0. 简介
Nano World Models 讨论的不是一个更大的视频生成模型,而是一个更适合研究者拆开实验的世界模型代码库。过去一年里,交互式视频生成和世界模拟器进展很快,但很多系统的训练数据、模型结构、采样策略和下游任务被绑在一起,读论文能知道它"效果很强",真正想改一个 action injection、换一个 latent space、复现实验指标时,往往要重写半条 pipeline。Nano World Models 的价值在这里:它把未来视频预测拆成可替换的配置轴,让目标函数、模型规模、动作注入、潜空间、数据集、评测和长时域 rollout 都能在同一接口下比较。对应的项目在GITHUB项目页。
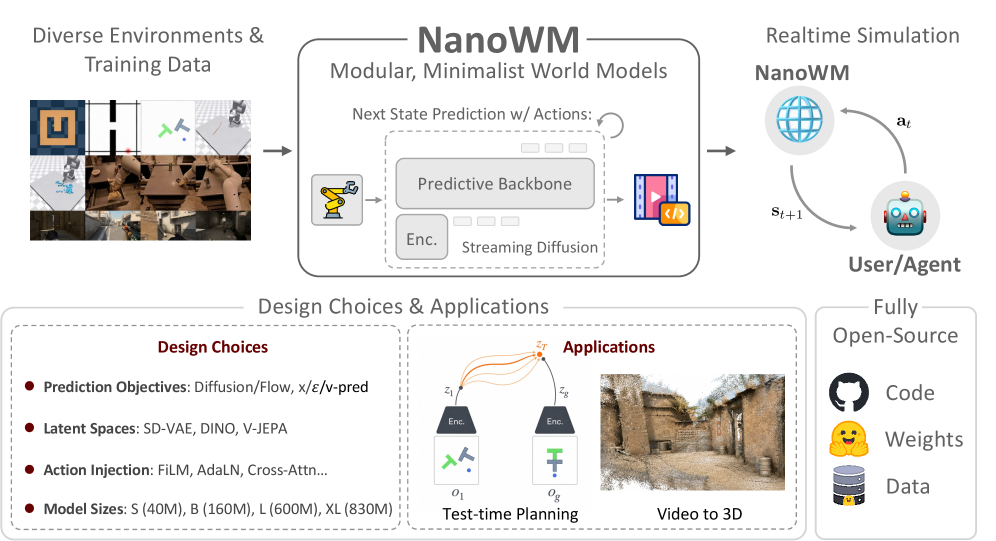
读这张图时不要只看"支持很多任务",更应该看它背后的接口统一:不同环境的数据先被编码成 latent observation,未来帧预测统一走 diffusion forcing,动作条件可以通过不同机制注入,最终同一套模型接口既能做视频 rollout,也能接 MPC planning 或 Video-to-3D。这里的关键是把世界模型从"一个封闭演示系统"改造成"可控实验对象"。
1. 为什么需要 Nano World Models
1.1 世界模型研究的真正瓶颈
**世界模型(World Model)**的基本目标,是让模型根据历史观测和条件变量预测未来观测,进而支持生成、规划和决策。对机器人、游戏智能体和空间智能来说,这件事很自然:如果模型能在执行动作前预测未来画面,就能把自己当作内部模拟器,比较不同动作序列的后果。问题在于,现代世界模型通常牵涉视频扩散、latent 编码、动作条件、采样调度、评测指标和下游 planner,任何一个环节换掉,都可能改变结果。
这也是 Nano World Models 的出发点。论文认为,世界模型算法正在从"发明新范式"进入"理解细粒度设计选择"的阶段 。换句话说,研究重点不只是提出一个更强模型,而是回答更具体的问题: x x x-prediction、 v v v-prediction、 ϵ \epsilon ϵ-prediction 和 flow matching 到底差在哪里;模型从 40M 到 460M 是否稳定变好;action 是直接加到 token 上、用 AdaLN、FiLM,还是 cross-attention 更合适;VAE、DINO、V-JEPA 这类 latent space 对预测和 planning 的影响是不是一致。没有统一代码,这些问题很难严谨比较。
1.2 它和"大模型世界模拟器"的差别
工业级世界模型通常追求高真实感、长时域、实时交互或强泛化,这些方向当然重要,但它们往往代价很高:训练成本高、数据不可得、代码不可复现、实验轴线难以控制。Nano World Models 反过来选择"足够小但完整"的路线,它不是为了在视觉效果上压过闭源系统,而是为了让研究者能在普通实验流程中改配置、跑消融、看指标、保存 rollout,再把结果接到 planning 或 3D 重建工具里。
官方 README 把这个仓库描述成一个基于 diffusion-forcing 训练视频世界模型的 minimalist repository,并提供训练、推理、评测、预训练 checkpoint 和文档。当前 Hugging Face collection 中可以看到 RT-1 prediction target 消融、action injection 消融、scale 消融,以及 DINO-WM、RT-1、CSGO 等任务 checkpoint。这个开放度是文章最值得重视的地方:它不是只发布一个模型,而是把模型设计选择暴露成可复现实验。
2. 一句话理解 Nano World Models
2.1 核心思想
Nano World Models 的一句话概括是:用 diffusion forcing 把未来视频预测统一成一个条件序列生成问题,再用 Hydra 配置把目标函数、模型规模、动作注入、latent space、数据集和采样方式变成可替换实验轴。 这句话里最关键的是"统一接口"。模型并不强迫研究者为 RT-1、CSGO、PushT、Point Maze 分别写独立训练流程,而是让这些数据源暴露相同形式的 observation window、action sequence 和 metadata。
形式上,模型接收历史观测 o 1 : T \mathbf{o}{1:T} o1:T,条件变量 c c c,有动作时还接收动作序列 a T : T + H − 1 \mathbf{a}{T:T+H-1} aT:T+H−1,目标是生成未来观测 o T + 1 : T + H \mathbf{o}_{T+1:T+H} oT+1:T+H。实际训练时,模型通常不直接预测 RGB,而是先通过 encoder 得到 latent:
