原文链接Generative Modeling by Estimating Gradients of the Data Distribution | Yang Song
一、生成模型
目标:假设有一个数据集 ,其中每个数据点都是独立地从一个潜在的数据分布
中采样出来的。给定这个数据集,生成建模的目标就是拟合一个模型来逼近这个数据分布,从而让我们能够通过从该分布中采样,随心所欲地合成新的数据点。
现有的生成模型根据如何表示概率分布,分为两大类:
1.1 基于似然的模型(Likelihood-based Models)
通过(近似)最大似然估计,直接学习数据的概率密度函数。典型代表包括:
- 贝叶斯网络 / VAE(Variational Autoencoder):引入隐变量 z,通过有向无环图(DAG)建模变量间的条件依赖关系。训练时最大化变分下界(ELBO)来间接逼近数据的似然度。
- 马尔可夫随机场(MRF / 能量模型 EBM) :无向图模型,通过能量函数定义概率,能量越低概率越高。由于无方向,其归一化常数(配分函数)通常难以精确计算。【马尔可夫性:未来只依赖当前状态,而不额外依赖过去历史。或者说:在给定当前状态的条件下,未来与过去条件独立
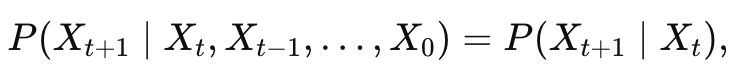 】
】 - 自回归模型(Autoregressive Models) :将高维数据的生成拆解为按序串行生成的过程,联合概率被拆解为条件概率的乘积:
。训练时可并行,推理时必须串行生成,速度较慢。
- 流模型(Normalizing Flows) :通过一系列可逆的、可导的非线性变换,将复杂的数据分布精确映射到简单的基础分布(如标准高斯),可精确计算似然。但对网络架构(可逆性、雅可比行列式可解)有极苛刻的数学限制。
1.2 隐式生成模型(Implicit Generative Models)
通过对采样过程建模来隐式表示 概率分布,不直接计算概率密度。最典型的代表是GAN(生成对抗网络) :通过神经网络将随机高斯向量变换为新样本,需对抗训练,容易出现模式崩溃(Mode Collapse)。
1.3 两类模型的共同局限
- 基于似然的模型:要么需要对网络架构施加严格限制以保证归一化常数可解,要么必须依赖代理目标函数(如 ELBO)进行近似训练。
- 隐式生成模型(GAN):对抗训练不稳定,容易模式崩溃。
二、核心障碍:归一化常数(分母)问题
2.1 问题根源
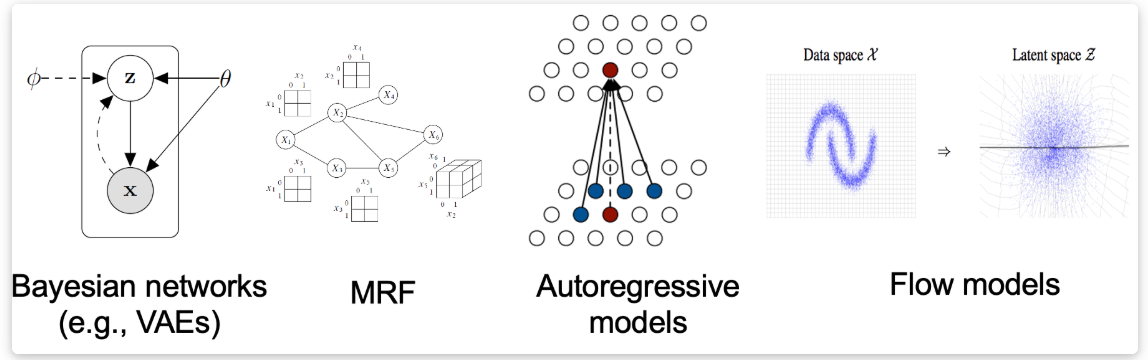
构建生成模型需要表示概率分布的方法。其中一种方法(就像在基于似然的模型中那样)是直接对概率密度函数(p.d.f.)或 概率质量函数(p.m.f.)建模。设 是一个由可学习参数
参数化的实值函数。我们可以通过以下方式定义一个概率密度函数:
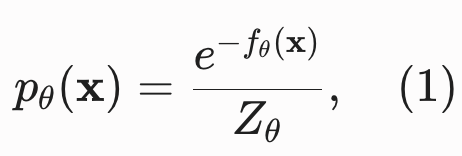
为了让概率模型严格归一化(所有可能图片的概率之和等于 1),需要引入归一化常数 ,用以确保
。 :
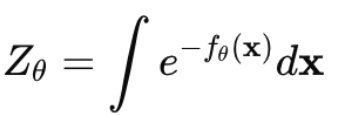
需要对全空间所有可能的图片排列组合(高维空间中是天文数字)求积分,在计算上完全不可解(Intractable)。
2.2 为什么概率总和必须等于 1?
不加总和约束,神经网络会无限制地给所有样本"刷分",导致数值爆炸,且失去鉴别能力(猫和狗的分数都无限大,无法区分)。总和为 1 是一个零和博弈的紧箍咒:给猫分配更多概率,就必须压低其他样本的概率,从而迫使模型真正学会数据分布。
关于"为什么两只猫的概率不能都是 70%" :
生成模型处理的是像素级的联合概率密度(即"这一张具体的图片出现的概率"),而非"属于猫这个类别的概率"。每张具体的猫图片分到的绝对概率可能只有 0.00001%,但其数值仍然远高于乱码图片,AI 在采样时就会以更高频率生成"像猫"的图片。
三、得分函数(Score Function):绕过分母的核心思路
通过对**得分函数(score function)进行建模,而不是直接对密度函数(density function)建模,我们可以绕过无法求解的归一化常数的难题。**
3.1 定义
得分函数 定义为对数概率密度关于输入 的梯度:
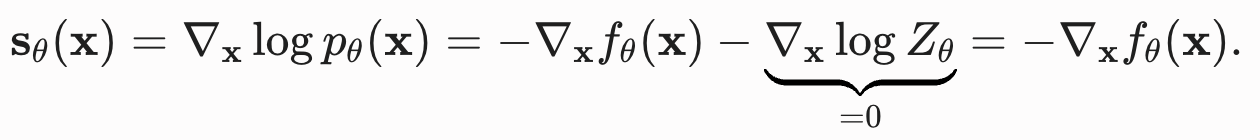
因为 是一个常数(或者说它只和参数
有关,和输入的数据
无关)。当我们对数据
求偏导(梯度
)时,
对
的导数直接等于0
为什么不直接叫梯度?
