导语 :
最近在做 AI Agent 相关的业务时,我发现很多初中级开发同学对
Tool Use(工具调用)的理解还停留在"调个 API"的表层。大家往往觉得 AI 好像有了自我意识,能自己查股票、看天气。但作为开发者,我们必须清醒:AI 并没有自我意识,这一切都是一个精心设计的"错觉" 。那个在显卡里疯狂跑的 LLM,本质上还是个"成语接龙"游戏,它是被困在服务器里的"缸中大脑"。它看不见屏幕,摸不到键盘,更别提去操作物理世界了。
那么,一个只能预测下一个词的概率模型,是怎么突破物理限制去调用 API、读数据库的?今天,我们就通过一段真实的 Node.js 代码,把 Tool Use 的底层逻辑扒个底朝天!
一、 核心概念:LLM + Tools = Agent 的"认知植入"
在讲代码前,我们先建立一个核心认知:工具调用,本质上是把"函数"降维成了"语言" 。
大模型不懂什么是天气 API,也不懂 SQL 查询,但它听得懂自然语言。我们在配置 tools 时,其实是在做一件非常精妙的事------认知植入。我们通过 JSON Schema 这种约束格式,把复杂的软件接口函数翻译成 LLM 能理解的"说明书"。
当用户问"青岛啤酒的收盘价是多少"时,LLM 发现训练语料里没有这个实时数据,但它通过"认知植入"知道有个叫 get_closing_price 的工具。于是,它严格按照说明书,生成了一段"自然语言代码"(JSON 格式的参数),然后中断执行,把这段代码交还给我们的 Runtime(比如 Node.js)去真正执行。
记住这个公式:LLM 负责决策与翻译,Runtime 负责执行与反馈。
二、 痛点与场景:为什么我们需要 Tool Use?
在传统软件开发中,我们习惯了"硬编码"逻辑。但在 AI 时代,我们面临两个核心痛点:
- LLM 的知识存在滞后性与幻觉:你问它今天的茅台股价,它要么瞎编,要么告诉你它不知道。
- AI 无法与物理世界交互:它不能直接连你的 MySQL,也不能帮你发钉钉消息。
Tool Use 完美解决了这两个问题。 它让 LLM 退回到它最擅长的事情上------意图识别与逻辑推理 ,而把"脏活累活"(查库、调接口)交回给传统软件世界。这就形成了新旧范式的结合:AI 做大脑,传统代码做手脚。
三、 重难点剖析:代码背后的"三步走"设计
结合提供的代码,我们来剖析 Tool Use 中最核心的 3 个重难点。
重难点 1:JSON Schema 的"认知植入"艺术
设计者为什么这么写?
代码中定义了 tools 数组,里面包含了 name、description 和 parameters。这不是随便写的,这是给 LLM 的"操作手册"。如果描述不清晰,LLM 就会猜错参数。
如何攻克/理解?
把 description 写得像教小白一样具体。parameters 里的 required 字段是强约束,告诉 LLM 哪些参数是必须的,防止它生成残缺的调用指令。
一、一句话总结
JSON Schema 就是给 JSON 数据定规矩:规定数据长什么样、字段有没有、类型是什么,用来约束、校验大模型输出内容,防止格式乱套。
二、放到你 Tool Calling 代码里
你写的这一整块就是 JSON Schema:
js
运行
css
parameters: {
type: 'object',
properties: {
name: {
type: 'string',
description: '股票名称'
}
},
required: ['name']
}它干两件事:
- **给大模型阅读(最重要)**告诉 AI:
- 参数必须是一个对象
- 必须包含
name字段 - name 必须是字符串
- 不能随便多加其他字段
AI 会严格遵守这套规则来生成 arguments 里的 JSON 字符串,不会乱写字段、不会类型错乱。
- 服务端校验模型输出的 JSON 会被 API 自动校验,不符合 Schema 格式就直接拦截,保证拿到的数据一定合法。
三、如果没有 JSON Schema 会发生什么?
