深入拆解 AlexNet:跟着一张猫咪照片,看数据如何流动
一、概述:AlexNet 的横空出世与核心贡献
2012 年,Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在 ImageNet 图像识别大赛中提交的 AlexNet 模型,以 84.7% 的 Top-5 准确率碾压第二名的 73.8%,一举开启了深度学习在计算机视觉领域的黄金时代。这不仅是一次比赛的胜利,更是深度学习方法论的全面验证。
AlexNet 到底做了哪些革命性改善?
性能对比:AlexNet 与同期方法
AlexNet 的成功证明了:深度卷积神经网络在大规模数据上可以学习到具有层次化结构的特征表示,从底层的边缘纹理到高层的语义概念,这种"由粗到细"的特征提取范式至今仍是 CNN 设计的核心思想。
二、分论:跟着猫咪图片,一步一步走过 AlexNet
我们选取一张真实的猫咪图片,从像素级开始,逐步实现每一层,追踪它在 AlexNet 中经历的每一次变换。
bash
# 导入 PyTorch 核心库
import torch
# 导入 PyTorch 神经网络模块
import torch.nn as nn
# 导入 PyTorch 函数式接口(如激活函数、池化等)
import torch.nn.functional as F
# 导入 torchvision 中的图像变换工具
import torchvision.transforms as transforms
# 导入 PIL(Python Imaging Library)用于图像加载和处理
from PIL import Image
# 导入 matplotlib 用于数据可视化
import matplotlib.pyplot as plt
# 导入 numpy 用于数值计算
import numpy as np
# 在 Notebook 中直接显示 matplotlib 图像
%matplotlib inline
# 配置 matplotlib 使用中文字体(解决中文显示乱码问题)
# SimHei(黑体)、Microsoft YaHei(微软雅黑)、DejaVu Sans(备用)
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei', 'DejaVu Sans']
# 解决负号显示问题
plt.rcParams['axes.unicode_minus'] = False
# 猫咪图片的路径(从 ImageNet 数据集中选取的示例图片)
image_path = 'image/cat.10006.jpg'
# 使用 PIL 打开图片文件
img = Image.open(image_path)
# 打印图片信息:尺寸(宽度×高度)和模式(RGB)
print(f'原始图片尺寸: {img.size}, 模式: {img.mode}')
# 创建一个 8×6 英寸的绘图窗口
plt.figure(figsize=(8, 6))
# 在窗口中显示图片
plt.imshow(img)
# 设置图片标题
plt.title('原始猫咪图片', fontsize=16)
# 关闭坐标轴显示(让图片更整洁)
plt.axis('off')
# 显示图片
plt.show()
原始图片尺寸: (460, 320), 模式: RGB
添加图片注释,不超过 140 字(可选)
2.1 输入预处理:从 460×320 到 227×227
AlexNet 的输入要求是 227×227×3 的 RGB 图像。
-
缩放至 227×227
-
转换为张量(0-1 归一化)
-
使用 ImageNet 均值和标准差进行归一化
bash
# 定义图像预处理流水线
# Compose 将多个变换串联起来,按顺序执行
transform = transforms.Compose([
# 步骤1: 将图像缩放至 227×227(AlexNet 要求的输入尺寸)
transforms.Resize((227, 227)),
# 步骤2: 将 PIL 图像转换为 PyTorch 张量
# 转换后像素值从 0-255 归一化到 0-1
transforms.ToTensor(),
# 步骤3: 使用 ImageNet 数据集的均值和标准差进行归一化
# 均值 [0.485, 0.456, 0.406] 和标准差 [0.229, 0.224, 0.225]
# 归一化后像素值变为接近标准正态分布(均值0,标准差1)
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 对图片应用预处理,并添加 batch 维度
# transform(img) 返回形状为 (3, 227, 227) 的张量
# unsqueeze(0) 在第0维添加 batch 维度,形状变为 (1, 3, 227, 227)
x = transform(img).unsqueeze(0)
# 打印预处理后的张量形状
print(f'预处理后张量形状: {x.shape}')
# 单独缩放图片用于可视化(不做归一化,保持原始颜色)
img_resized = transforms.Resize((227, 227))(img)
# 创建一个包含1行2列子图的绘图窗口
fig, axes = plt.subplots(1, 2, figsize=(14, 6))
# 左子图:显示原始图片
axes[0].imshow(img)
axes[0].set_title(f'原始图片 ({img.size[0]}×{img.size[1]})', fontsize=14)
