一句话介绍
多轮工具调用 agent 的训练数据成本昂贵,传统方案难以合成高质量的可用数据。RODS 利用 GRPO 训练时的奖励信号挑选种子样本,搭建模拟环境构造高质量合成数据,只用 400 条种子样本就达到了 17K 的离线大规模合成数据水平
- 论文标题:RODS --- Reward-Driven Online Data Synthesis for Multi-Turn Tool-Use Agents
- 论文地址 :https://arxiv.org/pdf/2606.19047
- 作者背景:蚂蚁集团、浙江大学、上海创智学院、西湖大学
- 开源仓库 :https://github.com/inclusionAI/AWorld-RL/tree/main/RODS
- 模型权重 :https://huggingface.co/RuishanFang/Qwen3-4B-RODS
一、动机
市面上 LLM agent 产品不少,但大多是把重心 harness 设计上,真正走到 agentic RL 来解决业务问题的并不多,主要原因还是训练的难度与成本较高,多轮、有跨步依赖、还得带真实工具响应的轨迹数据,人工构造的成本高昂,公开的基准数据也不多;合成数据也不容易 ------ 多轮数据是带有跨步状态依赖的执行轨迹,前后依赖关系很强,传统数据增强方案可能难以扩充出可用的数据集
"订机票" 和 "订火车票" 字面上像孪生任务,但后者没有选座、查会员里程等环节,改签退票政策也完全不同,想基于已有数据(订机票)来合成新数据(订火车票)很可能得到 "看起来合理、实际全错" 的假数据,模型学这种东西只能记下表层句式特点,学不会真正的工具协作
