锂电池制造的"不可能三角":如何用 PSO + SHAP 找到最优工艺窗口?
容量、内阻、缺陷率三者不可兼得------但我们可以找到全局最优的妥协方案。
本文提出一套完整的机器学习智能优化框架,从贝叶斯超参搜索到多目标 Pareto 前沿,再到 SHAP 可解释分析,手把手实现锂电池制造工艺的数据驱动优化。
一、背景:锂电池制造的"苦衷"
锂电池的性能------比容量、内阻、表面缺陷率------直接决定了终端产品的续航、安全性和良品率。而这些指标的命运,在电极制造阶段就已经被写定。
从浆料涂布到辊压成型,每一个工艺参数都在悄悄影响最终电池的表现:
- 涂布速度快了,产能提升,但涂层均匀性可能变差;
- 烘干温度高了,溶剂挥发充分,但可能导致粘结剂迁移和裂纹;
- 辊压压力大了,压实密度提高,容量上升,但内阻可能反弹,缺陷随之增多。
问题是:这些参数并不是独立作用的。它们之间存在复杂的非线性交互 ------你动了涂布速度,烘干温度的"最佳值"可能就变了。更棘手的是,容量、内阻、缺陷率三个目标经常相互冲突:追求极高容量,往往伴随内阻升高或缺陷率恶化。
传统的"试错法"和单目标优化已经无法应对这种多维博弈。我们需要一套系统性的方法:既能精确建模工艺参数与质量指标之间的复杂映射,又能在多目标冲突中找到全局最优的折中方案,还能解释清楚"为什么"------让工程师真正理解参数的影响机制,而不只是拿到一串数字。
这正是本文框架要做的事。
二、框架总览
这套框架由四个模块串联而成,形成一条完整的 "数据录入 → 模型构建 → 多目标寻优 → 可解释分析" 智能决策链路:
┌──────────────┐ ┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ │ │ │ │ │ │ │
│ 数据预处理 │───▶│ 多模型训练 │───▶│ PSO 多目标 │───▶│ SHAP 可解释 │
│ 与清洗 │ │ 与贝叶斯优化 │ │ 优化 │ │ 分析 │
│ │ │ │ │ │ │ │
└──────────────┘ └──────────────┘ └──────────────┘ └──────────────┘
EDA + 异常值 9模型 × 3目标 Pareto 前沿搜索 全局 + 局部
检测 + 特征筛选 Hyperopt TPE 折中最优解推荐 特征贡献归因第一步:加载数据,完成描述性统计、相关性分析和异常值清洗。
第二步:对随机森林、XGBoost、CatBoost 等 9 种回归模型,分别用贝叶斯优化(TPE 算法)搜索最优超参数,在三个质量目标上全面比拼,选出 CatBoost 作为基预测器。
第三步:以 CatBoost 为代理模型,运行多目标粒子群优化(MOPSO),在六维工艺参数空间中搜索 Pareto 最优解集,并基于加权归一化距离推荐折中最优解。
