内容参考于:图灵AI大模型全栈
图数据库如下:图属性就是LPG
| 数据库名称 | 数据模型 | 查询语言 | 核心优势 | 适用场景 | 许可协议 |
|---|---|---|---|---|---|
| Neo4j | 属性图 | Cypher | 生态最成熟、易用性最佳、ACID事务、原生图处理 | 推荐系统、欺诈检测、知识图谱、主数据管理 | 开源社区版 / 商业付费 |
| Nebula Graph | 属性图 | nGQL | 原生分布式 、水平扩展、高性能、中文社区活跃 | 超大规模图、社交网络、金融风控、互联网应用 | 开源 |
| JanusGraph | 属性图 | Gremlin | 高度灵活、与大数据生态(HBase/Cassandra/ES)集成性好 | 需要与现有大数据平台集成的复杂企业应用 | 开源 |
| TigerGraph | 属性图 | GSQL | 高性能、深度链接分析、内置并行图计算引擎 | 实时反欺诈、复杂多跳查询、实时推荐 | 商业付费 |
| Amazon Neptune | 双引擎 (属性图/RDF) | Gremlin / SPARQL | 全托管服务、高可用、与AWS生态无缝集成、双模型支持 | 希望快速上手、避免运维的AWS用户 | 商业付费 (按用量计费) |
| Apache Jena | RDF | SPARQL | 语义Web标准支持、支持推理、Java生态成熟 | 学术研究、语义网项目、需要逻辑推理的场景 | 开源 |
Neo4j
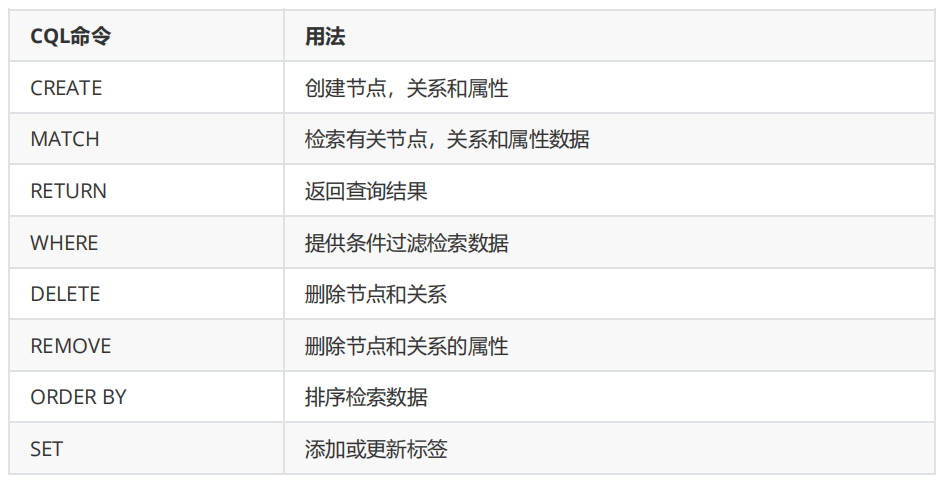
命令参考表,下方的内容都看完就可以看到这个表了
操作 主要子句 特点 / 注意事项 增 CREATE / MERGE MERGE 幂等,推荐用于避免重复 查 MATCH + RETURN 最核心,几乎所有查询都从这里开始 改 SET / REMOVE SET 可增/改属性,REMOVE 删除属性或标签 删 DELETE / DETACH DELETE DETACH 会自动删除关系再删节点 Neo4j里的j指的是java语言,Neo4j的3.x版本可以使用java8,java11才可以按照neo4j4.x的版本,java17才可以使用neo4j的5.x版本
java语言的安装网上一搜一大堆,下载下来只需要配置一下环境变量即可
