PyTorch强化学习实战(16)------Categorical DQN
0. 前言
传统的强化学习算法,无论是Q学习、深度Q网络 (Deep Q-Network, DQN)还是策略梯度方法,都遵循着一个共同的范式:学习期望价值。无论是状态价值函数 V ( s ) V(s) V(s) 还是动作价值函数 Q ( s , a ) Q(s, a) Q(s,a),本质上都是对随机回报的期望值。然而,期望只是对随机变量的一种粗糙描述,它丢失了关于回报分布的丰富信息。
想象一下,一个智能体面临两个选择:一个提供稳定的 +10 奖励,另一个以 50% 的概率获得 +100 奖励,50% 的概率获得 -80 奖励。两者的期望都是 +10,但风险特征截然不同。传统的强化学习算法无法区分这两种情况,因为它们只关注期望。更重要的是,仅靠期望价值无法捕捉到环境中的随机性、策略的随机性以及长期回报的完整分布信息。
2017 年,DeepMind 研究团队提出了分布强化学习,系统性地将强化学习的目标从学习期望价值扩展到学习完整的回报分布,本节将从期望视角的局限性出发,深入解析分布强化学习的理论基础、实现细节和实验效果。
1. Categorical DQN
论文《A distributional perspective on reinforcement learning》对Q学习的基石------Q值------提出了根本性质疑,尝试用更广义的Q值概率分布取而代之。接下来,我们深入理解这一理念,传统Q学习和价值迭代方法都将状态或动作价值表示为单一数值,用以表征从某状态(或状态-动作对)能获得的总奖励。但将未来所有可能奖励压缩为单个数值是否合理?在复杂环境中,未来奖励具有随机性,可能以不同概率产生不同价值。
以日常通勤为例:假设每天驾车从家到公司。多数情况下交通顺畅,约 30 分钟即可到达(虽不完全精确,但平均值为 30 分钟)。但偶尔会遇到道路施工或交通事故,导致通勤时间延长至三倍。这种通勤时间的概率分布可用随机变量的分布表示,如下图所示:
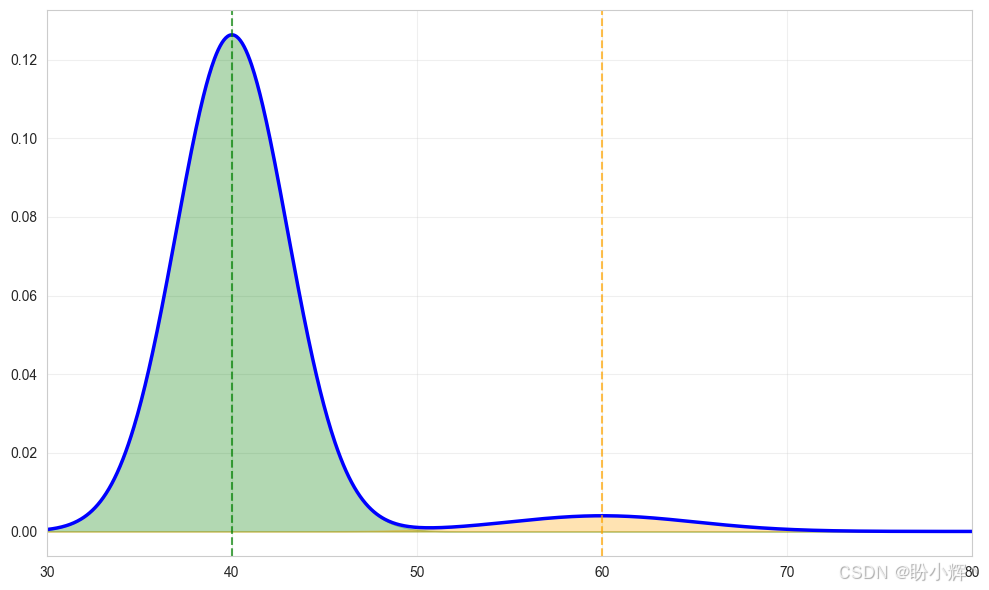
现在假设有另一种通勤选择:乘坐火车。这种方式耗时稍长,因为需要从家前往车站,再从车站到办公室,但相比驾车更为可靠。假设火车通勤时间平均为 40 分钟,仅有微小概率因列车故障额外增加 20 分钟。下图展示了火车通勤的时间分布:
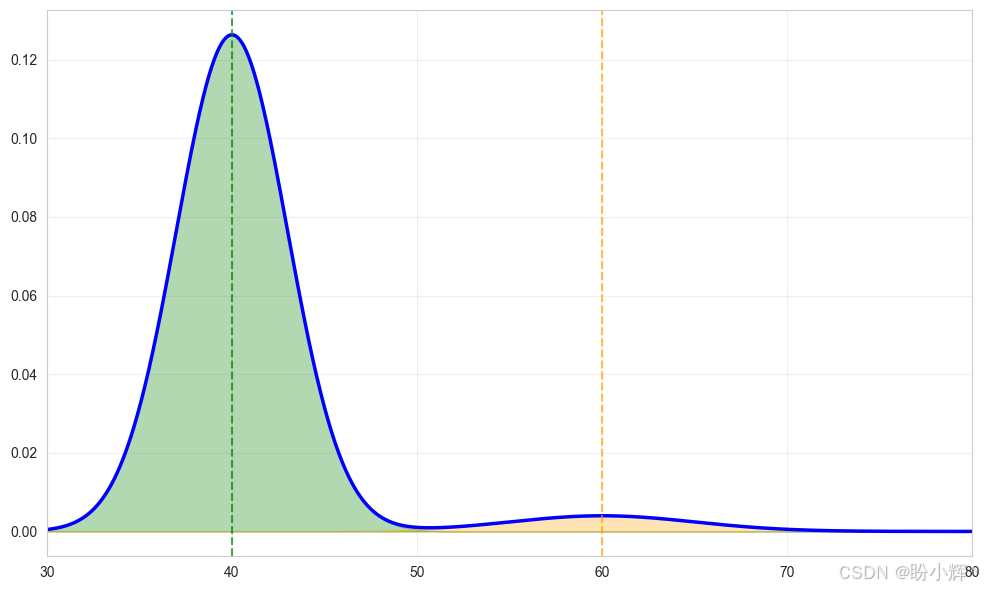
假设我们需要决定通勤方式。若仅比较汽车与火车的平均耗时,驾车可能更具吸引力------其平均通勤时间为 35.43 分钟,优于火车的 40.54 分钟。
然而,如果我们查看完整的分布,我们可能转而选择火车,因为即使是在最坏的情况下,火车通勤时间也仅 1 小时,而驾车可能长达 1.5 小时。用统计学术语表述,驾车的分布有更高的方差,因此如果必须在 60 分钟内到达办公室,火车是更可靠的选择。
这种决策复杂度在马尔可夫决策过程 (Markov Decision Process, MDP)中会进一步放大------当需要做出一系列相互影响的决策时,每个选择都可能改变后续状态。以通勤为例,重要会议时间的安排可能需根据所选交通方式调整。此时,若仅依赖平均奖励值,将丢失大量环境动态的关键信息。
