一次真实的编码会话,token 总量可能轻松冲到 400K 甚至更高------可模型的上下文窗口只有 200K。Claude Code 是怎么把"无限增长的对话"塞进"固定大小的窗口",还能一路保持思路连贯的?
答案不是"撑满了就总结一下"这么简单。它背后是一条 5 级渐进式压缩流水线:最便宜、最无损的手段先上,最贵、最有损的手段压到最后才用。本文做一次源码级拆解。
文章内容:
- Claude Code 用 5 层手段 管理上下文,核心哲学是渐进式压缩:cheapest first, heaviest last。
- 前 4 层(工具结果落盘、历史裁剪、微压缩、上下文折叠)几乎零成本、且基本无损/可回滚。
- 只有最后一层 AutoCompact 会真正调用一次 LLM 做摘要------这一层才是"有损不可逆"的 ,而绝大多数对话根本走不到这里。
- "有损不可逆"的根本局限,靠两件事兜底:跨会话的记忆系统 (CLAUDE.md / auto memory)+ 完整保留原始对话的 transcript。
- 整条压缩流水线位于源码
src/services/compact/,约 3,960 行 TypeScript / 5 个文件。
适合谁读:用 Claude Code 但好奇它"内部怎么转"的开发者;做 Agent / LLM 应用、需要自己设计上下文工程的工程师。

一、先理解问题:窗口有限,对话无限
把上下文窗口想象成模型的工作台面。对一个 200K token 的模型来说,这块台面在你发第一条消息之前就已经被占掉一部分了:
- 系统提示词 + 工具定义:约 20--25K token,是雷打不动的固定开销。
- 系统提醒(system reminders) :每轮再加 200--2,000 token,视情况而定。
- 剩下大约 175K token 才是"对话历史"能用的空间。
问题在于:历史会无限增长,窗口却不会 。你读一个 3,000 行的文件、跑几条 grep、让它改几轮代码------每次工具调用都往台面上堆 2K--8K token。不处理的话,迟早撑爆。
更微妙的是:撑爆之前,质量就已经开始下滑了 。这和电脑内存很像------你可以把内存用到 95%,但最后那点空间会被换页、GC、系统开销吃掉,程序反而卡死。LLM 同理:那块"空着"的上下文不是浪费,它是模型"思考"的地方。窗口越满,模型用来规划、权衡、评估代码改动的余地就越小。
所以 Claude Code 的目标不是"用满",而是在台面变乱的过程中持续清理,始终给推理留出余量。

二、核心设计哲学:渐进式压缩
整条流水线只有一句话原则:
最便宜的手段先上,最重的手段最后用。 (cheapest first, heaviest last)
每往下一层,要么消耗更多算力,要么丢掉更多细节。于是系统能做到:"能用零成本手段解决的,绝不动用花钱又有损的 LLM 摘要。" 实测结论也印证了这一点:绝大多数对话根本走不到最后一层。
下面是完整的 5 级全景。
scss
消息历史持续增长
L1 · 工具结果预算单块 >50K 字符 → 落盘 + 2KB 预览成本:零 · 可恢复
L2 · 历史裁剪 Snip回收陈旧的对话脚手架成本:零
L3 · 微压缩 MicroCompact回收旧工具输出 · 时间型/缓存型双路径成本:零 API 调用
L4 · 上下文折叠 Context Collapse~90% 触发 · 投影式折叠 · 可回滚成本:零 · 非破坏性
L5 · 自动压缩 AutoCompact分叉子 Agent 生成 LLM 摘要成本:一次 API 调用 · 不可逆
组装最终 API 请求三、逐层拆解
L1 · 工具结果预算(Tool Result Budget)
问题:某个工具一次就吐出一个巨大的内容块------比如读了个几 MB 的文件、跑了条刷屏的命令。
做法 :当单个工具结果超过阈值(DEFAULT_MAX_RESULT_SIZE_CHARS,约 50,000 字符 )时,Claude Code 不会粗暴截断 ,而是把完整输出落盘 ,只在上下文里留一个约 2KB 的预览:
lua
<persisted-output>
Output too large (2.3 MB). Full output saved to:
/tmp/.claude/session-xxx/tool-results/toolu_abc123.txt
Preview (first 2.0 KB):
[前 2000 字节内容] ...