下载
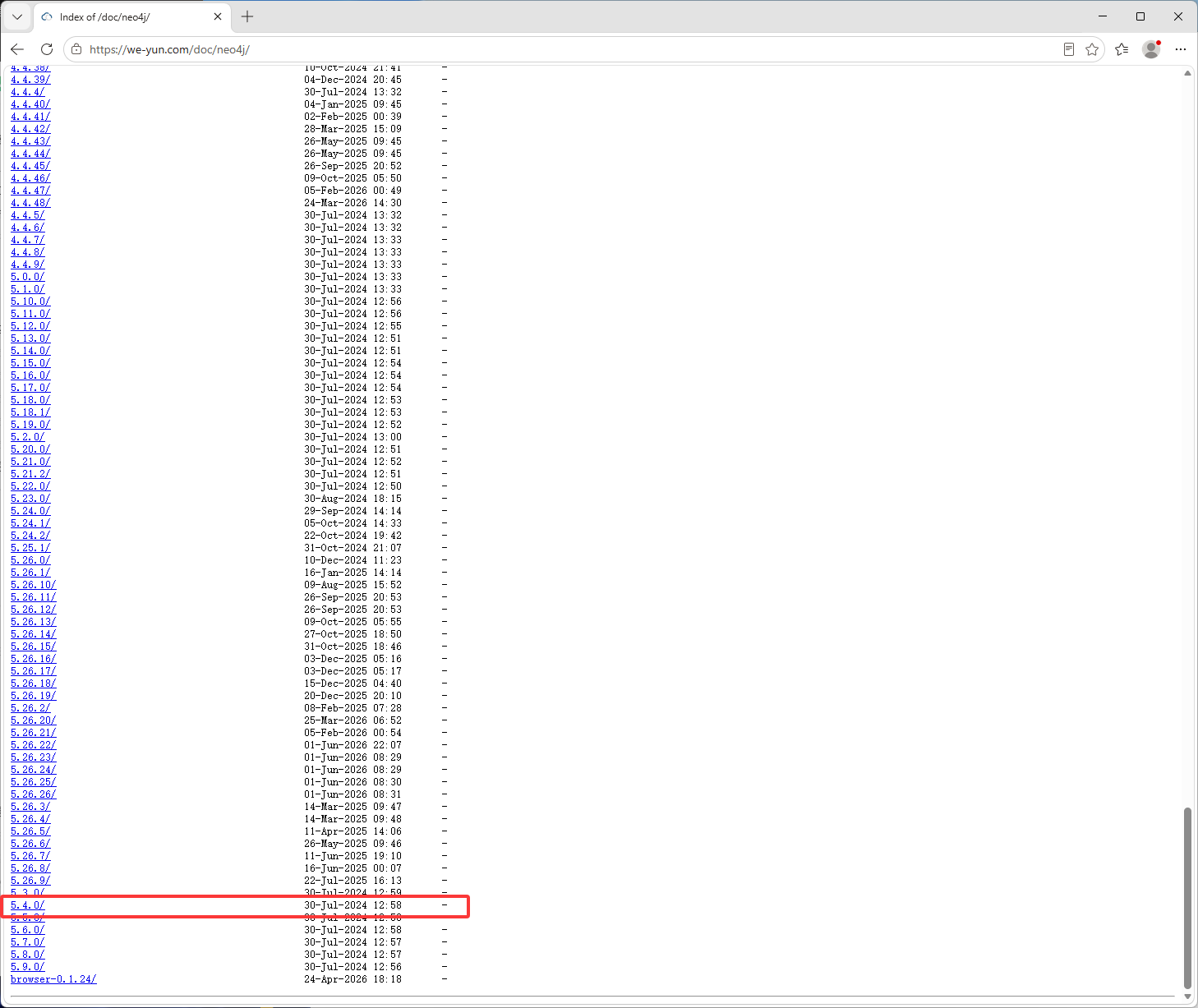
- 国内源地址:https://we-yun.com/doc/neo4j/
- 官网: https://neo4j.com/
- 操作文档地址: https://neo4j.com/docs/operations-manual/3.5/
- jdk地址: https://www.oracle.com/java/technologies/javase/jdk17-archive-downloads.html
用到的版本已放到百度网盘中,注意jdk是免费的,但是下载需要注册Oracle的账号,登录账号后才可以下载,账号的注册和账号也可以百度找
这里使用java17,neo4j5.4版本
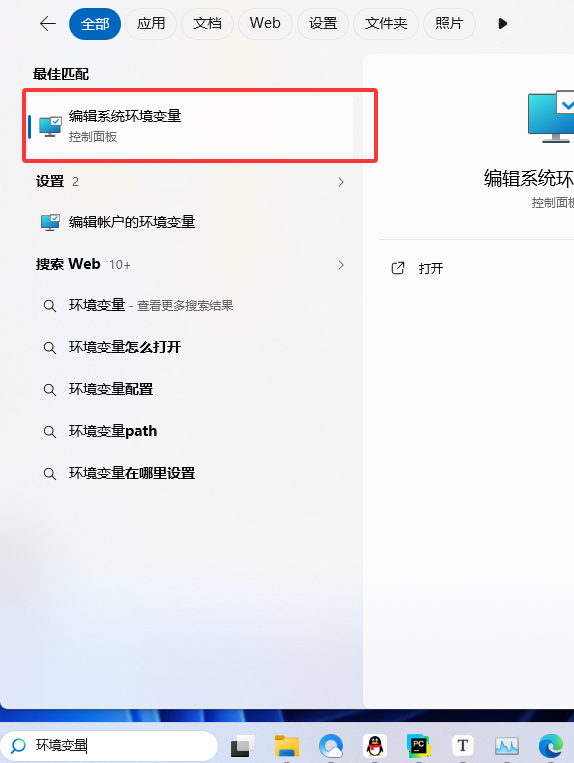
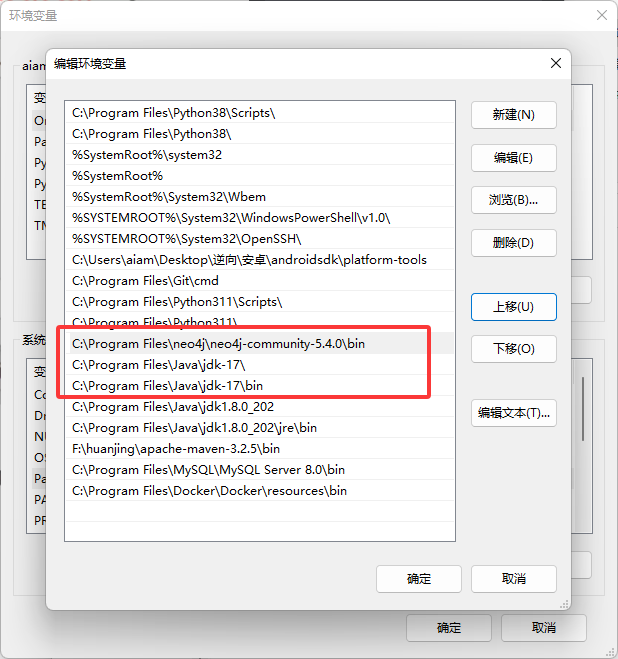
下载完需要配置环境变量,如下执行搜索环境变量,然后点击下图红框(最好编辑系统的)
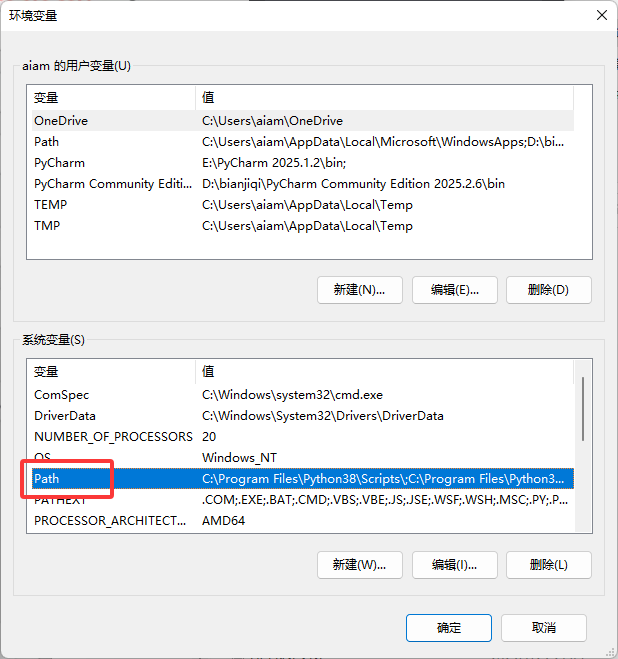
然后找到这个Path,选中Path然后点击编辑
然后添加下图红框的三个目录即可(java的解压目录也就是安装目录,neo4j的解压目录也就是安装目录),到它的bin目录
设置好环境变量就可以使用了,打开一个cmd窗口
终端命令
neo4j install-service | neo4j uninstall-service | neo4j update-service : 安装/卸载/更新 neo4j 服务 a
neo4j start/ neo4j stop/ neo4j restart/ neo4j status: 启动/停止/重启/状态
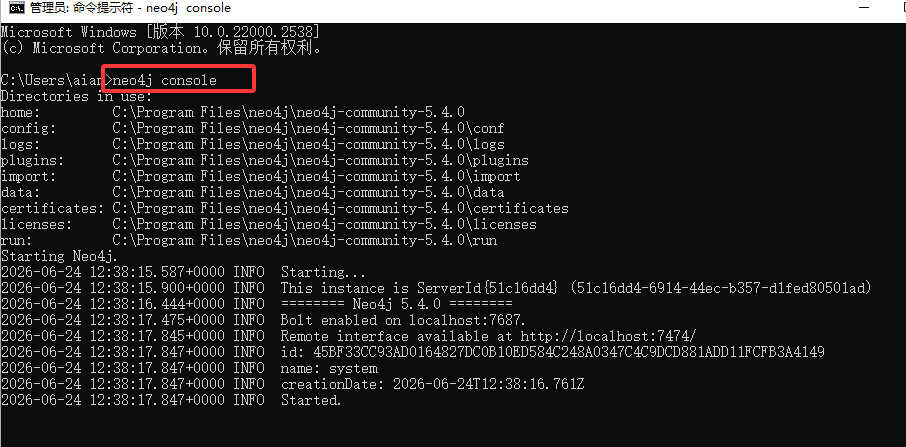
neo4j console: 直接启动 neo4j 服务器
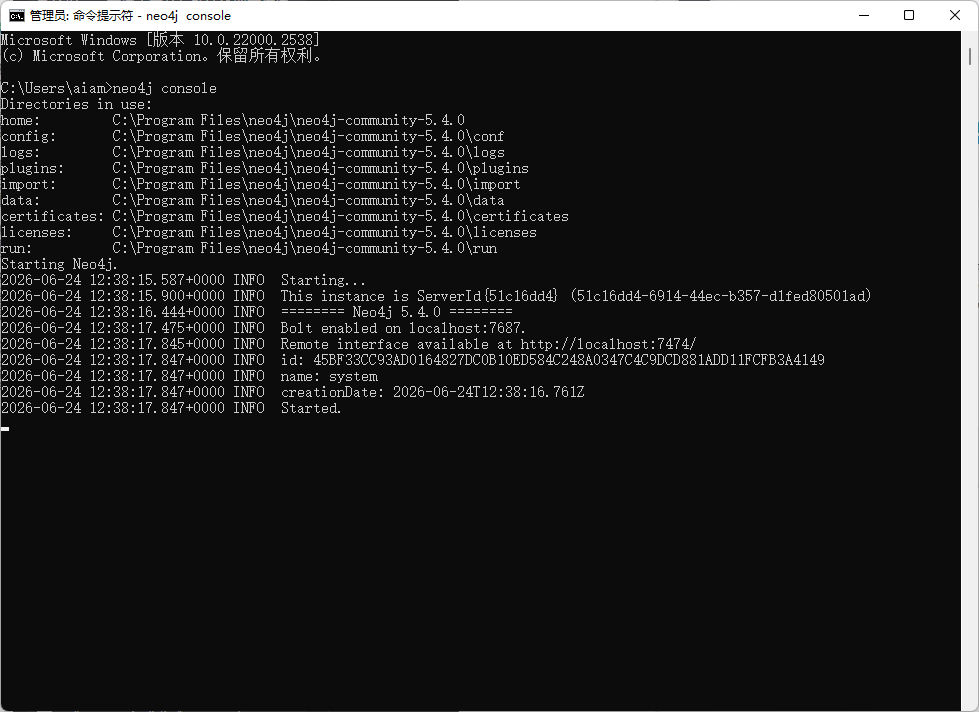
如下图使用neo4j console命令启动neo4j,先不要启动看完了再启动后面要配置东西
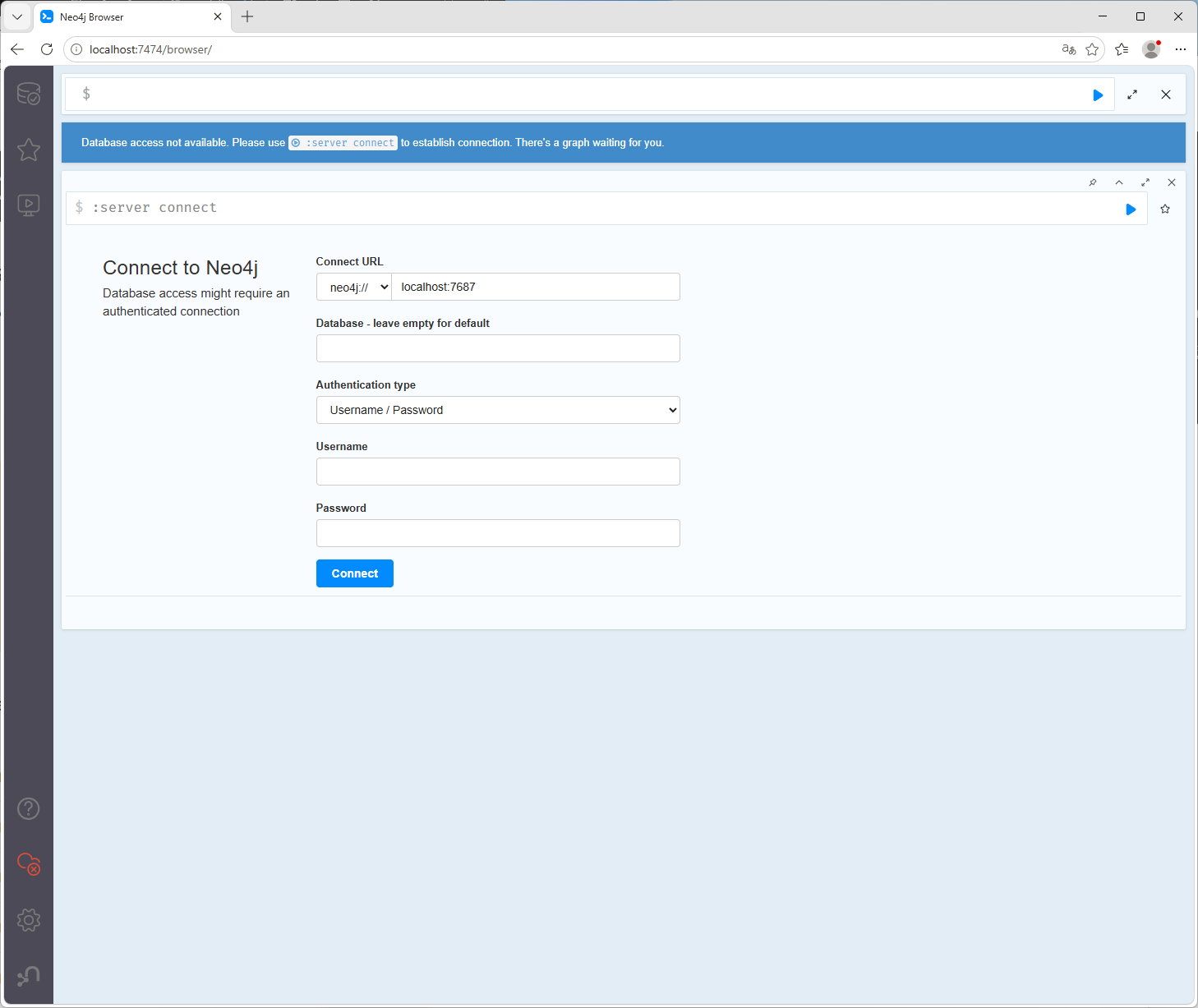
