1、LoRA技术
(1)概述
LoRA全称:Low-Rank Adaptation,低秩自适应
解决的核心痛点:全量微调模型(如Llama 70B)显存消耗巨大,算力成本难以负担。
核心思想:在保持原参数不变的情况下,利用线性代数中的"低秩矩阵"分解作为Adapter。
(2)常规微调 vs LoRA微调
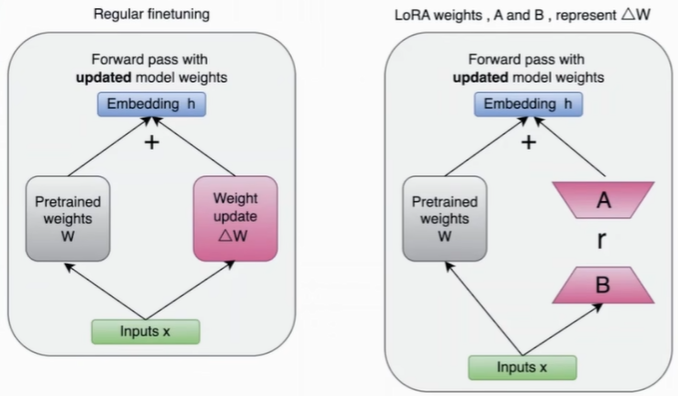
一般LoRA的PEFT微调参数占全部参数的5%左右。
(3)矩阵分解原理
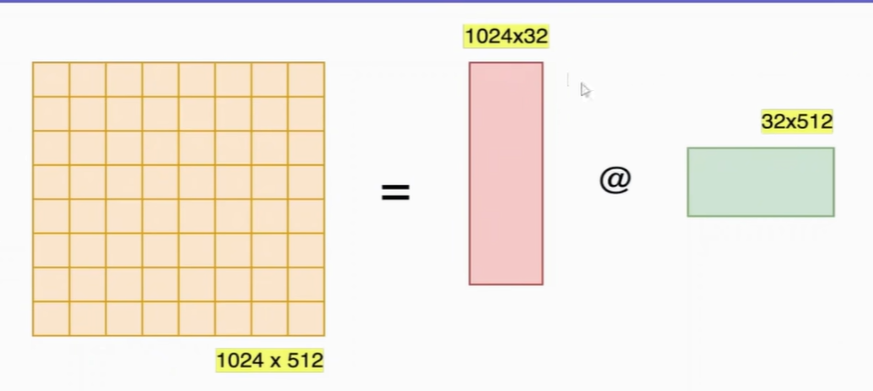
这里面的32就是矩阵的秩。
对于N * D的矩阵转为N * r以及r * D两个矩阵,我们希望r远远小于N和D。
一般r建议是4 ~ 32。
(4)权重初始化与缩放更新机制
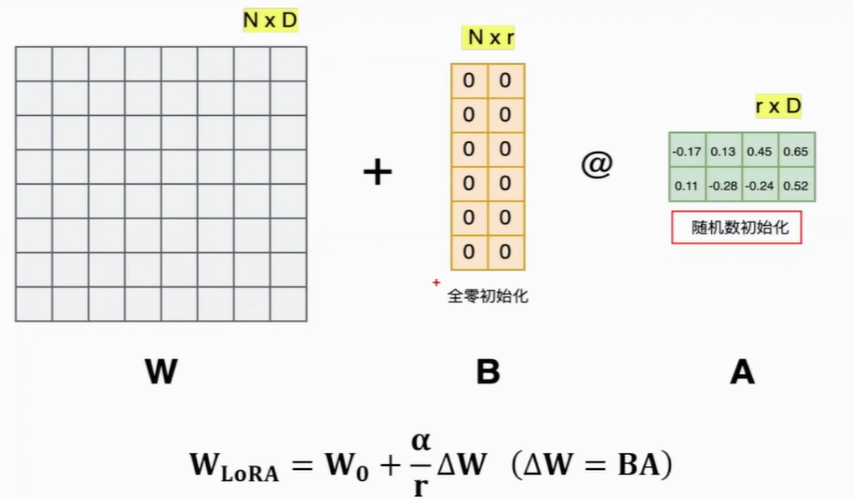
A一般初始化为高斯分布,B一般初始化为0,这样保证刚开始训练时为0,就是没有变化,之后随着训练再发生变化。
(5)代码实现
一般是基于Huggingface Transformers PEFT示例实现:
python
lora_config = LoraConfig(
alpha=1,
r=8,
target_modules=[
"q_proj",
"k_proj",
"v_proj",
"o_proj",
"gate_proj",
"up_proj",
"down_proj"
],
task_type="CAUSAL_LM"
)1)r=8
秩。这是LoRA最重要的超参数,它决定了低秩分解矩阵A和B的内部维度。
2)alpha=1
缩放系数。这是控制LoRA输出"影响力"的缩放系数。
3)target_modules
目标模块列表。指定要把LoRA适配器挂在模型的哪些线性层上。
4)task_type="CAUSAL_LM"
任务类型。causal_lm表明这是针对因果语音模型(自回归生成模型)的微调,比如LLaMA、Qwen等。它会告诉PEFT库采用适配该任务的前向传播逻辑,例如遮蔽未来的token。
2、模型量化
(1)定义
在大模型训练过程中,量化是一种降低模型计算复杂度和存储需求的技术。
量化的核心是:将模型的权重和激活值从高精度表示(如32位浮点数)转换位低精度表示(如8位整数),从而减少计算和内存使用,同时尽量保持模型性能。
量化主要分为两种主要类型:权重量化和激活量化。
权重量化:将模型权重从高精度表示(例如32位浮点数)转换为低精度表示(例如8位整数)。
激活量化:将模型激活值(即每一层的输出)从高精度表示转换为低精度表示。
量化方案分两种流派:线性映射、存索引号查找映射表
(2)线性映射
1)对称量化
- 核心公式
,
- 反量化
- 存储
int8 / int4数值
- 适用
权重Weight
2)非对称量化
- 核心公式
,
- 反量化
- 存储
int8 / int4数值
- 适用
激活值Activation
(3)存索引号查找映射表
1)均匀格点量化
- 核心公式
,将-1,1均分成
个格,记为grid,
- 反量化
- 存储
索引编号(如0~15)
