目录
- 一、分析
- 二、完整请求流程图
- [三、Python 实现](#三、Python 实现)
-
- [3.1 Python 完全纯算](#3.1 Python 完全纯算)
- [3.2 Python 调用 execjs](#3.2 Python 调用 execjs)
- [3.3 运行结果](#3.3 运行结果)
- 四、总结
免责声明:本文内容仅用于合法授权范围内的技术学习、安全研究、逆向分析方法交流与风控防护理解,不针对任何网站、产品或服务提供绕过、攻击、滥用或破坏性使用建议。文中涉及的接口分析、参数加解密、调试定位、代码复现、数据请求等内容,仅用于说明相关技术原理和分析流程。读者应在遵守相关法律法规、平台规则、robots 协议、用户协议以及获得合法授权的前提下进行学习和实验。请勿将本文中的方法、脚本或思路用于未授权访问、批量采集、账号撞库、绕过风控、破坏验证码体系、规避平台限制、侵犯数据权益、商业化滥用或影响线上系统稳定性的行为。对于真实网站案例,读者不应直接复制代码对线上服务进行高频请求或非授权调用。若相关网站、产品方、权利方或平台认为本文内容存在不适宜公开展示之处,可通过评论区、私信或作者主页提供的联系方式联系我;核实后将及时删除、替换或调整相关内容。读者因不当使用本文内容造成的任何法律责任、业务风险或经济损失,均由使用者自行承担,与作者无关。
一、分析
目标地址:https://zwfw.nmg.gov.cn/wsbsdt/website/pages/default/index
本案例目标是抓取内蒙古 12345 政务服务便民热线首页中 "诉求公开" 板块的公开工单列表数据。
从页面展示效果来看,每条公开诉求主要包含两部分信息:群众提出的问题,以及平台或承办单位给出的答复。这里先以页面可见的数据为目标,后面再根据接口实际返回内容决定最终能提取哪些字段。
进入页面后,"诉求公开" 列表会自动加载第一页数据。为了减少无关请求干扰,先打开 DevTools,切到 Network → Fetch/XHR,把已有的数据包清空,然后点击 "诉求公开" 板块下方的分页按钮。
通常情况下,清空后新出现的请求就是当前操作触发的接口;如果同时出现多个请求,就需要结合接口路径、请求参数和响应内容继续判断哪个才是列表接口。本案例比较简单,每点击一次分页按钮,Network 中只会新增一个数据包,所以定位起来很直接。我连续点击了 5 次分页,抓到的请求如下:

从上图可以确认接口为 https://zwfw.nmg.gov.cn/wsbsdt/rest/nmWebFrontPageRest/getCaseinfoList,请求方法是 POST。再看一下 Payload,发现传过去的不是明文参数,而是一段密文:
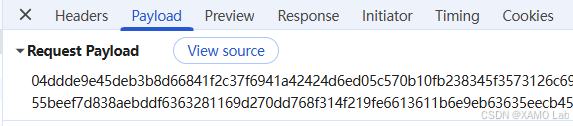
再看一下响应,发现返回的同样是一段密文,如下:

再看一下请求头,如下:
http
POST /wsbsdt/rest/nmWebFrontPageRest/getCaseinfoList HTTP/1.1
Accept: application/json, text/javascript, */*; q=0.01
Accept-Encoding: gzip, deflate, br, zstd
Accept-Language: zh-CN,zh;q=0.9
Cache-Control: no-cache
Connection: keep-alive
Content-Length: 322
Content-Type: application/json;charset=UTF-8
Cookie: .....cookie太长我省略了
Host: zwfw.nmg.gov.cn
Origin: https://zwfw.nmg.gov.cn
Pragma: no-cache
Referer: https://zwfw.nmg.gov.cn/wsbsdt/website/pages/defaultIndex/index.html
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/149.0.0.0 Safari/537.36
X-Requested-With: XMLHttpRequest
encrypt: 1
sec-ch-ua: "Google Chrome";v="149", "Chromium";v="149", "Not)A;Brand";v="24"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"右键请求 → Copy as cURL(bash) → 粘贴到 curlconverter.com 转成 Python 代码执行,先看能不能正常请求。这样也顺手整理出一个后面测试用的请求模板。因为前面已经看到请求体是密文,如果后面要抓多页,就得先搞清楚请求体密文是怎么生成的。实际测试下来,完整请求头可以正常拿到响应密文;把多余请求头删掉后,只保留 Content-Type、User-Agent 和 encrypt 这三个请求头,也还是能够正常返回密文,代码如下:
python
# -*- coding: utf-8 -*-
"""
@File : zwfw_nmg.py
@Author : XAMO Lab
@Date : 2026/6/23 15:14
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc :
"""
import requests
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/149.0.0.0 Safari/537.36',
'encrypt': '1',
}
data = '04ddde9e45deb3b8d66841f2c37f6941a42424d6ed05c570b10fb238345f3573126c69f49b893a0942723c3eefd93f59629e15fc43d623316d27daed786d0460f6b9825c135ae3f2af3d30be008869aece40b13ac01ecdf9242102a6b7fd5cc1f59187d320da73537968b40c3dcc8955beef7d838aebddf6363281169d270dd768f314f219fe6613611b6e9eb63635eecb45bd545a9dae970742f3e39ca4de5cff'
response = requests.post(
