从 Overlap 到语义边界、句子窗口、父子 Chunk、命题化切割与 Contextual Retrieval
文档切割时语义被切断,很多人第一反应是加overlap,但 overlap 只是兜底。真正的工程答案,是先减少错误切割,再在检索阶段把上下文补回来。
一、语义被切割到底是什么问题?
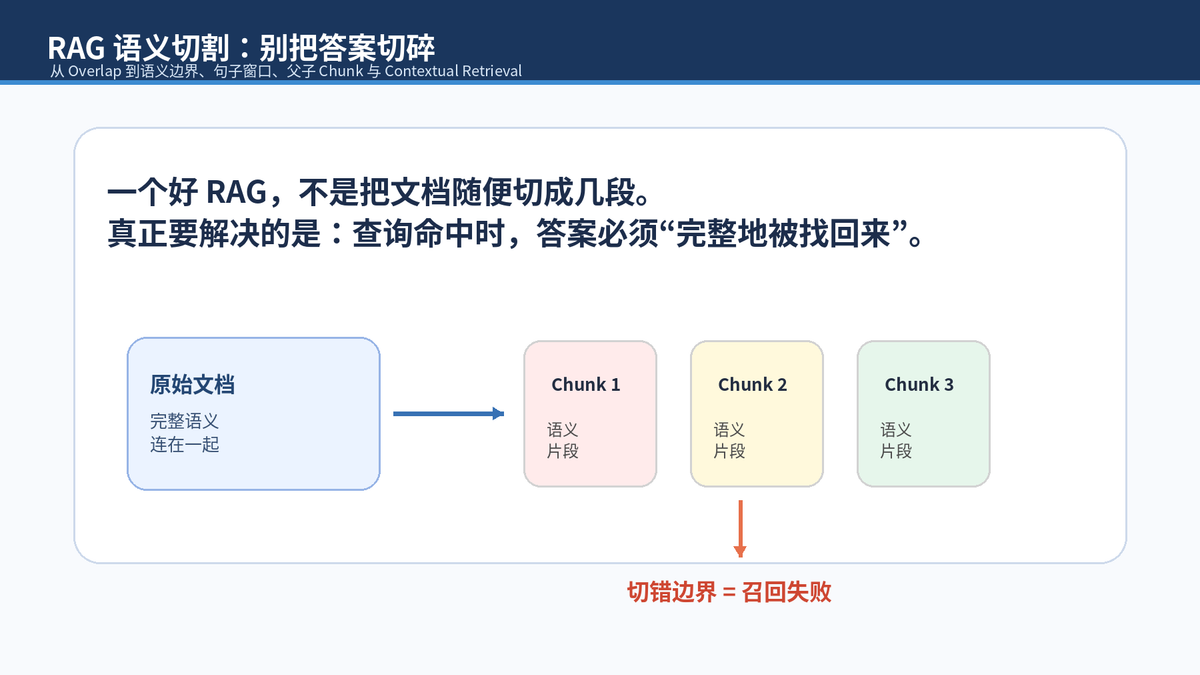
语义截断不是"信息没入库",而是"信息被拆成了两个弱片段"。比如一句企业服务条款被切成前半句和后半句,用户问"企业用户有哪些服务保障"时,两个 chunk 单独看都不够像答案,向量召回就可能失败。

所以,RAG 切割的目标不是把每个 chunk 做得一样长,而是让每个可被召回的单元尽量语义完整、主题集中、上下文可恢复。
二、两个方向:切得更好,或检索后补回来
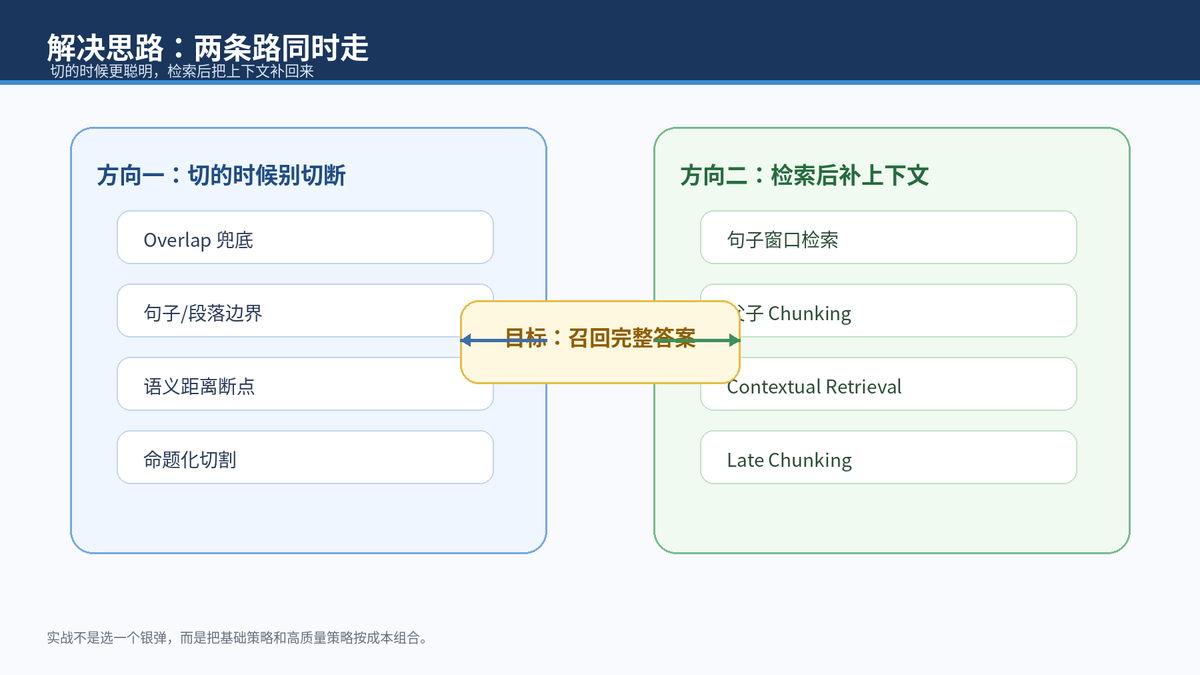
规避语义被切割,可以分成两个方向。第一类是在切割阶段尽量别把句子、段落、主题边界切断;第二类是在检索阶段,命中一个细粒度片段后,把它周围或父级上下文一起返回给大模型。
三、方案一:Overlap 是基础兜底,不是万能药
Overlap 的作用很简单:让相邻 chunk 共享一段文本,避免边界附近的文字完全丢失。一般可以从 chunk_size 的 10% - 20% 开始调,比如 chunk_size=800 token,overlap=100-160 token。

但 overlap 解决不了所有问题。它能让跨边界文字在某个 chunk 里出现,却不能保证这个 chunk 的主题足够清晰,也不能保证它在检索时排名靠前。遇到长条款、多条件、多结论的知识,单靠 overlap 很容易变成"存了,但搜不到"。
四、方案二:按语义边界切割