继承自传统统计学的 Fisher Score 命名传统;同时也为了与深度学习中"更新网络权重的参数梯度
3.2 关键数学性质:分母自动消失
当对含 的对数概率对x求导时:
由于 是关于
的常数 ,导数为 0,**分母
直接消失**。因此,基于得分的模型
可以使用任意网络架构,完全没有归一化约束。
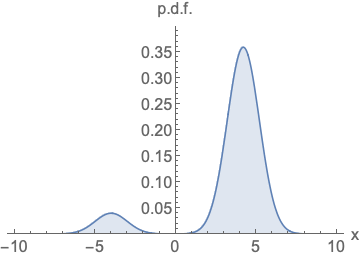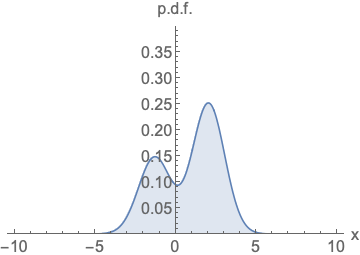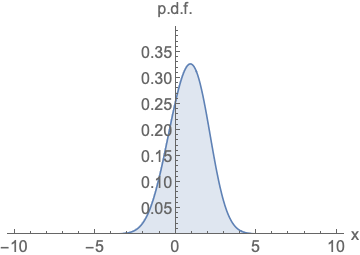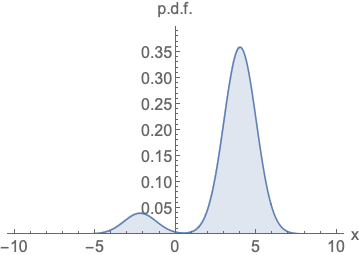
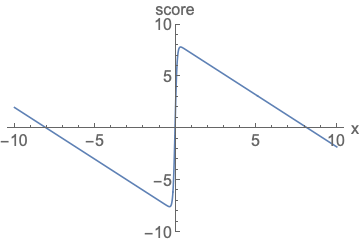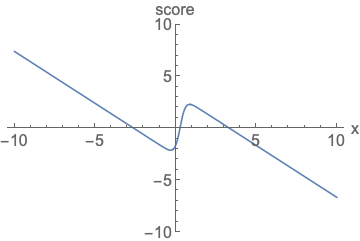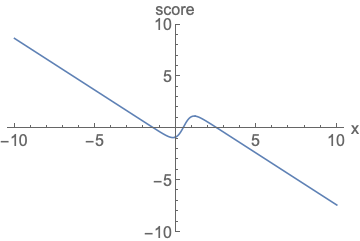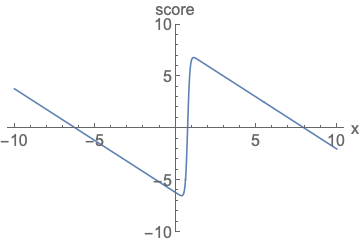
-
左图:参数化概率密度函数(p.d.f.)
无论如何改变模型的类型和参数,它都必须是归一化的(即曲线下方的面积积分必须等于 1)。这给网络架构套上了沉重的数学枷锁。
-
右图:参数化得分函数(score)
参数化得分函数时,完全不需要担心归一化问题。函数可以长成任意形状。
四、得分匹配(Score Matching)
4.1 问题与目标
训练得分模型的目标是使模型预测的得分 逼近真实数据得分
,两者之间的差距用**费舍尔散度(Fisher Divergence)**衡量:
得分匹配(score matching)可以在数据真实得分未知的情况下最小化费舍尔散度,目标函数可以直接在数据集上进行估计,使用随机梯度下降进行优化,类似于训练基于似然模型(在归一化常数已知时)的对数似然目标。
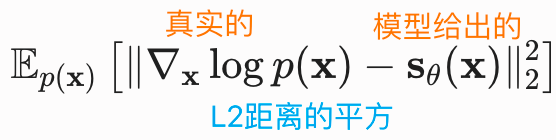
费舍尔散度本质上是两个向量场(修正方向场)之间的 距离,在期望意义下对所有真实数据点求平均。
-
普通图像的
比如把两张猫的图片像素对齐,对应格子相减。如果 AI 生成的猫少了一根胡须,像素对不上,普通的
-
费舍尔散度(得分的
它不比较图片本身的像素,而是把两张图塞进各自的"概率山"里,比较它们在每一个位置的山坡坡度方向。
新问题 :既然真实数据分布
4.2 分部积分:隐式得分匹配(ISM)
(显式)得分匹配的标准形式:
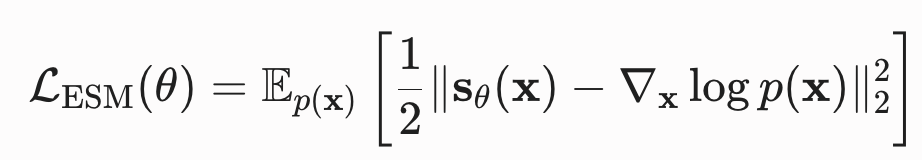
通过分部积分法,该目标函数可转换为不需要知道真实得分的隐式得分匹配(Implicit Score Matching,ISM)形式,二者在优化参数 时是完全等价的:
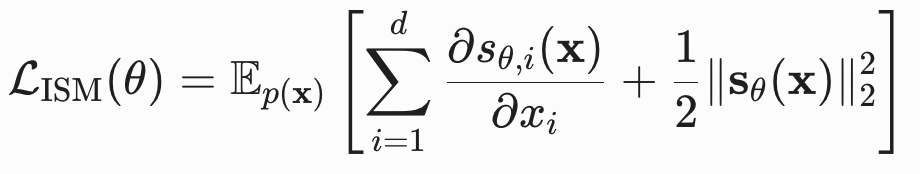
其中:
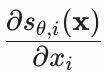 :模型输出对输入的偏导数,即雅可比矩阵的迹
:模型输出对输入的偏导数,即雅可比矩阵的迹 - 外层
分部积分"责任转移"的本质 :原本需要对 求微分的项,通过分部积分将微分符号从未知的