'https://zwfw.nmg.gov.cn/wsbsdt/rest/nmWebFrontPageRest/getCaseinfoList',
# cookies=cookies,
headers=headers,
data=data,
)
print(response.status_code)
print(response.text)接下来就可以开始分析了。这个案例我先解决的是响应密文的问题,验证方式也很直接:把浏览器返回的密文拿到本地扣好的 JS 代码里执行,能还原出页面上的明文就说明方向对了;当然,也可以直接用 Python 复写网页端逻辑。
分析阶段先扣 JS 代码,先定位解密处。常见办法有 Hook JSON.parse、搜索关键字、堆栈回溯几种,我这里还是先用最简单的方式,直接搜索 decrypt,结果如下:
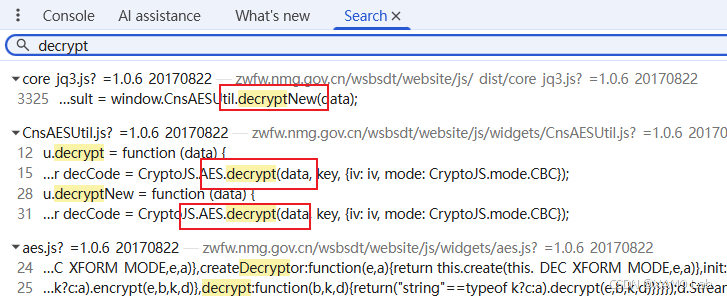
这些结果都还比较可疑,可以点进去逐个下断点,再翻页看看具体命中的是哪一个。我这里先测试第一个,进入 /js/_dist/core_jq3.js?_=1.0.6_20170822 后,看到 var decResult = window.CnsAESUtil.decryptNew(data); 这一行,直接在这里下断点,然后点击分页按钮验证。结果果然断住了,如下:
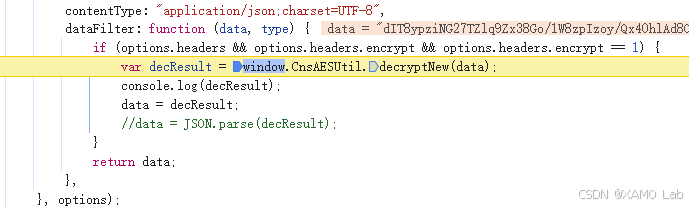
传入的参数 data 看着像响应的密文,这时可以直接在 Console 里执行 window.CnsAESUtil.decryptNew(data),进一步确认这里是不是我们要找的解密位置。执行后能看到返回的是页面明文数据,如下:
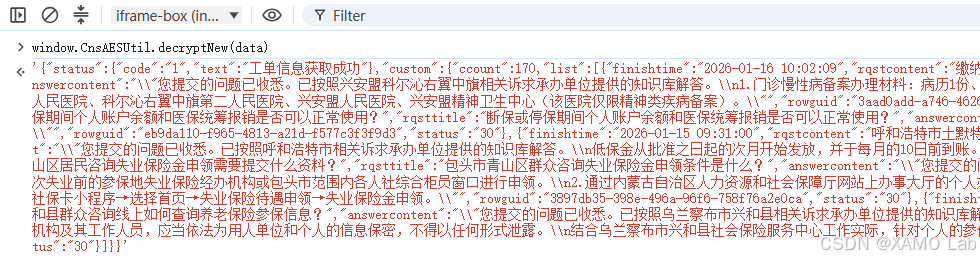
这一步基本可以确认,响应解密逻辑就在 decryptNew 里。接下来单步进入这个方法,看一下它内部到底做了什么:
javascript
u.decryptNew = function (data) {
var key = CryptoJS.enc.Utf8.parse('qnbpwgttcfv96fgw');
var iv = CryptoJS.enc.Utf8.parse('5141928399038306');
var decCode = CryptoJS.AES.decrypt(data, key, {iv: iv, mode: CryptoJS.mode.CBC});
var result = CryptoJS.enc.Utf8.stringify(decCode).toString();
return result;
};这段逻辑很清楚:data 是响应密文,key 和 iv 都是硬编码字符串,最后调用 CryptoJS.AES.decrypt 做 AES-CBC 解密。这里先不急着写 Python,先在本地新建一个 zwfw_nmg.js,把浏览器里的解密函数稍微改成 Node.js 能运行的形式:
javascript
CryptoJS = require('./CryptoJS')
function aesDecrypt(data) {
var key = CryptoJS.enc.Utf8.parse('qnbpwgttcfv96fgw');
var iv = CryptoJS.enc.Utf8.parse('5141928399038306');
var decCode = CryptoJS.AES.decrypt(data, key, {iv: iv, mode: CryptoJS.mode.CBC});
var result = CryptoJS.enc.Utf8.stringify(decCode).toString();
return result;
}
// 测试
console.log(aesDecrypt('dIT8ypziNG27TZlq9Zx38Go/1W8zpIzoy/Qx40hlAd8OWOb9yR9s.....Sas8kmF9rq/Y='));把浏览器响应里的密文复制进去测试,能够正常解出明文,说明响应解密这条链路已经扣对了,如下:
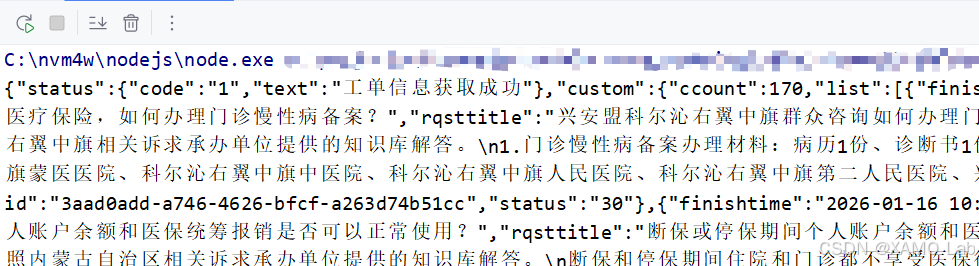
本地 JS 验证没问题后,就可以接回前面整理好的 Python 请求模板。这里先用 execjs 调用 zwfw_nmg.js,把接口返回的 response.text 传给 aesDecrypt:
python
import subprocess
from functools import partial
subprocess.Popen = partial(subprocess.Popen, encoding='utf-8')
import execjs
ctx = execjs.compile(open('./zwfw_nmg.js', 'r', encoding='utf-8').read())
# .... 省略已经写好的代码
print(ctx.call('aesDecrypt', response.text))运行后可以看到,Python 请求拿到的响应密文同样能被解开:
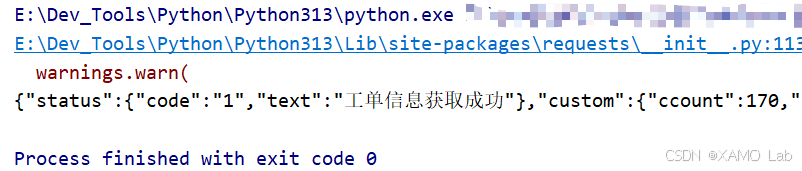
响应解密跑通之后,再来看请求体密文是怎么生成的。思路还是先从简单方法开始,直接全局搜索 encrypt,结果如下:
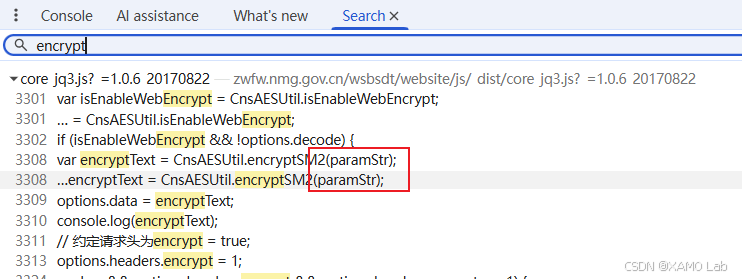
搜索结果里有一处出现了 paramStr,这个变量名很像 "参数字符串",和请求体加密高度相关,先点进去看上下文:
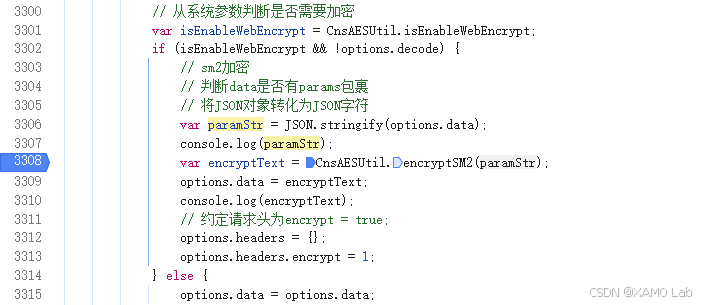
进入后可以看到 var encryptText = CnsAESUtil.encryptSM2(paramStr); 这一行,基本符合 "明文参数 → 加密请求体" 的特征。为了确认当前分页接口是否真的走这里,直接在这一行下断点,然后回到页面点击分页按钮。断点命中,说明请求体加密入口找对了:
和前面验证响应解密一样,这里也可以在 Console 中直接执行 CnsAESUtil.encryptSM2(paramStr),看返回值是否和 Network 里看到的 Request Payload 形态一致:
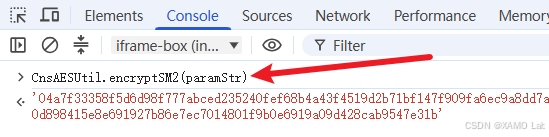
从结果来看,返回值和请求体里的密文形态一致。断点处还能看到 paramStr 的明文内容,例如:
python
{"token":"","params":{"first":3,"pagesize":5}}