没有约束,AI 自由发挥,可能输出:
json
json
{"stock_name":"青岛啤酒"}你代码里取 .name 就会拿到 undefined,程序直接出错。
有了 Schema,AI 只能写 name,不能自己乱造字段。
四、对应整条链路
- 你编写 JSON Schema(参数规则)
- 大模型读取规则,严格按照结构生成 JSON 文本
- 文本放进
toolCall.function.arguments - 你用
JSON.parse()转成对象 - 安心取值,不用担心字段不存在、类型错误
五、通俗比喻
JSON Schema = 表格模板:规定必须有 "股票名称" 这一栏,而且只能填文字,不能填数字。AI 填表时只能照着模板填,不能自己新增栏目、乱填内容。
补充小知识点
- Schema 不止用于 Function Calling,也用于结构化输出(让 AI 强制返回固定格式 JSON);
properties定义字段结构,required定义必填项,二者共同构成 Schema 主体。
重难点 2: 意图识别 对话中断与"自言自语"的上下文管理
设计者为什么这么写?
AI 会停止和你的对话,转而开始自言自语(思考),它严格按照刚刚定义的那套说明书,去生成一段自然语言代码
注意代码中的 messages.push 逻辑。当 LLM 返回 tool_calls 时,它并没有直接回答用户,而是返回了一个包含 id、function.name 和 arguments 的对象。此时,对话被中断了。
如何攻克/理解?
这是新手最容易晕的地方。LLM 的 tool_calls 不是最终答案,而是执行请求。我们需要:
- 把 LLM 的
tool_calls原封不动地追加到messages中(role 为assistant)。 - 本地执行函数后,把结果追加到
messages中(role 为tool,且必须带上tool_call_id进行关联)。 - 再次调用 LLM,让它根据工具返回的结果,生成最终的人类可读回复。
重难点 3:Runtime 的"桥梁"作用
设计者为什么这么写?
代码里的 get_closing_price 是一个纯传统的 JS 函数。LLM 绝对不可能直接执行它。
如何攻克/理解?