x t = e n c ( o t ) \mathbf{x}_t=\mathrm{enc}(\mathbf{o}_t) xt=enc(ot)
然后学习条件分布:
p θ ( x T + 1 : T + H ∣ x 1 : T , c , a T : T + H − 1 ) p_\theta(\mathbf{x}{T+1:T+H}\mid \mathbf{x}{1:T},c,\mathbf{a}_{T:T+H-1}) pθ(xT+1:T+H∣x1:T,c,aT:T+H−1)
这里的工程判断很明确:未来视频预测不是只追求像素好看,真正有用的世界模型还要能在动作变化时产生可区分的未来。因此 NanoWM 同时评测视觉指标和 planning 指标,并把 latent space 是否"用上动作"作为重要诊断项。
2.2 它支持哪些研究轴
Nano World Models 把世界模型拆成六个主要轴线。第一是生成目标,包括 diffusion 下的 ϵ \epsilon ϵ、 x x x、 v v v prediction,以及 flow matching。第二是模型规模,论文描述 NanoWM-S、B、L、XL 四档,官方配置和 checkpoint 常用 S/B/L,CSGO 有专门的 L/2 形状。第三是 action injection,包括 additive、AdaLN、AdaLN-fuse、FiLM 和 cross-attention。第四是 latent observation space,包括 SD-VAE、Web-DINO 和 V-JEPA 2.1。第五是数据环境,包括 DINO-WM 系列控制环境、CSGO 游戏数据和 RT-1 真实机器人数据。第六是 rollout 与下游应用,包括长时域生成、MPC planning、Video-to-3D。
| 研究轴 | NanoWM 中的可替换选项 | 核心问题 |
|---|---|---|
| 生成目标 | ϵ \epsilon ϵ / x x x / v v v / flow | 预测目标如何影响重建质量和分布质量 |
| 模型规模 | S / B / L / XL,常用 B/2 与 L/2 | 更大模型是否稳定提升 |
| 动作注入 | additive / AdaLN / AdaLN-fuse / FiLM / cross-attention | action 怎样进入视频 dynamics 更有效 |
| 潜空间 | SD-VAE / Web-DINO / V-JEPA 2.1 | 重建型 latent 与语义型 latent 是否同样适合 planning |
| 数据环境 | Point Maze / Wall / PushT / Rope / Granular / RT-1 / CSGO | 同一 pipeline 是否能覆盖不同动态复杂度 |
| 应用 | rollout / MPC / Video-to-3D | 世界模型如何变成下游工具 |
3. 方法主线:Diffusion Forcing 为什么是统一接口
3.1 从全序列扩散到逐帧噪声调度
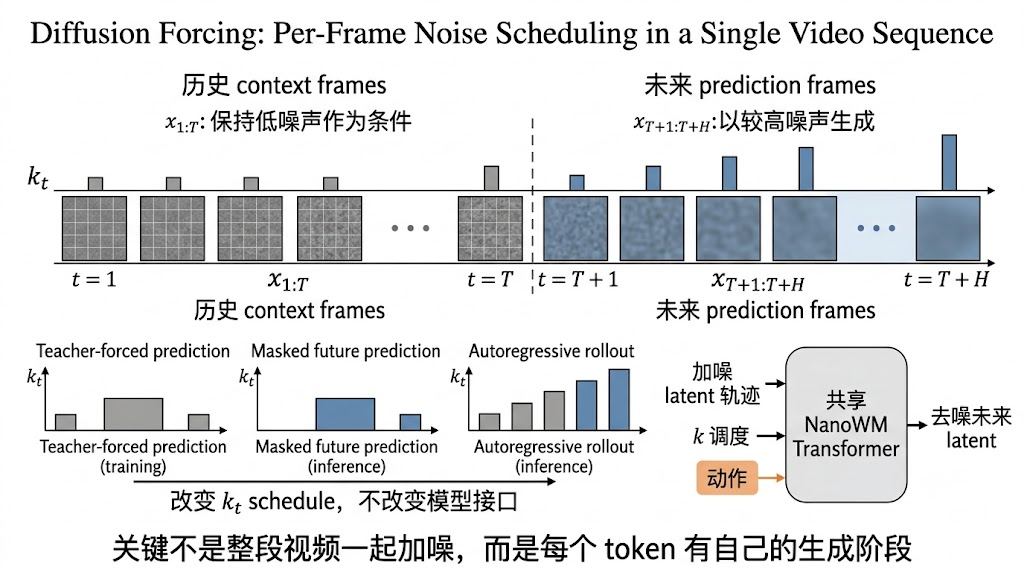
标准视频扩散通常把整段视频作为一个样本进行加噪和去噪,这对固定长度视频生成很自然,但不太适合在线交互。在线世界模型有两个额外要求:历史帧应该作为条件保持相对干净,未来帧可以逐步生成;当 rollout 超过训练窗口时,模型还要把自己生成的帧滑入历史窗口,继续预测后面的未来。Diffusion Forcing 的关键就是允许同一条序列中不同 token 拥有不同噪声水平。
Diffusion Forcing 原论文把它定义为一种训练范式:模型对一组 token 进行去噪,但每个 token 可以有独立 noise level。放到视频世界模型里,历史帧可以被赋予较低噪声,未来帧可以被赋予较高噪声;通过改变 noise schedule,同一个模型可以表达 teacher-forced prediction、masked future prediction 和 autoregressive rollout。NanoWM 正是把这个性质做成代码接口,而不是把每种采样方式写成独立模型。
3.2 统一公式
设 latent 序列为 x 1 : T + H \mathbf{x}_{1:T+H} x1:T+H,每一帧分配一个噪声索引 k t ∈ K k_t\in\mathbb{K} kt∈K,整条序列对应噪声调度:
k = ( k 1 , ... , k T + H ) \mathbf{k}=(k_1,\ldots,k_{T+H}) k=(k1,...,kT+H)
训练时,模型看到的是被不同程度加噪后的 latent trajectory,以及当前噪声调度 k \mathbf{k} k。如果 t ≤ T t\leq T t≤T 是历史 context frame,可以让 k t k_t kt 很小;如果 t > T t>T t>T 是未来 frame,可以让 k t k_t kt 更大。这样模型学到的不是普通 next-frame regression,而是"在给定历史和噪声日程时,把未来 latent 从噪声推回合理未来"的条件生成能力。
