1. 引言:大模型的本质是一堆数字
在讨论任何格式差异之前,需要先回到一个最基本的事实:大语言模型的本质,是海量的多维浮点数数组。GPT、LLaMA、Qwen,不管名字多响亮,剥开外壳之后,核心就是数十亿乃至数千亿个浮点数,按照特定的矩阵结构排列,构成模型的权重(weights)、偏置(bias)等参数。这些数字经过训练过程中的反向传播不断调整,最终编码了模型对语言的"理解"。一个 7B 参数的模型,以 FP16 精度存储,原始权重大约占 14GB;一个 70B 的模型则接近 140GB。
所谓"量化"(Quantization),就是削减这些浮点数小数点后的位数,用精度换体积。FP32(32位浮点)是训练时的标准精度,FP16/BF16(16位)是推理时的常用精度,INT8(8位整数)和 INT4(4位整数)则是更激进的压缩手段。更极端的做法是从训练阶段就限定权重只能取 0 或 1,这就是所谓的 1-bit 量化。量化等级越低,模型体积越小、推理越快,但精度损失也越大------这是一个工程上的权衡,而非简单的"越小越好"。
既然所有模型的核心都是浮点数数组,那为什么会出现 .pt、.safetensors、.gguf、.onnx 等五花八门的格式?这些格式之间到底有什么本质区别?选型时应该遵循什么逻辑?这篇文章将从底层原理出发,逐一拆解。
2. 格式分化的根源:场景需求决定存储规范
核心数组完全相同,格式却不同------这件事的根源在于:不同场景对"如何使用这些数组"有截然不同的需求。格式的本质不是"换一种方式存数字",而是围绕数组的存储方式、优化逻辑、附加信息和适配场景,形成的一整套管理规范。
具体来说,格式分化由三个维度的差异驱动。
第一,场景诉求差异。训练场景需要保留数组的可修改性和训练轨迹,方便微调和断点续训;部署场景追求存储效率和加载速度,需要剔除一切冗余;分享场景则要求跨框架兼容性和安全性,不能绑定特定代码。同一组权重,在这三个场景下的"最优包装方式"完全不同。
第二,优化方向差异。有的格式优先压缩数组体积(如 GGUF 的量化压缩),有的优先提升计算速度(如 TensorRT 的硬件专属编译),有的优先保证兼容性(如 ONNX 的跨框架统一表示)。优化方向不同,存储结构自然不同。
第三,生态绑定差异。PyTorch 和 TensorFlow 对数组的序列化方式不同,各自的原生格式会绑定框架的处理逻辑。而开源部署格式则脱离框架,独立定义数组的存储和解析规则,实现跨生态兼容。这种"绑定 vs 解耦"的选择,直接决定了格式的通用性。
理解了这三个维度,就能理解为什么格式会分成两大阵营:原生格式和开源部署格式。
3. 原生格式:训练框架的"状态存档"
3.1 什么是原生格式
原生格式是模型训练完成后最原始的输出,完全绑定训练框架。PyTorch 的 .pt/.bin、TensorFlow 的 .ckpt/SavedModel 都属于这一类。它们的定位是服务于训练、微调和科研,而非直接部署。
原生格式的核心特点可以用三个词概括:松散、依赖、未优化。"松散"指的是除了核心权重数组之外,还附带大量训练辅助信息;"依赖"指的是数组的解析必须依赖原始训练框架和模型结构代码;"未优化"指的是数组未做内存对齐、量化等处理,加载速度慢、内存占用大。
3.2 Checkpoint 详解:不只是权重
在原生格式中,最常见的存在形式是 Checkpoint(检查点)。Checkpoint 不是一种独立格式,而是原生格式的核心组成部分------它是训练过程中定期保存的模型中间状态,核心作用是防止训练中断导致进度丢失,同时实现模型版本管理。
一个完整的 Checkpoint 包含以下内容:
- 核心数组:模型的完整权重和偏置,这是与推理直接相关的部分
- 优化器状态:与权重一一对应的辅助数组(如 Adam 优化器的动量和二阶矩估计),以及学习率、权重衰减等超参数
- 训练状态:当前 epoch、step、数据加载进度、学习率调度器状态等
- 其他元数据:训练配置、损失值、随机数种子等
这些附加信息对于断点续训至关重要,但对推理来说完全是冗余。一个 7B 模型的权重可能只有 14GB,但包含完整优化器状态的 Checkpoint 可能膨胀到 40GB 以上------因为 Adam 优化器需要为每个参数额外存储两个同等大小的状态张量。这也是原生格式不适合直接部署的核心原因:推理时只需要权重数组,其余信息全部可以丢弃。
需要特别指出的是,在 ModelScope 等平台上经常看到标注为"checkpoint"的模型,这并不代表一种格式,而是表示这是训练过程中的阶段性版本(半成品),可能不是最终的最优权重。
3.3 Pickle:便利背后的安全隐患
PyTorch 的原生格式(.pt/.pth/.bin)底层使用 Python 的 pickle 模块进行序列化。Pickle 的设计初衷是序列化任意 Python 对象,包括对象的行为(方法),而不仅仅是数据。这意味着一个 pickle 文件在反序列化时可以执行任意 Python 代码------这不是 bug,而是 pickle 的设计特性。
这个特性在模型分享场景下构成了严重的安全威胁。2024 年 4 月,网络安全公司 Wiz 的研究人员在 Hugging Face 平台上发现了关键漏洞:攻击者可以上传包含恶意代码的 PyTorch 模型文件,当其他用户加载该模型时,恶意代码会自动执行,可能导致数据泄露、系统被控制甚至供应链攻击。2025 年 2 月,ReversingLabs 的研究人员又在 Hugging Face 上发现了至少两个利用"损坏的 pickle 文件"绕过安全扫描工具 Picklescan 的恶意模型。
正是这些安全事件,直接推动了 safetensors 格式的诞生和普及。
4. 开源部署格式:为推理而生的精简规范
与原生格式相对的是开源部署格式,包括 safetensors、GGUF、ONNX 等。它们的共同特点是:剔除训练冗余、脱离框架绑定、针对推理场景优化。但在具体实现上,各格式的侧重点截然不同。
4.1 Safetensors:安全与简洁的标杆
Safetensors 由 Hugging Face 开发,设计目标极其明确:安全地存储模型权重,仅此而已。
在安全性上,safetensors 采用严格的只读设计,文件中只包含数值张量和 JSON 格式的元数据头(记录张量名称、形状、数据类型和字节偏移量),不包含任何可执行代码。这从根本上消除了 pickle 格式的任意代码执行风险。该格式已通过 Trail of Bits 的外部安全审计。
在性能上,safetensors 支持零拷贝(zero-copy)操作和内存映射(mmap)技术,数据可以直接从磁盘映射到内存,无需额外复制,加载速度比 pickle 格式快 2-3 倍。对于超大模型(如 70B),safetensors 支持分片存储,将权重拆分为多个小文件,按需加载,避免一次性占用过多内存。
在生态上,safetensors 已成为 Hugging Face 平台的默认格式,截至 2024 年底,在 Hugging Face 模型库中的渗透率超过 90%。它支持 PyTorch、TensorFlow、JAX、PaddlePaddle 等多个框架,是目前开源模型分享的事实标准。