axes[0].axis('off')
# 右子图:显示缩放后的图片
axes[1].imshow(img_resized)
axes[1].set_title(f'缩放后图片 (227×227)', fontsize=14)
axes[1].axis('off')
# 自动调整子图间距
plt.tight_layout()
# 显示图片
plt.show()
预处理后张量形状: torch.Size([1, 3, 227, 227])
添加图片注释,不超过 140 字(可选)
2.2 网络总览:数据形状变化全表
在逐层拆解之前,先看一眼数据在整个网络中的形状变化轨迹:
2.3 第一站:Conv1 ------ 用粗粒度边缘捕捉器扫过整图
-
96 个 11×11 的卷积核,在 RGB 三个通道上同时滑动,步长为 4,不做填充(valid)。
-
每个卷积核输出一个 55×55 的特征图。
-
输出尺寸公式:(227−11)/4+1=55(227 - 11) / 4 + 1 = 55,所以是 55×55×96。
Conv1 使用 96 个卷积核,每个卷积核的形状是 11×11×3,即每个卷积核包含 3 个 11×11 的二维滤波器,分别对应输入的 R、G、B 三个通道。
假设我们取第 kk 个卷积核 WkW_k(形状为 11×11×3),在输入图像 XX(形状为 227×227×3)的某个位置 (i,j)(i,j) 处进行卷积:
-
通道 1(R 通道):卷积核的第 1 个滤波器 Wk:,:,0W_k:,:,0(11×11)与输入的 R 通道在位置 (i,j)(i,j) 处的 11×11 区域做逐元素相乘后求和,得到一个标量值 S1S_1。
-
通道 2(G 通道):卷积核的第 2 个滤波器 Wk:,:,1W_k:,:,1(11×11)与输入的 G 通道在位置 (i,j)(i,j) 处的 11×11 区域做逐元素相乘后求和,得到一个标量值 S2S_2。
-
通道 3(B 通道):卷积核的第 3 个滤波器 Wk:,:,2W_k:,:,2(11×11)与输入的 B 通道在位置 (i,j)(i,j) 处的 11×11 区域做逐元素相乘后求和,得到一个标量值 S3S_3。
-
跨通道融合:将三个通道的结果相加,再加上该卷积核的偏置 bkb_k:
Ok(i,j)=S1+S2+S3+bk=∑c=02∑p=010∑q=010Wkp,q,c⋅Xi+p,j+q,c+bkO_k(i,j) = S_1 + S_2 + S_3 + b_k = \sum_{c=0}^{2} \sum_{p=0}^{10} \sum_{q=0}^{10} W_kp,q,c \cdot Xi+p,j+q,c + b_k
- 滑动窗口:卷积核以步长 4 在输入图像上滑动,对每个位置重复上述计算,最终得到一个 55×55 的特征图。
-
每个卷积核参数:11×11×3 = 363(权重)+ 1(偏置)= 364
-
96 个卷积核总参数:96 × 364 = 34,944
每个卷积核就像一个"特征探测器",它在三个颜色通道上同时寻找特定的模式。例如,某个卷积核可能学会了检测"红色边缘"(在 R 通道上有强响应),另一个可能学会检测"绿色纹理",还有的可能学会检测"颜色对比度"(多个通道的差异)。
-
大核 + 大步长:11×11 是相当大的感受野,步长 4 则直接大幅缩小尺寸。这样第一层就能快速捕捉边缘、颜色块、简单纹理等底层特征。
-
96 个核:足够多的滤波器,分别学习不同方向的边缘、不同颜色模式等。
bash
# 第一层卷积(Conv1)
# nn.Conv2d(in_channels=3, out_channels=96, kernel_size=11, stride=4, padding=0)
# - in_channels=3: 输入通道数(RGB 三个通道)
# - out_channels=96: 输出通道数(96 个卷积核)
# - kernel_size=11: 卷积核大小(11×11)
# - stride=4: 步长(每次滑动4个像素)
# - padding=0: 不做填充
conv1 = nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0)
# 将输入张量 x 传入 Conv1
x = conv1(x)
# 输出形状: (1, 96, 55, 55),计算方式: (227 - 11) / 4 + 1 = 55
print(f'Conv1 输出形状: {x.shape}')
# ReLU 激活函数
# inplace=True: 原地操作,节省内存
# ReLU 的作用: f(x) = max(0, x),抛弃负值,引入非线性
relu1 = nn.ReLU(inplace=True)
x = relu1(x)
print(f'ReLU 后形状: {x.shape}')
# 局部响应归一化(LRN)
# size=5: 归一化窗口大小
# alpha=0.0001, beta=0.75, k=2: LRN 的超参数
# LRN 的作用: 对同一位置不同通道的激活值做跨通道抑制,模拟神经侧抑制
lrn1 = nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2)
x = lrn1(x)
print(f'LRN 后形状: {x.shape}')
# 最大池化(Pool1)
# kernel_size=3, stride=2: 3×3 窗口,步长 2
# 这是重叠池化(窗口 > 步长),能减轻过拟合
pool1 = nn.MaxPool2d(kernel_size=3, stride=2)
