该笔记总结自 《数据库系统概论》4小时期末不挂科!期末突击|核心考点|案例解析 的选集7 恢复技术
目录
事务
- 事务是用户定义的一个数据库操作序列,这些操作要么全做,要么全不做,是一个不可分割的工作单位。
- 在关系数据库中,一个事务可以是一条SQL语句,一组SQL语句或整个程序。
- 事务是数据库恢复和并发控制 的 基本单位 (常考)
事务定义
- 显式定义方式
sql
BEGIN TRANSACTION
SQL 语句1
SQL 语句2
COMMIT
BEGIN TRANSACTION
SQL 语句1
SQL 语句2
ROLLBACKCOMMIT
- 事务正常结束
- 提交事务的所有操作(读+更新)
- 事务中所有对数据库的更新写回到磁盘上的物理数据库中
ROLLBACK
- 事务异常终止
- 事务运行的过程中发生了故障,不能继续执行
- 系统将事务中对数据库的所有已完成的更新操作全部撤销
- 事务回滚到开始时的状态
- 隐式方式
当用户没有显式地定义事务时,数据库管理系统按缺省规定自动划分事务
ACID特性
(可类比操作系统课程)
- 原子性
事务是数据库的逻辑工作单位。事务中包括的诸操作要么都做,要么都不做 - 一致性
事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态 - 隔离性
一个事务的执行不能被其它事务干扰,一个事务内部的操作及使用的数据对其它并发事务是隔离的,并发执行的各个事务之间不能互相干扰 - 持续性
也称永久性。一个事务一旦提交,它对数据库中数据的改变应该是永久性的,接下来的其他操作或故障不应该对其执行结果有任何影响
故障
- 故障是不可避免的
计算机硬件故障,软件的错误,操作员的失误,恶意的破坏 - 故障的种类
事务内部的故障,系统故障,介质故障
事务内部的故障
- 有的可以通过事务程序本身发现的
例:
sql
-- 转账事务
BEGIN TRANSACTION
读账户甲的余额BALANCE1;
BALANCE1 = BALANCE1 -AMOUNT; --AMOUNT为转账金额
IF(BALANCE1 < 0) THEN
{ 打印'金额不足,不能转账';
--事务内部可能造成事务被回滚的情况
--撤销刚才的修改,恢复事务
ROLLBACK;
}
ELSE
{ 读账户乙的余额BALANCE2;
BALANCE2 = BALANCE2 + AMOUNT;
写回BALANCE2;
COMMIT;
}- 有的是非预期的,不能由事务程序处理的
例:运算溢出,死锁,违法完整性约束......
系统故障
- 又称为软故障 ,是指造成系统停止运转的任何事件,使得系统要重新启动。影响正在运行的所有事务,但不破坏数据库
- 内存中数据库缓冲区的信息全部丢失
- 所有正在运行的事务都非正常终止
- 部分尚未完成的事务的结果可能已送入物理数据库,从而造成数据库可能处于不正确的状态
原因:
- 特定类型的硬件错误(如CPU故障)
- 操作系统故障
- 数据库管理系统代码错误
- 系统断电
- 导致系统崩溃的计算机病毒
介质故障
也称为硬故障,指外存故障
- 磁盘损坏
- 磁头碰撞
- 瞬时强磁场干扰
- 破坏硬盘数据的计算机病毒
- 介质故障破坏数据库或部分数据库,影响正在存取这部分数据的所有事务
- 介质故障比前两类故障的可能性小 得多,但破坏性大得多
- 需要借助存储在其他地方的数据备份来恢复数据库
恢复策略
事务故障
- 恢复方法:由恢复子系统利用日志文件撤销(UNDO)此事务已对数据库进行的修改
- 事务故障的恢复由系统自动完成 ,对用户是隐蔽
- 反向扫描文件日志(即从最后向前扫描日志文件),查找该事务的更新操作。