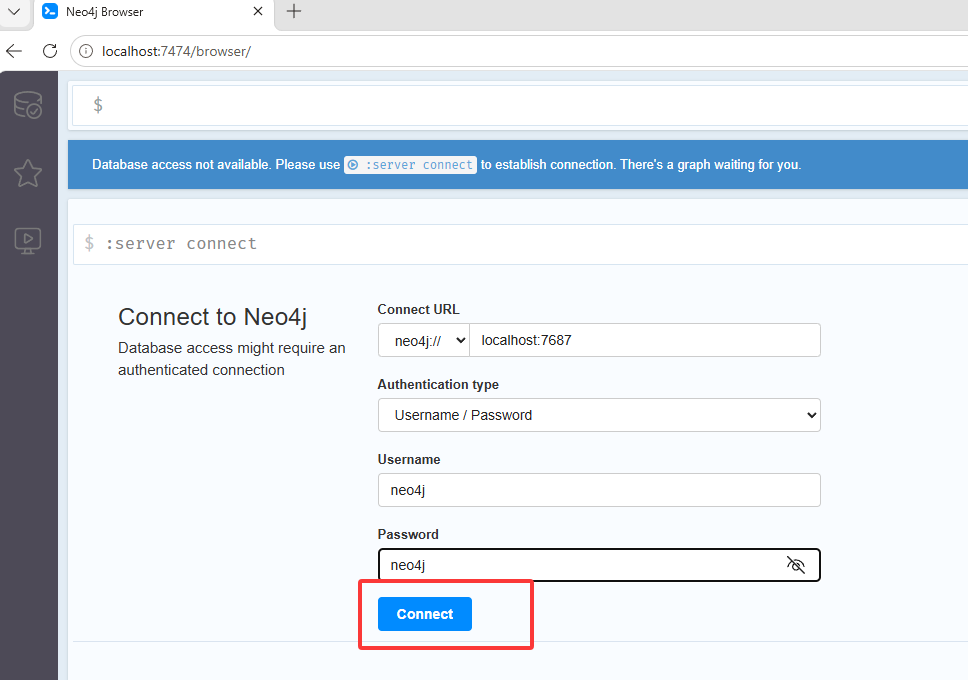
启动后就可以在浏览器输入http://localhost:7474/访问了,localhost表示本地电脑,对于的是127.0.0.1这个ip,注意下图的页面不要翻译成中文,它可能会报错
默认Username和Password都是neo4j,点击下图红框进行登录
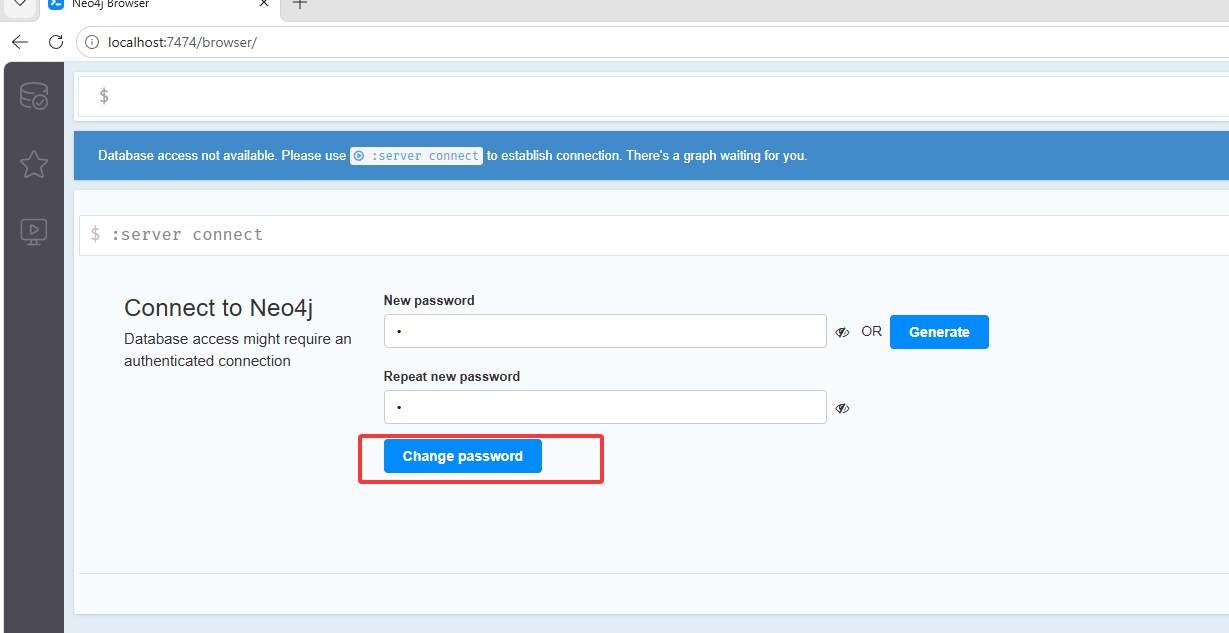
登录后它要改一个密码,这里的密码写的是11111111,不要忘记密码了
然后就可以使用了
使用代码连接neo4j,连接时要确保下图的内容已做好,也就是neo4j已启动
然后安装Python库
python -m pip install langchain_neo4j然后下载两个jar文件
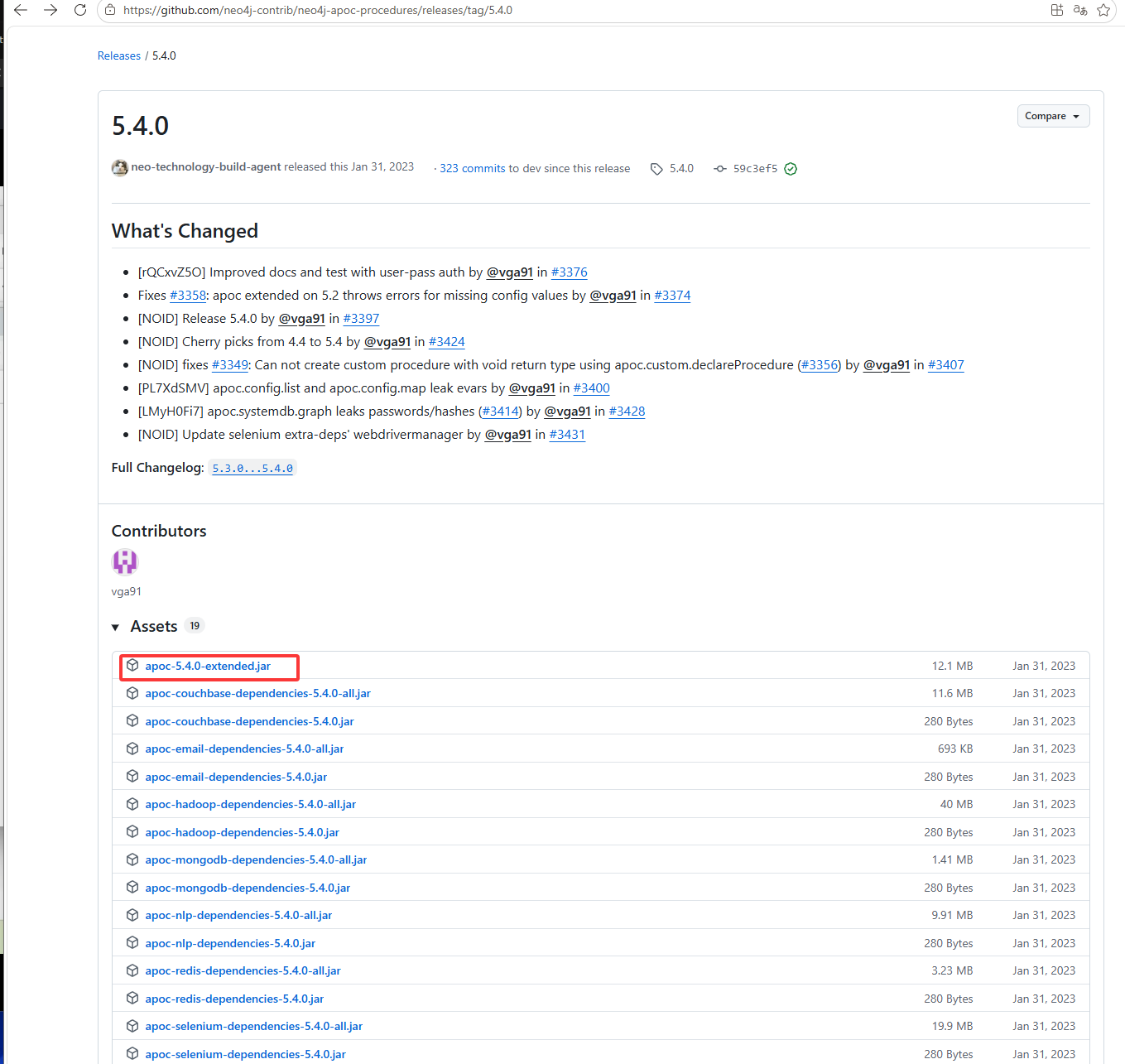
从下方连接找到对应版本的apoc-5.4.0-extended.jar
https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases/tag/5.4.0
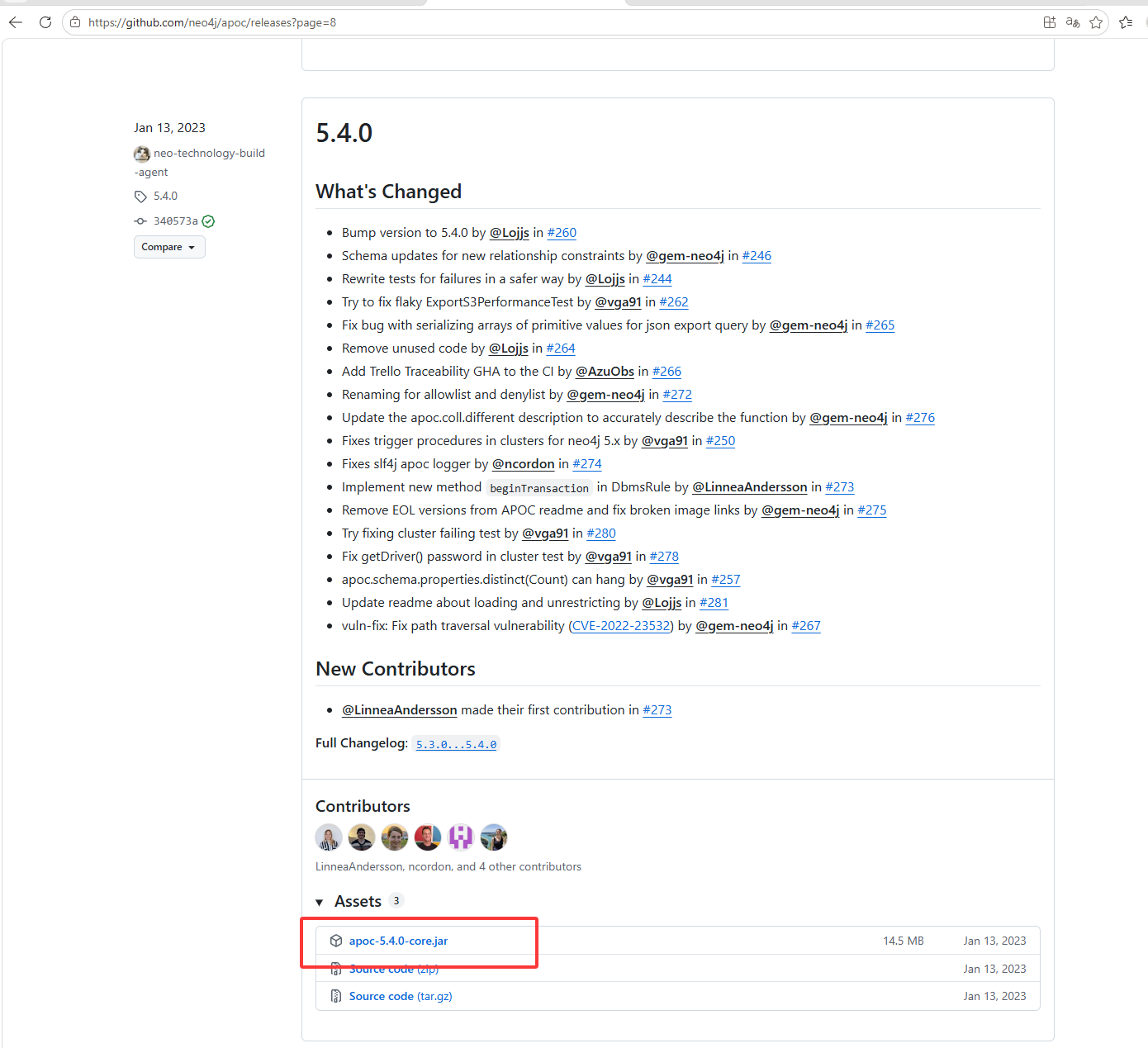
从下方连接找到对应apoc-5.4.x-core.jar
https://github.com/neo4j/apoc/releases
下方这个连接是找其它版本的apoc-xx-extended.jar文件
https://github.com/neo4j-contrib/neo4j-apoc-procedures/releases
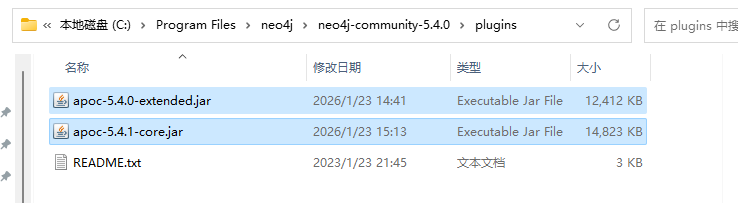
文件下载好后,放到下图的目录里neo4j安装目录中的plugins里
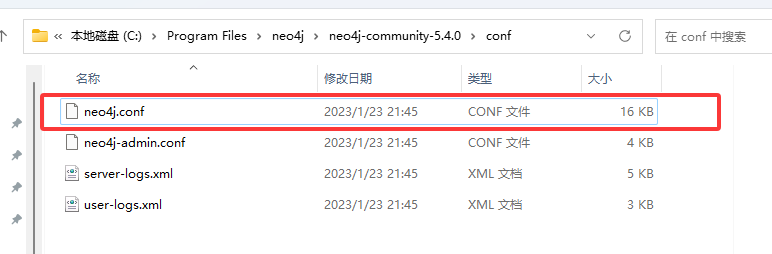
然后再修改下图红框的配置文件
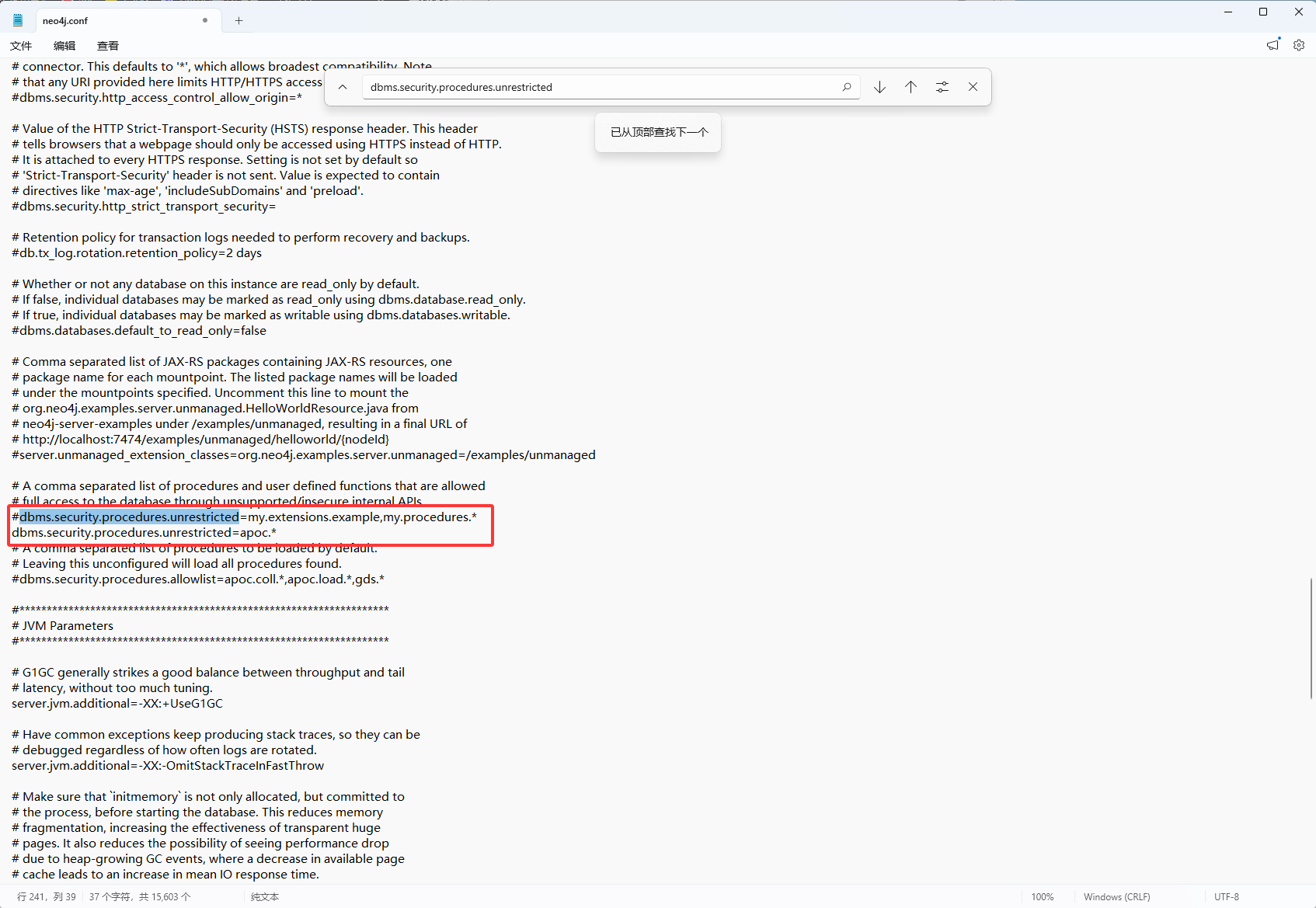
需要改
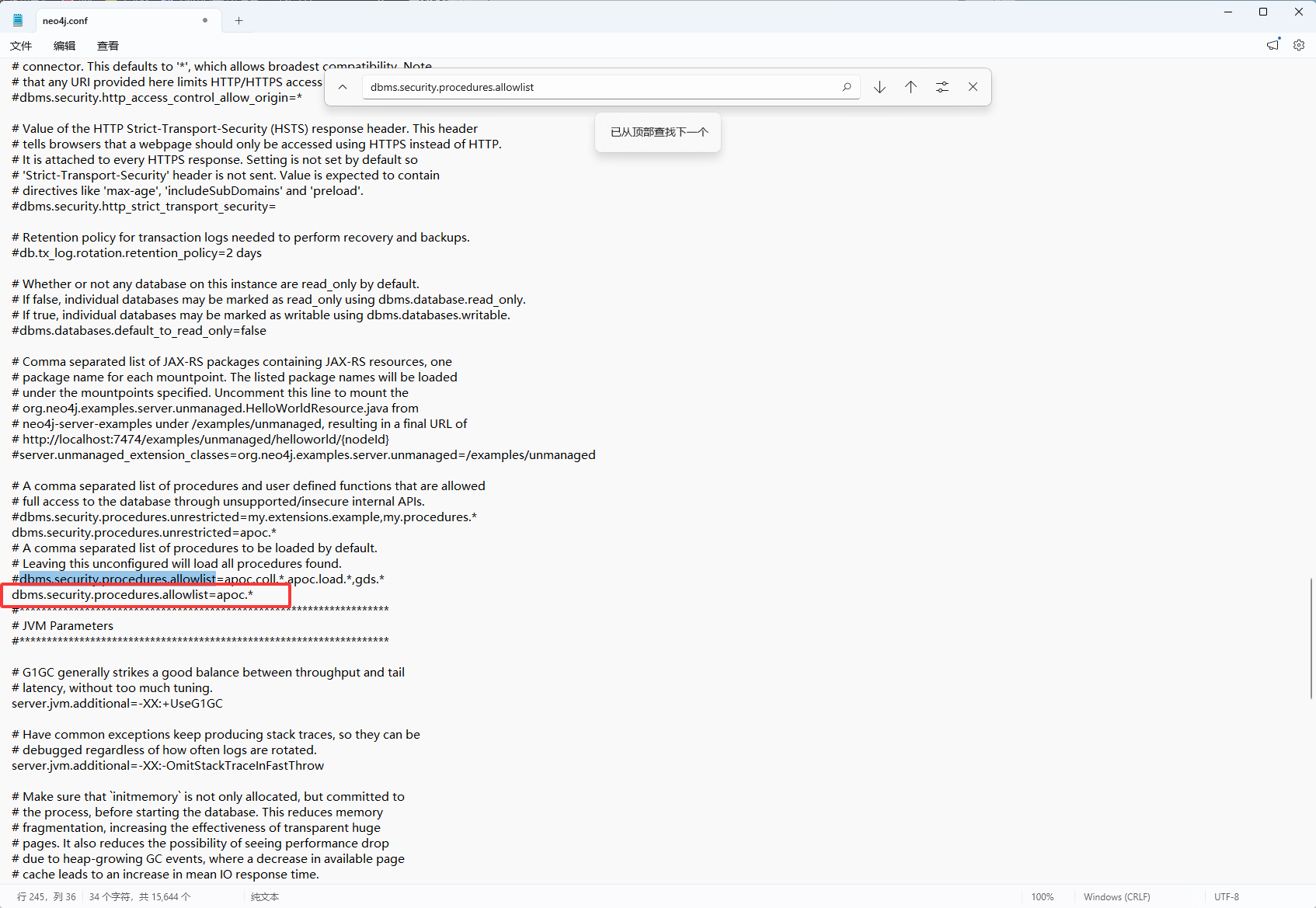