第四步:用 SHAP(Shapley Additive Explanations)方法对三个目标模型进行全局与局部的可解释分析,可视化每个工艺参数的贡献方向和依赖模式。
三、数据情况
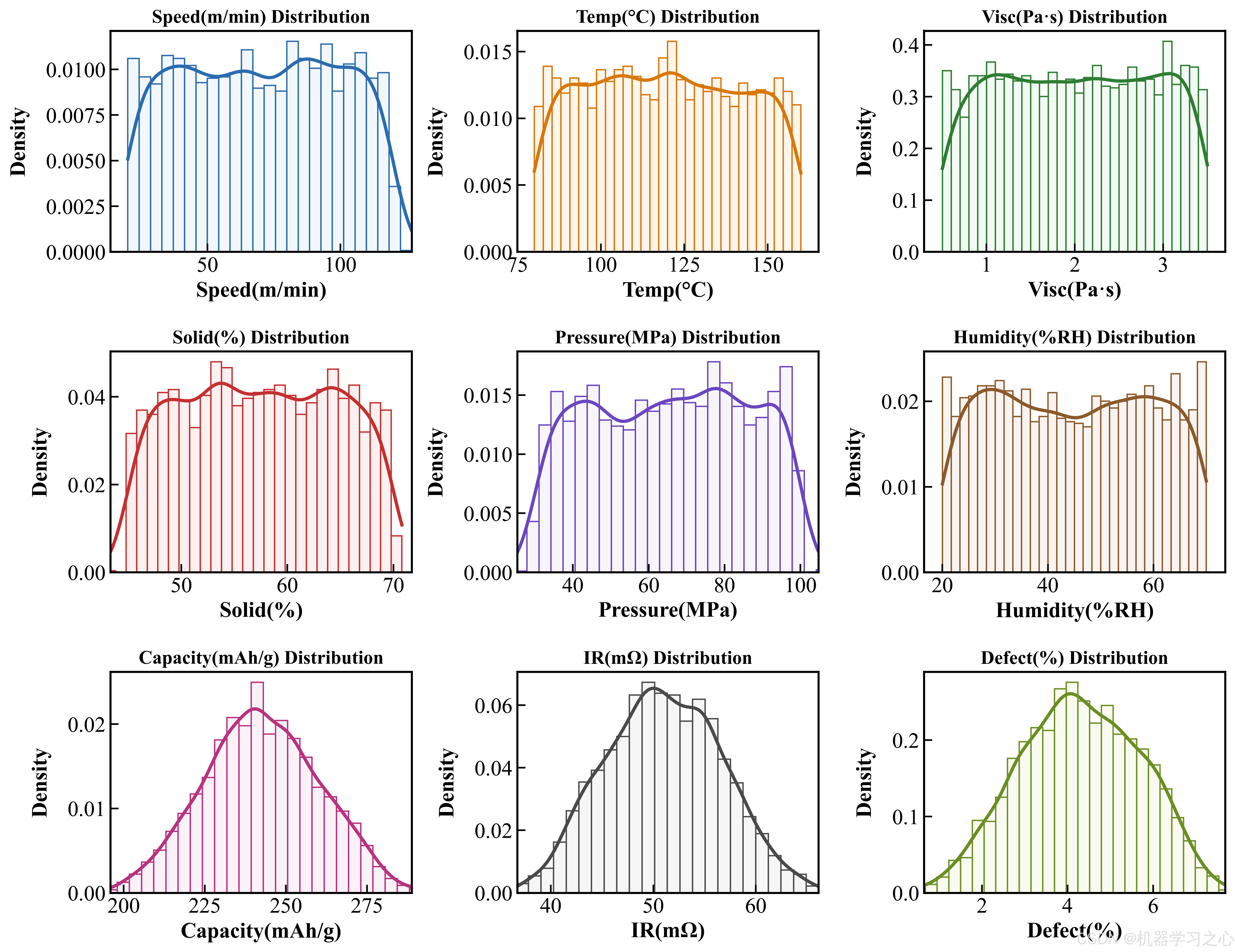
研究使用的数据集包含 3000 条工艺参数-质量指标配对样本,涵盖锂电池电极制造的核心变量:
输入特征(6个工艺参数):
| 特征 | 符号 | 单位 | 范围 |
|---|---|---|---|
| 涂布速度 | Speed | m/min | 20 ~ 148 |
| 烘干温度 | Temp | °C | 80 ~ 160 |
| 浆料黏度 | Visc | Pa·s | 0.5 ~ 3.5 |
| 固含量 | Solid | % | 40 ~ 71 |
| 辊压压力 | Pressure | MPa | 12 ~ 107 |
| 环境湿度 | Humidity | %RH | 20 ~ 70 |
输出目标(3个质量指标):
| 目标 | 符号 | 单位 | 均值 | 范围 |
|---|---|---|---|---|
| 比容量 | Capacity | mAh/g | 242.7 | 183 ~ 296 |
| 内阻 | IR | mΩ | 51.1 | 34 ~ 71 |
| 表面缺陷率 | Defect | % | 4.29 | 0.13 ~ 8.36 |
数据被按 8:2 比例划分为训练集(2400 条)和测试集(600 条)。随机种子固定为 42,确保结果可复现。
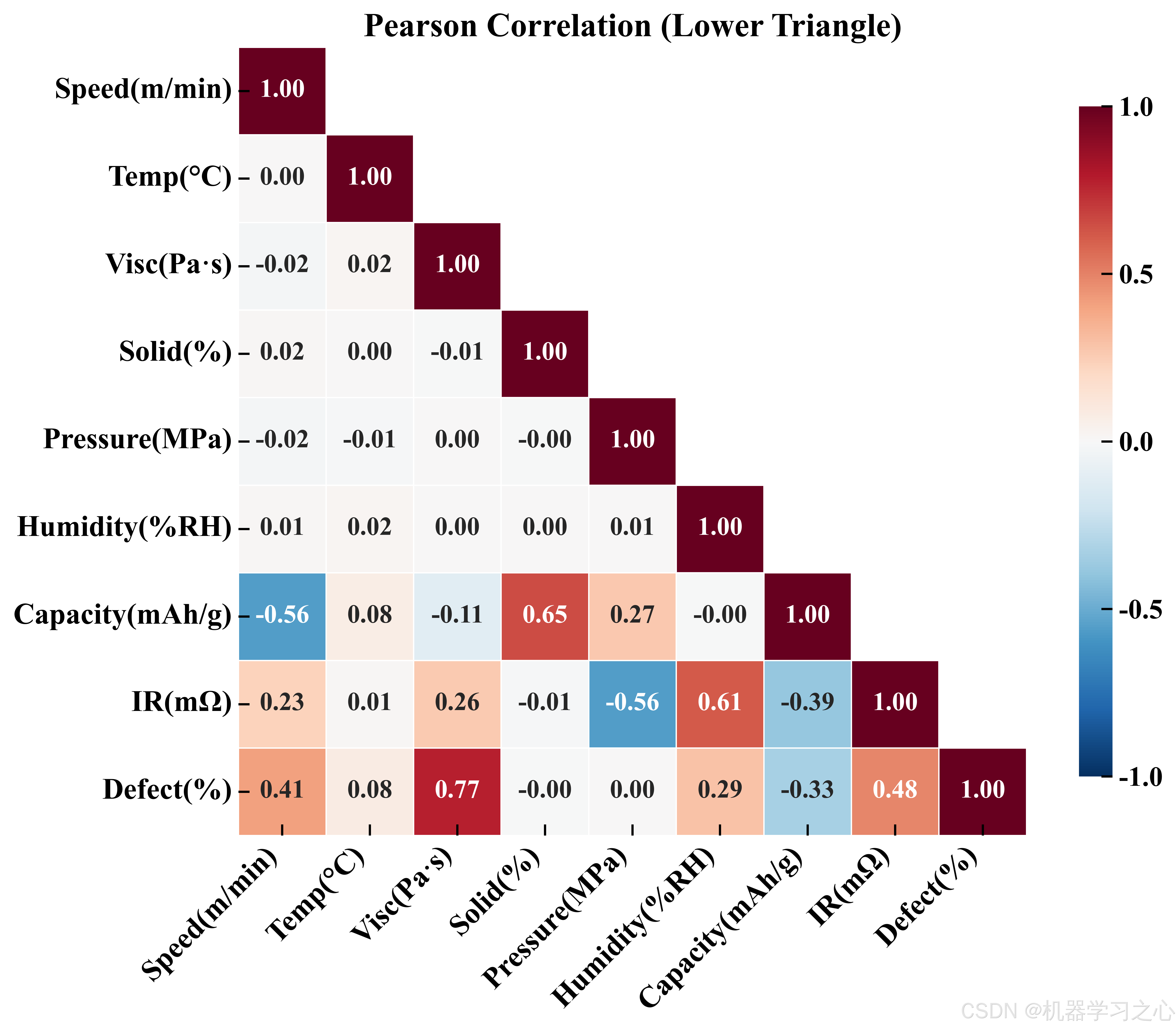
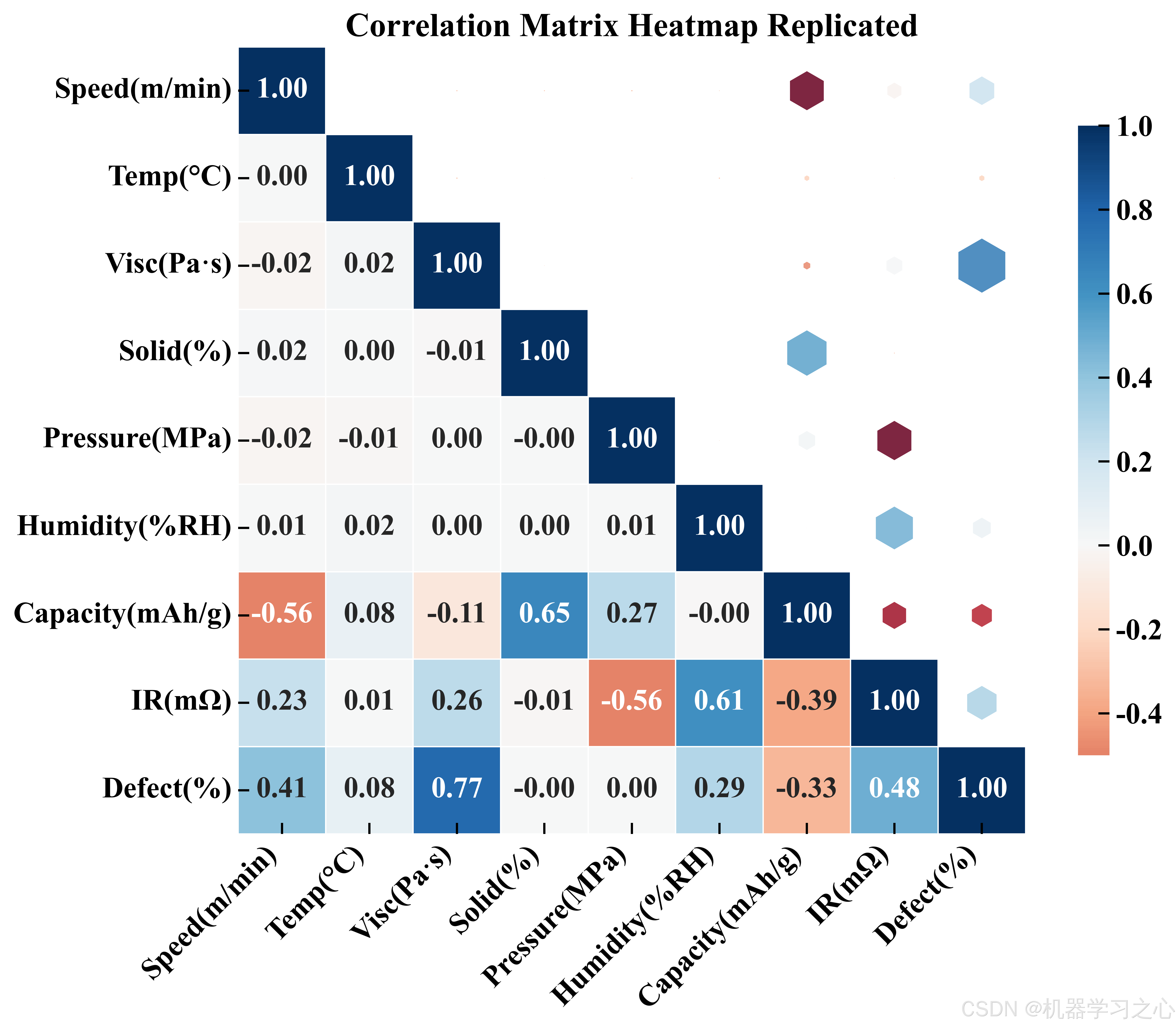
从 Pearson 相关系数热力图可以看出:固含量与容量呈显著正相关(r ≈ 0.58),辊压压力与内阻呈中等负相关,而湿度与缺陷率的关联最为紧密。值得注意的是,各工艺参数之间的共线性较弱 (绝大部分 |r| < 0.3),说明参数选择较为正交,有利于后续建模。
四、模型构建
4.1 为什么不让单一模型唱独角戏?
不同模型对数据的拟合偏好不同:树模型擅长捕捉非线性交互,SVR 对小样本更稳健,KNN 对局部结构敏感。在不确定"谁最好"的情况下,让所有选手同台竞技是最稳妥的策略。本框架召集了 9 位选手:
- 集成树模型:Random Forest、ExtraTrees、GBDT、AdaBoost、XGBoost、CatBoost
- 支持向量机:SVR(RBF 核)
- 线性模型:Ridge 回归
- 距离模型:KNN
4.2 超参数优化:从"手动调参"到"智能搜索"