{"token":"","params":{"first":4,"pagesize":5}}多次翻页对比可以发现,first 会随着分页变化,pagesize 固定为每页条数,所以 first 就是当前页索引。参数结构确认后,下一步只需要继续看 encryptSM2 内部到底调用了什么。单步进入后可以看到:
javascript
u.encryptSM2 = function (str) {
var result = sm2Util.encrypt(str);
return result;
};这里的 str 就是前面的 paramStr,也就是请求参数的 JSON 字符串。encryptSM2 本身只是转调了一层,真正的加密逻辑在 sm2Util.encrypt(str) 里。继续单步进入,会跳到 /js/widgets/sm2Util.js?_=1.0.6_20170822,最终停在混淆后的 x 函数中,入参 z 就是需要加密的明文参数:
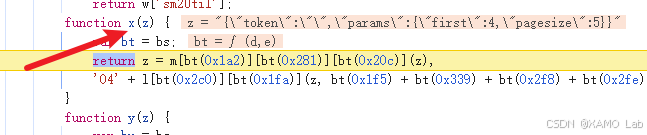
sm2Util.js 是混淆后的国密算法文件,当前阶段不需要把整份代码完全还原。更直接的做法是先把这个文件保存到本地,然后把命中的 x 函数导出到全局,后面直接调用它生成请求体密文:
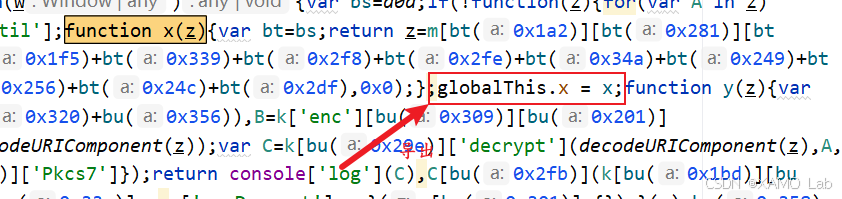
测试:
javascript
console.log(globalThis.x('{"token":"","params":{"first":5,"pagesize":5}}'));结果:
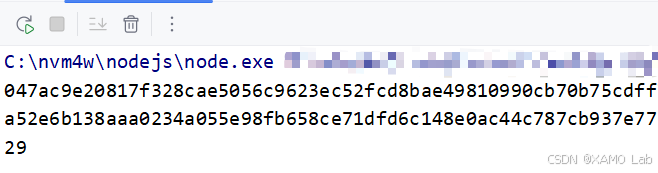
单独调用 globalThis.x(...) 能生成密文后,再封装成一个更清晰的函数,统一写到 zwfw_nmg.js 里管理:
javascript
require('./sm2Util')
function sm2Encrypt(paramStr){
return globalThis.x(paramStr)
}
console.log(sm2Encrypt('{"token":"","params":{"first":5,"pagesize":5}}'));封装后同样可以正常生成密文。接着把 Python 请求测试代码里的 data 替换成 sm2Encrypt(paramStr) 的返回值:
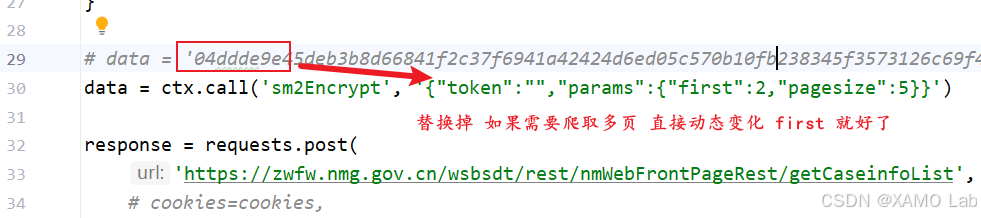
这里要注意一点:页面里的第一页 first 是从 0 开始的,不是从 1 开始。到这一步,请求体参数加密和响应体解密都已经跑通,整个接口复现流程就闭合了。
二、完整请求流程图
把前面断点里看到的逻辑串起来,这个接口的完整流程可以拆成两条线:请求方向负责把分页参数加密成 Request Payload,响应方向负责把服务端返回的密文解成 JSON。
text
页面点击分页按钮
│
▼
defaultIndex/js/index.js
getOpen(pageIndex, pageSize)
│
▼
原始业务参数
{ first: pageIndex, pagesize: pageSize }
│
▼
core_jq3.js -> Util.ajax(options)
统一包装参数
{
token: "",
params: {
first: pageIndex,
pagesize: pageSize
}
}
│
▼
JSON.stringify(options.data)
│
▼
paramStr 明文字符串
{"token":"","params":{"first":0,"pagesize":5}}
│
▼
CnsAESUtil.encryptSM2(paramStr)
│
▼
sm2Util.encrypt(paramStr)
│
├─ 先对 paramStr 做 Base64 编码
│
└─ 再用 SM2 公钥加密,模式参数为 0
公钥:
04A2C5ABFE372540F0CFAB644776B1CEC911F21739042D9FDF8326324357
790DBA3E3900338DE4FFDBA48204A176D444687904422180E0B1E3AF316C
4CA09AA704
│
▼
Request Payload
04 开头的十六进制 SM2 密文字符串
│
▼
POST /wsbsdt/rest/nmWebFrontPageRest/getCaseinfoList
Content-Type: application/json;charset=UTF-8
encrypt: 1服务端返回后,前端会在同一个 Ajax 封装里继续处理响应:
text
Response Body
Base64 形式的 AES 密文字符串
│
▼
core_jq3.js -> dataFilter(data, type)
判断 options.headers.encrypt == 1
│
▼
CnsAESUtil.decryptNew(data)
│
├─ AES/CBC/PKCS7
├─ Key: qnbpwgttcfv96fgw
└─ IV : 5141928399038306
│
▼
解密后的 JSON 字符串
│
▼
jQuery 按 dataType=json 解析成对象
│
▼
success 回调拿到 res
res.custom.ccount 总条数
res.custom.list 当前页列表
│
▼
列表字段
rqstcontent 诉求内容
answercontent 答复内容
finishtime 办结时间(接口返回字段,页面列表中不直接展示)这个流程里没有发现额外的动态 sign、timestamp 或登录态校验。真正需要复现的核心只有两块:请求体的 SM2 加密,以及响应体的 AES-CBC 解密。
三、Python 实现
上面已经把请求体加密和响应体解密逻辑都确认清楚了,接下来就可以写 Python 脚本了。这里我准备了两个版本:
nmg_12345_caseinfo_spider.py:纯 Python 版本,用gmssl生成 SM2 请求密文,用pycryptodome解 AES 响应。nmg_12345_caseinfo_execjs_spider.py:Python 调用 JS 版本,直接复用前面扣下来的sm2Util.js和CryptoJS.js。
这个案例是政府网站,代码里默认只请求前 2 页,每页 5 条,并发数也只给到 2,学习验证够用了,不需要把请求量开大。
目录结构如下:
text
nmg-12345-sm2-aes
├─ README.md
