文章目录
-
- 一、论文基础信息
- 二、研究前置:从FinLLM到MFFM的演进与现存行业痛点
-
- [1. 两代金融大模型对比](#1. 两代金融大模型对比)
- [2. 行业原生底层问题](#2. 行业原生底层问题)
- 三、第一部分:多模态金融数据与数据中心范式(论文第2章)
-
- [1. 核心范式:数据中心(Data-Centric)](#1. 核心范式:数据中心(Data-Centric))
- [2. 八大金融模态完整分类](#2. 八大金融模态完整分类)
- [3. 六类核心多模态金融数据源详解](#3. 六类核心多模态金融数据源详解)
- [四、第二部分:多模态金融应用------Agentic FinAI金融智能体生态(论文第3章)](#四、第二部分:多模态金融应用——Agentic FinAI金融智能体生态(论文第3章))
-
- [1. 核心载体:FinGPT驱动的FinAgent金融智能体](#1. 核心载体:FinGPT驱动的FinAgent金融智能体)
- [2. 标杆案例:巴菲特投资智能体Buffett Agent](#2. 标杆案例:巴菲特投资智能体Buffett Agent)
- [3. 金融智能生态三大支撑要素](#3. 金融智能生态三大支撑要素)
- 五、第三部分:MFFM模型发展现状与技术前景(论文第4章)
-
- [1. MFFM完整三阶段研发生命周期](#1. MFFM完整三阶段研发生命周期)
- [2. 现有主流MFFM模型梳理](#2. 现有主流MFFM模型梳理)
- [3. 金融多模态评测基准体系(Benchmark)](#3. 金融多模态评测基准体系(Benchmark))
- [4. MFFMs六大核心发展前景(未来技术路线)](#4. MFFMs六大核心发展前景(未来技术路线))
- 六、第四部分:MFFM落地核心挑战与安全治理方案(论文第5章)
-
- [1. 数据层面挑战](#1. 数据层面挑战)
- [2. 算力与工程挑战](#2. 算力与工程挑战)
- [3. 监管数字化DRR挑战](#3. 监管数字化DRR挑战)
- [4. 伦理与可信AI挑战](#4. 伦理与可信AI挑战)
- [5. FinAgent全链路四大风险](#5. FinAgent全链路四大风险)
- [6. 创新防护方案:ZKP零知识证明+区块链护栏框架](#6. 创新防护方案:ZKP零知识证明+区块链护栏框架)
- 七、论文结论与未来宏观发展方向
-
- [1. 整体结论](#1. 整体结论)
- [2. 长期产业与研究四大战略方向](#2. 长期产业与研究四大战略方向)
- 八、附录术语体系

Multimodal Financial Foundation Models (MFFMs): Progress, Prospects, and Challenges
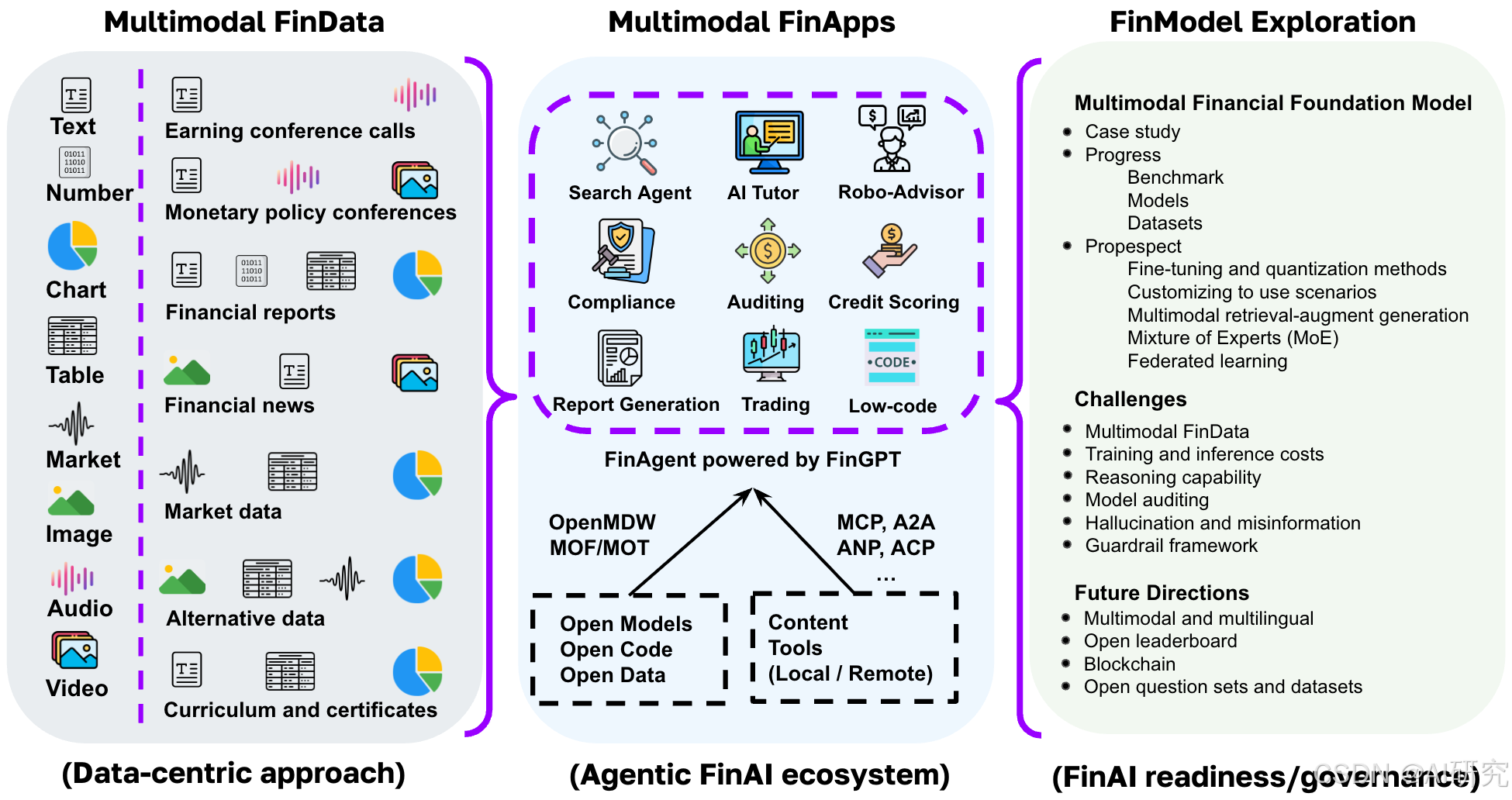
以下内容基于论文翻译整理
一、论文基础信息
- 发布背景:2024 ACM ICAIF金融AI顶会配套MFFM专题研讨会立场论文,arXiv预印本2025年7月更新;作者来自哥伦比亚大学、史蒂文斯理工、华盛顿大学Secure-FinAI实验室,同时总结Linux基金会FinOS FinLLM研究成果。
