摘要
VLA模型正在将机器人学习推向"通用策略"(generalist policy)范式:一个大规模预训练策略,可作为下游任务、不同机器人本体和场景迁移的统一初始化。
然而,在接触密集型操作中,纯视觉信息往往不足。拧瓶盖、擦盘子、插USB、翻书页、在气球上画图等任务的难点通常发生在接触发生之后:压力是否过大、是否已经插偏、是否即将打滑、是否需要减速或重新调整。这些关键信息依赖触觉反馈。
本文提出 FTP-1(Foundation Tactile Policy),一套面向接触密集型操作的通用基础触觉策略。该工作由 Sharpa 与清华大学、上海交通大学、UC Berkeley、ETH Zurich、复旦大学等机构联合完成,旨在让触觉策略摆脱"一个传感器训练一个策略、一个本体适配一套模型"的局限,实现跨触觉传感器与机器人平台的经验复用。
触觉策略通用化的核心挑战
触觉传感器的高度异构性长期制约着触觉策略的通用化。不同传感器的输出形式(图像型、阵列型、状态量)、分辨率、采样率、空间布局和接触响应特性差异极大,导致在一个传感器上学到的"触觉经验"难以直接迁移。
FTP-1 在预训练与验证中重点采用 Sharpa Wave(22主动自由度高灵巧手)和 Sharpa North 人形机器人平台,以及 Sharpa DTC(Dynamic Tactile Array,DTA)指尖触觉传感器。其中,Sharpa Wave 采用与人类手部高度同构(isomorphic)的设计,遵循黄金分割比例,在尺寸、关节自由度分布、指尖/掌部接触区域布局以及力传导特性上高度贴近人类手部,并集成高分辨率 Dynamic Tactile Array。该硬件设计为跨平台迁移提供了坚实基础:在 Wave 上预训练的触觉模型具备较强的向下兼容性,能够更有效地迁移到其他类人灵巧手平台。
团队额外采集的 Sharpa North-FTP-1 数据集包含约 4000 条长时序灵巧操作演示,为预训练提供了丰富的灵巧手接触操作分布数据。论文实验在 Sharpa North、Sharpa Wave 平台及 Sharpa DTC 传感器上完成了真实世界接触密集任务验证。
统一触觉表示:Morphology-Aware Tactile Token Space (MTTS)
为解决传感器异构问题,FTP-1 提出 Morphology-Aware Tactile Token Space(MTTS),将图像型(如 GelSight-Mini)、阵列型(如 Contactile)、状态型(力/力矩)等异构触觉信号统一映射为按功能区域(functional areas)组织的触觉 token,并通过共享的触觉 Transformer expert 学习跨传感器、跨本体的可迁移触觉表示与操作能力。
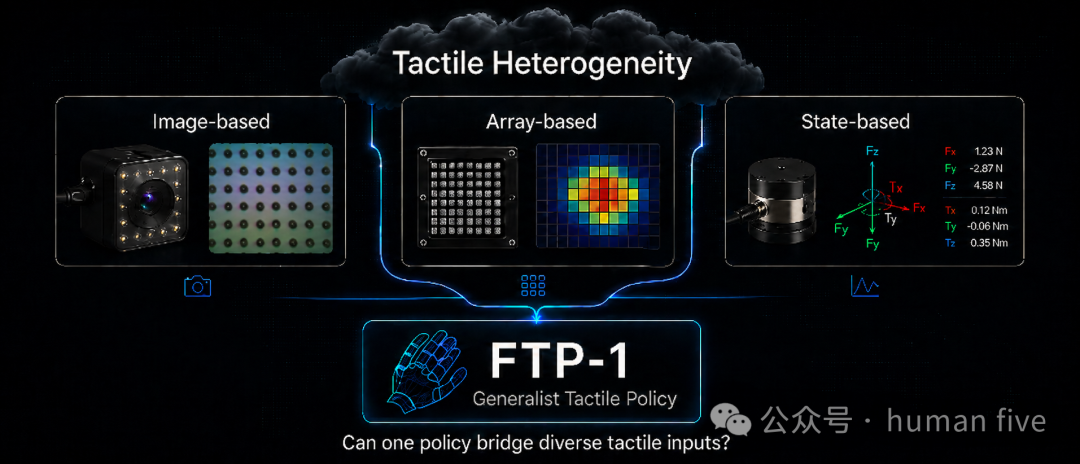
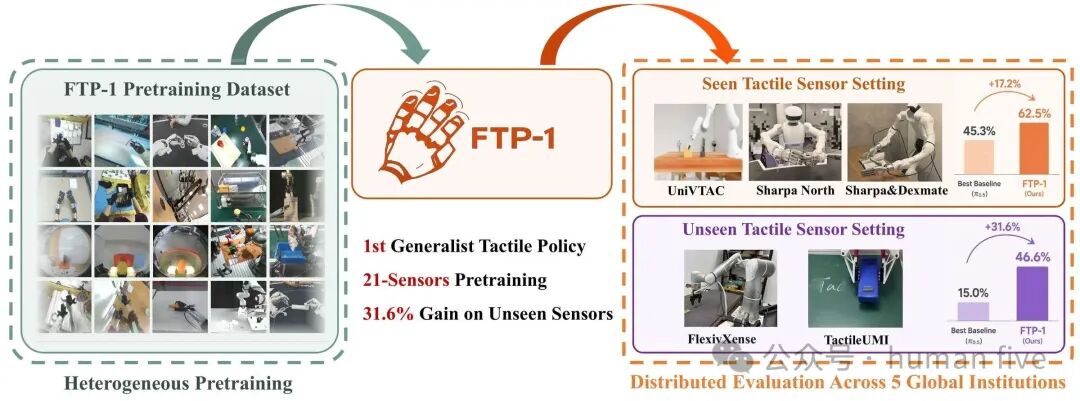
FTP-1 在约 3000 小时大规模异构触觉操作数据上进行预训练,数据来自 26 个来源,覆盖 21 种触觉传感器(包括人类演示、灵巧手机器人、夹爪机器人及 UMI 风格数据),并全部按 MTTS 接口进行统一整理。
实验验证
实验覆盖 5 套硬件设置、14 个接触密集任务、4 类下游触觉传感器。结果显示:
-
在预训练中已见过的触觉传感器设置上,FTP-1 相比最强基线平均成功率提升 17.2 个百分点;
-