x = pool1(x)
# 输出形状: (1, 96, 27, 27),计算方式: (55 - 3) / 2 + 1 = 27
print(f'Pool1 输出形状: {x.shape}')
Conv1 输出形状: torch.Size([1, 96, 55, 55])
ReLU 后形状: torch.Size([1, 96, 55, 55])
LRN 后形状: torch.Size([1, 96, 55, 55])
Pool1 输出形状: torch.Size([1, 96, 27, 27])
# 特征图可视化函数
# 参数:
# x: 输入张量,形状为 (batch_size, num_channels, height, width)
# title: 图表标题
# num_maps: 要显示的特征图数量,默认16
# cols: 每行显示的列数,默认8
def visualize_feature_maps(x, title, num_maps=16, cols=8):
# 移除 batch 维度,转换为 numpy 数组
# squeeze(0): 移除第0维(batch维度)
# detach(): 从计算图中分离,不计算梯度
# cpu(): 移动到 CPU(如果在 GPU 上)
# numpy(): 转换为 numpy 数组
features = x.squeeze(0).detach().cpu().numpy()
# 计算行数:向上取整
rows = (num_maps + cols - 1) // cols
# 创建绘图窗口
fig, axes = plt.subplots(rows, cols, figsize=(cols * 2, rows * 2))
# 设置总标题
fig.suptitle(f'{title} ({features.shape[0]}个通道)', fontsize=16)
# 遍历要显示的特征图
for i in range(min(num_maps, features.shape[0])):
row = i // cols # 计算行索引
col = i % cols # 计算列索引
# 根据行数选择访问方式(单行或多行)
if rows == 1:
ax = axes[col]
else:
ax = axes[row, col]
# 显示特征图,使用 viridis 颜色映射
ax.imshow(features[i], cmap='viridis')
# 关闭坐标轴
ax.axis('off')
# 设置子图标题(通道索引)
ax.set_title(f'通道 {i}', fontsize=10)
# 如果特征图数量不够填满网格,关闭多余的子图
for i in range(min(num_maps, features.shape[0]), rows * cols):
row = i // cols
col = i % cols
if rows == 1:
axes[col].axis('off')
else:
axes[row, col].axis('off')
# 调整子图间距,留出标题空间
plt.tight_layout(rect=[0, 0, 1, 0.95])
# 显示图片
plt.show()
# 调用可视化函数,显示 Pool1 后的特征图
visualize_feature_maps(x, 'Pool1 特征图(Conv1 + ReLU + LRN + Pool 后)')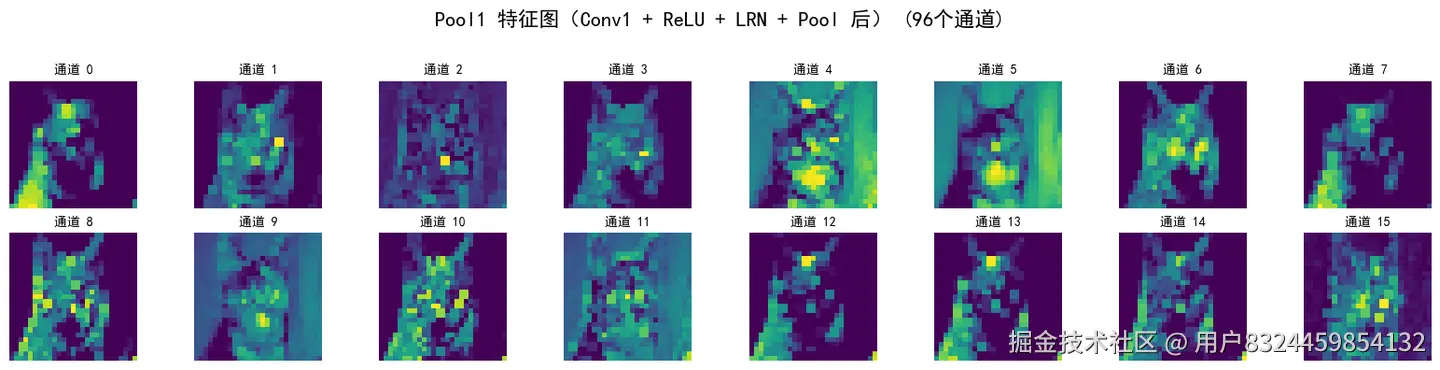
添加图片注释,不超过 140 字(可选)
2.4 第二站:Conv2 ------ 组合出更复杂的局部模式
-
256 个 5×5 卷积核,步长 1,填充 2(保持空间尺寸不变)。
-
输出尺寸:(27−5+2×2)/1+1=27(27 - 5 + 2×2) / 1 + 1 = 27,即 27×27×256。
-
同样经过 ReLU → LRN → 最大池化 (3×3, stride 2),池化后尺寸变为 (27−3)/2+1=13(27-3)/2+1 = 13,得到 13×13×256。
-
更小的卷积核可以捕捉更精细的纹理组合,比如由边缘组成的角点、曲线。
bash
# 第二层卷积(Conv2)
# nn.Conv2d(in_channels=96, out_channels=256, kernel_size=5, stride=1, padding=2)
# - in_channels=96: 输入通道数(Conv1 的输出通道数)
# - out_channels=256: 输出通道数(256 个卷积核)
# - kernel_size=5: 卷积核大小(5×5),比第一层小,捕捉更精细的特征
# - stride=1: 步长为1,逐像素滑动
# - padding=2: 填充2圈,保持空间尺寸不变
conv2 = nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2)
x = conv2(x)
# 输出形状: (1, 256, 27, 27),计算方式: (27 - 5 + 2×2) / 1 + 1 = 27
print(f'Conv2 输出形状: {x.shape}')
# ReLU 激活函数
relu2 = nn.ReLU(inplace=True)
x = relu2(x)
print(f'ReLU 后形状: {x.shape}')