- 核心定位 :首篇全面综述多模态金融基础模型(MFFMs) ,对比传统纯文本金融大模型FinLLM,完整梳理多模态金融数据、金融智能体应用、模型研发进展、未来技术路线、产业落地挑战与治理框架五大板块。
- 核心论点 :传统单文本FinLLM(BloombergGPT、初代FinGPT)仅能处理文字,无法适配金融行业海量图文、音频、时序、表格混合数据;MFFMs可统一解析文本、音频、图表、时序、报表、视频等异构金融数据,构建Agentic FinAI智能金融生态,但当前存在数据、算力、幻觉、监管、伦理、开放生态六大落地瓶颈,需配套安全防护与治理体系实现FinAI就绪。
- 核心贡献
- 系统性划分全品类多模态金融数据,提出数据中心(Data-Centric) 研发范式;
- 提出FinAgent双分类体系(工具智能体/金融业务智能体),构建完整金融智能体框架;
- 梳理MFFM完整三阶段研发生命周期(预训练-微调-对齐),对比闭源BloombergGPT与开源FinGPT路线优劣;
- 汇总全球主流金融多模态评测基准与代表性开源MFFM模型;
- 系统拆解产业落地全维度挑战,提出零知识证明+区块链双底层的FinAgent安全护栏框架;
- 明确MFFMs六大未来技术发展方向。
二、研究前置:从FinLLM到MFFM的演进与现存行业痛点
1. 两代金融大模型对比
- 第一代FinLLM(纯文本)
- 闭源代表:BloombergGPT(50B参数,708B训练token,训练成本276万美元、65万GPU小时,一次性大规模预训练,仅文本处理);
- 开源代表:FinGPT(8B基座,LoRA/QLoRA轻量化微调,单RTX3090即可训练,成本低于100美元,实时爬取34类金融文本持续迭代);
- 局限:无法解读财报图表、股价K线、电话会议语音情绪、央行发布会视频、CFA计算题表格等多模态信息。
- 第二代MFFMs(多模态金融基础模型):统一融合文本、数值、表格、时序、图表、音频、视频、卫星替代数据,实现跨模态联合推理,适配投资、审计、合规、交易全场景。
2. 行业原生底层问题
- 黑盒不可解释:模型决策无溯源,金融风控、审计、监管场景无法追责;
- 模型自相残杀(Model Cannibalism):大量新模型抄袭GPT-4等头部模型标注数据做监督训练,无原生金融领域学习;
- 开放洗白(Openwashing) :宣称开源但使用限制性协议,无完整权重、数据、文档开放;提出模型开放框架MOF,从16个维度量化模型开放度,推荐Apache/MIT宽松开源协议与OpenMDW开源许可证;
- 数据、隐私、偏见、幻觉、监管合规等多重落地障碍。
三、第一部分:多模态金融数据与数据中心范式(论文第2章)
1. 核心范式:数据中心(Data-Centric)
遵循"垃圾进、垃圾出(GIGO)"原则,高质量多模态数据是MFFM落地的前置条件。金融数据天然兼具流式、低信噪比、半结构化特征,模态混杂,必须搭建标准化数据采集、对齐、清洗、标注流水线。
2. 八大金融模态完整分类
文本、数值、表格、时序市场数据、图表、音频、图像/视频、另类数据(气候、卫星、社交舆情)。
3. 六类核心多模态金融数据源详解
(1)财报电话会议ECC(音频+文本双模态)
- 场景:上市公司季度业绩发布会,CEO/CFO演讲+分析师问答,语音音频+文字转录稿;