转移到了可知的模型
上。当
失去了微分符号,它退化为纯粹的概率密度权重/采样密度,可直接由数据集中样本的分布频率来近似。
把你手里的第 1 张、第 2 到第 N 张真猫图片
模型计算自己在这些真猫图片位置的输出
模型计算自己在这些真猫图片位置的梯度(雅可比矩阵的迹)。
将所有真猫图片算出来的结果加起来除以 N。
4.3 ISM 的三大优势
- 无需真实得分(无监督) :所有计算只涉及模型自身输出和已有数据集,不需要知道
- 非对抗训练:相比 GAN,训练完全基于标准随机梯度下降(SGD),无需判别器参与,训练稳定。
- 架构自由度高:对网络内部结构没有任何约束,只要输入输出维度一致(即输入图片,输出同维度的修正方向向量)即可。
五、朗之万动力学(Langevin Dynamics):从得分到生成
训练好得分模型后,通过朗之万动力学 进行采样(生成图片)。这是一种从任意初始分布出发,仅凭得分函数就能从该分布
中进行采样。具体来说,它从一个任意的先验分布
中初始化状态链,然后迭代执行以下公式:
- 得分项
- 随机项
当步长且迭代步数
时,
收敛为来自目标分布
的样本。
六、朴素得分模型的致命缺陷:低密度区域学不准
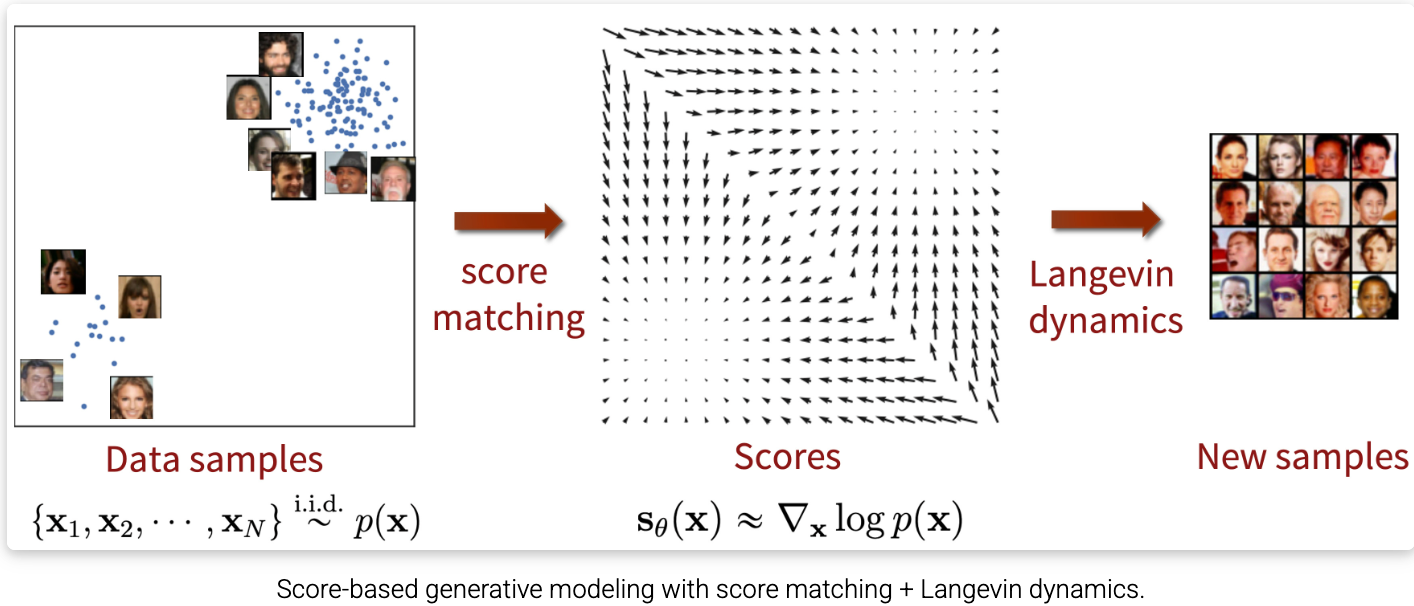
基于得分匹配 + 朗之万动力学的朴素生成模型流程:
数据样本 (Data samples) 得分场 (Scores) \\xrightarrow{\\text{朗之万动力学}} 新样本 (New samples)
6.1 问题根源
回顾 ISM 训练公式,真实数据得分函数与基于得分的模型之间的 差异被
(概率密度)加权:
- 高密度区 (有真实猫图片的区域):
- 低密度区 (无数据的纯噪声区域):
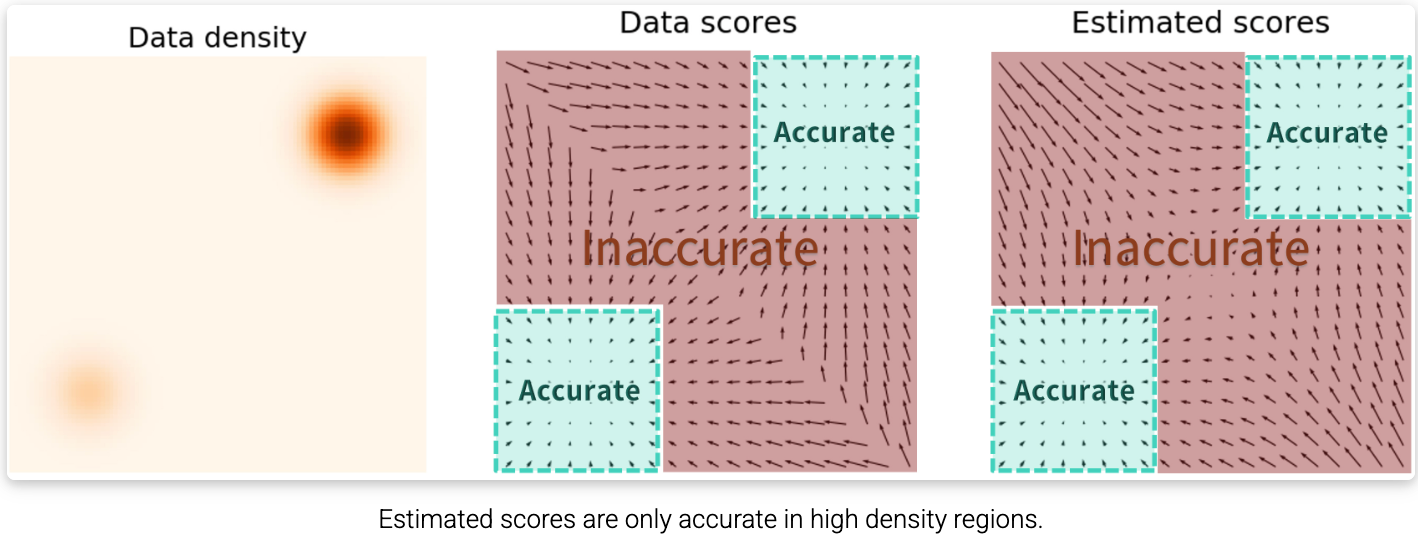
数据密度 (Data density):展示了两个高密度的橙色和黄色区域(有猫咪图片的区域),其余大片空白为低密度区(没有猫图片的冷门区域)。
真实得分 (Data scores):理想状态下全图每个角落都应该有的正确坡度。
估计得分 (Estimated scores) :AI 实际学出来的坡度。可以明显看到:只有在有数据的青色区域是准确的 (Accurate) ,而在大片没有数据的橙色中间区域全都是不准确的 (Inaccurate)。
6.2 采样时的开局暴击
在高维空间中,朗之万采样的初始点(随机噪声)100% 必然落在低密度的无人区。AI 开局就收到了错误的得分方向,立刻脱轨,无法生成有意义的图片。
七、多尺度噪声扰动与噪声条件得分网络:核心破局方案
7.1 核心思路
主动给真实数据加上大量噪声,强行将数据"抛洒"到全空间的低密度区域。
数学上,这等价于:从真实数据 x 中采样,加上幅度为 σ 的高斯噪声,得到 ,从而生成噪声扰动后的分布
。
大噪声将数据扩散到全空间后,低密度区域的权重 在全图都变大,AI 被迫在全空间认真学习得分,不再能"摆烂"。
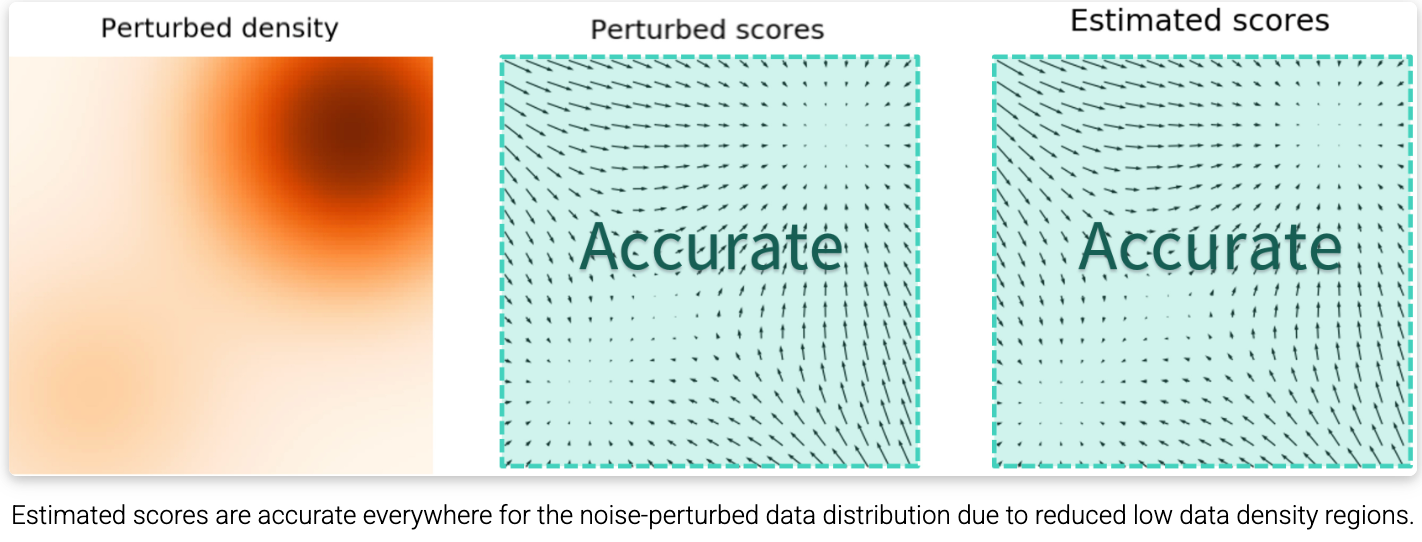
