第46篇:LinkedList源码与对比(2026版)
摘要:从双向链表底层结构到源码级解析,深入拆解 Node 节点、linkFirst/linkLast、node(index) 二分查找优化。全面对比 ArrayList vs LinkedList------时间复杂度、内存开销、使用场景,破除"LinkedList 插入一定更快"的误区(中间插入两者均为O(n),但性能量级不同)。覆盖生产避坑、面试高频题(含 ArrayDeque 选型、transient 自定义序列化),附完整对比表和练习题。一篇理清 List 选型,面试不再混淆。
📌 系列导航 :《Java 100 天进阶之路》完整目录 |⬅️ 上一篇:第45篇:ArrayList源码解析 |
➡️ 下一篇:第47篇:HashMap源码全解(上)
文章目录
-
- 第46篇:LinkedList源码与对比(2026版)
-
- 一、核心知识点
- 二、通俗讲解(1分钟开心学)
- [三、源码核心片段 + 场景说明](#三、源码核心片段 + 场景说明)
-
- [3.1 核心属性与构造方法](#3.1 核心属性与构造方法)
- [3.2 Node 节点结构](#3.2 Node 节点结构)
- [3.3 添加元素:头插与尾插](#3.3 添加元素:头插与尾插)
- [3.4 指定位置插入:`add(int index, E element)`](#3.4 指定位置插入:
add(int index, E element)) - [3.5 删除元素:头删与尾删](#3.5 删除元素:头删与尾删)
- [3.6 随机访问:`get(int index)` 为什么慢?](#3.6 随机访问:
get(int index)为什么慢?) - [3.7 自定义序列化机制](#3.7 自定义序列化机制)
- [四、ArrayList vs LinkedList 全面对比](#四、ArrayList vs LinkedList 全面对比)
- 五、避坑要点
- 六、面试高频考点
- 七、练习题
- [📊 你的学习进度](#📊 你的学习进度)
- [👉 下一篇文章预告](#👉 下一篇文章预告)
一、核心知识点
LinkedList底层数据结构:双向链表- 核心节点
Node:item(数据)、prev(前驱指针)、next(后继指针) - 核心属性:
first(头节点)、last(尾节点)、size(元素个数) - 双端队列特性:实现
Deque接口,可作栈/队列/双端队列使用 - 核心方法:
addFirst()、addLast()、removeFirst()、removeLast()、get(int) - 未实现
RandomAccess接口:随机访问性能差,应使用迭代器遍历 - 与
ArrayList的全面性能对比(时间复杂度 + 内存 + 场景) - 自定义序列化机制 :
transient+writeObject/readObject - 使用场景选型与生产环境避坑
二、通俗讲解(1分钟开心学)
1. LinkedList 是什么?
LinkedList 是一个双向链表,每个元素(节点)除了存储数据,还存储前一个和后一个节点的引用。它没有数组那种连续内存的限制,可以动态增减。
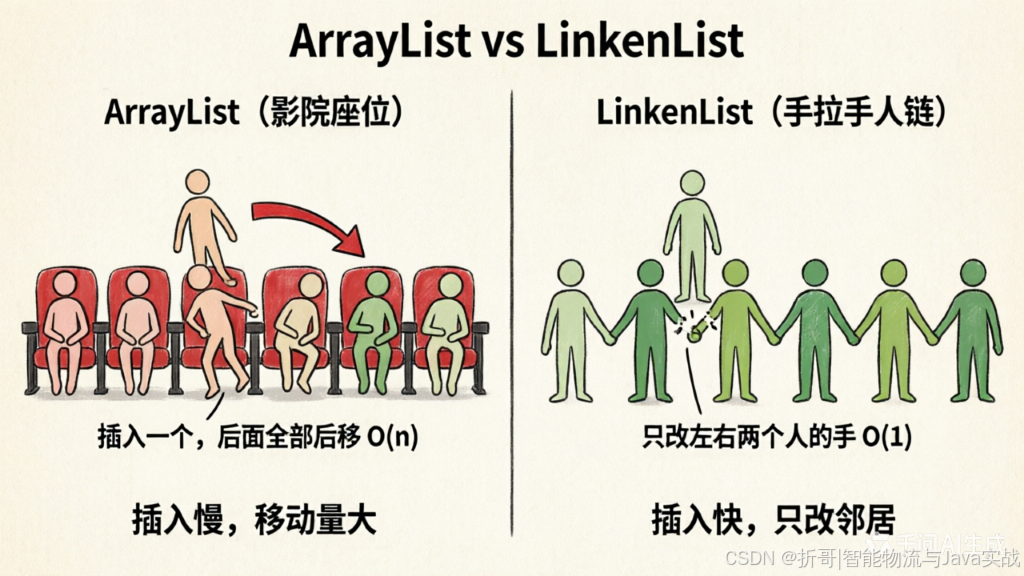
生活类比 :
ArrayList就像一排连着坐的影院座位,你可以在任意位置坐下,但想插入一个新座位就得把后面的所有座位往后挪。
LinkedList就像一条手拉手的人链,每个人只认识左右两个人。插入新人时,只需要让左右两人和新人的手拉上即可,其他人不用动。
2. 链表的节点长什么样?