更关键地,就算得到了一份可用的数据集也不是万事大吉。模型能力随训练在动,今天还踮脚才会的题,过两天可能就掌握了,但训练池里的数据还是那一批,导致大量样本要么太简单要么太难,对每次更新的梯度贡献几乎为零,相关研究称之为 "梯度饥饿"

二、解决方案
RODS 的核心思路是,利用 RL 时的奖励信号来指导数据合成,在不使用外部评估器的前提下构造最适合模型当前学习状态的新数据
2.1 边界检测
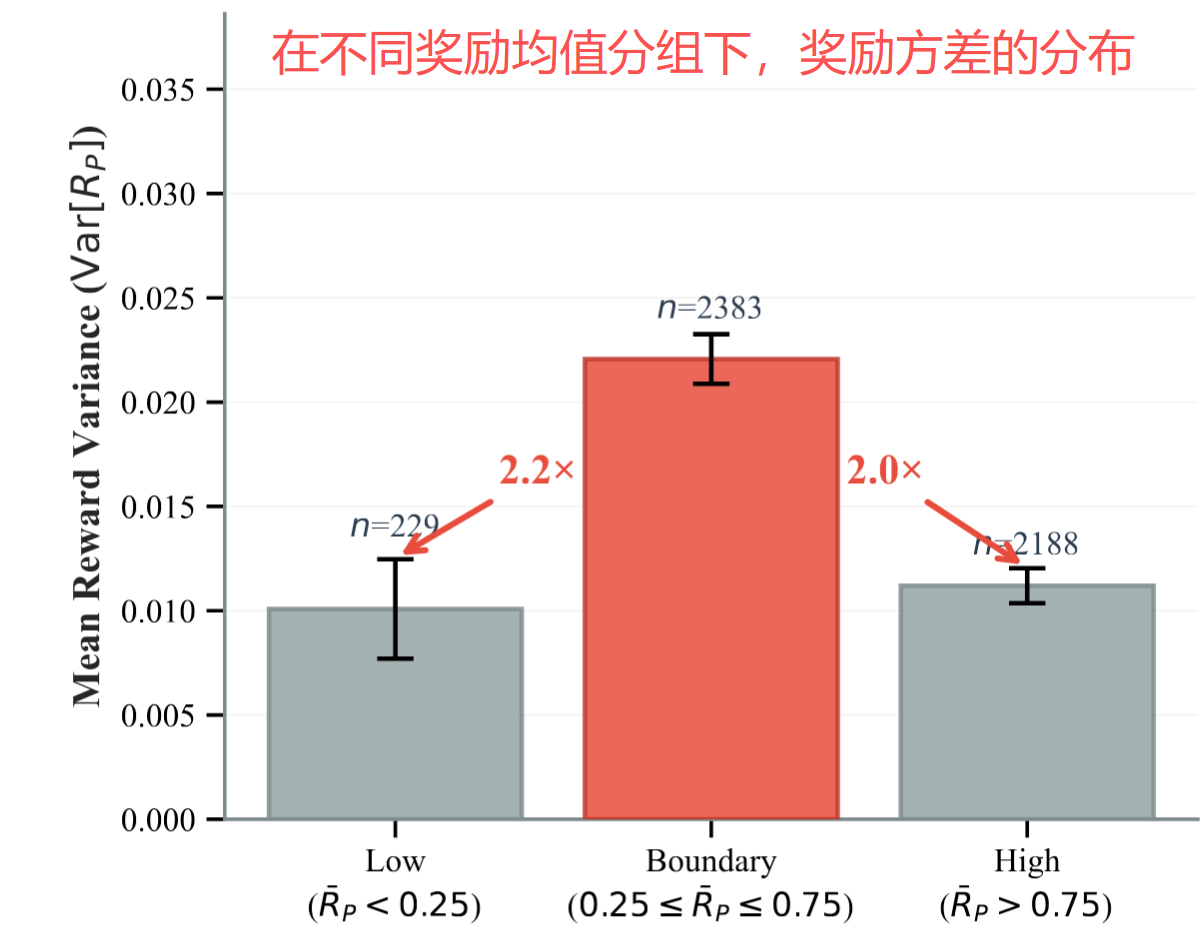
GRPO 训练时会对每个问题采样多条轨迹,然后用组内 reward 算 advantage。理论和实践经验都证明,reward 均值靠近 0.5 时,组内样本的奖励方差更大,即模型对一道题刚好对一半、错一半,这道题代表模型 "踮着脚勉强够到" 的能力边界