# 局部响应归一化(LRN)
lrn2 = nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2)
x = lrn2(x)
print(f'LRN 后形状: {x.shape}')
# 最大池化(Pool2)
pool2 = nn.MaxPool2d(kernel_size=3, stride=2)
x = pool2(x)
# 输出形状: (1, 256, 13, 13),计算方式: (27 - 3) / 2 + 1 = 13
print(f'Pool2 输出形状: {x.shape}')
# 可视化 Pool2 后的特征图
visualize_feature_maps(x, 'Pool2 特征图(Conv2 + ReLU + LRN + Pool 后)')
Conv2 输出形状: torch.Size([1, 256, 27, 27])
ReLU 后形状: torch.Size([1, 256, 27, 27])
LRN 后形状: torch.Size([1, 256, 27, 27])
Pool2 输出形状: torch.Size([1, 256, 13, 13])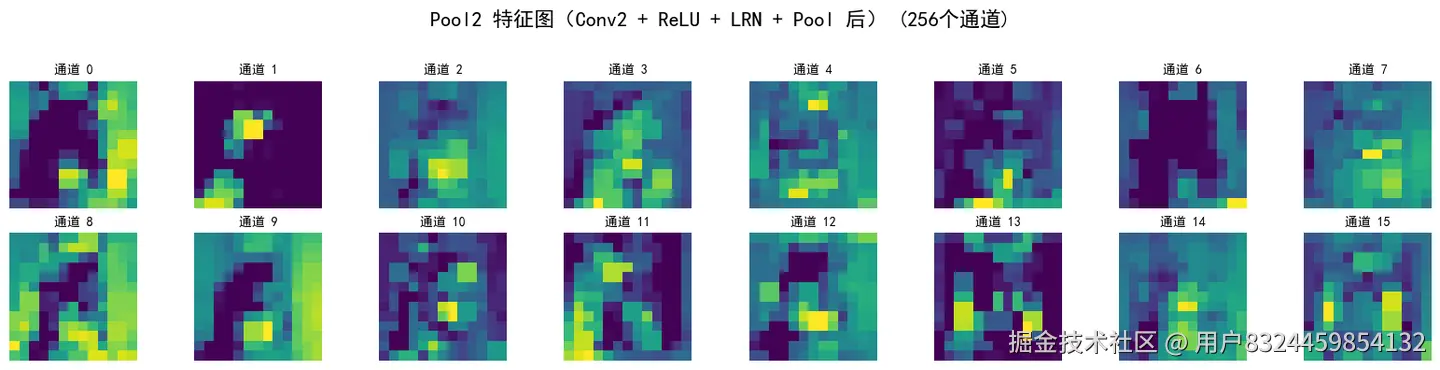
添加图片注释,不超过 140 字(可选)
2.5 第三站:Conv3 ------ 深度叠加,提取语义
-
384 个 3×3 卷积核,步长 1,填充 1(保持空间尺寸不变)。
-
输出尺寸:(13−3+2×1)/1+1=13(13 - 3 + 2×1) / 1 + 1 = 13,即 13×13×384。
-
ReLU 激活,无 LRN,无池化。
关键变化:从这一层开始,两个 GPU 的输出终于全连接------每个 3×3 卷积核都会同时看到所有通道。
bash
# 第三层卷积(Conv3)
# nn.Conv2d(in_channels=256, out_channels=384, kernel_size=3, stride=1, padding=1)
# - kernel_size=3: 使用 3×3 小卷积核,捕捉更精细的空间结构
# - stride=1, padding=1: 保持空间尺寸不变
conv3 = nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1)
x = conv3(x)
# 输出形状: (1, 384, 13, 13),计算方式: (13 - 3 + 2×1) / 1 + 1 = 13
print(f'Conv3 输出形状: {x.shape}')
# ReLU 激活函数
relu3 = nn.ReLU(inplace=True)
x = relu3(x)
print(f'ReLU 后形状: {x.shape}')
# 可视化 Conv3 后的特征图(无 LRN,无池化)
visualize_feature_maps(x, 'Conv3 特征图(Conv3 + ReLU 后)')
Conv3 输出形状: torch.Size([1, 384, 13, 13])
ReLU 后形状: torch.Size([1, 384, 13, 13])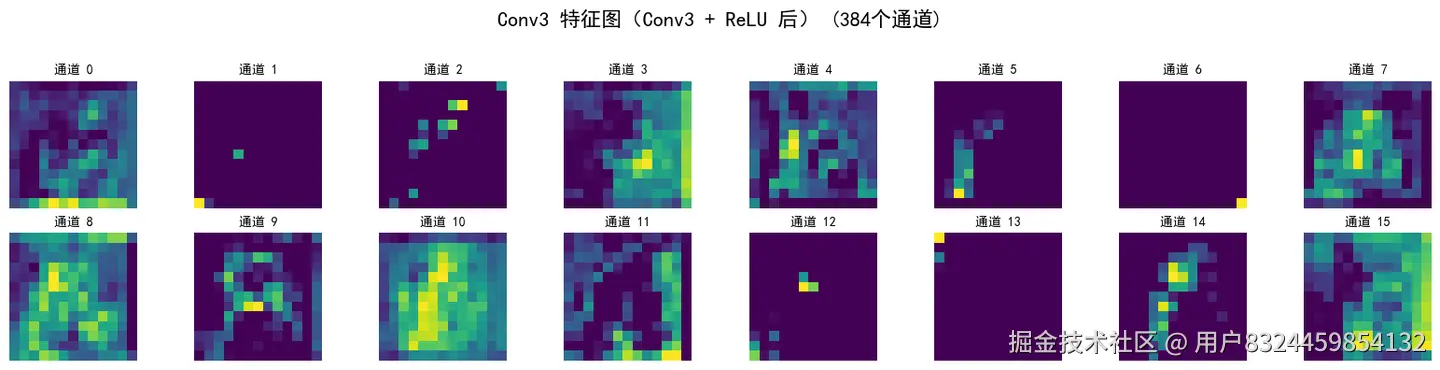
添加图片注释,不超过 140 字(可选)
2.6 第四站:Conv4 ------ 继续深度叠加
-
384 个 3×3 卷积核,步长 1,填充 1。
-
输出尺寸保持 13×13×384 不变。
-
又恢复分组卷积,两组各看到 192 通道。
-
ReLU,无池化。
bash
# 第四层卷积(Conv4)
# nn.Conv2d(in_channels=384, out_channels=384, kernel_size=3, stride=1, padding=1)
# - 输入输出通道数相同,继续在 384 维特征空间中提取特征
conv4 = nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1)
x = conv4(x)
# 输出形状: (1, 384, 13, 13),保持不变
print(f'Conv4 输出形状: {x.shape}')
# ReLU 激活函数
relu4 = nn.ReLU(inplace=True)
x = relu4(x)
print(f'ReLU 后形状: {x.shape}')
# 可视化 Conv4 后的特征图
visualize_feature_maps(x, 'Conv4 特征图(Conv4 + ReLU 后)')
Conv4 输出形状: torch.Size([1, 384, 13, 13])
ReLU 后形状: torch.Size([1, 384, 13, 13])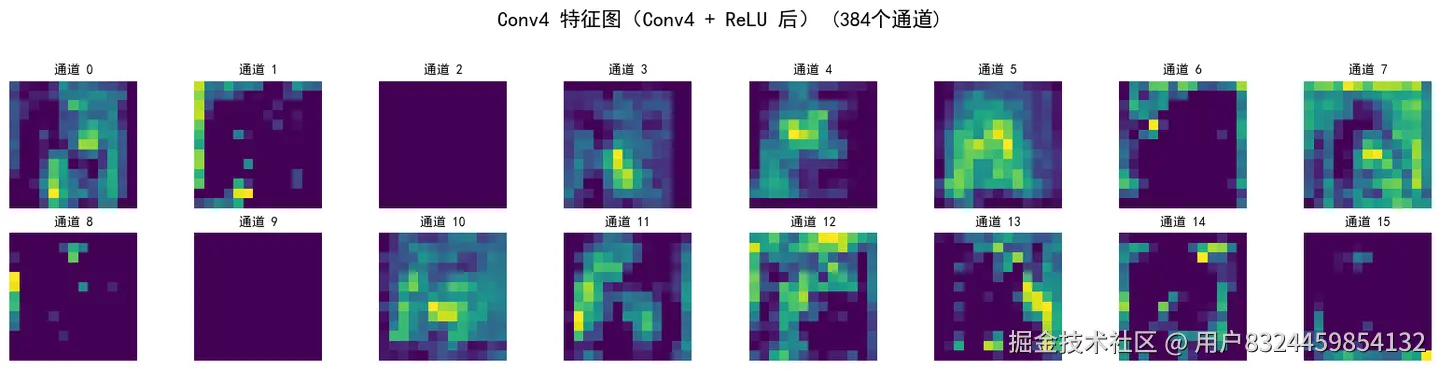
添加图片注释,不超过 140 字(可选)
2.7 第五站:Conv5 + Pool5 ------ 最后一层卷积
-
256 个 3×3 卷积核,步长 1,填充 1。
-
输出尺寸保持 13×13×256。
-
ReLU 后接 最大池化 (3×3, stride 2),输出尺寸 (13−3)/2+1=6(13-3)/2+1 = 6,得到 6×6×256。
-
3×3 是捕捉最小空间结构(方向、交点等)的核,多层 3×3 卷积堆叠可等价于更大感受野(两层 3×3 等价一层 5×5),而参数更少、非线性更强,能学到更复杂的语义级概念。
至此,猫咪图被提炼成 6×6 空间网格上的 256 维特征向量。
bash
