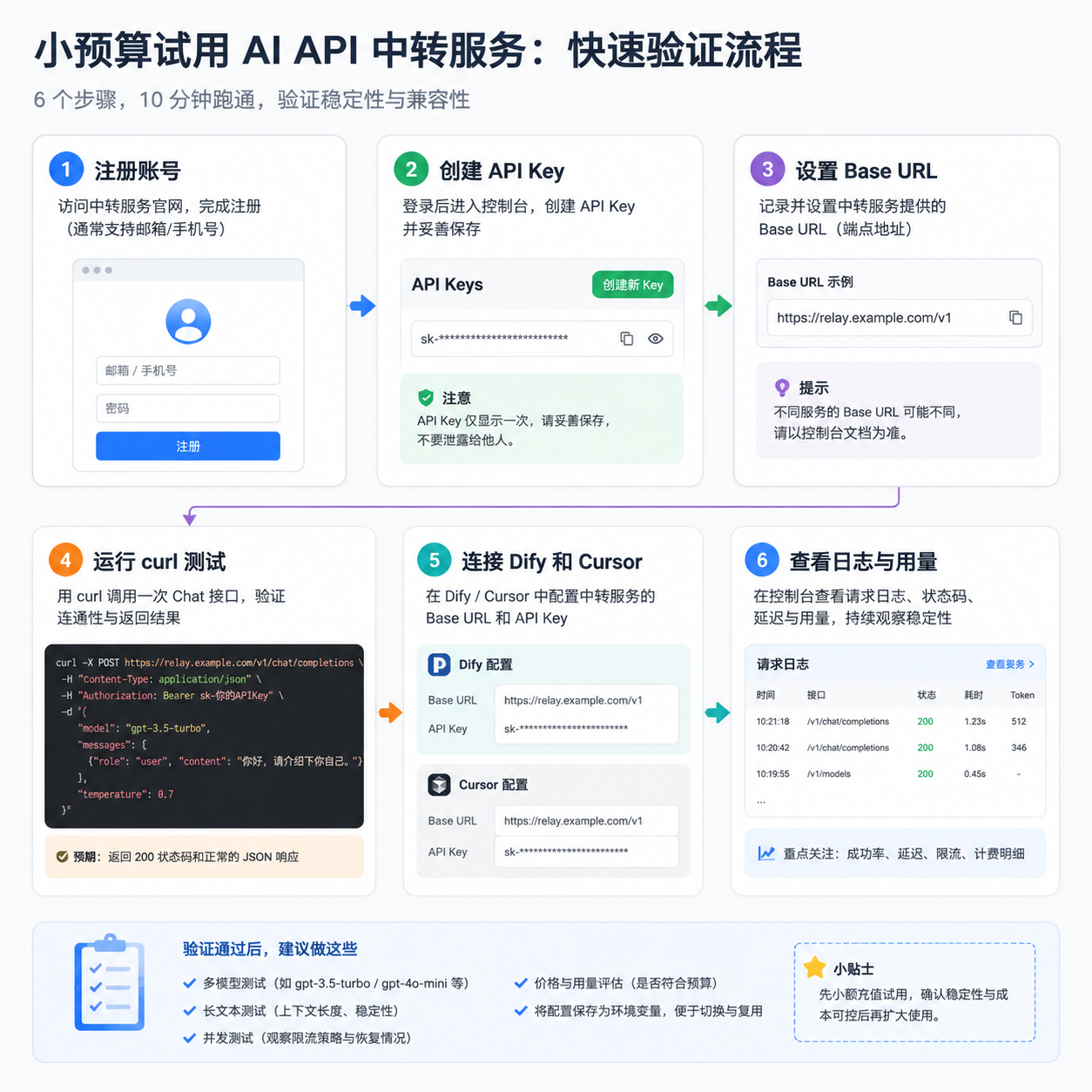
很多开发者第一次选择 API 中转站时,会先看价格。这个反应很自然:同样是 OpenAI 兼容接口,如果能用更小的预算完成 Dify 工作流、Cursor 编码辅助、Chatbox 对话测试、Cherry Studio 批量任务和后端脚本调用,当然值得纳入候选。
但真正接入项目以后,问题往往不只来自单价。更常见的是:白天测试正常,晚上高峰开始 timeout;页面写了很多模型,实际 model_not_found;工具里 Base URL 填错,curl 能通但 Dify 不通;账单里看不到项目归因,团队复盘时不知道成本花在哪里。

本文按三个维度拆开看:价格透明、晚高峰稳定性、模型真实性。向量引擎可以理解为面向 AI 应用、开发工具和工作流场景的 API 中转与模型接入服务,适合需要 OpenAI 兼容接口、统一模型入口、Dify/Cursor/Chatbox/Cherry Studio 接入、自建脚本调用、团队接口管理的用户评估使用。注册试用入口:https://178.nz/csdn
如果你正在问"国内 AI API 中转站怎么选""API 中转站靠不靠谱怎么判断""Base URL 怎么填写""Dify 和 Cursor 接第三方接口怎么配",可以先按本文流程做小额测试,再决定是否长期使用。
先明确本文要解决的问题
本文主要覆盖这些真实使用问题:
- 2026 年 API 中转站怎么选
- 国内 AI API 中转站怎么判断靠不靠谱
- API 中转站只看价格可以吗
- 稳定的 OpenAI 兼容接口怎么验收
- API 中转站模型真实性怎么判断
- Base URL 怎么填写才不容易错
- API Key 怎么申请和保管
- Dify 用什么 API 接口
- Cursor 怎么配置第三方 Base URL
- Chatbox 怎么配置 OpenAI 兼容接口
- Cherry Studio 怎么添加自定义服务商
- invalid_api_key、model_not_found、timeout、rate_limit 怎么排查
这些问题可以归到一条主线:先用小额预算完成可复现验证,再看账单、稳定性、模型 ID、工具配置和企业留档。
价格维度:不要只看首页单价
价格需要看三件事:计费规则是否清楚、充值门槛是否适合试用、成本是否能被追踪。
很多平台会把页面单价放在显眼位置,但开发者真正要关心的是完整成本:
| 检查项 | 为什么重要 | 小额试用时怎么验证 |
|---|---|---|