在未见过的传感器设置上(如 Xense 图像触觉和 Contactile 阵列触觉),FTP-1 仍取得 31% 的成功率提升。
这表明 FTP-1 学到的并非特定硬件的触觉模式,而是可跨传感器、跨本体迁移的通用接触操作知识。
本文核心贡献
-
首套面向触觉的通用基础策略 FTP-1,将 generalist policy 范式系统性地引入跨传感器、跨本体的触觉操作学习领域。
-
Morphology-Aware Tactile Token Space (MTTS),提出一种统一触觉接口,将异构触觉信号映射到带有功能区域语义的 token 空间,实现"相似接触区域"的表示共享。
-
大规模异构触觉操作预训练数据集,包含约 3000 小时数据、26 个来源、21 种触觉传感器,并按 MTTS 接口统一整理(其中包含团队采集的 Sharpa North-FTP-1 高质量灵巧操作数据集)。
-
跨已见与未见传感器的真机与仿真实验,全面验证大规模触觉预训练能够带来真正可迁移的接触操作能力,而非仅提升同分布微调效果。
FTP-1 为接触密集型机器人操作开辟了从"专用策略"走向"通用触觉基础模型"的新路径,为未来具身智能的发展提供了重要基础。
1 引言
近年来,通用机器人策略模型快速发展。π0、π0.5、GR00T等视觉语言动作模型证明,大规模异构数据预训练可以让机器人策略获得更好的初始化,并在新任务、新场景、新本体上更高效地微调。
这一路线默认视觉是主要输入。但对于大量真实机器人任务来说,任务成败不只取决于"看见了什么",还取决于"摸到了什么"。
插孔任务中,视觉很难判断细小偏差是否已经造成卡滞;擦拭任务中,视觉不能稳定估计持续接触压力;拧瓶盖时,策略需要感知是否滑动、是否夹紧、是否需要重新施力;翻书页时,纸张摩擦、指尖压力、是否分离成功,都带有强烈触觉属性。
触觉反馈对于接触密集型操作至关重要,但现有触觉策略大多绑定在特定传感器、特定机器人本体、特定任务上。
触觉硬件之间的差异远大于相机之间的差异。图像触觉传感器记录接触形变图像,阵列触觉传感器记录离散压力/力场,力/力矩传感器记录低维状态信号;同样是"手指末端接触",在不同机械手、不同夹爪、不同传感器安装位置上,其信号形态完全不同。
因此,触觉学习面临一个核心问题:
能否训练一个单一触觉策略,从异构触觉经验中学习可迁移的接触操作知识,并在未见过的触觉传感器和机器人本体上继续发挥作用?
FTP-1正是围绕这个问题展开。
它不再把触觉视作某个任务上的附加输入,也不把触觉编码器绑定到单一硬件,而是从模型接口、预训练数据、策略架构、下游评测四个层面重新组织触觉策略学习流程。
2 相关工作
2.1 通用机器人策略
通用机器人策略希望摆脱单任务训练范式,在大规模机器人数据上预训练统一模型,再快速适配新任务、新环境与新本体。
OpenVLA、π0、π0.5、GR00T、RDT等模型从视觉、语言、动作、轨迹数据中学习通用行为先验;Open X-Embodiment等数据集推动了跨机器人平台的大规模预训练;一些工作进一步引入人类视频、VR演示、潜在动作token、世界模型等信号增强迁移能力。
但这些通用策略大多以视觉与语言为核心输入,触觉信息通常缺失。对于接触丰富、形变物体、小间隙装配、持续压力控制等任务,仅依赖视觉往往不足。
2.2 触觉策略学习
已有大量工作证明,触觉能够显著提升接触密集型操作表现。基于视觉-触觉融合的策略可以更好完成插拔、擦拭、按压、灵巧抓取、手内操作等任务。
但多数方法仍然围绕单一传感器和单一硬件设置设计。模型可能可以在某款图像触觉传感器上工作,却难以迁移到阵列触觉传感器;可能适配某只机械手,却无法自然迁移到夹爪或另一款灵巧手。
