目录
[1.6 HTTP 请求(Request)](#1.6 HTTP 请求(Request))
[1.6.1 认识 URL](#1.6.1 认识 URL)
[URL 基本格式](#URL 基本格式)
[②要访问的服务器的 IP 地址或者域名:127.0.0.1 和 www.baidu.com](#②要访问的服务器的 IP 地址或者域名:127.0.0.1 和 www.baidu.com)
[④带有层次结构的路径:/java113 和 /web](#④带有层次结构的路径:/java113 和 /web)
[⑤查询字符串(Query String):?characterEncoding=utf8&useSSL=false](#⑤查询字符串(Query String):?characterEncoding=utf8&useSSL=false)
[关于 URL encode](#关于 URL encode)
[1.6.2 认识"方法"(method)](#1.6.2 认识“方法”(method))
[1.GET 方法](#1.GET 方法)
[使用 Fiddler 观察 GET 请求](#使用 Fiddler 观察 GET 请求)
[GET 请求的特点](#GET 请求的特点)
[2.POST 方法](#2.POST 方法)
[使用 Fiddler 观察 POST 方法](#使用 Fiddler 观察 POST 方法)
[POST 请求的特点](#POST 请求的特点)
[经典面试题GET 和 POST 的区别](#[经典面试题]GET 和 POST 的区别)
[3.GET 请求通常建议设计成 幂等的,而 POST 无要求](#3.GET 请求通常建议设计成 幂等的,而 POST 无要求)
[网上有些资料对于 GET 和 POST 的说法有待商榷~~](#网上有些资料对于 GET 和 POST 的说法有待商榷~~)
[1.POST 比 GET 更安全](#1.POST 比 GET 更安全)
[2.GET 传输数据有长度限制](#2.GET 传输数据有长度限制)
[3.GET 只能传输文本,POST 可以传输二进制](#3.GET 只能传输文本,POST 可以传输二进制)
书接上文:7.网络原理- HTTP/HTTPS(第一弹)~~
1.6 HTTP 请求(Request)
1.6.1 认识 URL
URL 基本格式
平时我们俗称的"网址"其实就是说的 URL(Uniform Resource Locator 统一资源定位符),用来描述网络上的唯一资源的位置的
比如像我们之前学习MySQL的时候接触到的 JDBC,创建 DataSource 时就需要设置 url、设置 user、设置 password......
而 MySQL 就是一个"客户端-服务器"结构的程序,存储数据的本体是在服务器,也属于一个网络资源~~
而 JDBC 的 URL 大概是这样的:
jdbc:mysql://127.0.0:3306/java113?characterEncoding=utf8&useSSL=false我们逐步拆分讲解:
①协议名称:jdbc:mysql://
因为我们当前谈到的 URL,不是 HTTP 专属的概念,而是可以给各种协议提供支持的~~是网络中通用的概念
在 JDBC 中就叫:jdbc:mysql
如果你连的不是MySQL,你连的是 Oracle,那就叫:jdbc:oracle
如果你连的是 SQLite,那就叫:jdbc:sqlite
如果你用的是 HTTP,那就叫:http:
如果你用的是 HTTPS,那就叫:https
总之就是表示当前是以哪个协议使用的~~
比如我们现在打开百度搜索"不孕不育",那么就能看到此时协议名称就变成 https 了👇
观察协议名称的变化
javahttps://www.baidu.com/s?wd=%E4%B8%8D%E5%AD%95%E4%B8%8D%E8%82%B2&rsv_spt=1&rsv_iqid=0xdcfaf39600163c77&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb_enter&rsv_sug3=13&rsv_sug1=7&rsv_sug7=101&rsv_btype=i&inputT=1827&rsv_sug4=1827&rsv_sug=1②要访问的服务器的 IP 地址或者域名:127.0.0.1 和 www.baidu.com
每一台网络设备都会有自己的 IP 地址,但这 IP 地址是由一串数构成的,对于咱们记忆来说不太方便,不像英文单词那样朗朗上口,所以咱们就想了个办法,用一串单词来代表 IP 地址,这样我们记域名就行了
而且域名和 IP 可以相互转换,这个过程是通过 DNS 域名解析系统来完成的(DNS 既是一套系统,也是一种应用层协议)
③端口号:3306
区分哪个应用程序,在 Java EE:5.网络原理-初识 有对端口号的解释,每个程序使用网络的时候都会关联一个空闲的端口号,大家自行查看,这里就不赘述了
那么为什么第二个在百度中查询时的网址没有端口号??是不需要嘛??
