order_seq_cst------它在 happens-before 的基础上加了一条全局顺序,把所有 seq_cst 操作排进同一条时间线。这是最强的保证,也是最容易推理的模型。
码字不易,欢迎大家点赞,关注,评论,谢谢!