开发者必须充当"中间人"。LLM 吐出 JSON 字符串(toolCall.function.arguments),我们需要用 JSON.parse 解析,然后手动路由 到对应的本地函数。执行完后,再把结果喂回给 LLM。 JSON.parse(字符串):把JSON 格式的文本字符串,转换成 JavaScript 对象。
放到你这段代码里
js
运行
matlab
// toolCall.function.arguments 的值是字符串:'{"name":"青岛啤酒"}'
const args = JSON.parse(toolCall.function.arguments)- 转换前:只是一段文字,不能直接点
.name取值 - 转换后:变成 JS 对象
{ name: "青岛啤酒" },就可以写args.name
四、 核心交互时序图
为了让大家更直观地理解这个"缸中大脑"是怎么工作的,我画了下面这张时序图:
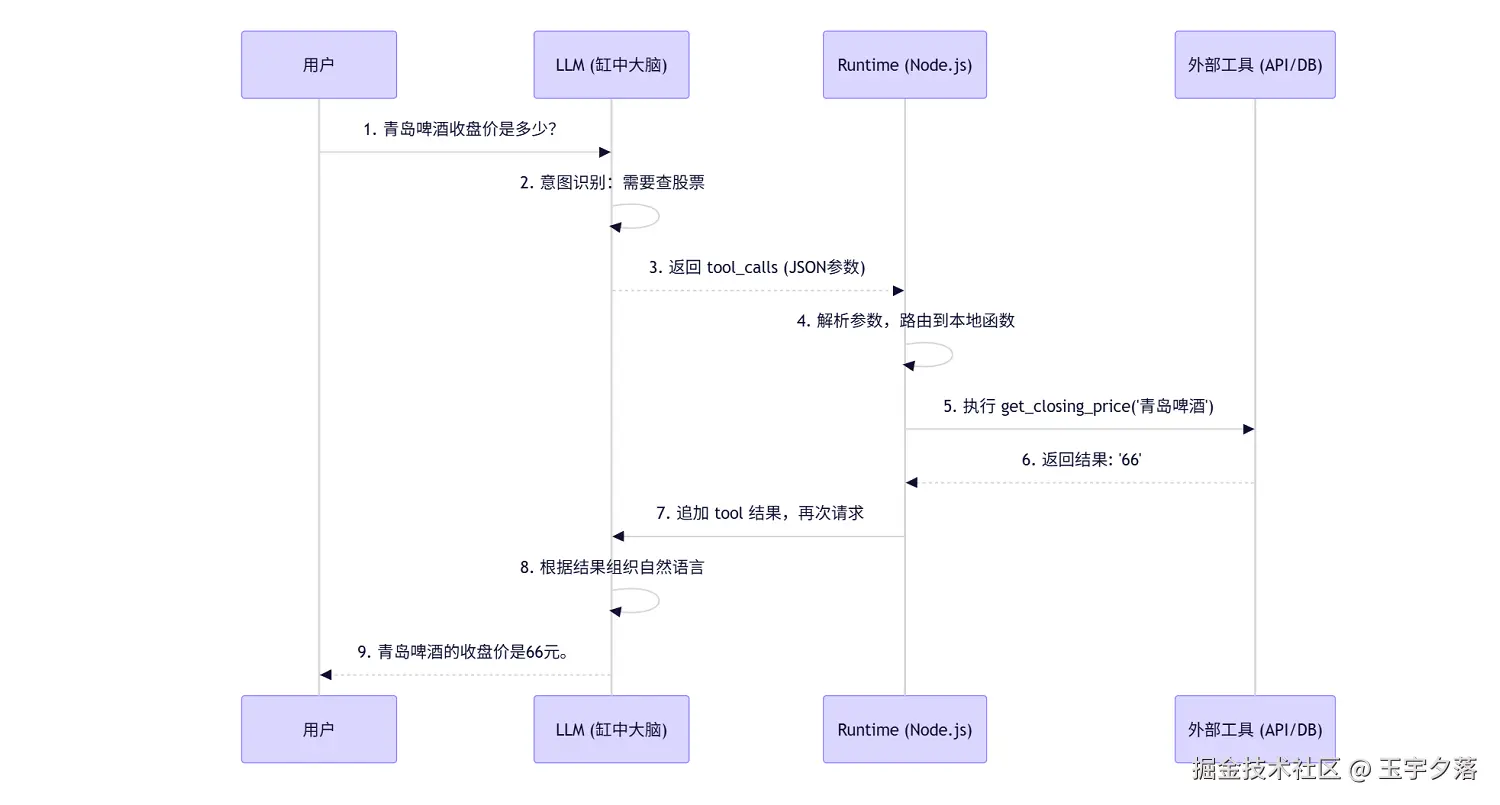
五、 避坑指南:新手最容易踩的 3 个坑
基于代码和实战经验,给大家总结了几个标准解决方案:
-
坑一:忘记把
tool_calls放入历史消息- 错误示范 :LLM 返回
tool_calls后,直接执行工具,然后把结果发给 LLM,但messages里缺少了 LLM 发起调用的那条记录。 - 正确做法 :必须严格按照
User -> Assistant(tool_calls) -> Tool(result)的顺序追加消息。LLM 需要看到自己"曾经下达过指令",才能理解后续的结果。
- 错误示范 :LLM 返回
-
坑二:
tool_call_id对不上- 错误示范 :返回工具结果时,不传
tool_call_id,或者传错了。 - 正确做法 :一次对话可能触发多个工具调用,必须使用 LLM 返回的
toolCall.id作为tool_call_id进行精确关联,否则 LLM 会陷入逻辑混乱。
- 错误示范 :返回工具结果时,不传
-
坑三:工具描述(Description)太简略
- 错误示范 :
description: "获取天气" - 正确做法 :
description: "获取指定城市的实时天气情况,包括温度、湿度和天气状况。当用户询问天气、气温时使用此工具。"描述越像"Prompt",LLM 的决策越精准。
- 错误示范 :
六、 面试高频考点
如果你在面试中遇到 AI Agent 或 LLM 应用开发的问题,这几个底层原理一定要背熟:
Q1:LLM 本身是如何执行工具的?
