前言
最近在做一个企业信息批量采集的小工具,本意是去找现成的API。API还没正式接入,先顺手在官网搜了几家公司试试数据质量。
搜了几条之后看了一眼URL,结构挺规整的,就用 requests 拉了一页试试。结果直接返回了 HTML,没有验证码,没有跳转,什么都没拦。
后面又加了几层,还是没拦。
既然反爬约等于没有,那就顺便看看能从页面上拿到哪些数据。
@toc
一、网站长什么样?能查到什么?
网站在这里:鲸海数据
ini
<https://www.kqdaas.com/?utm_source=csdn&utm_medium=blog&utm_campaign=202606_brand_launch&utm_content=csdn_005>首页就有非常明显的搜索框,支持输入公司名称、法人名字或产品关键词。

返回的是基础工商信息,公司名称、统一社会信用代码、法定代表人、注册资本、成立日期、注册地址、经营状态、所述行业、经营范围这些字段都有。
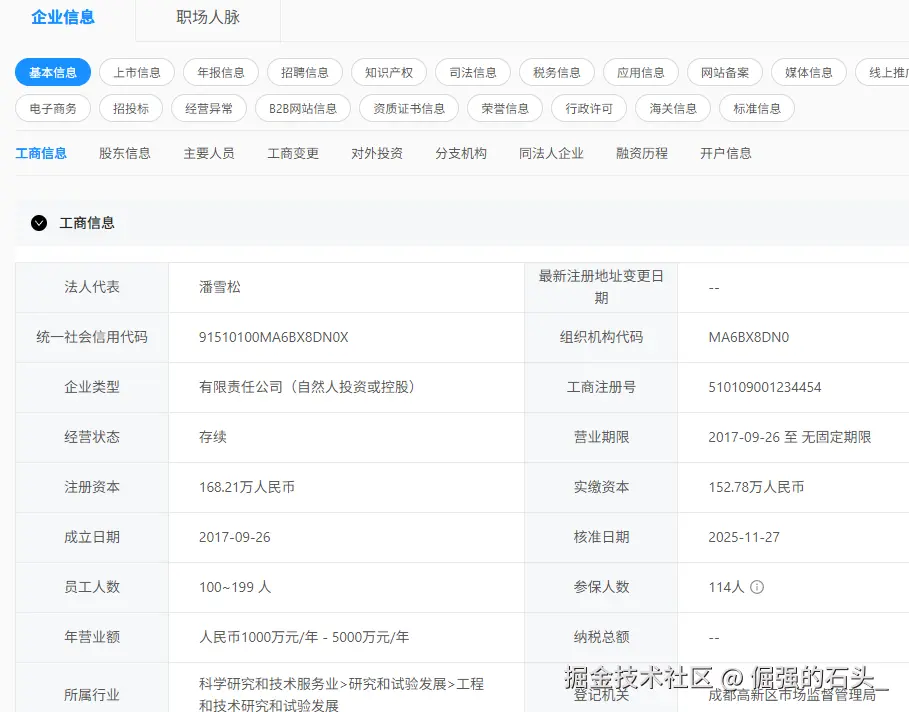
对于做数据清洗、客户筛选、初步市场分析的场景来说,这些字段已经够用了。
二、爬虫实战:代码直接跑
既然网站不设防,那就不客气了。用 requests + BeautifulSoup 写一个简单的爬虫,批量爬取企业基础信息。
python
import csv
import json
import re
import time
from urllib.parse import quote
import requests
# 鲸海数据(kqdaas.com)是 Next.js Server Action 接口:
# - 不是普通 GET 返回 HTML,而是 POST /search 带 next-action 头,
# body 里的 keywords 才是真正的搜索词,返回 RSC 流式文本。
# - 真正的数据在以 "1:" 开头的那行 JSON 里(data.records)。
# - NEXT_ACTION / COOKIE(尤其 hh-token 登录态) 来自浏览器抓包,失效需重新抓包替换。
BASE_URL = "https://www.kqdaas.com/search"
# 搜索关键词列表
KEYWORDS = ["科技", "信息", "数据"]
OUTPUT_CSV = "company_data.csv"
HEADERS = {
"accept": "text/x-component",
"content-type": "text/plain;charset=UTF-8",
"origin": "https://www.kqdaas.com",
"referer": BASE_URL,