当动作价值可能呈现复杂分布时,不必局限于预测均值,直接处理分布或许能带来更好效果。实验结果表明,这一思路确实有效,但代价是方法复杂度的提升,其核心思想是预测每个动作的价值分布(类似前文的汽车/火车时间分布)。作者进一步证明,贝尔曼方程可推广至分布形式: Z ( x , a ) = D R ( x , a ) + γ Z ( x ′ , a ′ ) Z(x,a)\stackrel D = R(x,a) + γZ(x′,a′) Z(x,a)=DR(x,a)+γZ(x′,a′),该式与经典贝尔曼方程形式相似,但 Z ( x , a ) Z(x,a) Z(x,a) 与 R ( x , a ) R(x,a) R(x,a) 均为概率分布而非标量值, A = D B A \stackrel D = B A=DB 表示分布 A A A 和 B B B 等价。
所得的概率分布可用于训练我们的网络,使其能更准确地预测给定状态下每个动作的价值分布------其训练方式与Q学习完全相同。唯一的区别在于损失函数需要替换为适用于分布比较的度量标准,例如分类问题中常用的 KL 散度(又称交叉熵损失),或是 Wasserstein 距离。作者虽从理论上论证了 Wasserstein 度量的优越性,但在实际应用时遇到了限制,因此最终采用了 KL 散度。
2. 实现 Categorical DQN
本节代码使用 dqn_extra.py 中的 distr_projection 函数来执行分布投影操作。在代码实现前,有必要先阐明实现逻辑的核心要点。
该方法的核心在于对概率分布的建模。虽然分布表示方式多样,但论文作者选择了一种通用参数化分布方案,在预设取值范围内均匀布置固定数量的离散值(称为原子,atom)。这个取值范围需要覆盖折扣奖励的预期累计值域。作者尝试了不同数量的原子,通过实验发现,当将取值区间 [-10,10] 划分为 N_ATOMS=51 个等分区间时能获得最佳效果。
网络需要对每个原子(共 51 个)预测未来折扣价值落入该区间的概率。方法的核心逻辑在于,首先对下一状态最佳动作的分布使用 γ γ γ (折扣因子)进行收缩,将即时奖励添加到分布中,并将结果投影回原始的原子区间。这一系列操作通过 dqn_extra.distr_projection 函数实现。
(1) 首先,初始化存储投影结果的数组:
python
def distr_projection(next_distr: np.ndarray, rewards: np.ndarray,
dones: np.ndarray, gamma: float):
"""
Perform distribution projection aka Catergorical Algorithm from the
"A Distributional Perspective on RL" paper
"""
batch_size = len(rewards)
proj_distr = np.zeros((batch_size, N_ATOMS), dtype=np.float32)
delta_z = (Vmax - Vmin) / (N_ATOMS - 1)该函数接收一个形状为 (batch_size, N_ATOMS) 的概率分布批次、奖励数组、表示回合完成的标志位,以及以下超参数:Vmin (最小值)、Vmax (最大值)、N_ATOMS (原子数量)和 gamma (折扣因子)。其中 delta_z 变量表示值区间内每个原子的宽度。
(2) 遍历原始分布中的每个原子,并根据贝尔曼算子计算该原子在值域边界约束下的投影位置:
python
for atom in range(N_ATOMS):