2)NF4非均匀格点
- 原理
为正态分布量身定做非均匀格点,0附近密集,尾部稀疏,且格点内含0。做法:将标准正态分布按累积概率(面积)均分为N个等概率区间,每个区间选取其中位数作为该区间的量化代表值。
- 核心公式
,取当前分块中的绝对最大值
- 反量化
- 存储
索引编号(如0~15)
- 适用
QLoRA微调中4-bit基座模型的权重
3、QLoRA工作流程
简要描述:加载时压成4-bit存好,计算时临时解压成16-bit算好,反向时只改LoRA的小参数。
(1)基座模型初始化量化
在训练开始前,将原始 FP16 基座模型离线转换为 4-bit 存储态,具体拆解如下:
-
分块(Block-wise):将大权重张量切成小块(如每 64 或 256 个值为一块),目的是让每个块拥有独立的缩放因子,以适配局部数值分布。
-
计算缩放因子 :对于每个块,计算其绝对最大值
scale = absmax(X_block)(即该块内最大的那个数值)。 -
归一化 :将块内所有权重除以
scale,压缩到[-1, 1]区间:X_norm = X_block / scale。 -
非均匀格点映射 :拿着归一化后的值,去匹配预计算好的 NF4 非均匀格点表 (包含 16 个专为正态分布设计的格点值),取最近的格点,并存储其索引(0~15)。
-
双重量化(Double Quantization) :把所有块算出来的
scale(原本是 FP32)再收集起来,进一步量化为 8-bit,以节省额外显存。 -
最终存储 :显存中只保留4-bit 的索引 + 8-bit 的 scale 元数据 。同时,将基座模型的所有
requires_grad设为False,完全冻结。
(2)前向传播
-
按需解压 :计算某一层时,将该层对应的 4-bit 索引临时反量化 回 BF16/FP16。操作是:查 NF4 格点表得到浮点数,再乘以该块存好的
scale(即X_deq = grid[idx] * scale)。注意:是一次解压一层,算完立刻丢弃临时的 FP16 张量,显存里永远只躺着 4-bit 压缩态。 -
双轨计算:
-
基座支路:
h_base = W_dequantized @ x -
LoRA 支路:
h_lora = (B @ A) @ x(A、B 为 BF16/FP16 全精度,可训练)
-
-
结果合并 :
h_output = h_base + (alpha / r) * h_lora,输出至下一层,直至算出最终 Loss。
(3)反向传播
-
梯度截断 :由于基座
W的requires_grad=False,框架不为其计算或存储梯度。即使 Loss 回传时数学上存在梯度,也会被直接丢弃(Detach)。 -
仅更新适配器 :梯度仅流经 LoRA 支路,计算出
dA和dB,优化器(如 Paged AdamW)仅更新A和B的权重,基座W完全纹丝不动。
(4)迭代循环
-
基座恒冻 :每一轮迭代,基座模型始终维持那份初始的 4-bit 压缩状态,量化格点和
scale固定不变。 -
适配器演进 :只有全精度的 LoRA 矩阵
A和B在梯度下降中逐步优化,适应下游任务。