javahttps://www.baidu.com/s?wd=%E4%B8%8D%E5%AD%95%E4%B8%8D%E8%82%B2&rsv_spt=1&rsv_iqid=0xdcfaf39600163c77&issp=1&f=8&rsv_bp=1&rsv_idx=2&ie=utf-8&tn=baiduhome_pg&rsv_enter=1&rsv_dl=tb_enter&rsv_sug3=13&rsv_sug1=7&rsv_sug7=101&rsv_btype=i&inputT=1827&rsv_sug4=1827&rsv_sug=1不是不需要,而是没写的时候,浏览器会自动添加一个默认的端口号,这个端口号取决于协议是啥~
http=>80
https=>443
这个是访问远端服务器的那个端口,不是浏览器自身的"客户端的端口"
像我们之前讲过五元组:源端口、源IP、目的端口、目的IP、协议类型
这里就属于目的 IP 和目的端口,此时我们站在客户端的视角,我们输入的域名:www.baidu.com 就是服务器的 IP(目的 IP),后面的端口就是目的端口,而我们浏览器自身所在主机的 IP 和自身在它这次通信中系统分配的端口,我们在这个地方是见不到的~~
答疑:为啥 Linux 也有这样的内容??
因为网络,这个东西和操作系统是无关的~~
正如 Windows 主机也能访问 Linux 服务器,比如 搜狗、飞书、CCtalk 服务器都是 Linux~~
Windows 和 Linux 是不同的系统,其实是同一套网络规则,遵守相同的网络协议~~
④带有层次结构的路径:/java113 和 /web
因为我们想要访问的是,某个主机上某个程序管理的某个资源~~
通过 IP 确定了主机,通过 端口 确定了程序,接下来就需要确定 资源~~
这个资源可以是你硬盘上的文件,也可以是虚拟的资源(通过一段代码逻辑来生成的数据)
每一层就相当于目录,目录里面还可以有子目录~~
比如说我们在去 B 站随便找一个带层次的👇
javahttps://www.bilibili.com/video/BV1XECzYLEqt/?spm_id_from=333.788.videopod.episodes&vd_source=98fd26fb3e8a5c7d43580e62ed5f2182&p=5在这个 URL 里:
www.bilibili.com 就是域名
/video/BV1XECzYLEqt/ 就是路径了
其中 video 就相当于一个目录一样,然后 video 里面有一个 BV1XECzYLEqt 这个 bilibili 号,这个bilibili 号就属于 video 目录下的一个具体资源了~~
因此我们可以根据需要灵活定义任意的层次结构,对提供的资源进行分类组织~~
⑤查询字符串(Query String):?characterEncoding=utf8&useSSL=false
通过前面一段已经描述了唯一性,那后面是干啥的呢?