# 第五层卷积(Conv5)
# nn.Conv2d(in_channels=384, out_channels=256, kernel_size=3, stride=1, padding=1)
# - 将通道数从 384 减少到 256,为全连接层做准备
conv5 = nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1)
x = conv5(x)
# 输出形状: (1, 256, 13, 13)
print(f'Conv5 输出形状: {x.shape}')
# ReLU 激活函数
relu5 = nn.ReLU(inplace=True)
x = relu5(x)
print(f'ReLU 后形状: {x.shape}')
# 可视化 Conv5 后的特征图
visualize_feature_maps(x, 'Conv5 特征图(Conv5 + ReLU 后)')
# 最大池化(Pool5)------ 最后一层池化
pool5 = nn.MaxPool2d(kernel_size=3, stride=2)
x = pool5(x)
# 输出形状: (1, 256, 6, 6),计算方式: (13 - 3) / 2 + 1 = 6
print(f'Pool5 输出形状: {x.shape}')
# 可视化 Pool5 后的特征图
visualize_feature_maps(x, 'Pool5 特征图(最后一层池化后)')
Conv5 输出形状: torch.Size([1, 256, 13, 13])
ReLU 后形状: torch.Size([1, 256, 13, 13])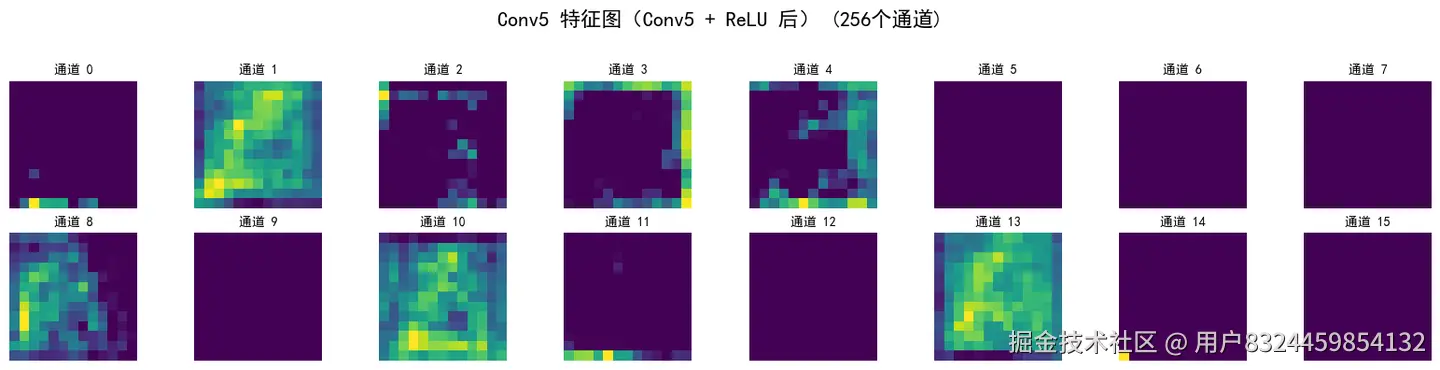
添加图片注释,不超过 140 字(可选)
bash
Pool5 输出形状: torch.Size([1, 256, 6, 6])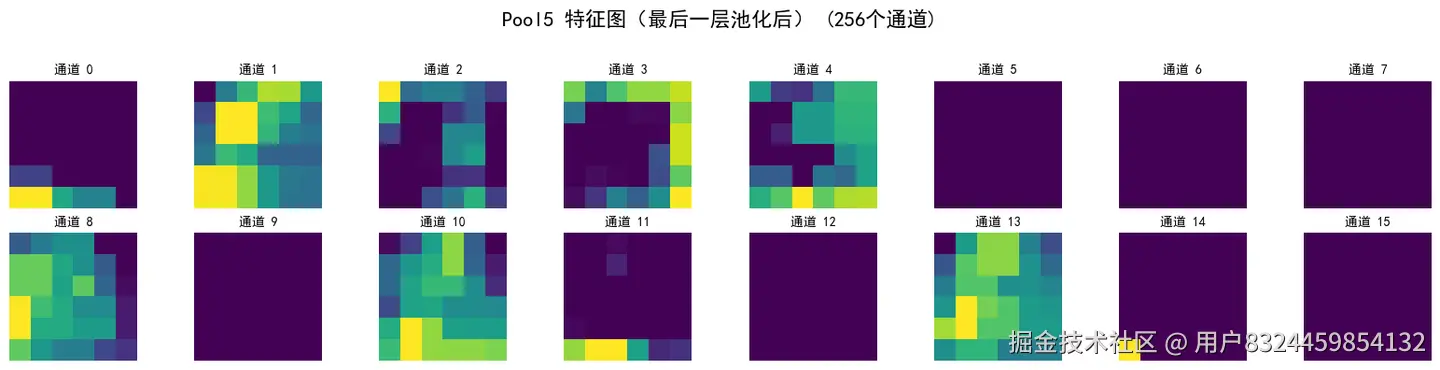
添加图片注释,不超过 140 字(可选)
2.8 第六站:展平 + 全连接 ------ 从局部特征到全局判断
展平: 将 Conv5 的池化输出 6×6×256 = 9216 个神经元拉成一条一维向量,送入全连接网络。
bash
# 展平操作:将 4 维张量转换为 2 维张量
# x.size(0): 保持 batch 维度不变(这里是 1)
# -1: 自动计算剩余维度,将 6×6×256 展平为 9216
# 输入形状: (1, 256, 6, 6) → 输出形状: (1, 9216)
x = x.view(x.size(0), -1)
# 打印展平后的向量长度
print(f'展平后的向量长度: {x.shape[1]}')
# 验证计算:6 × 6 × 256 = 9216
print(f'计算验证: 6 × 6 × 256 = {6 * 6 * 256}')
# 创建热力图可视化展平后的特征向量
fig, ax = plt.subplots(figsize=(12, 2))
# 将张量转换为 numpy 数组并显示
ax.imshow(x.detach().cpu().numpy(), cmap='viridis', aspect='auto')
ax.set_title('展平后的特征向量', fontsize=14)
ax.set_xlabel('特征维度', fontsize=12)
ax.set_ylabel('样本', fontsize=12)
plt.show()
展平后的向量长度: 9216
计算验证: 6 × 6 × 256 = 9216
添加图片注释,不超过 140 字(可选)
FC6
- 9216 → 4096 维,全连接 + ReLU + Dropout(0.5)。
为什么要用巨大的 4096? 全连接层是整个网络中参数最爆炸的地方(FC6 参数就高达 9216×4096 ≈ 37M),但它承担了最关键的任务:把散布在 6×6 网格上的所有局部语义特征整合起来,形成全局的表征。
Dropout 为什么是 0.5? 4096 维的超大向量极易过拟合。训练时随机关闭一半神经元,强迫网络学习冗余而鲁棒的特征。
bash
# 第六层:全连接层 FC6
# nn.Linear(in_features=9216, out_features=4096)
# - in_features=256*6*6=9216: 展平后的特征维度
# - out_features=4096: 输出维度(4096 个神经元)
# 参数数量: 9216 × 4096 ≈ 37M
fc6 = nn.Linear(256 * 6 * 6, 4096)
x = fc6(x)
# 输出形状: (1, 4096)
print(f'FC6 输出形状: {x.shape}')
# ReLU 激活函数
relu6 = nn.ReLU(inplace=True)
x = relu6(x)
print(f'ReLU 后形状: {x.shape}')
# Dropout(0.5):以 0.5 的概率随机丢弃神经元
# 作用:防止过拟合,强迫网络学习冗余而鲁棒的特征
dropout6 = nn.Dropout(0.5)
x = dropout6(x)
print(f'Dropout 后形状: {x.shape}')
# 创建可视化:热力图 + 柱状图
fig, axes = plt.subplots(2, 1, figsize=(12, 5))
# 热力图:展示所有 4096 个神经元的激活值
axes[0].imshow(x.detach().cpu().numpy(), cmap='viridis', aspect='auto')