"next-action": "7f4db410c3cc3eabe9c3ae6dd4b83ade5bd1c26d8d",
"next-router-state-tree": (
"%5B%22%22%2C%7B%22children%22%3A%5B%22(local)%22%2C%7B%22children%22%3A%5B%22search%22"
"%2C%7B%22children%22%3A%5B%22__PAGE__%22%2C%7B%7D%2Cnull%2Cnull%5D%7D%2Cnull%2Cnull%5D%7D"
"%2Cnull%2Cnull%5D%7D%2Cnull%2Cnull%2Ctrue%5D"
),
"user-agent": (
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
"AppleWebKit/537.36 (KHTML, like Gecko) Chrome/149.0.0.0 Safari/537.36"
),
"Cookie": (
"__bid_n=19eba682f8b6864d065fd9; "
"hh-token=hanhai-local-32960d96fc2ee62271c544a21f95c3de; "
"nb-referrer-hostname=www.kqdaas.com"
),
}
def parse_records(text):
"""从 RSC 流式响应里取出 data.records。
响应每行形如 <id>:<json>,只有一行 JSON 含 data.records。
只能按 \\n 切分,splitlines() 会在记录内的 Unicode 行分隔符(\\x85 等)处截断 JSON。
"""
for line in text.split("\n"):
_, sep, payload = line.partition(":")
if not sep or not payload.startswith("{"):
continue
try:
data = json.loads(payload).get("data")
except json.JSONDecodeError:
continue
if isinstance(data, dict) and "records" in data:
return data
return None
def search(keyword):
"""搜索关键词,返回 data 字典(含 records / totalRecords),失败返回 None。"""
