刚换一套数据库,先别急着看复杂语法。日常开发里最先撞上的,往往还是那些普通条件:=、<>、like、in、between、is null、order by、limit、group by。这些东西看起来简单,真到迁移 SQL 或排查接口数据时,反而最容易因为"应该差不多"而少看一眼。
这次用一张很小的测试表,把常见查询条件集中跑一遍。环境是已经初始化好的 app_db,表放在 app_schema 下。当前实例初始化时启用了 --enable-ci,所以大小写相关的结果只按当前环境记录,不能直接拿去推所有安装模式。
先准备一批够用的数据
测试表叫 app_schema.t_filter_demo。字段没有故意设计得复杂,name 放名称,category 放分类,status 放状态,score 和 price 用来做范围、排序和聚合,remark 专门留给 NULL 判断。
数据一共 12 行,里面混了几类东西:mysql、Kingbase、sql、oracle、pgsql;状态有 online、offline、draft;name 里故意放了 MySQL-basic、mysql-limit、MYSQL-LIKE 这种大小写不同的值。score 有一行是 NULL,remark 有 4 行是 NULL。后面的每个查询都靠这批数据说话。
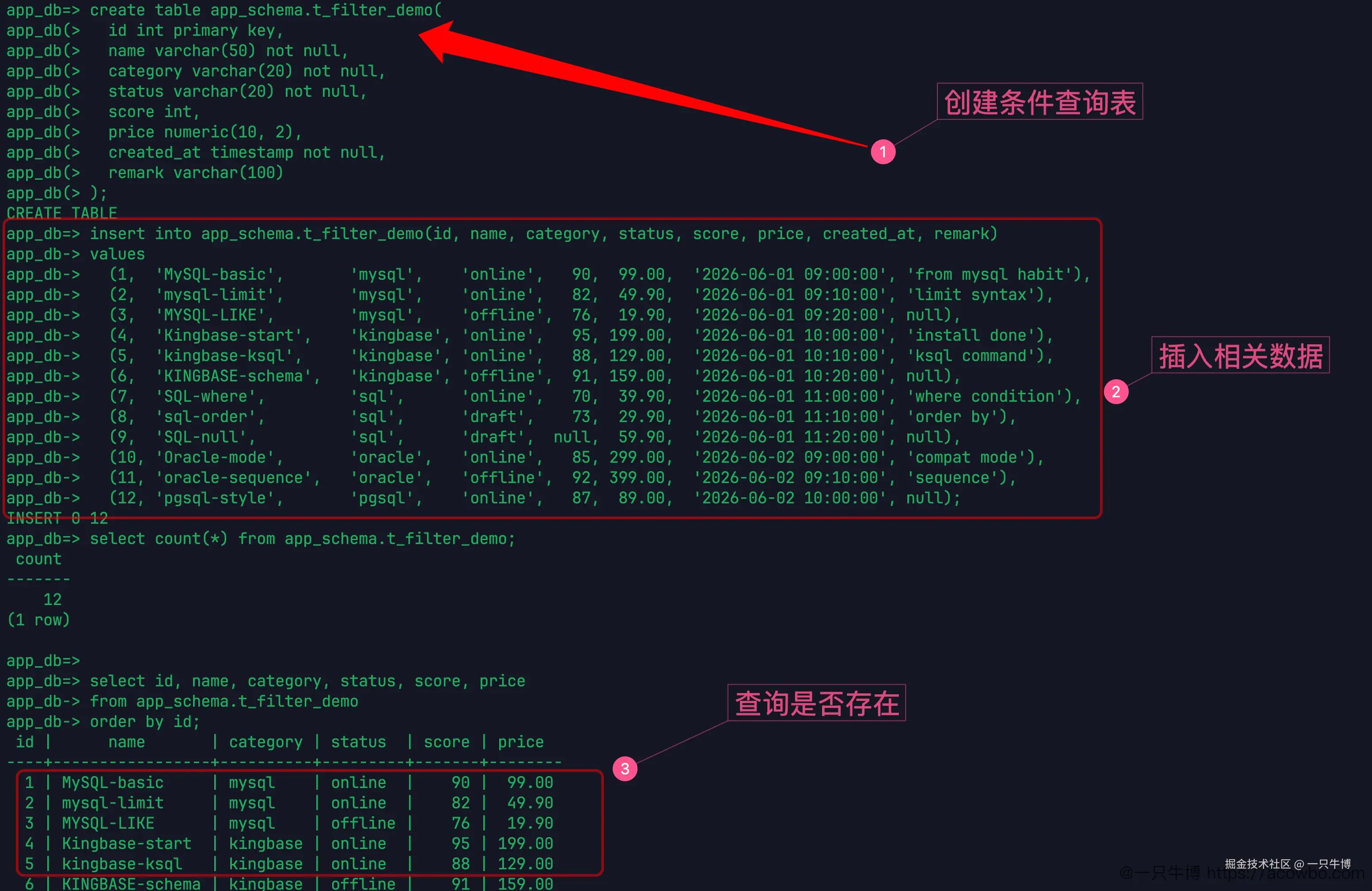
这张表不是业务模型,只是为了把查询条件喂饱。比如 category 适合看 in 和 group by,status 适合看不等值和分组统计,score 适合看 between、排序和聚合函数,remark 适合看 NULL 的判断方式。