也有工作研究触觉表征预训练,例如通过视觉-触觉配对数据学习触觉编码器,或在特定传感器数据上预训练触觉策略。这些方法提升了同类传感器上的下游表现,但尚未形成跨图像型、阵列型、状态型触觉输入的端到端通用触觉策略。
FTP-1的定位是:不是给视觉策略临时加一个触觉分支,而是把触觉本身作为基础策略预训练的一等公民,研究触觉操作能力能否像视觉语言能力一样被大规模预训练、共享并迁移。
3 FTP-1:通用基础触觉策略
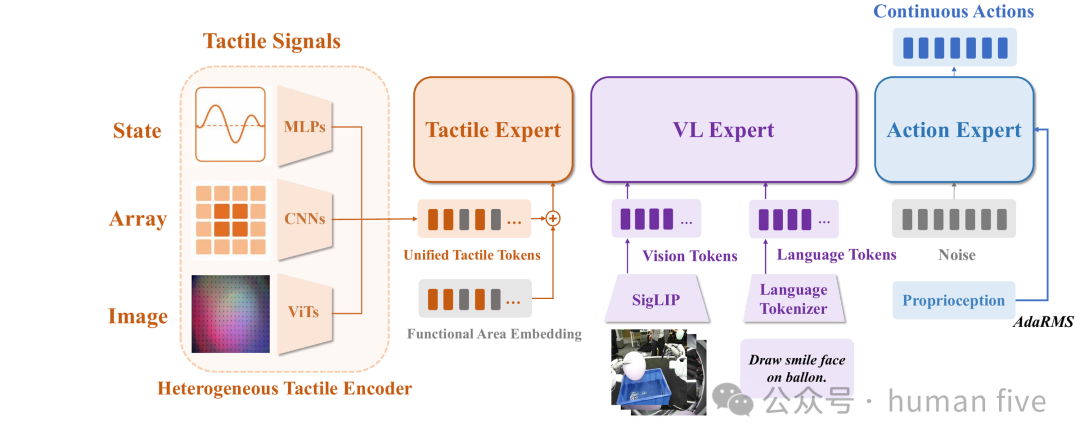
FTP-1输入包括语言指令、多视角RGB图像、本体状态与触觉观测;输出为未来一段连续动作chunk。整体结构继承多专家基础策略范式,由视觉语言expert处理图像与语言,由触觉expert处理触觉token,由动作expert融合多模态信息并生成连续动作。
关键区别在于,FTP-1没有简单把触觉输入塞进视觉语言模型,而是为触觉设计了一套独立且可共享的接口与专家模块。
3.1 触觉异构性的核心瓶颈
对视觉模型而言,不同相机输入通常仍可统一成图像token;对语言模型而言,不同文本都可统一成token序列。
触觉没有这样天然统一的接口。
同一只手的指尖、指腹、掌心、腕部力矩,不仅信号形态不同,功能意义也不同。不同机器人本体上的触觉传感器数量、覆盖区域、安装位置、采样频率、输出维度都可能不同。直接把所有触觉数据拼接到一起训练,会导致模型既难以共享知识,也容易过拟合某个传感器的形态。
FTP-1把问题转化为:先统一"触觉发生在哪个功能区域",再统一"该区域对应的触觉token如何被编码"。
3.2 Morphology-Aware Tactile Token Space(MTTS)
为解决触觉异构性,FTP-1提出Morphology-Aware Tactile Token Space(MTTS)。
MTTS定义了24个功能区域槽位。对于手内触觉,0到14号槽位对应不同手部功能区域;对于腕部与手指力/力矩信号,15到20号槽位用于表达torque/force相关信息;21到23号槽位保留给未来扩展。
对于平行夹爪,两侧触觉传感器被映射到拇指尖与食指尖功能槽位,因为它们在夹取行为中的功能语义类似于双指抓取。
这样,不同传感器虽然底层信号不同,但最终都会被组织到统一的功能区域token空间中。模型看到的不再只是"某个设备上的某个数组/图像",而是"某个功能区域上的触觉信息"。
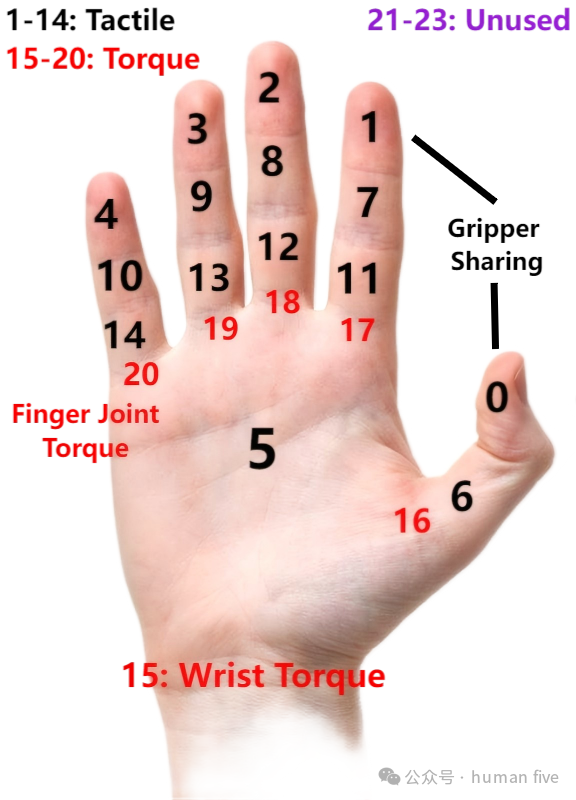
每个MTTS token还会加入可学习的functional-area embedding。该embedding在不同传感器之间共享,用于告诉模型当前触觉token对应的末端执行器功能区域。左右手使用不同功能区域embedding,以区分双手触觉信号。
这种设计的直观意义是:即使下游传感器从未出现在预训练中,只要它能被映射到相应功能区域,模型仍可复用预训练触觉expert中学到的接触语义。
3.3 异构触觉编码器
MTTS统一了触觉token的语义位置,但原始触觉输入仍然形态各异。FTP-1为不同触觉模态设计异构编码器。
图像型触觉输入,例如GelSight或Sharpa DTC,先被resize为统一图像尺寸,再经过传感器特定的轻量ViT与共享T3 Transformer触觉编码器,最终取CLS token作为该功能区域的触觉表示。