比固定长度更稳的做法,是优先沿着自然边界切:先按标题和段落,再按句子,最后才按 token 长度兜底。LangChain 文档也把文本结构、长度和文档结构视为常见切割策略,并说明递归切割会尽量保留段落、句子等更大的自然单元。
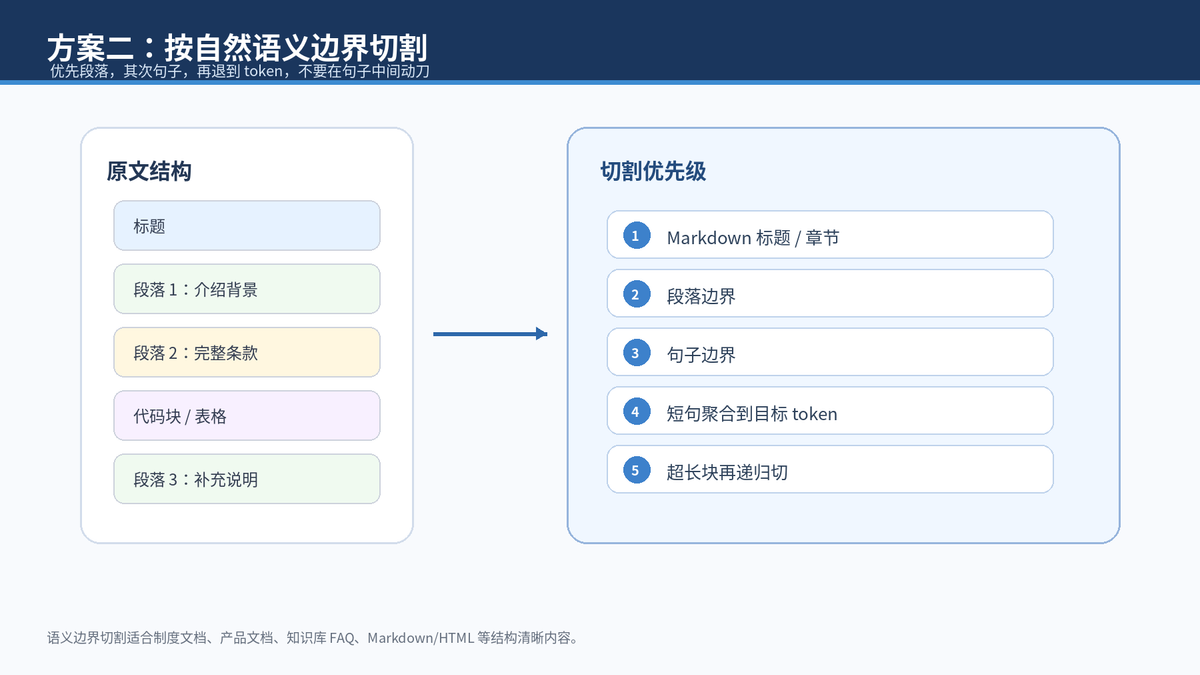
实现时可以这样理解:一个 chunk 就像一个小段落,最好有明确主题,能独立表达一个意思。如果文档是 Markdown、HTML、JSON、代码文件,还应该使用结构感知切割,不要把表格行、函数体、标题层级切乱。
bash
from langchain_text_splitters import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=120,
separators=["\n## ", "\n### ", "\n\n", "。", "!", "?", "\n", " ", ""]
)
chunks = splitter.split_text(document_text)五、进阶:语义距离断点切割
语义边界切割还可以再进一步:把文档先切成句子,给每个句子生成 embedding,计算相邻句子的语义距离。如果距离突然变大,说明主题切换明显,就把这里作为候选切点。LlamaIndex 的 SemanticSplitterNodeParser 就是这类思路:根据句子间 embedding 相似度自适应选择断点。
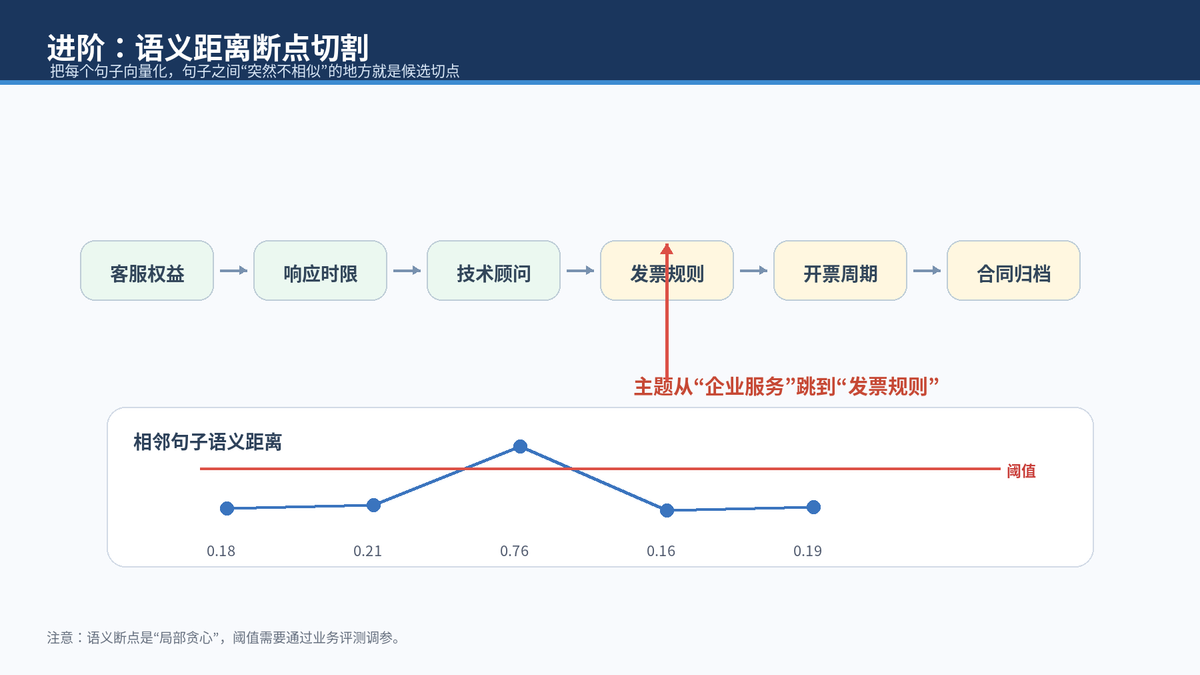
这类方案看起来很智能,但不是必胜。2024 年一项关于语义切割成本的研究指出,语义切割在部分场景有收益,但收益并不总是稳定,也不一定足以覆盖额外计算成本。因此,语义切割一定要接评测集,而不是凭感觉上线。
bash
from llama_index.core.node_parser import SemanticSplitterNodeParser