扰动后的密度 (Perturbed density):原本孤立的两个高密度圈,被大噪声冲刷、晕染开,连成了一片,覆盖了全图。
扰动后的得分 (Perturbed scores):在整个空间中都有了理想的斜率趋势。
估计出的得分 (Estimated scores) :AI 实际学出来的坡度。由于大片区域都被噪声填满了数据,AI 在全图每个角落都学得极其精准 (Accurate)。
下方小字:由于低数据密度区域的减少,噪声扰动后的数据分布在各处的估计得分都是准确的。
"填满无人区"的数学本质:加大量噪声后的图片看起来是乱码,但数学上它仍然残留了极其微弱的"原图数据特征"(条件概率)。这相当于在原本空无一物的空间中制造了一条隐形的"引力斜坡",AI 学到的并非"如何画出猫",而是"在这种乱码状态下,应该往哪个方向微调才能让图像更接近数据分布"。
7.2 多尺度噪声:等比数列阶梯
单一大噪声会过度破坏数据;单一小噪声覆盖面不足。科学家引入等比数列的多重噪声尺度:
- 噪声按等比数列衰减(几何级数),而非等差,使得开局大刀阔斧、终局精雕细琢。
7.3 噪声条件得分网络(Noise Conditional Score-Based Model,NCSN)
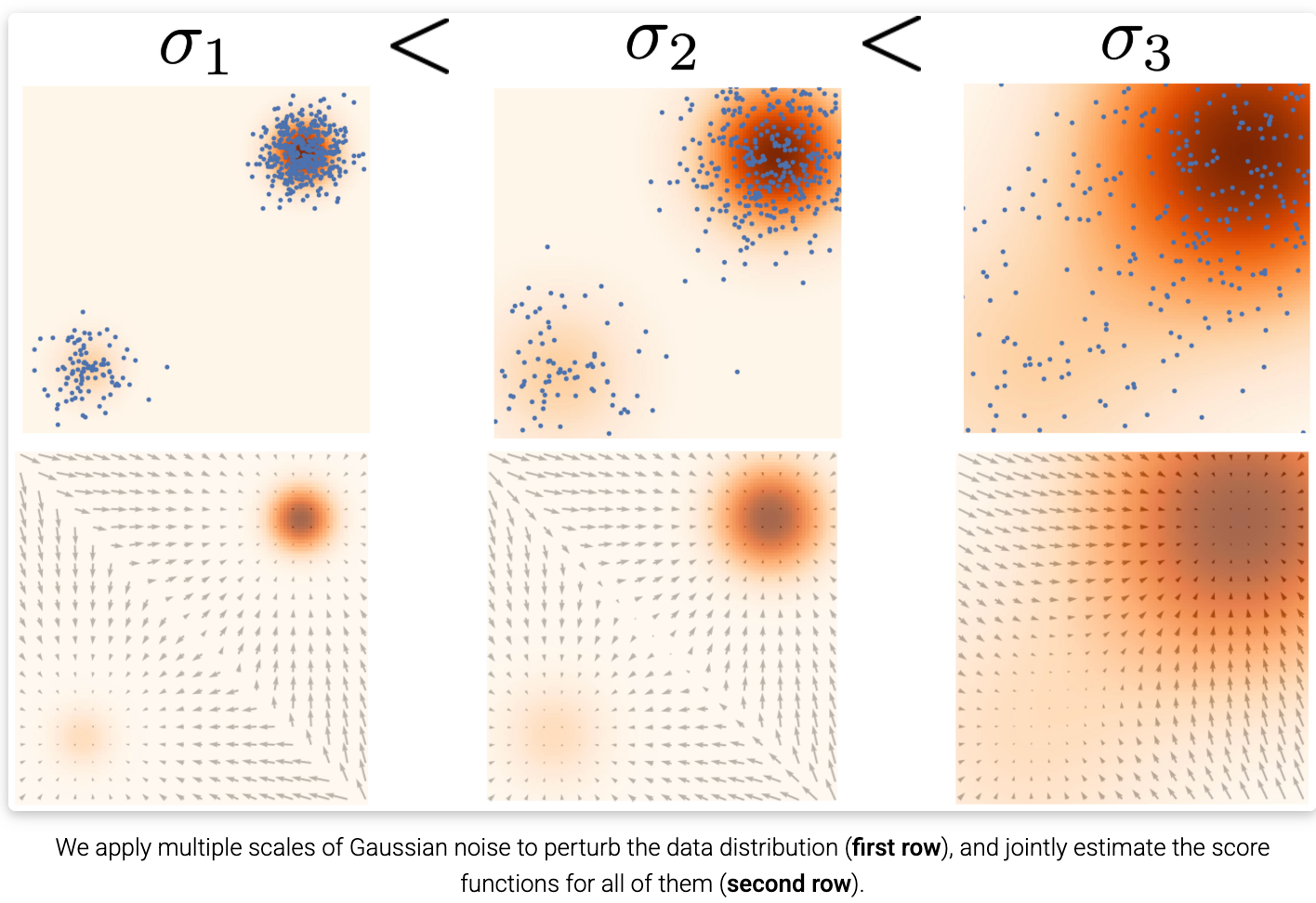
应用多个尺度的高斯噪声来扰动数据分布(第一行 ),并联合估计它们所有分布的得分函数(第二行 )。图中可以明显看到,随着
不为每种噪声单独训练一个网络,而是训练一个同时接受图像与噪声级别 作为输入的联合网络:
训练目标为所有噪声尺度费舍尔散度的加权和:

权重 通常选取
,目的是平衡不同噪声阶段损失的数值量级。
7.4 退火朗之万动力学(Annealed Langevin Dynamics):生成阶段
训练完成后,按噪声从大到小依次运行朗之万动力学采样:
- 从纯随机噪声出发(初始化
- 在最大噪声
- 随噪声级别逐步降低(从
- 在最小噪声
7.5 三大实战炼丹铁律(NCSNv2)
| 铁律 | 内容 |
|---|---|
| 等比缩噪 | 噪声按几何级数衰减,最大噪声需与所有训练数据点的最大两两距离相当 |
| U-Net 架构(含跳跃连接) | 浅层网络(微观细节)与深层网络(宏观框架)通过跳跃连接直接通信,防止局部雕刻时全局结构崩坏 |
| EMA 权重平均 | 测试时使用最近训练权重的指数移动平均(EMA),消除训练末期的参数抖动,获得更稳健的生成结果 |
八、连续时间随机微分方程(Score SDE)
把"分 L 步加噪"推向极限,即 时,加噪过程就从"阶梯式的跳变"变成"连续平滑的演变"。
"1000 层楼梯走起来还是一阶一阶地顿挫。我们为什么不直接修一部'如丝般顺滑'的无级变速扶梯,让加噪和去噪变成一条完美的、连续光滑的物理曲线呢?"这个过程用SDE实现
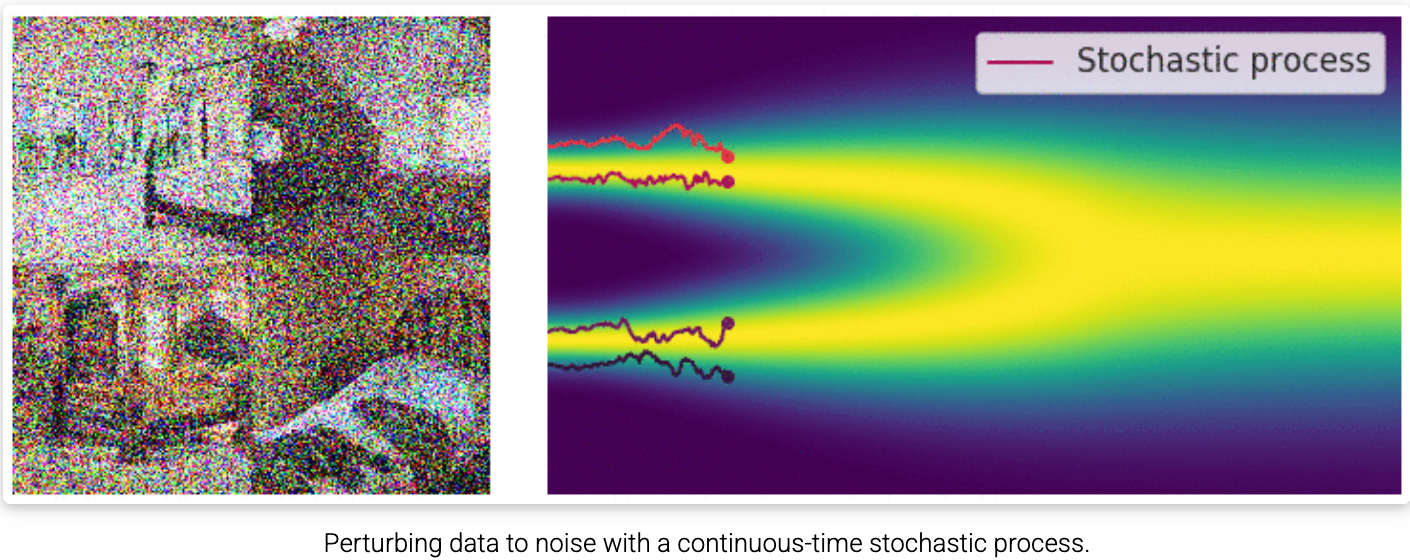
8.1 从离散阶梯到连续流动
当噪声尺度的数量 时,离散的"阶梯加噪"演变为连续时间的随机过程,用**随机微分方程(SDE)**描述:
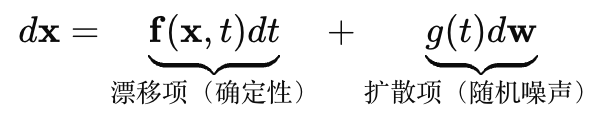