- 案例:特斯拉2024Q3电话会议,发布会后股价显著上涨;
- 数据集:MDRM(576场标普500企业会议,8.8万条音频-文本对齐样本);
- 痛点:数据集行业覆盖不足、音频与文本精准对齐难度高。
(2)央行货币政策会议MPC(音频+文本+视频三模态)
- 场景:美联储、欧央行等政策发布会,决定利率、通胀调控,直接影响汇率、大宗商品、股市;
- 数据集:MONOPOLY(180GB,六国央行340场会议,15729分钟音视频文本);
- 痛点:多模态数据存储成本高、音视频文字跨模态对齐技术门槛高。
(3)金融监管报告
涵盖SEC 10-K年报、10-Q季报、8-K重大事件公告、XBRL标准化财报、券商研报、年报;
现状:通用大模型在FinanceBench财报问答准确率仅19%-30%,存在术语歧义、表格提取、财务计算三大错误。
(4)金融新闻与社交舆情
覆盖彭博、路透、推特、Reddit等;典型案例:GameStop空头挤压事件,社交舆情直接驱动股价暴涨;
痛点:信息可信度低、海量数据处理困难、图文表格文本难以对齐。
(5)市场时序数据+另类数据
- 市场数据:股票、期货、汇率时序K线、交易量、财务指标;支撑量化交易、强化学习交易智能体FinRL;
- 另类数据:气候气象、卫星影像、用户行为数据,用于大宗商品、周期行业价格预测;
- 合成多模态数据:解决金融私有数据隐私、高质量标注稀缺问题,是前沿研究方向,但金融领域成熟方案缺失。
(6)金融考证/教学数据(CFA、FRM、CPA考题)
包含文字、汇率表格、计算题、图表,用于评测模型金融推理、数学计算能力;现有GPT-4等大模型复杂考题正确率极低,代表基准QFinBen。
四、第二部分:多模态金融应用------Agentic FinAI金融智能体生态(论文第3章)
1. 核心载体:FinGPT驱动的FinAgent金融智能体
全部智能体基于MCP模型上下文协议、A2A智能体互操作协议 实现工具调用、多智能体协同;分为工具智能体、金融业务智能体两大类别。
类别1:工具智能体(通用底层工具)
- 检索智能体Search Agent:对接本地财报、雅虎财经、社交平台、数据库,实时拉取多模态金融数据,低成本替代彭博终端;
- AI教学智能体Tutor Agent:面向CFA、金融课程,个性化答疑,依托QFinBen题库评测模型推理能力;
- 智能投顾Robo-Advisor:融合多模态数据生成个性化资产配置,降低传统投顾服务门槛;
- 低代码编码智能体Coding Agent:自动生成量化分析、回测、数据清洗Python代码。
类别2:金融业务智能体(垂直业务落地)
- 信用评分智能体:基于多维度数据生成可解释信用打分;
- 审计智能体Auditing Agent:自动核查财报、识别财务风险,减少人工审计误差;
- 合规智能体Compliance Agent:自动化监管条文解读、合规校验,适配多国碎片化金融监管;
- 报告生成智能体:自动整合表格、图表、时序数据生成标准化研报、监管申报材料;
- 交易智能体Trading Agent
- FinRL:深度强化学习交易框架,集成DQN、PPO等算法;
- FinMem:单智能体,内置记忆库动态更新交易策略;
- FinCon:多层级多智能体系统,具备自我复盘修正机制;