v = rewards + (Vmin + atom * delta_z) * gamma
tz_j = np.minimum(Vmax, np.maximum(Vmin, v))例如,索引为 0 的第一个原子对应值 Vmin=-10。当样本获得 +1 的奖励时,该原子将被投影到值 −10⋅0.99 + 1 = −8.9 的位置(假设折扣因子 gamma=0.99)。换句话说,它会向右偏移。如果计算值超出 Vmin 和 Vmax 定义的取值范围,我们会将其截断到边界值。
(3) 接下来,计算样本投影后的原子编号:
python
b_j = (tz_j - Vmin) / delta_z(4) 当然,样本可能被投影到两个原子之间。此时,我们需要将原始分布中源原子的值按比例分配到其左右两侧的原子上。这种分配需谨慎处理,因为目标原子可能恰好与某个原子位置重合。这种情况下,我们只需将源分布值直接加到目标原子上即可。以下代码处理投影原子恰好落在目标原子上的情况。否则,变量 b_j 将不是整数值,此时需要使用变量 l 和 u (分别表示投影点下方和上方原子的索引):
python
l = np.floor(b_j).astype(np.int64)
u = np.ceil(b_j).astype(np.int64)
eq_mask = u == l
proj_distr[eq_mask, l[eq_mask]] += next_distr[eq_mask, atom](5) 当投影点落在两个原子之间时,我们需要将源原子的概率值分配到相邻的上下两个原子上:
python
ne_mask = u != l
proj_distr[ne_mask, l[ne_mask]] += next_distr[ne_mask, atom] * (u - b_j)[ne_mask]
proj_distr[ne_mask, u[ne_mask]] += next_distr[ne_mask, atom] * (b_j - l)[ne_mask](6) 当然,我们还需要正确处理回合终止时的状态转移。这种情况下,我们的投影计算不应考虑下一状态的分布,而应直接将概率 1 分配给所获得的奖励值。但若该奖励值也落在原子之间,我们仍需根据原子位置合理分配概率。以下代码分支处理了这种情况:它会先将已终止样本( done 标志为 True )的分布置零,再计算最终的投影结果:
python
if dones.any():
proj_distr[dones] = 0.0
tz_j = np.minimum(Vmax, np.maximum(Vmin, rewards[dones]))
b_j = (tz_j - Vmin) / delta_z
l = np.floor(b_j).astype(np.int64)
u = np.ceil(b_j).astype(np.int64)
eq_mask = u == l
eq_dones = dones.copy()
eq_dones[dones] = eq_mask
if eq_dones.any():
proj_distr[eq_dones, l[eq_mask]] = 1.0
ne_mask = u != l
ne_dones = dones.copy()
ne_dones[dones] = ne_mask
if ne_dones.any():
proj_distr[ne_dones, l[ne_mask]] = (u - b_j)[ne_mask]
