摘要
本文针对多输入多输出(MIMO)系统中的自适应传输问题,将奇异值分解(SVD)预编码、注水功率分配与基于 SINR 阈值的自适应调制相结合,构建了一套完整的闭环自适应传输方案。通过仿真对比了 BPSK、QPSK、16QAM、64QAM 四种固定调制方式与自适应调制方案在不同信噪比下的误码率与吞吐量性能。结果表明,自适应调制方案通过动态选择调制阶数并关闭质量过差的子信道,在误码率与频谱效率之间取得了有效平衡,相比固定调制方案具有更强的鲁棒性与实用性,为 5G/6G 系统中灵活资源配置提供了设计参考。
1 背景和意义
1.1 背景
近年来,随着移动互联网、物联网、车联网、卫星通信等技术的迅猛发展,无线通信系统需要同时支持高速率、高可靠、低时延、广连接等多种业务需求。从 4G LTE 到 5G NR,乃至未来的 6G,频谱资源日趋紧张,而用户对数据速率的需求呈指数级增长。如何在有限的频谱带宽内尽可能多地传输有效信息,同时保证在各种复杂环境下的通信质量,已成为无线通信设计的核心问题。
传统通信系统通常采用单一的、固定的调制编码方案。例如,数字电视广播采用固定的 QPSK 或 16QAM。这种设计具有实现简单、控制开销低的优点,但在时变信道条件下暴露出严重缺陷:
- 保守选择:若为应对最差信道条件而选用低阶调制(如 BPSK),则在信道良好时频谱效率极低,大量带宽被浪费。例如在 SNR=20 dB 时,BPSK 仍只传送 1 bit/symbol,而理论上 16-QAM 可以传送 4 bit/symbol,速率相差 4 倍。
- 激进选择:若为追求高速率而选用高阶调制(如 16-QAM 或 64-QAM),一旦信道恶化(如进入深衰落),误码率将急剧上升,甚至导致通信链路完全中断。例如在 Rayleigh 衰落信道下,SNR=10 dB 时 16-QAM 的 BER 可能高达 10⁻¹,无法满足大多数业务要求。
- 无适应性:固定调制无法响应信道的瞬时变化,无法在可靠性和效率之间动态折中,导致整体系统吞吐量远低于理论容量
1.2 意义
多输入多输出(MIMO)技术通过在收发端配置多根天线,开辟了空间维度,能在不增加频谱带宽的前提下使信道容量随天线数线性增长,已成为 4G/5G 的核心技术之一。
当发射端已知信道状态信息(CSI)时,奇异值分解(SVD)可将MIMO信道分解为多个互不干扰的并行子信道,实现最优的空间复用。在此基础上,注水功率分配根据各子信道的质量差异化分配功率------优质信道多分配、劣质信道少分配甚至关闭,从而在总功率约束下最大化信道容量。然而,实际系统采用离散调制方式(如 QPSK、16QAM 等),而非理论上的高斯输入,因此需引入自适应调制:依据各子信道有效信噪比动态选择最合适的调制阶数,在保证误码率的前提下最大化吞吐量。
将SVD预编码、注水算法和自适应调制三者有机联合,构成了一套完整的闭环MIMO自适应传输方案。尽管该方案在信息论上具有最优性,但在实际离散调制约束下的性能表现如何、相较于传统固定调制能获得多大增益,仍需系统的仿真评估。
2 理论基础


(关于 MIMO 和注水法具体细节,可以参考我往期博客有写)。
自适应调制(Adaptive Modulation, AM)是一种根据无线信道质量动态调整传输参数的技术,其核心思想是:在信道条件良好时采用高阶调制以提高数据速率,在信道恶化时切换至低阶调制以保证传输可靠性,从而在链路可靠性和频谱效率之间达到最佳平衡。
本文仿真在功率分配的基础上,采用基于 SINR 阈值的调制选择策略,其工作原理如下:
- 首先预设一组 SINR 切换阈值,当估计的有效 SINR 高于某调制方式对应的阈值且低于更高效调制方式的阈值时,系统即选择该调制方式。
| 调制方式 | 每符号比特数 | SINR 阈值 (dB) | 适用场景 |
|---|---|---|---|
| 关闭 | 0 | -∞ | 信道极差,无法可靠传输 |
| BPSK | 1 | 0 | 低SNR场景,保障基本连接 |
| QPSK | 2 | 6 | 中等SNR,通用场景 |
| 16QAM | 4 | 12 | 高SNR,追求更高速率 |
| 64QAM | 6 | 20 | SNR充足,最大化吞吐量 |
3 仿真设计
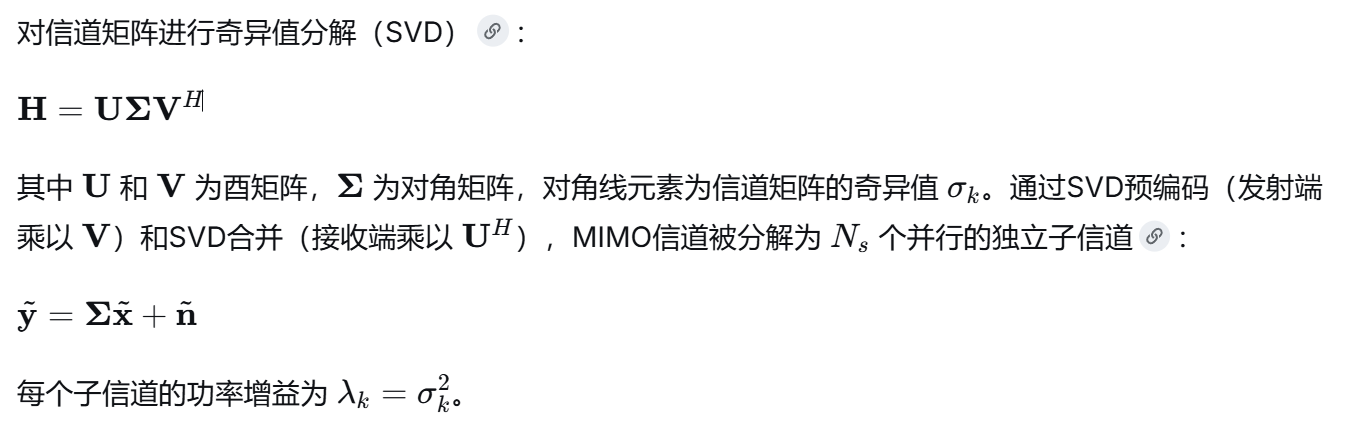
