目录
-
- 1.摘要
- [2.LLM 增强 Q-Learning 方法](#2.LLM 增强 Q-Learning 方法)
- 3.实验分析
- 4.结论
- 7.参考文献
- 8.算法辅导·应用定制·读者交流
1.摘要
多飞行助手旅行商问题(mFSTSP)多架 UAV 与卡车协同配送,传统调度方法在大规模场景下计算成本高、探索低效,且容易陷入局部最优。本文提出LLM-QL 将 Q-Learning 局部探索与 LLM 对未知环境全局理解结合,用专门设计的提示词把问题建模转为 LLM 易理解形式并生成启发式项指导探索。
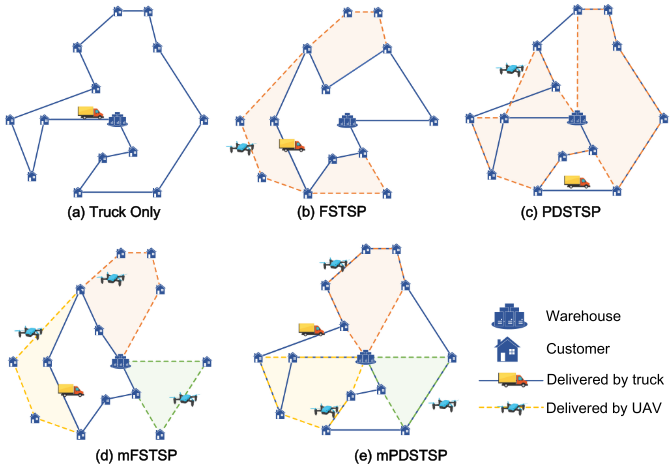
2.LLM 增强 Q-Learning 方法
问题建模
mFSTSP 目标是最小化卡车和多 UAV 完成所有配送并返回终点总完成时间:
min t c + 1 \min\; t_{c+1} mintc+1
关键约束包括:每个客户只被卡车或某架 UAV 服务一次;卡车从仓库出发并返回终点;每架 UAV 每次任务最多服务一个客户;UAV 飞行时间不超过续航;卡车路径保持连通并消除子回路。
将 mFSTSP 转为序贯决策问题 。状态 S = ( i , D ) S=(i,D) S=(i,D) 表示卡车当前位置和 UAV 状态;动作 A = ( j , m ) A=(j,m) A=(j,m) 表示选择下一节点 j j j 和运输方式 m m m,其中 m = 0 m=0 m=0 为卡车, m = 1 m=1 m=1 为 UAV。Q 表 Q i , j , m Qi,j,m Qi,j,m 存储从节点 i i i 到节点 j j j 并使用工具 m m m 累计回报。
Q i , j , m = Q i , j , m + α ( R i , j , m + γ max A ′ Q j , k , m ′ ) − Q i , j , m (12) Qi,j,m=Qi,j,m+\alpha\left(Ri,j,m+\gamma\max_{A'}Qj,k,m'\right)-Qi,j,m \tag{12} Qi,j,m=Qi,j,m+α(Ri,j,m+γA′maxQj,k,m′)−Qi,j,m(12)