axes[0].set_title('FC6 全连接层输出(热力图)', fontsize=14)
axes[0].set_ylabel('样本', fontsize=12)
# 柱状图:展示前 100 个神经元的激活值
axes[1].bar(range(100), x[0, :100].detach().cpu().numpy())
axes[1].set_title('FC6 前 100 个神经元激活值', fontsize=14)
axes[1].set_xlabel('神经元索引', fontsize=12)
axes[1].set_ylabel('激活值', fontsize=12)
# 自动调整子图间距
plt.tight_layout()
plt.show()
FC6 输出形状: torch.Size([1, 4096])
ReLU 后形状: torch.Size([1, 4096])
Dropout 后形状: torch.Size([1, 4096])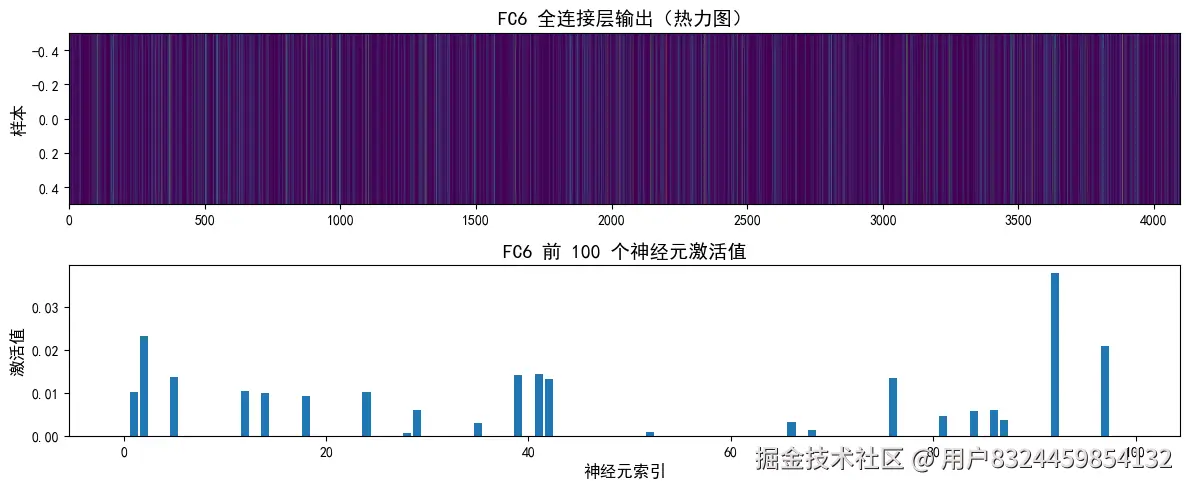
添加图片注释,不超过 140 字(可选)
FC7
- 4096 → 4096 维,全连接 + ReLU + Dropout(0.5)。
这一层继续对特征进行非线性变换,进一步提炼高级语义信息。
bash
# 第七层:全连接层 FC7
# nn.Linear(in_features=4096, out_features=4096)
# - 输入输出维度相同(4096),继续提炼高级语义特征
# 参数数量: 4096 × 4096 ≈ 16M
fc7 = nn.Linear(4096, 4096)
x = fc7(x)
# 输出形状: (1, 4096)
print(f'FC7 输出形状: {x.shape}')
# ReLU 激活函数
relu7 = nn.ReLU(inplace=True)
x = relu7(x)
print(f'ReLU 后形状: {x.shape}')
# Dropout(0.5)
dropout7 = nn.Dropout(0.5)
x = dropout7(x)
print(f'Dropout 后形状: {x.shape}')
# 可视化 FC7 输出
fig, ax = plt.subplots(figsize=(12, 2))
ax.imshow(x.detach().cpu().numpy(), cmap='viridis', aspect='auto')
ax.set_title('FC7 全连接层输出', fontsize=14)
ax.set_xlabel('神经元索引', fontsize=12)
ax.set_ylabel('样本', fontsize=12)
plt.show()
FC7 输出形状: torch.Size([1, 4096])
ReLU 后形状: torch.Size([1, 4096])
Dropout 后形状: torch.Size([1, 4096])
添加图片注释,不超过 140 字(可选)
FC8(输出层)
- 4096 → 1000 维,全连接 + Softmax,对应 ImageNet 的 1000 个类别。
经过 Softmax,我们得到 1000 个概率值,每个值代表输入图像属于对应类别的概率。
bash
# 第八层:全连接层 FC8(输出层)
# nn.Linear(in_features=4096, out_features=1000)
# - out_features=1000: 对应 ImageNet 的 1000 个类别
# 参数数量: 4096 × 1000 ≈ 4M
fc8 = nn.Linear(4096, 1000)
x = fc8(x)
# 输出形状: (1, 1000)
print(f'FC8 输出形状: {x.shape}')
# Softmax 激活函数:将输出转换为概率分布
# dim=1: 在 batch 维度上进行 Softmax
# Softmax 的作用: 将任意实数转换为 0-1 之间的概率,且所有概率之和为 1
softmax = nn.Softmax(dim=1)
output = softmax(x)
print(f'Softmax 后形状: {output.shape}')
# 获取预测概率最高的前 5 个类别
# torch.topk: 返回前 k 个最大值及其索引
top5_prob, top5_idx = torch.topk(output, 5)
# 打印 Top 5 预测结果
print()
print('预测结果(Top 5):')
print('=' * 40)
for i in range(5):
# top5_idx[0][i].item(): 获取第 i 名的类别索引
# top5_prob[0][i].item(): 获取第 i 名的概率
print(f'第{i+1}名: 类别 {top5_idx[0][i].item()}, 概率: {top5_prob[0][i].item():.4f}')
# 可视化前 20 个类别的概率
fig, ax = plt.subplots(figsize=(10, 5))
ax.bar(range(20), output[0, :20].detach().cpu().numpy(), color='skyblue')
ax.set_title('FC8 输出层前 20 个类别概率', fontsize=14)
ax.set_xlabel('类别索引', fontsize=12)
ax.set_ylabel('概率', fontsize=12)
