在前面的文章中,我们讨论了如何利用 Data Fabric 构建数据服务。那篇文章的核心观点是:企业数据建设不能停留在一次性报表、临时数据结果和点对点数据 API 上,而是要把高频使用的数据资产,沉淀为可持续调用、统一治理、可解释、可追溯的数据服务。
但数据服务上线之后,事情并没有结束。很多企业在数据建设中都有一个共同问题:重建设,轻运营。
数据目录建起来了,但不知道哪些资产真正被使用;数据 API 发布了,但缺少持续监控;指标服务上线了,但口径变化后没有及时同步;质量规则配置了,但很多异常仍然是在业务报错之后才发现;服务越来越多,但哪些服务应该优化、哪些服务应该合并、哪些服务应该下线,并没有形成持续判断机制。
这说明,企业不仅需要构建数据服务,还需要运营数据服务。
所谓数据运营,不是简单统计有多少张表、多少个接口、多少个指标,也不是给数据资产做一次盘点。真正的数据运营,是持续观察数据资产和数据服务如何被使用、是否稳定可信、是否支撑关键业务、是否存在重复建设和风险调用,并基于这些反馈持续优化数据能力。
这正是 Data Fabric 可以继续发挥作用的地方。Data Fabric 的价值,不只是让数据可访问、可理解、可治理、可服务化,更重要的是,它可以通过主动元数据、服务调用监控、质量反馈、血缘分析、用户行为和治理策略,把数据服务的运行过程转化为持续可观察、可评估、可优化的数据运营体系。
|----------------------------------------------|
| Data Fabric 不只是构建数据服务,还要让数据服务持续产生价值。 |
一、数据服务上线之后,运营才真正开始
在很多数据项目中,"上线"常常被视为一个阶段性终点。数据模型上线了,接口发布了,指标服务注册了,数据目录中可以查到了,似乎项目就已经完成。但从数据使用的角度看,上线只是开始。
一个数据服务上线之后,还需要持续回答很多问题:谁在使用这个服务?调用频率是否稳定?是否支撑了关键业务流程?是否减少了重复开发?服务返回的数据质量是否稳定?用户是否理解服务中的指标口径?调用过程是否存在异常行为?上游数据变化是否影响了服务结果?服务是否已经被新的服务替代?是否还有继续维护的价值?
如果这些问题没有被持续观察,数据服务很容易变成"上线即沉默"。它可能仍然挂在服务目录中,但没人知道是否还被使用;它可能被多个系统调用,但没人知道是否存在质量风险;它可能和其他服务高度重复,但没人负责合并;它可能依赖已经变更的上游字段,但只有在业务出现异常时才被发现。
因此,数据服务的价值不取决于"有没有上线",而取决于"上线之后是否被持续使用、持续治理、持续优化"。从这个角度看,Data Fabric 构建数据服务只是第一步。真正让数据服务成为企业数据能力的,是后续持续运营。
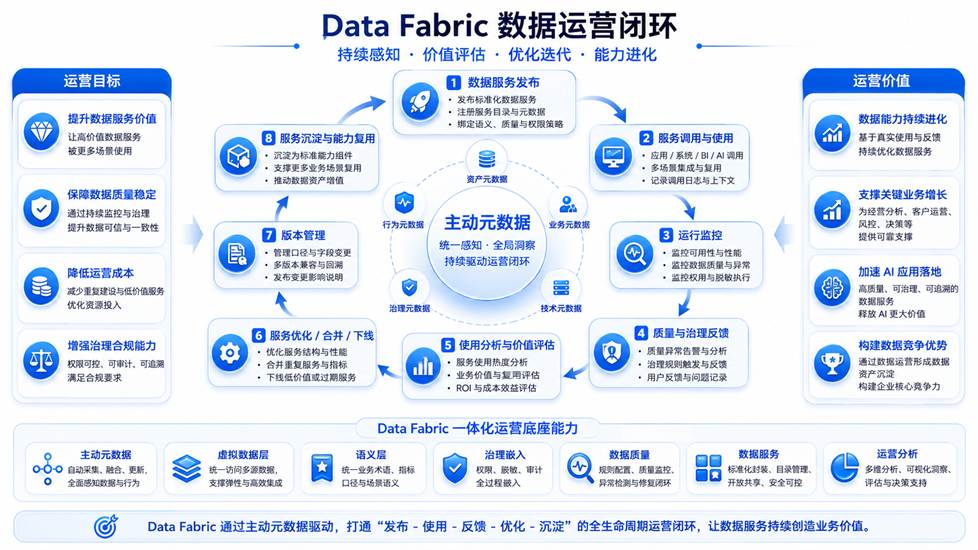