其实后面 ? 后面的部分叫做 查询字符串,对要访问的资源补充说明
也是键值对结构,键值对之间使用 & 分割,键和值之间使用 = 分割
此处键值对能咋写,都是程序员自定义的,你想咋写就咋写~~
?这个东西可有可无~~
比如 👇就没有~~
javahttps://www.baidu.com/
打个比方捋一下~~
比如我改行去卖熏肉大饼~~
我在陕科大六餐厅的18号位置盘了一个档口,菜单如下:
熏肉大饼:猪肉熏肉大饼、牛肉熏肉大饼、鸡肉熏肉大饼
粥:八宝粥、皮蛋瘦肉粥
那么点餐的过程就类似于:
javahttps://陕科大六餐厅:18/熏肉大饼/猪肉的熏肉大饼?葱=少放&香菜=不要&辣椒=微辣
上述我们介绍的是 URL 的常见情况,其实 URL 还有完整版的版本
这里多了几个信息:
⑥登录认证信息
现在一般就直接搞个登录页面了,所以现在的登录认证不会写到 URL 里
⑦片段标识符
区分当前这个页面的哪个部分~~
现在也有,但也不是很多了~~
带片段标识符的一般文档类网址会有,下面给大家找一下瞅一瞅👇
了解片段标识符
我们发现在切换标题的时候,片段标识符也会随之改变,用来区分页面的每一个部分
这个东西现在虽然有,但是不是很多见,以后开发中不一定能遇到这种东西,有个印象就行了~~
类似 https://music.163.com/#/discover/playlist 这里的 #后面也是片段标识符,有些网站会借助片段标识符实现路径效果~~
关于 URL encode
像 / ?:# = ......等这样的字符,已经被 URL 当作特殊意义理解了,因此这些字符不能随意出现
所以,如果某个参数中需要带有这些字符,就必须先对特殊字符进行转义
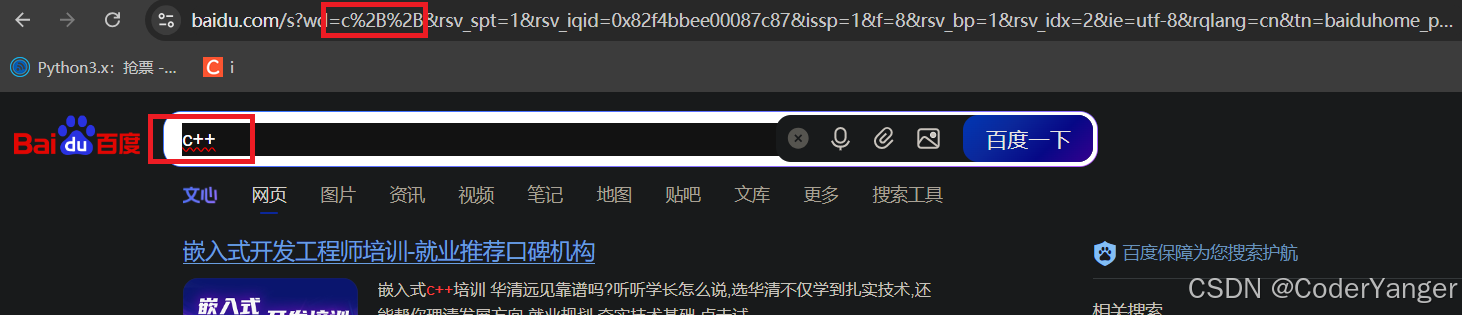
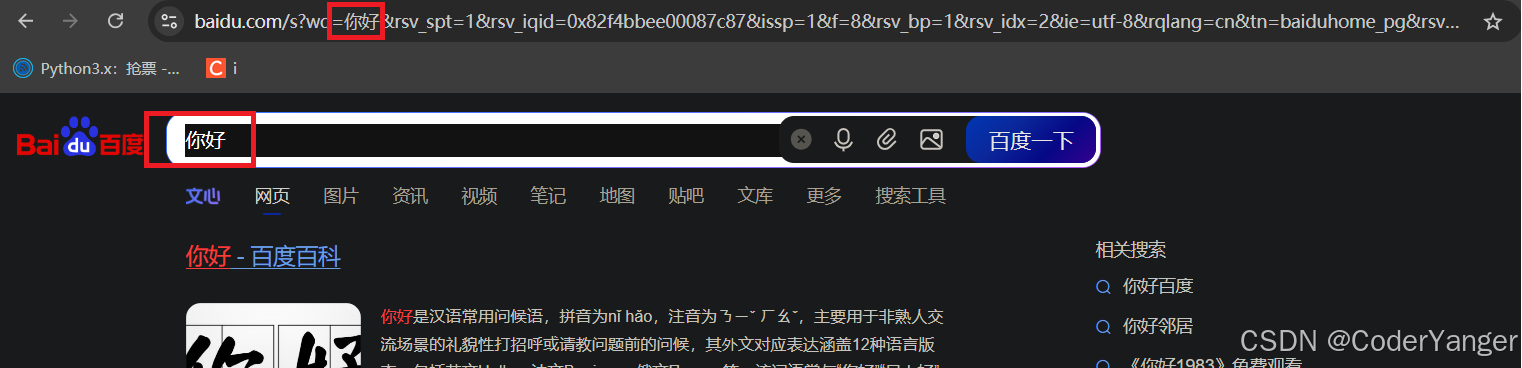
上面例子中我们发现,搜索 abc 和 你好 的时候,都是不变的,但是搜索 c++ 的时候就变成了 c%2B%2B,这个过程中,+ 就被转义成了 %2B
其实转义操作,不仅仅是标点符号,对于中文等其他非英语系的文字,也是需要转义的,只不过很多浏览器为了用户看起来方便,显示的时候显示转义之前的
实际上,通过抓包就能看到,是已经转义的数据👇
"你好"被转义
通过上述视频我们发现,"你好"被转义成了"%E4%BD%A0%E5%A5%BD"
其实这里的转义是非常非常重要的,如果没有进行转义,就可能会使这里的请求失败~~
闲聊:
之前比特汤老湿在搜狗的时候,做了一个"index 页面"功能~~
本来,这个页面一天的收益是 40w rmb,但是这个新版本上线之后,收益直接减半20w
这个事情直到2周之后才发现~~
答疑:
Q1:扣工资了吗??年终奖咋样??