- XBRL智能体:解析标准化监管财报,提取结构化财务指标。
2. 标杆案例:巴菲特投资智能体Buffett Agent
- 训练方案:基于Llama3.1-8B基座,FinLoRA轻量化微调,2.5万条巴菲特问答数据集(股东信、股东大会音频、采访、伯克希尔财报);
- 成本:微调算力成本不足100美元;
- 效果:输出风格贴合巴菲特通俗化价值投资逻辑,BERTScore相比基座提升8.8%;可对接检索智能体实时获取最新市场数据。
3. 金融智能生态三大支撑要素
- 开放模型:依托MOF开放度框架、OpenMDW开源协议,解决"开放洗白"乱象;
- 标准化智能体协议
- MCP:打通AI与本地文件、数据库、线上金融数据源的双向安全连接;
- A2A:实现多个金融智能体互相通信、协同完成复杂任务;
- 开源生态配套:开放数据集、评测排行榜、开源代码仓库(Awesome-MFFMs)。
五、第三部分:MFFM模型发展现状与技术前景(论文第4章)
1. MFFM完整三阶段研发生命周期
- 持续预训练:通用语料+海量金融多模态语料联合训练,搭建领域基础认知;代表:Open-FinLLMs(FinLLaMA),520亿金融token持续预训练;
- 指令微调:多模态图文/音视频指令数据集训练,对齐用户金融任务需求;代表FinLLaVA(143万图文对微调,图表理解能力超越多数闭源模型);
- 人类偏好对齐:采用DPO直接偏好优化,降低幻觉、输出符合金融专业规范;代表FinTral。
2. 现有主流MFFM模型梳理
- Open-FinLLMs:FinLLaMA(文本金融大模型)、FinLLaVA(多模态,图表表格理解领先开源模型);
- FinTral:基于Mistral-7B,文本任务五项超越GPT-4,多模态仅弱于GPT-4V;
- FinVis-GPT:金融图表专用多模态模型,专攻K线、技术指标解读;
3. 金融多模态评测基准体系(Benchmark)
论文汇总十余套专用基准,覆盖文本、音频、图表、多语言、智能体、RAG六大评测方向:
- FinBen:通用金融文本全任务基准;
- MultiFinBen:首个多语言、多模态全球金融基准;
- QFinBen:CFA/CPA考证复杂推理题库;
- MME-Finance:金融图表视觉问答VQA基准,现有模型K线解读普遍薄弱;
- FinAudio:金融音频专用评测基准;
- OmniEval:金融RAG检索增强生成评测;
- InvestorBench:交易智能体专用评测;
- Open FinLLM开放排行榜:动态更新30万+金融考题,打通学术界与产业界评测标准。
4. MFFMs六大核心发展前景(未来技术路线)
- 金融专用推理模型Reasoning Models:基于CoT思维链、GRPO强化学习提升数学计算、复杂财报推理;代表Fin-R1、Fin-O1;
- 多模态检索增强生成MRAG:融合图文音视频外部知识库,从根源缓解模型幻觉;
- 场景化定制微调:LoRA/QLoRA轻量化适配投顾、交易、审计等细分场景(如巴菲特智能体);
- 轻量化微调与量化技术:FinLoRA、量化压缩,降低部署算力成本,支持本地离线金融AI;
- MoE混合专家架构:拆分多模态子任务专属专家模块,在控制算力前提下提升模型容量;