java
private static class Node<E> {
E item; // 存储的数据
Node<E> next; // 指向下一个节点
Node<E> prev; // 指向上一个节点
}每个节点就像火车的一节车厢------车厢里有货物(item),车厢之间有挂钩连接(prev 和 next),可以双向行驶。
3. 为什么 LinkedList 没有随机访问能力?
ArrayList 实现了 RandomAccess 接口,可以通过索引直接跳到任意位置(O(1))。LinkedList 没有实现这个接口,要访问第 N 个元素,必须从链表头部或尾部一个一个节点找过去(O(n))。
4. 为什么 LinkedList 增删快?
- ArrayList 中间插入 :需要把插入点后面的所有元素往后挪(
System.arraycopy),O(n) - LinkedList 中间插入:只需要修改前后两个节点的指针指向,O(1)
⚠️ 但有一个陷阱 :中间插入前需要先定位到插入位置(O(n)),所以实际复杂度是 O(n)。
三、源码核心片段 + 场景说明
3.1 核心属性与构造方法
java
public class LinkedList<E> extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {
transient int size = 0; // 元素个数
transient Node<E> first; // 头节点
transient Node<E> last; // 尾节点
public LinkedList() { }
public LinkedList(Collection<? extends E> c) {
this();
addAll(c);
}
}💡
transient修饰size、first、last:LinkedList 自定义了序列化逻辑,不会序列化无效的空节点指针和头部/尾部引用,只遍历链表保存有效元素,节省序列化空间与耗时(参见 3.7 节)。
3.2 Node 节点结构
java
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}3.3 添加元素:头插与尾插
尾插 addLast() / linkLast():
java
public boolean add(E e) {
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
first = newNode;
else
l.next = newNode;
size++;
modCount++; // 记录结构性修改,用于快速失败机制(fail-fast)
}💡
modCount++是集合框架的统一设计,用于在迭代时检测并发修改,抛出ConcurrentModificationException。
头插 addFirst() / linkFirst():
java
public void addFirst(E e) {
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}3.4 指定位置插入:add(int index, E element)
java
public void add(int index, E element) {
checkPositionIndex(index); // 保证 index 合法
if (index == size)
linkLast(element);
else
linkBefore(element, node(index));
}node(index) 方法------双向链表的二分查找优化:
java
Node<E> node(int index) {
// 如果 index 在前半部分,从头开始找
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
// 如果 index 在后半部分,从尾开始找
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}💡
node(index)利用双向链表的特性:index 在前半部分就从 head 往后找,在后半部分就从 tail 往前找 ,最多只遍历一半元素。由于checkPositionIndex已保证index合法,node(index)不会在空链表上被调用。
3.5 删除元素:头删与尾删
头删 removeFirst():
java
public E removeFirst() {
final Node<E> f = first;
if (f == null)
throw new NoSuchElementException();
return unlinkFirst(f);
}
private E unlinkFirst(Node<E> f) {
final E element = f.item;
final Node<E> next = f.next;
f.item = null;
f.next = null; // help GC ------ 断开旧头节点的引用链,让GC快速回收
first = next;
if (next == null)
last = null;
else
next.prev = null;
size--;
modCount++;
return element;
}💡
f.item = null; f.next = null;作用是断开旧头节点所有引用,让垃圾回收器能快速回收废弃节点,避免无效 Node 长期驻留堆内存。
3.6 随机访问:get(int index) 为什么慢?