终端提示符是 app_db=>,说明当前连接库是 app_db,当前用户不是管理员提示符下常见的 #。这类小信息平时容易忽略,但写查询实验时很有用,至少能先确认没有连到安装时的 test 库,也没有继续用 system 做所有操作。
等值和不等值先确认
最普通的等值查询没有悬念:
sql
select id, name, category, status, score
from app_schema.t_filter_demo
where category = 'mysql'
order by id;返回的是 1、2、3 三行,正好都是 mysql 分类。这里先把最基础的 where category = 'mysql' 跑通,后面再叠更多条件。
不等值用了两种写法:
sql
where status <> 'online'以及:
sql
where status != 'online'两次返回结果一致,都是 3、6、8、9、11 这 5 行,也就是 offline 和 draft 状态的数据。当前环境下,<> 和 != 都能用。写迁移脚本时,如果原来的 MySQL SQL 里用了 !=,至少这个场景下没有直接卡住。
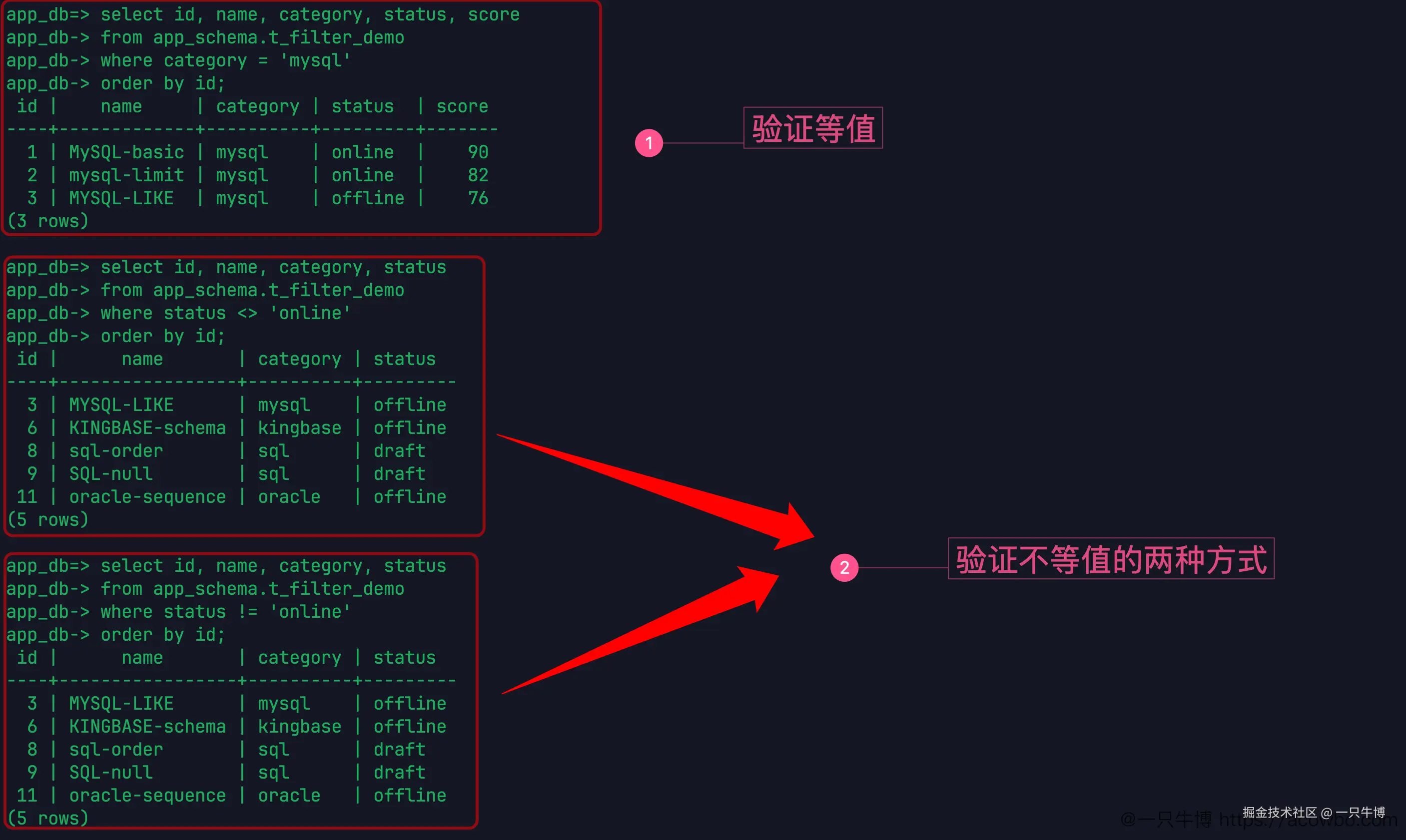
不过长期写 SQL,<> 仍然更接近标准写法;!= 更像从 MySQL 使用习惯带过来的写法。能不能用是一回事,团队里怎么统一又是另一回事。
这里还顺手确认了一点:status <> 'online' 返回的是所有非 online 的明确值,不会把 NULL 混进来。当前测试表的 status 字段是 not null,所以结果很好读。如果业务表里状态字段允许 NULL,不等值条件就要重新检查,不能想当然把 NULL 当成"不是 online"。