这套抽象的好处,是目标函数和采样方式可以被配置化。对于 diffusion objective,模型可以预测 ϵ \epsilon ϵ、 x x x 或 v v v;对于 flow matching,模型可以预测从噪声到数据路径上的 velocity field。GitHub 训练文档中也把这些目标作为同一套 experiment.diffusion.pred_name 的不同取值,而不是不同代码分支。
3.3 训练循环的代码化理解
NanoWM 的真实训练入口由 PyTorch Lightning 接管,核心逻辑在 NanoWMTrainingModule.training_step。下面是 nano-world-model/src/experiments/train_experiment.py:199-240 的源码节选,可以直接看到它怎样从 batch 取出视频和动作、用 latent codec 编码帧、按 diffusion forcing 或 full-sequence diffusion 选择 timestep 形状,再调用 self.diffusion.training_losses 计算目标函数。
python
def training_step(self, batch, batch_idx):
x = batch["video"].to(self.device)
video_name = batch["video_name"]
action = None
if self.args.model.use_action:
action = batch["action"].to(self.device)
with torch.no_grad():
b, _, _, _, _ = x.shape
x = rearrange(x, "b f c h w -> (b f) c h w").contiguous()
x = self._vae_encode(x)
x = rearrange(x, "(b f) c h w -> b f c h w", b=b).contiguous()
if self.args.model.extras == 78:
raise ValueError("T2V training is not supported at this moment!")
elif self.args.model.extras == 2:
model_kwargs = dict(y=video_name)
else:
model_kwargs = dict(y=None)
if self.args.model.use_action:
model_kwargs["action"] = action
diffusion_mode = self.args.experiment.diffusion.mode
if diffusion_mode == "diffusion_forcing":
t_shape = (x.shape[0], x.shape[1])
elif diffusion_mode == "full_seq_diffusion":
t_shape = (x.shape[0],)
else:
raise ValueError(f"Unknown diffusion_mode: {diffusion_mode}. Must be 'full_seq_diffusion' or 'diffusion_forcing'")
t = sample_training_timesteps(
t_shape,
self.diffusion.num_timesteps,
strategy=self.args.experiment.diffusion.timestep_sampling,
logit_normal_mean=self.args.experiment.diffusion.logit_normal_mean,
logit_normal_std=self.args.experiment.diffusion.logit_normal_std,
device=self.device,
)
loss_dict = self.diffusion.training_losses(self.model, x, t, model_kwargs)
loss = loss_dict["loss"].mean()这段源码里最关键的不是某个变量名,而是两个设计选择。第一,diffusion_forcing 下的 t_shape=(B,T),说明每一帧可以拥有自己的 diffusion timestep;如果切到 full_seq_diffusion,timestep 只按 batch 采样。第二,目标函数并没有散落在训练循环里,而是收敛到 self.diffusion.training_losses(...),目标类型由 experiment.diffusion.pred_name、noise_schedule、zero_terminal_snr 等配置决定。这就是 NanoWM 能做 x/v/epsilon/flow 消融的原因:训练循环不变,变的是 diffusion 对象和配置。