阵列型触觉输入,例如Contactile或AetherGlove,通过傅里叶编码增强信号维度,再使用CNN捕获空间触觉结构,并压缩为一个功能区域token。
状态型触觉输入,例如力/力矩传感器、关节torque、低维接触状态,同样经过傅里叶编码与轻量MLP,转化为MTTS token。
如果同一传感器在多个功能区域上拥有相同形态输入,FTP-1会共享对应编码器参数,以减少传感器特定参数量,并鼓励模型学习共通触觉动力学。
3.4 共享触觉专家
FTP-1采用独立触觉Transformer expert处理MTTS token。动作expert可以读取触觉expert输出,但触觉expert不会反向读取动作expert或视觉语言expert。
这种模块化设计有三点作用。
第一,它让触觉知识可以作为独立模块迁移。面对未见过的触觉传感器时,下游只需从头训练传感器特定编码器,而共享触觉expert、功能区域embedding以及部分共享触觉模块可以直接复用。
第二,它避免触觉输入破坏预训练视觉语言expert已有知识。实验中,简单把触觉token注入视觉语言expert的Tactile-VLA基线,在部分真机任务上反而弱于纯视觉语言策略,说明不恰当的多模态融合可能会干扰原本较强的视觉语言表征。
第三,它提高了触觉处理效率与可扩展性。触觉expert只关注触觉token之间的交互,动作expert再统一融合视觉、语言、本体状态与触觉信息。
3.5 统一动作空间
不同机器人本体拥有不同动作空间。灵巧手可能需要手指关节控制,双臂机器人需要左右末端位姿或关节控制,夹爪只需要开合距离。
FTP-1采用统一动作空间,将机器人动作表示为固定长度稀疏向量。左右臂、头部、补充控制量等动作槽位统一排列;不同本体只填充自身支持的控制维度,并使用mask排除缺失动作维度的损失。
对于手部控制,FTP-1沿用Function--Actuator--Aligned Space(FAAS)思想,把功能相似的关节映射到相同动作槽位,从而让不同灵巧手共享动作语义。
该设计与MTTS相互呼应:MTTS统一触觉输入的功能区域,统一动作空间统一输出动作的功能槽位。二者共同支撑跨本体、跨传感器的策略预训练。
4 FTP-1-Dataset:大规模异构触觉预训练数据
仅有统一模型接口还不够。要学习可迁移的触觉操作能力,模型必须见过足够多的触觉传感器、机器人本体、任务形式与接触模式。
FTP-1-Dataset聚合26个数据来源,覆盖21种触觉传感器,其中包括7种图像型触觉、5种阵列型触觉、9种状态型触觉。数据来源包含人类演示、灵巧手机器人、夹爪机器人、UMI风格系统等。
除整合已有数据外,作者还采集了Sharpa North-FTP-1数据,包含4000条长时序灵巧操作演示。
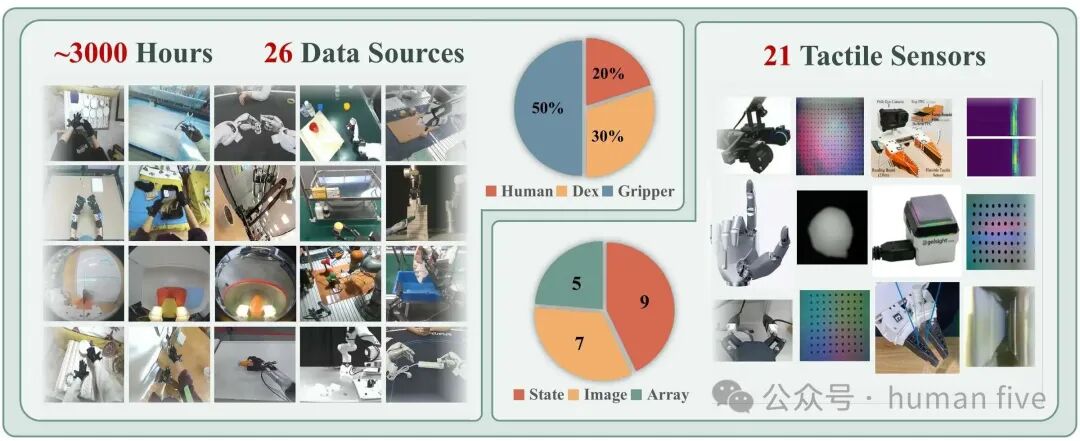
原始数据规模差异很大,因此预训练时采用数据源特定采样比例,重采样后最终预训练混合约为:20%人手数据、30%灵巧手数据、50%夹爪数据。
所有触觉标注均按照MTTS功能区域组织。具有腕部位姿或头部位姿标注的数据,会被转换到统一坐标方向定义。语言标注经过重写以增加指令多样性。
这种数据组织方式的重点不是简单堆数据,而是把原本分散在不同硬件、不同格式、不同任务中的触觉经验,映射到同一个模型可学习的触觉token空间中。
5 下游微调实验:已见传感器设置
本文首先验证一个基本问题:在预训练中已经覆盖过的触觉传感器设置上,FTP-1预训练是否能提升下游触觉策略微调效果?