所以 RODS 重点关注平均 reward 处于中间位置(0.25~0.75)的样本,训练的每一步中,系统把这些样本按奖励方差排序,依次送进数据合成引擎,生成结构类似的新变体
2.2 同构数据合成
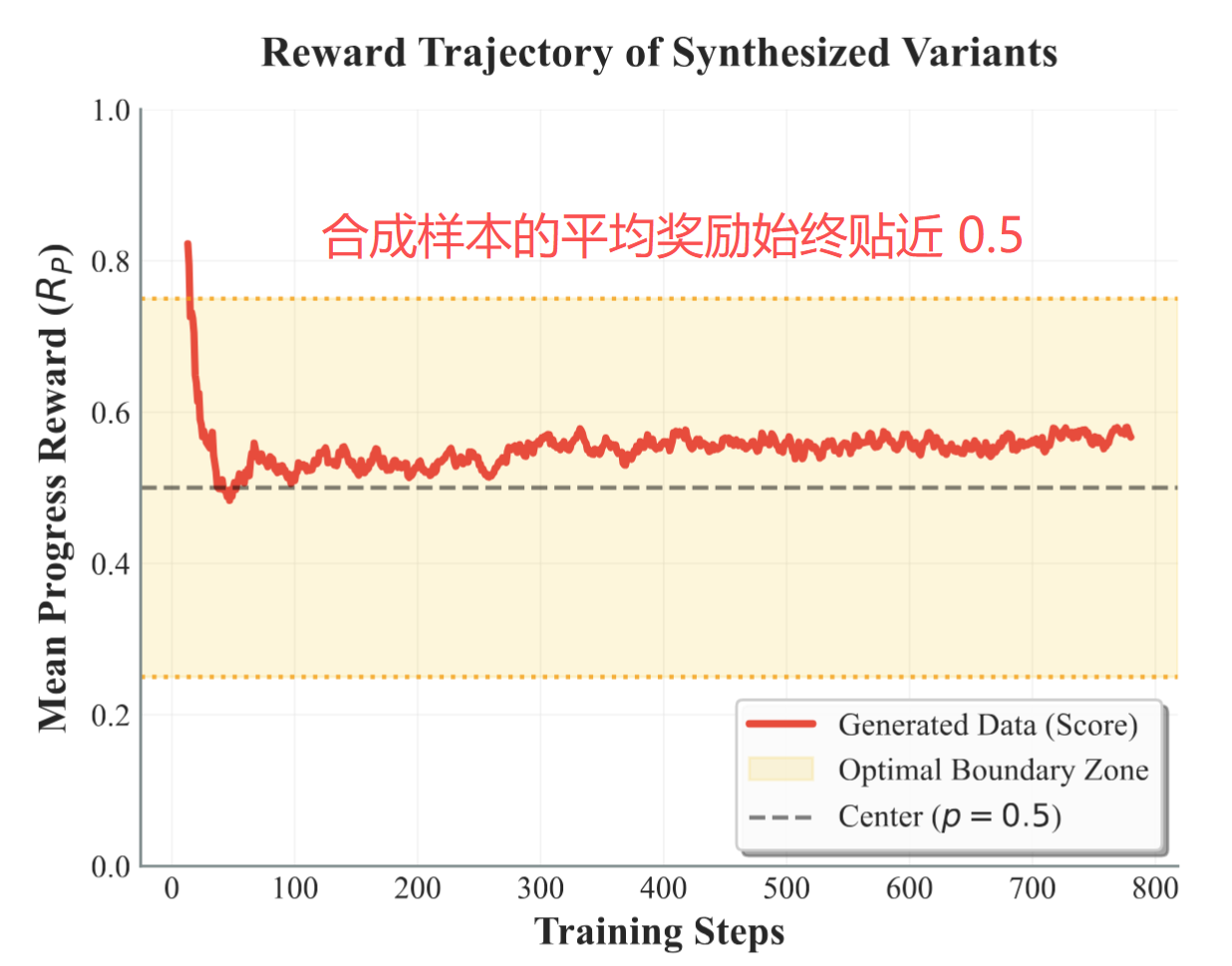
正如前文所述,数据合成在多轮场景之所以难做,是因为轨迹数据存在严格的跨轮依赖。RODS 提出 skill-aligned resampling 方法避免依赖结构被打破:只保留种子样本的 API 调用图和依赖深度,表层故事、参数、环境全部重新生成:
-
规划: Planner Agent 根据种子的 API 拓扑和依赖深度,规划一条新的接口调用序列,并同步给出一条潜在的故事线,比如 "用户在策划一次商务出差"。这条故事线之后会作为整段对话的语义锚点
-