图 1 Data Fabric 数据运营闭环
二、传统数据平台的问题,是重建设而轻运营
传统数据平台建设中,常见的工作重心是"建设更多能力"。建设数据仓库,建设数据湖,建设数据目录,建设指标平台,建设 API 服务,建设质量规则,建设权限体系。
这些工作当然重要。但如果缺少运营机制,建设出来的能力很容易变成静态资产。
例如,数据目录中登记了大量表和字段,但业务人员仍然不知道哪些数据最可信、哪些数据最常用、哪些数据适合当前场景。数据 API 发布了很多,但同类接口不断重复,字段定义越来越分散。指标平台中沉淀了大量指标,但不同版本指标之间的差异没有被及时治理。质量规则配置了不少,但质量异常与具体业务影响之间没有建立清晰联系。
这类问题的本质,是企业把数据资产当成"建设成果",却没有把它们当成"持续运营对象"。数据资产不是登记完成就结束,数据服务不是发布完成就结束,指标口径不是定义完成就结束,质量规则不是配置完成就结束,权限策略也不是审批完成就结束。
只要数据仍然在被调用、被组合、被分析、被 AI 使用,它就处在持续变化的运行状态中。传统数据平台的问题,不是没有工具,而是很多工具更擅长"建设"和"管理",不擅长持续感知数据运行过程。
而 Data Fabric 的一个重要差异在于,它可以把数据资产、数据服务、用户行为、质量状态、血缘关系和治理策略连接起来,让数据运营从人工巡检转向持续感知。
三、主动元数据让数据运营变得可感知
数据运营的前提,是能够看见数据如何被使用。过去,数据运营依赖人工统计和事后排查。哪个服务被调用最多,哪个指标最常用,哪些字段经常一起出现,哪些数据源质量不稳定,哪些调用行为存在风险,往往需要人工从日志、报表、权限系统和质量平台中分别查找。
这种方式效率低,也很难形成持续闭环。Data Fabric 的核心能力之一,是主动元数据。主动元数据不仅记录数据是什么,还记录数据如何变化、如何被使用、如何被访问、如何影响下游、如何触发治理规则。
在数据运营场景中,主动元数据可以持续采集和分析多类信号:数据服务的调用频率,字段和指标的访问热度,服务响应时间和失败率,数据质量异常记录,上游变更对下游服务的影响,不同用户和系统的访问行为,权限拒绝和脱敏触发情况,用户对数据服务的反馈,以及 AI Agent 对数据服务的调用记录。
这些信号让数据运营不再依赖人工感觉,而是可以基于真实使用情况进行判断。一个指标服务被多个业务系统和 BI 报表反复调用,说明它具有较高复用价值;一个数据服务调用频率很高,但经常出现质量异常,说明它需要优先治理;某些字段经常被一起查询,说明它们可能适合沉淀为业务对象服务;某个服务长期无人调用,可能需要评估是否下线或合并。
主动元数据让数据运营从"事后看问题"变成"持续看状态"。这也是 Data Fabric 数据运营体系和传统数据管理的重要区别。
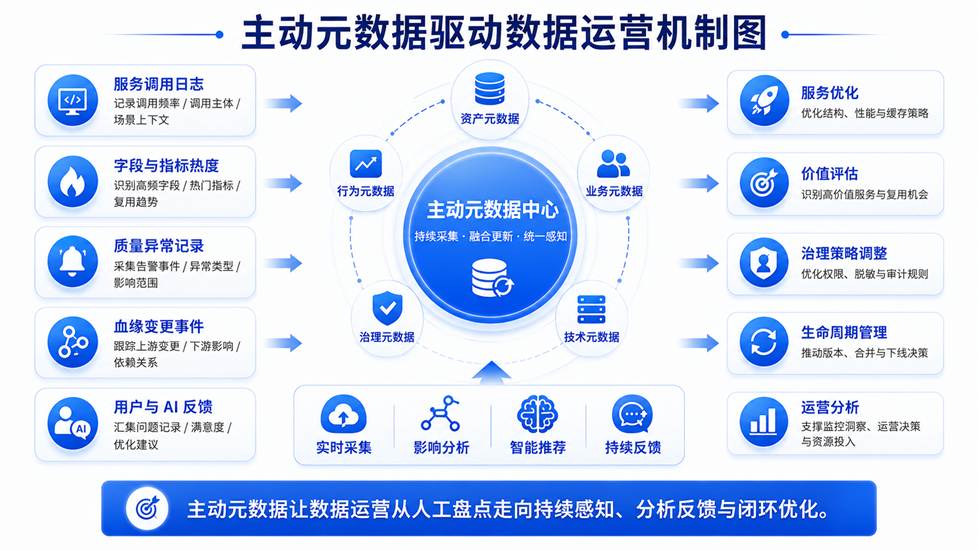