</persisted-output>为什么是"落盘"而不是"截断"? 截断意味着永久丢失 ------万一 bug 恰好藏在第 500 行呢?落盘后,模型如果后续真需要那段内容,可以用 Read 工具从磁盘把完整文件取回来。2KB 预览则刚好够它判断"要不要去取"。
✍️ 这是对很多笔记里"Snip 就是直接截断"说法的修正:第一层的本质是可恢复的落盘,而不是丢弃。这恰恰呼应了整套系统"尽量不做不可逆操作"的取向。
L2 · 历史裁剪(History Snip)
可以把这一层理解成对话脚手架的垃圾回收。会话里那些重复的 assistant 包装、冗余的记账信息、早就不影响下一步决策的旧片段,会在更重的压缩启动之前先被裁掉。它同样是零成本,且只动"明显没用"的部分。
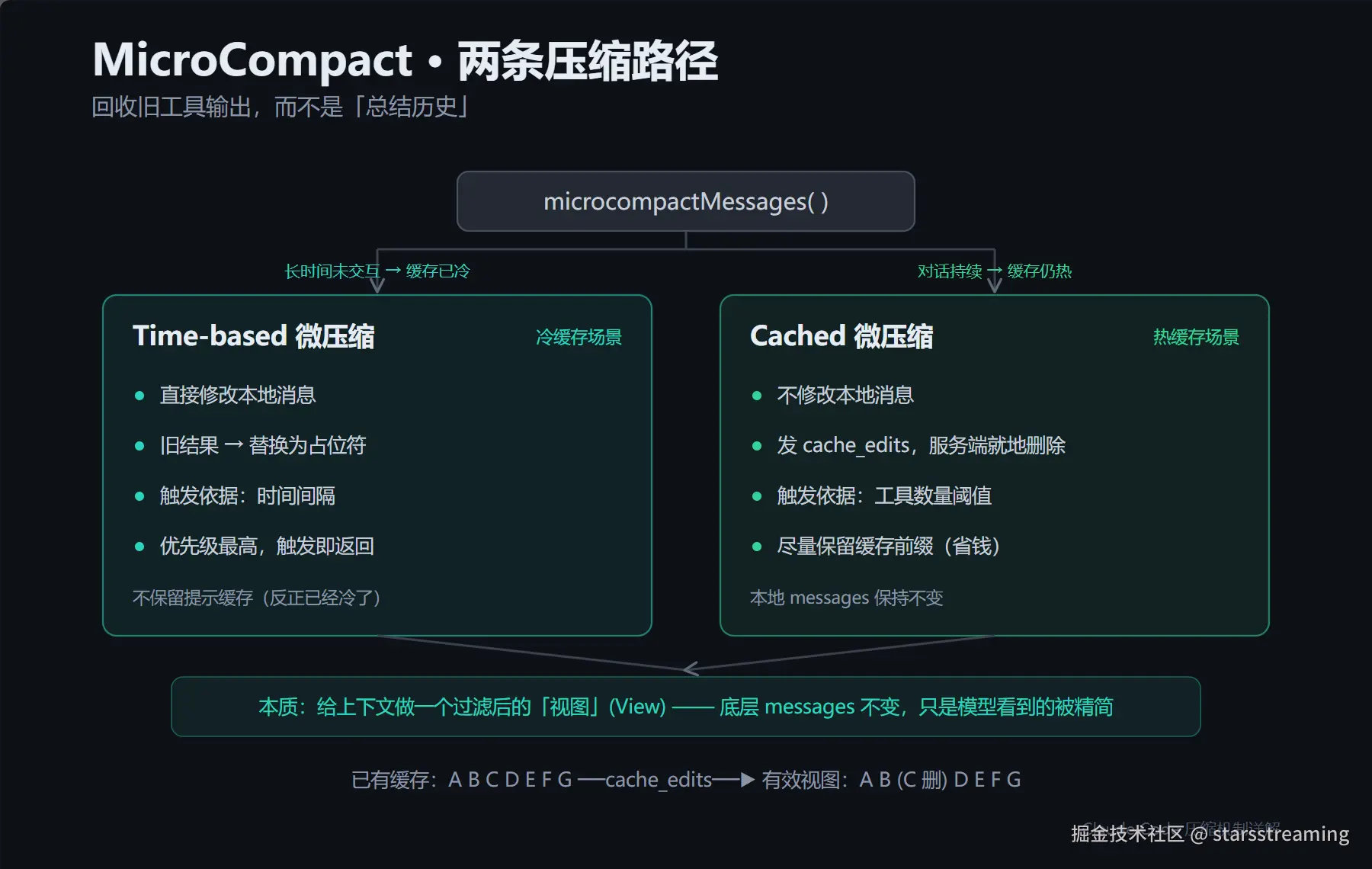
L3 · 微压缩(MicroCompact)------ 回收旧工具输出
这是最关键、也最精妙的一层。一句话定性:
MicroCompact 不是"总结历史",而是"对旧工具输出做垃圾回收"。
3.1 它专门清理哪些东西
微压缩只回收"旧工具调用返回的大块原始内容",因为这些内容有个共同点------丢了还能再拿回来:
| 工具类型 | 为什么适合清理 |
|---|---|
| Read | 文件之后可以重新读取 |
| Bash / Shell | 旧日志通常很大,而且可能已经过时 |
| Grep | 搜索结果可以重新生成 |
| Glob | 文件列表可以重新扫描 |
| WebSearch / WebFetch | 网页内容可以重新获取 |
| Edit / Write | 修改结果通常已经落到文件系统里 |
3.2 两条互斥的路径:时间型 vs 缓存型