模拟落地: Executor 把这条新序列在模拟环境里跑一遍,确保所有跨轮依赖都跑通;如果不通,最多重试 3 次纠错。跑通之后,Query Agent 再把每一轮 API 调用翻译成对应的自然语言用户问句
-
故事化重写: Rewrite Agent 拿第一步那条故事线,把整段对话一次性整体重写,让所有轮的问句都锚定同一个目标,最后 Critique Agent 打分把关,质量不过的回退给 Rewrite 重写
2.3 动态回放缓冲
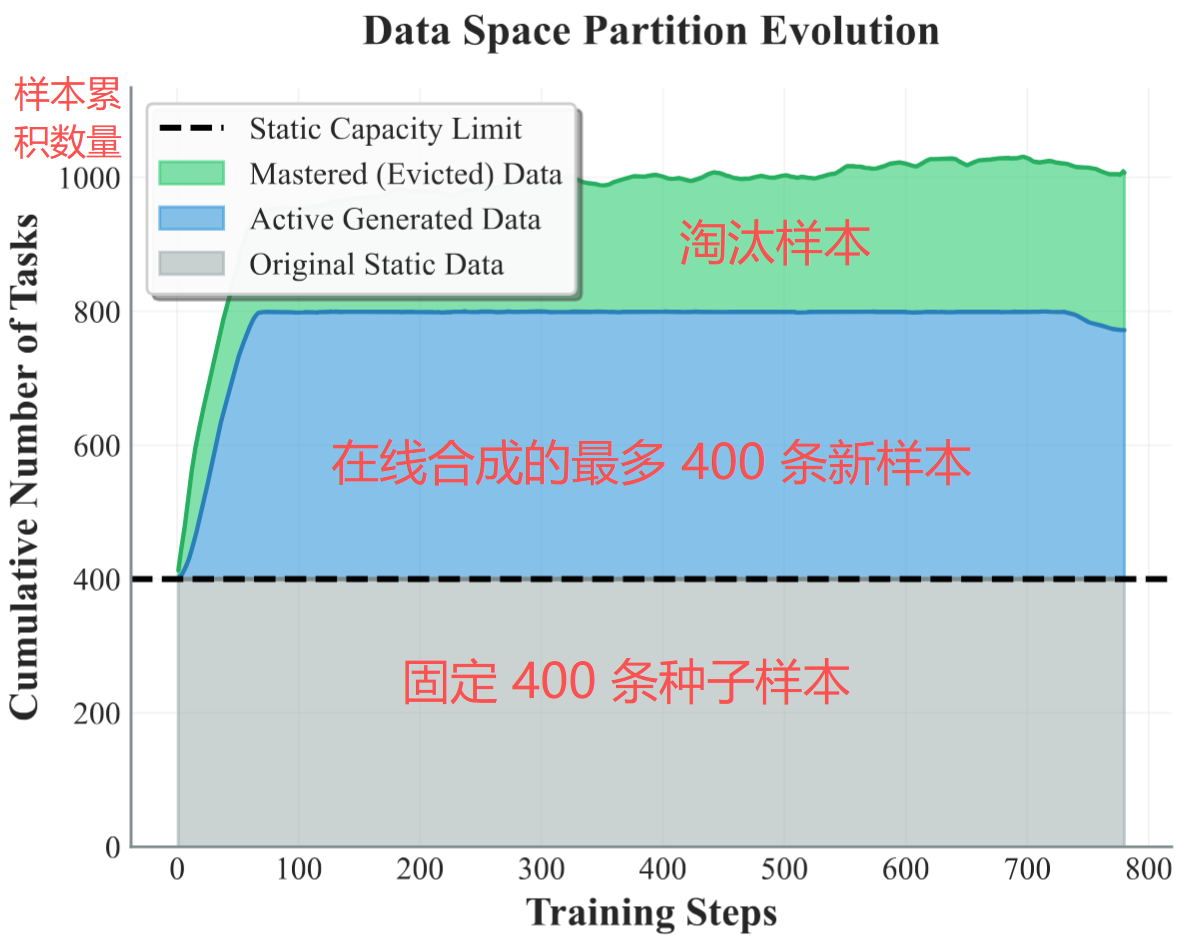
合成出来的新样本,并不立刻塞进训练,而是先进入一个候选队列,在 epoch 边界统一注入,且单次注入量不超过现有池子的 20%,避免数据分布震荡
RODS 还通过以下机制确保池子中有足够多的边界样本:
- 试用期过滤:新变体注入后先观察,一上来 reward 就过低、连边都摸不到的,直接剪掉