# Server Action 入参结构固定,多加 pageIndex/pageSize 等字段会让服务端返回 data:null,
# 必须与抓包 body 完全一致。URL 上的 keyword 仅用于路由,真正搜索词在 body.keywords。
body = json.dumps([{
"type": "filter",
"keywords": keyword,
"businessLocation": "$undefined",
"companyIndustry": "$undefined",
"companyType": "$undefined",
"foundTime": "$undefined",
"registCapital": "$undefined",
"operateState": "$undefined",
"contactType": "$undefined",
"companyScale": "$undefined",
}], ensure_ascii=False)
resp = requests.post(f"{BASE_URL}?keyword={quote(keyword)}",
headers=HEADERS, data=body.encode("utf-8"), timeout=15)
resp.raise_for_status()
resp.encoding = "utf-8" # requests 会猜错编码导致中文乱码、JSON 解析失败
return parse_records(resp.text)
def main():
results = []
for keyword in KEYWORDS:
try:
data = search(keyword)
except Exception as e:
print(f"关键词「{keyword}」出错: {e}")
continue
if not data:
print(f"关键词「{keyword}」未解析到数据,next-action / cookie 可能已失效,需重新抓包")
continue
for r in data["records"]:
results.append({
"公司名称": re.sub(r"</?strong>", "", r.get("companyName", "")), # 去掉高亮标签
"统一社会信用代码": r.get("creditNumber", ""),
"法定代表人": r.get("juridicalPerson", ""),
})
print(f"关键词「{keyword}」爬取完成,本页 {len(data['records'])} 条,"
f"总计可搜 {data.get('totalRecords', 0)} 条")
time.sleep(1) # 礼貌性延迟