其中, α \alpha α 为学习率, γ \gamma γ 为折扣因子。奖励原先取路径距离倒数,距离越短奖励越高。
LLM 增强 Q-Learning
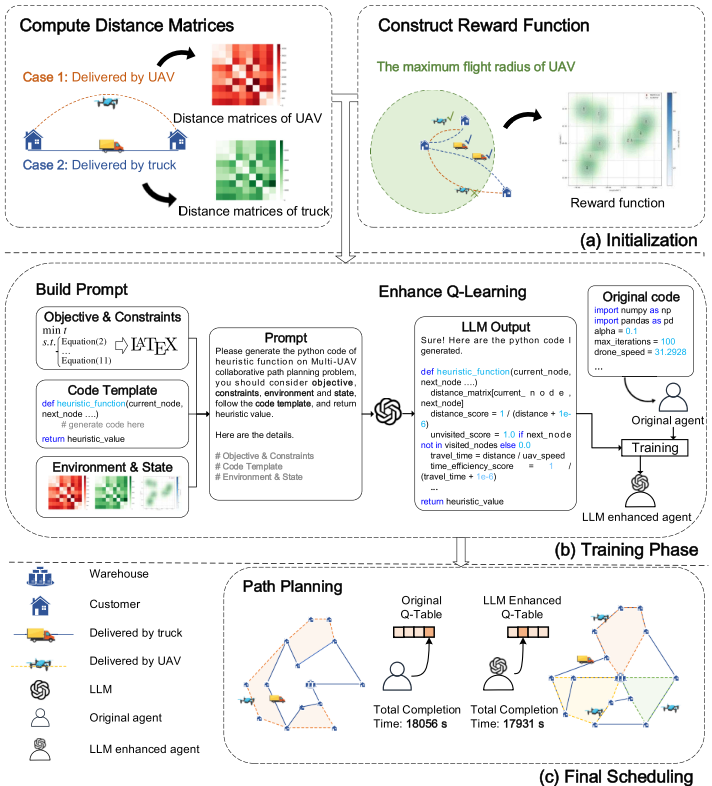
LLM-QL 先分别构造卡车道路距离矩阵和 UAV 欧氏距离矩阵。卡车距离反映真实路网,UAV 距离反映直飞路径。将目标函数、约束、当前状态和 Python 模板输入 LLM ,让其生成可执行启发式函数 H i , j , m Hi,j,m Hi,j,m。启发式项综合距离、未访问状态、客户优先级、邻近连接度和时间效率,用于指导动作选择。
LLM-QL 的奖励函数为:
R i , j , m = { 1 T i , j , m , 若所有约束满足 − ∞ , 若任一约束违反 Ri,j,m= \begin{cases} \dfrac{1}{Ti,j,m}, & \text{若所有约束满足}\\ -\infty, & \text{若任一约束违反} \end{cases} Ri,j,m=⎩ ⎨ ⎧Ti,j,m1,−∞,若所有约束满足若任一约束违反
引入 LLM 启发式后 Q 值更新:
Q i , j , m ← Q i , j , m + α ( R i , j , m + γ max A ′ Q j , k , m ′ ) + H i , j , m − Q i , j , m Qi,j,m\leftarrow Qi,j,m+\alpha\left(Ri,j,m+\gamma\max_{A'}Qj,k,m'\right)+Hi,j,m-Qi,j,m Qi,j,m←Qi,j,m+α(Ri,j,m+γA′maxQj,k,m′)+Hi,j,m−Qi,j,m