├─ nmg_12345_caseinfo_spider.py
├─ nmg_12345_caseinfo_execjs_spider.py
└─ js/
└─ nmg_12345_crypto.js依赖安装:
bash
pip install requests pycryptodome gmssl loguru PyExecJS其中 PyExecJS 版本需要本地能正常调用 Node.js。这个版本还需要准备两个前端公共库文件:CryptoJS.js 和 sm2Util.js。
最简单的目录放法是把这两个文件放到当前案例的 js/ 目录下:
text
nmg-12345-sm2-aes
└─ js/
├─ nmg_12345_crypto.js
├─ CryptoJS.js
└─ sm2Util.js如果你自己的项目里有统一的公共库目录,也可以不复制文件,直接通过环境变量 JS_REVERSE_SHARED_JS_LIB_DIR 指向那个目录,脚本会从里面读取 CryptoJS.js 和 sm2Util.js。
3.1 Python 完全纯算
纯 Python 版本不依赖前端 JS 文件,适合最后落地使用。这里要注意三点:
- 第一页的
first是0,不是1。 - 请求明文格式是
{"token":"","params":{"first":0,"pagesize":5}}。 - 请求体是
JSON -> Base64 -> SM2 -> 前面补 04,响应体是AES/CBC/PKCS7解密。
文件名:nmg_12345_caseinfo_spider.py
python
# -*- coding: utf-8 -*-
"""
@File : nmg_12345_caseinfo_spider.py
@Author : XAMO Lab
@Date : 2026/6/23 17:25
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc : 内蒙古12345政务热线诉求公开采集(SM2 请求加密 + AES/CBC/PKCS7 响应解密 + 小并发测试)
"""
import base64
import json
import sys
import time
import warnings
from concurrent.futures import ThreadPoolExecutor, as_completed
from typing import Any, Dict, List
warnings.filterwarnings(
"ignore",
message=r"urllib3 .* or chardet .*charset_normalizer .* doesn't match a supported version!",
)
import requests
from Crypto.Cipher import AES
from Crypto.Util.Padding import unpad
from gmssl import sm2
from loguru import logger
logger.remove()
logger.add(sys.stdout, level="INFO")
class Nmg12345Crypto:
"""内蒙古12345接口加解密"""
# sm2Util.js 中硬编码的 SM2 公钥,原始值带 04 前缀。
SM2_PUBLIC_KEY = (
"04A2C5ABFE372540F0CFAB644776B1CEC911F21739042D9FDF8326324357"
"790DBA3E3900338DE4FFDBA48204A176D444687904422180E0B1E3AF316C"
"4CA09AA704"
)
AES_KEY = b"qnbpwgttcfv96fgw"
AES_IV = b"5141928399038306"
def __init__(self) -> None:
public_key = (
self.SM2_PUBLIC_KEY[2:]
if self.SM2_PUBLIC_KEY.startswith("04")
else self.SM2_PUBLIC_KEY
)
self.sm2_crypt = sm2.CryptSM2(private_key="", public_key=public_key, mode=0)
def encrypt_request(self, payload: Dict[str, Any]) -> str:
"""
请求体加密:
JSON 字符串 -> Base64 -> SM2 加密 -> 前面补 04。
"""
plaintext = json.dumps(payload, ensure_ascii=False, separators=(",", ":"))
b64_plaintext = base64.b64encode(plaintext.encode("utf-8"))
return "04" + self.sm2_crypt.encrypt(b64_plaintext).hex()
def decrypt_response(self, cipher_text: str) -> Dict[str, Any]:
"""响应体解密: Base64 密文 -> AES/CBC/PKCS7 -> JSON。"""
cipher = AES.new(self.AES_KEY, AES.MODE_CBC, self.AES_IV)
plain = unpad(cipher.decrypt(base64.b64decode(cipher_text.strip())), AES.block_size)
return json.loads(plain.decode("utf-8"))
class Nmg12345CaseinfoSpider:
"""内蒙古12345政务热线诉求公开采集"""
API_URL = "https://zwfw.nmg.gov.cn/wsbsdt/rest/nmWebFrontPageRest/getCaseinfoList"
REFERER = "https://zwfw.nmg.gov.cn/wsbsdt/website/pages/defaultIndex/index.html"
ORIGIN = "https://zwfw.nmg.gov.cn"
def __init__(
self,
page_size: int = 5,
max_workers: int = 2,
retries: int = 2,
request_interval: float = 0.3,