proj_distr[ne_dones, u[ne_mask]] = (b_j - l)[ne_mask]
return proj_distr我们已经介绍了该方法的核心,distr_projection 函数,它是最复杂的部分。接下来继续介绍网络架构和改进的损失函数。
(7) 首先从网络架构开始,在 dqn_extra.py 文件中定义 DistributionalDQN 类:
python
Vmax = 10
Vmin = -10
N_ATOMS = 51
DELTA_Z = (Vmax - Vmin) / (N_ATOMS - 1)
class DistributionalDQN(nn.Module):
def __init__(self, input_shape: tt.Tuple[int, ...], n_actions: int):
super(DistributionalDQN, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(input_shape[0], 32, kernel_size=8, stride=4),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=4, stride=2),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=1),
nn.ReLU(),
nn.Flatten()
)
size = self.conv(torch.zeros(1, *input_shape)).size()[-1]
self.fc = nn.Sequential(
nn.Linear(size, 512),
nn.ReLU(),
nn.Linear(512, n_actions * N_ATOMS)
)
sups = torch.arange(Vmin, Vmax + DELTA_Z, DELTA_Z)
self.register_buffer("supports", sups)
self.softmax = nn.Softmax(dim=1)主要区别在于全连接层的输出,输出一个大小为 n_actions * N_ATOMS 的向量,对于 Pong 游戏来说就是 6×51=306 个值。每个动作需要预测 51 个原子(称为支撑点,support )上的概率分布。每个原子对应一个特定的奖励值,这些奖励值在 -10 到 10 之间均匀分布,步长为 0.4,这些支撑点存储在网络的缓冲区中。
(8) forward() 方法返回一个 3D 张量 (batch, actions, supports) 作为预测的概率分布:
python
def forward(self, x: torch.ByteTensor) -> torch.Tensor:
batch_size = x.size()[0]
xx = x / 255
fc_out = self.fc(self.conv(xx))
return fc_out.view(batch_size, -1, N_ATOMS)
def both(self, x: torch.ByteTensor) -> tt.Tuple[torch.Tensor, torch.Tensor]:
cat_out = self(x)
probs = self.apply_softmax(cat_out)
weights = probs * self.supports
res = weights.sum(dim=2)