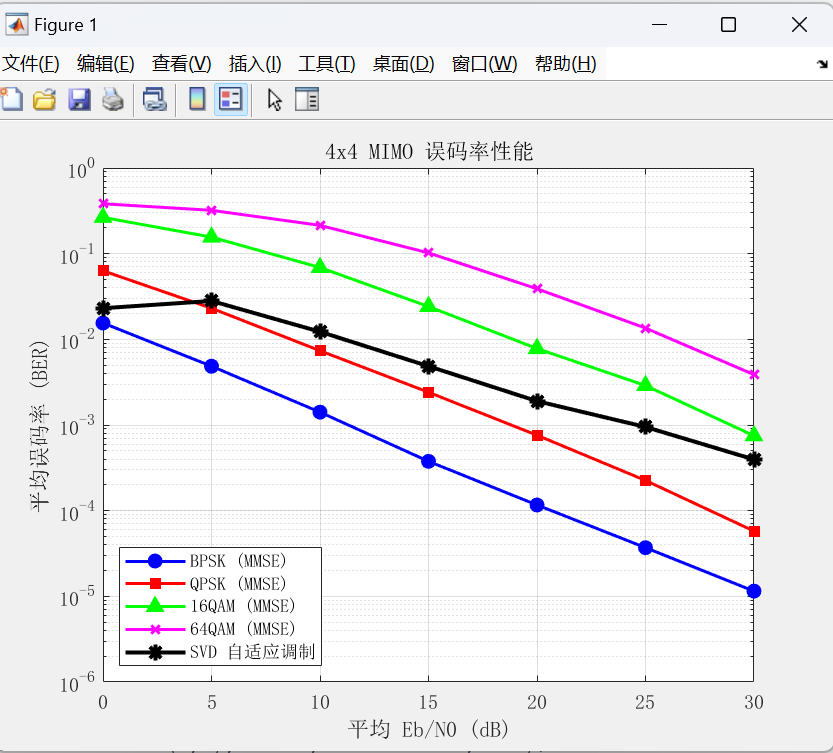
仿真流程如下图所示,对比了自适应调制和固定调制下的误码率和吞吐量。

可以看到:
- 固定调制中,BPSK性能最优,64QAM最差,与理论一致。自适应方案介于之间,验证了系统通过关闭劣质子流或采用低阶调制避免误码激增的策略。
- 吞吐量性能:自适应方案差于 64QAM,比其他的都好
体现了其在可靠性与频谱效率之间的有效折衷。
部分代码:
c
clc; clear; close all;
% --- 仿真参数 ---
simParams.EbN0_dB_vec = 0:5:30;
simParams.numBlocks = 5000;
simParams.symbolsPerBlock = 100;
% --- MIMO 参数 ---
mimoParams.Nt = 4;
mimoParams.Nr = 4;
mimoParams.Nstreams = mimoParams.Nt;
% --- 自适应调制参数 ---
adaptParams.mod_orders = [0, 2, 4, 16, 64];
adaptParams.bits_per_symbol_map = [0, 1, 2, 4, 6];
adaptParams.sinr_thresholds_db = [-Inf, 0, 6, 12, 20];
adaptParams.P_total = mimoParams.Nt;
adaptParams.Es_per_stream_avg = adaptParams.P_total / mimoParams.Nstreams;
adaptParams.k_avg_approx = mean(adaptParams.bits_per_symbol_map(adaptParams.bits_per_symbol_map > 0));
% --- 固定调制参数 ---
fixedParams.mod_list = {'BPSK', 'QPSK', '16QAM', '64QAM'};
fixedParams.M_map = [2, 4, 16, 64];
fixedParams.k_map = [1, 2, 4, 6];
% --- 结果存储变量 ---
results.ber_fixed = zeros(length(fixedParams.mod_list), length(simParams.EbN0_dB_vec));
results.thr_fixed = zeros(length(fixedParams.mod_list), length(simParams.EbN0_dB_vec));
results.ber_adapt = zeros(1, length(simParams.EbN0_dB_vec));
results.thr_adapt = zeros(1, length(simParams.EbN0_dB_vec));
% --- 仿真循环(遍历 Eb/N0) ---
fprintf('4x4 MIMO 对比仿真开始(SVD 自适应 vs 固定 MMSE)...\n');
startTime = tic;
for i_ebn0 = 1:length(simParams.EbN0_dB_vec)
EbN0_dB = simParams.EbN0_dB_vec(i_ebn0);
fprintf(' Eb/N0 = %d dB\n', EbN0_dB);
loopStartTime = tic;
% 计算 N0
EbN0_linear = 10^(EbN0_dB/10);
N0 = adaptParams.Es_per_stream_avg / (adaptParams.k_avg_approx * EbN0_linear);
noiseVar = N0 / 2;
% --- 固定调制仿真(使用 MMSE 接收机) ---
for m = 1:length(fixedParams.mod_list)
mod_idx_fixed = find(adaptParams.mod_orders == fixedParams.M_map(m));
k_fixed = fixedParams.k_map(m);
total_tx_bits_fixed = 0;