) -> None:
"""
:param page_size: 每页条数,页面默认 5
:param max_workers: 并发线程数,政府网站测试保持小并发
:param retries: 单页失败后的重试次数
:param request_interval: 重试间隔,避免过快请求
"""
self.page_size = page_size
self.max_workers = max_workers
self.retries = retries
self.request_interval = request_interval
self.crypto = Nmg12345Crypto()
self.session = requests.Session()
self.session.headers.update({
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
"Content-Type": "application/json;charset=UTF-8",
"Origin": self.ORIGIN,
"Referer": self.REFERER,
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/149.0.0.0 Safari/537.36"
),
"X-Requested-With": "XMLHttpRequest",
"encrypt": "1",
})
@staticmethod
def build_payload(page_index: int, page_size: int) -> Dict[str, Any]:
"""构造加密前的请求体。页面第一页 page_index 从 0 开始。"""
return {
"token": "",
"params": {
"first": page_index,
"pagesize": page_size,
},
}
@staticmethod
def parse_cases(data: Dict[str, Any]) -> List[Dict[str, str]]:
"""解析诉求公开列表字段。"""
rows = []
for item in data.get("custom", {}).get("list", []):
rows.append({
"诉求内容": item.get("rqstcontent") or item.get("rqsttitle", ""),
"答复内容": item.get("answercontent", ""),
"办结时间": item.get("finishtime", ""),
})
return rows
def fetch_page(self, page_index: int) -> List[Dict[str, str]]:
"""请求并解析单页数据。"""
payload = self.build_payload(page_index, self.page_size)
encrypted_body = self.crypto.encrypt_request(payload)
for attempt in range(1, self.retries + 1):
try:
resp = self.session.post(self.API_URL, data=encrypted_body, timeout=20)
resp.raise_for_status()
decrypted = self.crypto.decrypt_response(resp.text)
rows = self.parse_cases(decrypted)
logger.info("page_index={} 获取 {} 条记录", page_index, len(rows))
return rows
except Exception as exc:
logger.warning(
"page_index={} 第 {}/{} 次请求失败: {}",
page_index,
attempt,
self.retries,
exc,
)
if attempt < self.retries:
time.sleep(self.request_interval * attempt)
logger.error("page_index={} 请求失败,已跳过", page_index)
return []
def run(self, pages: int = 2) -> List[Dict[str, str]]:
"""
小规模测试采集。
政府网站案例仅用于学习验证,默认只请求前 2 页。
"""
all_rows: List[Dict[str, str]] = []
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
futures = {
executor.submit(self.fetch_page, page_index): page_index
for page_index in range(pages)
}
for future in as_completed(futures):
page_index = futures[future]
try:
all_rows.extend(future.result())
except Exception as exc:
logger.error("page_index={} 处理异常: {}", page_index, exc)
all_rows.sort(key=lambda row: row.get("办结时间", ""), reverse=True)
return all_rows
def main() -> None:
spider = Nmg12345CaseinfoSpider(page_size=5, max_workers=2, retries=2)
rows = spider.run(pages=2)
logger.info("本次共获取 {} 条记录", len(rows))
for row in rows:
logger.info("{}", json.dumps(row, ensure_ascii=False))
if __name__ == "__main__":
main()3.2 Python 调用 execjs
execjs 版本更适合刚扣完 JS 后做对照验证。公共库不写进案例目录,只保留本站自己的核心包装逻辑。
核心 JS 文件:js/nmg_12345_crypto.js