Diffusion 对象本身在同一个模块初始化。下面是 nano-world-model/src/experiments/train_experiment.py:76-83 的源码节选,它把配置中的 prediction target、noise schedule 和 diffusion steps 传给 create_diffusion:
python
self.diffusion = create_diffusion(
timestep_respacing="",
noise_schedule=args.experiment.diffusion.noise_schedule,
pred_name=args.experiment.diffusion.pred_name,
diffusion_steps=args.experiment.diffusion.diffusion_steps,
snr_gamma=args.experiment.diffusion.snr_gamma,
zero_terminal_snr=args.experiment.diffusion.zero_terminal_snr,
)如果 pred_name=v,训练目标由 diffusion 实现解释为 velocity-style parameterization;如果 pred_name=x,目标更接近 clean latent;如果切到 flow,则走 flow matching 对应路径。文章里不应该写一个仓库不存在的"目标构造函数",因为真正承担这件事的是 diffusion.training_losses 与 create_diffusion 组合。这个细节很重要:读者照着源码查,能找到实现;照着抽象示例查,只会找不到函数。
4. 架构:latent video token + Transformer + action injection
4.1 为什么不直接预测像素
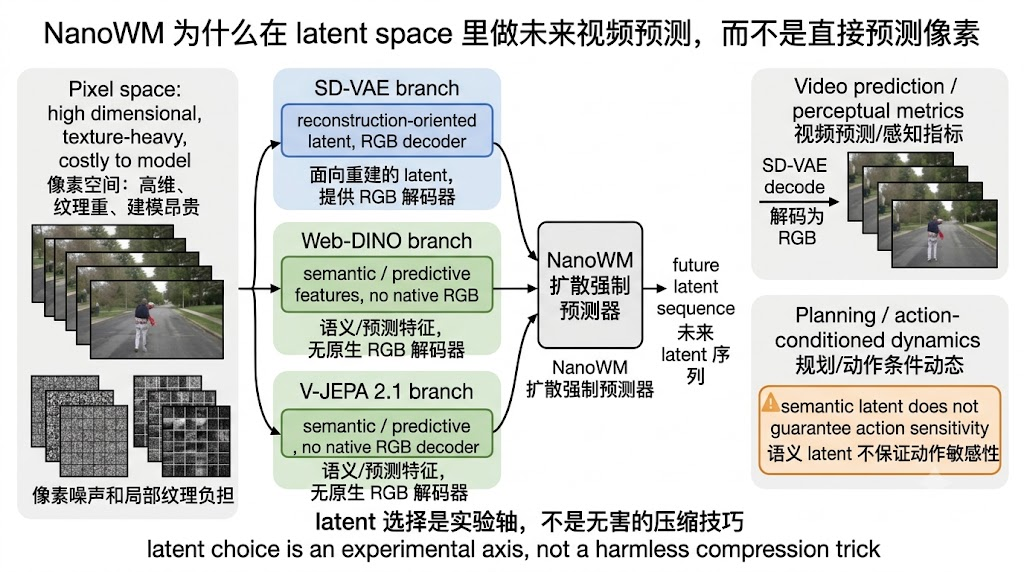
NanoWM 默认预测 encoded observation,而不是直接预测 RGB 像素。这个选择来自现代视频生成和机器人世界模型的共同经验:像素空间维度高、局部纹理噪声多,直接预测容易把容量耗在颜色和细节上;latent space 能把帧压缩成更适合生成的表示,再由 decoder 还原成 RGB,或者直接在表示空间里做 planning。SD-VAE latent 是重建导向的,可以解码成图像;Web-DINO 和 V-JEPA 2.1 是语义/预测特征导向的,不天然支持 RGB 重建。
这个选择不是实现细节,而是论文最重要的实验轴之一。直觉上,DINO 或 V-JEPA 这类语义特征更"懂世界",似乎更适合 planning;但 NanoWM 的 PushT 结果显示,语义 latent 在相同 diffusion-forcing 接口下可能学不到可控 dynamics,表现为 ground-truth action、zero action、random action rollout 之间距离几乎不变,action embedding RMS 接近零。换句话说,语义强不等于世界模型能用动作做反事实预测。
4.2 Transformer 主干和 patch 规模
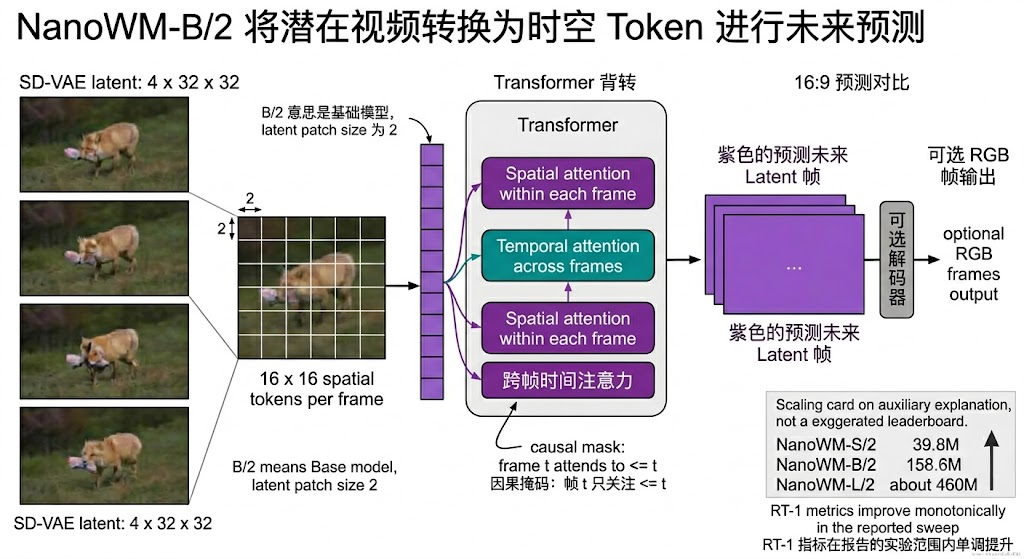
NanoWM 使用 Transformer 处理 latent video tokens。对 VAE latent,每帧 latent 被分成空间 patch,投影到 hidden dimension,再经过 interleaved spatial-temporal attention。模型命名沿用视频/图像 diffusion 社区的习惯:NanoWM-B/2 表示 Base 规模、latent patch size 为 2;NanoWM-B/4、B/8 则使用更粗 patch。官方配置文档列出常用模型:NanoWM-S/2 约 40M,NanoWM-B/2 约 160M,NanoWM-L/2 约 460M;CSGO 由于分辨率形状不同,有专门的 S/2 和 L/2 CSGO 配置。
进一步看,模型规模实验给出比较清晰的结论:在 RT-1 50K-step ablation 中,S/2 到 B/2 再到 L/2,PSNR、SSIM、LPIPS、FID 都单调改善。S/2 约 39.8M 参数,FID 54.95;B/2 约 158.6M,FID 42.27;L/2 约 460M,FID 36.31。这个结果不是说"越大越值得",而是说明在 NanoWM 的实验范围内,还没有看到 scaling 失效;B/2 更适合作为默认质量/成本折中,L/2 更适合追求容量,S/2 更适合快速迭代。