AND、OR 最怕括号省掉
组合条件先看 and:
sql
select id, name, category, status, score
from app_schema.t_filter_demo
where category = 'Kingbase'
and status = 'online'
order by id;返回 4、5 两行。表里 category 存的是 kingbase,查询里写的是 Kingbase,当前环境仍然匹配到了。这个现象和前面提到的 --enable-ci 有关系,大小写不敏感不是随口假设出来的,是这次查询结果里能看到的。
再把 or 加进来:
sql
where (category = 'mysql' or category = 'Kingbase')
and status = 'online'返回 1、2、4、5 四行。这里括号不能省。没有括号时,读 SQL 的人要在脑子里重新算 and、or 的优先级;有括号时,条件分组直接写在语句里。

从 MySQL 迁过来的 SQL,大量筛选条件都长这样:一个主条件,再叠几个状态、分类、时间范围。KingbaseES 能跑这些基本条件不稀奇,真正要养成的是把复杂条件写得不含糊。尤其是 or 混在一串 and 里时,括号比解释更可靠。
LIKE 的大小写表现要实测
LIKE 这里特意用了大小写不一样的名称。先排除名字里包含 sql 的数据:
sql
select id, name, category
from app_schema.t_filter_demo
where name not like '%sql%'
order by id;返回 4、6、10、11 四行。Kingbase-start、KINGBASE-schema、Oracle-mode、oracle-sequence 都没有被 %sql% 匹配到。
接着分别查:
sql
where name like 'MYSQL%'和:
sql
where name like 'mysql%'两次结果都是 1、2、3 三行:MySQL-basic、mysql-limit、MYSQL-LIKE。这说明当前实例里,LIKE 对这批字符比较是大小写不敏感的。

这里不要把结论写大。只能说当前环境、当前初始化方式下,MYSQL% 和 mysql% 查出来一致。如果换成没有启用大小写不敏感的实例,或者换字符集、排序规则,应该重新跑一遍。迁移 MySQL 的时候,LIKE 往往藏在搜索接口里,大小写表现最好提前确认。
还有一个细节:not like '%sql%' 把 MySQL-basic、mysql-limit、MYSQL-LIKE、SQL-where、sql-order、SQL-null 都排除了。这个结果比只看 like 'mysql%' 更能暴露大小写影响,因为 %sql% 在字符串中间匹配,MySQL 里的 SQL 也被算进去了。
IN、NOT IN、BETWEEN 都比较顺
IN 适合替代一串 or。这次查 mysql 和 Kingbase 两类:
sql
select id, name, category, status
from app_schema.t_filter_demo
where category in ('mysql', 'Kingbase')