# 允许访问非限制性的过程(APOC需要) dbms.security.procedures.unrestricted=apoc.* # 允许所有的 APOC 过程 dbms.security.procedures.allowlist=apoc.*如下图修改unrestricted
如下图修改allowlist
设置好后如果neo4j已经运行了,需要进行重启,也就是把之前的cmd关了,重新打开一个然后执行neo4j console
代码
python# 从 langchain_neo4j 工具包中导入 Neo4jGraph 类 # 语法说明:from ... import ... 是 Python 的导入语法,从指定包里拿出需要的类/函数直接用 # 作用说明:Neo4jGraph 是 LangChain 官方封装好的 Neo4j 图数据库工具类 # 它帮我们简化了数据库连接、Cypher语句执行、知识图谱读写等操作,不用自己手写原生驱动代码 from langchain_neo4j import Neo4jGraph # 定义常量:Neo4j 数据库的连接地址(统一资源标识符 URI) # 命名全大写是 Python 约定:表示这是固定不变的常量,不要在运行中修改 # bolt 是 Neo4j 专用的二进制通信协议,传输效率比 http 更高,是连接 Neo4j 的标准协议 # localhost 表示数据库运行在你本地电脑上;7687 是 Neo4j Bolt 协议的默认端口号 NEO4J_URI = "bolt://localhost:7687" # 定义常量:Neo4j 数据库的登录用户名 # Neo4j 安装后默认的初始用户名就是 neo4j,如果你没改过就用这个 NEO4J_USERNAME = "neo4j" # 定义常量:Neo4j 数据库的登录密码 # 为什么单独抽出来写成常量:方便统一修改配置,不用在业务代码里到处找密码,也符合「配置和代码分离」的规范 # 注意:实际使用时要把这里的值换成你自己本地数据库设置的密码 NEO4J_PASSWORD = "11111111" # 替换为你的密码 # 创建 Neo4j 数据库连接实例,赋值给 graph 变量 # 后续所有对图数据库的操作(增删改查、构建知识图谱、图检索等)都通过这个 graph 对象来调用 # 执行成功后,graph 就是一个已连接的图数据库操作对象,类型为 Neo4jGraph graph = Neo4jGraph( url=NEO4J_URI, # 