实际上当时整个团队一天的收益是 1000w+
损失 20w 差不多就是 2% 左右的情况,还不算特别严重~~
超过 5% 甚至 10% 才是非常严重~~
最后年终奖还是拿到了,但是被大领导狠狠教育了~~
Q2:怎么这么赚钱??
百度那边的收益大约是这里的3倍左右~~
总之,要是秋招的时候你能发现有广告团队的,你就猛猛冲就行了!!这玩楞老挣钱了!!
但是这一般都不叫广告团队,差不多叫"商业"团队,有时候光凭广告都能养活一个公司~~
转义规则
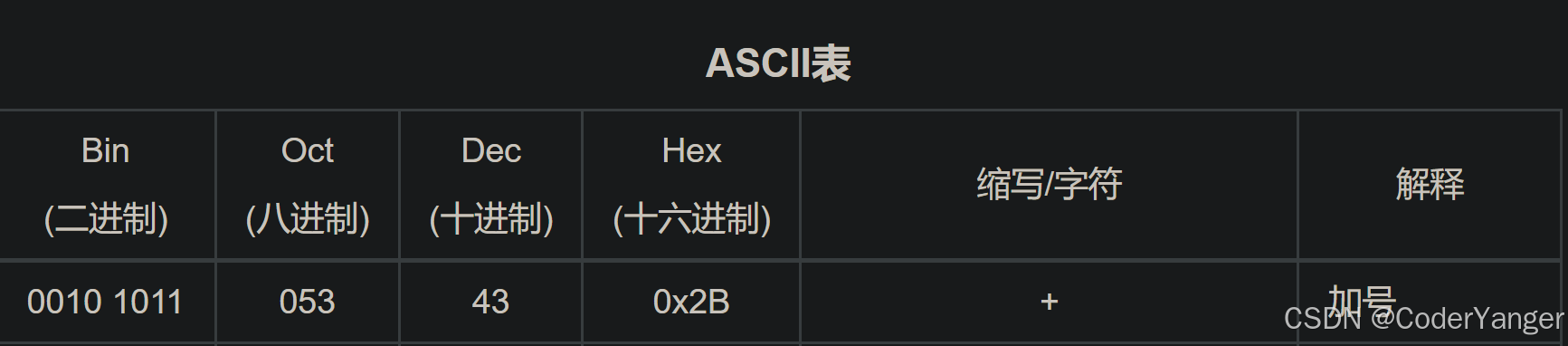
URL encode 把数据的二进制内容的每个字节取出来,用16进制表示,前面加上%即可
+转义成%2吧,是因为+的16进制正是2b👇
而"你好"转义成"%E4%BD%A0%E5%A5%BD",是因为"你好"的 UTF-8 编码是这样的格式
答疑
Q1:写代码按照code那个机制写就可以了??
我们都是会有一些现成的方法去直接调用的
比如前端去构造一个 http 请求,涉及到这种 中文,就可以调用 js 提供的 urlencode 方法来给它转一下
Java 服务器收到请求之后,读取到参数,也需要调用一个方法给它 decode 一下
只不过在我们开发中,我们使用一些 Spring 这一套,decode 一般已经自动完成了
要是前端写的话就得自己写了,换句话说,真正写代码,不一定真的手动来调用,我们知道这个东西就行了~~
Q2:当时是前端的?