total_rx_errors_fixed = 0;
M_k_indices_fixed = repmat(mod_idx_fixed, 1, mimoParams.Nstreams);
P_k_list_fixed = ones(1, mimoParams.Nstreams) * adaptParams.Es_per_stream_avg;
k_bits_per_sym_fixed = repmat(k_fixed, 1, mimoParams.Nstreams);
fprintf(' 固定 %s(MMSE)...\n', fixedParams.mod_list{m});
for i_block = 1:simParams.numBlocks
H = generate_mimo_channel(mimoParams.Nr, mimoParams.Nt);
block_tx_bits_list = cell(1, mimoParams.Nstreams);
for iStream = 1:mimoParams.Nstreams
num_bits_stream = k_bits_per_sym_fixed(iStream) * simParams.symbolsPerBlock;
block_tx_bits_list{iStream} = randi([0 1], num_bits_stream, 1);
end
tx_signal = mimo_transmit(block_tx_bits_list, M_k_indices_fixed, P_k_list_fixed, simParams.symbolsPerBlock, adaptParams.mod_orders, adaptParams.bits_per_symbol_map);
noise = sqrt(noiseVar) * (randn(mimoParams.Nr, simParams.symbolsPerBlock) + 1j*randn(mimoParams.Nr, simParams.symbolsPerBlock));
rx_signal = H * tx_signal + noise;
% 调用 MMSE 接收机
[rx_sym_est, G_matrix_fixed] = mimo_receive_mmse(rx_signal, H, N0);
[num_errors_iter, num_bits_iter, ~] = demodulate_and_compare(rx_sym_est, block_tx_bits_list, M_k_indices_fixed, adaptParams.mod_orders, adaptParams.bits_per_symbol_map, G_matrix_fixed);
total_tx_bits_fixed = total_tx_bits_fixed + num_bits_iter;
total_rx_errors_fixed = total_rx_errors_fixed + num_errors_iter;
end
if total_tx_bits_fixed > 0
results.ber_fixed(m, i_ebn0) = total_rx_errors_fixed / total_tx_bits_fixed;
results.thr_fixed(m, i_ebn0) = mimoParams.Nstreams * k_fixed * (1 - results.ber_fixed(m, i_ebn0));
else
results.ber_fixed(m, i_ebn0) = NaN; results.thr_fixed(m, i_ebn0) = 0;
end
end
% --- 自适应调制仿真(基于 SVD) ---
total_tx_bits_adapt = 0;
total_rx_errors_adapt = 0;
total_throughput_bits_adapt = 0;
fprintf(' 自适应(SVD)...\n');
for i_block = 1:simParams.numBlocks
H = generate_mimo_channel(mimoParams.Nr, mimoParams.Nt);