- 边界漂移淘汰:观察若干次后,如果 reward 漂到 "已掌握" 或 "彻底做不出",说明已经偏离边界,剔除相关样本
- 方差剪枝:变体数一旦触到上限(400条),就按 reward 方差从低到高退役(方差越低意味着梯度信号越弱)
此外,长期没被采到的变体也会被清掉,防止堆积陈旧样本。至此,任意时刻的活跃训练池就稳定在 800 条上下(400种子+400变体),被掌握的样本会及时淘汰,池子始终维持在边界浓度最高的状态
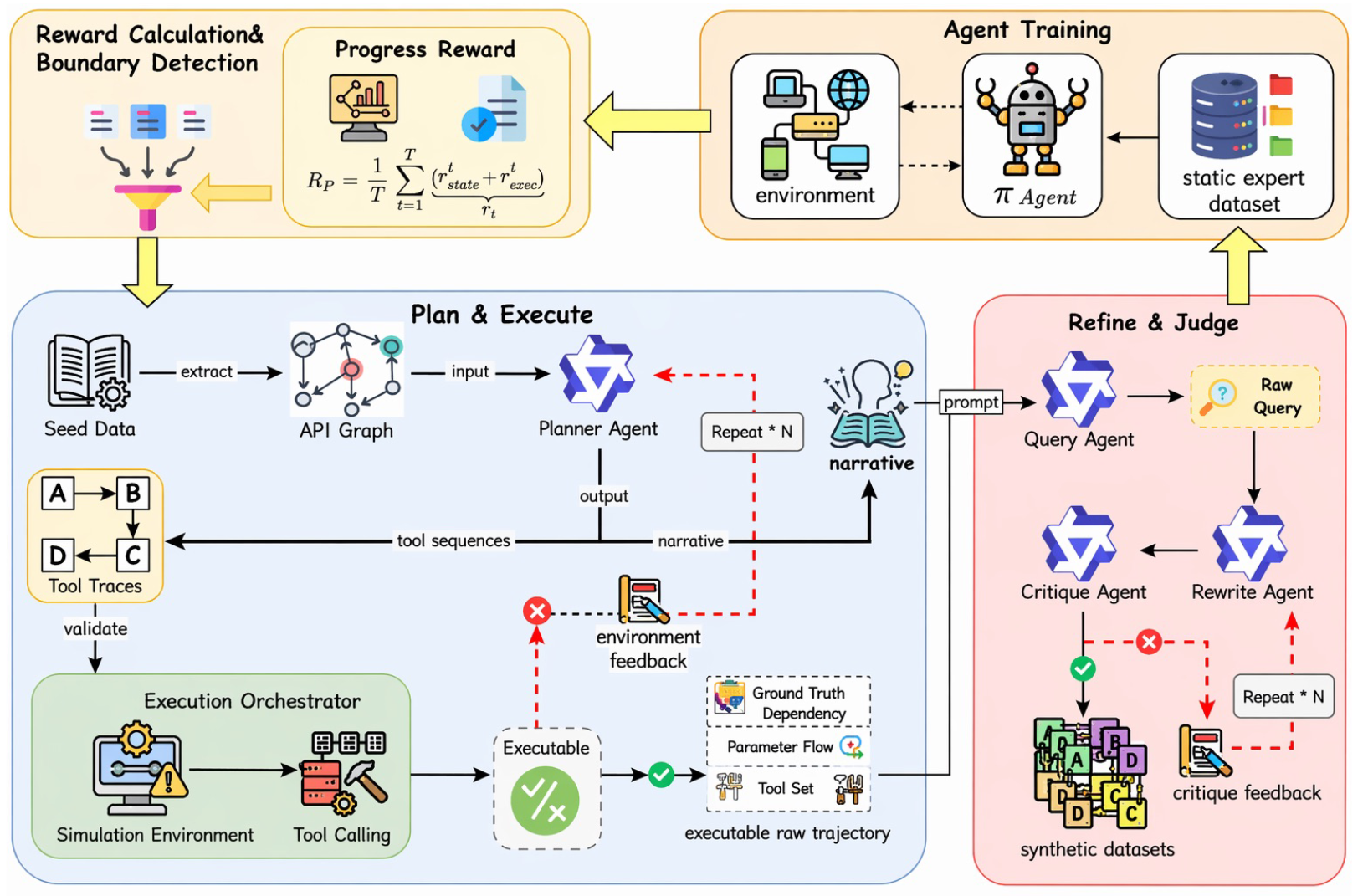
整个训练 + 数据合成的循环流程如下图所示:
三、实验结果
3.1 多轮工具调用
基于 Qwen2.5-7B-Instruct、Qwen3-4B-Instruct 和 Llama-3.1-8B-Instruct 训练,在 BFCL V3 多轮基准上测试。