其中:
- g(t):扩散系数(Diffusion Coefficient),控制噪声注入的剧烈程度(单位时间内噪声方差的增长率)
8.2 三种常用 SDE 设计
VE SDE: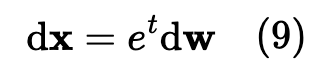
-
把前面的确定性牵引
-
让沙尘暴的速度随着时间按指数狂飙(
VP SDE(方差保持):让图片一边融化,一边把整体能量控制住,别让数值爆炸。这些设计,本质上就是科学家在决定"我的无级变速扶梯要用什么样的速度往下运行"。
| SDE 类型 | 漂移项 f | 扩散项系数 g(t) | 特点 |
|---|---|---|---|
| VE SDE(方差爆炸) | 0 | σ(t)指数增长 | 与等比数列加噪(NCSN)等价 |
| VP SDE(方差保持) | 保持总能量稳定,与 DDPM 等价 | ||
| sub-VP SDE | --- | --- | VP SDE 的改进变体 |
8.3 连续时间训练目标(公式 11)
- 时间 t 在区间 0,T内均匀采样
- λ(t):权重函数,用于平衡不同噪声阶段损失的数值量级。大噪声阶段原始误差天然极小,因此 λ(t)在大噪声时赋予较大权重,小噪声时赋予较小权重
- 当
8.4 先验分布
先验分布是整个框架中人工提前指定的、完全已知的纯随机噪声分布,通常为标准多元高斯分布 :
- 前向加噪的终点:数据被彻底融化后趋近的最终分布
- 逆向生成的起点:凭空生成图片时的初始随机噪声
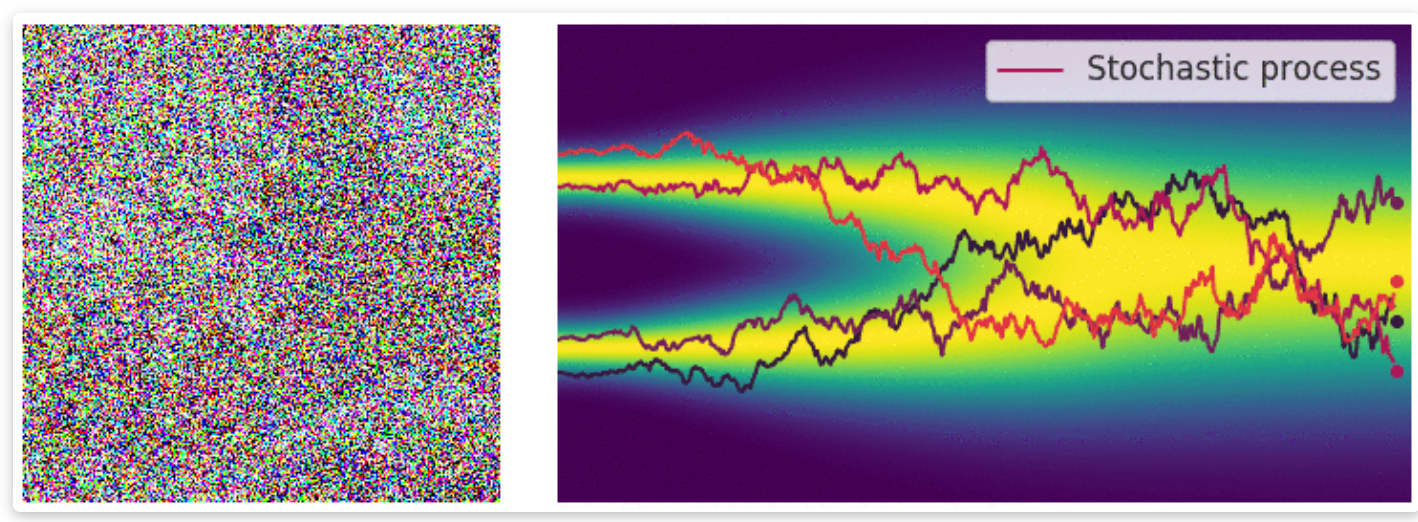
九、逆向 SDE:时间倒流生成新样本
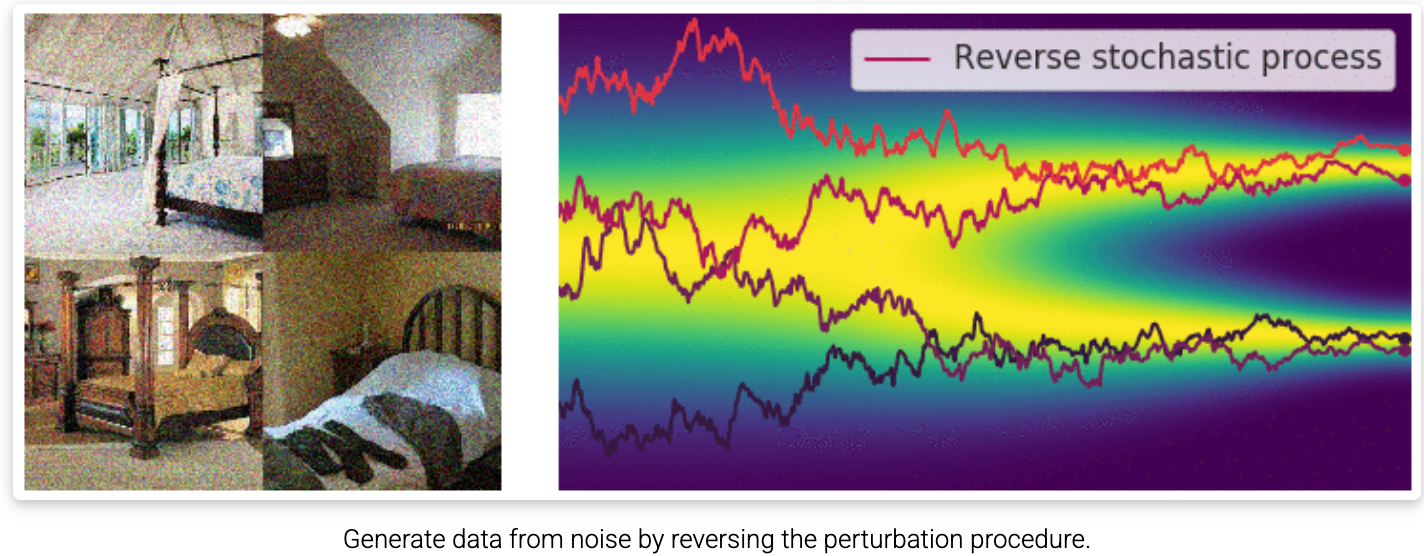
左边是一堆初始的纯随机乱码;右边展示了逆向随机过程中,数据轨迹如何从右侧散乱的噪声状态,收敛凝聚回左侧几个清晰的独立分支(高概率目标区)。
9.1 理论逆向 SDE(公式 10)
数学上证明,任何前向 SDE 都存在对应的解析逆向方程:
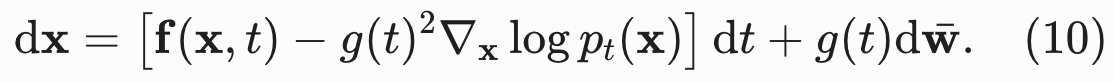
对应一个负的无穷小时间步长,因为 SDE (10) 需要在时间上逆向求解 (从 t = T 到 t = 0)。为了计算这个逆向 SDE,我们需要估计
,而这恰好就是
的得分函数(score function)。
- 方程中唯一的未知项是得分函数

图像从右到左,在**得分函数(蓝色框)**的指引下,将噪声抹去,重新凝聚回清晰的小狗
求解逆向 SDE 产生了一个基于得分的生成模型。利用 SDE 可以将数据转换为简单的噪声分布;如果我们知道每个中间时间步的分布得分,就可以逆转该过程,从而从噪声中生成样本。
9.2 实用逆向 SDE(公式 12)
将训练好的时间相关得分网络 代入(10),得到一个估计的逆向SDE:
(12)
生成流程 :从先验分布 π(x)中采样一个纯噪声 ,在区间 0,T内逆向求解 SDE,时间从 T 倒流到 0,最终输出生成样本
。
9.3 为什么逆向生成的是"新"样本,而非"原样本"?
两个核心原因:
- 逆向方程中的随机项依然存在 :尾部的