4.3 Action injection 不只是把动作拼进去
动作条件是世界模型区别于普通视频生成的关键。如果模型只预测"自然视频下一帧",它可以忽略 action;但在机器人或游戏里,同一个当前画面配上不同动作,未来应该不同。NanoWM 支持五种动作注入机制:additive 是把 action embedding 加到对应帧 token;AdaLN 和 AdaLN-fuse 通过 adaptive layer norm 调制特征;FiLM 通过 feature-wise modulation 改变通道;cross-attention 让 video tokens attend 到 action tokens。
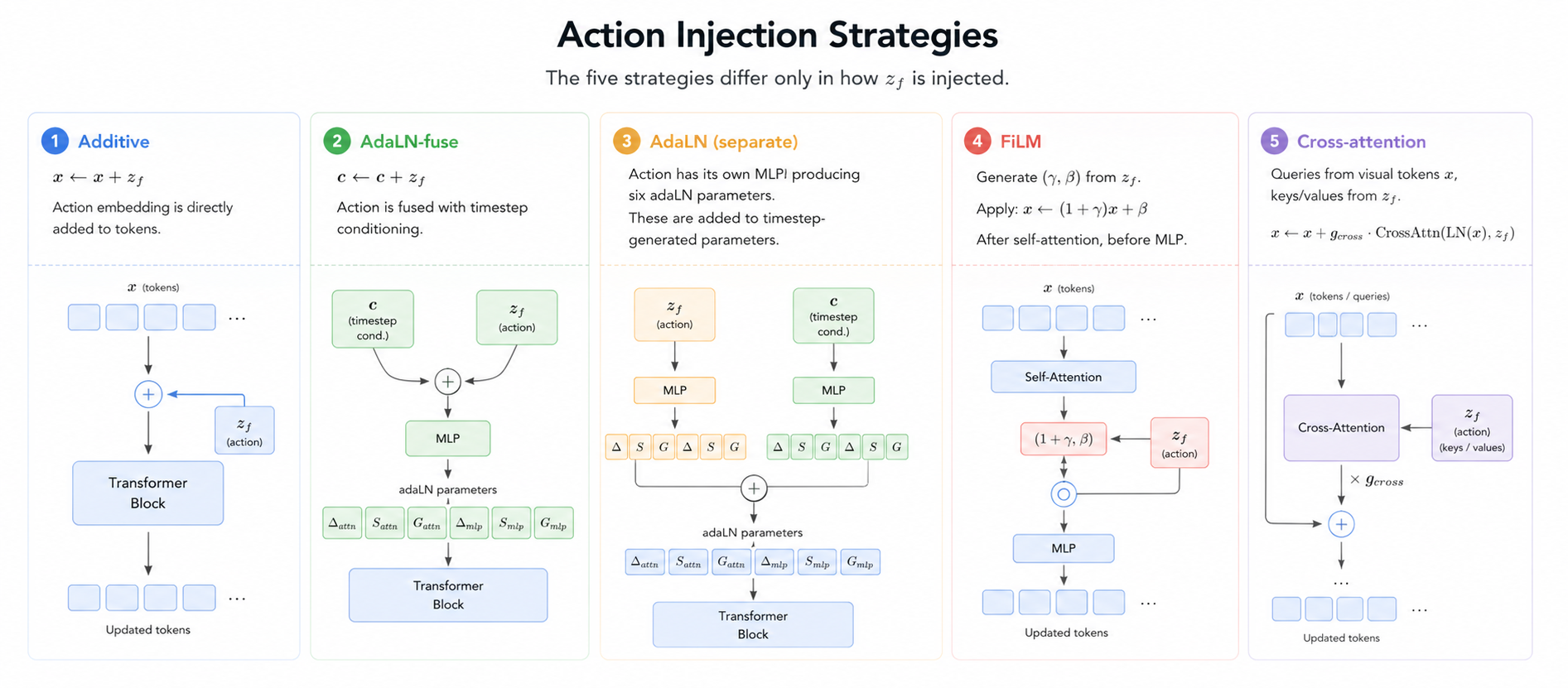
官方实验给出的判断很克制:action injection 是任务相关的。RT-1 上 FiLM 的视觉指标最好,FID 40.62,略优于 additive 的 42.27;但 PushT 上 simple additive 最强,而且没有额外参数。cross-attention 在这些规模下反而弱,RT-1 FID 到 51.12。这里的工程启发很直接:不要假设更复杂的条件交互一定更好,低维动作和较短 prediction horizon 下,简单 additive 可能是更稳的默认项。
5. 代码结构:Hydra 让实验变成配置轴
5.1 环境安装和路径设置
官方 README 的 quick start 很短,核心是创建 nanowm 环境并设置数据与输出路径。LeRobot 数据加载由 lerobot==0.3.3 提供,官方还特别说明不要安装 lerobot-datasets,它是数据格式版本名,不是 PyPI 包。FID/FVD 评测需要额外下载 i3d torchscript 权重,这一点很容易漏掉。
bash
git clone https://github.com/simchowitzlabpublic/nano-world-model.git
cd nano-world-model
conda env create -f environment.yml
conda activate nanowm
export DATASET_DIR=/path/to/dino_wm_data
export CSGO_DATA_DIR=/path/to/csgo
export RT1_DATA_ROOT=/path/to/rt1_fractal
export RESULTS_DIR=/path/to/results
mkdir -p pretrained_models/i3d
curl -L \
"https://www.dropbox.com/scl/fi/c5nfs6c422nlpj880jbmh/i3d_torchscript.pt?rlkey=x5xcjsrz0818i4qxyoglp5bb8&dl=1" \
-o pretrained_models/i3d/i3d_torchscript.pt如果你只是想理解流程,最建议从 DINO-WM PushT 开始。PushT 数据相对轻,动作维度低,视觉结构清楚,训练和评测速度比 RT-1、CSGO 更适合做第一次实验。RT-1 更接近真实机器人视频,但动态和视觉复杂度高;CSGO 更适合观察长时域 autoregressive rollout 和视觉漂移。
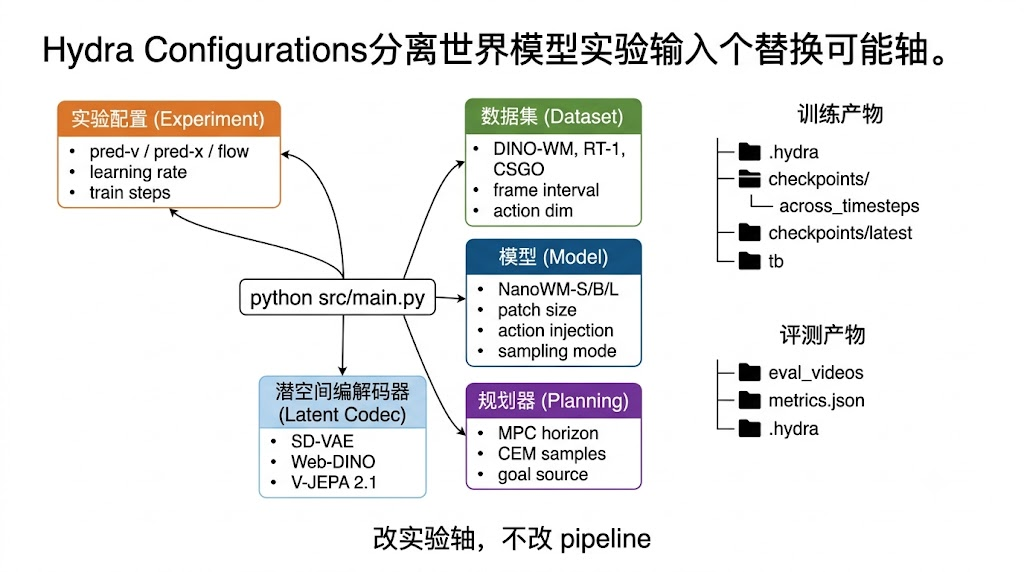
5.2 Hydra 配置的最小理解
NanoWM 的所有训练、评测和 planning 都从 src/main.py 进入,Hydra 负责把 experiment、dataset、model、latent_codec、planning 等配置组合起来。顶层配置不是文章里临时概括出来的,nano-world-model/src/configs/config.yaml:1-9 实际写法如下:
yaml
defaults:
- model: nanowm_b2
- latent_codec: sd_vae
- dataset: dino_wm/point_maze
- experiment: default
- planning: base路径可以来自环境变量,也可以写进 gitignored 的 src/configs/local/paths.yaml。真正使用时,常见做法是通过命令行覆盖某个轴。例如切换数据集、模型规模或动作注入,不需要改 Python 文件:
bash
# 训练 DINO-WM PushT,NanoWM-B/2
python src/main.py \
experiment=dino_wm_pusht \