java
public E get(int index) {
checkElementIndex(index);
return node(index).item; // node(index) 需要遍历
}node(index) 需要从头/尾遍历到目标位置,时间复杂度 O(n)。这就是 LinkedList 随机访问慢的根本原因。
3.7 自定义序列化机制
size、first、last 都标记了 transient,所以默认序列化不会保存它们。LinkedList 通过自定义 writeObject/readObject 实现高效序列化:
java
private void writeObject(java.io.ObjectOutputStream s) throws IOException {
s.defaultWriteObject(); // 写非transient字段
s.writeInt(size); // 写有效元素个数
for (Node<E> x = first; x != null; x = x.next)
s.writeObject(x.item); // 逐个写元素
}
private void readObject(java.io.ObjectInputStream s) throws IOException, ClassNotFoundException {
s.defaultReadObject();
int size = s.readInt();
for (int i = 0; i < size; i++)
linkLast((E) s.readObject()); // 按顺序恢复
}💡 只序列化有效元素,不序列化空节点和指针,节省序列化空间与耗时。面试常问:"LinkedList 的
transient有什么用?答:自定义序列化,只存有效元素,不存指针。"
四、ArrayList vs LinkedList 全面对比
| 维度 | ArrayList | LinkedList |
|---|---|---|
| 底层结构 | 动态数组 | 双向链表 |
| 随机访问 get(int) | O(1) | O(n) |
| 尾插 add(E) | 均摊 O(1)(扩容时可能 O(n)) | O(1) |
| 头插 addFirst | O(n)(需移动全部元素) | O(1) |
| 中间插入 add(i, E) | O(n)(数组拷贝) | O(n)(定位 O(n) + 插入 O(1)) |
| 中间删除 remove(i) | O(n)(数组拷贝) | O(n)(定位 O(n) + 删除 O(1)) |
| 头删 removeFirst | O(n) | O(1) |
| 内存占用 | 连续内存,仅存数据 | 每个节点约 24~32 字节额外开销 |
| 实现接口 | RandomAccess |
Deque(可作队列/栈) |
| 使用场景 | 读多写少 | 头尾操作多、队列/栈 |
💡 重要补充 :虽然中间插入两者时间复杂度均为 O(n),但底层执行效率差距巨大:
ArrayList依靠System.arraycopy(native 内存拷贝),10 万条数据中间插入耗时约 1~2msLinkedList需要node(index)逐节点 Java 循环遍历,同样操作耗时约 50~100ms万条数据场景下,ArrayList 中间插入性能通常优于 LinkedList 。只有频繁头尾操作时,LinkedList 才真正有优势。
📏 内存开销说明 :在 64 位 JVM 开启压缩指针(默认)时,每个 Node 对象头约 12~16 字节,加上item、prev、next三个引用(各 4 字节,共 12 字节),再加上对齐填充,实际每个节点额外消耗约 24~32 字节 。百万数据时,LinkedList 比 ArrayList 多占用约 24~32MB 内存。
⚠️add(E)的"均摊 O(1)":ArrayList 每次扩容时 O(n),但扩容频率低(n 次插入触发约 log₂n 次扩容),将开销均摊到每次插入后,平均仍为 O(1)。日常批量尾插 ArrayList 整体效率远高于 LinkedList。
五、避坑要点
| 错误/误区 | 后果 | 正确做法 |
|---|---|---|
| 大量随机访问使用 LinkedList | 性能极差,O(n) 遍历 | 用 ArrayList |
| 认为 LinkedList 中间插入总是 O(1) | 忽略定位开销 | 理解:定位 O(n) + 插入 O(1) = O(n) |
用 for 循环遍历 LinkedList |
每次 get(i) 都从头遍历,O(n²) |
用迭代器或增强 for |
把 LinkedList 当队列用却用了 get(0) |
不必要的遍历开销 | 用 offer/poll 系列方法 |
| 忽略内存开销 | 大量数据时内存爆炸 | 每个节点约 24~32 字节开销,大集合慎用 |
| 多线程并发读写 | ConcurrentModificationException、数据错乱 |
使用 CopyOnWriteArrayList、ConcurrentLinkedDeque,或手动加锁 synchronized |
| 混淆 Deque 和 List 方法 | 代码意图不清晰 | 队列场景用 offer/poll,列表场景用 add/remove |
六、面试高频考点
Q1:ArrayList 和 LinkedList 的区别?
底层结构不同:ArrayList 基于动态数组,LinkedList 基于双向链表。随机访问:ArrayList O(1),LinkedList O(n)。头尾操作:LinkedList 更快(O(1)),ArrayList 需要移动元素(O(n))。中间插入/删除:两者都是 O(n)------ArrayList 慢在元素移动,LinkedList 慢在节点定位。内存:ArrayList 连续存储,LinkedList 每个节点约 24~32 字节额外开销。接口:LinkedList 实现了 Deque,可作队列/栈。
Q2:LinkedList 的插入真的是 O(1) 吗?
不一定。头插和尾插 是 O(1)。中间插入 需要先调用
node(index)定位,时间复杂度 O(n),所以整体是 O(n)。只有在已经持有节点引用的情况下(如迭代器),插入才是 O(1)。
Q3:LinkedList 为什么没有实现 RandomAccess 接口?
RandomAccess是一个标记接口,表示支持快速随机访问。LinkedList 基于链表,随机访问需要从头/尾遍历,时间复杂度 O(n),不具备快速随机访问的能力,所以没有实现该接口。
Q4:遍历 LinkedList 用什么方式最快?
使用迭代器 或增强 for 循环 (底层也是迭代器)。因为 LinkedList 的
get(int)是 O(n),用for循环遍历会变成 O(n²)。迭代器沿着指针逐个访问,是 O(n)。
Q5:LinkedList 可以当队列用吗?