精炼回答 :LLM 本身不具备执行任何工具的能力。它本质上是一个 Next Token Prediction(下一个词预测)模型。Tool Use 是通过在 System Prompt 中注入 JSON Schema 进行"认知植入",让 LLM 输出符合特定格式的文本(tool_calls)。真正的执行是由外部的 Runtime(如 Node.js/Python)解析这段文本后,通过传统代码去调用的。
Q2:为什么工具调用通常需要两次甚至多次请求 LLM?
精炼回答 :因为 LLM 无法在生成
tool_calls的同时生成最终答案。第一次请求,LLM 识别意图并输出工具调用参数,此时对话中断;外部 Runtime 执行工具并将结果(role: tool)追加到上下文中;第二次请求,LLM 阅读工具返回的结果,再进行自然语言的总结与回复。这是一个"思考-行动-观察"的循环。
Q3:JSON Schema 在 Tool Use 中扮演什么角色?
精炼回答:它是连接"自然语言"与"强类型代码"的桥梁。它将复杂的软件接口函数降维成 LLM 能理解的"语言说明书",通过严格的类型约束(如 string, object, required)来限制 LLM 的概率随机性,确保生成的函数调用参数是合法且可被代码解析的。
结语
从"成语接龙"到"全能 Agent",Tool Use 让我们看到了大模型突破物理边界的无限可能。但作为开发者,我们要时刻保持清醒:AI 负责想象与决策,我们负责兜底与执行。 只有理解了这套"精心设计的错觉",我们才能写出真正健壮、可靠的 AI 应用。
javascript
运行
javascript
import OpenAI from 'openai';
import dotenv from 'dotenv';
dotenv.config();
const openai = new OpenAI({
apiKey: process.env.DEEPSEEK_API_KEY,
baseURL: process.env.DEEPSEEK_API_URL,
});
// 工具列表,附带JSON Schema参数约束
const tools = [
{
type: 'function',
function: {
name: 'get_closing_price',
description: '获取指定股票的收盘价',
parameters: {
type: 'object',
properties: {
name: {
type: 'string',
description: '股票名称'
}
},
required: ['name']
}
}
},
{
type: 'function',
function: {
name: 'get_weather',
description: '获取指定城市的天气',
parameters: {
type: 'object',
properties: {
city: {
type: 'string',
description: '城市名称'
}
},
required: ['city']
}
}
}
];
// 本地工具函数
function get_closing_price(name) {
if (name === '青岛啤酒') {
return '66';
} else if (name === '贵州茅台') {
return '3000';
} else {
return '未找到股票';
}
}
// 封装请求大模型
async function send_message(messages) {
const response = await openai.chat.completions.create({
model: 'deepseek-v4-flash',
messages,
tools,
tool_choice: 'auto',
});
return response;
}
async function main() {
let messages = [
{ role: 'user', content: '青岛啤酒的收盘价是多少?' }
];
// 第一轮对话,模型决定调用工具
const response = await send_message(messages);
const message = response.choices[0].message;
console.log('模型返回message 对象:', JSON.stringify(message));
// 修复:不要写成字符串 'message.role'
messages.push({
role: message.role,
content: message.content,
tool_calls: message.tool_calls
});
// 判断是否触发工具调用
if (message.tool_calls) {
const toolCall = message.tool_calls[0];
if (toolCall.function.name === 'get_closing_price') {
// 解析模型输出的JSON参数字符串
const args = JSON.parse(toolCall.function.arguments);
const price = get_closing_price(args.name);
console.log('股票价格:', price);
// 把工具执行结果塞入上下文
messages.push({
role: 'tool',
tool_call_id: toolCall.id,
content: price
});
console.log('更新后完整对话上下文:', messages);
// 第二轮对话:让大模型整理结果,输出自然语言回答
const finalRes = await send_message(messages);
console.log('最终结果:', finalRes.choices[0].message.content);
} else if (toolCall.function.name === 'get_weather') {
// 天气工具逻辑在这里扩展
}
}
}
main();