传统超参数调试依赖经验或网格搜索,效率低下。本框架采用 Hyperopt 库的 TPE(Tree-structured Parzen Estimator)算法,以 3 折交叉验证的平均 R² 为优化目标:
L=−R2‾CV \mathcal{L} = -\overline{R^2}_{CV} L=−R2CV
即最小化负交叉验证 R²(等价于最大化 R²),每次评估(共 30 轮)自动在超参数空间中抽样、评估、更新概率模型,逐步收敛到最优区域。
以 CatBoost 为例,其搜索空间覆盖了迭代次数(700-2000)、树深度(3-8)、学习率(0.005-0.1)、正则化系数(L2、random_strength)、采样率(subsample、rsm)等 8 个关键参数。
4.3 评估体系:六大指标立体画像
仅看 R² 不足以反映模型的真实表现。每个模型在反归一化后,同步输出六个评估指标:
R2=1−∑(yi−y^i)2∑(yi−yˉ)2 R^2 = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2} R2=1−∑(yi−yˉ)2∑(yi−y^i)2
RMSE=1n∑(yi−y^i)2, \text{RMSE} = \sqrt{\frac{1}{n}\sum (y_i - \hat{y}_i)^2}, RMSE=n1∑(yi−y^i)2 ,
MAE=1n∑∣yi−y^i∣ \quad \text{MAE} = \frac{1}{n}\sum |y_i - \hat{y}_i| MAE=n1∑∣yi−y^i∣
MAPE=100%n∑∣yi−y^i∣yi∣+ε∣, \text{MAPE} = \frac{100\%}{n}\sum \left|\frac{y_i - \hat{y}_i}{|y_i| + \varepsilon}\right|, MAPE=n100%∑ ∣yi∣+εyi−y^i ,
MaxErr=max∣yi−y^i∣ \quad \text{MaxErr} = \max|y_i - \hat{y}_i| MaxErr=max∣yi−y^i∣
EV=1−Var(y−y^)Var(y) \text{EV} = 1 - \frac{\text{Var}(y - \hat{y})}{\text{Var}(y)} EV=1−Var(y)Var(y−y^)
所有指标在测试集上计算,并通过多模型雷达图可视化排名全貌。
4.4 赛果揭晓
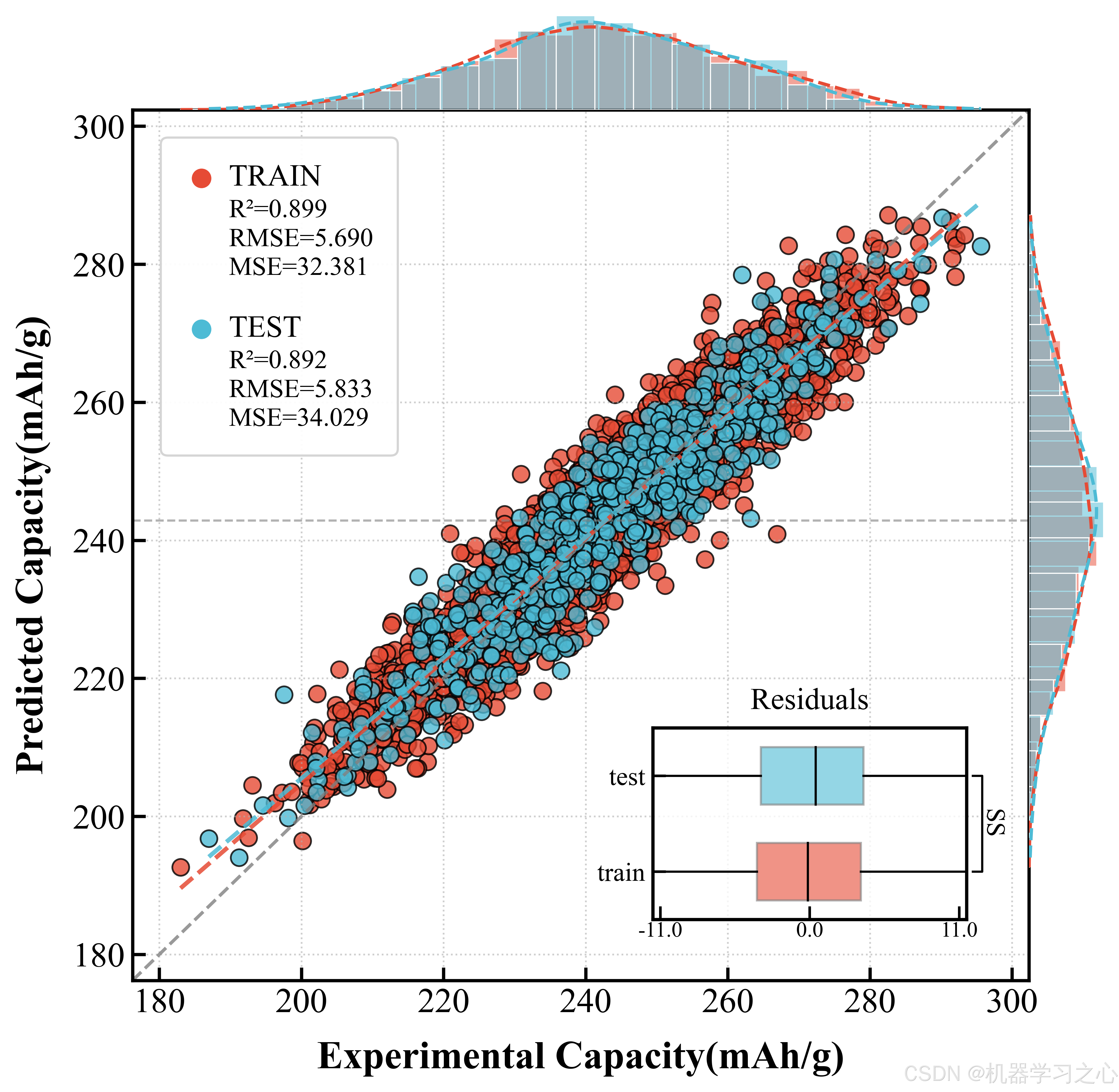
经过 27 组贝叶斯优化(9 模型 × 3 目标),CatBoost 在三个目标上全部夺冠------且优势在各项指标上具有一致性。最终测试集表现:
| 目标 | 最优模型 | Test R² | Test RMSE | Test MAE |
|---|---|---|---|---|