return cat_out, res除了 forward() 方法外,我们还定义了 both() 方法,该方法可通过单次调用同时计算原子的概率分布和Q值。
(9) 该网络还定义了几个辅助函数,用于简化Q值的计算并对概率分布应用 softmax:
python
def qvals(self, x: torch.ByteTensor) -> torch.Tensor:
return self.both(x)[1]
def apply_softmax(self, t: torch.Tensor) -> torch.Tensor:
return self.softmax(t.view(-1, N_ATOMS)).view(t.size())(10) 最后的改动是新的损失函数,不再使用贝尔曼方程,而是应用分布投影,并计算预测分布和投影分布之间的 KL 散度:
python
def calc_loss(batch: tt.List[ExperienceFirstLast], net: dqn_extra.DistributionalDQN,
tgt_net: dqn_extra.DistributionalDQN, gamma: float,
device: torch.device) -> torch.Tensor:
states, actions, rewards, dones, next_states = common.unpack_batch(batch)
batch_size = len(batch)
states_v = torch.as_tensor(states).to(device)
actions_v = torch.tensor(actions).to(device)
next_states_v = torch.as_tensor(next_states).to(device)
# next state distribution
next_distr_v, next_qvals_v = tgt_net.both(next_states_v)
next_acts = next_qvals_v.max(1)[1].data.cpu().numpy()
next_distr = tgt_net.apply_softmax(next_distr_v)
next_distr = next_distr.data.cpu().numpy()
next_best_distr = next_distr[range(batch_size), next_acts]
proj_distr = dqn_extra.distr_projection(next_best_distr, rewards, dones, gamma)
distr_v = net(states_v)
sa_vals = distr_v[range(batch_size), actions_v.data]
state_log_sm_v = F.log_softmax(sa_vals, dim=1)
proj_distr_v = torch.tensor(proj_distr).to(device)
loss_v = -state_log_sm_v * proj_distr_v
return loss_v.sum(dim=1).mean()以上代码主要是为调用 distr_projection 和 KL 散度计算做准备,KL 散度的定义如下:
D K L ( P ∣ ∣ Q ) = − ∑ i p i l o g q i D_{KL}(P||Q)=-\sum_ip_ilogq_i DKL(P∣∣Q)=−i∑pilogqi
为了计算概率的对数,我们使用了 PyTorch 的 log_softmax 函数,它以数值稳定的方式同时实现了 log 和 softmax 运算。
3. 运行结果
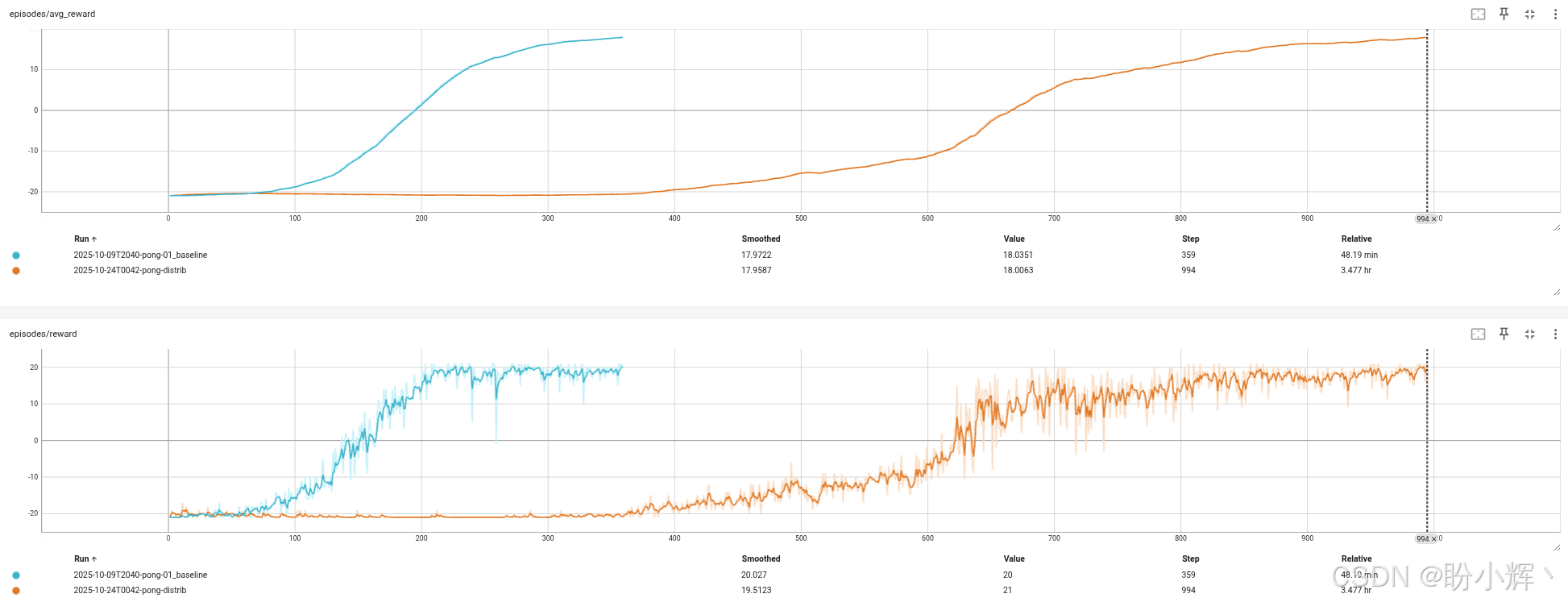
Categorical DQN 的收敛速度略慢于原始 DQN 且稳定性稍差,因为网络输出维度扩大了 51 倍,而且损失函数也发生了变化。在未进行超参数调优的情况下,Categorical DQN 需要多训练回合才能通关游戏。另一个可能的因素是,Pong 游戏过于简单,难以得出普适性结论。
下图对比了 Categorical DQN 与经典 DQN 的奖励动态和损失值变化。如图所示,Categorical DQN 方法的奖励动态表现逊于经典 DQN:
我们可以观察训练过程中概率分布的动态变化。若启动训练时添加 --img-path 参数(指定存储目录),程序将固定保存特定状态的概率分布图。例如,下图展示了训练初期(3万帧后)某个状态下六个动作的概率分布:
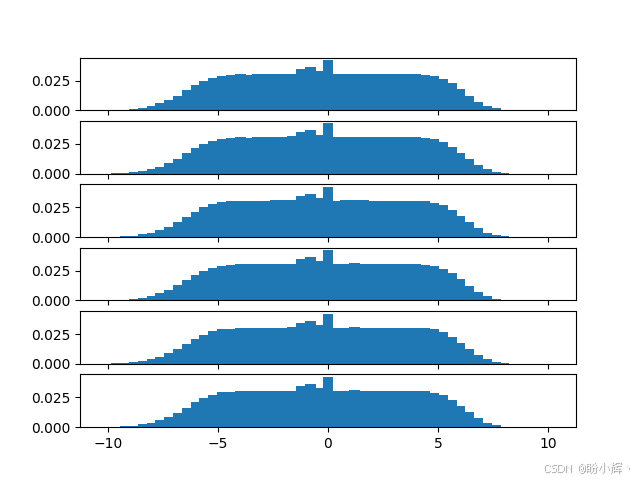
所有分布都非常分散(此时网络尚未收敛),中间的峰值对应网络预期从动作获得的负奖励。经过50万帧训练后,同一状态的概率分布如下图所示:
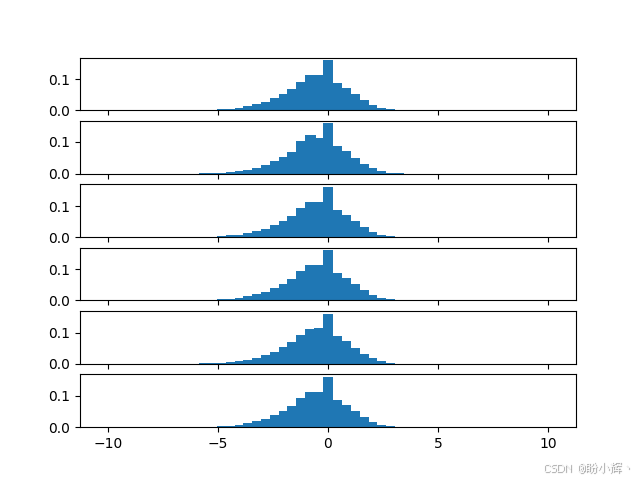
可以看到不同动作对应的分布存在明显差异。第一个动作(对应 NOOP,即无操作)的分布整体左偏,表明在该状态下无操作通常会导致失分。而第五个动作RIGHTFIRE的均值明显右移,说明该动作能带来更高得分。
4. 超参数调优
Categorical DQN 超参数调优效果不佳。经过 30 次调优迭代后,未能找到比常规参数组合收敛速度更快的学习率与 gamma 值组合。
小结
分布强化学习通过建模完整的回报分布,突破了传统算法仅关注期望价值的局限。本节详细阐述了 Categorical DQN 核心原理:将价值分布表示为固定区间内的离散原子,通过投影操作实现贝尔曼算子的分布版本,并采用 KL 散度作为损失函数。实现上,网络输出每个动作对应原子的概率分布,通过 distr_projection 函数完成分布投影。
系列链接
PyTorch强化学习实战(1)------强化学习(Reinforcement Learning,RL)详解
PyTorch强化学习实战(2)------强化学习环境库Gymnasium
PyTorch强化学习实战(3)------Gymnasium API扩展功能
PyTorch强化学习实战(4)------PyTorch基础
PyTorch强化学习实战(5)------PyTorch Ignite 事件驱动机制与实践
PyTorch强化学习实战(6)------交叉熵方法详解与实现
PyTorch强化学习实战(7)------表格学习与贝尔曼方程
PyTorch强化学习实战(8)------Q学习详解与实现
PyTorch强化学习实战(10)------强化学习高级组件
PyTorch强化学习实战(11)------N步DQN(N-step DQN)
PyTorch强化学习实战(12)------Double DQN(DDQN)
PyTorch强化学习实战(13)------噪声网络(NoisyNet-DQN)