from llama_index.embeddings.openai import OpenAIEmbedding
splitter = SemanticSplitterNodeParser(
buffer_size=1,
breakpoint_percentile_threshold=95,
embed_model=OpenAIEmbedding()
)
nodes = splitter.get_nodes_from_documents(documents)六、方案三:句子窗口检索
句子窗口检索的思路是:索引时每个句子单独向量化,检索时命中一个句子后,不只返回这一句,而是把前后 N 句一起返回。这样既保持了单句级定位精度,又让 LLM 看到完整上下文。

bash
def sentence_window(sentences, hit_index, window=2):
start = max(0, hit_index - window)
end = min(len(sentences), hit_index + window + 1)
return "".join(sentences[start:end])
# 向量库命中 sentence_id=42
context = sentence_window(all_sentences, hit_index=42, window=2)句子窗口的缺点也明显:索引数量会变多,元数据要保存句子顺序、文档 ID、段落 ID。适合"答案在某一句附近,但需要上下文解释"的制度文档、客服知识库和产品手册。
七、方案四:父子 Chunking
父子切割可以理解成"用小块找,用大块答"。小 chunk 主题聚焦,负责精确召回;父 chunk 包含更完整的段落或章节,负责给 LLM 生成答案。检索命中 child 后,系统通过 parent_id 找到父级内容,返回给模型。