- 起点的蝴蝶效应:原图 100% 融化为纯噪声后,其原始信息已彻底消失。生成时从标准高斯随机采样的起点与原图融化后的坐标几乎不可能完全相同,极小的偏差在千步迭代后被非线性系统无限放大。
结论:逆向方程保证最终生成的是"同分布"的高质量样本,但不是"原样本"的完美复制。
9.4 KL 散度的理论保证(公式 13)
当权重函数选择为似然权重 时:
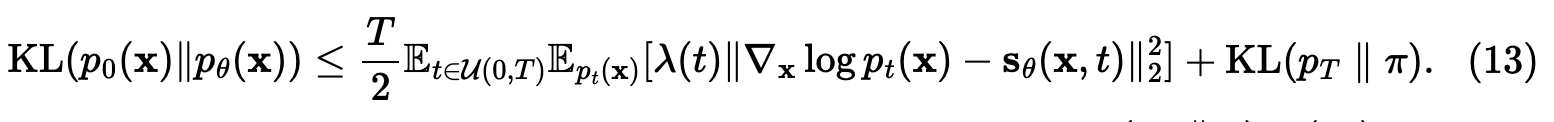
最小化 SDE 训练损失等价于压低生成分布 与真实数据分布
之间的 KL 散度上界,从而在数学上提供了最大似然训练的严格理论保证。
1. 传统似然模型:
死磕"绝对概率" ──> 遇到算不出的超大分母 Z_θ ──> 走进死胡同 ❌
2. 朴素得分匹配:
求导干掉分母,改看"坡度趋势" ──> 在真猫真狗大本营学得准 ──> 但在噪声无人区严重摆烂 ❌
3. 多尺度噪声 (NCSN):
主动掀起不同级别的沙尘暴灌满全图 ──> 给无人区修了一条引力磁力线 ──> 训练出能听懂噪声关卡的神经网络 ──> 追平 GAN 稳步通关
4. 连续时间 SDE (Score SDE):
把阶梯噪声变成丝滑的"无级变速扶梯" (公式 8 & 10) ──> 开启逆向时间长河的逆向 SDE ──> 纯随机噪声如流水般逆向凝聚 ──> 终成现代扩散模型统治天下的数学王座 👑十、工程落地:数值 SDE 求解
10.1 欧拉-丸山方法(Euler-Maruyama)
计算机运行连续方程必须离散化。将时间步长 dt替换为有限的 Δt(负时间步长 ,初始化
,并迭代以下步骤直到
):
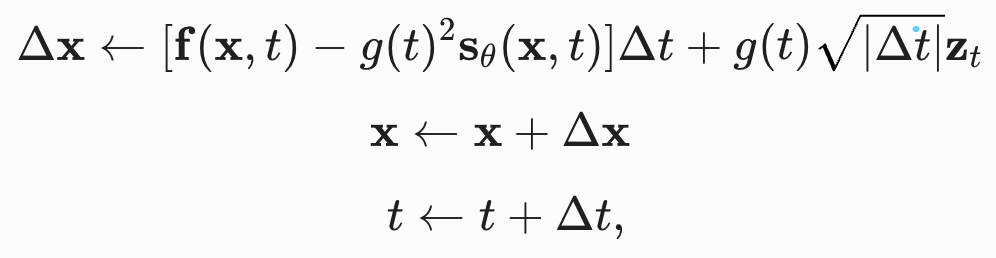
(随机噪声项乘以是因为离散化后布朗运动的方差正比于时间步长。)
10.2 预测器-矫正器采样法(Predictor-Corrector, PC)
将"大步推进"与"原地精修"结合:
| 角色 | 操作 | 作用 |
|---|---|---|
| 预测器(Predictor) | 执行一步 SDE 求解器,时间从 |
粗略去噪,在时间轴上向前赶路 |
| 矫正器(Corrector) | 时间指针冻结 在 |
原地利用得分函数反复微调像素,将图像拉回高概率轨道 |
因为数学上可以证明,我们最终要的只是 t = 0 瞬间的那个清晰图片样本。至于从 t = T 到 t = 0 的中间过程中,小狗图片的像素在第 2 秒和第 1.9 秒之间是否保持了物理学上严格连续的运动轨迹,根本不重要。 既然中间的轨迹不需要严格连续,我们就可以在每一秒钟的间隙里,让矫正器停下时间,把图像像素反复擦洗、修正到最完美的状态,然后再让预测器推进到下一秒。
两者配合消除了离散化带来的步长误差,大幅提升生成质量。实验结果(CIFAR-10):
| 方法 | FID ↓(越低越好) | Inception Score ↑ |
|---|---|---|
| StyleGAN2 + ADA | 2.92 | 9.83 |
| Ours(PC采样器) | 2.20 | 9.89 |
十一、概率流 ODE(Probability Flow ODE)