当时没有专门的前端,前端的活后端就客串了
因为当时前端的代码都很简单,后端顺手就搞了,所以就勉为其难叫全栈工程师了~~
其实主要工作还是在后端~~



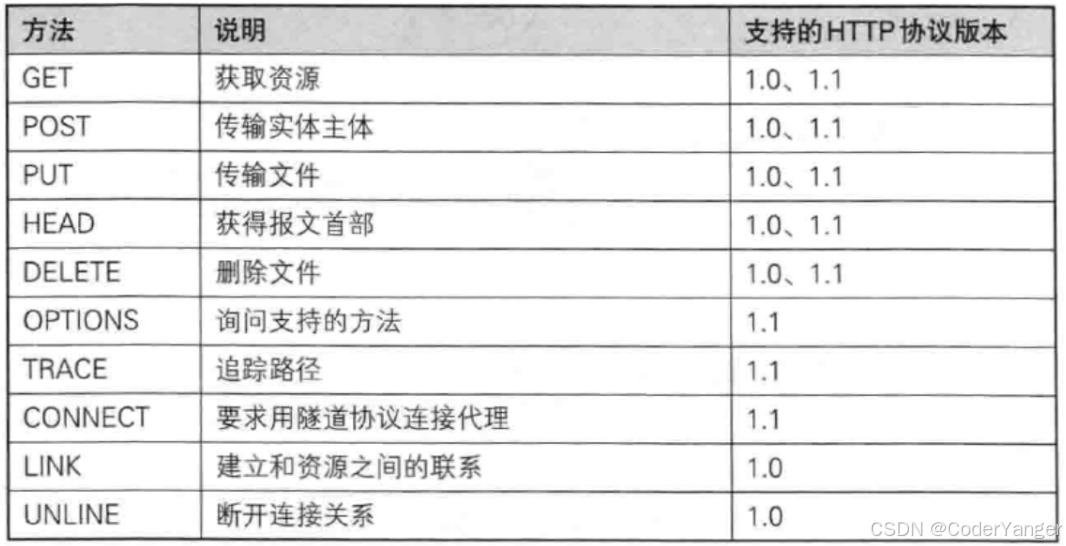
1.6.2 认识"方法"(method)
这次请求要干啥~~
虽然有这么多方法,但其实我们重点只需要掌握 GET 和 POST 这两个就行了
再往多了说,我们最多再掌握 PUT 和 DELETE ,这四个就足够了~~
正如东晋的谢灵运说过的:
天下文才十斗,曹子建独占八斗,我占一斗,天下人共分一斗~~=>才高八斗典故的由来(曹子建就是曹植)
而这里就相当于:
天下的方法有十斗,GET 独占八斗,POST 占一斗,剩下的方法共分一斗~~
所以这里掌握 GET 和 POST 就差不多了,也没想的那么难~~
在我们学习的时候很多学科都是不分家的~~
但是在 GET 和 POST 这两个最常见的请求中,从语义上来说~~
实际开发中,不一定会严格按照语义来进行区分~~
也就是说你用 GET 也可以给服务器传数据,你使用 POST 也可以给服务器获取数据~~
程序员实际实现的时候,可以自行灵活掌控的~~
1.获取 html、获取 css、获取 js 等操作,都是 get
2.登录、上传文件,就是典型的 post
1.GET 方法
GET 常用于获取服务器上的某个资源
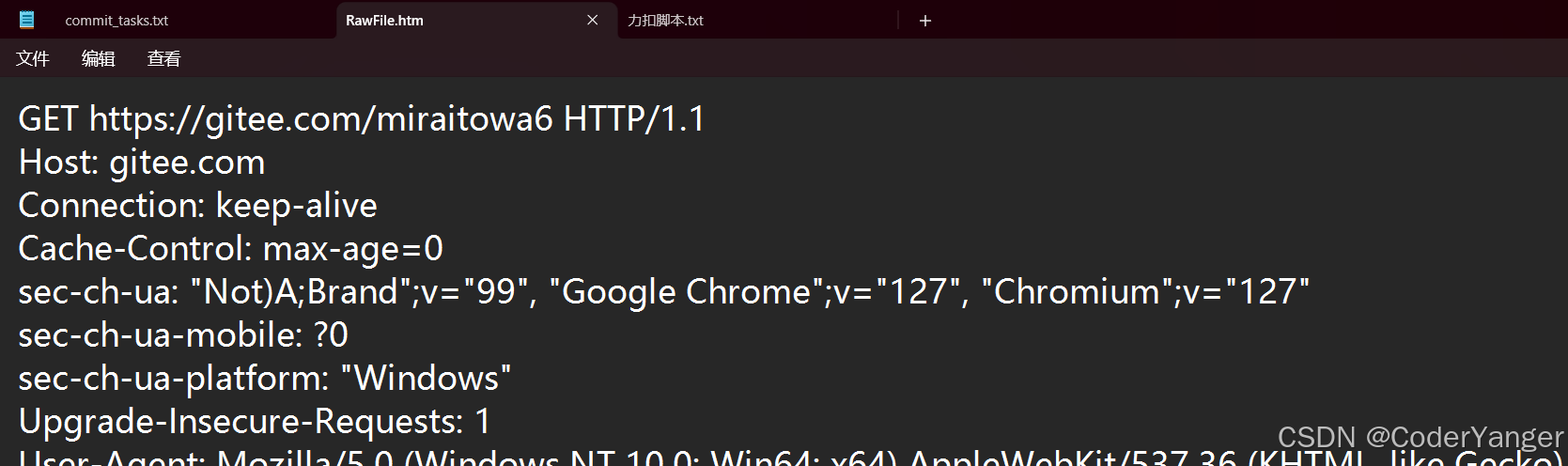
使用 Fiddler 观察 GET 请求
我们使用 Fiddler 抓几个 GET
那怎么抓 CSS、JS 呢??
强制刷新:Ctrl+F5~~
普通刷新:F5,只是重新访问服务器
而强制刷新,能够忽略本地缓存吗,所有资源都重新从服务器获取~~
浏览器的缓存机制:浏览器从服务器/通过网络加载网页(CPU最快,然后是内存、硬盘、网络)
通常情况下,从网络加载数据比硬盘加载要慢(当然,如果你充钱,用万兆网卡除外~~)
而浏览器为了加快访问页面的速度,就会把页面依赖的一些 静态资源(css、js、图片、字体、mp3......)这些内容缓存到硬盘上
这样,只需要第一次访问服务器,需要加载这么多东西,后续再访问,就不必重新加载~~
上述视频演示中,我们能够发现,只是普通刷新,只能得到一个蓝色的网页,但是我们强制刷新之后,就能抓到很多,其中紫色的是 css、绿色的是 js~~