dataset=dino_wm/pusht \
model=nanowm_b2
# 训练 CSGO,使用 CSGO 专用 L/2 模型形状
python src/main.py \
experiment=csgo \
dataset=game/csgo \
model=nanowm_l2_csgo
# RT-1 主训练
python src/main.py \
experiment=rt1 \
dataset=rt1/rt1 \
model=nanowm_b2
# 改 action injection 为 FiLM
python src/main.py \
experiment=ablation_rt1 \
dataset=rt1/rt1 \
model=nanowm_b2 \
model.action_injection.type=film这里最值得复用的不是某条命令,而是配置组织方式。experiment 管训练策略、学习率、step 数、diffusion 目标;dataset 管数据路径、frame interval、action dim;model 管模型规模、patch、action injection、sampling mode;planning 管 MPC horizon、CEM 样本数和目标来源。清楚这个分层后,复现实验就不再是"猜代码在哪里改",而是知道该改哪个配置组。
6. 从训练到评测:一条完整实现路线
6.1 训练第一个模型
官方文档的默认训练例子是 DINO-WM PushT、NanoWM-B/2、pred-v、additive injection、cosine + ZTSNR。这组默认值不是随便选的:pred-v 是仓库默认,additive 是质量/参数折中最好,B/2 是默认规模,cosine + ZTSNR 是 v v v 和 x x x prediction 常用 schedule。训练输出会写到 ${RESULTS_DIR} 对应的 run 目录,包含 .hydra 配置快照、checkpoints/latest、checkpoints/across_timesteps 和 TensorBoard 日志。
bash
python src/main.py \
experiment=dino_wm_pusht \
dataset=dino_wm/pusht \
model=nanowm_b2如果要做目标函数消融,可以直接覆盖 experiment.diffusion.pred_name。当前官方 training docs 中,除了论文主表强调的 ϵ / x / v \epsilon/x/v ϵ/x/v 外,还列出了 flow matching 消融:flow 在该文档表中达到 23.54 PSNR 和 38.10 FID,优于默认 v v v 的 FID 42.27; x x x 在 SSIM 和 LPIPS 上最好。这个口径和论文正文" x x x reconstruction 更好、 v v v FID 更好且作为默认"略有扩展,写实验时建议标明使用的是论文表还是当前 GitHub docs。
bash
# x-prediction 消融
python src/main.py \
experiment=ablation_rt1 \
dataset=rt1/rt1 \
model=nanowm_b2 \
experiment.diffusion.pred_name=x
# flow matching 消融
python src/main.py \
experiment=ablation_rt1 \
dataset=rt1/rt1 \
model=nanowm_b2 \
experiment.diffusion.pred_name=flow \
experiment.diffusion.snr_gamma=0.0 \
experiment.diffusion.zero_terminal_snr=false6.2 固定种子评测
NanoWM 的标准评测使用 256 个固定 validation clips,seed 为 42,默认 250 DDIM sampling steps,sequential scheduling。指标包括 PSNR、SSIM、LPIPS、FID,长视频足够时也可以算 FVD。评测输出包括 metrics.json、sample comparison MP4 和 .hydra 配置快照。这个设计很重要,因为世界模型论文常见问题是定性视频很好看,但指标难复现;固定子集和固定 seed 至少让不同 ablation 有共同比较面。
bash
python src/main.py \
experiment=evaluate_only \
dataset=dino_wm/pusht \
model=nanowm_b2 \
experiment.resume_from_checkpoint=/path/to/checkpoint.ckpt \
experiment.evaluation.batch_size=1 \