微压缩内部分两条路,互斥,按场景择一:
scss
microcompactMessages()
|
+-------------+--------------+
| |
长时间未交互? 缓存仍然有效?
| |
是 是
| |
Time-based Microcompact Cached Microcompact
(直接改本地消息内容) (改用 cache_edits)
| |
冷缓存场景 热缓存场景| 对比项 | Time-based Microcompact | Cached Microcompact |
|---|---|---|
| 使用场景 | 长时间没继续对话,缓存大概率已过期 | 对话持续进行,缓存仍然有效 |
| 是否修改本地消息 | 修改 | 不修改 |
| 如何删除内容 | 把旧结果替换为固定占位符 | 给 API 发送 cache_edits |
| 是否保留提示缓存 | 不需要(缓存已经冷了) | 尽量保留缓存前缀 |
| 触发依据 | 时间间隔 | 工具数量阈值 |
| 优先级 | 最高,触发后直接返回 | 时间路径未触发时才执行 |
Cached 路径的巧思 :它不改本地消息,而是给服务端发一条 cache_edits 指令,让服务端在原缓存块里"就地标记删除" ,从而不破坏宝贵的缓存前缀:
css
已有缓存: A B C D E F G
↓ 发送 cache_edits:基于原缓存,把 C 标记为删除
有效视图: A B D E F G🧠 类比 :把它想成数据库里的视图(View) ------底层的消息数组(表)原封不动,但每次 API 请求看到的是一个被过滤、被精简后的"投影"。
3.3 一个容易踩坑的追问:cache 里到底还在不在?
Q:微压缩后,被标记删除的旧工具结果,cache 里还缓存着吗?