入参 url:数据库的完整连接地址,传入上面定义的 NEO4J_URI 常量 username=NEO4J_USERNAME, # 入参 username:数据库登录用户名,传入上面定义的用户名常量 password=NEO4J_PASSWORD # 入参 password:数据库登录密码,传入上面定义的密码常量 )Neo4j使用的是CQL语言
使用和创建节点:
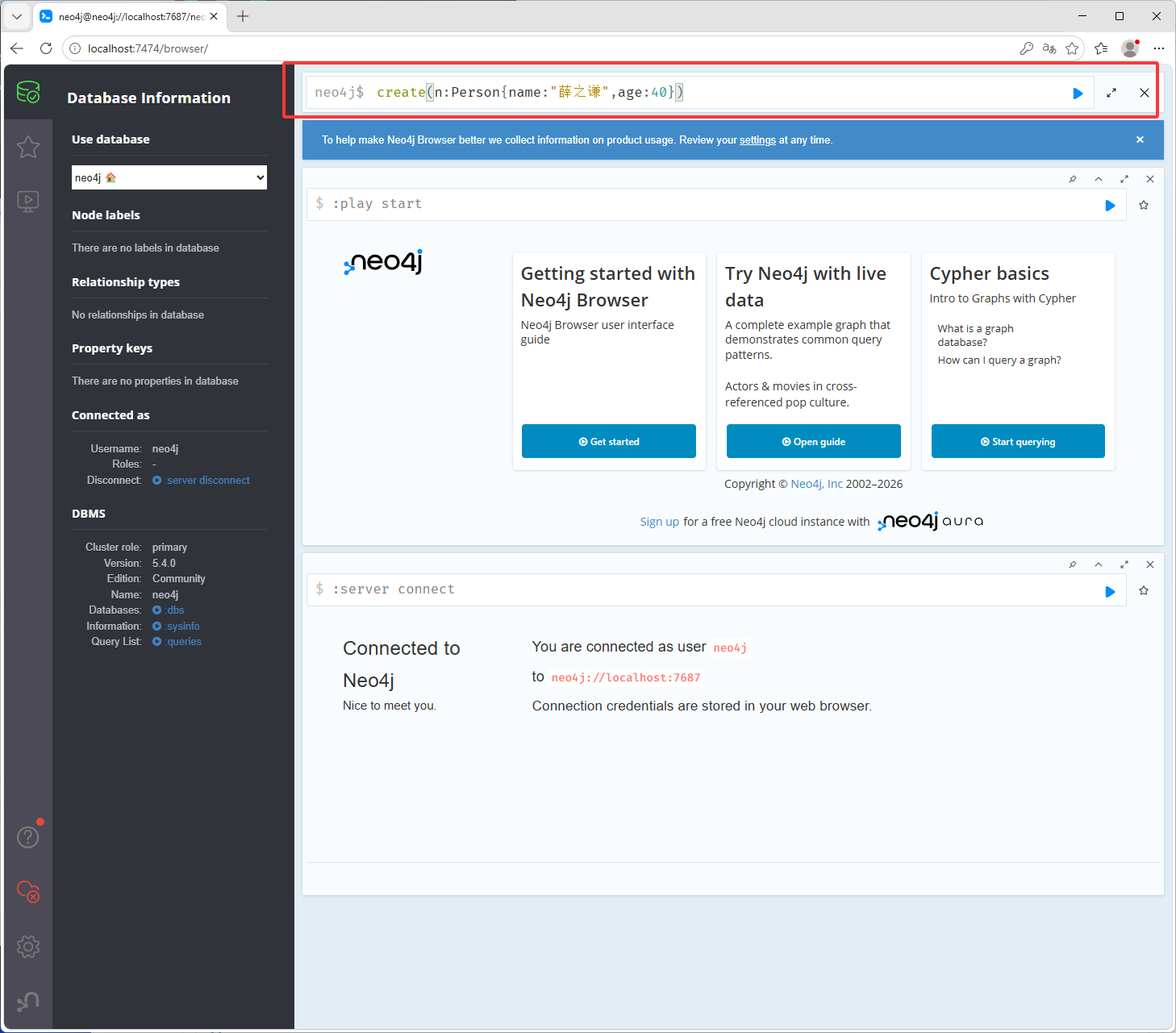
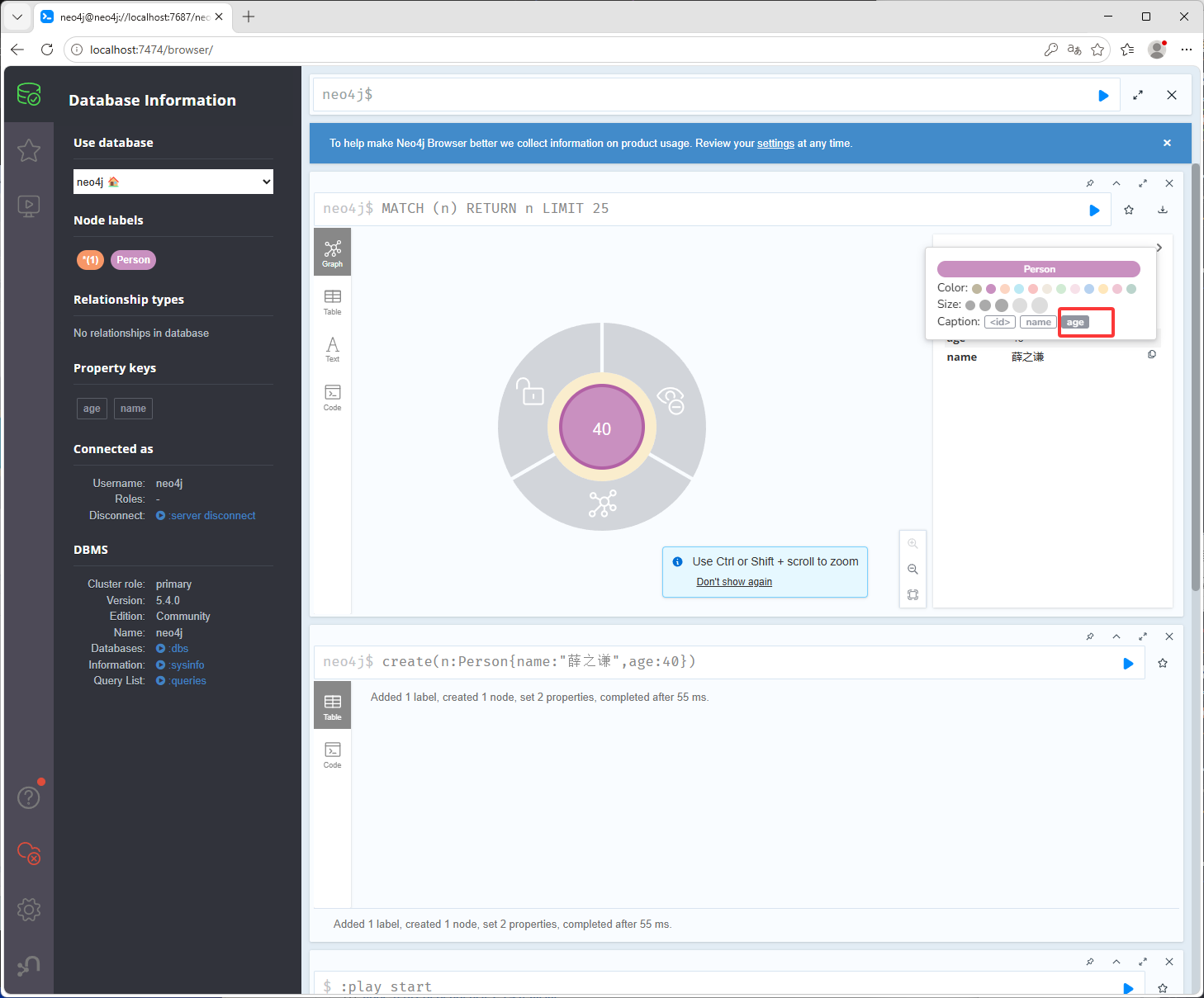
执行命令 create(n:Person{name:"薛之谦",age:40}) 创建一个节点和属性n是节点的名字(这里的n是个临时的执行完后就没用了,可以理解为一个变量,在命令中使用),n有一个Person的标签,节点属性有name和age,也就是名字和年龄,名字是薛之谦,年龄是40岁,在下图红框位置输入命令,也就是说一个括号表示一个节点,括号里面可以写节点名字,节点属性信息,节点标签,按shift加回车(Enter)键可以换行
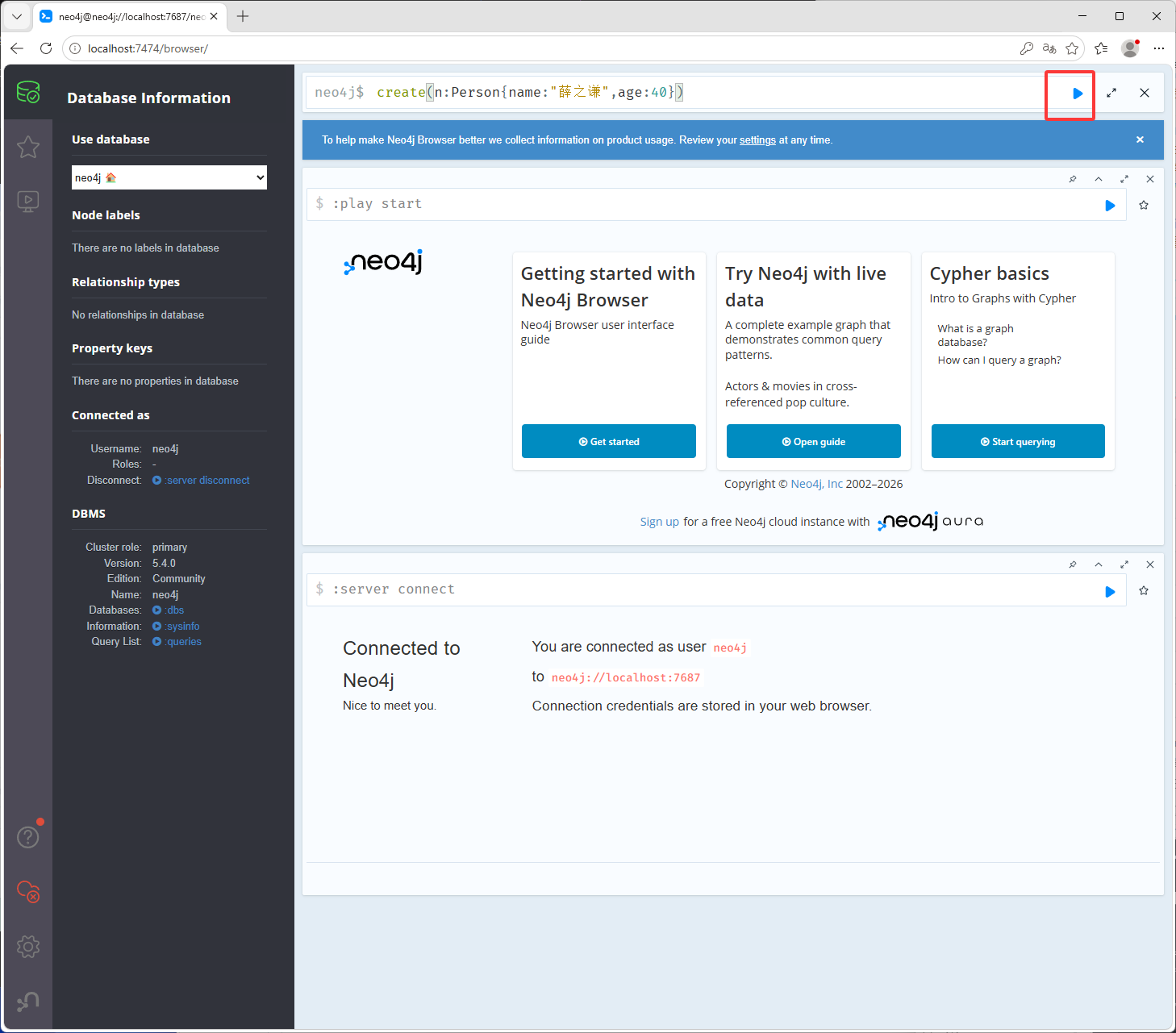
按CTRL加回车(Enter)键或点击下图红框,就可以执行了
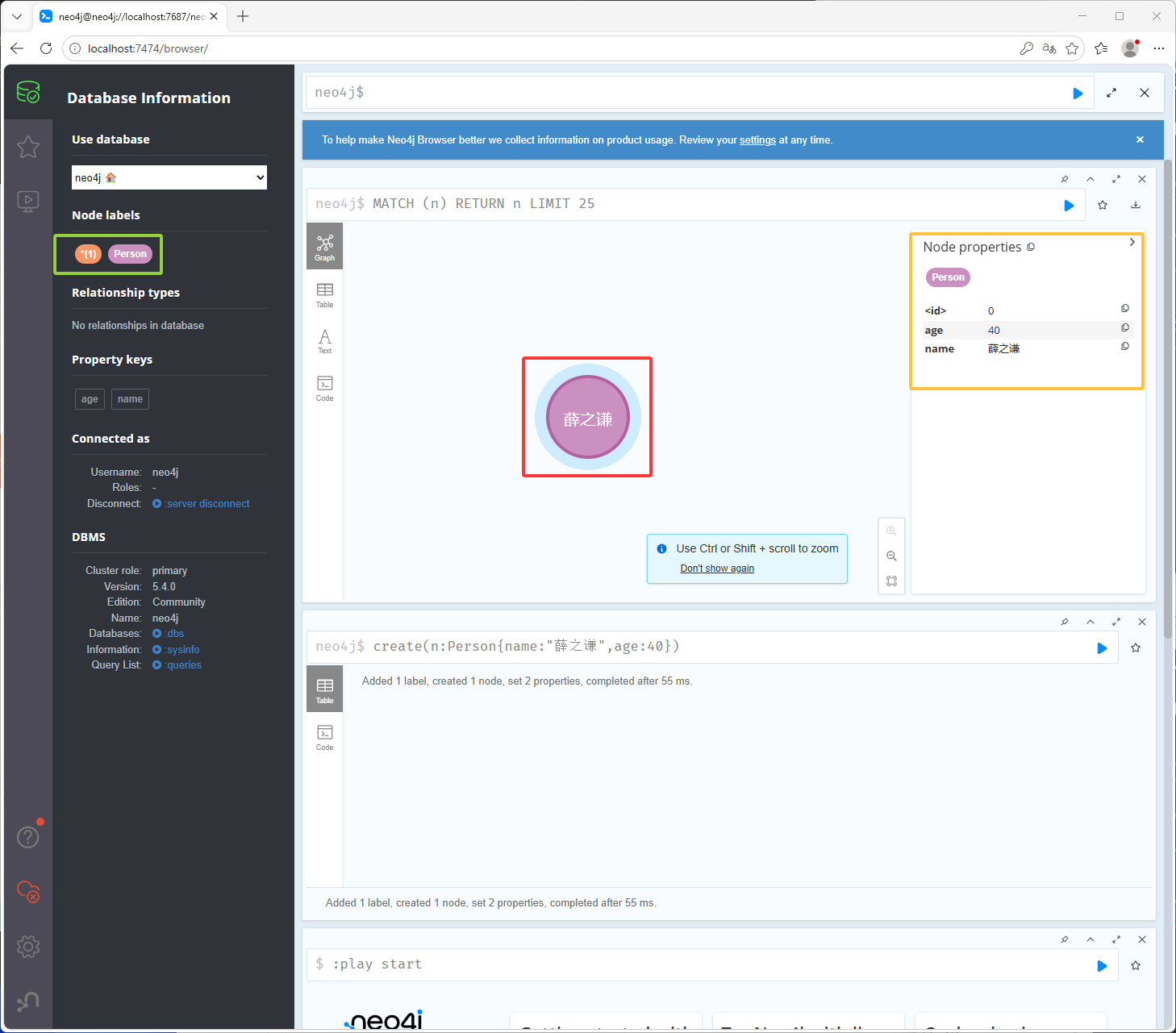
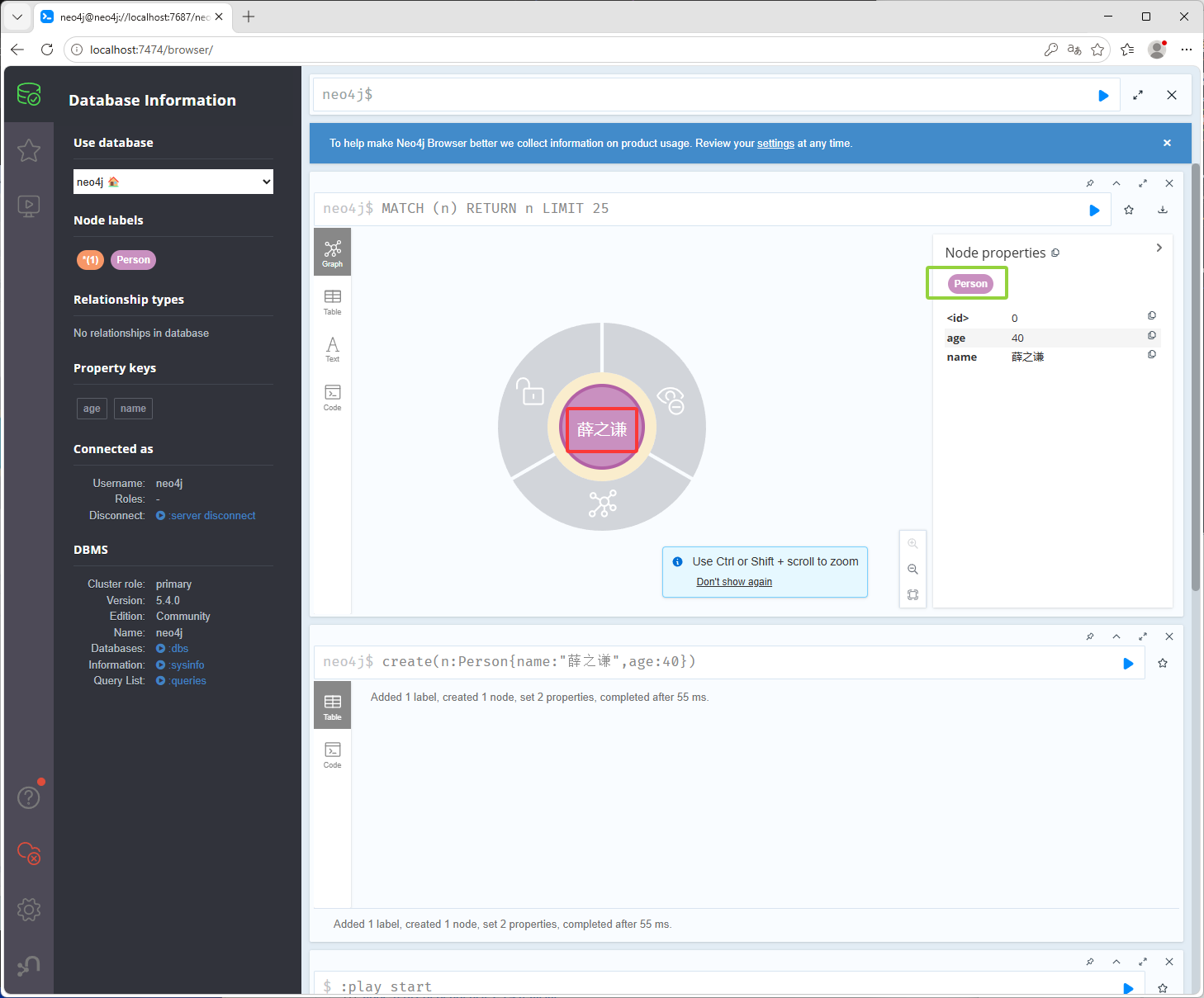
下图绿框是节点的标签,鼠标放到下图红框位置或点击下图红框位置可以看到下图黄框的内容,绿框位置的*表示所有节点Person是我们刚刚创建的标签,可以看到下图黄框它有一个默认的id值为0
下图红框显示的内容,可以通过点击下图绿框进行修改
点击下图红框位置就会显示age的值了,也就是年龄
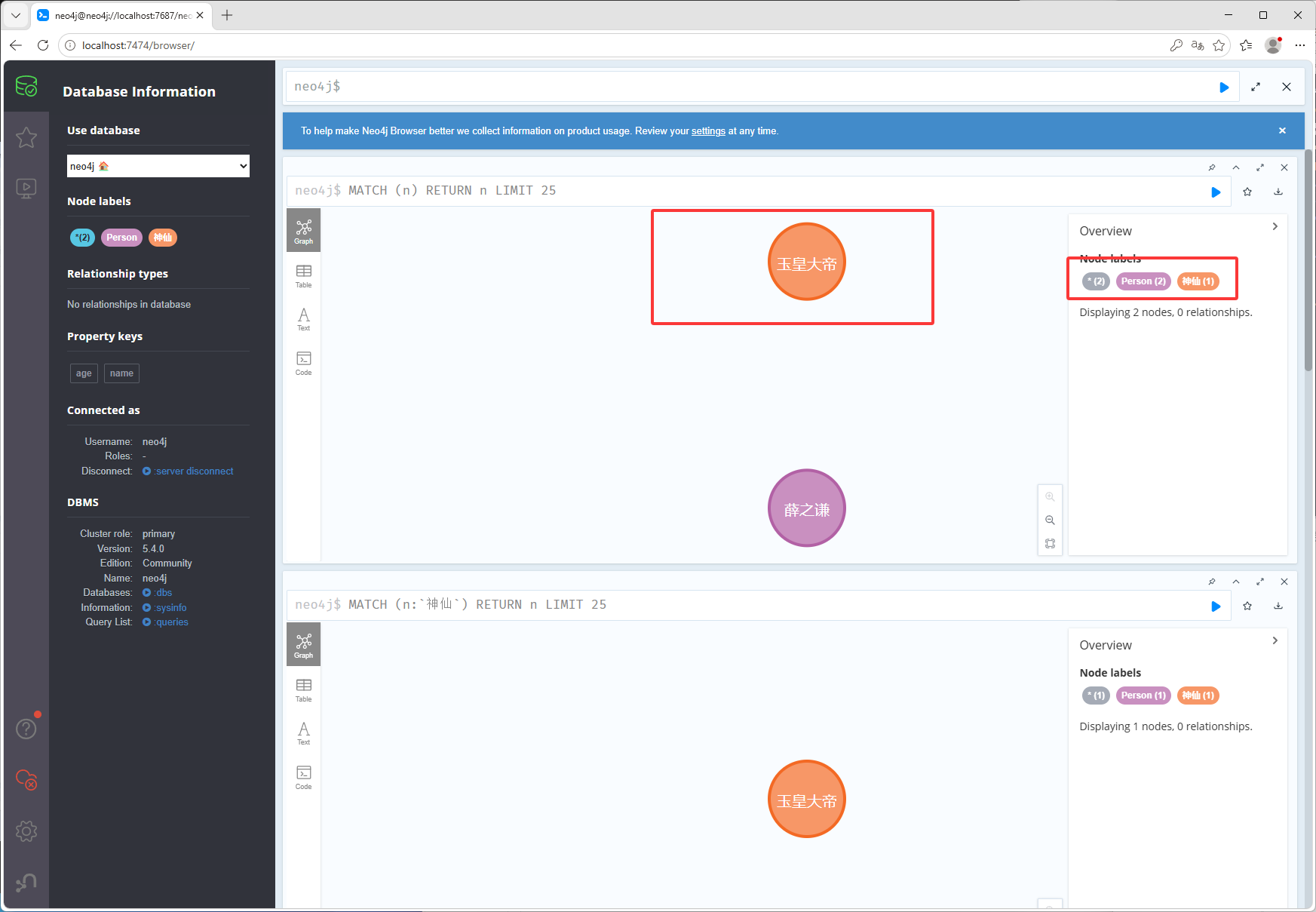
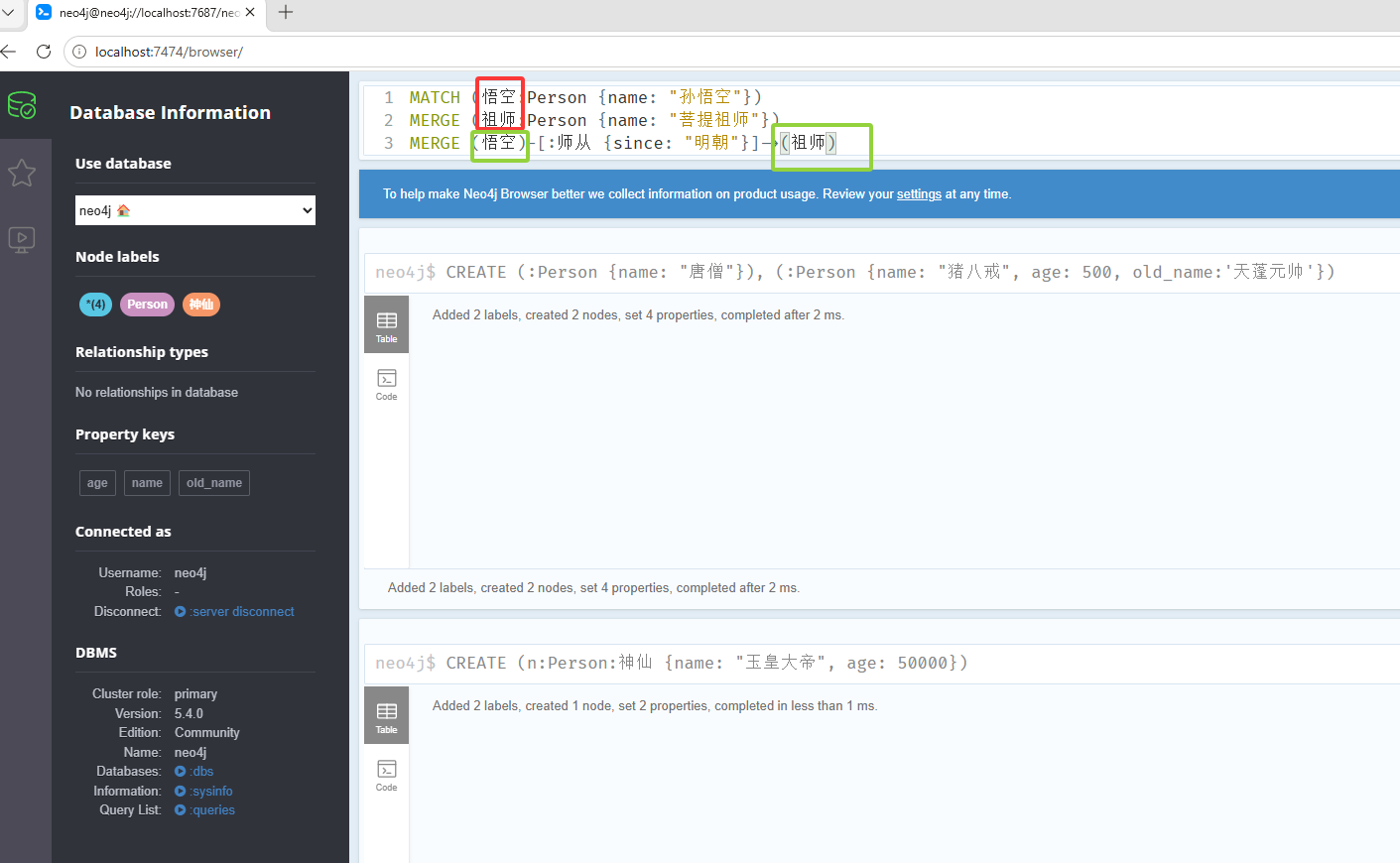
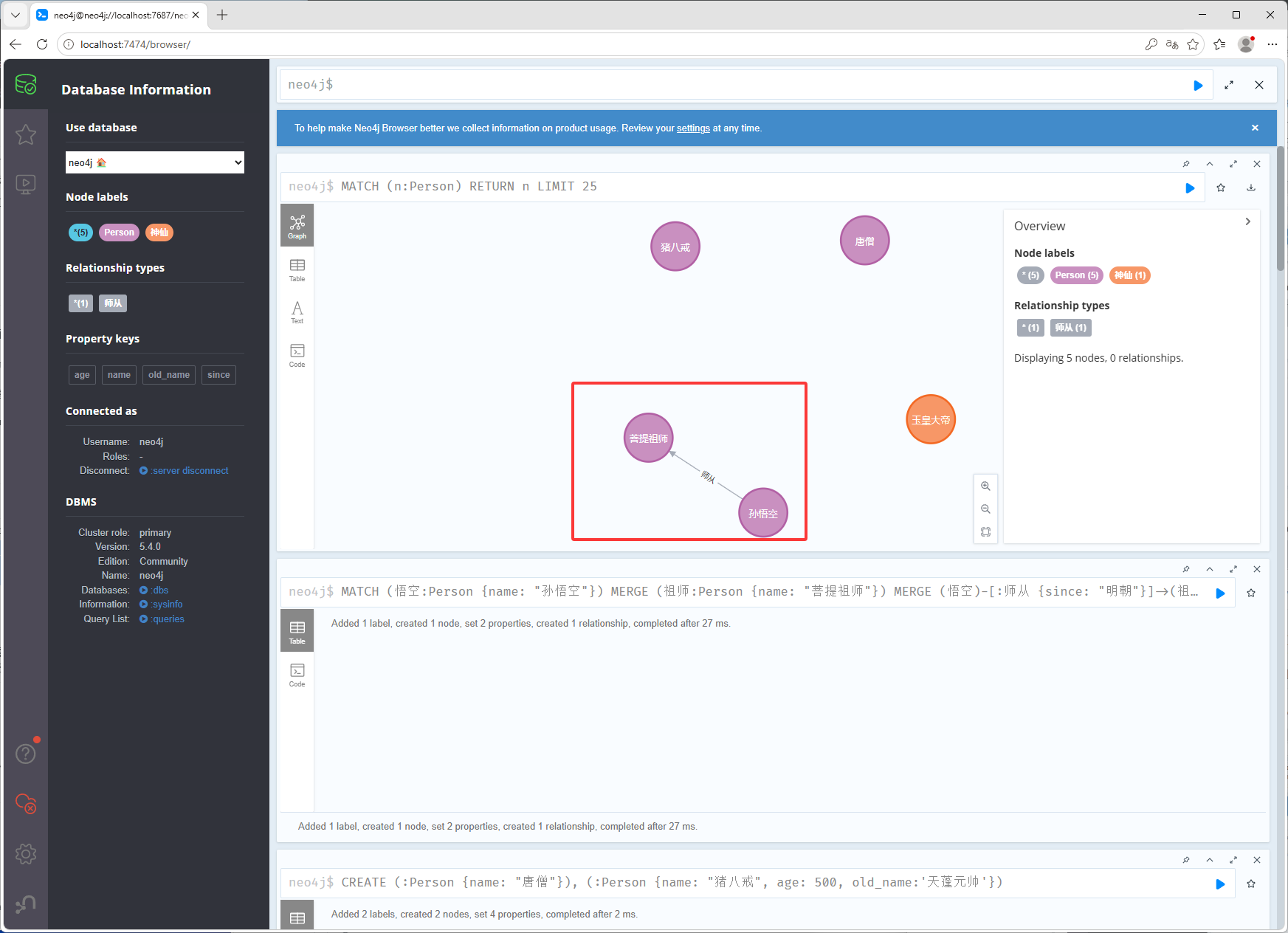
以上就是创建节点,创建多标签CREATE (n:Person:神仙 {name: "玉皇大帝", age: 50000}),如下图它有Person标签和神仙标签