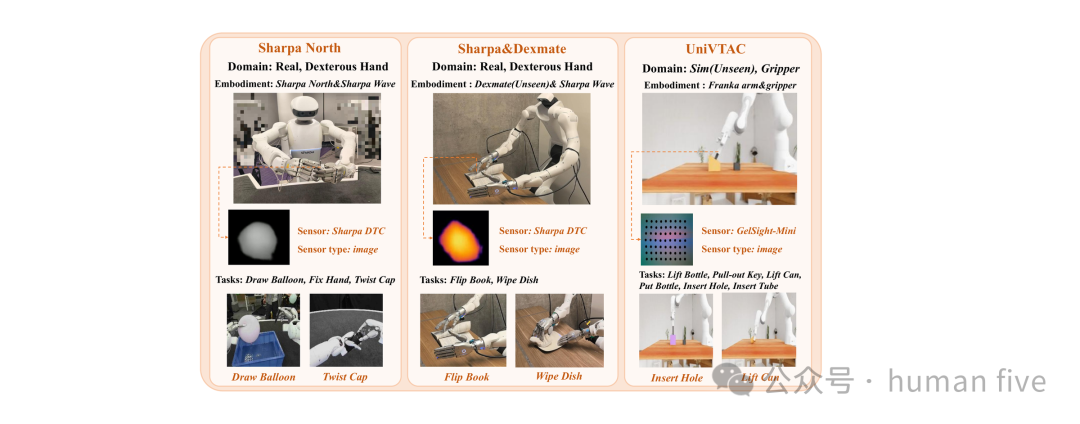
实验覆盖三类设置:UniVTAC仿真环境、Sharpa North真机、Sharpa&Dexmate真机。这些设置使用的GelSight-Mini与Sharpa DTC触觉传感器都出现在FTP-1预训练数据中,因此下游微调可以初始化触觉tokenizer与触觉expert。
对比基线包括:
π0.5:不使用触觉输入的强视觉语言动作策略;
Tactile-VLA:将触觉输入注入VLM expert,但没有独立触觉expert;
FTP-π0.5:使用FTP-1架构,但不进行大规模FTP-1触觉预训练,用于隔离预训练贡献。
5.1 UniVTAC仿真基准
UniVTAC包含6个接触密集任务,覆盖手内操作、插入、拔出等行为。每个任务评估100次rollout。
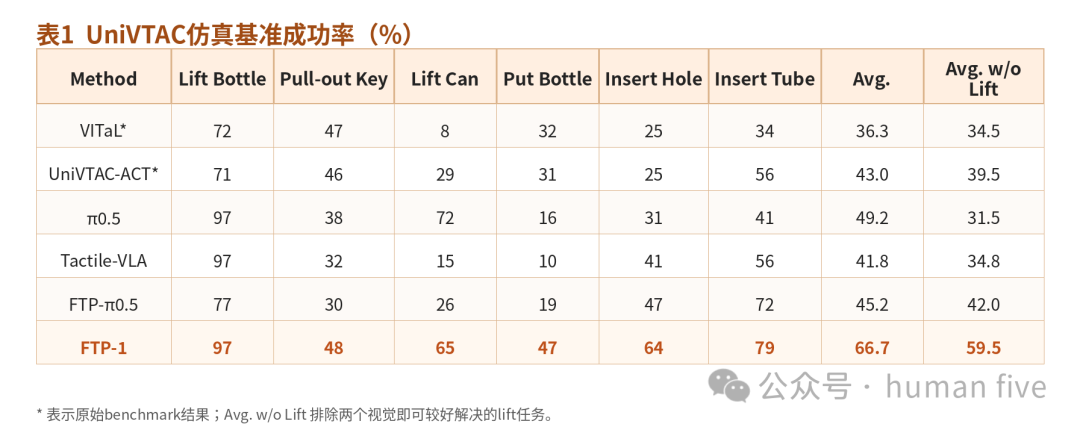
结果显示,FTP-1在整体平均成功率上达到66.7%,显著高于所有基线。由于Lift Bottle与Lift Can在仿真中可被纯视觉策略较好解决,论文额外报告了排除这两个任务后的平均值。此时FTP-1仍达到59.5%,相比第二名提升约17.5个百分点。
这一结果说明,FTP-1的优势主要体现在真正需要接触反馈的任务上,而不是依赖视觉即可完成的简单场景。
5.2 真机接触密集任务
真机评测包含两个平台。
Sharpa North平台测试Draw Balloon、Fix Hand、Twist Cap等长时序灵巧任务,涉及形变物体交互、小零件操作、双手协同与持续接触控制。
Sharpa&Dexmate平台测试Flip Book与Wipe Dish,重点考察按压、摩擦、持续接触、力控稳定性等能力。
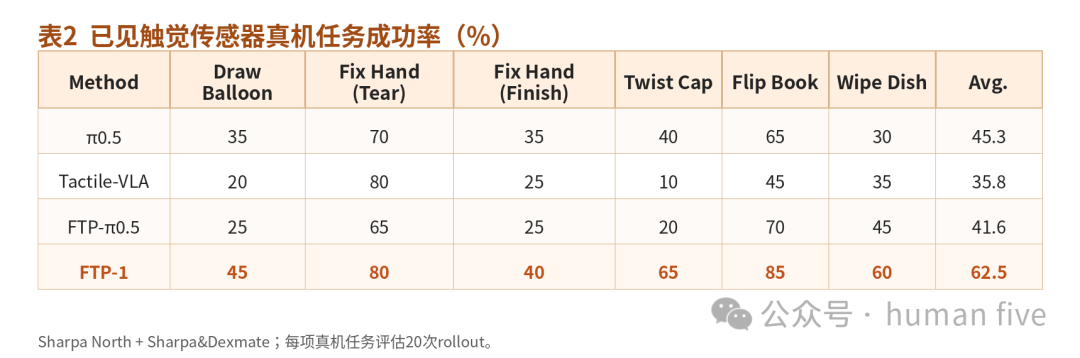
FTP-1在所有方法中平均成功率最高,达到62.5%。最强基线π0.5为45.3%,FTP-1提升17.2个百分点。
值得注意的是,纯视觉语言策略π0.5在真机任务上排名第二,超过两个触觉基线。这反而说明:触觉不是简单"加上就有用"。如果多模态融合方式不合适,触觉输入可能扰乱原本较强的视觉语言表示,造成动作不稳定。
观察策略行为可以看到,Tactile-VLA与FTP-π0.5在接触条件变化时更容易产生不稳定动作;π0.5缺少触觉反馈时,常常无法维持稳定按压力,也难以根据拧瓶盖或擦拭过程中的接触变化做出反应。FTP-1则能够在多类任务中生成更平滑、更稳定的动作。

6 更关键的问题:能否迁移到未见触觉传感器?