每轮训练中,算法按 ε \varepsilon ε-greedy 策略选择动作,计算 LLM 启发式值并更新 Q 表,直到所有节点访问完成。
3.实验分析
实验使用西雅图城市数据集,包含仓库、客户经纬度和包裹重量。卡车距离采用真实道路网络距离,UAV 距离采用欧氏距离。LLM 使用 ChatGPT-4o,框架不依赖特定模型。
对比方法包括 MILP、2PML 和 MAPPO。
消融实验
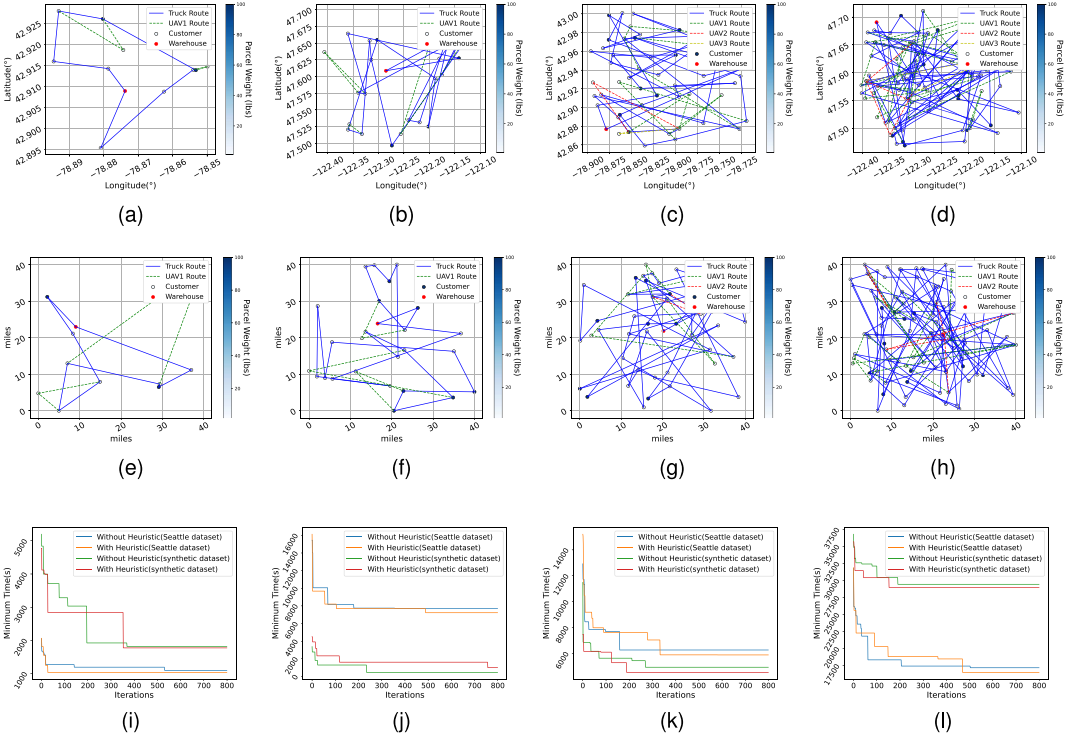
消融实验比较有无 LLM 启发式的 Q-Learning。小规模任务中,加入启发式后不一定每次都达到精确最优,但收敛明显更快;大规模任务中,收敛速度相近,但启发式版本给出更准确的总完成时间。两类数据集上结果一致,说明 LLM-QL 具有泛化性。
解质量与问题规模比较
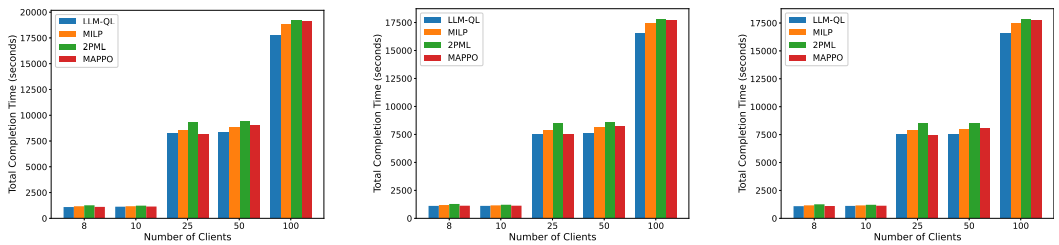
在不同客户规模和 UAV 数量下,LLM-QL 总完成时间最低,说明其能在固定迭代内更快找到更好解。MILP 在小规模可精确求解,但大规模复杂度迅速上升;2PML 受聚类和路径规划两阶段折中影响;MAPPO 虽提高协作效率,但大规模下训练和计算压力较大。
4.结论
LLM-QL通过启发式项减少无效探索并加速收敛。理论上,加入有界启发式不破坏 Bellman 算子压缩性且近似误差有界。实验表明,LLM-QL 在大规模场景中优于 MILP、2PML 和 MAPPO,在总完成时间、运行时间和 UAV 利用率等关键指标上最高提升约 1.35 倍。
7.参考文献
Zhou Q, Wu J, Zhu M, et al. LLM-QL: a LLM-enhanced Q-learning approach for scheduling multiple parallel dronesJ. IEEE Transactions on Knowledge and Data Engineering, 2025.
8.算法辅导·应用定制·读者交流
xx