| Capacity | CatBoost | 0.8917 | 0.0529 | 0.0420 |
| IR | CatBoost | 0.9142 | 0.0453 | 0.0356 |
| Defect | CatBoost | 0.8910 | 0.0612 | 0.0479 |
三个目标的 R² 均超过 0.89,内阻预测的 R² 更是达到 0.914。这说明 CatBoost 成功捕获了工艺参数到质量指标之间的复杂映射关系------无论是主效应还是交互效应。
五、MOPSO多目标优化
5.1 问题的数学定义
以 CatBoost 三个子模型构成代理预测函数:
y^cap=fcap(x)\hat{y}{cap} = f{cap}(\mathbf{x})y^cap=fcap(x)
y^ir=fir(x)\quad \hat{y}{ir} = f{ir}(\mathbf{x})y^ir=fir(x)
y^def=fdef(x)\quad \hat{y}{def} = f{def}(\mathbf{x})y^def=fdef(x)
其中 x=x1,x2,...,x6\mathbf{x} = x_1, x_2, \\dots, x_6x=x1,x2,...,x6 为六维工艺参数向量,受限于各参数的物理范围 x∈lb,ub\mathbf{x} \in \\mathbf{lb}, \\mathbf{ub}x∈lb,ub。
容量是"越大越好",内阻和缺陷率是"越小越好"。统一为最小化问题:
minxF(x)=−fcap(x), fir(x), fdef(x) \min_{\mathbf{x}} \quad \mathbf{F}(\mathbf{x}) = \left -f_{cap}(\\mathbf{x}),\\; f_{ir}(\\mathbf{x}),\\; f_{def}(\\mathbf{x}) \\right xminF(x)=−fcap(x),fir(x),fdef(x)
5.2 MOPSO 算法原理
多目标粒子群优化(MOPSO)是本框架的寻优核心。它模拟鸟群觅食行为,在搜索空间中部署一群"粒子",每个粒子代表一组候选工艺参数:
速度更新:
Vit+1=w⋅Vit+c1r1(pbesti−Xit)+\mathbf{V}_i^{t+1} = w \cdot \mathbf{V}_i^t +c_1 r_1 (\mathbf{pbest}_i - \mathbf{X}_i^t) +Vit+1=w⋅Vit+c1r1(pbesti−Xit)+
c2r2(gbest−Xit)c_2 r_2 (\mathbf{gbest} - \mathbf{X}_i^t)c2r2(gbest−Xit)
位置更新:
Xit+1=Xit+Vit+1 \mathbf{X}_i^{t+1} = \mathbf{X}_i^t + \mathbf{V}_i^{t+1} Xit+1=Xit+Vit+1