javascript
/* 内蒙古12345政务热线诉求公开
* 本文件只保留本站核心 JS 包装逻辑。
* CryptoJS 和 sm2Util.js 由 Python 侧 execjs 编译前注入。
*/
const AES_KEY = "qnbpwgttcfv96fgw";
const AES_IV = "5141928399038306";
function buildPayload(pageIndex, pageSize) {
return JSON.stringify({
token: "",
params: {
first: pageIndex,
pagesize: pageSize,
},
});
}
function sm2Encrypt(paramStr) {
if (typeof globalThis.x !== "function") {
throw new Error("sm2Util.js 未暴露 globalThis.x");
}
return globalThis.x(paramStr);
}
function aesDecrypt(ciphertext) {
const key = CryptoJS.enc.Utf8.parse(AES_KEY);
const iv = CryptoJS.enc.Utf8.parse(AES_IV);
const decCode = CryptoJS.AES.decrypt(ciphertext, key, {
iv: iv,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7,
});
return CryptoJS.enc.Utf8.stringify(decCode).toString();
}
function makeRequestBody(pageIndex, pageSize) {
const plain = buildPayload(pageIndex, pageSize);
return {
plain: plain,
body: sm2Encrypt(plain),
};
}
function decryptResponse(ciphertext) {
return JSON.parse(aesDecrypt(ciphertext));
}Python 文件:nmg_12345_caseinfo_execjs_spider.py
python
# -*- coding: utf-8 -*-
"""
@File : nmg_12345_caseinfo_execjs_spider.py
@Author : XAMO Lab
@Date : 2026/6/23 17:47
@Blog : https://blog.csdn.net/xw1680
@Tool : PyCharm
@Desc : 内蒙古12345政务热线诉求公开采集(Python 调用 execjs 复现)
"""
import json
import os
import subprocess
import sys
import time
import warnings
from concurrent.futures import ThreadPoolExecutor, as_completed
from functools import partial
from pathlib import Path
from typing import Any, Dict, List
warnings.filterwarnings(
"ignore",
message=r"urllib3 .* or chardet .*charset_normalizer .* doesn't match a supported version!",
)
import requests
from loguru import logger
subprocess.Popen = partial(subprocess.Popen, encoding="utf-8")
import execjs
logger.remove()
logger.add(sys.stdout, level="INFO")
BASE_DIR = Path(__file__).resolve().parent
JS_DIR = BASE_DIR / "js"
CORE_JS = JS_DIR / "nmg_12345_crypto.js"
class Nmg12345CaseinfoExecjsSpider:
"""内蒙古12345政务热线诉求公开采集(Python 调 execjs 版本)"""
API_URL = "https://zwfw.nmg.gov.cn/wsbsdt/rest/nmWebFrontPageRest/getCaseinfoList"
REFERER = "https://zwfw.nmg.gov.cn/wsbsdt/website/pages/defaultIndex/index.html"
ORIGIN = "https://zwfw.nmg.gov.cn"
def __init__(
self,
page_size: int = 5,
max_workers: int = 2,
retries: int = 2,
request_interval: float = 0.3,
) -> None:
"""
:param page_size: 每页条数,页面默认 5
:param max_workers: 并发线程数,政府网站测试保持小并发
:param retries: 单页失败后的重试次数
:param request_interval: 重试间隔,避免过快请求
"""
self.page_size = page_size
self.max_workers = max_workers
self.retries = retries
self.request_interval = request_interval
self.ctx = self._compile_js()
self.session = requests.Session()
self.session.headers.update({
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9",
"Content-Type": "application/json;charset=UTF-8",
"Origin": self.ORIGIN,
"Referer": self.REFERER,