11.1 核心动机
逆向 SDE 尾部的随机项 导致了生成的不确定性,也使得精确计算似然值成为不可能。
数学上可以证明,存在与逆向 SDE 拥有完全相同边缘分布集合 的常微分方程(ODE) ,即概率流 ODE (公式 14):(可以找到一个确定性的 ODE,它和原来的随机 SDE 在每一个时间点 t 的概率分布 完全相同,尽管两者的轨迹长得完全不一样。)
(14)
关键区别:
- 得分项系数从
- 随机项彻底消失:方程变为纯确定性 ODE
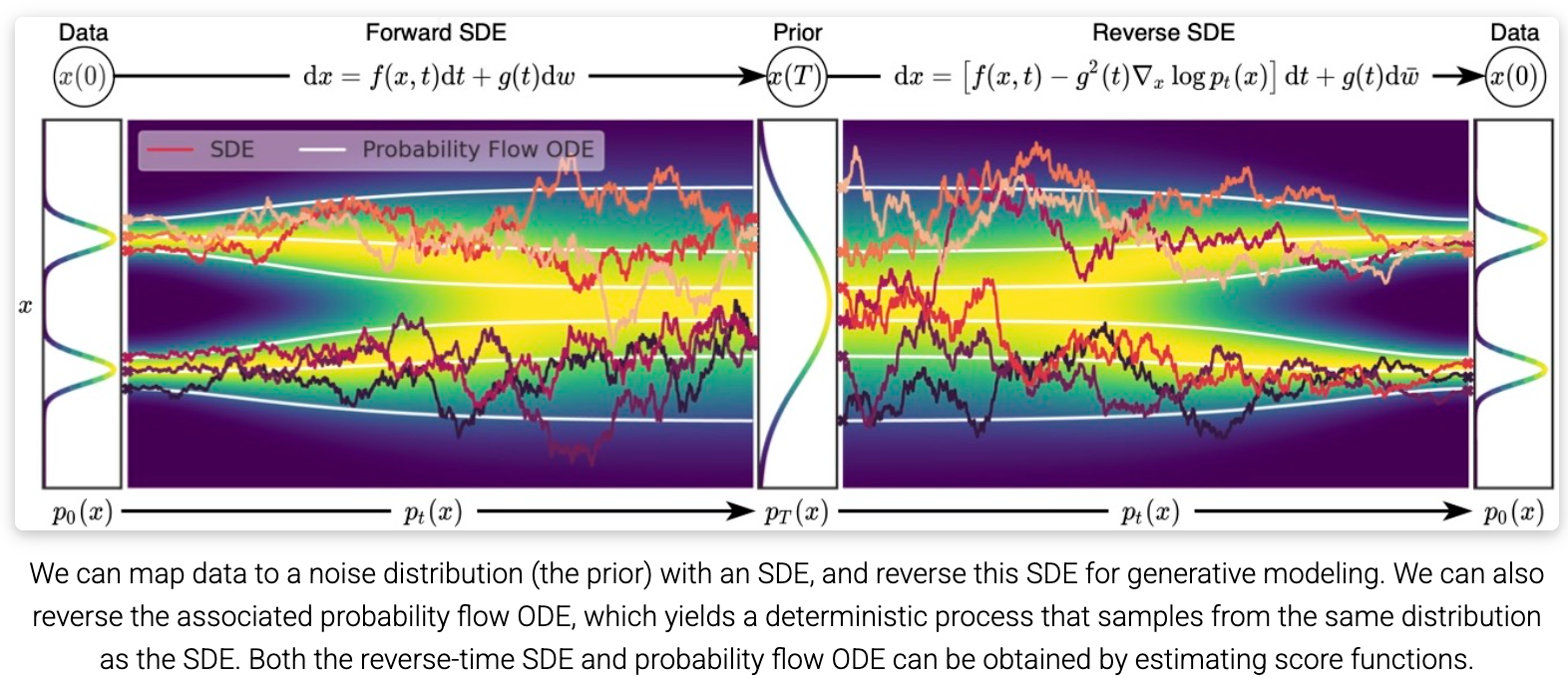
可以使用 SDE 将数据映射到噪声分布(先验),并在生成模型中逆转该 SDE。也可以逆转相关的概率流 ODE,从而产生一个从与 SDE 相同的分布中进行采样的确定性过程。逆向时间 SDE 和概率流 ODE 都可以通过估计得分函数来获得。
轨迹层面(单条曲线)
SDE 的每一条轨迹都是随机的锯齿曲线(图中彩色折线),每次运行都不一样。
ODE 的每一条轨迹是光滑曲线(图中白色曲线),给定起点后完全确定,每次运行结果相同。
这两种轨迹长得完全不同。
分布层面(全体轨迹的统计行为)
但如果你不看单条轨迹,而是看在时间点 t,所有轨迹上的数据点聚集形成的概率分布 p_t(\mathbf{x}),SDE 和 ODE 给出的结果是一模一样的。
具体来说:
- t=0时,两者都是原始数据分布
- t=T时,两者都收敛到先验噪声分布
- 中间任意时刻 t,两者的边缘分布
这就是"不改变边缘分布集合 \{p_t(\mathbf{x})\}_{t \in 0,T} {pt(x)}"的含义。
11.2 核心机制与数学逻辑
- 强行砍掉"随机项"的代价(对比公式 10 与 14)
标准的逆向 SDE(公式 10):
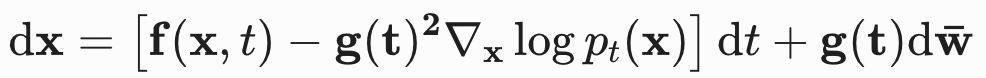
概率流 ODE(公式 14):
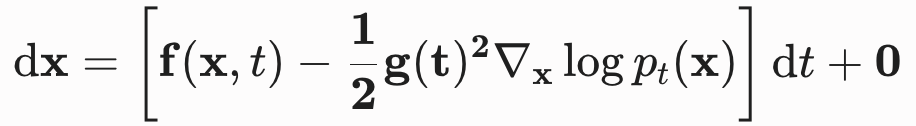
-
尾巴上的随机项彻底变成了 0:这意味着整个方程里不再包含任何"布朗运动",方程从"随机微分方程(SDE)"变成了"常微分方程(ODE)"。
-
得分项前面的系数从 1 变成了
- 边缘分布不变:白色平滑线的本质
图中的文字强调了一个核心黑话:"不改变其边缘分布集合"。
这是什么意思?我们盯着中间那张布满彩色线条的图看:
-
彩色锯齿线(SDE):一堆像素在往回走的时候,一边往中心靠拢,一边疯狂地上下乱抖。
-
白色光滑线(ODE):像素不发生任何多余的抖动,像水流一样极其顺滑、确定地流向终点。
"边缘分布不变"的意思是:虽然白色线不像彩色线那样乱抖,但在任何一个特定的时间点 t(在图上拉一条垂直的切线),无数条白色线在这一刻的分布密度(也就是那个青色的钟形曲线),和无数条彩色线在这一刻的分布密度一样。
这就产生了一个工程上的巨大神迹:我们用白色线(ODE)来生成图像,在每一秒钟所遇到的数据分布,和用彩色线(SDE)完全相同。它最终能在不引入任何随机抖动的情况下,同样100%平滑、稳定地走到终点,生成出质量完全一样的精美图像!