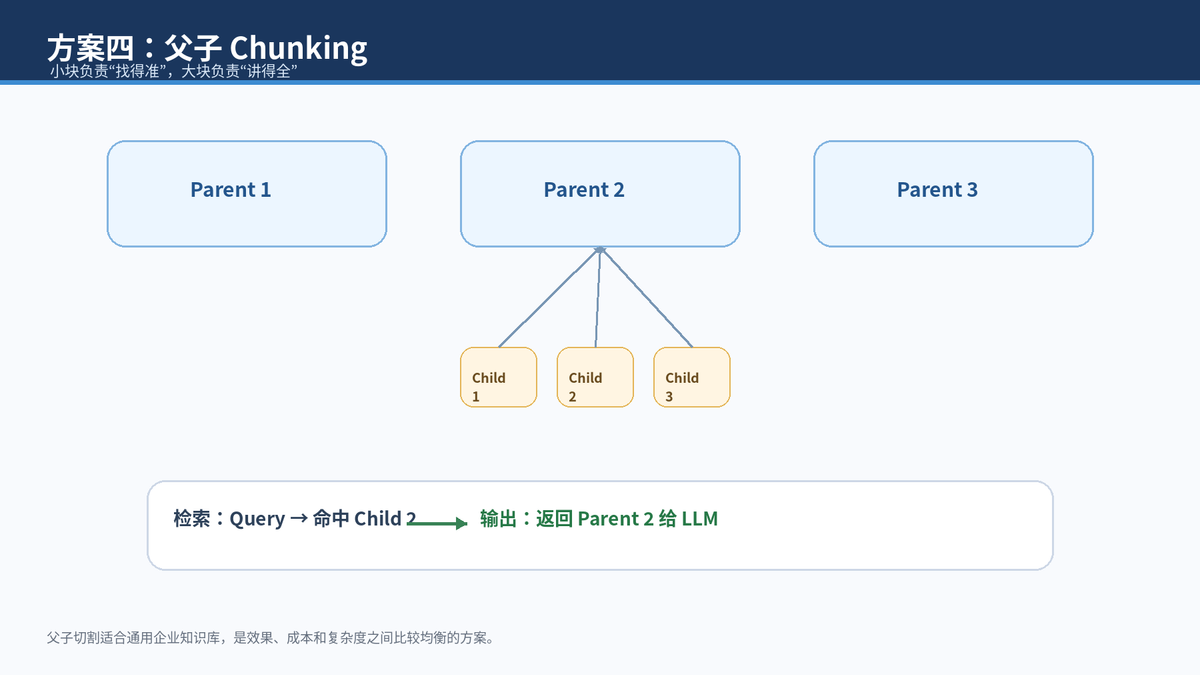
父子 Chunk 是很多生产 RAG 的默认增强方案。它比句子窗口更可控,因为父块大小可以固定;也比单纯大 chunk 更准,因为检索仍然基于小块。代价是索引和元数据设计更复杂。
bash
child_record = {
"child_id": "docA_p03_c07",
"parent_id": "docA_p03",
"text": "企业用户客服响应时间不超过 2 小时。",
"metadata": {"doc_id": "docA", "section": "企业服务条款"}
}
# 检索命中 child 后,根据 parent_id 取完整父块
parent_text = parent_store.get(child_record["parent_id"])八、方案五:命题化切割
命题化切割是更激进的方案:不按原文位置切,而是让 LLM 把文档抽取成一条条独立事实。每条命题都尽量自包含,单独拿出来也能看懂。比如一个长句可以拆成三个事实:享有优先客服、响应不超过 2 小时、可申请技术顾问。

它的优点是语义密度高、检索精度好;缺点是成本高,并且需要防止 LLM 抽取时改写事实、漏事实或编事实。适合合同条款、风控规则、医疗/法律等高价值知识,不适合所有文档无脑全量使用。
九、方案六:Contextual Retrieval
Contextual Retrieval 的关键不是"重新切",而是在向量化前给每个 chunk 加一段背景说明。Anthropic 的方案是:让模型看完整文档和当前 chunk,为当前 chunk 生成简短上下文,再把"上下文 + chunk"一起做 embedding 和 BM25 索引。Anthropic 公布的实验中,Contextual Embeddings + Contextual BM25 将 Top-20 检索失败率从 5.7% 降到 2.9%,相当于降低 49%。