答疑
Q1:这些不是还有 CDN 服务器吗??
CDN 也是通过网络加载的呀
是比直接访问公司的机房快
但是不如访问本地硬盘的~~
Q2:啥是 CDN??
比如说我的浏览器在阜新,人家搜狗的服务器在北京(大兴机房),此时,如果我的请求去访问北京的大兴机房,肯定是要消耗一个比较多的时间,物理上就有这么一个距离
为了加快这个速度咋办??
于是搜狗就在运营商那边租了一个 CDN 服务器,而运营商提供的这个 CDN 服务器,在全国各地都有~~就可以把那些 CSS、JS 等一些静态资源,提前放到这个 CDN 服务器里,后续我再访问的时候就不需要再去北京访问了,我就直接在阜新本地访问这个 CDN 资源就可以了~~
即使如此,就算我访问阜新本地的服务器,肯定还是不如我直接读硬盘来的快~~
Q3:那是不是网络在国外更慢~~
那肯定的呀,你访问 Gitee 肯定比访问 GitHub 快啊,那 GitHub 三天两头都可能用不了,都是正常的~~
GET 请求的特点
GET 请求一般都是没有 body 的,如果需要通过 GET 给服务器发送一些数据,都是通过 query string 给传递过去的~~
比如我们随便点个蓝色的、绿色的和紫色的都能发现没有 body👇
GET 请求没有 body
简单总结一下 GET 请求的特点:
①首行的第一部分为 GET
②URL 的 query string 可以为空,也可以不为空
③header 部分有若干个键值对结构
④body 部分为空
2.POST 方法
POST 方法常用于提交用户输入的数据给服务器(比如登录页面)
使用 Fiddler 观察 POST 方法
之前我们抓了一个登录场景的 POST,下面我抓一下更换头像、上传头像、上传图片的这种 POST 👇
上传图片时 Fiddler 抓到的 POST
上述过程中我们后面看到的这一堆👇
这些body内容就是我们刚才景甜小姐姐图片的数据~~
对于 POST 来说,两个典型的场景:
1.登录
2.上传=> 请求带有正文的,正文就是保存了当前上传的数据的内容
上述请求中,图片本身是二进制,通过特殊方式进行转码(base64 编码,把二进制转为文本),这样就能放到 URL 的 body 里面来传输到服务器里面去了
其实 body 也是可以直接填 二进制数据~~
但是有些程序员在写的时候就会转码,有的就不转~~
POST 请求的特点