dataset.loader.validation_fixed_subset_size=256 \
dataset.loader.validation_fixed_subset_seed=42采样方式也会影响速度和质量。sequential 是默认,逐帧自回归去噪,质量通常更高;full_sequence 会联合去噪整段 clip,速度更快但质量略低。planning 场景通常要求大量 candidate rollouts,如果仍用 sequential,每次 CEM 优化都会很慢,所以官方 planning 文档建议设置 model.scheduling_mode=full_sequence。
bash
python src/main.py \
experiment=evaluate_only \
dataset=dino_wm/pusht \
model=nanowm_b2 \
experiment.resume_from_checkpoint=/path/to/checkpoint.ckpt \
model.scheduling_mode=full_sequence \
model.num_sampling_steps=507. 下游工具:从未来视频到 Planning 和 3D
7.1 长时域 rollout
官方 long rollout 脚本可以从训练 checkpoint 生成 50 帧以上视频。CSGO 示例使用 4 帧历史,生成 50 帧,总共 32 个样本,batch size 4,50 DDIM steps,sequential scheduling。--config 需要指向训练 run 里的 .hydra/config.yaml,因为 rollout 需要匹配训练时的数据、模型形状和解码设置。
bash
python src/sample/rollout.py \
--config /path/to/run/.hydra/config.yaml \
--ckpt /path/to/checkpoint.ckpt \
--save_path results/long_rollout/csgo_100k \
--num_samples 32 \
--batch_size 4 \
--rollout_length 50 \
--history_length 4 \
--num_sampling_steps 50 \
--scheduling_mode sequential \
--history_stabilization_level 0.02 \
--fps 8长时域 rollout 的核心权衡是质量和速度。官方文档建议 50 DDIM steps 是质量/速度折中点,25 steps 可做快速预览,250 steps 适合追求更高质量。history_stabilization_level 用于给历史 latent 注入小噪声,帮助缓解 teacher-forcing brittleness;但过高会洗掉细节。这些参数不是"调参装饰",它们直接决定模型能否从短窗口生成稳定长视频。
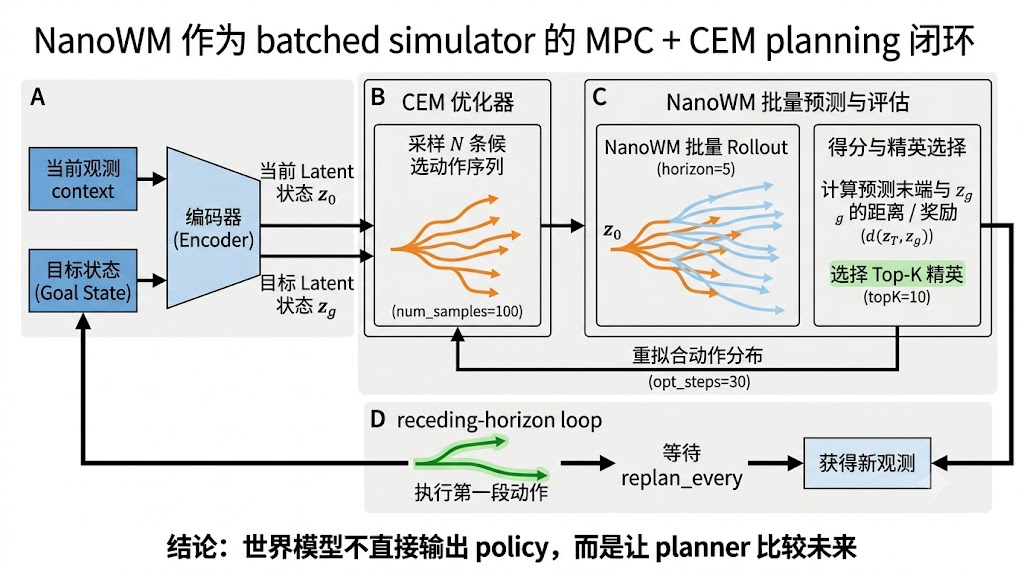
7.2 MPC + CEM planning
NanoWM 的 planning 接口把世界模型当作 batched rollout function。给定当前 observation、goal latent 和一批 candidate action sequences,模型并行预测未来 latent,再用目标函数打分。CEM 更新动作分布,保留 top-K elites,重复若干轮后执行最优序列的前几个动作,再重新观测和规划。这个流程不是训练 policy,而是把世界模型当作测试时 planner。
先看 nano-world-model/src/planning/cem_planner.py:90-95。CEM 并不直接访问环境未来状态,而是把每一批候选动作交给 world_model.rollout,再让 objective function 给预测 latent 打分:
python
with torch.no_grad():
z_obses, _ = self.world_model.rollout(
obs_0=obs_0_expanded,
act=cur_actions,
)
losses.append(self.objective_fn(z_obses, z_obs_g_expanded))接着看 nano-world-model/src/planning/cem_planner.py:163-200。这段源码就是 CEM 的核心循环:从当前 mu/sigma 采样动作序列,计算 loss,取 top-k elites,再用 elite actions 更新分布。它比伪流程更值得放进文章,因为这里能看到 action_samples[0] = mu[b]、动作裁剪、sigma_min 这些会影响稳定性的实现细节。