图 2 主动元数据驱动数据运营
四、数据服务价值需要被持续评估
数据服务不是越多越好。一个企业如果只追求服务数量,很容易走向另一种混乱:服务目录越来越长,接口越来越多,指标越来越多,但真正被高频使用、能够支撑关键业务的数据服务并不多。
因此,构建数据运营体系时,必须建立数据服务价值评估机制。数据服务价值不能只看是否上线,而要从多个维度持续判断。
首先是使用热度。一个服务是否被持续调用,调用频率是否稳定,调用方是否覆盖多个系统和场景,这是判断服务价值的基础。其次是业务价值。一个服务即使调用频率不高,但如果支撑的是关键经营分析、风险控制、客户运营、监管报送或 AI 核心应用,它仍然具有较高价值。
第三是质量稳定性。高价值服务必须具备稳定的数据质量。如果服务经常因为上游延迟、字段异常、口径变化导致结果不可信,那么它的运营优先级应该更高。第四是复用程度。好的数据服务应该减少重复开发。如果多个系统都围绕同一类客户、订单、产品或指标重复取数,说明存在沉淀标准服务的机会。
第五是治理合规。数据服务不仅要好用,还要受控。它是否绑定权限规则,是否执行动态脱敏,是否记录审计,是否能够追溯调用过程,都会影响服务的企业级可用性。第六是性能表现。一个服务如果响应慢、失败率高、调用链路不稳定,即使业务价值很高,也会影响使用体验。
第七是用户反馈。数据服务最终是被业务系统、分析人员、算法模型和 AI Agent 使用的。用户是否能理解服务说明,是否认可指标口径,是否频繁提出修改需求,也是运营判断的重要依据。第八是 AI 适配度。随着 AI Agent 进入企业数据使用流程,数据服务还需要判断是否适合被 AI 调用:语义是否清晰,输入输出是否明确,权限边界是否可控,结果是否可解释。
通过这些维度,数据服务就不再只是一个"发布对象",而是一个可以被持续评估的数据产品或数据能力。
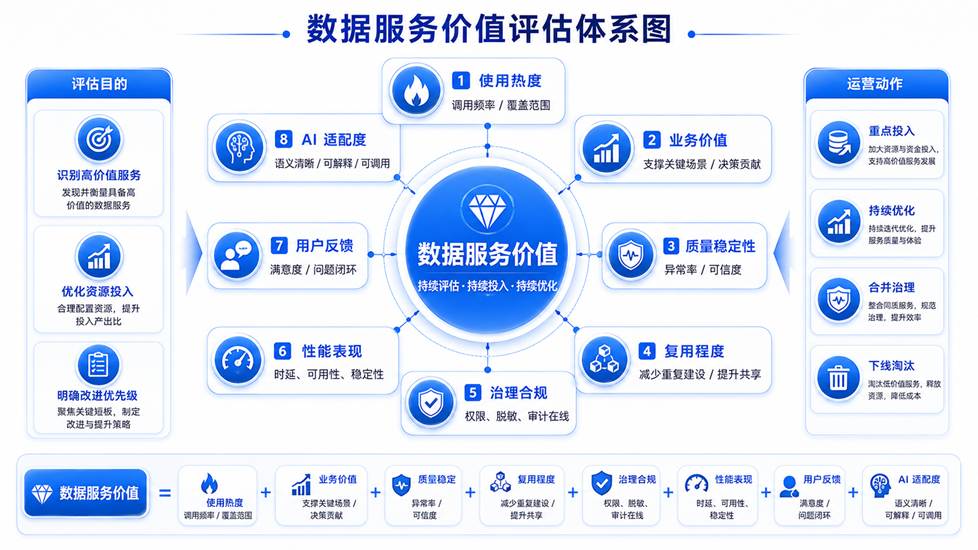
图 3 数据服务价值评估体系
五、数据服务也需要生命周期管理
数据服务既然需要持续运营,就必然需要生命周期管理。一个数据服务从产生到退出,通常会经历几个阶段。
第一阶段是服务识别。企业需要判断哪些数据、指标、对象和场景值得被服务化。这个判断不应该只依赖人工规划,也应该结合主动元数据中反映出来的使用频率、复用潜力和业务价值。
第二阶段是服务设计。服务设计不只是定义接口参数和返回字段,还要明确服务对应的业务对象、指标口径、适用场景、权限要求、质量阈值、血缘来源和负责人。
第三阶段是服务发布。服务发布后,需要进入统一服务目录,让业务系统、BI 工具、数据科学团队和 AI Agent 能够发现、申请和调用。第四阶段是服务调用。服务进入真实使用环境后,才会产生有价值的运营信号。哪些用户在调用,哪些系统在依赖,哪些字段被频繁访问,哪些场景中出现异常,都需要被记录。