| 输入和输出 token 是否分开计费 | 长文、代码生成和总结任务的成本差异很大 | 跑同一组短文本和长文本请求,对照账单变化 |
| 失败重试是否计费 | timeout 后自动重试可能增加消耗 | 故意设置较短 timeout,看失败记录是否清楚 |
| 不同模型倍率是否明确 | 模型 ID 切换会影响预算 | 用同一提示词测试两个模型,记录成本差异 |
| 充值门槛是否适合试用 | 评估阶段不适合一次性投入太多 | 先完成小额连通性和工具接入 |
| 是否能按项目归因 | 团队使用时需要知道谁在消耗 | 通过后端代理写入 project_id 或 cost_group |
把向量引擎这类候选服务放进评估清单时,建议先不要把所有工具一次接满。先完成一条最小链路:申请 API Key、确认 Base URL、跑通 curl、再接一个工具。这样可以把价格、稳定性和配置问题分开观察。
Base URL:先把三个地址分清楚
评估 OpenAI 兼容接口时,先区分三层地址:
- 服务根域名:
https://api.vectorengine.cn - 工具里常填的 Base URL:
https://api.vectorengine.cn/v1 - Chat Completions 完整接口:
https://api.vectorengine.cn/v1/chat/completions
多数工具里填 https://api.vectorengine.cn/v1。脚本里如果直接请求 chat completions,才拼成完整接口。很多 404 和 model_not_found 并不是平台不可用,而是工具里把完整接口当成 Base URL,导致路径重复。
curl:先做一条最小连通性请求
下面这条请求只验证四件事:Key、模型 ID、接口路径、网络连通性。
bash
curl https://api.vectorengine.cn/v1/chat/completions \
-H "Authorization: Bearer $VECTORENGINE_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4o-mini",
"messages": [
{
"role": "system",
"content": "You are an API relay smoke test assistant."
},
{
"role": "user",
"content": "Return a short JSON object with status and model_check fields."