可以。LinkedList 实现了
Deque接口(双端队列),提供了offer()(入队)、poll()(出队)、peek()(查看队首)等方法。同时也可以当栈用(push/pop)。
Q6:什么时候用 ArrayList,什么时候用 LinkedList?
用 ArrayList :① 频繁随机访问;② 主要在尾部操作;③ 数据量可预估。用 LinkedList :① 频繁头尾操作;② 需要作为队列/栈使用;③ 插入删除操作远多于访问。2026 年补充 :如果需要队列/栈,
ArrayDeque比 LinkedList 性能更好(内存连续、无节点开销),可作为优先选择。
Q7:LinkedList 和 ArrayDeque 有什么区别?如何选型?
ArrayDeque基于循环数组实现,没有节点对象开销,内存更紧凑,性能更高。LinkedList基于链表,每个节点需要额外存储两个指针(约 24~32 字节)。选型建议 :优先使用
ArrayDeque(队列/栈场景),无节点指针内存开销,读写性能远高于 LinkedList。⚠️ 注意 :
ArrayDeque仅实现Deque,未实现List接口,不支持get(index)按索引访问 ,也不允许存储null。若业务需要同时具备 List 索引查询 + 队列功能,才选用 LinkedList。
Q8:size、first、last 为什么用 transient 修饰?
LinkedList 自定义了序列化逻辑。如果默认序列化,会保存
first/last引用和所有节点指针,浪费空间且可能因循环引用导致问题。通过transient+ 自定义writeObject/readObject,只序列化有效元素,不序列化空节点和指针,节省序列化空间与耗时。面试高频题。
七、练习题
-
源码推导 :以下代码中,
list.add(2, "X")的执行过程中,node(2)会从 head 还是 tail 开始遍历?为什么?javaLinkedList<String> list = new LinkedList<>(); for (int i = 0; i < 10; i++) list.add("item" + i); list.add(2, "X");💡 思路 :
node(index)判断 index < size/2(2 < 5),从头开始遍历。 -
性能对比 :分别用
ArrayList和LinkedList在头部插入 10 万条数据,对比耗时,分析原因。💡 思路 :
ArrayList每次头插都需System.arraycopy移动全部元素,O(n²);LinkedList头插仅修改指针,O(n)。可参考代码:java// 对比测试 List<Integer> arrayList = new ArrayList<>(); List<Integer> linkedList = new LinkedList<>(); long start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) arrayList.add(0, i); System.out.println("ArrayList 头插耗时:" + (System.currentTimeMillis() - start) + "ms"); start = System.currentTimeMillis(); for (int i = 0; i < 100000; i++) linkedList.add(0, i); System.out.println("LinkedList 头插耗时:" + (System.currentTimeMillis() - start) + "ms"); -
场景设计:你正在开发一个消息队列,需要频繁从队尾入队、队首出队,数据量约 10 万条。选 ArrayList 还是 LinkedList?为什么?
💡 答案 :优先选择
ArrayDeque(循环数组双端队列),无节点指针内存开销,读写性能远高于 LinkedList。仅业务同时需要 List 索引查询 + 队列功能时,才选用 LinkedList。 -
代码改错:下面的代码有什么性能问题?如何优化?
javaLinkedList<Integer> list = new LinkedList<>(); for (int i = 0; i < 100000; i++) { list.add(i); } for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); }💡 思路 :
list.get(i)在 LinkedList 中是 O(n),循环遍历是 O(n²)。应改用迭代器或增强 for。java// 优化后 for (Integer num : list) { System.out.println(num); } // 或显式迭代器 Iterator<Integer> it = list.iterator(); while (it.hasNext()) { System.out.println(it.next()); } -
源码分析 :阅读
LinkedList.node(int index)源码,解释为什么它最多只遍历链表的一半。💡 思路 :
size >> 1等价于size / 2,判断 index 在前半还是后半,分别从 head 或 tail 出发,最多遍历一半元素。
📊 你的学习进度
- 当前:第46篇 / 共108篇 · 进阶篇:集合框架源码解析(第45~50篇)
- ✅ 已完成:基础篇44篇 + 第45~46篇
- 📖 正在学:第46篇
- ⏳ 待学习:第47~108篇
👉 📚 完整目录 & 学习指南 | 🔥 订阅本专栏,不错过每一篇
👉 下一篇文章预告
内容简介 :哈希算法、
put/get流程、哈希冲突解决(链地址法)、JDK 7 vs JDK 8 差异、扰动函数原理。
💡 学完这篇,你将彻底搞懂 Java 最核心的集合------HashMap 的设计思想。
📌 《Java 100 天进阶之路 | 从入门到上岗就业》 每天一篇,建议收藏 + 关注 ,一起100天拿offer!
👉 点击关注我,更新后第一时间收到推送!