11.2 概率流 ODE 的四大工程优势
- 完全确定性生成(图像精准编辑与反转) :给定固定噪声起点,每次运行结果完全相同。可将真实图片通过前向 ODE 精准映射到唯一噪声坐标,再通过逆向 ODE 无损还原,实现完美可逆(用于图像编辑、换脸等)。
- 精确计算对数似然 :概率流 ODE 本质上是一个连续归一化流(CNF)/神经 ODE ,可通过瞬时变量代换公式 精确计算任意图片的绝对概率密度
- 极大提升采样速度:确定性轨迹极为平滑,可使用高阶 ODE 求解器(如 DPMSolver)采取大步长跨越。原本 SDE 需要 1000 步,ODE 求解器仅需 10~20 步即可生成高质量图像,实现秒级出图。
- 防止模式崩塌:负对数似然(NLL)提供了可量化监控训练质量的客观指标,且 KL 散度上界在数学上确保模型必须覆盖完整的数据分布。
实验结果(负对数似然,bits/dim ↓):
| 方法 | CIFAR-10 | ImageNet |
|---|---|---|
| RealNVP | 3.49 | --- |
| Glow | 3.35 | --- |
| Ours(概率流 ODE) | 2.99 | --- |
| Sparse Transformer(自回归) | 2.80 | --- |
| Image Transformer | 2.90 | 3.77 |
| Ours(似然权重训练) | 2.83 | 3.76 |
十二、应用:可控生成与逆问题求解
12.1 逆问题的数学本质
前向问题 :从清晰图像 x 出发,经已知的物理测量过程(如 MRI 欠采样、CT 稀疏角度)得到残缺观测图 y,由转移概率 描述。
逆问题 :已知残缺观测图 y,如何恢复高清图像 x,即求?
12.2 贝叶斯公式 + 得分函数(公式 15)
根据贝叶斯定理,我们有 。
对贝叶斯公式两边取对数并对 x 求梯度以极大地简化这一表达式,从而推导出以下针对得分函数的贝叶斯定理:
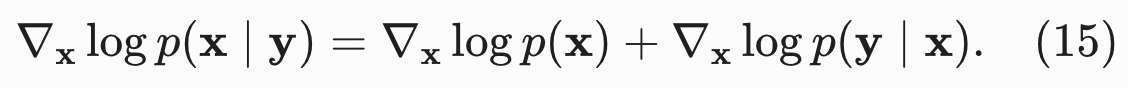
分母 与 y 无关,对
求梯度后直接消失------分母再次被求导消灭。
两项分工:
- 无条件数据得分
- 物理测量约束梯度
12.3 相比监督学习的优势
- 对仪器高度鲁棒:预训练的得分网络只学习"什么是正常器官",与具体仪器解耦。换了新机器型号,只需替换物理约束项,无需重新训练
- 防止幻觉:物理约束项实时监督 AI 的生成方向,一旦偏离真实测量数据,立刻产生惩罚力场纠正
十三、与扩散模型(DDPM)的历史合流
13.1 两大门派的独立发展
| 维度 | 得分匹配门派(宋飏等,2019) | 传统扩散模型门派(Jascha等,2015) |
|---|---|---|
| 思想源头 | Fisher Score + 朗之万动力学 | 热力学扩散 + 变分概率论 |
| 训练目标 | 最小化费舍尔散度(得分匹配) | 最大化证据下界(ELBO) |
| 生成方式 | 朗之万动力学步进 | 学习到的隐变量解码器 |
13.2 2020年:Jonathan Ho 的 DDPM 揭开统一面纱
Ho 等人(2020)发现,将扩散模型的 ELBO 公式层层数学化简后,其核心训练项在数学形式上与多尺度得分匹配损失函数的加权组合完全等价。
扩散模型解码器预测的"噪声向量 ",乘以系数后与得分模型输出的"得分向量
"等价:
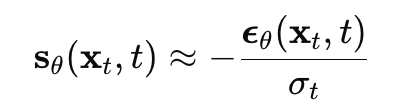
Ho 随后将扩散模型的解码器换成 U-Net 架构,同样生成出超高质量图片,击败 GAN。
13.3 宋飏的 SDE 框架:终极大一统(ICLR 2021)
宋飏等人进一步将噪声尺度推向无穷,证明:
得分匹配模型(NCSN)和扩散概率模型(DDPM),都是由得分函数决定的随机微分方程(SDE)的不同离散化形式。
这一发现同时打通了:
- 预测器-矫正器(PC)采样器:融合两派技术优势
- 概率流 ODE:实现确定性生成与精确似然计算
- 连续时间统一框架:覆盖所有噪声级别的训练与推理
13.4 类比:波粒二象性式的两种视角
正如量子力学中波动力学(薛定谔)与矩阵力学(海森堡)是等价的不同表述,得分视角与扩散视角也各自延伸出不同的技术触角:
- 得分视角:自然求解逆问题、精确计算似然、连接到能量模型(EBM)、薛定谔桥、最优传输理论
- 扩散视角:自然连接到 VAE、有损数据压缩、变分概率推断框架
十四、全链路逻辑总结
传统似然模型
└── 死磕绝对概率 → 遇到不可积分母 Z_θ → 走进死胡同 ❌
│
▼
朴素得分匹配(2019)
└── 求导消灭分母,改学"坡度趋势"(得分函数)
→ 仅在高密度数据区学得准
→ 在低密度噪声无人区严重摆烂 ❌
│
▼
多尺度噪声 + NCSN(2019)
└── 主动用多级高斯噪声灌满低密度区
→ 制造全空间引力指南针(隐形磁力线)
→ 条件网络(噪声级别作为输入)+ 退火朗之万采样
→ 在 CIFAR-10 上追平 GAN ✅
│
▼
连续时间 SDE 框架(ICLR 2021)
└── 噪声层数 L → ∞,阶梯 → 连续流动
→ SDE 大一统(NCSN ≡ DDPM 的不同离散化形式)
→ 预测器-矫正器采样器:PC 组合提升画质
→ 似然权重训练 + KL 散度上界理论保证 ✅
│
▼
概率流 ODE
└── 砍掉随机项(得分系数 × 1/2)
→ 完全确定性生成轨迹
→ 100% 可逆通道(图像反转与精准编辑)
→ 精确计算绝对概率(继承 CNF/Neural ODE 的似然计算能力)
→ ODE 快速求解器(10~20步出图)✅
│
▼
应用
├── 可控生成:贝叶斯公式 + 得分相加 → 求解 MRI/CT 逆问题
└── 数学大一统 → 现代扩散模型(Stable Diffusion / DDPM / Flux 等)的理论基石附录:核心数学概念速查
| 概念 | 简要定义 |
|---|---|
| 得分函数 |
|
| 费舍尔散度 | 两个得分函数(向量场)之间的 |
| 隐式得分匹配(ISM) | 利用分部积分将费舍尔散度转化为只含模型自身输出的可计算公式 |
| 雅可比矩阵的迹 | ISM 中 |
| 朗之万动力学 | 得分函数 + 随机噪声的迭代采样方法,收敛到目标分布 |
| 先验分布 |
前向加噪过程的终点分布,生成过程的起点,通常为标准高斯 |
| 漂移系数 |
SDE 中的确定性力场,控制数据的定向位移 |
| 扩散系数 g(t) | SDE 中噪声注入速度的放大系数, |
| 似然权重 |
训练时平衡不同噪声阶段损失量级,并建立 KL 散度不等式的权重设计 |
| 负对数似然(NLL) | 评估生成模型对真实数据分布估计准确性的量化指标,数值越低越好 |
| 概率流 ODE | 与逆向 SDE 共享相同边缘分布,但完全确定性的常微分方程,得分系数减半 |
| 瞬时变量代换公式 | 用于沿 ODE 轨迹精确追踪概率密度变化的数学工具,实现精确似然计算 |