[M_k_indices, P_k_list, k_bits_per_sym, U, S, V] = adaptive_ctrl_svd(H, N0, adaptParams);
block_tx_bits_list = cell(1, mimoParams.Nstreams);
if sum(k_bits_per_sym) == 0, continue; end
for k = 1:mimoParams.Nstreams
num_bits_stream = k_bits_per_sym(k) * simParams.symbolsPerBlock;
if num_bits_stream > 0, block_tx_bits_list{k} = randi([0 1], num_bits_stream, 1);
else, block_tx_bits_list{k} = []; end
end
tx_signal = mimo_transmit_svd(block_tx_bits_list, M_k_indices, P_k_list, simParams.symbolsPerBlock, adaptParams.mod_orders, adaptParams.bits_per_symbol_map, V);
noise = sqrt(noiseVar) * (randn(mimoParams.Nr, simParams.symbolsPerBlock) + 1j*randn(mimoParams.Nr, simParams.symbolsPerBlock));
rx_signal = H * tx_signal + noise;
rx_sym_est = mimo_receive_svd(rx_signal, U);
[num_errors_iter, num_bits_iter, throughput_bits_iter] = demodulate_and_compare(rx_sym_est, block_tx_bits_list, M_k_indices, adaptParams.mod_orders, adaptParams.bits_per_symbol_map, S);
total_tx_bits_adapt = total_tx_bits_adapt + num_bits_iter;
total_rx_errors_adapt = total_rx_errors_adapt + num_errors_iter;
total_throughput_bits_adapt = total_throughput_bits_adapt + throughput_bits_iter;
end
if total_tx_bits_adapt > 0, results.ber_adapt(i_ebn0) = total_rx_errors_adapt / total_tx_bits_adapt;
else, results.ber_adapt(i_ebn0) = NaN; end
results.thr_adapt(i_ebn0) = total_throughput_bits_adapt / (simParams.numBlocks * simParams.symbolsPerBlock);
loopEndTime = toc(loopStartTime);
fprintf(' Eb/N0 = %d dB 完成(耗时:%.2f 秒)\n', EbN0_dB, loopEndTime);
end
totalTime = toc(startTime);
fprintf('仿真完成(总耗时:%.2f 秒)\n', totalTime);
% --- 绘制结果图形(中文) ---
% 设置中文字体(Windows 系统通常支持 '宋体',也可用 'SimHei')
set(0,'DefaultAxesFontName','宋体');
set(0,'DefaultTextFontName','宋体');
figure(1); % 误码率
semilogy(simParams.EbN0_dB_vec, results.ber_fixed(1,:), '-bo', 'LineWidth', 1.5, 'MarkerFaceColor', 'b'); hold on;