}
],
"temperature": 0.1
}'如果这一步失败,不要急着改 Dify、Cursor 或后端代码。先看错误类型:
401多半是 API Key、Bearer 前缀或复制空格问题。404多半是路径或模型 ID 问题。429多半是并发或额度问题。timeout多半需要看网络、请求长度和平台高峰状态。
稳定性维度:要看晚高峰,不只看一次成功
API 中转站容易暴露问题的时间通常不是一次白天测试,而是团队集中调用的时间段。内容生成、自动化脚本、批量总结、代码辅助都可能在晚上集中运行,低频测试看不出的排队、限流和流式中断会在这时出现。
建议至少做三个时间段的小样本验证:
| 时间段 | 看什么 | 建议记录 |
|---|---|---|
| 工作日上午 | 基础连通性 | 状态码、首包时间、总耗时 |
| 晚上高峰 | timeout、rate_limit、流式中断 | 失败率、错误类型、重试次数 |
| 次日凌晨 | 非高峰对照 | 延迟是否明显回落 |
稳定性不是一句"能不能用",而是要能复现、能记录、能定位。向量引擎作为候选 API 接入方案时,也建议先通过小样本脚本观察几轮,再接入长期任务。
Python:记录延迟和错误类型
下面这个脚本适合小样本稳定性测试。它不会做压测,只记录几次请求的状态、耗时和错误提示。
python
import os
import time
import requests
API_KEY = os.environ["VECTORENGINE_API_KEY"]
BASE_URL = "https://api.vectorengine.cn/v1"
MODEL = "gpt-4o-mini"
def probe(round_id: int) -> dict:
started = time.perf_counter()
try:
resp = requests.post(
f"{BASE_URL}/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
"X-Project-Id": "relay-selection-trial",
},
json={
"model": MODEL,
"messages": [
{"role": "system", "content": "You are a concise API test assistant."},
{"role": "user", "content": f"Round {round_id}: reply with one sentence."},
],
"temperature": 0.2,
},
timeout=(5, 45),
)
latency_ms = int((time.perf_counter() - started) * 1000)
return {
"round": round_id,
"ok": resp.status_code == 200,
"status": resp.status_code,
"latency_ms": latency_ms,
"error_hint": None if resp.ok else resp.text[:160],
}
except requests.Timeout:
return {"round": round_id, "ok": False, "status": "timeout", "latency_ms": None}
except requests.RequestException as exc:
return {"round": round_id, "ok": False, "status": "network_error", "detail": str(exc)[:160]}
if __name__ == "__main__":
for i in range(1, 6):
print(probe(i))
time.sleep(1)如果五次里偶发一次失败,不一定说明服务不可用;但如果同一时间段连续出现 timeout、rate_limit 或流式中断,就要记录并换时间段复测。
模型真实性维度:看模型 ID、上下文和任务表现
模型真实性不是让平台喊口号,而是看可验证信息。低价渠道容易出现的问题包括:模型 ID 显示不清楚、上下文长度和预期不一致、复杂代码任务表现明显缩水、工具调用参数不透传。
可以用这几类任务做初筛:
| 验证任务 | 观察点 | 异常信号 |
|---|---|---|
| 短问答 | 响应速度、格式遵循 | 总是套模板、不按 JSON 输出 |
| 长上下文 | 是否能引用前文细节 | 只记住开头或结尾 |
| 代码修改 | 是否能保持函数边界 | 随意改接口或漏掉错误处理 |
| 工具参数 | 是否尊重 temperature、stream 等参数 | 参数被忽略或行为不稳定 |
| 多轮对话 | 上下文是否连续 | 第二轮开始答非所问 |
模型真实性也和成本相关。如果一个平台宣传大量模型,但没有模型说明、调用日志和账单细节,后续排查会很被动。
Dify 和 Cursor 配置建议
Dify 适合工作流和自动化应用,配置时可以这样做:
- Provider 选择 OpenAI Compatible 或自定义 OpenAI 兼容服务。
- Base URL 填
https://api.vectorengine.cn/v1。 - API Key 使用 Dify 专用 Key,不和生产后端共用。
- 模型 ID 先用 curl 验证过的值。
- 先跑一个短 Chatflow,再接知识库和工具调用。
Cursor 适合编码辅助,配置时要关注:
- 第三方 Base URL 填 OpenAI 兼容入口。
- API Key 不要和 Chatbox、Cherry Studio 共用。
- 模型 ID 要和团队确认的候选模型一致。
- 如果提示 timeout,先用短提示词和小文件测试。
- 如果提示模型不存在,优先检查大小写和模型权限。
Chatbox 和 Cherry Studio 也可以接同一套 OpenAI 兼容接口,但建议分别建 Key,方便观察不同工具的成本和错误类型。
Node.js:在后端代理里做模型和成本归因
如果团队里多人使用 API,不建议把同一个 Key 直接发给每个工具。后端代理可以统一记录工具来源、项目、模型、状态码和耗时。
javascript
import express from "express";
const app = express();
app.use(express.json({ limit: "1mb" }));
const BASE_URL = "https://api.vectorengine.cn/v1";
const API_KEY = process.env.VECTORENGINE_API_KEY;