safetensors 的局限在于:它只存储权重,不包含模型架构信息和分词器,这些需要通过额外的配置文件(如 config.json、tokenizer.json)提供。此外,它不做量化优化,权重以原始精度存储,不适合低资源设备直接部署。
4.2 GGUF:本地推理的终极方案
GGUF(GPT-Generated Unified Format)是 GGML 格式的继任者,由 llama.cpp 社区开发,专为在消费级硬件上高效运行量化大模型而设计。
GGUF 的核心特性是量化。它支持从 Q2(2-bit)到 Q8(8-bit)的多种量化方案,以及 K-quant 系列的混合精度量化(如 Q4_K_M、Q5_K_M),可以在保留 95% 以上原始能力的前提下,将模型体积压缩到原来的 1/4 甚至 1/8。一个 7B 的 FP16 模型约 14GB,经过 Q4_K_M 量化后仅约 4GB,可以在 8GB 内存的笔记本上流畅运行。
GGUF 的另一个重要特性是自包含。一个 GGUF 文件中不仅包含量化后的权重,还包含模型架构信息(层数、注意力头数等)、分词器数据、提示模板等元数据,无需任何额外配置文件即可直接加载推理。这种"单文件即完整模型"的设计,极大降低了本地部署的门槛。
在存储层面,GGUF 采用连续内存布局,支持 mmap 快速映射,加载速度极快。即使模型大小超过可用内存,也能通过 mmap 实现部分加载推理。GGUF 与 llama.cpp 生态深度绑定,后者支持 CUDA、Metal、OpenCL、Vulkan 等多种后端,覆盖了从 x86 CPU 到 Apple Silicon 到 NVIDIA GPU 的几乎所有消费级硬件。
GGUF 的局限在于:量化不可避免地会带来精度损失,对于需要高精度输出的场景(如医疗、金融)可能不适用;此外,GGUF 主要面向 LLM,对视觉模型、多模态模型的支持相对有限。
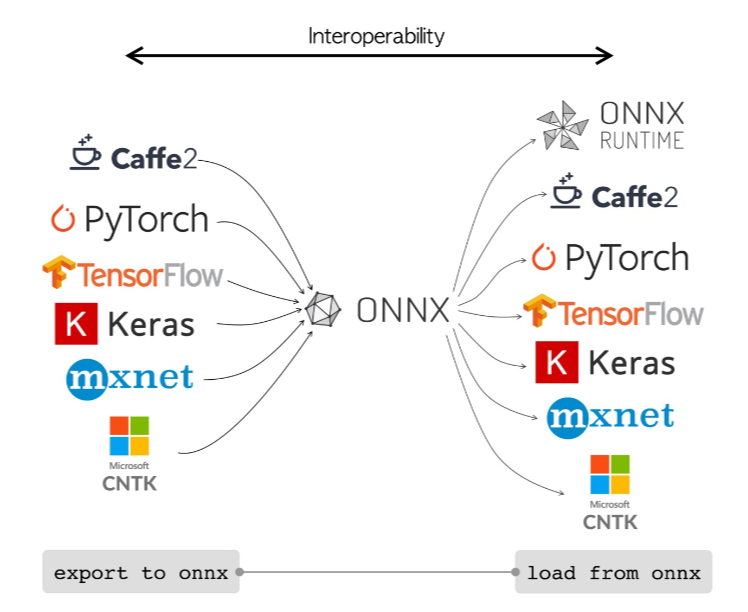
4.3 ONNX:跨平台部署的中间件
ONNX(Open Neural Network Exchange)由微软和 Facebook 于 2017 年联合发起,定位是机器学习模型的"通用中间表示",实现"训练一次,随处部署"。
与 safetensors 和 GGUF 不同,ONNX 文件中不仅包含权重数组,还包含完整的计算图(Computation Graph)------即模型中每个算子(卷积、矩阵乘法、激活函数等)的定义及其之间的数据流关系。这使得 ONNX 可以完整描述一个模型的推理逻辑,而不仅仅是参数。
ONNX 的核心价值在于互操作性。在 PyTorch 中训练的模型,可以导出为 ONNX 格式,然后在 ONNX Runtime、TensorRT、OpenVINO 等任意兼容的推理引擎上运行,无需重写推理代码。ONNX Runtime 支持 Python、C++、C#、Java、JavaScript 等多种语言,覆盖云端、边缘、移动端等各类部署环境。
ONNX 还可以作为"中转站",将模型进一步转换为硬件专属格式。例如,先将 PyTorch 模型导出为 ONNX,再通过 TensorRT 编译为 NVIDIA GPU 专属的 engine 文件,获得极致的推理性能。这种"ONNX → 硬件专属格式"的流水线,是工业级部署中最常见的模式。
ONNX 的局限在于:它的通用性是以牺牲极致性能为代价的------同一个模型,ONNX Runtime 的推理速度通常不如 TensorRT 的原生 engine;此外,ONNX 的算子覆盖并非 100%,某些框架特有的算子可能无法直接导出,需要手动处理。