同分布提升固然重要,但通用触觉策略最关键的检验是:面对预训练中从未出现过的新触觉传感器,FTP-1是否还能提供有用初始化?
本文在两个未见传感器设置上进行评测。
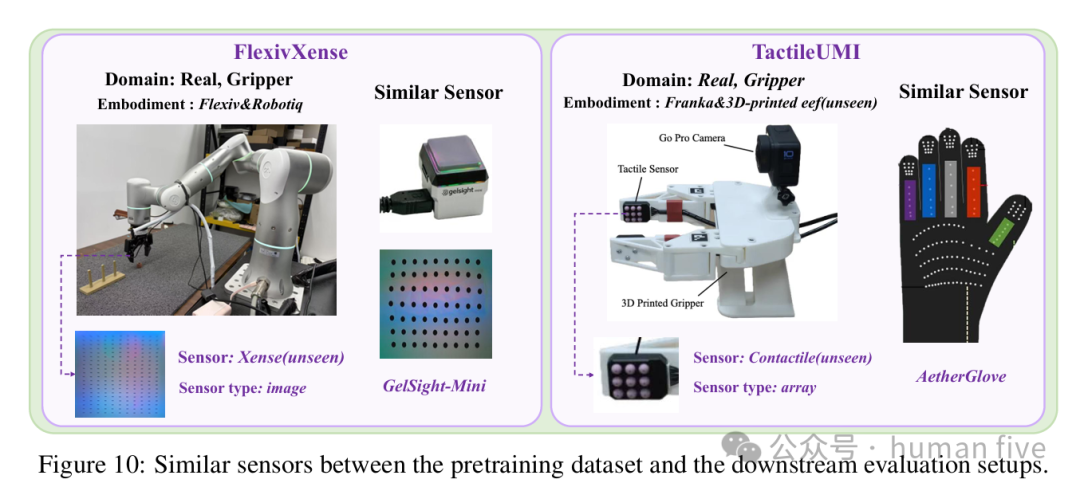
FlexivXense使用Xense图像触觉传感器,测试Insert Hanoi与Insert USB两个精细插入任务。每个任务使用100条微调演示。
TactileUMI使用Contactile阵列触觉传感器,测试Wipe Board按压擦拭任务,使用50条微调演示。
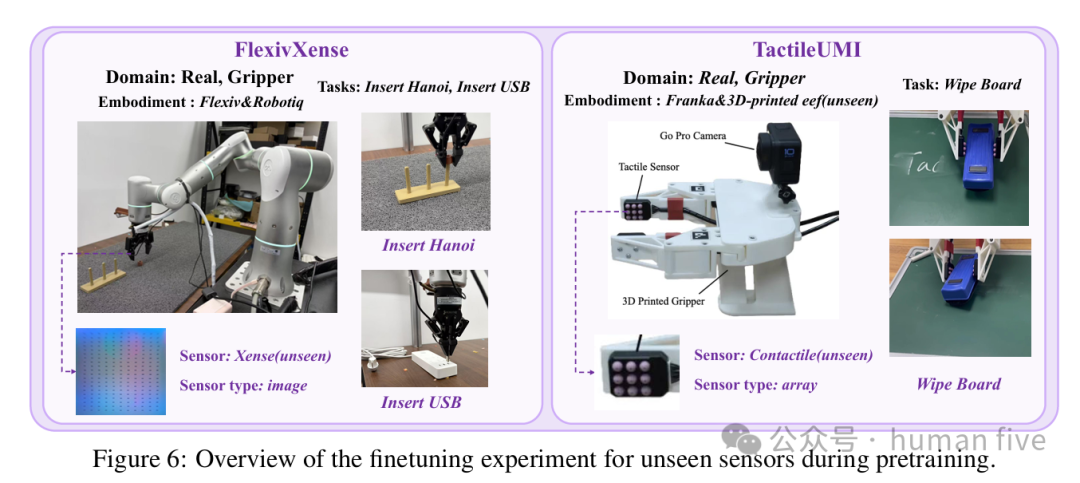
这些传感器本身没有出现在FTP-1预训练中。微调时,传感器特定触觉编码器从头训练;共享触觉expert、功能区域embedding,以及部分共享触觉模块仍复用预训练参数。
论文还分析了未见传感器与预训练中相近传感器的关系:Xense同为图像型触觉,最接近GelSight-Mini;Contactile为阵列型触觉,最接近AetherGlove。
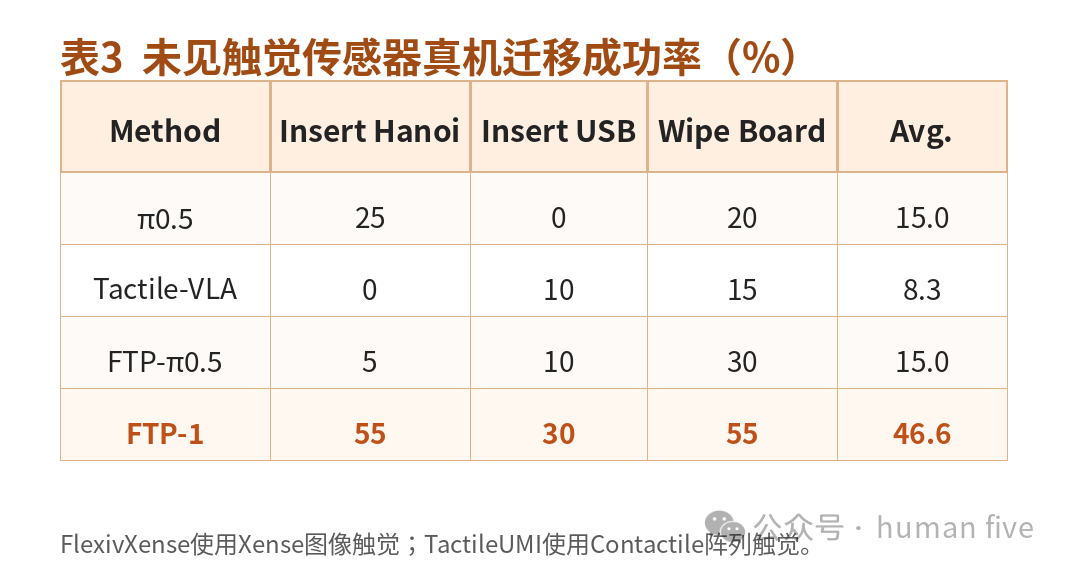
结果非常关键:FTP-1在未见传感器任务上平均成功率达到46.6%,而最强基线仅为15.0%,提升31.6个百分点。
在Insert Hanoi任务中,当圆形积木与柱子发生错位时,FTP-1会根据触觉反馈减慢插入速度并进行反应式调整;纯视觉策略虽然偶尔也能表现出恢复行为,但缺乏触觉调节,常因继续硬插而失败。
在Insert USB任务中,仅有100条演示,任务对数据效率要求很高。FTP-1动作更稳定,而其他模型容易在插入阶段产生细小抖动,导致成功率下降。
在Wipe Board任务中,FTP-1更容易维持稳定按压力与连续表面接触;其他模型常出现压力不足、接触丢失或动作不连续。


这一组实验说明,FTP-1并不只是记住了某些预训练传感器的输入分布,而是通过MTTS与共享触觉expert学习到了可迁移的触觉操作知识。
7 预训练收益究竟来自哪里?