bash
CONTEXT_PROMPT = """
你会看到一篇完整文档和其中一个 chunk。
请用 1-2 句话说明这个 chunk 在全文中的位置、主题和关键背景。
不要引入原文没有的信息。
<document>
{full_document}
</document>
<chunk>
{chunk}
</chunk>
"""
context = llm.generate(CONTEXT_PROMPT.format(
full_document=doc_text,
chunk=chunk_text
))
index_text = context + "\n" + chunk_text这个方案尤其适合 chunk 离开原文后"没头没尾"的知识:政策条款、产品规则、会议纪要、长文档里的跨段引用。成本可以通过 Prompt Caching、批处理和只对高价值文档启用来控制。
十、扩展方案:Late Chunking
传统流程是先切 chunk,再分别 embedding。Late Chunking 则反过来:先用长上下文 embedding 模型编码完整文档,让 token 表示带上全局语境,再在池化阶段形成 chunk 向量。Late Chunking 论文指出,传统单独编码 chunk 会丢失周围上下文,Late Chunking 试图保留这种上下文信息。

Late Chunking:先看全文,再生成 chunk 向量
它不是所有系统都能直接用,因为需要长上下文 embedding 模型和合适的实现。但它提醒我们:chunk 的质量不仅取决于怎么切,也取决于 embedding 时模型看到了多少上下文。
十一、几种方案怎么选?