对照组包括常规的固定数据集 RL、同样主打少样本 RL 的 EnvTuning 方法、GPT-4o、DeepSeek-V3.2,以及大规模数据合成方案 FunReason-MT-4B,得分汇总如下:
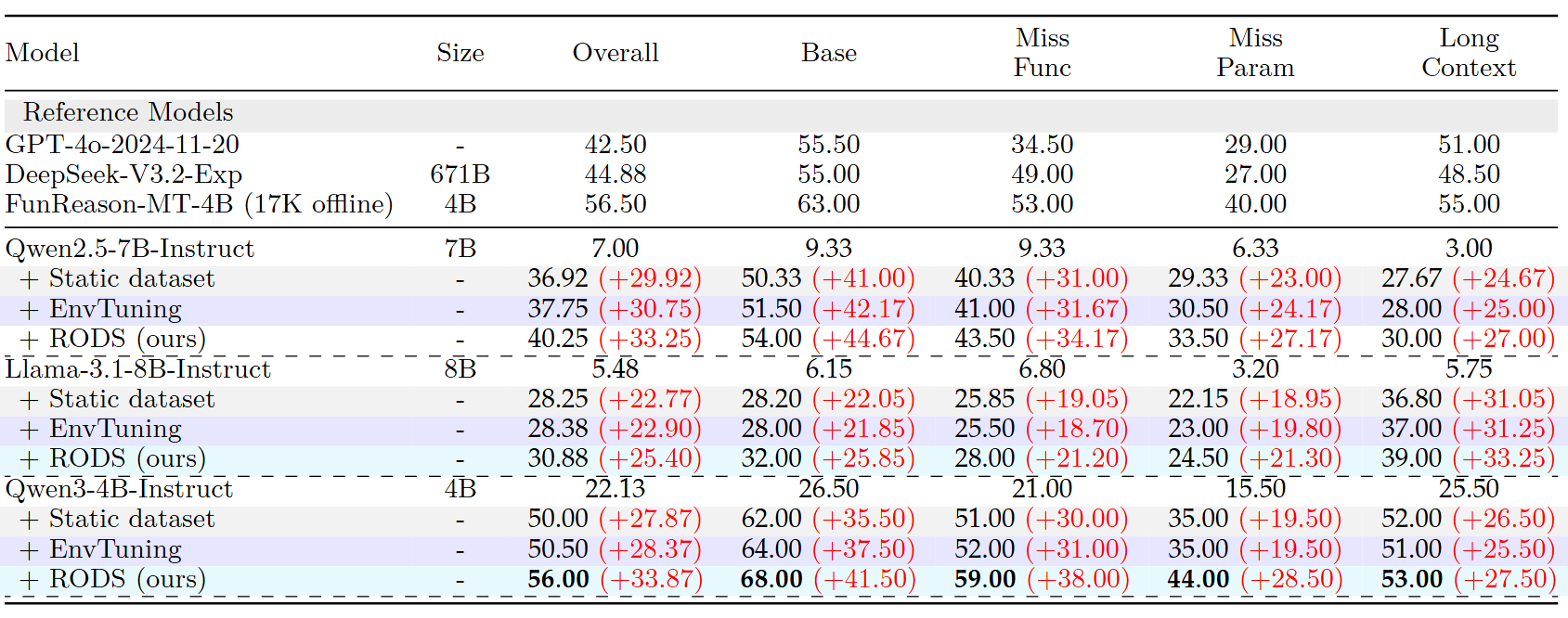
EnvTuning:环境调优,精心设计一个带有课程、提示和奖励的智能训练环境,让 LLM Agent 在极度缺乏高质量训练数据的情况下,从增强环境中获取更详细的学习信号,吃透种子样本
基准得分与合成数据规模成正比关系:
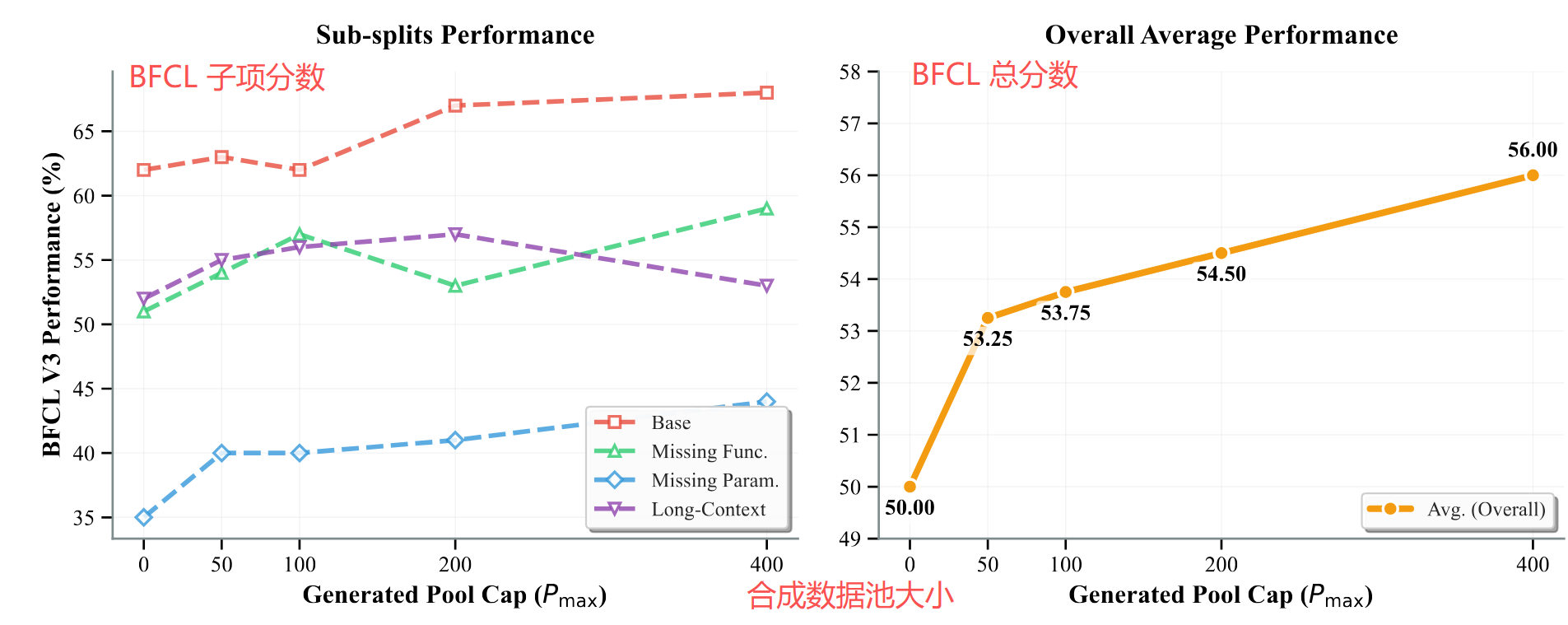
数据效率方面,FunReason-MT-4B 使用了 17K 条数据来训练,而在同样的模型规模下,RODS 仅用 800 条数据就达到了同等效果