order by category, id;返回 6 行,包括 3 行 kingbase 和 3 行 mysql。同样,因为当前环境大小写不敏感,Kingbase 能匹配到表里的 kingbase。
反过来用 not in,结果就是剩下的 oracle、pgsql、sql 三类,共 6 行。
范围条件用了 between 85 and 95:
sql
select id, name, score, price
from app_schema.t_filter_demo
where score between 85 and 95
order by score desc, id;返回 7 行,包含 95,也包含 85。between 的边界是包含两端的,这一点和 MySQL 里常见理解一致。结果按 score desc, id 排序后,最高分是 Kingbase-start 的 95,最低一行是 Oracle-mode 的 85。
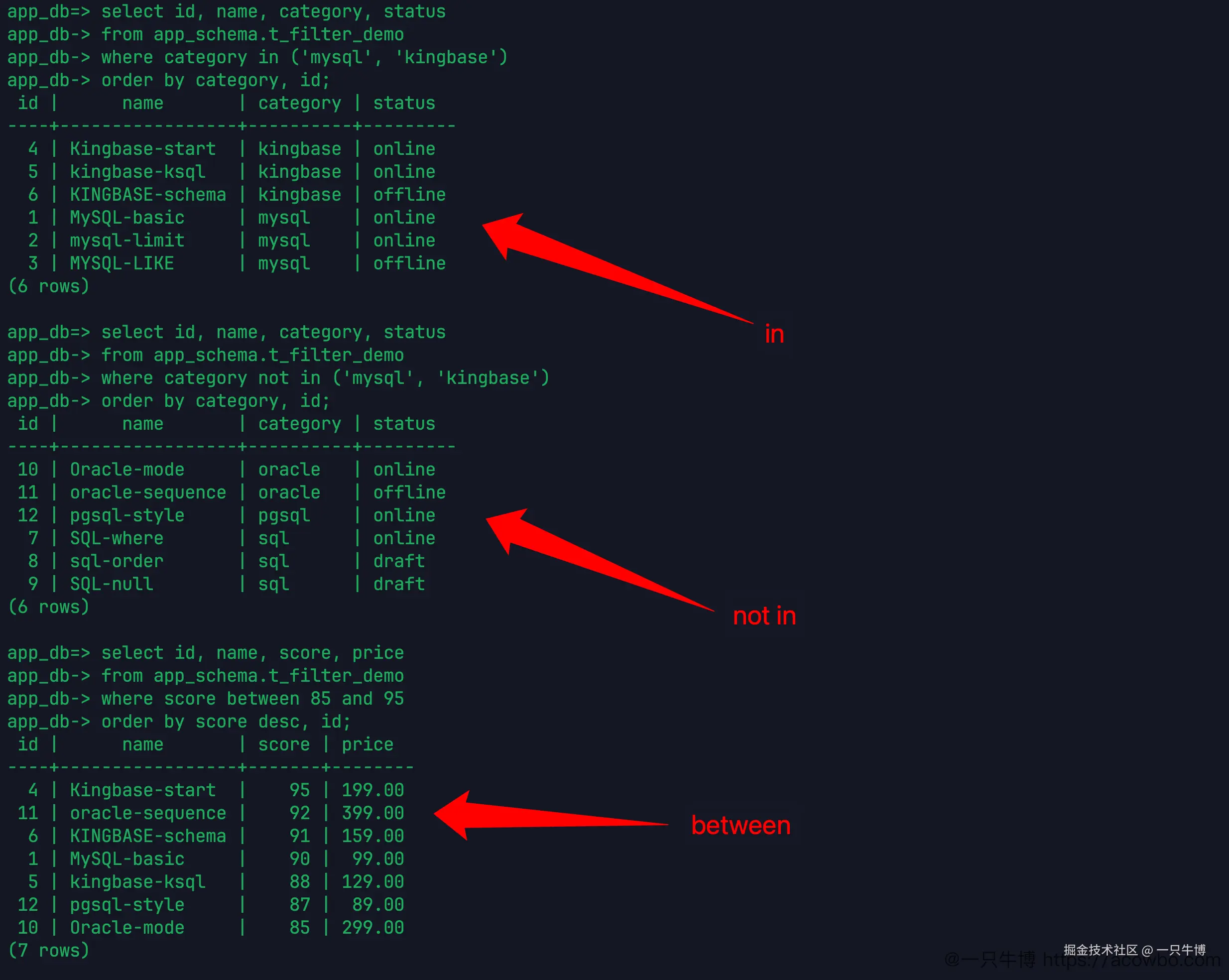
这些条件本身不难,容易出问题的是数据里有 NULL 的时候。not in 遇到 NULL 子查询时会变得麻烦,不过这次先只用固定列表,不把子查询混进来。NULL 单独看。
order by category, id 也帮忙看清了返回顺序。in 的结果不是按列表里 'mysql', 'Kingbase' 的顺序回来,而是按 SQL 里写的排序字段回来。接口如果对返回顺序有要求,就把 order by 写清楚,不要靠插入顺序或者 in 列表顺序。
NULL 不要用等号猜
remark 字段有 4 行是 NULL。用正确写法查:
sql
where remark is null返回 3、6、9、12 四行。反过来:
sql