A:会暂时同时存在于"服务端原始缓存块"和"本地消息历史"里,但在模型当前使用的有效缓存视图中已被排除 ,不再占用上下文。一句话------cache 里仍包含它,但模型有效上下文不包含它。
| 所在位置 | 是否还在 |
|---|---|
Claude Code 本地 messages |
还在 |
| 本地会话记录 / transcript | 通常还在 |
| 服务端原始缓存块 | 很可能暂时还在,直到 TTL 过期 |
| 模型当前有效上下文 | 不在 |
| 后续请求的有效 token 统计 | 不再计入活动上下文 |
L4 · 上下文折叠(Context Collapse)------ 增量、可回滚
如果前几层还不够,进入折叠层。它的定位和"自动压缩"有本质区别:
Context Collapse 是持续、增量式的上下文管理;AutoCompact 是达到阈值后对整段会话的一次集中式重写。
折叠层最大的优点是非破坏性、可回滚 :原始消息从不删除 ,生成的摘要存放在一个独立的 collapse store ,由 projectView() 在请求时把摘要"叠加"到原始消息之上。换句话说,模型看到的是折叠后的视图,但底层数据还在------需要时能还原。
它大约在 ~90% 利用率 开始提交(commit), ~95% 进入更强的阻塞式处理。和自动压缩的完整对比:
| 对比项 | Context Collapse | AutoCompact(自动压缩) |
|---|---|---|
| 工作方式 | 持续、增量式管理 | 达到阈值后一次性执行 |
| 处理粒度 | 更细,逐步提交可保留信息 | 更粗,把旧上下文整体摘要化 |
| 触发阶段 | 约 90% 开始 commit,95% 进入阻塞处理 | 有效窗口剩约 13K token 时触发 |
| 是否调用模型 | 通常由独立 context agent 整理、提交 | 会调用模型生成摘要 |
| 对原消息的影响 | 维护独立的 committed log,逐步折叠活动上下文 | 直接用"摘要 + 保留的近期消息"替换旧消息 |
| 中断程度 | 偏增量、后台式整理 | 类似一次 stop-the-world 压缩 |
| 信息保留 | 倾向保存更细粒度的结构化信息 | 主要依赖摘要质量 |
| 能否与自动压缩并存 | --- | 开启 Collapse 后,主动 AutoCompact 被禁用 |
一句话记住差异:
- AutoCompact :以"对话段落"为压缩单位 → "上下文快满了,把过去整体总结一次。"
- Context Collapse :以"事实、决定、状态、产物"为提交单位 → "在上下文变满的过程中,持续把有价值的信息提交出去,再逐步折叠已处理的活动上下文。"
L5 · 自动压缩(AutoCompact)------ 唯一真正"有损"的一层
走到这里,才会真的调用一次 LLM 做摘要。这也是幻灯片上"有损不可逆"画框的那一层。
5.1 触发与阈值(以 200K 窗口为例)
- 保留约 20,000 token 给"写摘要"本身用;
- 保留约 13,000 token 作为缓冲------所以当有效窗口只剩约 13K 时触发;
- 另有 3,000 token 的手动压缩缓冲:只剩这么多时,新请求会被阻塞,提示你手动
/compact。

5.2 调用链:一张图看懂"该不该压、怎么压"
arduino
用户发一条消息
│
▼
主对话循环(query loop,⚠️ 推断)
│
▼
autoCompactIfNeeded(messages, ...) ← 总指挥
│
▼
先查熔断器:连续失败 ≥ 3 次? ──是──▶ 直接放弃(防死循环)
│否
▼
shouldAutoCompact(...) ← 只负责判断「该不该」
│ 一连串"直接返回 false"的守卫(递归 / 实验开关 / 功能未开)
│ 都过了 → 数 token → calculateTokenWarningState → 返回 true/false
▼
返回 false → 不压,结束
返回 true → 继续:
│
▼
trySessionMemoryCompaction(...) ← ① 优先用「会话记忆」压
│ 成功 → 清理 + 返回 wasCompacted:true
│ 失败 / 不可用 ↓
▼
compactConversation(...) ← ② 退而用传统 LLM 摘要
│ 成功 → 清理 + consecutiveFailures:0 + 返回
└ 抛错 → 失败次数 +1 + 返回 wasCompacted:false几个值得注意的设计:
- 熔断器(circuit breaker) :连续失败 3 次就停止再试,避免在异常情况下反复烧钱、卡死。
- 会话记忆优先:在真正花钱做完整摘要之前,先尝试用后台预先攒好的"会话记忆"来压------能省掉那次昂贵的模型调用。
- 摘要的提示词 强制保留三类信息:完成了什么、当前状态、做过的关键决策 。压缩后
messages只剩一条,但 Agent 知道"之前发生过什么",能接着干活。
5.3 还有一层"兜底中的兜底":反应式压缩(Reactive Compact)
再周密的估算也有失手的时候------某个工具结果意外巨大、多个系统提醒同时注入、token 估算偏低......一旦 API 直接返回 413(Prompt Too Long) ,Reactive Compact 会立刻触发:只保留最后 4 条消息、其余全部摘要 ,然后重试。一个 hasAttemptedReactiveCompact 守卫保证它只尝试一次,不会陷入重试死循环;若一次仍不够,错误才上抛给用户。
这一层的哲学很值得玩味:与其追求完美的 token 计数,不如接受估算的不精确,并提供一条稳健的恢复路径。
5.4 以及:手动 / Agent 主动压缩
除了自动触发,压缩也能被主动调用:你随时可以 /compact(还能附带指令,比如"重点保留认证相关的工作");Agent 自己也可能在即将切换到一个完全不同的任务 时,主动 compact 清空当前上下文,为新任务腾地方。
四、那个绕不开的问题:有损不可逆,怎么破?