3.2 消融实验
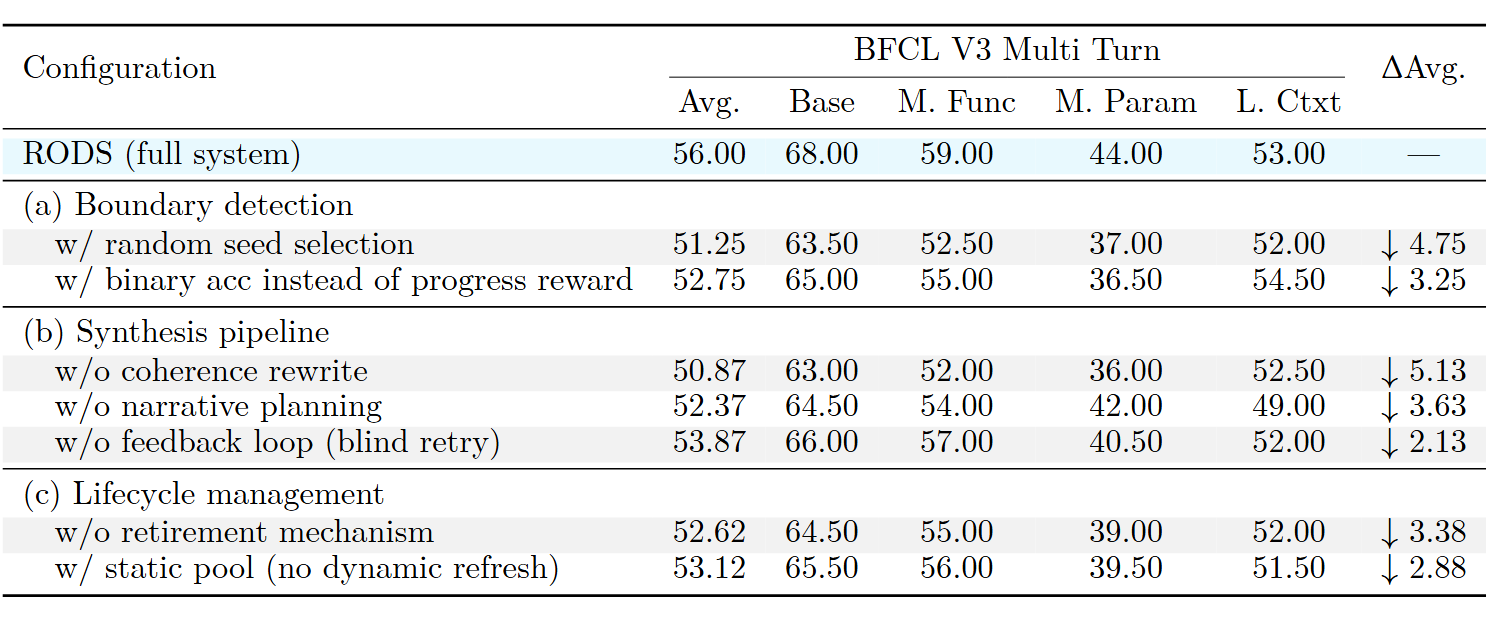
移除一致性重写导致整体性能下降最大(-5.13%),合成的样本在质量判断器上的通过率从 63% 暴跌至 12%;去掉其他组件也会带来一定的效果衰退
四、局限
-
依赖确定性的模拟环境。合成 pipeline 需要可执行的 Python 对象搭建确定性模拟环境,用于验证新 API 序列能否跑通、并提供反馈。一旦换到不透明的环境,或远程的 MCP server,这套验证就难以照搬。作者把 "如何安全地包裹有状态的 MCP 端点" 列为后续方向
-
省数据但不省算力。边界检测本身零额外推理开销,但合成 pipeline 要另起一个 32B 模型集群常驻跑,GPU 占用翻倍,换来 20× 数据效率,某些场景下这一 trade off 可能不划算