简单总结一下:
①首行的第一部分为 POST
②URL 的 query string 一般为空(也可以不为空)
③header 部分有若干个键值对结构
④body 部分一般不为空,body 内的数据格式通过 header 中的 Content-Type 指定,body 的长度有 header 中的 Content-Length 指定
经典面试题GET 和 POST 的区别
面试中被谈到了,首先抛出结论:
GET 和 POST 没有本质区别,经常是能够混着用的
从使用方法习惯上来说,主要是两个方面的区别~~
1.语义上的区别
GET 一般用于获取数据,POST 一般用于提交数据
语义上可以混着用~~
2.携带数据的方式
GET 的 body 一般为空,需要传递的数据通过 query string 传递
POST 的 query string 一般为空,需要传递的数据通过 body 传递
但其实二者也可以混着用:
POST 也是可以带有 query string(还是有一些的)
GET 理论上也可以带 body(更少见)
答疑
Q1:POST 不是 params 吗??
params 可以放到 query string 中,也可以放到 body 中
Q2:go 的中国市场大吗??
呈现逐渐增长的趋势吧~~但目前肯定还是不如 Java 的
很多公司都会使用 go 对 Java 的项目重构~~
就是因为 Java 太重,太啰嗦,框架套框架,模式罗模式,哪怕再简单的功能,也要考虑一大堆有的没的东西~~
而 go 不管那么多,就很轻量、简洁~~
Q3:但是目前一般只有大公司才用 Go
只能说呈现上升趋势,新的创业公司不少用 Go 的~~
其他区别(了解即可)
3.GET 请求通常建议设计成 幂等的,而 POST 无要求
这个是 HTTP 标准文档给的建议,但是只是建议,不是强制要求
幂等:请求是一定的,得到的响应也是一定的~~
比如说今天给羊吃草,明天就能给你挤出奶,天天吃草,第二天就天天都能挤出奶,每天吃草都能挤出奶,这就是幂等的
但要是说今天羊吃草,明天挤出奶,明天再吃草,后天就不挤出奶了,挤出"翔"了,那就不是幂等的了~~
这个是否幂等,也是我们服务器开发中需要考虑到的一个环节~~
尤其是像支付的这样的场景,通常都要考虑幂等性,防止重复操作而产生二次扣款这样的恶性Bug~~
答疑:加载网站首页就需要幂等吗??