semilogy(simParams.EbN0_dB_vec, results.ber_fixed(2,:), '-rs', 'LineWidth', 1.5, 'MarkerFaceColor', 'r');
semilogy(simParams.EbN0_dB_vec, results.ber_fixed(3,:), '-g^', 'LineWidth', 1.5, 'MarkerFaceColor', 'g');
semilogy(simParams.EbN0_dB_vec, results.ber_fixed(4,:), '-mx', 'LineWidth', 1.5);
semilogy(simParams.EbN0_dB_vec, results.ber_adapt, '-k*', 'LineWidth', 2, 'MarkerSize', 8);
hold off;
xlabel('平均 Eb/N0 (dB)');
ylabel('平均误码率 (BER)');
legend('BPSK (MMSE)', 'QPSK (MMSE)', '16QAM (MMSE)', '64QAM (MMSE)', 'SVD 自适应调制', 'Location', 'southwest');
title('4x4 MIMO 误码率性能');
grid on; ylim([1e-6 1]);
figure(2); % 吞吐量
plot(simParams.EbN0_dB_vec, results.thr_fixed(1,:), '-bo', 'LineWidth', 1.5, 'MarkerFaceColor', 'b'); hold on;
plot(simParams.EbN0_dB_vec, results.thr_fixed(2,:), '-rs', 'LineWidth', 1.5, 'MarkerFaceColor', 'r');
plot(simParams.EbN0_dB_vec, results.thr_fixed(3,:), '-g^', 'LineWidth', 1.5, 'MarkerFaceColor', 'g');
plot(simParams.EbN0_dB_vec, results.thr_fixed(4,:), '-mx', 'LineWidth', 1.5);
plot(simParams.EbN0_dB_vec, results.thr_adapt, '-k*', 'LineWidth', 2, 'MarkerSize', 8);
hold off;
xlabel('平均 Eb/N0 (dB)');
ylabel('吞吐量 (bps/Hz)');
legend('BPSK (MMSE)', 'QPSK (MMSE)', '16QAM (MMSE)', '64QAM (MMSE)', 'SVD 自适应调制', 'Location', 'northwest');
title('4x4 MIMO 吞吐量性能');
grid on;
ylim([0 mimoParams.Nstreams*max(adaptParams.bits_per_symbol_map)+1]);4 总结
本文围绕 MIMO 系统中的自适应传输方案,对 SVD 预编码、注水功率分配与自适应调制三者联合优化进行了仿真分析。在 4×4 MIMO 配置下,仿真对比了 BPSK、QPSK、16QAM 及 64QAM 四种固定调制方案与基于 SINR 阈值的自适应调制方案的性能。
从误码率角度看,自适应调制方案通过主动关闭信道质量较差的子流或降阶调制,有效抑制了深衰落子信道对整体误码率的拖累,其 BER 性能优于同条件下的高阶固定调制方案,验证了以可靠性换效率的策略合理性。从吞吐量角度看,自适应方案在中等 SNR 区间的总吞吐量优于除 64QAM 以外的所有固定调制方案,且相比 64QAM 的激进策略,自适应方案不会在高误码区域出现"丢包换速率"的不可用状态,展现了良好的鲁棒性与实用性。总体上,该方案实现了链路可靠性与频谱效率之间的有效折衷,贴合当前 5G/6G 系统对灵活资源配置的需求,为实际系统设计提供了参考依据。
源代码 与仿真图表所见即所得,完整代码获取方式请见文末vx公众号