第五阶段是服务监控。监控内容不只包括接口可用性和响应时间,还包括数据质量、权限触发、脱敏执行、血缘影响、异常访问和用户反馈。第六阶段是服务优化。根据运营数据,可以优化服务口径、调整缓存策略、合并重复服务、拆分复杂服务、补充质量规则、调整权限策略。
第七阶段是版本管理。服务口径变化、字段变化、数据源变化、权限变化,都需要形成版本管理,避免调用方在不知情的情况下受到影响。第八阶段是服务合并或下线。长期无人使用、重复建设、质量不稳定或已经被新服务替代的服务,应该进入合并、下线或归档流程。
没有生命周期管理,数据服务会越建越多,最终变成新的负担。有了生命周期管理,数据服务才能保持清晰、稳定和可持续。

图 4 数据服务生命周期管理
六、数据运营的目标是让能力持续进化
数据运营不是为了"看管数据",而是为了让数据能力持续进化。通过运营,企业可以发现哪些数据真正有价值。如果某些数据被多个系统高频调用,说明它们可能是核心数据资产;如果某些指标被多个报表反复使用,说明它们应该沉淀为标准指标服务;如果某些字段经常一起出现,说明它们可能对应一个重要业务对象。
通过运营,企业可以推动源头数据治理。如果某个数据服务频繁出现质量异常,问题可能不在服务本身,而在上游数据源、采集链路、加工规则或口径定义。数据运营可以通过血缘分析,把问题反推到源头。
通过运营,企业可以减少重复建设。如果多个系统分别开发了相似的数据接口,说明企业缺少统一的数据服务沉淀。通过服务调用分析和字段组合分析,可以识别重复服务,并推动统一封装。
通过运营,企业可以优化权限和治理策略。如果某类字段频繁触发权限拒绝,可能说明授权策略过于粗糙;如果某类用户经常访问高敏感数据,可能需要强化审批和审计;如果某些脱敏规则影响业务使用,也需要重新评估展示粒度。
通过运营,企业可以提升数据服务体验。高频服务可以优化缓存和路由,复杂服务可以拆分成更清晰的服务,低频但高价值服务可以加强质量保障,长期不用的服务可以下线,避免干扰使用者。
所以,数据运营不是静态管理,而是持续优化。它让数据服务不再停留在"上线状态",而是进入"运行状态、反馈状态、优化状态"。
|---------------------------------------|
| 数据运营的核心不是把数据管住,而是让数据服务在真实使用中持续进化。 |
七、AI 应用让数据运营变得更加重要
AI 应用会进一步放大数据运营的重要性。传统报表和 BI 分析通常由人来选择数据、理解字段、确认口径和判断结果。而 AI Agent 可能会自动理解问题、自动选择数据服务、自动组合多个数据源、自动生成分析结论。
这意味着,AI 对数据服务运营提出了更高要求。如果企业没有数据运营体系,就很难回答这些问题:AI Agent 调用了哪些数据服务?调用的数据质量是否稳定?使用的指标口径是否正确?是否触发了敏感字段脱敏?是否存在越权调用?AI 输出结果能否追溯到数据来源?哪些数据服务被 AI 高频使用?哪些服务应该优化为 AI 工具服务?