不要把这些方案理解成互斥选项。更真实的做法是分层组合:基础层用 overlap 和语义边界,通用增强层用父子 Chunk 或句子窗口,高质量层再叠加 Contextual Retrieval 或命题化切割。
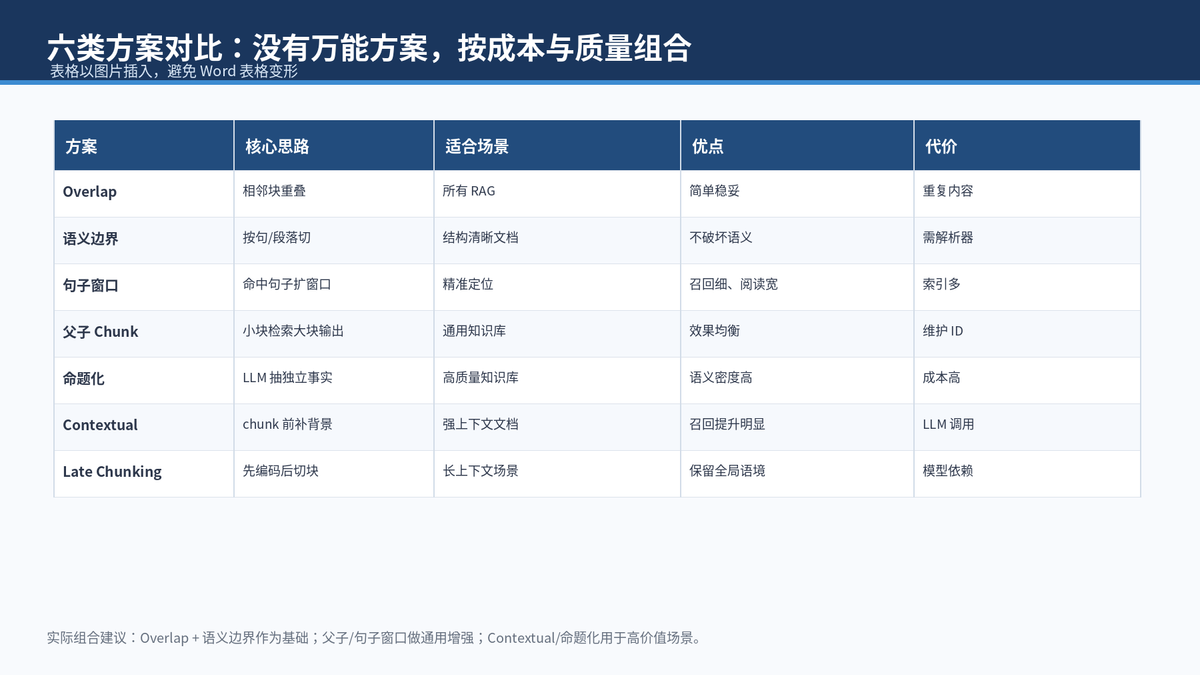
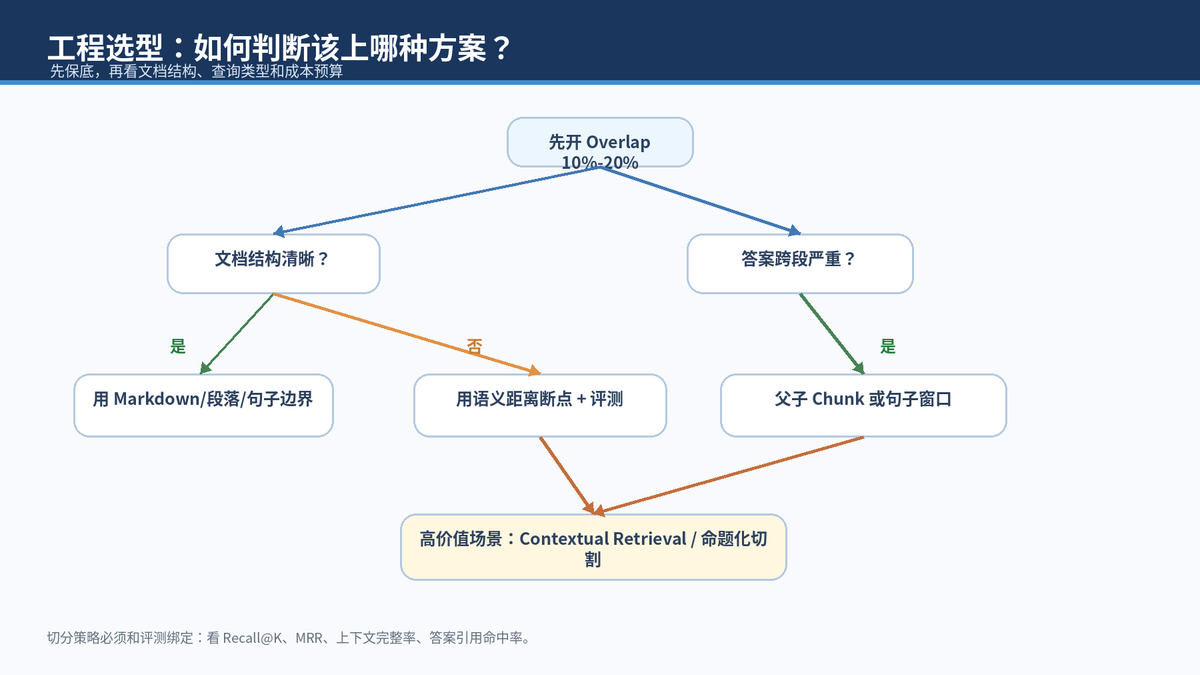
如果是普通知识库,优先从"结构化切割 + overlap + 父子 Chunk + rerank"开始。如果是合同、风控、医疗、客服SLA这类高价值知识,再考虑 Contextual Retrieval 和命题化切割。如果文档非常长、跨段依赖强,可以评估 Late Chunking 或长上下文 embedding 方案。
十二、生产级实现:切割策略必须可评测
切割不是写一个 splitter 脚本就完事。只要调整 chunk_size、overlap、断点阈值、父子块大小,都可能影响召回、延迟、成本和答案完整性。因此,生产 RAG 必须把切割策略纳入评测闭环。