| 参数 | 含义 | 设定值 |
|---|---|---|
| www | 惯性权重 | 0.65 |
| c1c_1c1 | 个体认知系数 | 1.6 |
| c2c_2c2 | 社会认知系数 | 1.6 |
| r1,r2r_1, r_2r1,r2 | 随机因子 | ~ U(0,1) |
区别于单目标 PSO,多目标版本的全局引导 gbest\mathbf{gbest}gbest 从外部 Pareto 档案中按拥挤距离加权概率随机选取------拥挤距离越大的解被选中的概率越高,鼓励粒子向探索不足的区域移动。
5.3 Pareto 支配与拥挤距离
在多目标优化中,一个解支配另一个解的判定标准是:在所有目标上不差,且至少在一个目标上严格更优(最小化意义下):
$
\prec B \iff \forall k: f_k(A) \leq f_k(B) ;$∧ ∃j:fj(A)<fj(B)\land\; \exists j: f_j(A) < f_j(B)∧∃j:fj(A)<fj(B)
非支配解构成 Pareto 最优前沿。拥挤距离度量前沿上各解的分布密度:
cdi=∑k=1mfk(i+1)−fk(i−1)fkmax−fkmin cd_i = \sum_{k=1}^{m} \frac{f_k(i+1) - f_k(i-1)}{f_k^{\max} - f_k^{\min}} cdi=k=1∑mfkmax−fkminfk(i+1)−fk(i−1)
边界点拥挤距离设为 +∞+\infty+∞。当档案容量超过上限(300),按拥挤距离升序裁剪------优先删掉最"拥挤"的解,保持前沿的均匀覆盖。
5.4 折中最优解的选取策略
Pareto 前沿给出的是"没有免费午餐"的最优解集------不同解在三个目标上各有取舍。为给决策者一个明确的推荐方案,本框架采用加权归一化距离方法:
score=wcap⋅(1−cap−capmincapmax−capmin)+\text{score} = w_{cap} \cdot \left(1 - \frac{cap -cap_{\min}}{cap_{\max} -cap_{\min}}\right) +score=wcap⋅(1−capmax−capmincap−capmin)+ wir⋅ir−irminirmax−irmin+w_{ir} \cdot \frac{ir - ir_{\min}}{ir_{\max} - ir_{\min}} +wir⋅irmax−irminir−irmin+ wdef⋅def−defmindefmax−defminw_{def} \cdot \frac{def - def_{\min}}{def_{\max} - def_{\min}}wdef⋅defmax−defmindef−defmin