- 联邦学习FL:DP-LoRA差分隐私联邦微调,保护金融机构私有交易、客户数据,实现多方联合训练不泄露原始数据。
六、第四部分:MFFM落地核心挑战与安全治理方案(论文第5章)
1. 数据层面挑战
- 私有专有数据壁垒:机构交易、信贷、客户数据高度敏感,无法公开用于训练;
- 多模态高质量数据集稀缺:音视频、财报图表对齐标注成本极高;
- 数据合规限制:各国金融监管、数据隐私法规限制跨机构、跨境数据流通;
- 解决方案:合成多模态金融数据、联邦学习、零知识证明隐私计算。
2. 算力与工程挑战
大规模多模态预训练算力成本极高(对标BloombergGPT百万GPU小时);推理延迟高,无法满足实时量化交易需求;量化、MoE、轻量化微调是主流优化路径。
3. 监管数字化DRR挑战
全球金融监管体系碎片化(美国联邦/州双层监管、欧盟多国协同监管);XBRL标准化财报解析难度大,通用模型财报问答准确率不足30%;CDM通用领域模型是标准化解决方案。
4. 伦理与可信AI挑战
- 隐私泄露:本地敏感财报、客户数据输入第三方模型引发泄密;
- 系统性偏见:信贷、风控模型对特定群体产生歧视;
- 版权侵权:模型训练爬取新闻、研报、书籍引发版权纠纷;
- 幻觉与虚假信息:模型编造财报数据、政策解读,直接造成投资亏损;
- 谄媚效应Sycophancy:迎合用户主观观点,输出不符合客观金融事实的结论。
5. FinAgent全链路四大风险
- 本地敏感文件输入外部模型造成数据泄露;
- 互联网舆情、新闻自带虚假信息被模型采信;
- 无权限抓取付费金融数据源,产生版权违规;
- 模型幻觉输出错误数据,误导交易、风控决策。
6. 创新防护方案:ZKP零知识证明+区块链护栏框架
- 零知识证明ZKP:在不暴露原始隐私数据前提下,验证模型推理、工具调用流程合规;生成轻量化证明文件,保护机构私有数据与模型知识产权;
- 许可式区块链:永久存证智能体检索、推理、输出全流程日志,形成不可篡改审计台账,满足监管追溯要求;
- 整体防护逻辑:全链路动作上链存证,ZKP证明操作合规,同时拦截未授权数据源访问、过滤虚假信息、校验模型输出事实准确性。
七、论文结论与未来宏观发展方向
1. 整体结论
MFFMs突破传统FinLLM纯文本限制,统一处理金融行业全模态异构数据,依托FinAgent智能体构建覆盖投资、审计、合规、交易、投教的完整金融AI生态;但当前受数据、算力、幻觉、监管、隐私、开放生态六大瓶颈制约,距离产业规模化落地仍有较大差距,必须配套完整安全治理框架实现FinAI就绪。
2. 长期产业与研究四大战略方向
- 多语言+全模态一体化模型:适配全球跨境金融市场,统一处理文本、图表、音频、时序、视频;
- 开源数据集与标准化考题库:降低中小机构训练MFFM的数据门槛,统一行业评测标准;
- 动态开放MFFM与FinAgent排行榜:持续迭代评测体系,打通产学研落地通道;
- 区块链+隐私计算融合:解决数据隐私、模型确权、监管审计三大核心痛点,支撑多方协同的开放金融AI生态。
八、附录术语体系
论文配套两套术语表:
- 大模型/智能体术语:Transformer、LLM、LoRA、QLoRA、RAG、MCP、A2A、Openwashing等;
- 金融领域术语:ECC、MPC、XBRL、CDM、Robo-Advisor、DRR数字化监管报送等,方便跨领域研究者阅读。