这个一般不需要,比如说你打开B站,首页里的视频是一个样子,你刷新一下,首页里的视频就变成别的了,这就不是幂等的~~
4.缓存问题
GET 设计成 幂等 了,就可以允许 GET 请求的结果被缓存
POST 由于不要求 幂等,经常是不 幂等 的,就认为不能被缓存
但实际上现在 GET 不幂等的情况太常见了~~
现在的互联网产品,都讲究"个性化推荐",这就很难做到 幂等 了,因为每次推荐的结果都不一样嘛~~
网上有些资料对于 GET 和 POST 的说法有待商榷~~
1.POST 比 GET 更安全
考虑在登录场景,需要输入用户名和密码
GET 就会把用户名和密码放到 URL 的 query string 中,就会显示在浏览器地址栏上了
类似于👇
https://gitee.com/miraitowa6?username=CoderYanger&password=xxx看上去肯定不安全,但其实安不安全不是说你放到地址栏上面就不安全
保证安全,关键是"加密传输"
而 POST 传输如果不加密,那黑客随便抓个包,也就看到了~~
所以只要是明文传输,都谈不上安全~~
2.GET 传输数据有长度限制
这个是上古时期,还是 IE 浏览器的年代,当时 IE6(Windows xp) 浏览器对于 URL 的长度是有限制的
此时传输的数据太多,可能就会被截断~~
但是现在的主流浏览器/服务器 早都没有这样的限制了
现在比较长的 URL 很多时候也能见到~~
课件内容
网上有些资料上描述:get 请求长度最多为 1024kb 这样的说法是错误的
HTTP 协议由 RFC 2616 标准定义,标准原文中明确说明:"Hypertext Transfer Protocol -- HTTP/1.1,"does not specify any reuirement for URL length
没有对 URL 的长度有任何的限制
实际 URL 的长度取决于浏览器的实现和 HTTP 服务器端的实现,在浏览器端,不同的浏览器最大长度是不同的,但是现代浏览器支持的长度一般都很长;在服务器端,一般这个长度是可以配置的
3.GET 只能传输文本,POST 可以传输二进制
也不能完全说错的,GET 确实 URL 只能放文本,但是却可以把二进制通过 base64 转码成文本的(这个肯定完全可行)
另一方面,GET 也不是完全就不能带 body(只是有些客户端/服务器不支持而已)
答疑
Q1:URL不是get和post都有的吗?为什么get有长度限制,而post没有长度限制呢?
看你数据部分放哪里~~
GET 数据放到 url query string
要传输的数据很多,url就会很长
而post 放到 body 里,url 就可以比较短了~~
Q2:Body有长度限制吗?
url / body 在标准文档中都是没有明确限制长度的~~
但是浏览器的实现、服务器的实现有没有限制,不好说~~
至少可以认为主流的浏览器和服务器,都没有限制 / 即使有,也是非常大的数值,完全够用~~
Q3:面试说错就寄了
相比于知识点掌握怎样
其实面试官更关心你会不会深入思考~~
而不是说大家都那么说你也就那么说了~~
3.其他方法
PUT
DELETE
我们用到的不是很多,主要是实现 Restful 风格的 API 的时候,会用到~~
啥是 Restful 风格的 API??谈不上规范,只是设计服务器接口的一种"习惯"~~
新增:POST
删除:DELETE
修改:PUT
查询:GET
这里的知识在学习到 Java EE 进阶的时候会给大家解释,内容有点多~~
答疑
Q1:感觉POST就可以干增删改三个操作了
其实这四个操作中的任何一个,都可以进行增删改查,完全取决于你代码咋写~~
比如你可以让 DELETE 进行增删改查,但这么写的话,就有点别扭~~
因为有专门的你不用,你写完大家理解的成本也高~~
Q2:它们不是函数吗?
这是写代码定义的,属于编写网站的基本操作~~
前端代码中,构造 HTTP 请求,选择使用哪个方法
后端代码中,处理 HTTP 请求,针对当前这个方法指定一些逻辑和行为
Q3:和重写差不多?
这个不是重写,跟重写区别还是蛮大的~~
阶段性小结
1.HTTP~~
|-----------------------|-----------------|
| 请求 | 响应 |
| 1.首行=方法+URL+版本号 | 1.首行=方法+URL+版本号 |
| 2.请求头:键值对 | 2.响应头:键值对 |
| 3.空行 | 3.空行 |
| 4.正文(GET一般没有,POST一般有) | 4.正文(基本都有~~) |2.URL 的格式:
协议名://IP地址(域名):端口号/路径(可能有层次结构)?查询字符串
IP地址:确认哪一台主机
端口号:确认是主机上的哪一个程序
路径:程序中管理的哪一个资源
查询字符串:对访问的字符串作进一步的补充说明
3.URL encode
由于查询字符串中的键值对是由程序员自定义的
特殊字符可能会产生歧义,而发生错误,因此需要对查询字符串的内容进行转码
转码规则:2进制内容用16进制表示,并且前面加上一个%
4.方法
GET(最常用)
POST(其次常用)
PUT(Restful API 设计风格才涉及)
DELETE(Restful API 设计风格才涉及)
闲聊:我们后面学习 Spring,基于 Spring MVC 写的服务器程序,正是一个 HTTP 的服务器~~
5.GET 和 POST 区别
1)语义
2)GET 经常把数据放到 URL 的 query string 中,POST 经常把数据放到 body 中