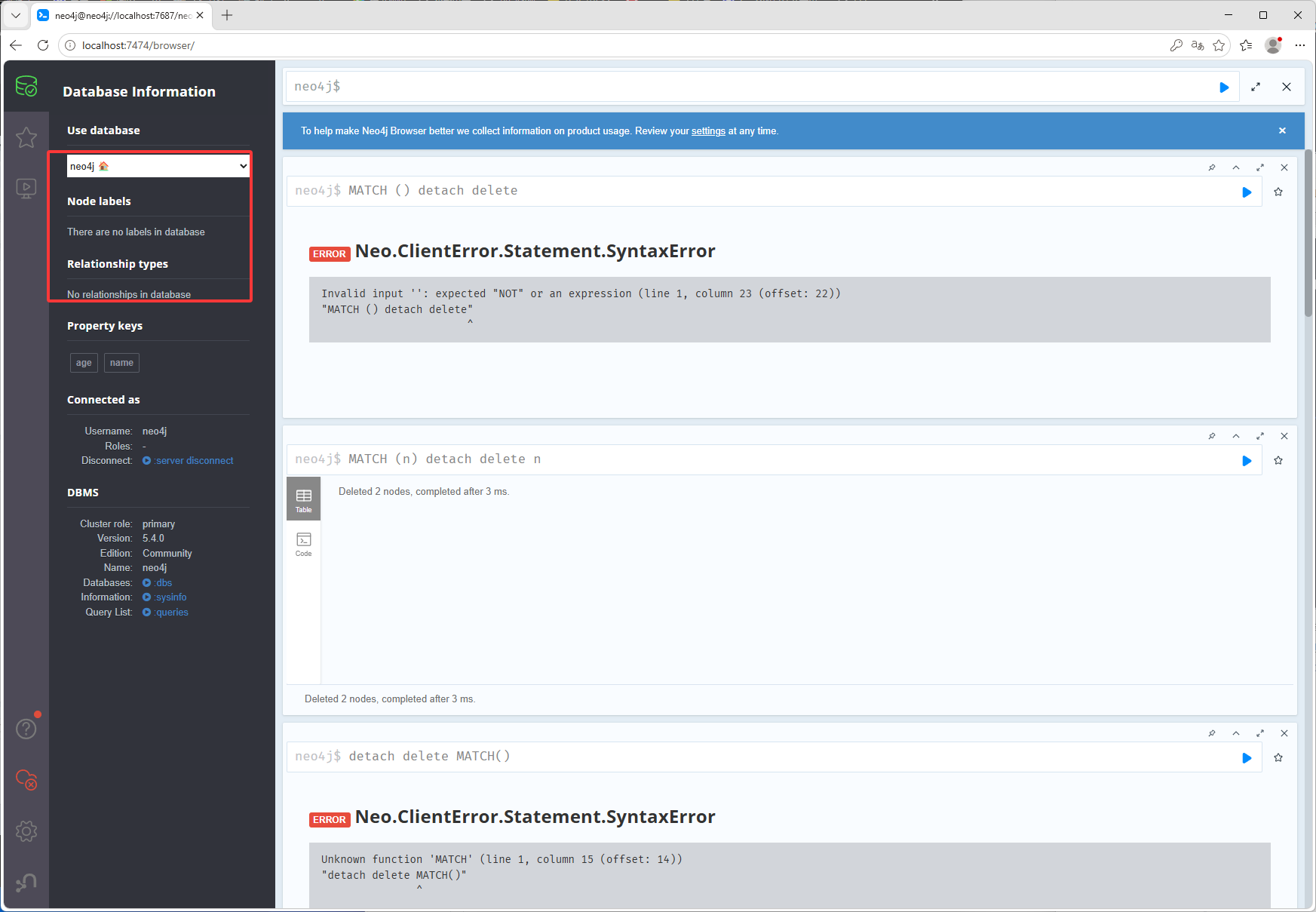
上方用到了一个n有点抽象这里给试一下,MATCH (n) detach delete n 这个命令MATCH()表示所有节点,detach delete是删除节点,删除什么节点呢?MATCH(n)括号里写一个n,然后这个n就是所有的节点,然后把这个n给到detach delete,也就是detach delete n 这样就是删除所有节点了,相当于 这样的写法detach delete MATCH(),但是这是一个没办法执行的指令,只能MATCH (n) detach delete n这样写,如下图就把所有节点全删了
注意使用CREATE它会重复创建已有的数据,如果已有的数据不想重复创建需要下方的写法
// 查询name属性是孙悟空的节点,查询出来给到悟空变量 MATCH (悟空:Person {name: "孙悟空"}) // MERGE 如果不存在就创建,存在就复用 MERGE (祖师:Person {name: "菩提祖师"}) MERGE (悟空)-[:师从 {since: "明朝"}]->(祖师)如下图红框是一个变量(相当于上方的n),绿框是使用变量,创建线的语法是
(a)-变量:边的名字{边的属性:"xxx"}->(b),也就是下图里的 MERGE (悟空)-:师从 {since: "明朝"}->(祖师)
如下图
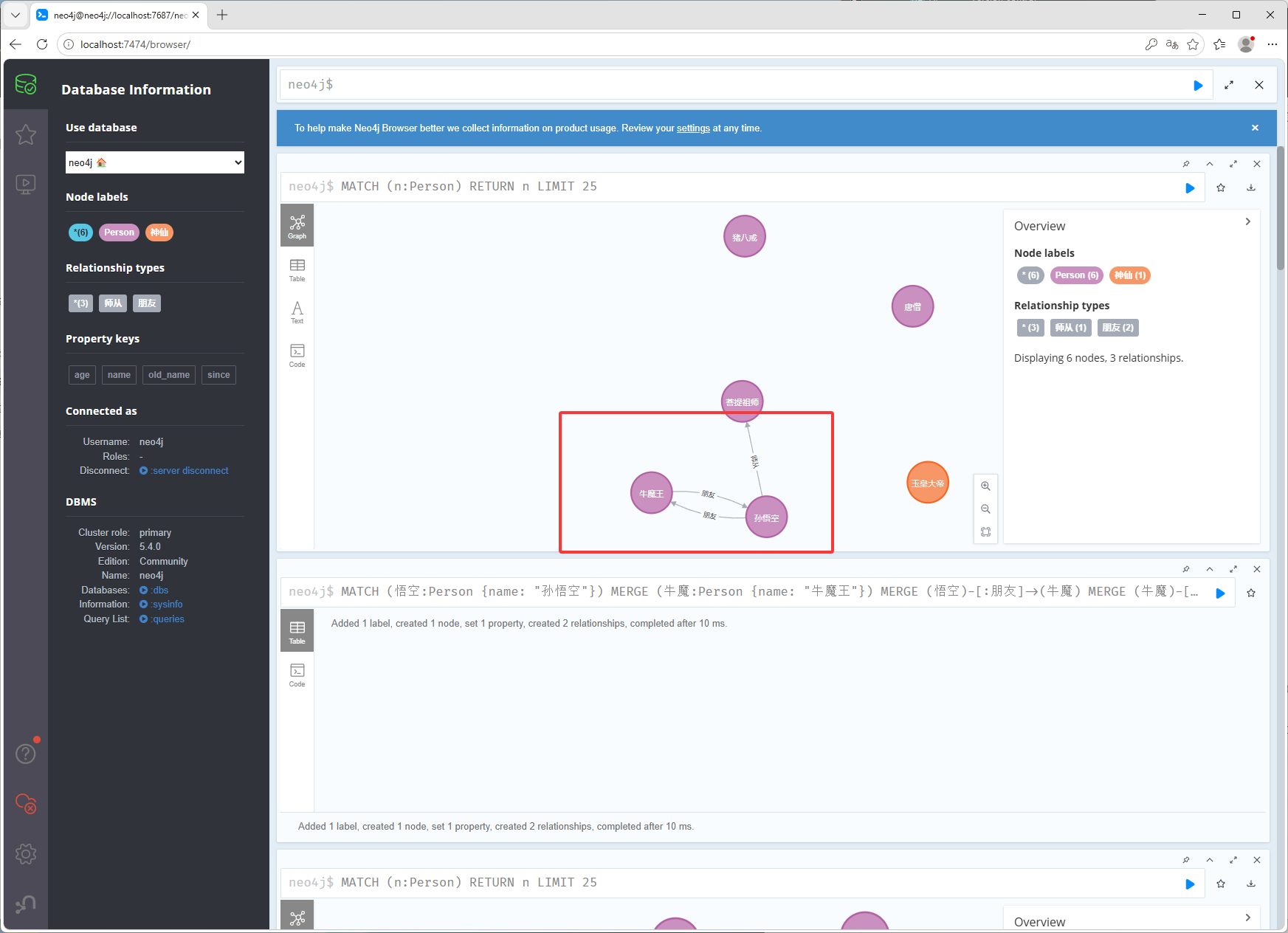
创建双向关系
MATCH (悟空:Person {name: "孙悟空"}) MERGE (牛魔:Person {name: "牛魔王"}) MERGE (悟空)-[:朋友]->(牛魔) MERGE (牛魔)-[:朋友]->(悟空)如下图红框,注意牛魔王之前是没有的,通过MERGE质量创建的
查询节点:
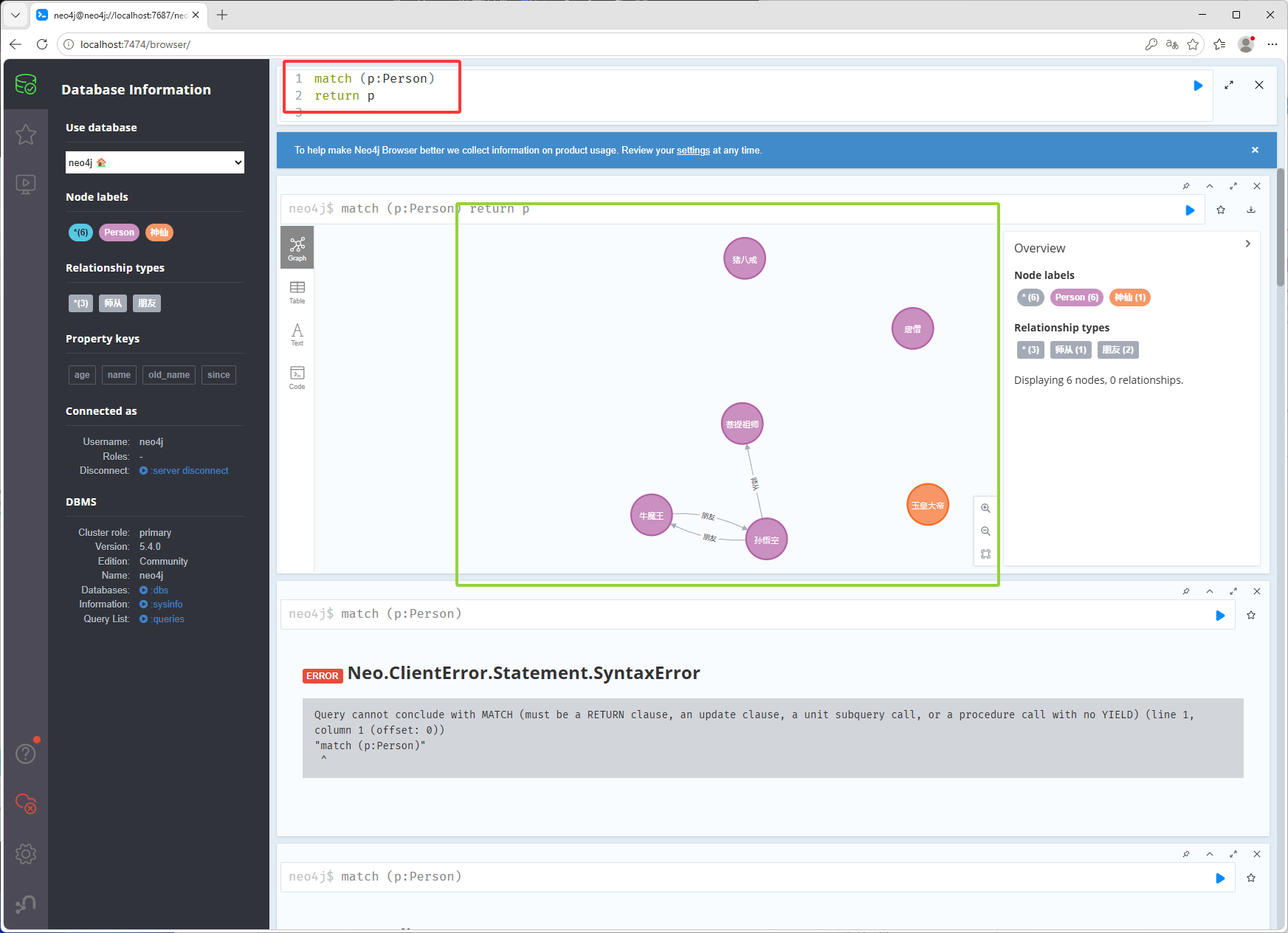
查询所有person标签下的节点
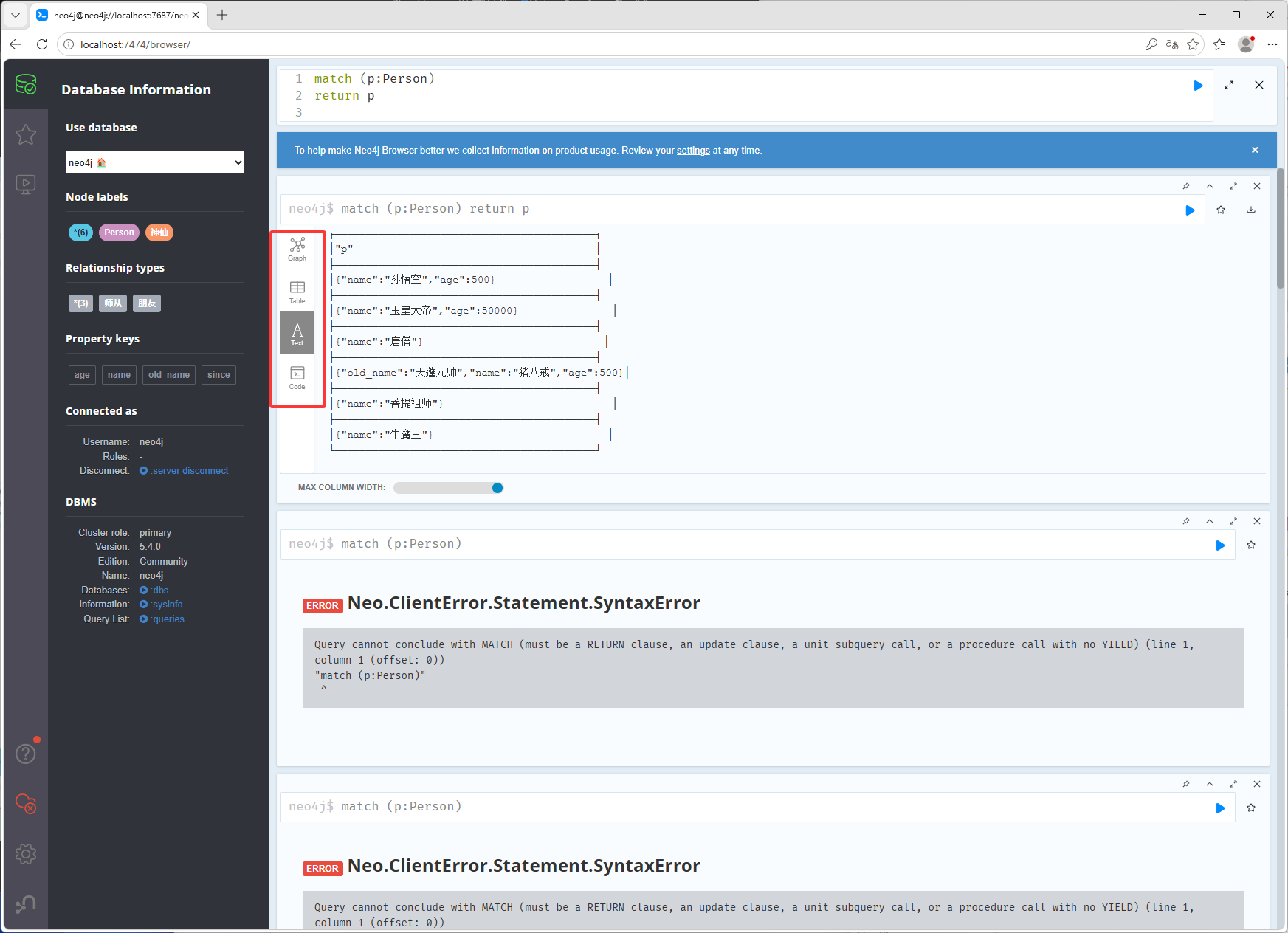
match (p:Person) return p点击下图红框可以查看其它的数据形式
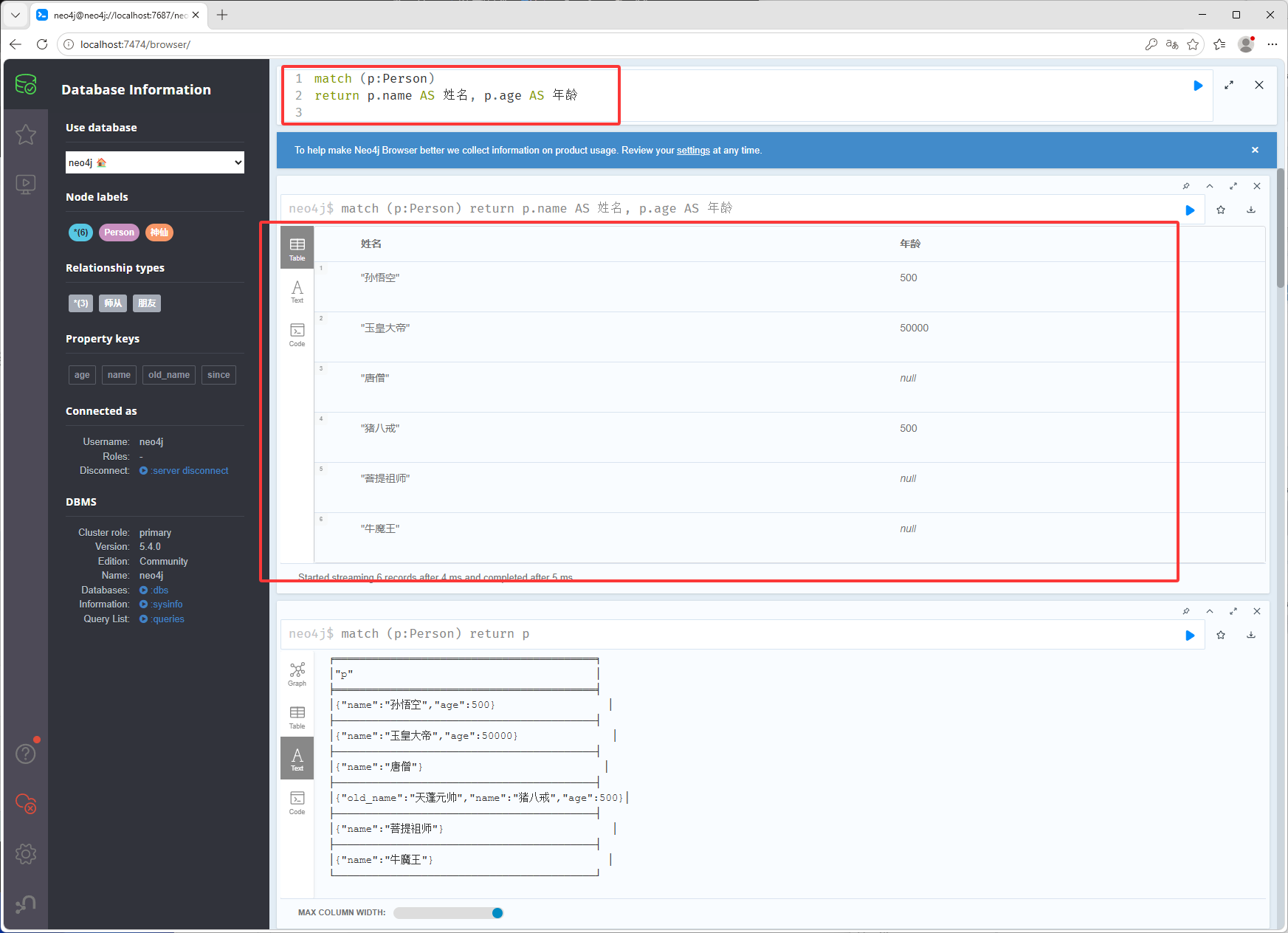
如下图只返回姓名和年龄