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/149.0.0.0 Safari/537.36"
),
"X-Requested-With": "XMLHttpRequest",
"encrypt": "1",
})
@staticmethod
def _has_js_libs(path: Path) -> bool:
return (path / "CryptoJS.js").exists() and (path / "sm2Util.js").exists()
@classmethod
def _resolve_js_lib_dir(cls) -> Path:
"""优先使用环境变量,其次找当前 js 目录,最后向上找 shared/js-libs。"""
env_dir = os.getenv("JS_REVERSE_SHARED_JS_LIB_DIR")
if env_dir:
path = Path(env_dir).expanduser().resolve()
if cls._has_js_libs(path):
return path
candidates = [JS_DIR]
candidates.extend(parent / "shared" / "js-libs" for parent in [BASE_DIR, *BASE_DIR.parents])
for path in candidates:
if cls._has_js_libs(path):
return path
raise FileNotFoundError("未找到 CryptoJS.js 和 sm2Util.js,请放到 js/ 目录或设置 JS_REVERSE_SHARED_JS_LIB_DIR")
@classmethod
def _compile_js(cls) -> execjs.ExternalRuntime.Context:
"""读取公共库和本站核心 JS,编译为 execjs 上下文。"""
js_lib_dir = cls._resolve_js_lib_dir()
prefix = f'''
if (typeof window === "undefined") {{
global.window = global;
global.self = global;
global.globalThis = global;
}}
const CryptoJS = require({json.dumps(str(js_lib_dir / "CryptoJS.js"), ensure_ascii=False)});
require({json.dumps(str(js_lib_dir / "sm2Util.js"), ensure_ascii=False)});
'''
source = prefix + "\n" + CORE_JS.read_text(encoding="utf-8")
return execjs.compile(source)
def _make_request_body(self, page_index: int) -> Dict[str, str]:
"""调用 JS 生成请求体密文。"""
return self.ctx.call("makeRequestBody", page_index, self.page_size)
def _decrypt_response(self, ciphertext: str) -> Dict[str, Any]:
"""调用 JS 解密响应密文。"""
return self.ctx.call("decryptResponse", ciphertext.strip())
@staticmethod
def parse_cases(data: Dict[str, Any]) -> List[Dict[str, str]]:
"""解析诉求公开列表字段。"""
rows = []
for item in data.get("custom", {}).get("list", []):
rows.append({
"诉求内容": item.get("rqstcontent") or item.get("rqsttitle", ""),
"答复内容": item.get("answercontent", ""),
"办结时间": item.get("finishtime", ""),
})
return rows
def fetch_page(self, page_index: int) -> List[Dict[str, str]]:
"""请求并解析单页数据。"""
for attempt in range(1, self.retries + 1):
try:
crypto = self._make_request_body(page_index)
logger.info("page_index={} 开始请求 | plain={}", page_index, crypto.get("plain"))
resp = self.session.post(self.API_URL, data=crypto["body"], timeout=20)
resp.raise_for_status()
decrypted = self._decrypt_response(resp.text)
rows = self.parse_cases(decrypted)
logger.success("page_index={} 解密成功,获取 {} 条记录", page_index, len(rows))
return rows
except Exception as exc:
logger.warning(
"page_index={} 第 {}/{} 次请求失败: {}",
page_index,
attempt,
self.retries,
exc,
)
if attempt < self.retries:
time.sleep(self.request_interval * attempt)
logger.error("page_index={} 请求失败,已跳过", page_index)
return []
def run(self, pages: int = 2) -> List[Dict[str, str]]:
"""
小规模测试采集。
政府网站案例仅用于学习验证,默认只请求前 2 页。
"""
logger.info(
"开始采集内蒙古12345诉求公开(execjs 版)| 共 {} 页 | 每页 {} 条 | 并发 {}",
pages,