- 对该事务的更新操作执行逆操作 。即将日志记录中"更新前的值"写入数据库。
- 插入操作,"更新前的值"为空,则相当于做删除操作
- 删除操作,"更新后的值"为空,则相当于做插入操作
- 若是修改操作,则相当于用修改前值代替修改后值
- 继续反向扫描日志文件,查找该事务的其他更新操作,并做同样处理。
- 如此处理下去,直至读到此事务的开始标记,事务故障恢复就完成了
系统故障
- 系统故障造成数据库不一致状态的原因
- 未完成事务对数据库的更新可能已写入数据库
- 已提交事务对数据库的更新可能还留在缓冲区没来得及写入数据库
- 恢复方法
- Undo 故障发生时未完成的事务
- Redo 已完成的事务
- 系统故障的恢复由系统在重新启动时自动完成 ,不需用户干预
- 正向扫描日志文件(即从头扫描日志文件)
- 重做队列(REDO-LIST):在故障发生前已经提交的事务
这些事务既有BEGIN TRANSACTION记录,也有COMMIT记录 - 撤销队列(UNDO-LIST):故障发生时尚未完成的事务
这些事务只有BEGIN TRANSACTION记录,无相应的COMMIT记录
- 重做队列(REDO-LIST):在故障发生前已经提交的事务
- 对撤销队列事务进行撤销(UNDO)处理
- 反向扫描日志文件,对每个撤销事务的更新操作执行逆操作
即将日志记录中"更新前的值"写入数据库
- 反向扫描日志文件,对每个撤销事务的更新操作执行逆操作
- 对重做队列事务进行重做(REDO)处理
- 正向扫描日志文件,对每个重做事务重新执行登记的操作
即将日志记录中"更新后的值"写入数据库
- 正向扫描日志文件,对每个重做事务重新执行登记的操作
- 正向扫描日志文件(即从头扫描日志文件)
介质故障
方式:
- 重装数据库
- 重做已完成的事务
恢复步骤:
- 装入最新的后备数据库副本(离故障发生时刻最近的转储副本),使数据库恢复到最近一次转储时的一致性状态。
- 对于静态转储的数据库副本,装入后数据库即处于一致性状态
- 对于动态转储的数据库副本,还须同时装入转储时刻的日志文件副本,利用恢复系统故障的方法(即REDO+UNDO),才能将数据库恢复到一致性状态
- 装入有关的日志文件副本(转储结束时刻的日志文件副本),重做已完成的事务。
- 首先扫描日志文件,找出故障发生时已提交的事务的标识,将其记入重做队列
- 然后正向扫描日志文件,对重做队列中的所有事务进行重做处理。即将日志记录中"更新后的值写入数据库
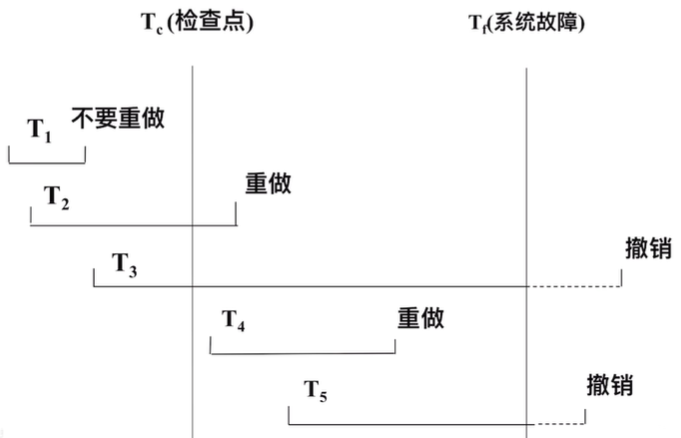
具有检查点的恢复技术
前面提到的恢复方法都需要扫码日志,会浪费大量时间
- 检查点记录的内容
建立检查点时刻所有正在执行的事务清单
这些事务最近一个日志记录的地址 - 重新开始文件的内容
记录各个检查点记录在日志文件中的地址 - 动态维护日志文件的方法
周期性地执行如下操作:建立检查点,保存数据库状态。
具体步骤是:- 将当前日志缓冲区中的所有日志记录写入磁盘的日志文件中
- 在日志文件中写入一个检查点记录
- 将当前数据缓冲区的所有数据记录写入磁盘的数据库中
- 把检查点记录在日志文件中的地址写入一个重新开始文件
- 恢复子系统可以定期或不定期地建立检查点,保存数据库状态
- 定期
按照预定的一个时间间隔,如每隔一小时建立一个检查点 - 不定期
按照某种规则,如日志文件已写满一半建立一个检查点
- 定期
- 使用检查点方法可以改善恢复效率
- 当事务T在一个检查点之前提交,T对数据库所做的修改已写入数据库
- 写入时间是在这个检查点建立之前或在这个检查点建立之时
- 在进行恢复处理时,没有必要对事务T执行重做操作
系统出现故障时,恢复子系统将根据事务的不同状态采取不同的恢复策略