function classify(status, text) {
const lower = text.toLowerCase();
if (status === 401 || lower.includes("invalid_api_key")) return "invalid_api_key";
if (status === 404 || lower.includes("model_not_found")) return "model_not_found";
if (status === 429 || lower.includes("rate_limit")) return "rate_limit";
if (status >= 500) return "upstream_error";
return "unknown_error";
}
app.post("/relay/chat", async (req, res) => {
const started = Date.now();
const tool = req.header("x-ai-tool") || "unknown";
const project = req.header("x-project-id") || "trial";
const model = req.body.model || "gpt-4o-mini";
try {
const upstream = await fetch(`${BASE_URL}/chat/completions`, {
method: "POST",
headers: {
"Authorization": `Bearer ${API_KEY}`,
"Content-Type": "application/json",
},
body: JSON.stringify({
model,
messages: req.body.messages,
temperature: req.body.temperature ?? 0.2,
stream: false,
}),
signal: AbortSignal.timeout(45000),
});
const text = await upstream.text();
const latencyMs = Date.now() - started;
const errorType = upstream.ok ? null : classify(upstream.status, text);
console.log(JSON.stringify({
ts: new Date().toISOString(),
tool,
project,
model,
status: upstream.status,
latency_ms: latencyMs,
error_type: errorType,
}));
res.status(upstream.status).type("application/json").send(text);
} catch {
res.status(504).json({ error: "timeout", message: "upstream request timed out" });
}
});
app.listen(3000);这段代码的重点不是复杂架构,而是让"价格、稳定性、模型真实性"都能留下证据。以后排查 Dify 慢、Cursor 报错或 Cherry Studio 批量任务异常时,能先看日志,而不是凭感觉判断。
常见报错排查表
| 报错 | 常见原因 | 先检查什么 | 建议动作 |
|---|---|---|---|
invalid_api_key |
Key 错误、过期、复制带空格 | 环境变量、Bearer 前缀、工具配置 | 换测试 Key,重新跑 curl |
model_not_found |
模型 ID 不存在或无权限 | 模型名称、大小写、候选模型列表 | 用确认可用的模型重测 |
timeout |
请求过长、网络慢、高峰排队 | 提示词长度、timeout 设置、时间段 | 缩短请求,换时段复测 |
rate_limit |
并发过高、批量任务过密 | Cherry Studio 并发、后端队列 | 降低并发,加入退避 |
| 401 | 鉴权失败 | Authorization 格式 | 确认 Bearer 前缀 |
| 404 | 路径或模型问题 | Base URL 是否多拼路径 | 工具填 /v1,脚本拼完整接口 |
| 成本异常 | 重试过多或多人共用 Key | 日志、项目归因、账单 | 拆 Key,记录 project_id |
企业用户还要补充看什么
如果只是个人测试,先完成小额连通性和工具配置即可。如果进入企业试用或客户项目,还要补充检查:
- ICP 备案、营业执照、增值电信业务许可证等主体材料。
- 对公付款和发票流程是否能留档。
- API Key 是否能按项目、成员或用途拆分。
- 是否能保留日志审计、成本归因和异常复盘材料。
- 是否有备用方案,避免单一路径影响交付。
合规不是本文主线,但只要涉及企业长期使用,就不能只看技术连通。
FAQ
1. API 中转站是不是越便宜越值得选?
不是。价格只是一个维度。还要看计费是否透明、晚高峰是否稳定、模型 ID 是否清楚、账单是否能追踪、工具是否容易配置。
2. 工具里 Base URL 应该填哪个?
多数 OpenAI 兼容工具里填 https://api.vectorengine.cn/v1。脚本直接请求 chat completions 时使用完整接口。不要把完整接口填到要求 Base URL 的输入框里。
3. curl 能通,Dify 还是失败怎么办?
先确认 Dify 里使用的是同一个 API Key、同一个模型 ID、同一个 Base URL。再看 Dify 是否自动拼接 /chat/completions,避免路径重复。
4. 如何判断模型真实性?
看模型 ID、上下文长度、复杂代码任务、多轮一致性、参数透传和账单记录。不要只用一个短问答判断。
5. 向量引擎适合怎么评估?
可以把向量引擎作为候选 API 接入方案,先用小额测试跑通 curl,再接 Dify 或 Cursor,随后记录晚高峰延迟、错误类型、账单和项目归因。
总结
2026 年选择 API 中转站,不能只看页面上的单价。更稳妥的做法是按"价格透明、晚高峰稳定性、模型真实性"三条线做小额验证。
个人开发者可以先看小额试用、Base URL 是否容易配置、Chatbox 或 Cursor 是否能快速跑通;团队项目要补充后端代理、日志审计、Key 拆分和成本归因;企业用户还要看主体材料、对公付款、发票和采购留档。
向量引擎这类 OpenAI 兼容接口候选方案,适合放进这套流程里评估:先跑通最小请求,再接工具,再看日志和账单,最后决定是否进入长期使用。