plt.show()
FC8 输出形状: torch.Size([1, 1000])
Softmax 后形状: torch.Size([1, 1000])
预测结果(Top 5):
========================================
第1名: 类别 690, 概率: 0.0010
第2名: 类别 686, 概率: 0.0010
第3名: 类别 352, 概率: 0.0010
第4名: 类别 494, 概率: 0.0010
第5名: 类别 787, 概率: 0.0010
添加图片注释,不超过 140 字(可选)
2.9 数据形状变化一览
bash
# 打印数据形状变化完整轨迹
# 帮助读者回顾整个网络中数据形状的变化过程
print('数据形状变化完整轨迹:')
print('=' * 60)
# 输入图像: 227×227×3(RGB 三通道)
print(f'{"输入图像":<10}: {"(227, 227, 3)":<20}')
# Conv1: 11×11 卷积,步长4,无填充 → 55×55×96
print(f'{"Conv1":<10}: {"(55, 55, 96)":<20} # 11x11 conv, s4, valid')
# Pool1: 3×3 最大池化,步长2 → 27×27×96
print(f'{"Pool1":<10}: {"(27, 27, 96)":<20} # 3x3 max pool, s2')
# Conv2: 5×5 卷积,步长1,填充2 → 27×27×256(保持空间尺寸)
print(f'{"Conv2":<10}: {"(27, 27, 256)":<20} # 5x5 conv, s1, p2')
# Pool2: 3×3 最大池化,步长2 → 13×13×256
print(f'{"Pool2":<10}: {"(13, 13, 256)":<20} # 3x3 max pool, s2')
# Conv3: 3×3 卷积,步长1,填充1 → 13×13×384(保持空间尺寸)
print(f'{"Conv3":<10}: {"(13, 13, 384)":<20} # 3x3 conv, s1, p1')
# Conv4: 3×3 卷积,步长1,填充1 → 13×13×384(保持空间尺寸)
print(f'{"Conv4":<10}: {"(13, 13, 384)":<20} # 3x3 conv, s1, p1')
# Conv5: 3×3 卷积,步长1,填充1 → 13×13×256(保持空间尺寸)
print(f'{"Conv5":<10}: {"(13, 13, 256)":<20} # 3x3 conv, s1, p1')
# Pool5: 3×3 最大池化,步长2 → 6×6×256
print(f'{"Pool5":<10}: {"( 6, 6, 256)":<20} # 3x3 max pool, s2')
# 展平: 6×6×256 = 9216 → 一维向量
print(f'{"展平":<10}: {"(9216,)":<20} # 6*6*256')
# FC6: 全连接层,9216 → 4096
print(f'{"FC6":<10}: {"(4096,)":<20}')
# FC7: 全连接层,4096 → 4096
print(f'{"FC7":<10}: {"(4096,)":<20}')
# FC8: 输出层,4096 → 1000(1000 个类别概率)
print(f'{"FC8":<10}: {"(1000,)":<20} # 各类别概率')三、总论:AlexNet 的设计哲学与深远影响
3.1 为什么这么设计?------ AlexNet 的设计哲学
- ReLU 替代 tanh/sigmoid
非饱和非线性,极大加速收敛,告别梯度消失。这是 AlexNet 成功的关键技术之一。
- 重叠池化与数据增强
随机裁剪、水平翻转、PCA 颜色扰动,相当于免费增加了成千上万倍的训练样本;重叠池化进一步抑制过拟合。
- Dropout
在全连接层中以 0.5 概率随机丢弃神经元,打破复杂共适应,显著提升泛化能力。
- 分组卷积
受限于显存而生的工程折衷,却意外带来了正则化效果,让两组 GPU 学到互补的滤波器。
- 从大到小的卷积核设计
先 11×11 大视野捕捉基本元素,再 5×5 组合成局部模式,最后多层 3×3 提取高级语义------这种"由粗糙到精细"的金字塔结构至今仍是 CNN 设计的核心思想。
3.2 AlexNet 的性能表现
3.3 对后世的深远影响
虽然今天 ResNet、Transformer 等架构早已大幅超越它,但 AlexNet 中几乎每一个设计点------ReLU、Dropout、重叠池化、小卷积堆叠------都为后世网络铺好了基石:
-
VGG 继承了小卷积核堆叠的思想,用 16-19 层 3×3 卷积取得更好效果
-
GoogleNet 借鉴了分组卷积的思路,设计了 Inception 模块
-
ResNet 延续了深度网络的探索,用残差连接解决了更深网络的训练难题
-
现代 CNN 几乎都采用了 ReLU 激活和 Dropout 正则化
3.4 结语
跟着一张猫咪图片,我们走完了 AlexNet 从像素到"猫"的全流程。理解 AlexNet,就是读懂了当代视觉 AI 的序章。那些冷冰冰的数字背后,是深度学习从理论走向实践的坚实一步。
现在,如果你找一张猫咪照片,手动代入这个 227→55→27→13→6 的尺寸变化,是否会觉得,一只若隐若现的猫正在逐渐浮现呢?