固定评测集:至少覆盖高频问题、长答案问题、跨段问题、边界条件问题。
核心指标:Recall@K、MRR、nDCG、上下文完整率、答案引用命中率、幻觉率。
成本指标:索引条数、向量存储大小、平均检索延迟、rerank 延迟、LLM 输入 token。
上线方式:每次切割策略变更都要重建索引,做 A/B 或离线回归。
十三、一个可落地的组合方案
如果让我在企业知识库里落地一套比较稳的方案,我会这样设计:
文档解析时保留标题层级、页码、段落、表格和来源链接。
按 Markdown/标题/段落/句子做递归切割,chunk_size 初始 600-900 token,overlap 10%-20%。
同时建立 child chunk 和 parent chunk:child 用于检索,parent 用于回答。
对合同、制度、SLA 等高价值文档启用 Contextual Retrieval。
召回阶段做向量 + BM25 混合检索,再用 rerank 过滤噪声。
返回给 LLM 前做去重、合并、排序,并保留引用来源。
用固定问题集持续评测 Recall@K、Faithfulness、答案完整率和成本。
十四、面试回答模板
如果面试官问"怎么规避语义被切割掉的问题",不要只回答"加 overlap"。可以这样回答:
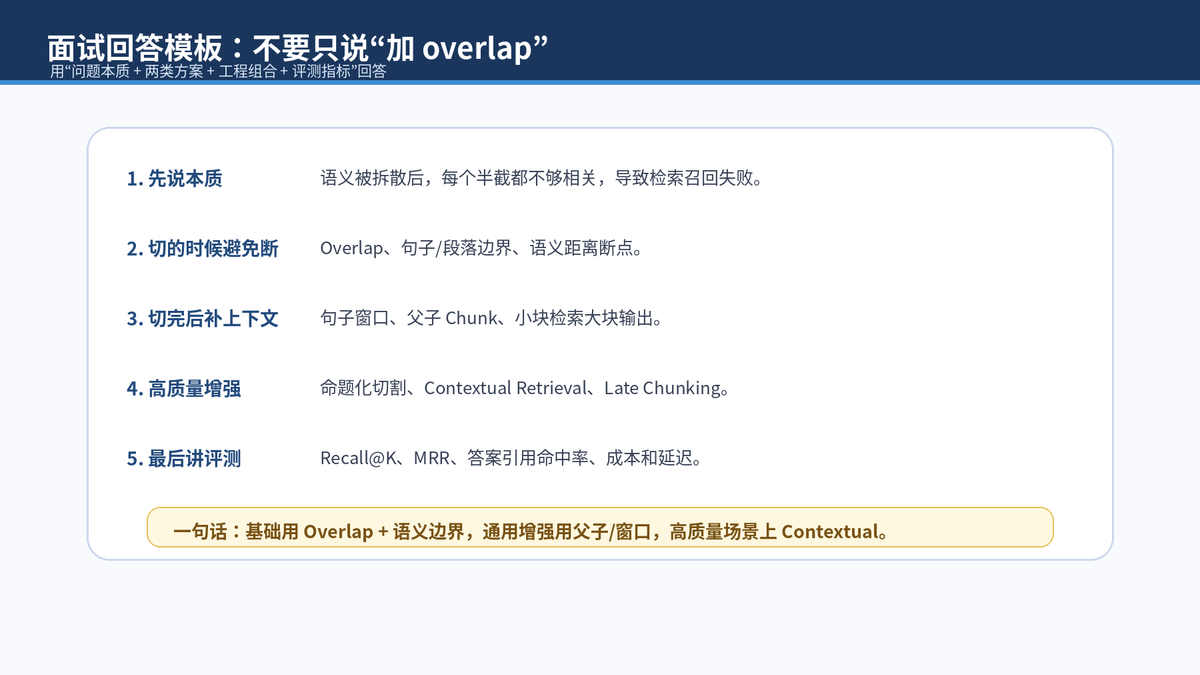
语义截断的本质是 chunk 被拆散后,单个片段不够完整,导致检索相关度下降。我的处理思路分两类:第一类是在切的时候尽量不截断语义,包括 overlap、句子/段落边界、语义距离断点;第二类是在检索后补上下文,包括句子窗口、父子 Chunk。对于高质量知识库,可以进一步上命题化切割和 Contextual Retrieval。最终不靠感觉判断,而是用 Recall@K、上下文完整率和答案引用命中率评测。