其中 wcap=0.5w_{cap} = 0.5wcap=0.5,wir=0.25w_{ir} = 0.25wir=0.25,wdef=0.25w_{def} = 0.25wdef=0.25------容量权重更高,因为比容量直接决定能量密度,是锂电池最核心的竞争力指标。
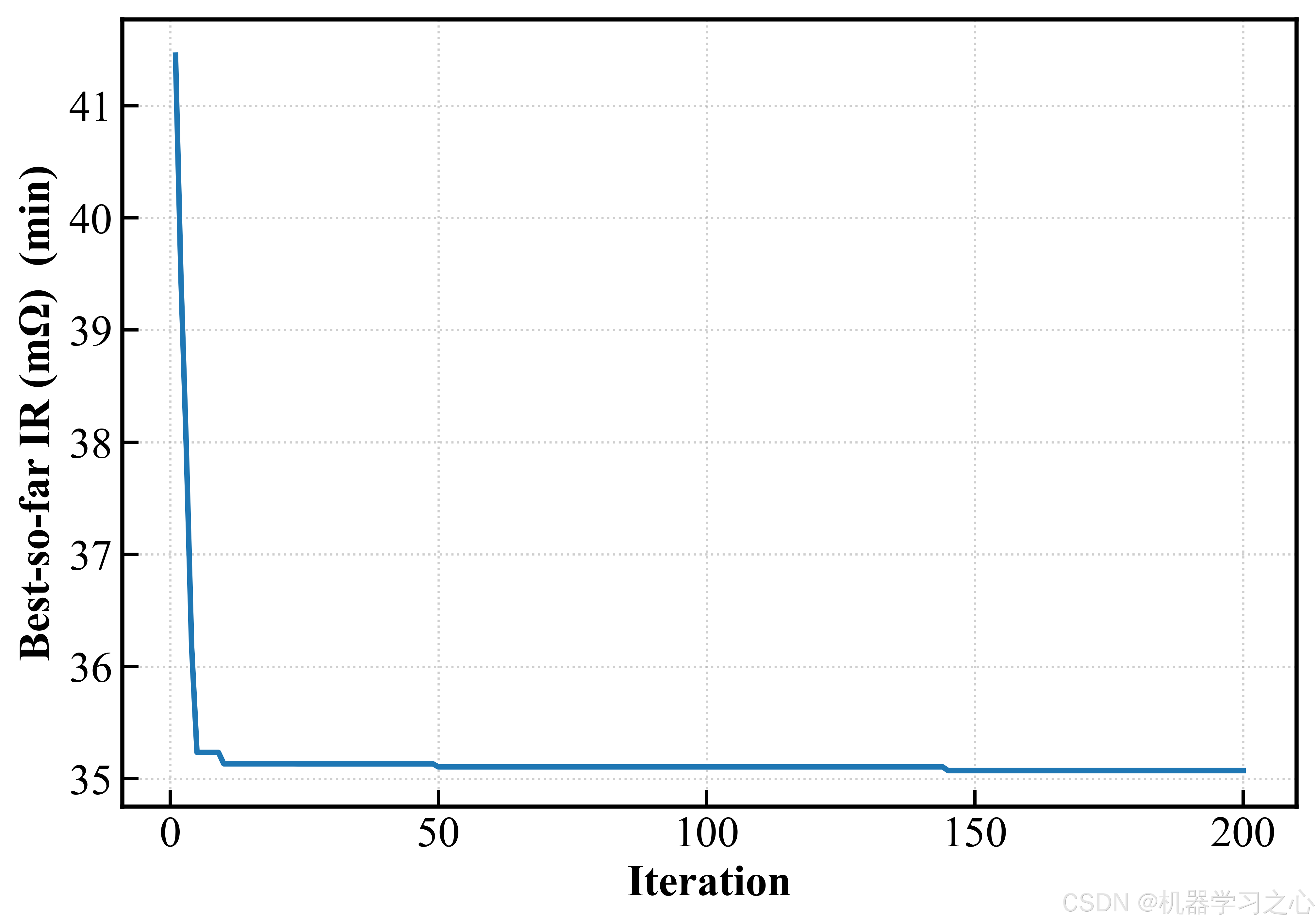
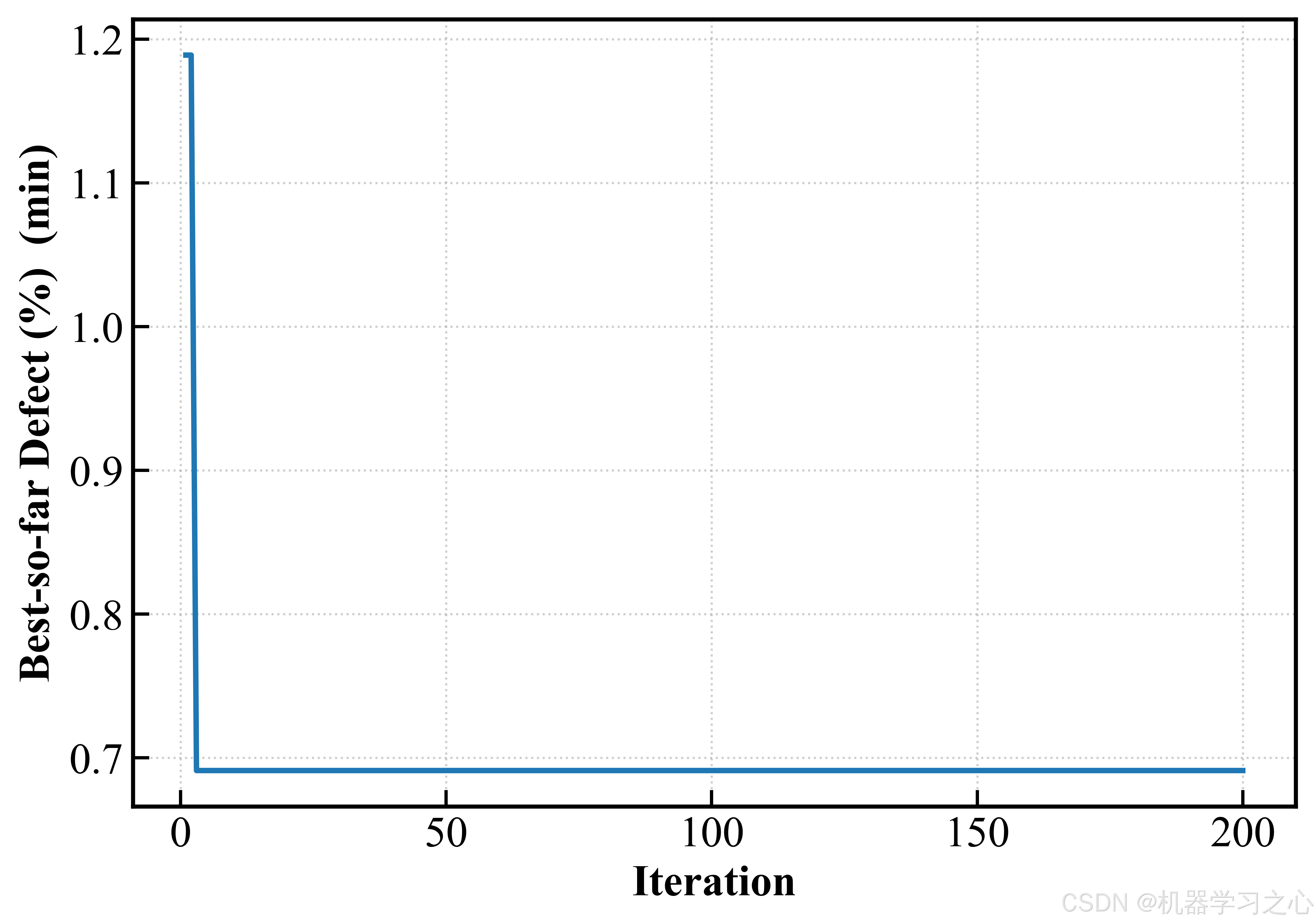
5.5 优化结果
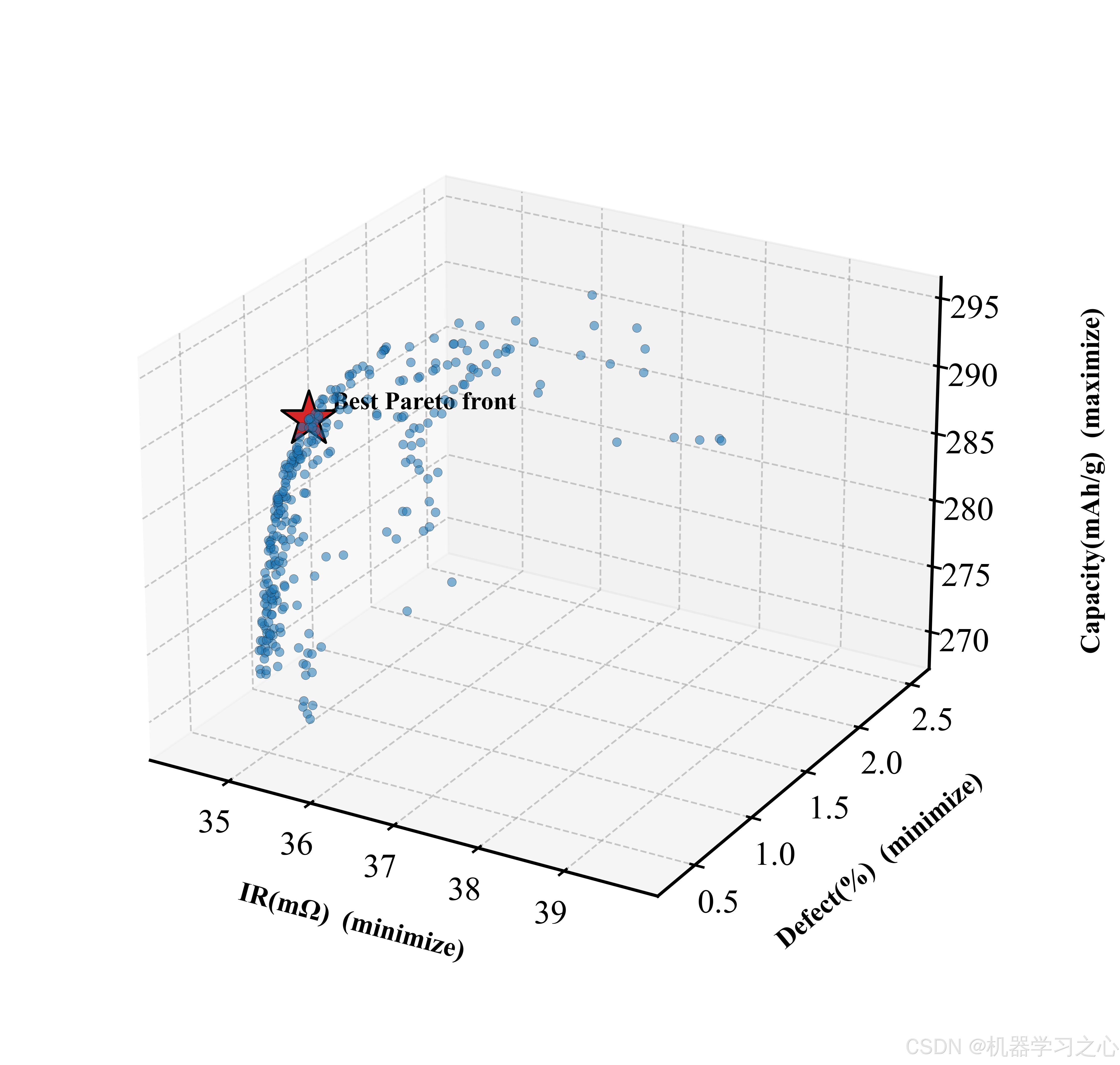
100 粒子 × 200 轮迭代后,外部档案收敛到 300 个 Pareto 非支配解。关键结果如下:
| 解类型 | Speed | Temp | Visc | Solid | Pressure | Humidity | Capacity | IR | Defect |
|---|---|---|---|---|---|---|---|---|---|
| 容量最大 | 20.0 | 127.2 | 1.24 | 70.7 | 94.1 | 23.6 | 292.85 | 37.68 | 1.832 |
| 内阻最小 | 20.0 | 119.5 | 0.92 | 59.5 | 107.4 | 20.0 | 274.98 | 34.71 | 0.936 |
| 缺陷最小 | 31.0 | 107.2 | 0.52 | 59.9 | 107.4 | 20.0 | 270.83 | 35.58 | 0.464 |
| 折中最优 | 20.0 | 119.1 | 0.50 | 70.8 | 104.7 | 20.0 | 290.13 | 35.12 | 0.795 |
一个令人印象深刻的发现:折中最优解的容量(290.13 mAh/g)仅比极端最大化容量(292.85)低约 1% ,但缺陷率从 1.83% 骤降至 0.80% ------降幅超过 56%。换句话说,牺牲不到 1% 的容量,就能换来缺陷率砍半------这在工业生产中意味着良品率的大幅提升和可观的成本节约。
从二维 Pareto 前沿图中可以清晰看到三个目标两两之间的"此消彼长"关系:Capacity-IR 前沿呈典型的凸曲线,Capacity-Defect 的权衡尤为明显------想同时获得高容量和低缺陷,窗口非常狭窄。
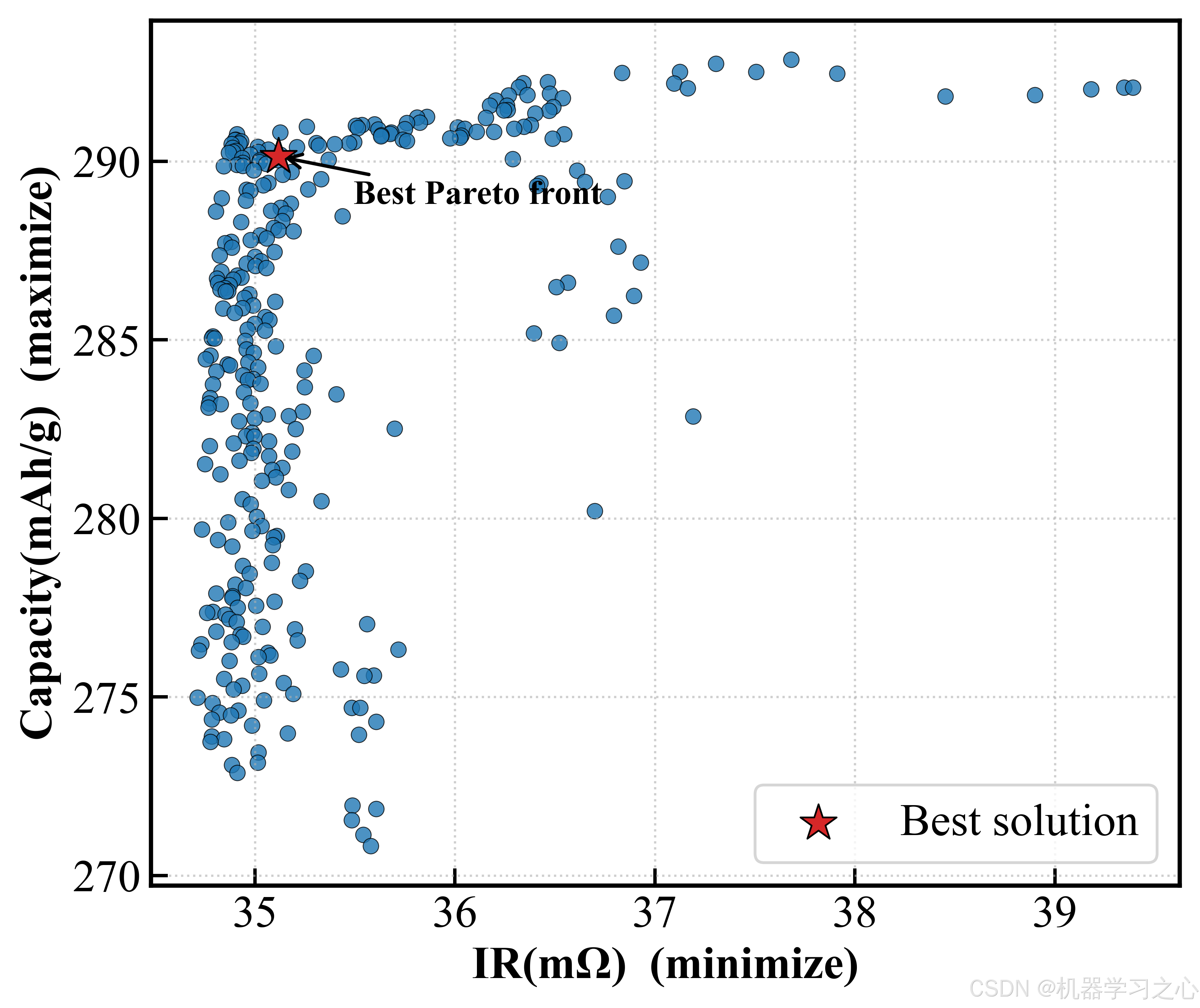
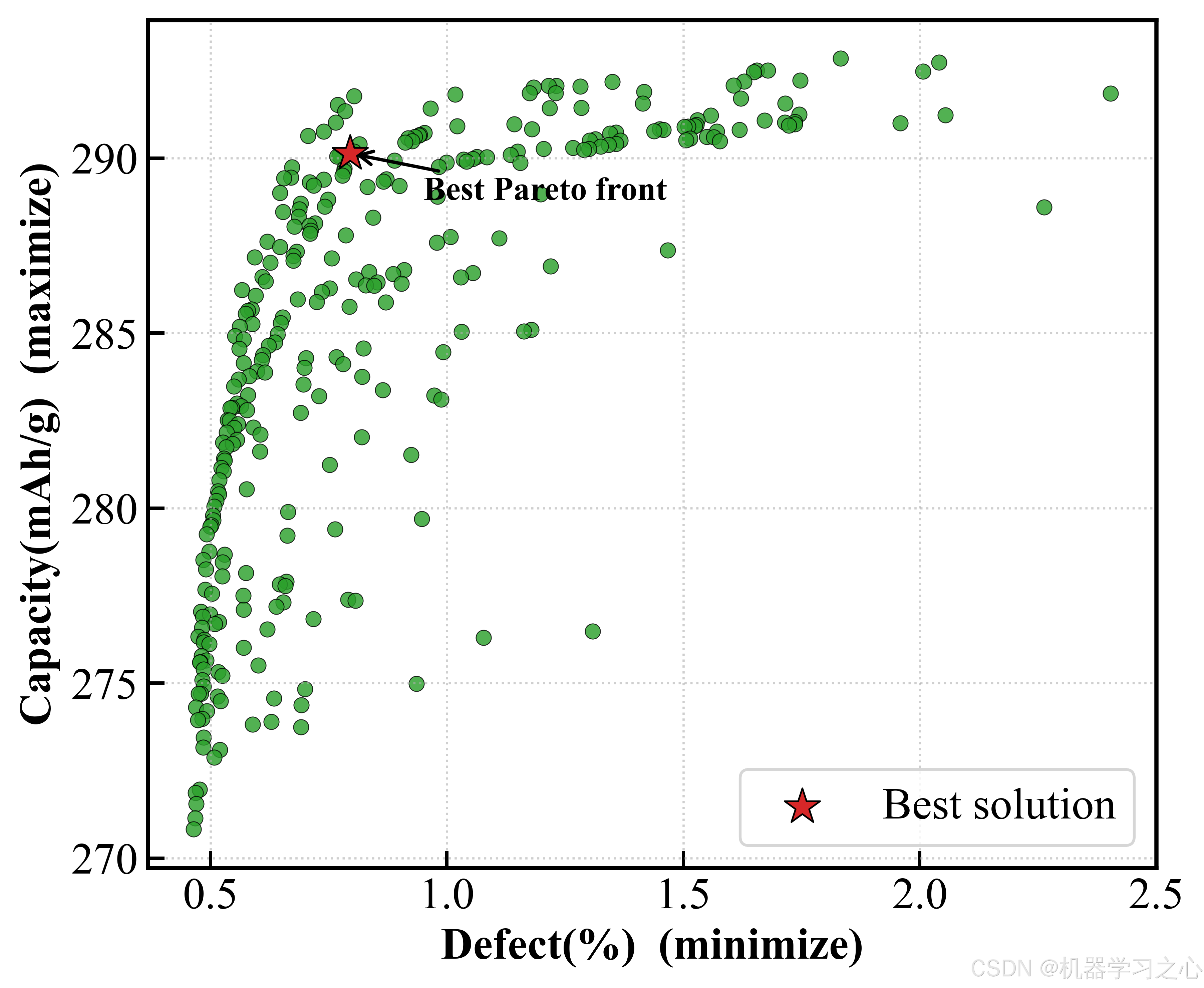
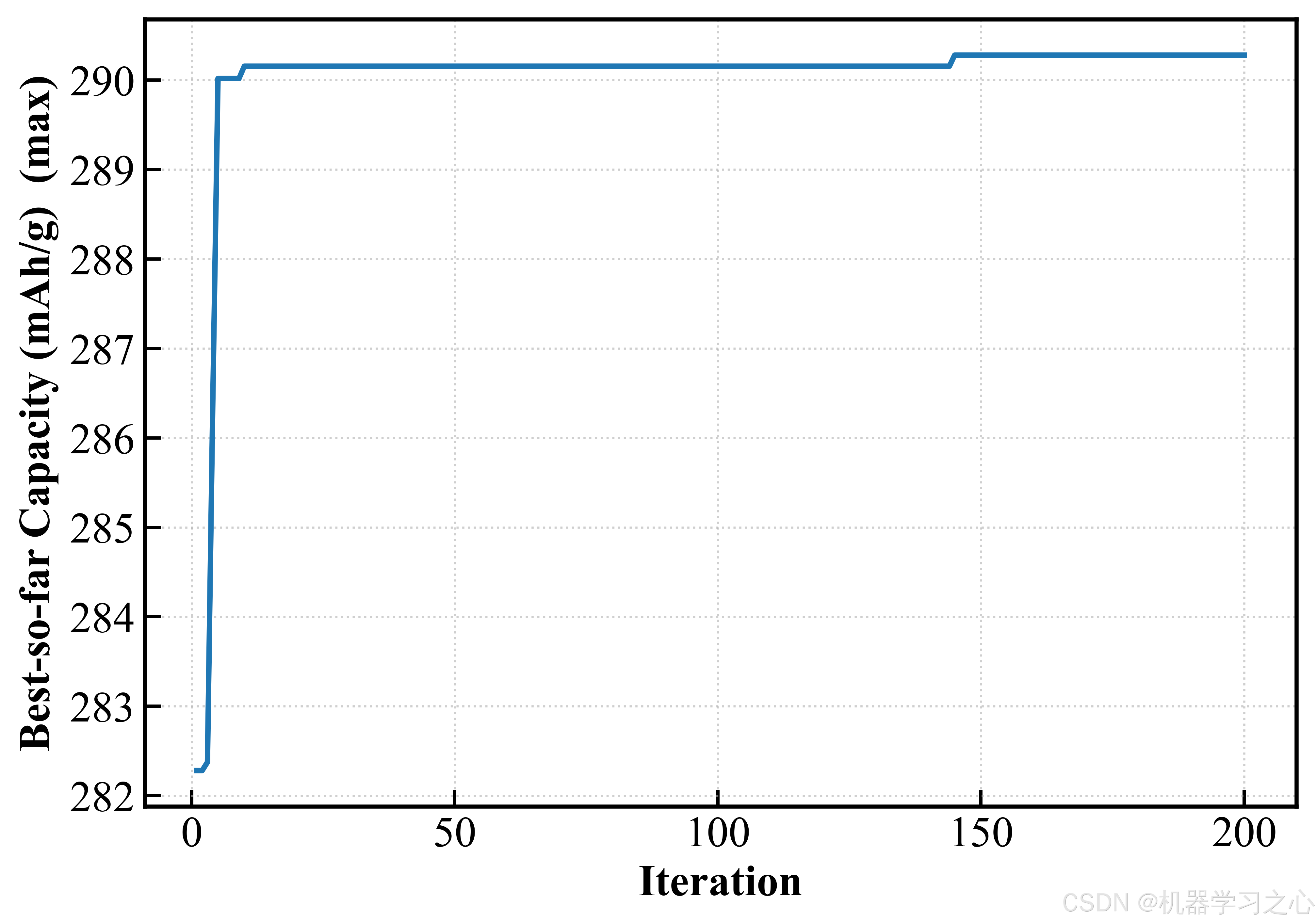
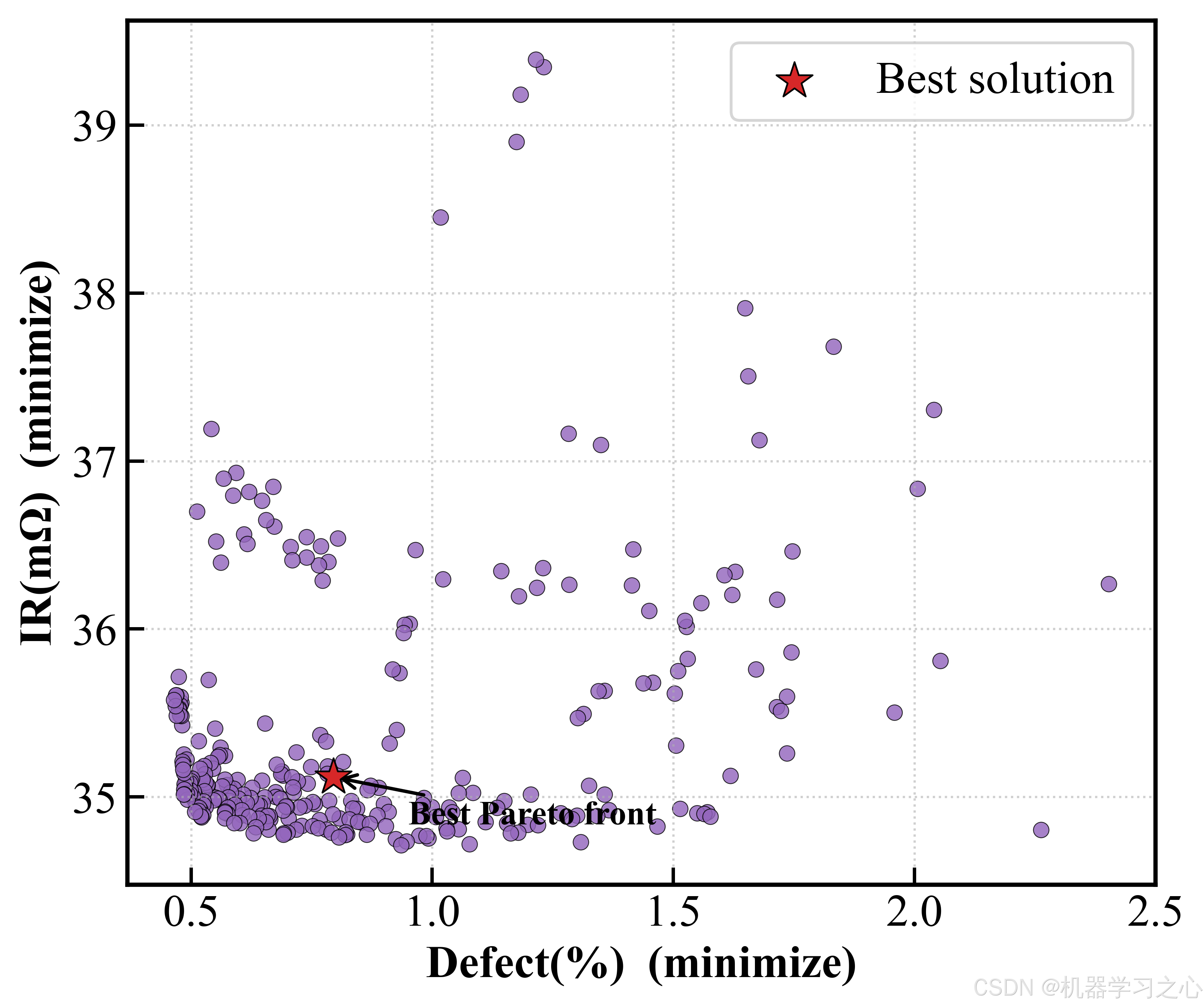
六、SHAP 可解释分析
6.1 为什么需要 SHAP?