python
for i in range(self.opt_steps):
# Optimize each instance in batch
batch_losses = []
for b in range(batch_size):
# Sample action sequences
action_samples = (
torch.randn(self.num_samples, self.horizon, self.action_dim).to(self.device)
* sigma[b]
+ mu[b]
)
action_samples[0] = mu[b] # First sample is current mean
# Clip to action space if bounds provided.
if self.action_low is not None or self.action_high is not None:
action_samples = action_samples.clamp(
min=self.action_low if self.action_low is not None else -float("inf"),
max=self.action_high if self.action_high is not None else float("inf"),
)
obs_0_single = {k: v[b:b+1] for k, v in obs_0.items()}
z_obs_g_single = {
k: v[b:b+1] if v is not None else None
for k, v in z_obs_g.items()
}
loss = self._compute_losses_for_samples(
obs_0_single=obs_0_single,
z_obs_g_single=z_obs_g_single,
action_samples=action_samples,
)
# Select top-k
topk_idx = torch.argsort(loss)[:self.topk]
topk_actions = action_samples[topk_idx]
batch_losses.append(loss[topk_idx[0]].item())
# Update distribution, flooring sigma so it doesn't collapse.
mu[b] = topk_actions.mean(dim=0)
sigma[b] = topk_actions.std(dim=0).clamp(min=self.sigma_min)世界模型 rollout 侧也有真实接口。nano-world-model/src/planning/diffusion_world_model.py:125-140 显示,planner 调用的不是手写 dynamics,而是 dfot_sample,并把候选动作通过 model_kwargs={"action": act_chunk} 注入扩散采样:
python
chunk_latents = dfot_sample(
diffusion=self.diffusion,
model=self.model,
shape=shape,
context=cur_ctx,
n_context_frames=n_context,
model_kwargs={"action": act_chunk},
scheduling_mode=scheduling_mode,
num_sampling_steps=num_sampling_steps,
eta=eta,
history_stabilization_level=self.args.experiment.diffusion.history_stabilization_level,
) # [B, total_frames, C_lat, H_lat, W_lat]
# Keep only the newly generated frames (skip context)
new_latents = chunk_latents[:, n_context : n_context + chunk_len]官方 planning 文档中,planning.horizon 默认 5,cem.num_samples 默认 100,cem.topk 默认 10,cem.opt_steps 默认 30;in-the-loop rollout 通常用较少 DDIM steps,比如 20,因为 planner 每轮要评估大量候选。PushT 使用 dataset goals 更合适,因为随机目标在 5 planner steps 内通常不可达;Point Maze 和 Wall 可以使用 random state goals。