在 AI 场景下,数据服务不是简单被系统调用,而是可能被智能体自动选择、组合和解释。这会带来新的风险,也会带来新的运营机会。
风险在于,如果数据服务语义不清、质量不稳、权限边界模糊,AI 可能会放大这些问题,并输出不可靠结果。机会在于,通过主动元数据记录 AI 调用行为,企业可以知道哪些数据服务最适合 AI 使用,哪些服务需要补充语义说明,哪些指标需要标准化,哪些服务需要强化审计和解释能力。
因此,AI 不是让数据运营变得可有可无,而是让数据运营变得更加重要。企业 AI 要稳定落地,不能只依赖模型能力,还需要一套持续运营的数据服务体系。
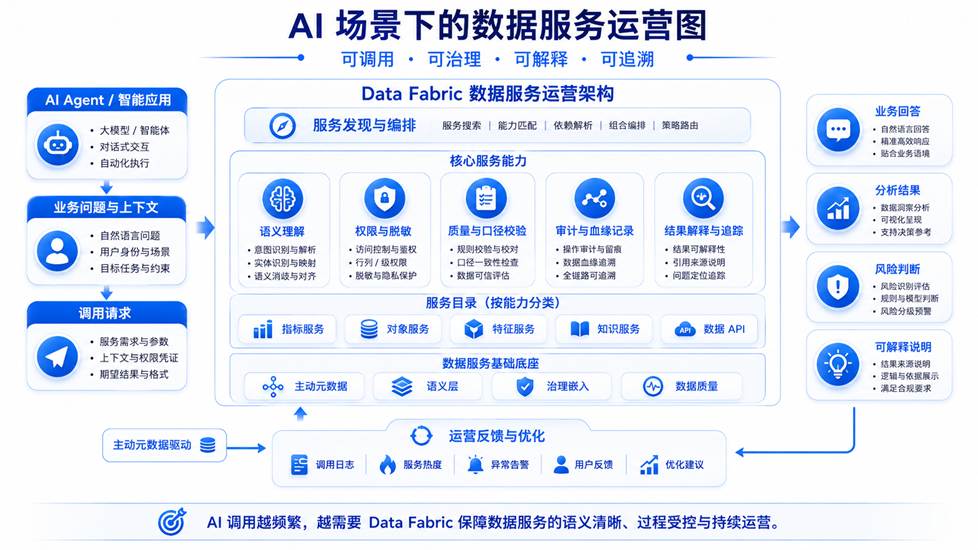
图 5 AI 场景下的数据服务运营:AI Agent 通过 Data Fabric 调用可信数据服务,语义、权限、质量、审计和运营反馈同步参与。
八、Data Fabric 让数据运营走向持续优化
利用 Data Fabric 构建数据运营体系,不是为了多一套管理流程,而是为了让数据资产、数据服务和数据应用之间形成持续反馈。
主动元数据负责感知真实使用情况。虚拟数据层负责支撑跨源访问。语义层负责保证业务含义一致。治理嵌入负责让调用过程可控可信。质量规则负责保障数据服务稳定可靠。服务监控负责记录运行状态。价值评估负责判断哪些服务值得继续投入。生命周期管理负责推动服务优化、合并和下线。
这些能力共同构成 Data Fabric 数据运营体系。从这个角度看,Data Fabric 不只是一个数据集成架构,也不只是一个数据服务架构。它更像是一套能够让数据能力持续运行、持续反馈、持续优化的企业数据运营底座。
过去,企业数据建设更关注"有没有数据资产"。后来,企业开始关注"有没有数据服务"。而在 Data Fabric 体系下,企业还需要进一步关注"这些数据服务是否真正被使用、是否持续可信、是否能够复用、是否能持续产生价值"。
这就是数据运营的核心。数据服务上线不是终点,数据资产登记不是终点,指标口径定义不是终点,质量规则配置也不是终点。真正重要的是,数据能力能否在不断使用中被观察、被评价、被优化。
利用 Data Fabric 构建数据运营体系,最终要实现的不是把数据管起来,而是让数据能力在企业业务、分析和 AI 场景中持续进化。
|------------------------------------------------------------|
| 企业数据运营的终点不是 " 管住数据 " ,而是让数据能力持续创造业务价值。 |