CatBoost 虽然预测精度极高,但作为集成树模型,其内部决策逻辑对工程师而言仍是一个"黑箱"。知道"什么参数组合最优"固然重要,但理解"每个参数如何 影响质量、何时 影响最大、影响方向是否单调"才是工艺优化的底层认知。
SHAP(SHapley Additive exPlanations)基于博弈论中的 Shapley 值,将模型对单个样本的预测值分解为各特征的边际贡献之和:
f(x)=ϕ0+∑i=1Dϕi f(x) = \phi_0 + \sum_{i=1}^{D} \phi_i f(x)=ϕ0+i=1∑Dϕi
其中 ϕ0\phi_0ϕ0 为基线值(所有样本预测均值),ϕi\phi_iϕi 为特征 iii 的 SHAP 值------正值表示该特征推高了预测值,负值表示推低了预测值。
6.2 全局可解释
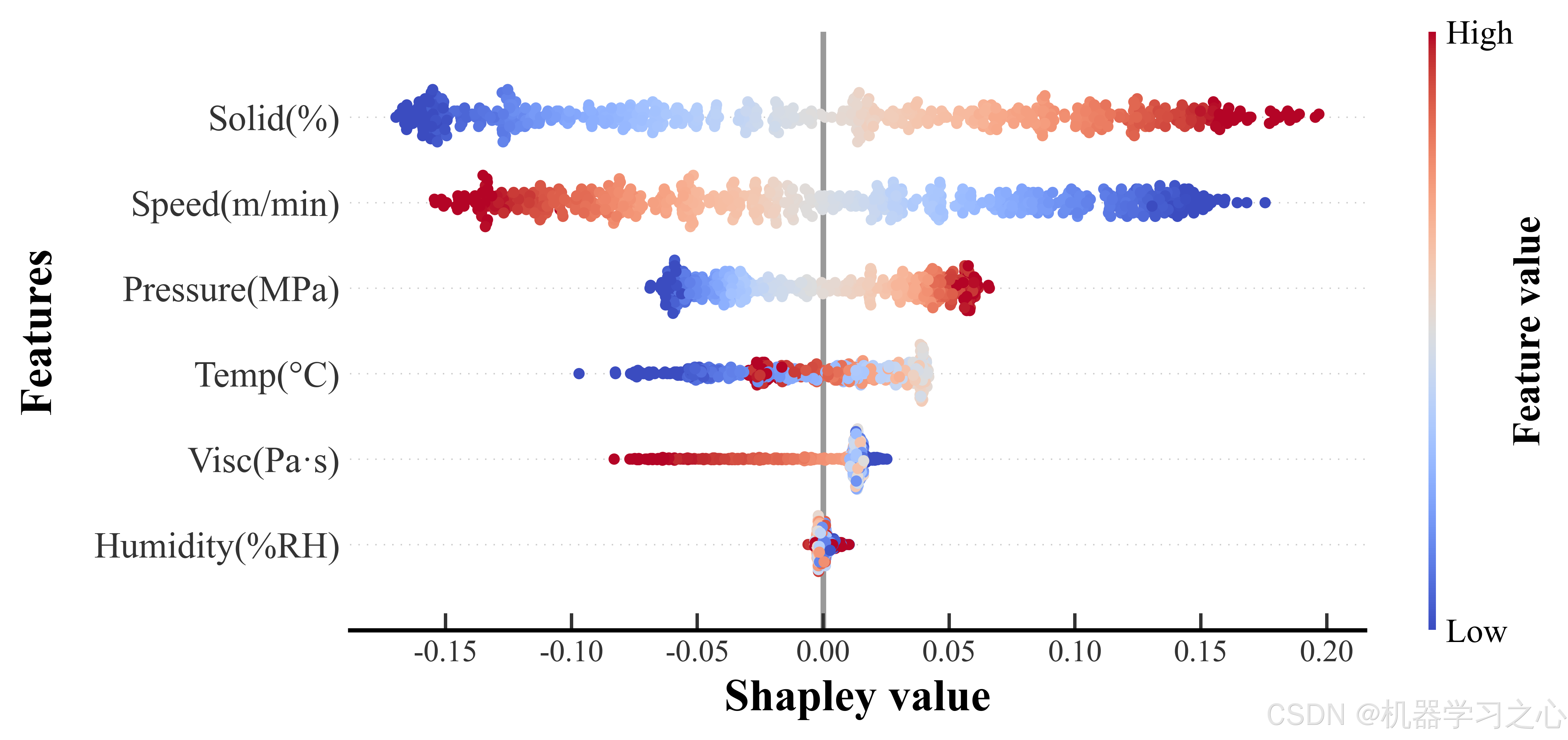
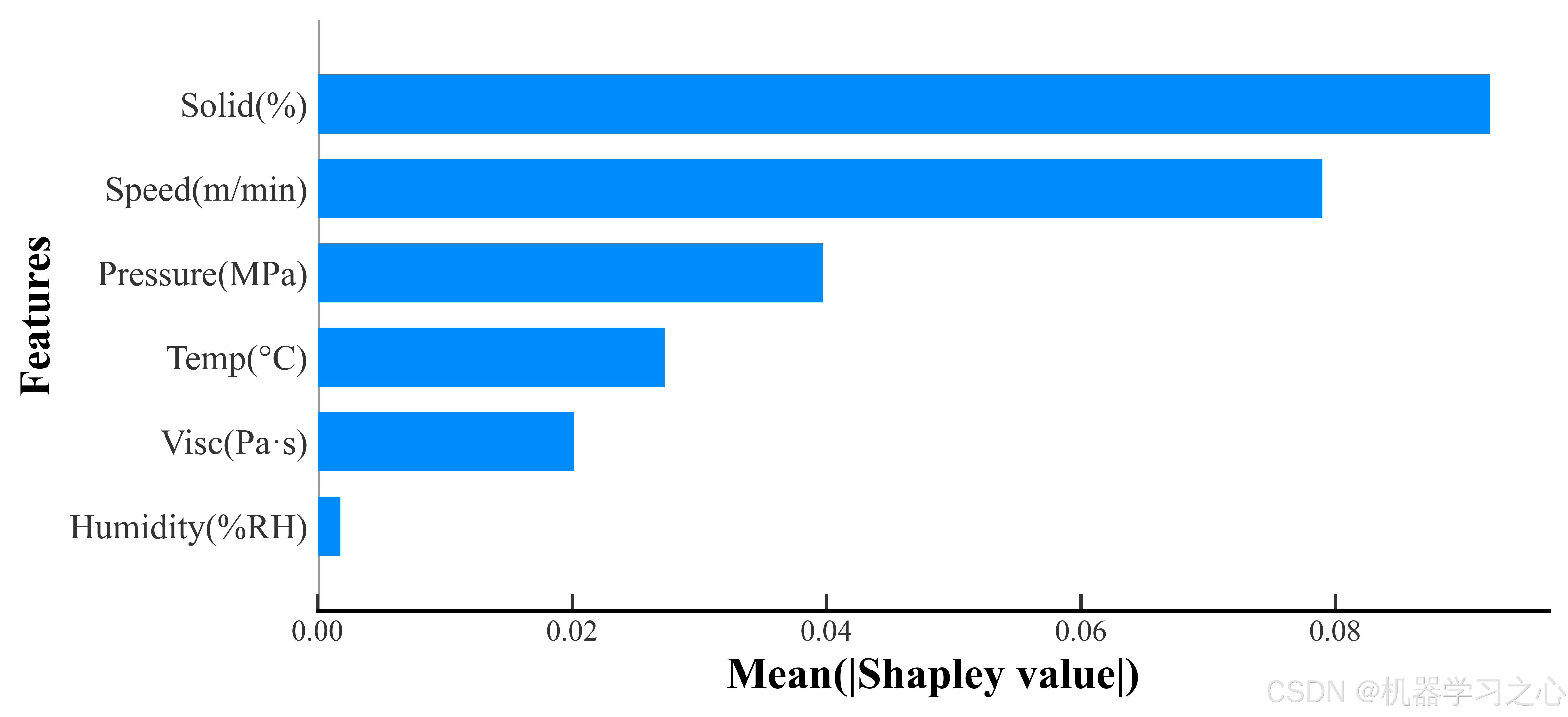
对于三个质量目标,全局 beeswarm 图揭示了关键工艺参数及其影响模式:
Capacity 预测的关键驱动因素:
- 固含量(Solid%)和辊压压力(Pressure)是最强特征------固含量越高,容量越高(正向贡献);压力在中等范围的正向贡献最显著
- 涂布速度对容量的贡献方向并非单调------低速时 SHAP 值为正,高速时反转为负,说明存在最佳速度窗口
IR 预测的关键驱动因素:
- 辊压压力是内阻预测的最强信号------压力越大,内阻越低(负向贡献),符合压实减少孔隙率的物理直觉
- 烘干温度和固含量的 SHAP 分布存在明显的"双峰",暗示不同工艺区间的影响机制可能不同
Defect 预测的关键驱动因素:
- 环境湿度是缺陷率的首要影响因素------高湿度几乎一致地推高缺陷率,呈强烈的正向单调性
- 烘干温度对缺陷率的影响呈现 U 型:过低(干燥不完全)和过高(热应力导致裂纹)都会增加缺陷
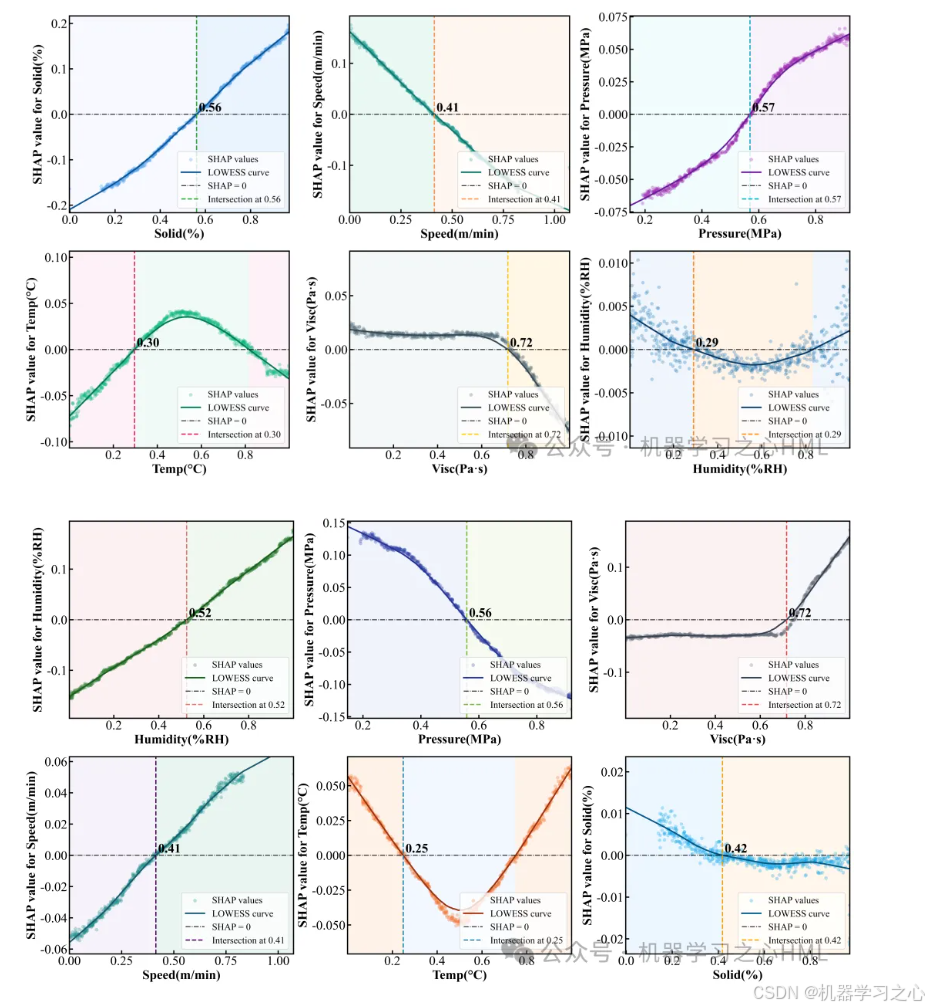
6.3 特征依赖图:非线性关系的可视化
特征依赖图进一步展露了参数-质量关系的细粒度模式。以固含量对容量的依赖为例:LOWESS 平滑曲线(frac=0.4)显示,固含量低于 55% 时 SHAP 贡献接近零甚至为负;一旦超过 55%,贡献迅速上升并保持正向------这是一个明显的阈值效应 ,提醒工程师在调参时需要确保固含量越过这个临界点。
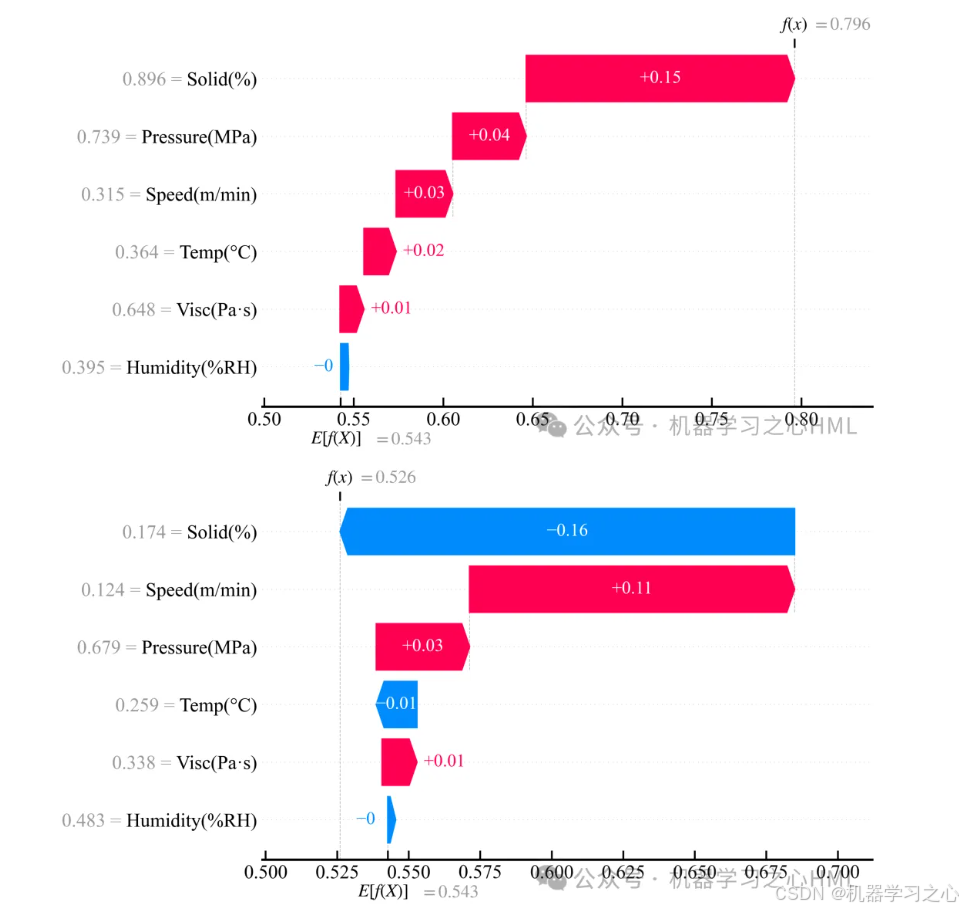
6.4 局部可解释:具体到每一个样本
对于任意一个测试样本,SHAP 的 waterfall 瀑布图和 force 力图可以逐特征展示该样本的预测是如何"拼凑"出来的。例如,第 100 号样本的容量预测基线约为 242.7,固含量高贡献了约 +15 的增量,环境湿度略高贡献了约 -3 的减量......最终得到该样本的预测值。这种"逐条拆账"的可解释性让工程师能够追溯任何异常预测的根源。
七、技术路线
将上述模块串联起来,整套框架的技术路线如下:
输入:sim_battery_process_3000.csv (3000行 × 9列)
│
├─[步骤1] 数据探索与预处理
│ ├─ 核密度分布图、Pearson相关系数热力图(含显著性标注)
│ ├─ ECDF/CCDF + Q-Q + Boxenplot 异常值检测
│ └─ Tukey 1.5×IQR 异常值剔除
│
├─[步骤2] 多模型训练与贝叶斯优化
│ ├─ MinMaxScaler 归一化至 [0,1]
│ ├─ 9模型 × 3目标 × 30轮 TPE 贝叶斯搜索
│ ├─ 3折交叉验证 R² 最大化
│ ├─ 反归一化后六指标评估
│ └─ 雷达图多模型排名 → 选出 CatBoost
│
├─[步骤3] MOPSO 多目标优化
│ ├─ CatBoost 三目标代理预测器
│ ├─ 100粒子 × 200迭代,Pareto支配排序
│ ├─ 拥挤距离档案裁剪(max_size=300)
│ ├─ 加权归一化折中最优解推荐
│ └─ 二维/三维 Pareto 前沿 + 收敛曲线可视化
│
└─[步骤4] SHAP 可解释分析
├─ TreeExplainer + kmeans(50) 背景