回到最初的灵魂拷问。先把结论说清楚:这条流水线里,前四层基本都是无损或可回滚的 ------落盘可 Read 回来、折叠可还原、微压缩只是"视图"过滤。真正不可逆的,只有第 5 层那次 LLM 摘要。 系统的全部努力,就是让对话尽量止步于前几层,把"有损摘要"压到最少发生。
但只要它会发生,信息论上就一定有损耗。Claude Code 用两件事来兜底这条根本局限:
- 跨会话的记忆系统 :压缩管的是"当前会话的台面整洁度",而
CLAUDE.md/ auto memory 管的是"跨会话的长期知识"。每个会话从干净上下文开始,记忆文件在开头被读入;auto memory 还能让 Claude 根据你的纠正自动记笔记。两者配合,Agent 既不被当前对话淹没,又不丢失重要的长期信息。 - 完整的原始档案(transcript) :
.transcripts/里保存了压缩前的全部原始对话 。它是事后取证 / 回溯用的备份------Agent 平时不会主动去翻,但只要你需要,一切都在。
五、一个少有人提的隐患:注入指令会"穿透"压缩
这是整套设计里一个容易被忽视、却很值得警惕的点:压缩流水线对所有内容一视同仁。
摘要器(summarizer)会用同一条流水线处理"用户指令"和"工具结果"。如果攻击者在某个项目文件里埋了恶意指令,而模型恰好读了那个文件------这些指令会一起被卷进摘要 ,在压缩后与正常上下文再也无法区分 。那个让摘要质量很高的 <analysis> 草稿区,也会忠实地把注入指令一并保留下来。流水线里没有一个环节去区分"这是用户说的"还是"这是模型读到的文件里写的"。
换句话说:prompt injection 不仅能影响当前回答,还可能"固化"进被压缩后的长期上下文里。 做 Agent 安全的同学,这是个值得单独深挖的攻击面。
六、写在最后:从这套设计能学到什么
抛开 Claude Code 本身,这套压缩流水线其实是一份很好的上下文工程范本:
- 分层降级,便宜的先上。 不要一上来就动用最贵、最有损的手段;先穷尽零成本、可恢复的清理。
- 能可逆就别不可逆。 落盘而非截断、折叠而非删除、视图过滤而非物理移除------把"不可逆操作"压到最后、最少。
- 接受不完美,但准备好恢复路径。 与其追求完美的 token 估算,不如做好 413 兜底。这是工程上的成熟,而非妥协。
- 结构化地保留关键信息。 摘要强制保留"做了什么 / 当前状态 / 关键决策",而不是自由发挥------固定模板能显著降低"丢掉要紧细节"的概率。
- 压缩 ≠ 记忆。 会话内的整洁度和跨会话的长期知识,是两套互补的系统,别用一个去硬扛另一个的活。
想自己摸一遍?在真实会话里跑一次
/context,对照本文的阈值,看看 system prompt、tools、memory、messages 和那块 autocompact 缓冲各占多少 token------把"理论"和"实测"对上号,比只读源码更有体感。
附:技术坐标与说明
-
压缩流水线源码位于
src/services/compact/,约 3,960 行 TypeScript,横跨 5 个文件。 -
关键函数:
autoCompactIfNeeded/shouldAutoCompact/calculateTokenWarningState/trySessionMemoryCompaction/compactConversation/microcompactMessages/projectView。