with open(OUTPUT_CSV, "w", newline="", encoding="utf-8-sig") as f:
writer = csv.DictWriter(f, fieldnames=["公司名称", "统一社会信用代码", "法定代表人"])
writer.writeheader()
writer.writerows(results)
print(f"总共爬取 {len(results)} 条数据,已写入 {OUTPUT_CSV}")
if __name__ == '__main__':
main()连续跑了一大批数据,几乎没有遇到限制,这种佛系程度在现在的企业数据站里确实少见**:**
- 没被封IP
- 没有弹验证码
- 未触发任何限速提示
- 数据字段完整可用
当然,具体的选择器需要大家自己去页面里看一下,不同网站的HTML结构不一样,这里只是给个框架。
三、2点风险提示
上面这套能跑通,但有几点还是得提醒一下。
一个是时效性。这种几乎不设防的状态,大概率不会一直持续。哪天流量上来了,或者运维随手加了个限流,可能就没了。如果你现在手头有数据采集的需求,趁早。
另一个是合规。爬之前最好看一眼 robots.txt,请求频率控制一下(代码里写个 time.sleep(1) 不费事),仅限合法合规用途。尊重数据版权,大规模商业化使用建议走官方API
四、有些数据爬虫拿不到,还是要接API
如果你需要的是更深入的维度,比如司法风险、招投标记录、知识产权布局、资质证书、舆情信息,这些爬虫拿不到,还是得靠API。
鲸海数据的API我顺手也测了一下,注册就送的1000次免费额度是全平台通用的,不是那种只开放一两个接口的阉割版。有深度查询需求的朋友可以顺便把API额度也领了。
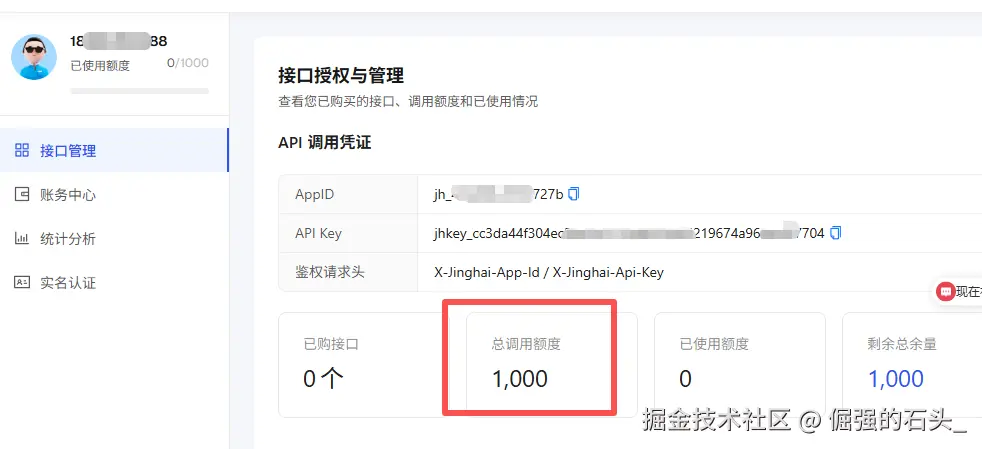
接口维度也比较多,企业服务相关的数据基本都有,我交叉测试了几个维度,精确度和及时性都还可以。
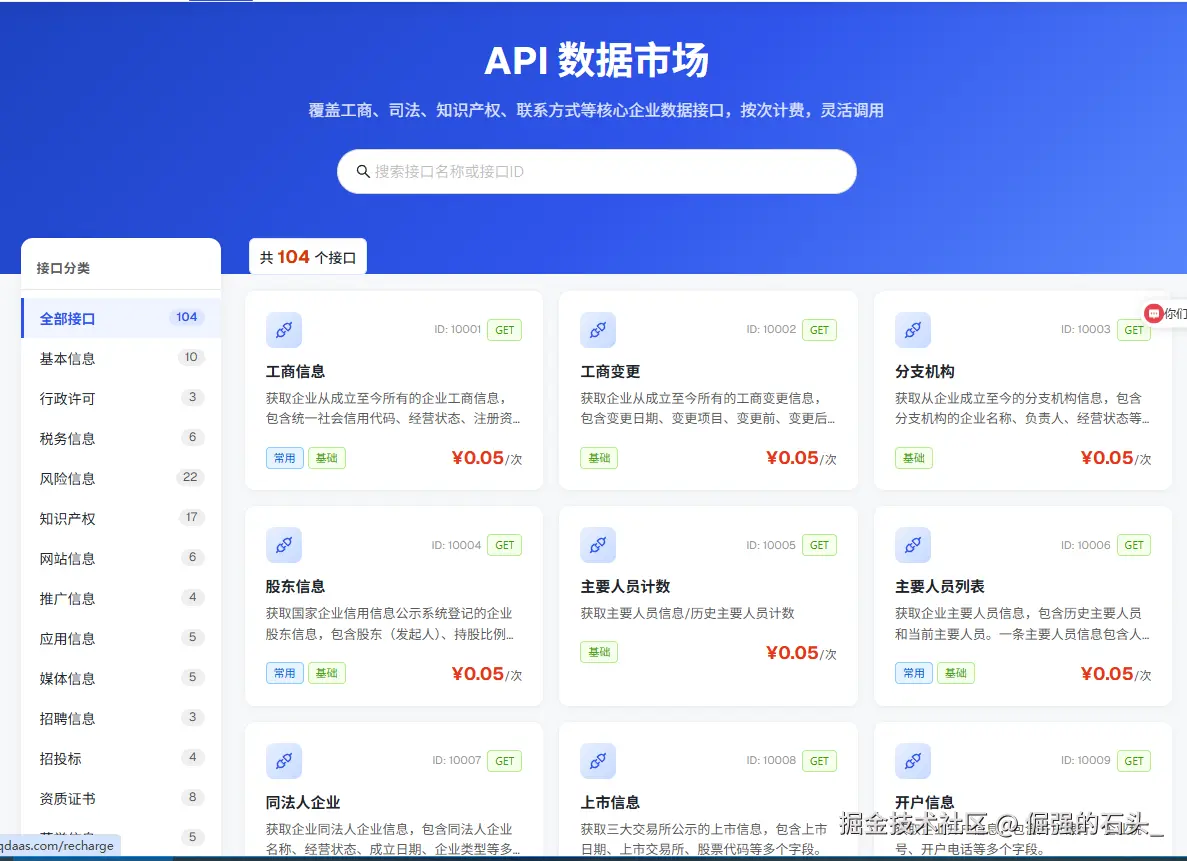
接口是标准的RESTful风格,用GET请求加Header鉴权就能调,Python几行代码的事。每个接口还有在线调试功能和详细的JSON 返回示例,方便你检查验证数据结构、字段完整性和参数逻辑。
比如「招投标信息列表」接口的JSON 返回示例如下:
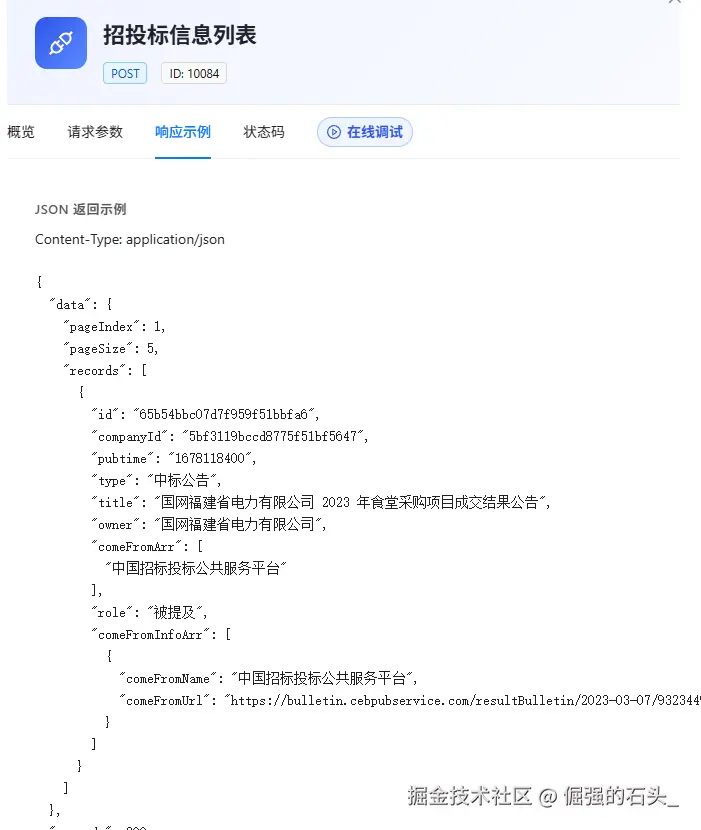
大概就这样,有这方面数据需求的朋友,趁着反爬还没上、API 有免费额度,早点去占个位,传送门:
ini
<https://www.kqdaas.com/?utm_source=csdn&utm_medium=blog&utm_campaign=202606_brand_launch&utm_content=csdn_005>