未见传感器上的提升可能有两种解释。
一种解释是数据分布更接近:FTP-1预训练数据本身与下游任务相似,因此微调更容易。
另一种解释是可迁移触觉知识:触觉分支在大规模异构触觉数据中学到了通用接触操作能力,因此即使传感器不同,也能提供更好的初始化。
为区分这两种可能,论文构造了No-Tactile-Pretraining checkpoint(NTP)。NTP使用与FTP-1相同的数据与训练设置,但预训练阶段不输入触觉,也不包含触觉相关结构。下游微调时再加入与FTP-1相同的触觉架构,得到NTP-1。
这样,NTP-1与FTP-1架构相同,数据来源相同,差别只在于预训练阶段是否真的学习过触觉分支。
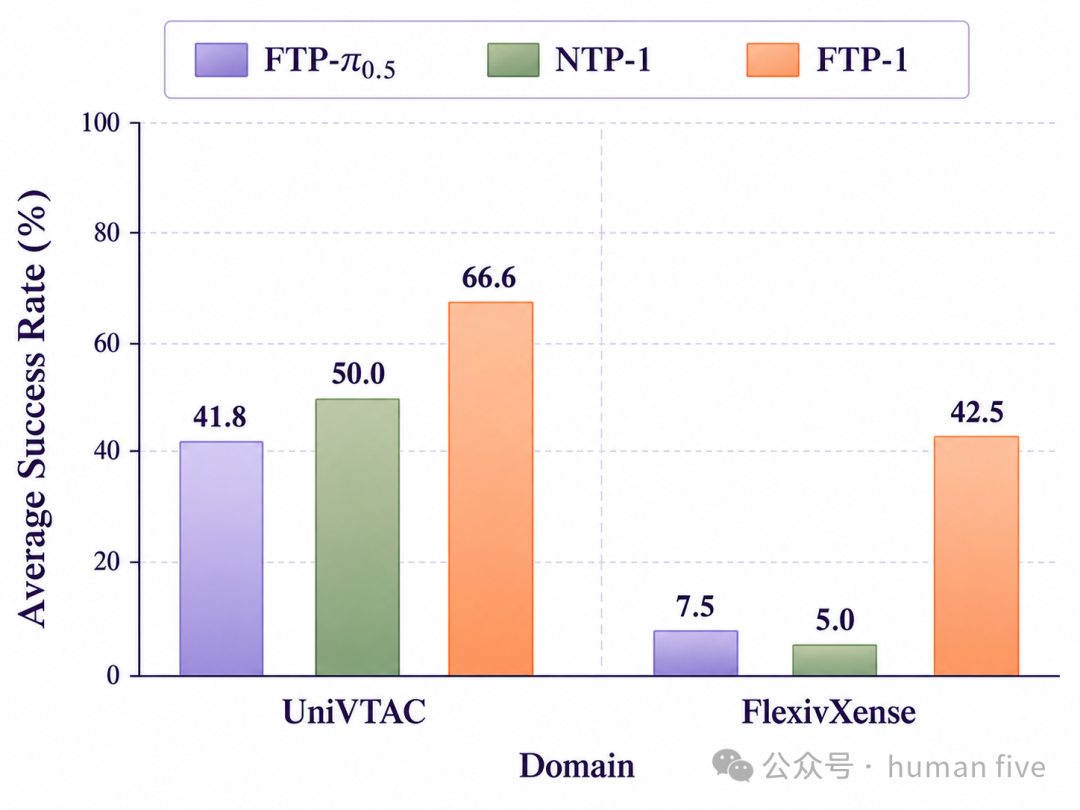
在UniVTAC上,NTP-1优于FTP-π0.5,说明FTP-1数据分布本身确实对部分下游任务有帮助。但NTP-1仍明显低于FTP-1,说明触觉分支预训练提供了额外收益。
在FlexivXense未见传感器任务上,差距更明显:FTP-1相比NTP-1提升37.5个百分点。没有触觉分支预训练时,NTP-1在关键插入阶段对触觉变化不够鲁棒,动作更不稳定。
因此,消融实验支持第二种解释:FTP-1的收益主要来自预训练触觉知识,而不仅仅是数据分布接近。
8 FTP-1学到的是什么触觉能力?
从任务行为看,FTP-1带来的能力可以概括为三类。
第一,稳定接触维持能力。
在Wipe Dish、Wipe Board等任务中,策略需要持续保持合适按压力。视觉可以看到末端位置,却很难判断是否真正贴合表面;触觉反馈帮助FTP-1维持连续接触。
第二,力/接触变化下的反应式调整。
在Insert Hanoi与Insert USB中,失败常来自轻微偏移。FTP-1在触觉反馈显示错位时会减速或调整,而不是继续执行开环插入。这类行为更接近人类在插入小物体时的"摸着走"。
第三,长时序接触操作中的鲁棒性。