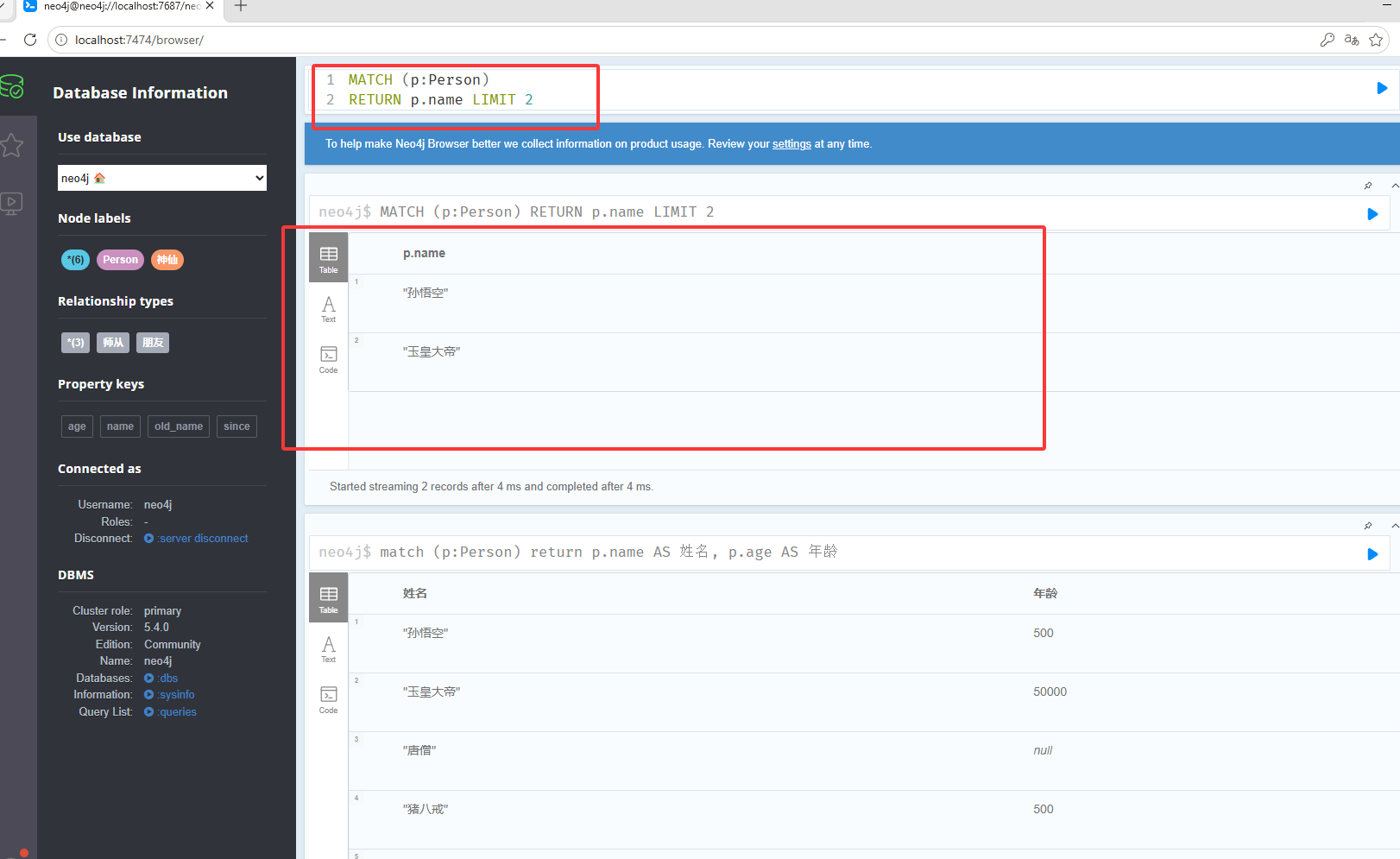
match (p:Person) return p.name AS 姓名, p.age AS 年龄限制数量前两天数据
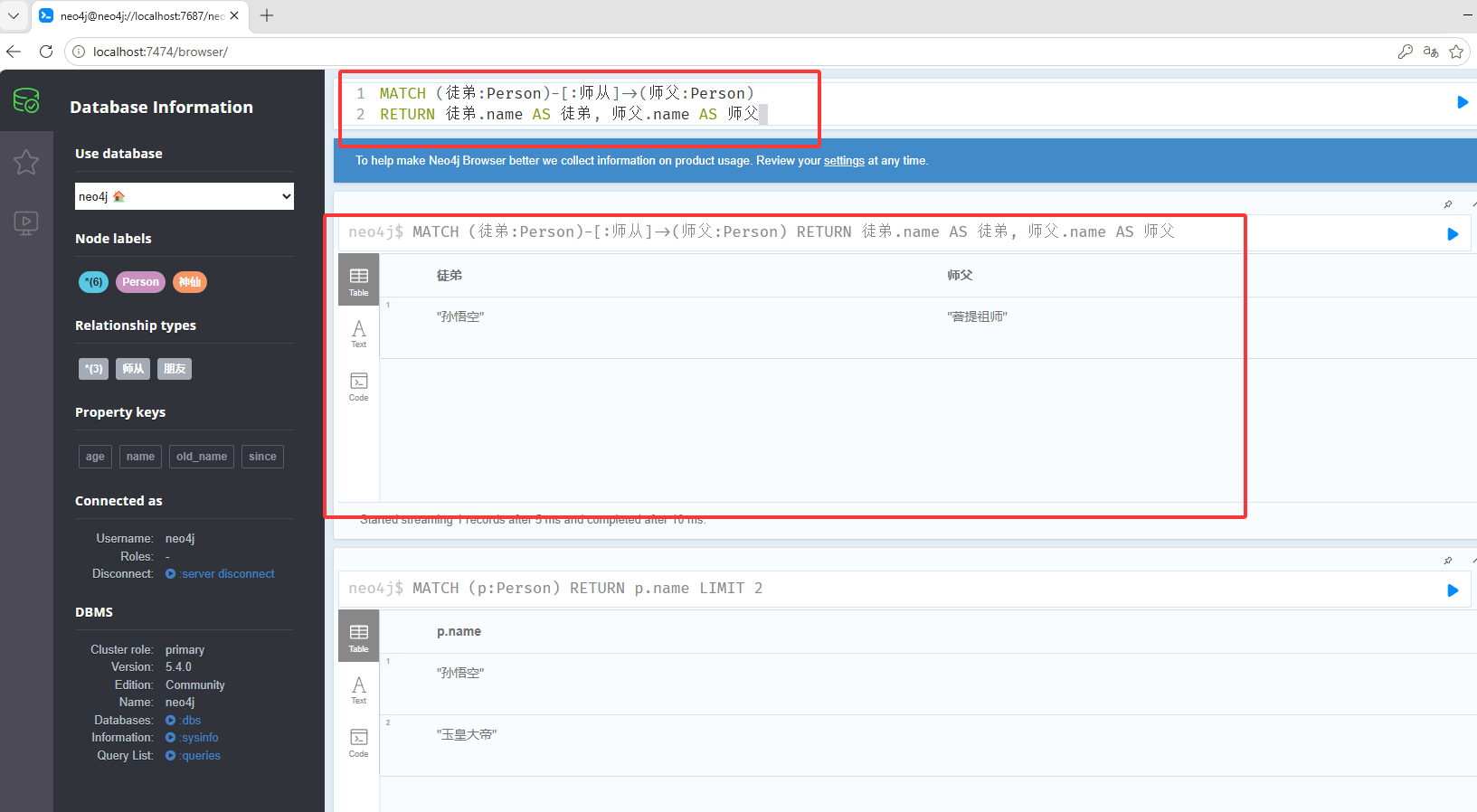
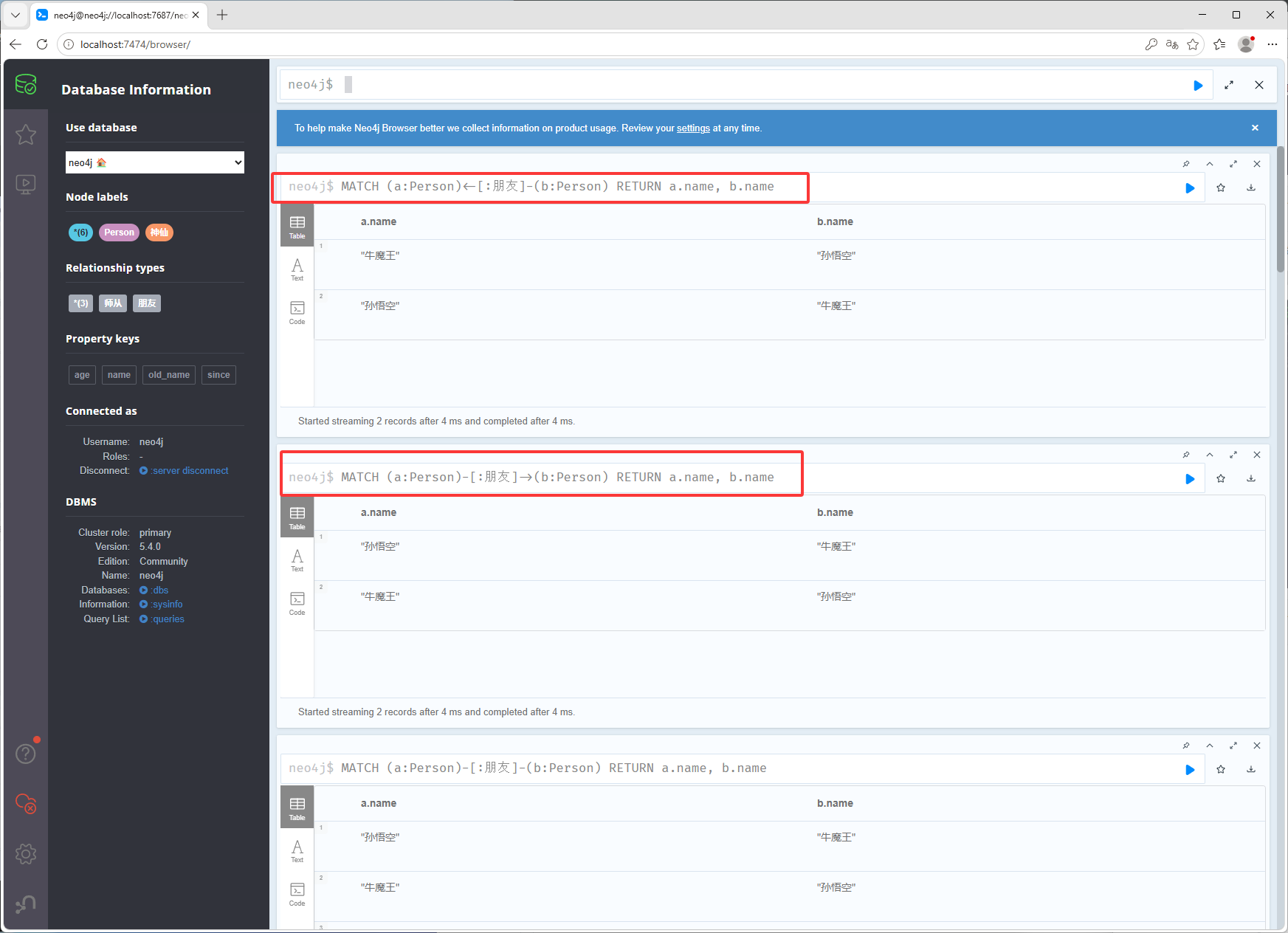
MATCH (p:Person) RETURN p.name LIMIT 5根据关系查找,MATCH (徒弟:Person)-:师从->(师父:Person),表示查询(徒弟:Person)标签,-:师傅->边的名字,(师父:Person)标签,也就是说从Person中查找师从关系的节点
MATCH (徒弟:Person)-[:师从]->(师父:Person) RETURN 徒弟.name AS 徒弟, 师父.name AS 师父双向关系
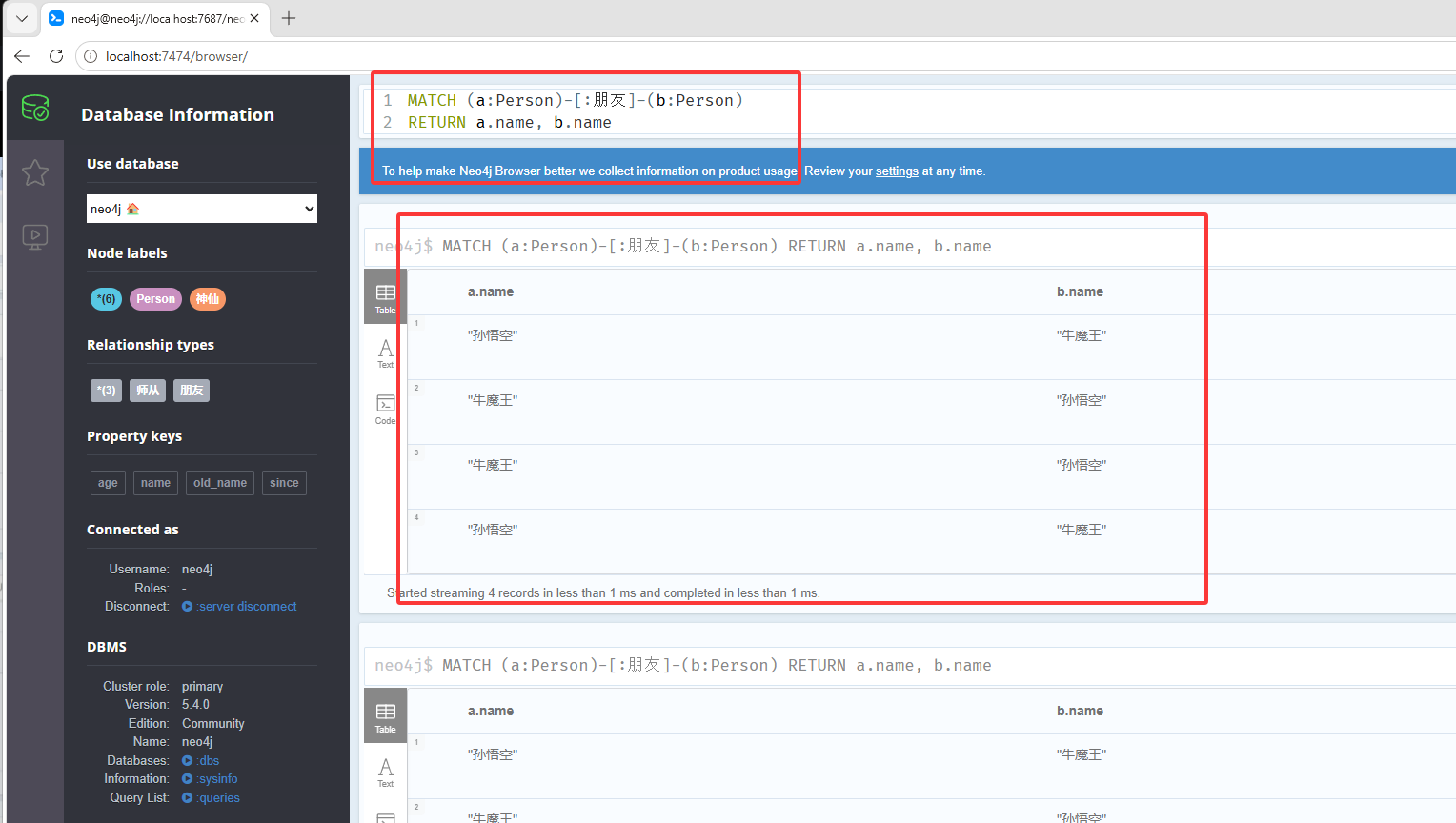
如果只要一组可以如下图红框的写法
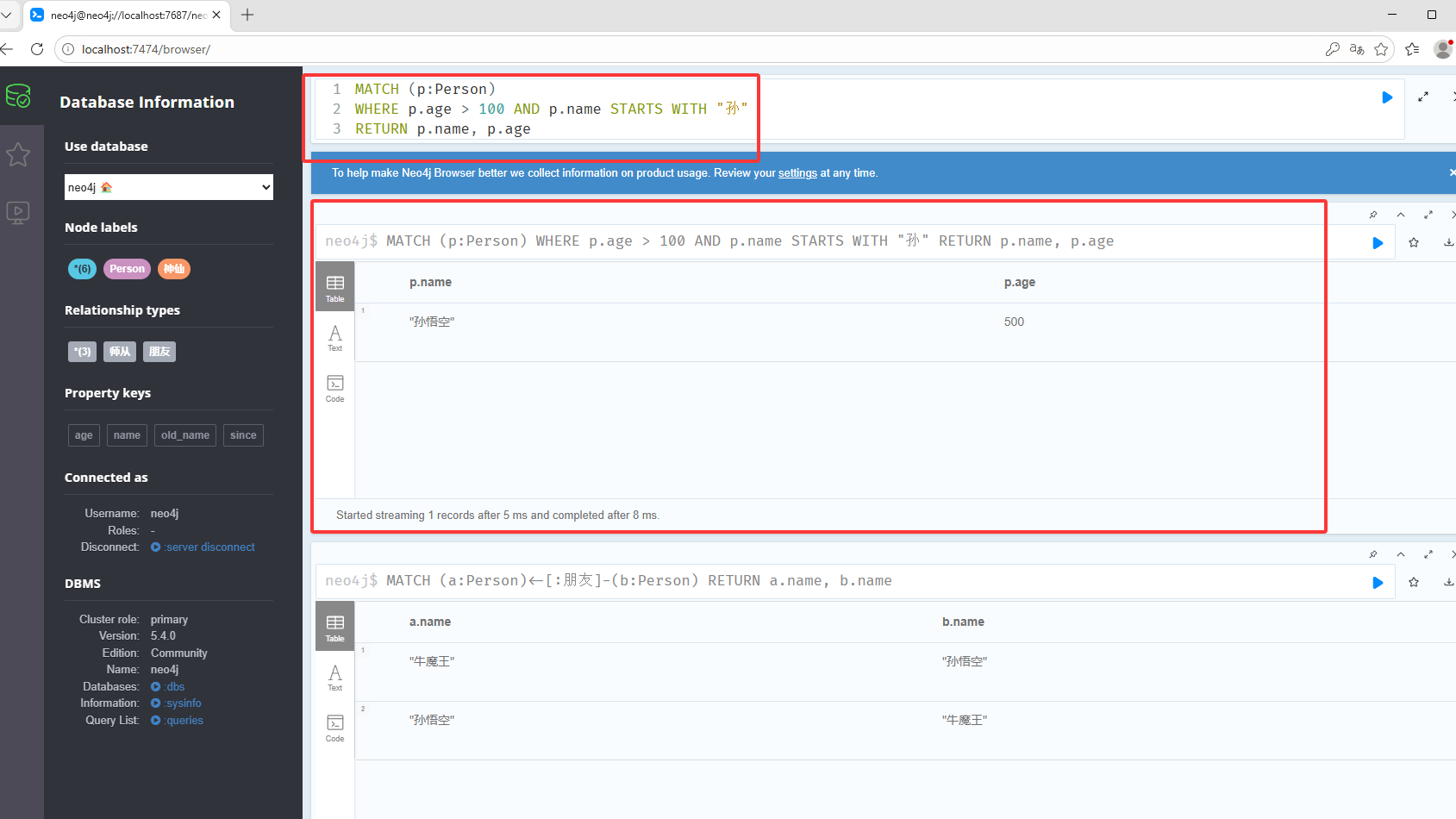
MATCH (a:Person)-[:朋友]-(b:Person) RETURN a.name, b.name条件查询WHERE,如下查询年龄大于100,姓名中包含孙的节点
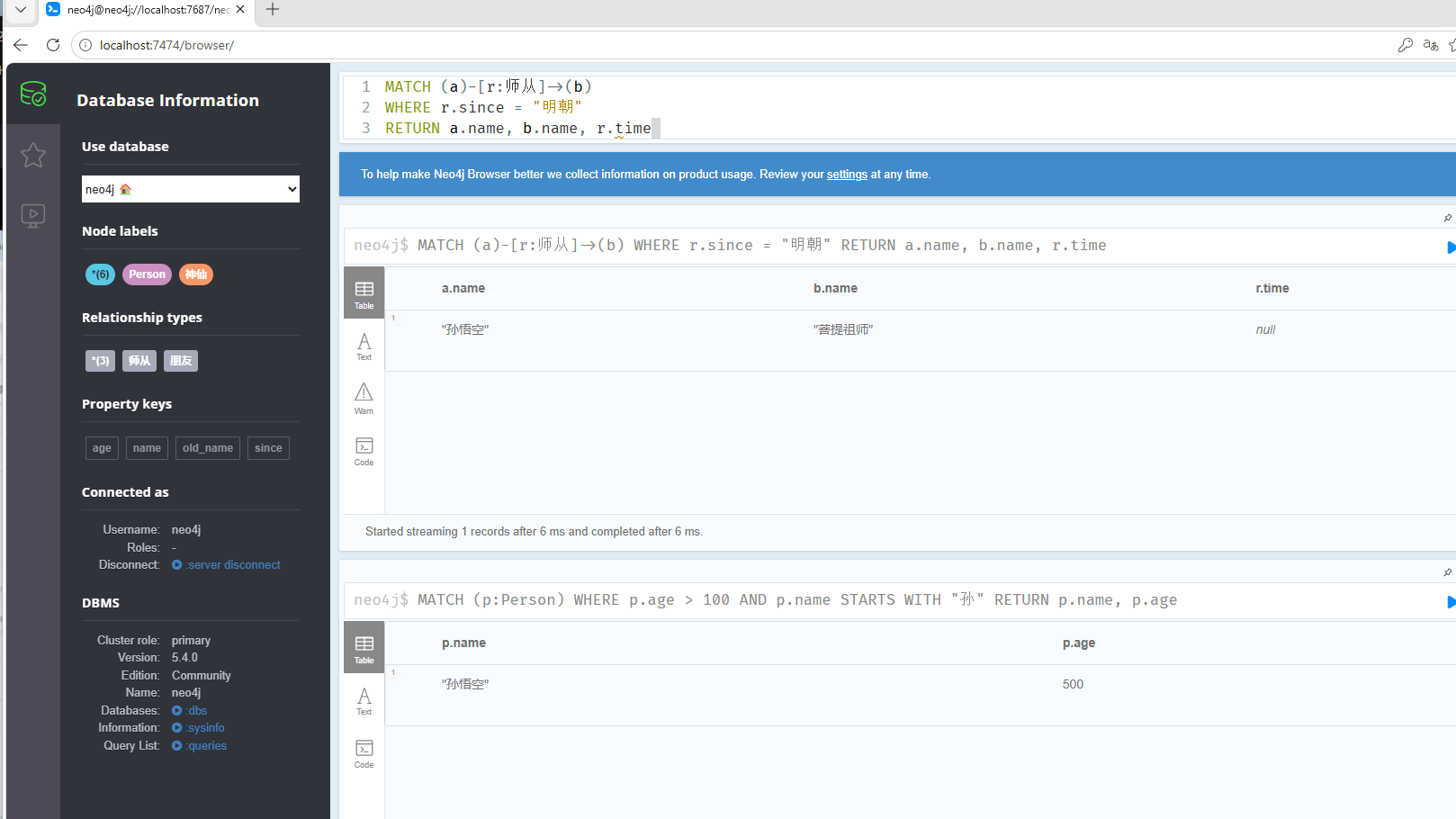
MATCH (p:Person) WHERE p.age > 100 AND p.name STARTS WITH "孙" RETURN p.name, p.age查找关系,关系中的since属性值为明朝的数据
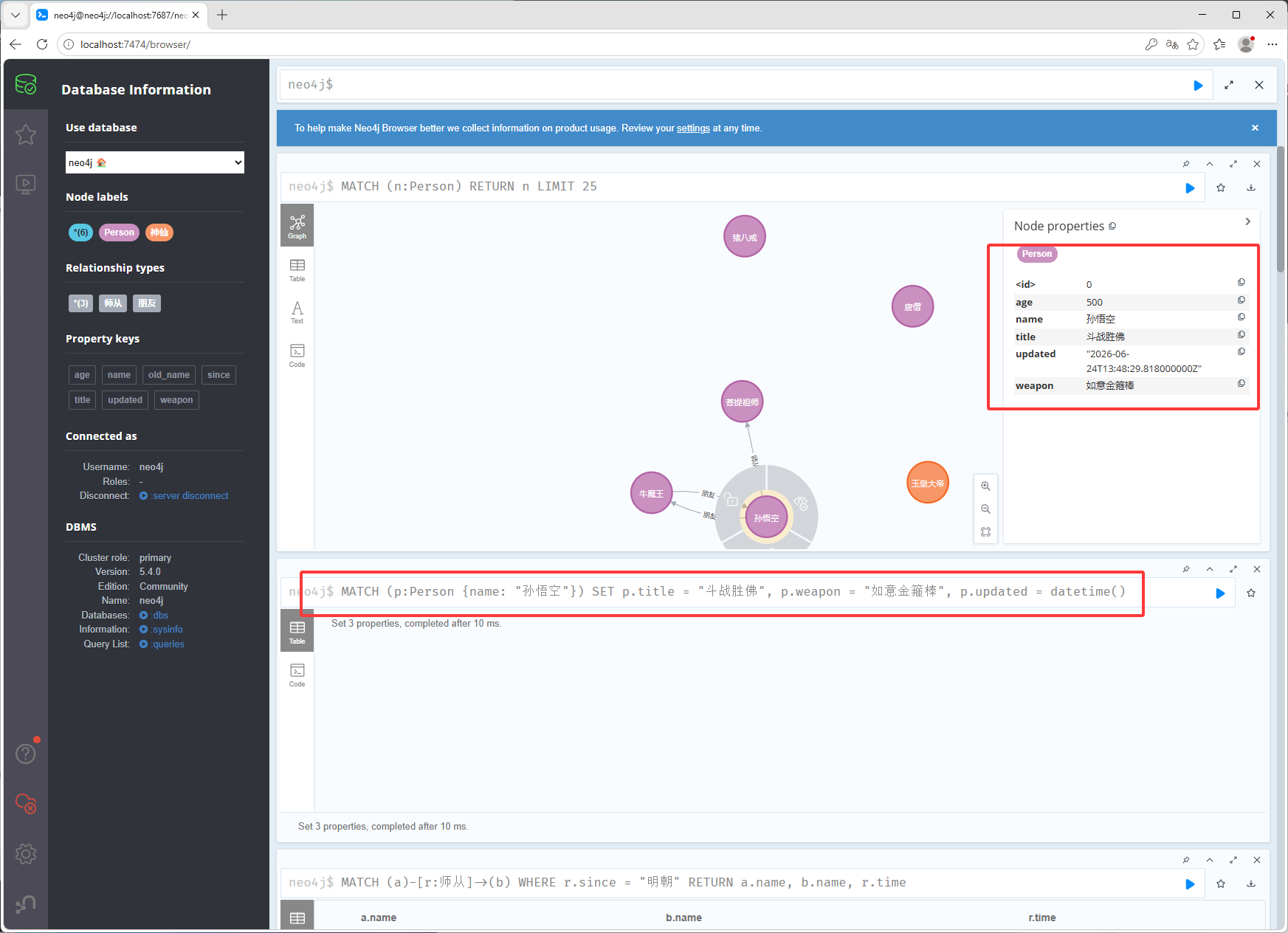
MATCH (a)-[r:师从]->(b) WHERE r.since = "明朝" RETURN a.name, b.name, r.time修改数据:
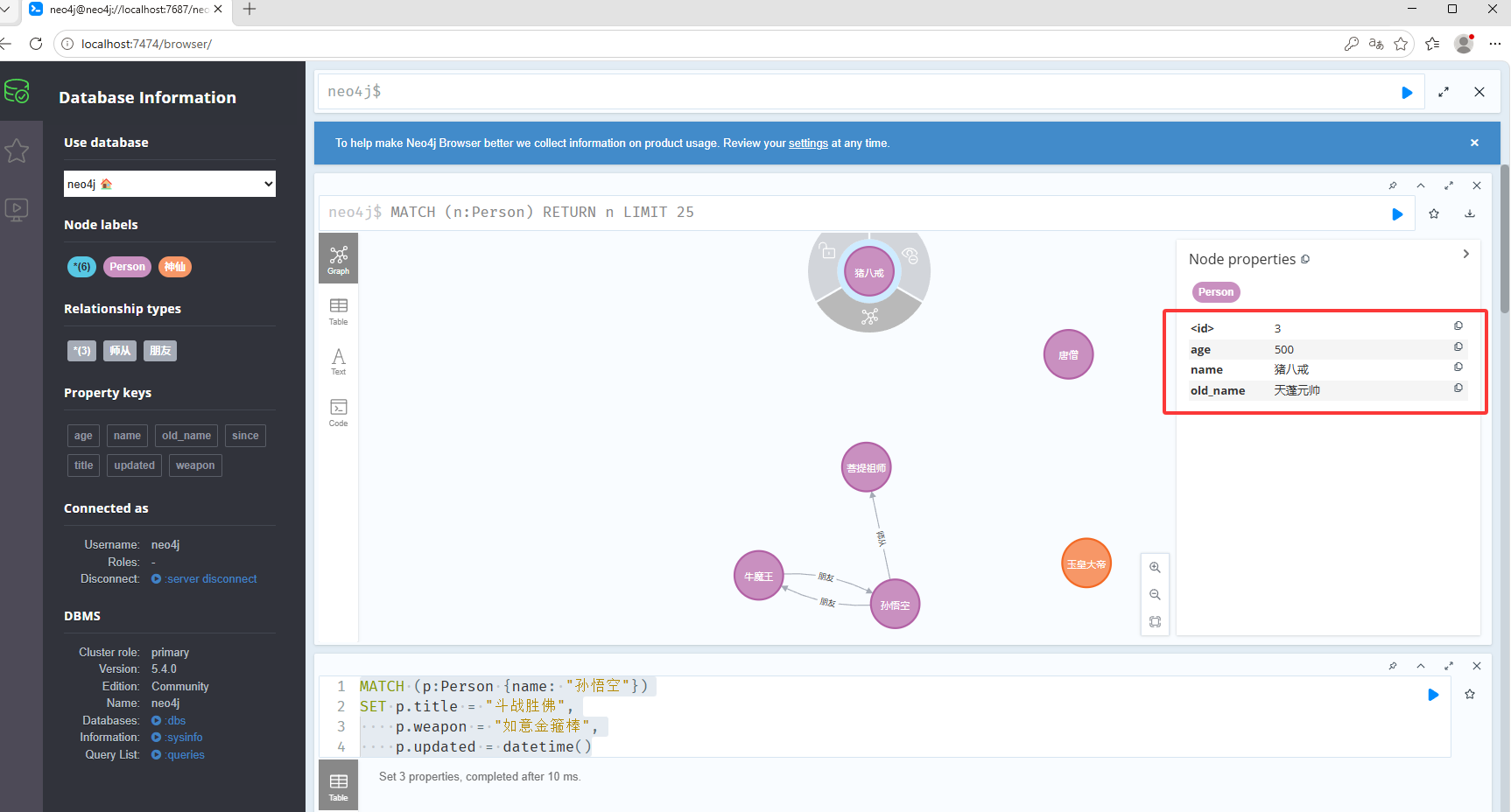
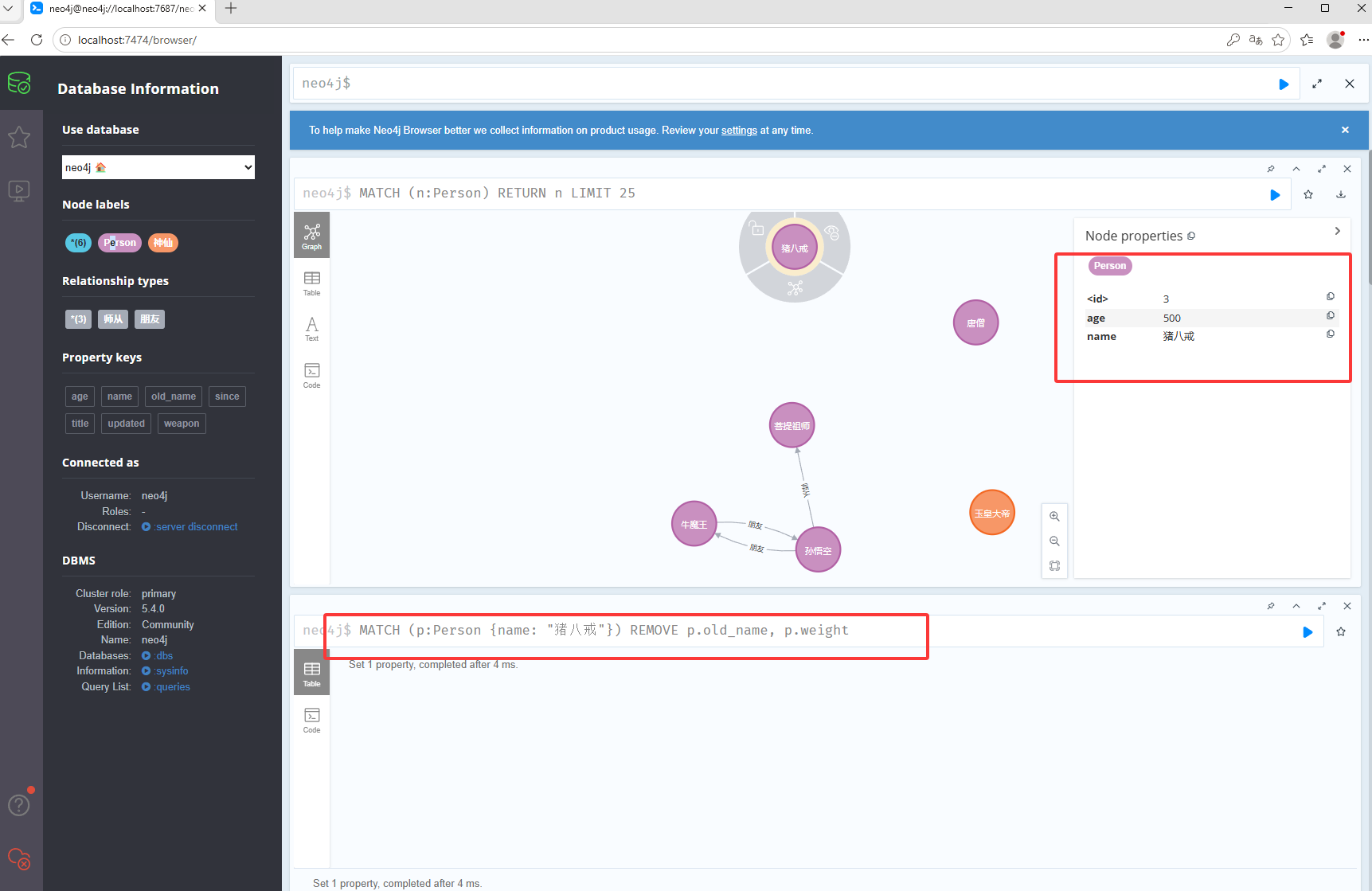
MATCH (p:Person {name: "孙悟空"}) SET p.title = "斗战胜佛", p.weapon = "如意金箍棒", p.updated = datetime()删除属性,如下图删除之前