self.page_size,
self.max_workers,
)
all_rows: List[Dict[str, str]] = []
with ThreadPoolExecutor(max_workers=self.max_workers) as executor:
futures = {
executor.submit(self.fetch_page, page_index): page_index
for page_index in range(pages)
}
for future in as_completed(futures):
page_index = futures[future]
try:
all_rows.extend(future.result())
except Exception as exc:
logger.error("page_index={} 处理异常: {}", page_index, exc)
all_rows.sort(key=lambda row: row.get("办结时间", ""), reverse=True)
logger.info("采集完成,共 {} 条记录", len(all_rows))
return all_rows
def main() -> None:
spider = Nmg12345CaseinfoExecjsSpider(page_size=5, max_workers=2, retries=2)
rows = spider.run(pages=2)
for row in rows:
logger.info("{}", json.dumps(row, ensure_ascii=False))
if __name__ == "__main__":
main()3.3 运行结果
运行命令:
bash
python nmg_12345_caseinfo_spider.py
python nmg_12345_caseinfo_execjs_spider.py两份脚本都使用默认的小规模配置进行测试:
text
pages=2
page_size=5
max_workers=2纯 Python 版本运行结果:
text
2026-06-23 18:39:41.527 | INFO | __main__:fetch_page:144 - page_index=0 获取 5 条记录
2026-06-23 18:39:41.541 | INFO | __main__:fetch_page:144 - page_index=1 获取 5 条记录
2026-06-23 18:39:41.542 | INFO | __main__:main:185 - 本次共获取 10 条记录execjs 版本运行结果:
text
2026-06-23 18:39:58.353 | INFO | __main__:run:168 - 开始采集内蒙古12345诉求公开(execjs 版)| 共 2 页 | 每页 5 条 | 并发 2
2026-06-23 18:39:58.515 | INFO | __main__:fetch_page:142 - page_index=0 开始请求 | plain={"token":"","params":{"first":0,"pagesize":5}}
2026-06-23 18:39:58.516 | INFO | __main__:fetch_page:142 - page_index=1 开始请求 | plain={"token":"","params":{"first":1,"pagesize":5}}
2026-06-23 18:39:59.249 | SUCCESS | __main__:fetch_page:147 - page_index=0 解密成功,获取 5 条记录
2026-06-23 18:39:59.273 | SUCCESS | __main__:fetch_page:147 - page_index=1 解密成功,获取 5 条记录最终整理出来的字段如下:
| 字段 | 来源字段 | 说明 |
|---|---|---|
| 诉求内容 | rqstcontent |
群众提交的问题内容 |
| 答复内容 | answercontent |
平台或承办单位答复内容 |
| 办结时间 | finishtime |
接口返回字段,页面列表不展示 |
四、总结
这个案例整体不算复杂,真正需要拆开的就两件事:请求体为什么不是明文,以及响应体为什么直接看不到 JSON。
请求方向还是按前面的思路来定位:先搜索 encrypt,找到 paramStr 和 CnsAESUtil.encryptSM2(paramStr) 这一处后下断点。断住以后可以看到,真正送去加密的分页参数是下面这种结构:
json
{"token":"","params":{"first":0,"pagesize":5}}然后调用 CnsAESUtil.encryptSM2(paramStr)。继续跟进去可以看到,它最后走的是 sm2Util.encrypt,也就是前端混淆文件 sm2Util.js 里的 SM2 加密逻辑。这里要特别注意两点:第一页的 first 从 0 开始;生成的 SM2 密文前面带 04,Python 复现时也要保持这个格式。
响应方向更直接,列表接口返回的是一整段密文,真正解密的位置在 core_jq3.js 里的 window.CnsAESUtil.decryptNew(data)。这个函数没有动态参数,AES 的 Key 和 IV 都是写死的:
text
Key = qnbpwgttcfv96fgw
IV = 5141928399038306
Mode = CBC
Padding = PKCS7所以这个接口最终可以拆成下面这个流程:
text
分页参数 -> JSON.stringify -> Base64 -> SM2 加密 -> POST 请求
响应密文 -> AES/CBC/PKCS7 解密 -> JSON.parse -> 提取字段落地代码我给了两个版本。纯 Python 版本适合最终使用,不依赖浏览器端 JS;execjs 版本适合刚分析完 JS 后做对照验证,能更直观地确认自己扣下来的逻辑是不是和浏览器一致。实际写案例时,我一般会先用 execjs 跑通,再根据算法和参数改成纯 Python,这样排查问题会轻松很多。
最后还是要强调一下,这类政务网站案例只适合学习逆向流程和加解密还原,不适合大量采集。脚本里默认只请求前 2 页,每页 5 条,并发数也控制为 2,这样既能验证请求加密、响应解密和字段解析都没问题,也不会对目标网站造成额外压力。