Draw Balloon、Fix Hand、Twist Cap、Flip Book等任务包含多个接触阶段,且接触状态会不断切换。FTP-1的动作更平滑稳定,说明预训练触觉expert提供了跨阶段的接触表征先验。

这些能力并不是由单一传感器特征决定的,而是由大量不同触觉输入、不同末端执行器、不同任务接触模式共同塑造出来的。
9 结论
本文提出FTP-1,一套面向接触密集型操作的通用基础触觉策略。
FTP-1通过MTTS将异构触觉信号映射到统一功能区域token空间,再由共享触觉Transformer expert学习跨传感器、跨本体可迁移的触觉操作表示。配合统一动作空间与大规模异构触觉数据预训练,FTP-1为触觉策略学习提供了一个可复用的模型级起点。
实验表明,FTP-1不仅在已见触觉传感器设置上提升下游微调性能,更能迁移到预训练中未见过的Xense图像触觉和Contactile阵列触觉设置,在真机接触任务中取得显著成功率提升。
这说明触觉预训练可以带来可迁移的接触操作能力,包括稳定接触维持、力感知调节、错位恢复与长时序接触鲁棒性。这些能力是纯视觉策略难以稳定获得的,也是机器人真正走向复杂物理世界所需要的关键能力。
10 局限性与未来工作
FTP-1仍是通用触觉策略的早期探索。
首先,本文主要关注通用触觉感知与策略微调,并未系统解决触觉/力反馈伺服控制问题。未来可以将异构触觉编码框架扩展到触觉预测、接触预测以及基于预测的低层力控闭环。
其次,尽管FTP-1-Dataset已经包含约3000小时数据、26个来源、21种传感器,但与视觉语言基础模型的数据规模相比仍然有限。进一步聚合更大规模、更高质量、更多本体和更多传感器的触觉数据,是提升通用触觉策略上限的关键方向。
最后,当前触觉硬件生态仍然高度碎片化。FTP-1通过MTTS提供了一个统一接口,但如何覆盖未来更多传感器形态、动态触觉信息、滑移与微振动信号,仍需要社区继续探索。
总体而言,FTP-1给出了一个清晰信号:触觉不应只是视觉策略的附属输入,而可以成为基础机器人策略预训练的重要模态。随着触觉数据规模扩大、传感器接口统一、模型架构继续演进,通用触觉智能有望成为接触密集型机器人操作的核心基础能力。