├─ 全局:beeswarm + 特征重要性排序
├─ 特征依赖图:LOWESS 平滑 + 正负贡献着色
└─ 局部:waterfall + force plot(每目标4个样本)
输出:Pareto 工艺参数推荐 + SHAP 解释报告 + 全套可视化八、运行环境
8.1 Python 环境
| 类别 | 核心库 |
|---|---|
| 科学计算 | numpy, pandas, scipy |
| 可视化 | matplotlib, seaborn, statsmodels |
| 机器学习 | scikit-learn(ensemble/svm/neighbors/linear_model) |
| 树模型 | xgboost, catboost |
| 超参优化 | hyperopt(TPE 算法) |
| 可解释性 | shap(TreeExplainer) |
备注:代码中还导入了 PyTorch 和 TensorFlow/Keras 作为备选深度学习框架,但本框架实际运行中未使用神经网络模型------CatBoost 已足够胜任。
8.2 关键参数
| 参数 | 设定值 | 说明 |
|---|---|---|
| train/test split | 8:2 | random_state=42 |
| 标准化方法 | MinMaxScaler(0,1) | X 和 y 独立 fit |
| 贝叶斯优化 max_evals | 30 | 每模型-目标组合 |
| 交叉验证折数 | 3 | KFold |
| PSO 粒子数 | 100 | --- |
| PSO 迭代次数 | 200 | --- |
| 惯性权重 w | 0.65 | --- |
| 加速系数 c1/c2 | 1.6/1.6 | --- |
| 速度上限系数 | 0.25 | vmax = 0.25×(ub-lb) |
| Archive 上限 | 300 | --- |
| 折中最优权重 | 0.50/0.25/0.25 | cap/ir/def |
| SHAP 背景样本数 | 50 | kmeans 聚类 |
| LOWESS 平滑 frac | 0.4 | --- |
| SHAP 局部分析样本 | 第1,100,200,300 | 1-based 索引 |
九、应用场景
这套"机器学习代理建模 + 多目标粒子群优化 + SHAP 可解释分析"的技术框架具有极强的通用性,核心思路可迁移至以下场景:
流程工业参数优化: 化工反应条件调优、钢铁轧制工艺优化、水泥烧成参数寻优------任何通过多个物理/化学参数控制多个质量指标的连续制造过程都可以直接套用。
配方设计: 合金成分设计、药物辅料比例优化、食品配方调配------输入是各组分的配比(约束为百分比之和),输出是多个性能指标,天然适合多目标优化。
供应链参数调优: 库存水位、配送频率、安全库存等决策变量同时影响成本、服务水平、碳排放,Pareto 前沿帮助管理者直观看到权衡。
环境工程: 废水处理药剂投加量优化(去除率 vs 成本 vs 污泥产量)、建筑能耗参数组合优化(舒适度 vs 能耗 vs 初投资)。
框架的关键优势在于:
- 不依赖物理模型------纯数据驱动,有历史数据就能跑;
- 可解释------SHAP 让黑箱模型透明化,符合工业应用的审慎要求;
- 端到端------从原始数据到最优工艺参数推荐,一条流水线输出完整分析报告。
十、写在最后
在"工业 4.0"和"智能制造"的叙事中,数据驱动的工艺优化是落地最扎实、回报最直接的方向之一。本文提出的框架的价值不在于某个单一算法的创新------PSO、CatBoost、SHAP 各自都是成熟的工具------而在于将它们以合理的逻辑串联成一个端到端的智能决策系统。
从数据清洗到模型选型,从多目标寻优到可解释归因,每一步都有明确的输入、输出和质量检验标准。我们希望这套框架不仅适用于锂电池制造,更能为更广泛的工业场景提供一个可复用的"配方"。
毕竟,好的工具应该让工程师把时间花在理解工艺本质上,而不是花在调参和猜谜上。
本文代码基于 Python 生态构建,完整 Notebook 及输出结果已开源。数据为模拟数据集,用于方法验证和框架演示。实测场景中请替换为实际生产数据即可复用整套流程。