如下图删除之后
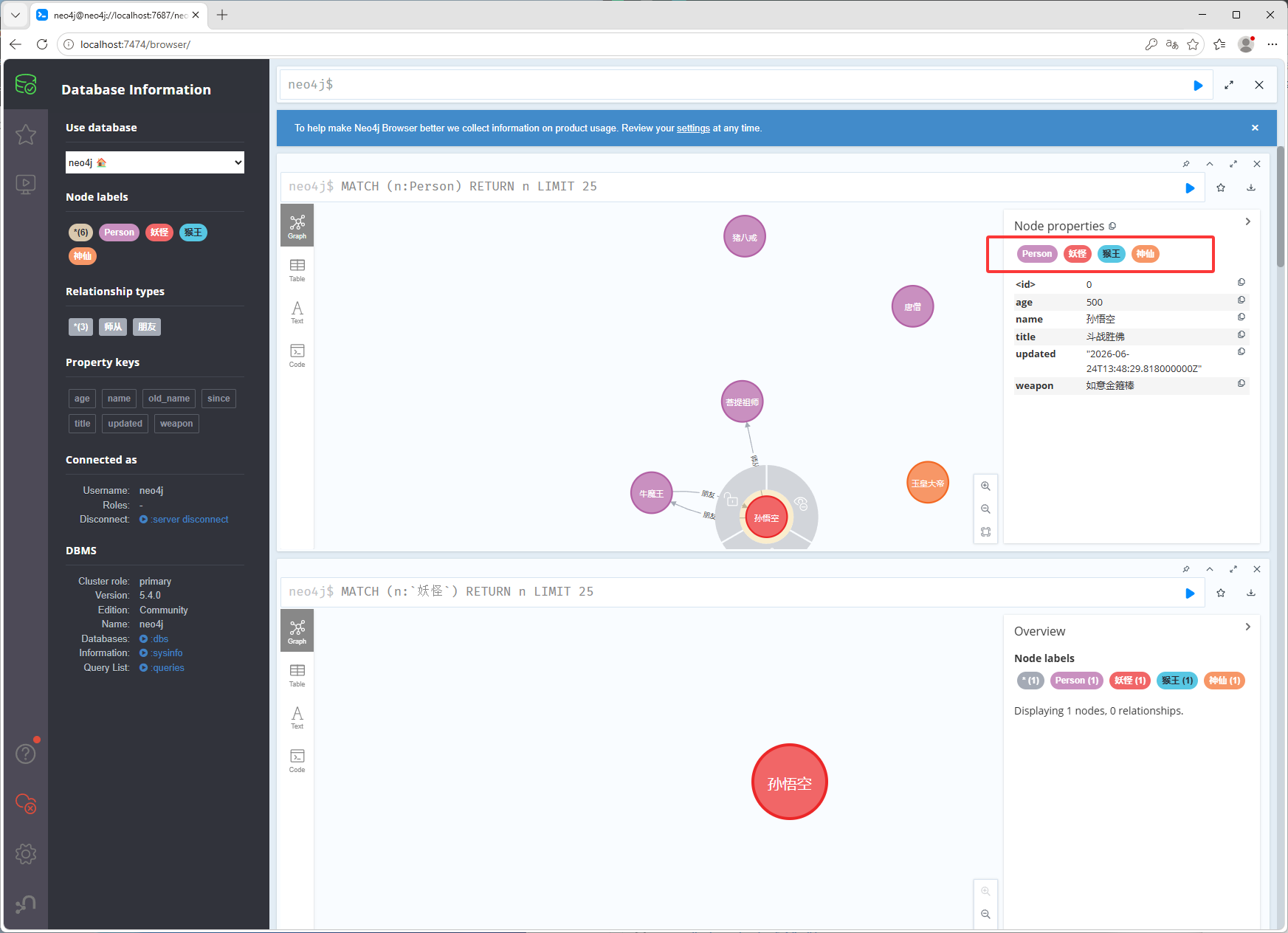
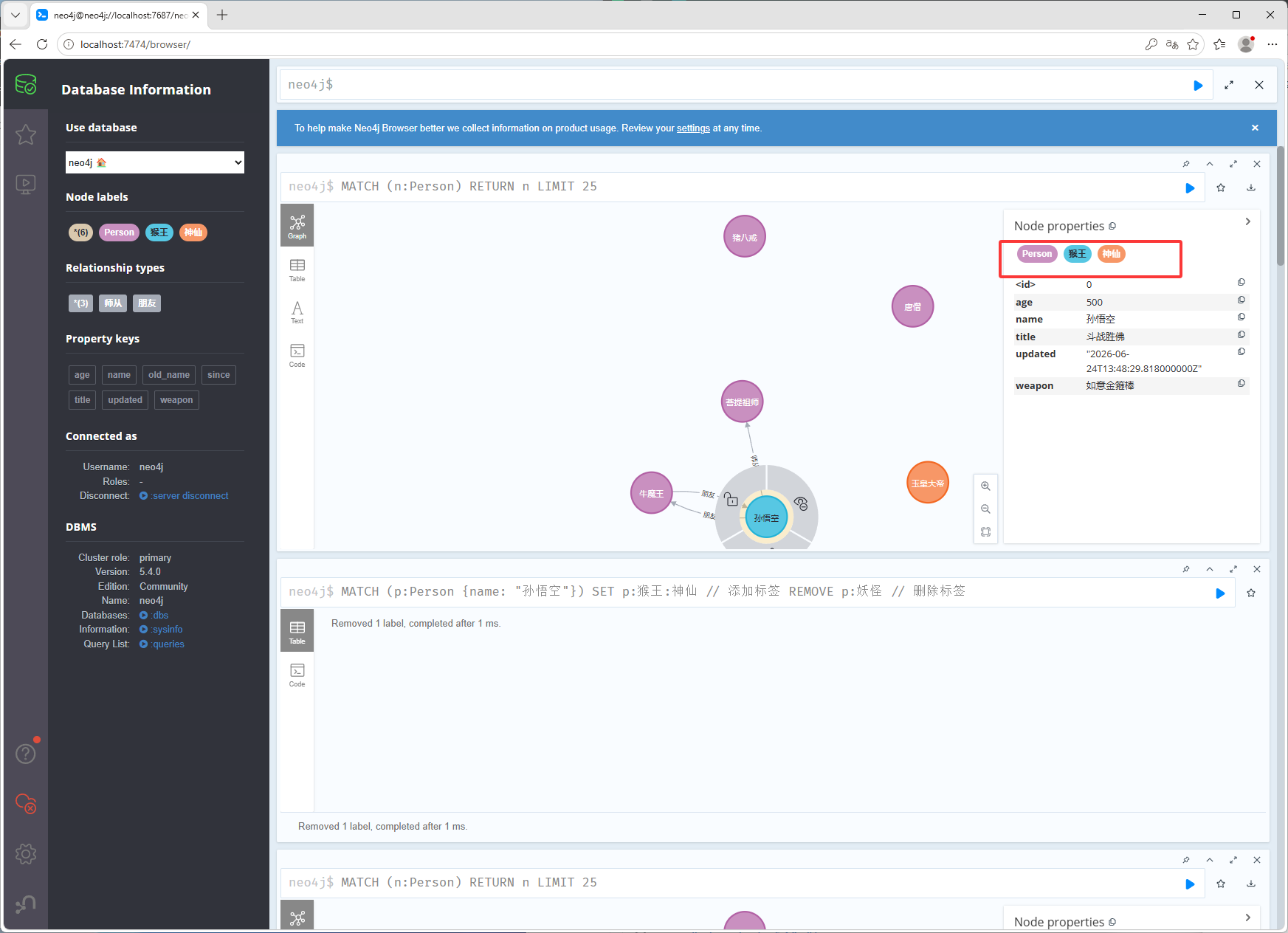
MATCH (p:Person {name: "猪八戒"}) REMOVE p.old_name, p.weight修改标签,如下图修改之前的标签
修改之后的标签
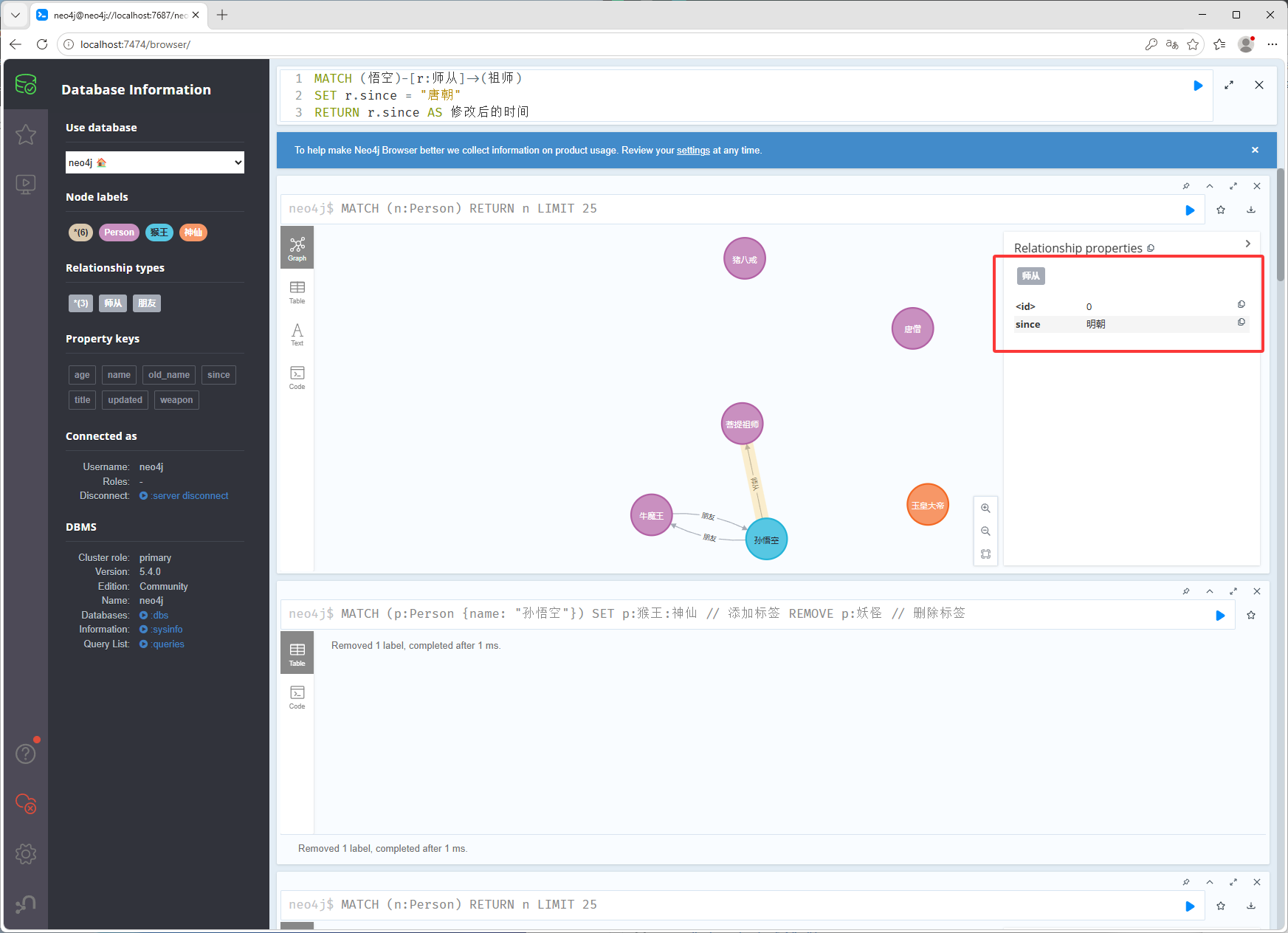
MATCH (p:Person {name: "孙悟空"}) SET p:猴王:神仙 // 添加标签 REMOVE p:妖怪 // 删除标签修改关系,修改之前
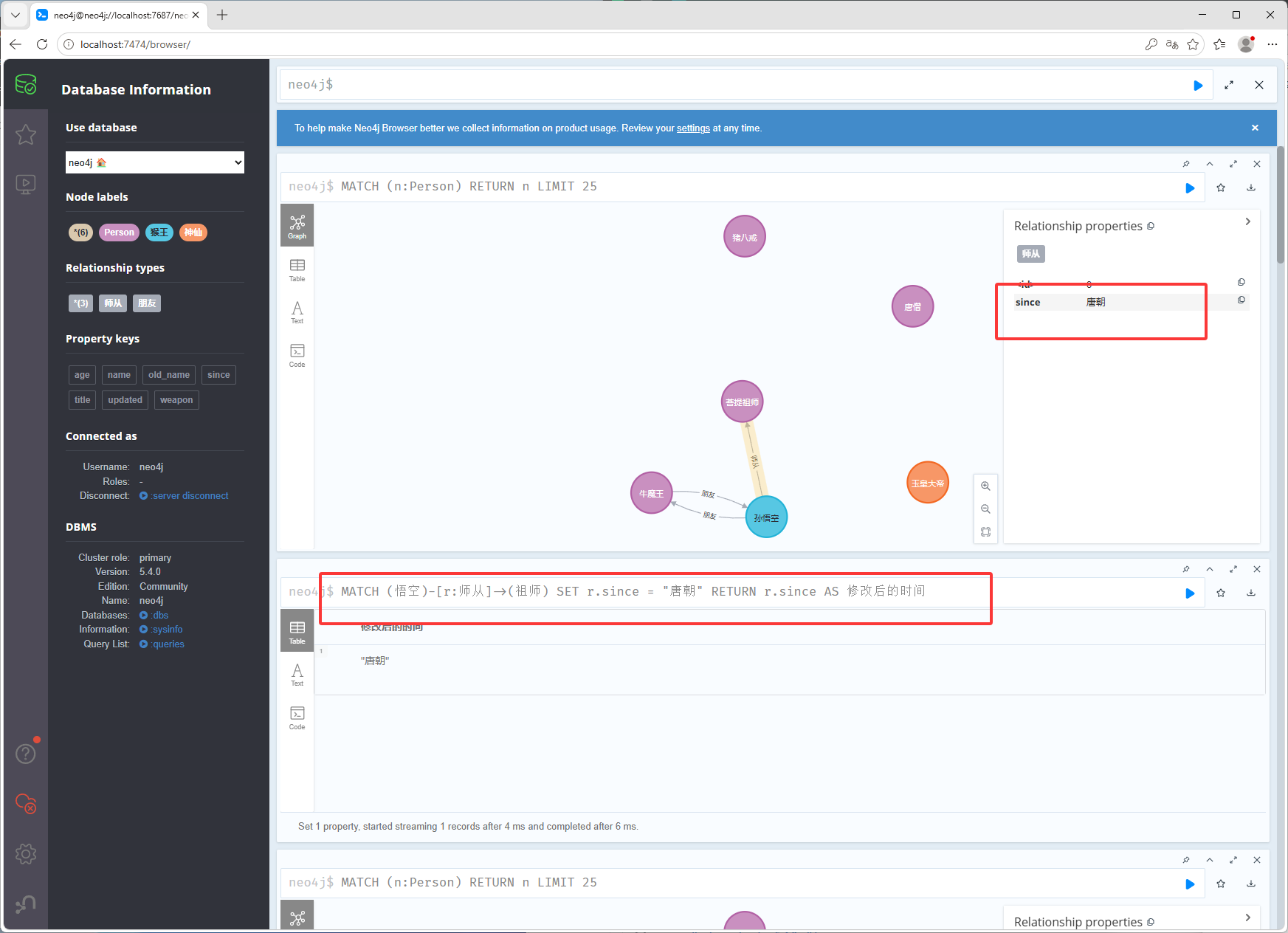
修改之后
MATCH (悟空)-[r:师从]->(祖师) SET r.since = "唐朝" RETURN r.since AS 修改后的时间修改关系名字
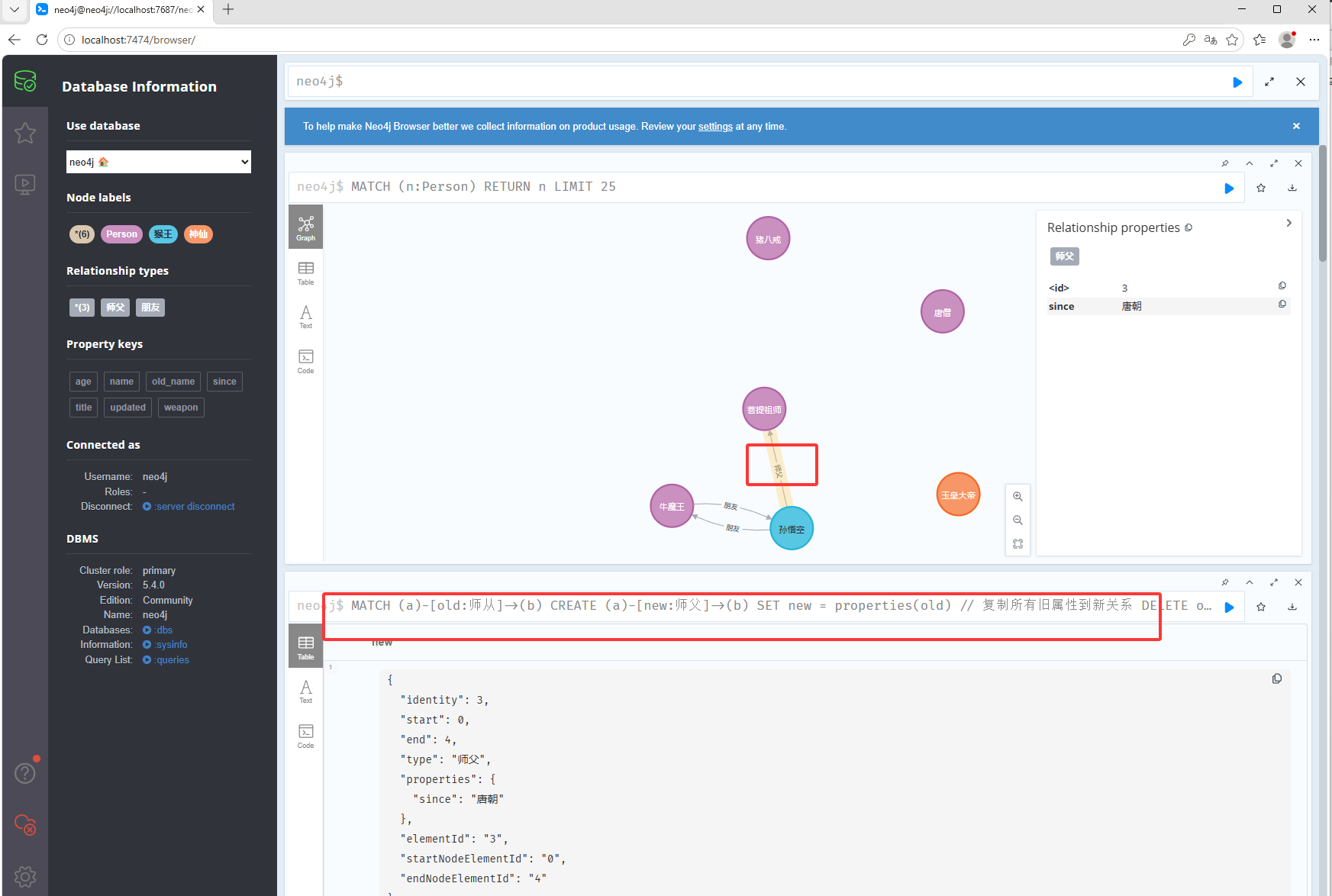
通过查找出名字为师从的边,然后使用properties复制师从边的数据,然后通过set把师从的数据给到师父
MATCH (a)-[old:师从]->(b) CREATE (a)-[new:师父]->(b) SET new = properties(old) // 复制所有旧属性到新关系 DELETE old RETURN new删除关系:
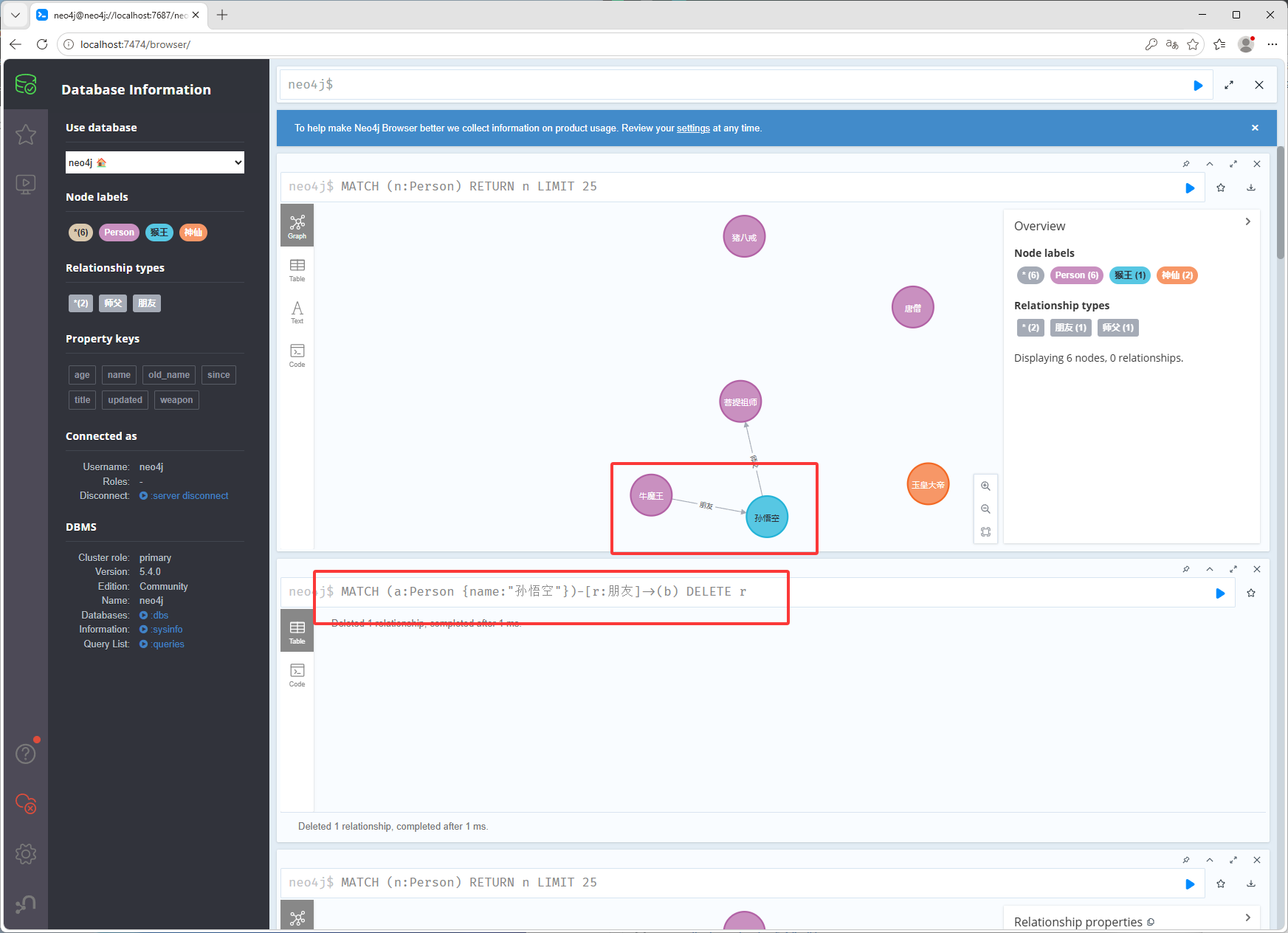
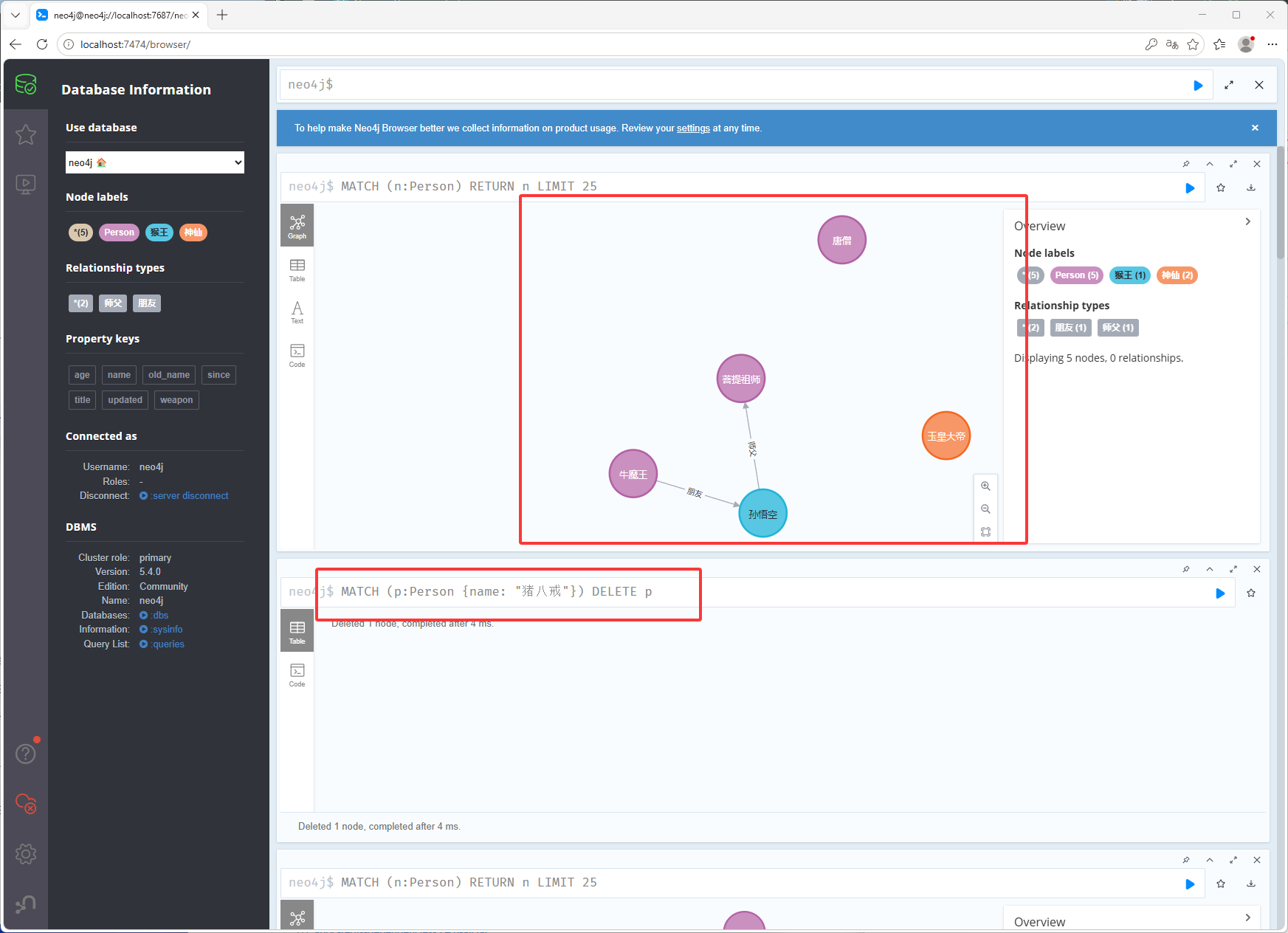
MATCH (a:Person {name:"孙悟空"})-[r:朋友]->(b) DELETE r删除节点,如下图删除了猪八戒
// 如果存在关系删除时会报错 MATCH (p:Person {name: "猪八戒"}) DELETE p删除节点和关系(也就是边)
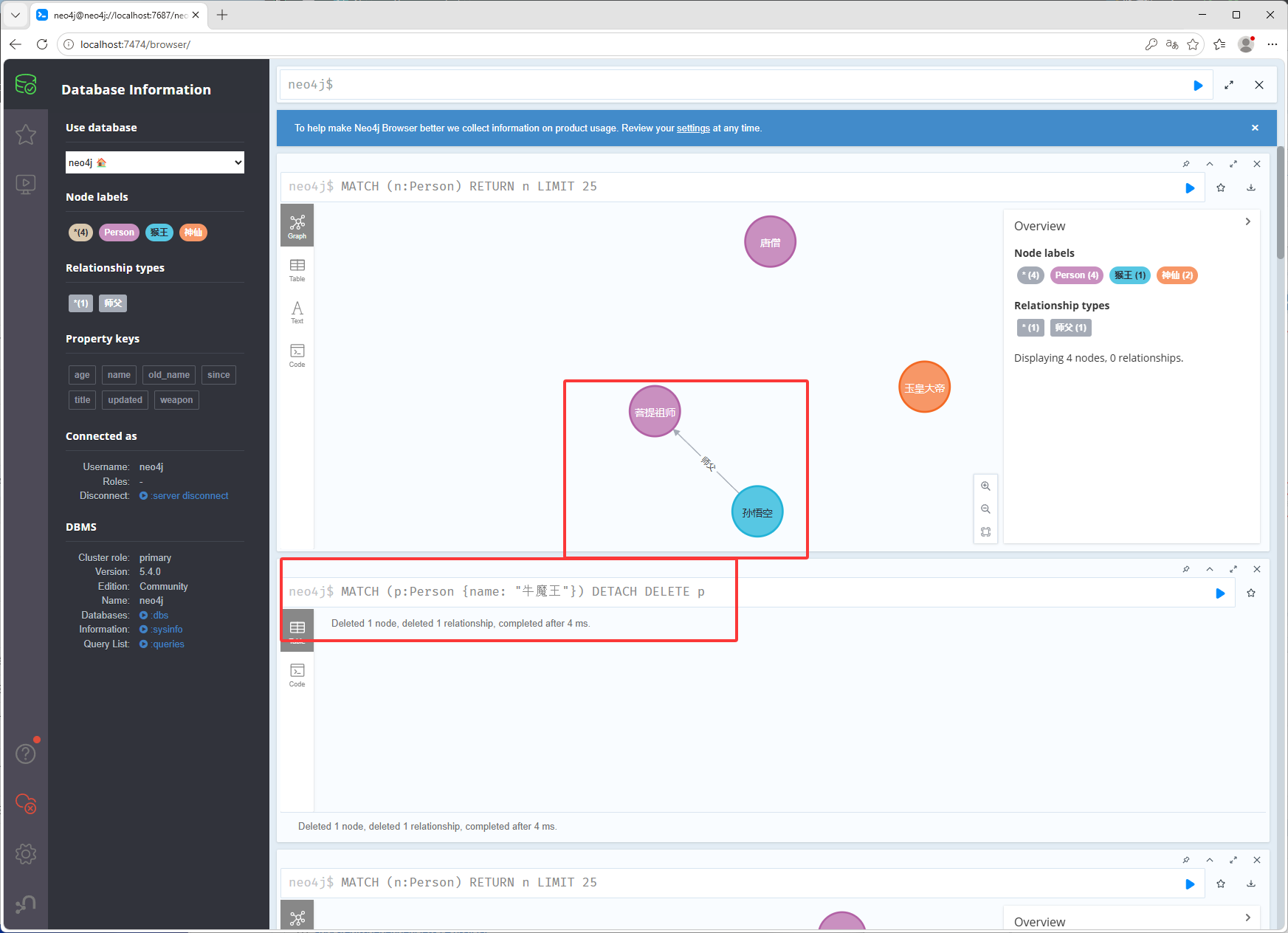
// 同时删除节点和所有关系 MATCH (p:Person {name: "牛魔王"}) DETACH DELETE p清空数据库
MATCH (n) DETACH DELETE n