附录:完整网络结构代码
下面是 AlexNet 的完整 PyTorch 实现,将所有层整合到一个 nn.Module 中:
bash
# 导入 PyTorch 核心库和神经网络模块
import torch
import torch.nn as nn
class AlexNet(nn.Module):
"""
AlexNet 完整实现
参考论文: ImageNet Classification with Deep Convolutional Neural Networks
作者: Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton
AlexNet 网络结构(8层):
- 卷积层: Conv1 → Conv2 → Conv3 → Conv4 → Conv5
- 全连接层: FC6 → FC7 → FC8(输出层)
输入: 227×227×3 RGB 图像
输出: 1000 个类别的概率分布
"""
def __init__(self, num_classes=1000):
"""
初始化 AlexNet 网络
参数:
num_classes: 输出类别数量,默认为 1000(ImageNet 数据集)
"""
super(AlexNet, self).__init__()
# 卷积层部分:使用 nn.Sequential 容器组织
# 负责从图像中提取特征,输出形状: (batch, 256, 6, 6)
self.features = nn.Sequential(
# Conv1: 11x11 卷积, 步长 4, 无填充
# 输入: (batch, 3, 227, 227) → 输出: (batch, 96, 55, 55)
nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=0),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # → (batch, 96, 27, 27)
# Conv2: 5x5 卷积, 步长 1, 填充 2(保持空间尺寸)
# 输入: (batch, 96, 27, 27) → 输出: (batch, 256, 27, 27)
nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),
nn.ReLU(inplace=True),
nn.LocalResponseNorm(size=5, alpha=0.0001, beta=0.75, k=2),
nn.MaxPool2d(kernel_size=3, stride=2), # → (batch, 256, 13, 13)
# Conv3: 3x3 卷积, 步长 1, 填充 1(保持空间尺寸)
# 输入: (batch, 256, 13, 13) → 输出: (batch, 384, 13, 13)
nn.Conv2d(256, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# Conv4: 3x3 卷积, 步长 1, 填充 1(保持空间尺寸)
# 输入: (batch, 384, 13, 13) → 输出: (batch, 384, 13, 13)
nn.Conv2d(384, 384, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
# Conv5: 3x3 卷积, 步长 1, 填充 1(保持空间尺寸)
# 输入: (batch, 384, 13, 13) → 输出: (batch, 256, 13, 13)
nn.Conv2d(384, 256, kernel_size=3, stride=1, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2), # → (batch, 256, 6, 6)
)
# 全连接层部分:使用 nn.Sequential 容器组织
# 负责将提取的特征映射到分类结果
self.classifier = nn.Sequential(
# FC6: 将展平后的特征(9216维)映射到 4096 维
nn.Linear(256 * 6 * 6, 4096), # 256*6*6 = 9216
nn.ReLU(inplace=True),
nn.Dropout(0.5), # 随机丢弃 50% 的神经元,防止过拟合
# FC7: 继续非线性变换,保持 4096 维
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Dropout(0.5),
# FC8: 输出层,映射到 num_classes 个类别
nn.Linear(4096, num_classes),
)
# 初始化权重参数
self._initialize_weights()
def _initialize_weights(self):
"""
初始化权重参数
- 卷积层: 使用 Kaiming 正态初始化(ReLU 激活函数推荐)
- 全连接层: 使用标准差为 0.01 的正态初始化
- 偏置项: 初始化为 0
"""
for m in self.modules():
if isinstance(m, nn.Conv2d):
# Kaiming 初始化(针对 ReLU 激活函数优化)
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
if m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
# 正态分布初始化,标准差为 0.01(论文中的设置)
nn.init.normal_(m.weight, 0, 0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
"""
前向传播函数
参数:
x: 输入张量,形状为 (batch_size, 3, 227, 227)
返回:
输出张量,形状为 (batch_size, num_classes)
"""
# 经过卷积层提取特征
x = self.features(x)
# 展平操作:将 4 维张量转换为 2 维张量
x = x.view(x.size(0), -1)
# 经过全连接层进行分类
x = self.classifier(x)
return x
# ============================================
# 创建模型实例并统计参数
# ============================================
# 创建 AlexNet 模型实例
alexnet = AlexNet(num_classes=1000)
print('AlexNet 模型创建完成')
# 计算并打印模型总参数量
# sum(p.numel() for p in alexnet.parameters()): 遍历所有参数并求和
# numel(): 返回张量的元素个数
print(f'模型总参数量: {sum(p.numel() for p in alexnet.parameters()):,}')
# 详细统计每一层的参数数量
print()
print('参数统计:')
print('=' * 50)
total_params = 0
for name, param in alexnet.named_parameters():
param_count = param.numel()
total_params += param_count
print(f'{name:<30}: {param_count:,} 个参数')
print('=' * 50)
print(f'{"总计":<30}: {total_params:,} 个参数')