where remark is not null返回 8 行。
再故意写一次:
sql
where remark = null结果是 0 行。这个结果很适合拿来提醒自己:NULL 不是一个普通值,不能用 = 去匹配。要查空值,就写 is null;要排除空值,就写 is not null。
score is null 也单独跑了一次,只返回 9 号 SQL-null。后面的聚合统计会用到它,因为 count(*) 和 count(score) 的结果不一样。
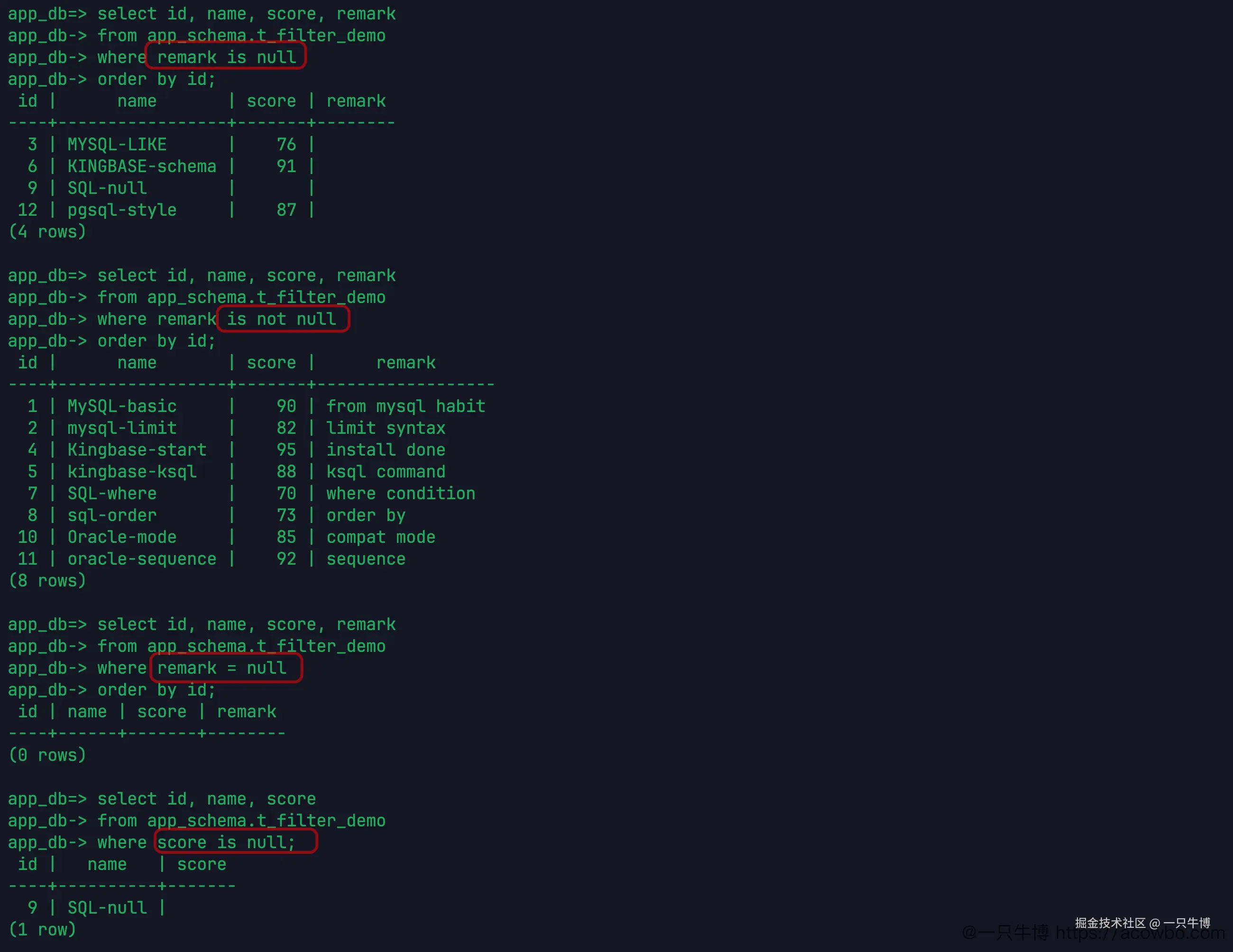
从 MySQL 切到 KingbaseES,NULL 这块反而不用背新东西,按 SQL 里的正常写法来就行。真正要改的是一些偷懒习惯:接口拼条件时不要把 = null 拼进去,动态 SQL 里也不要把 NULL 当成普通字符串处理。
remark 和 score 两个字段都放了 NULL,效果不一样:remark 是文本备注,适合验证空值筛选;score 是数字,后面会参与 avg。同样是 NULL,到了统计函数里就会影响计数和平均值,这比单纯查出空行更容易在报表里踩坑。
排序和 LIMIT 可以直接组合
取分数最高的 5 行:
sql
select id, name, category, score
from app_schema.t_filter_demo
where score is not null
order by score desc, id
limit 5;返回结果是 4、11、6、1、5,对应分数 95、92、91、90、88。这里先用 score is not null 把 NULL 排除掉,再按分数倒序排,最后加 id 兜底。
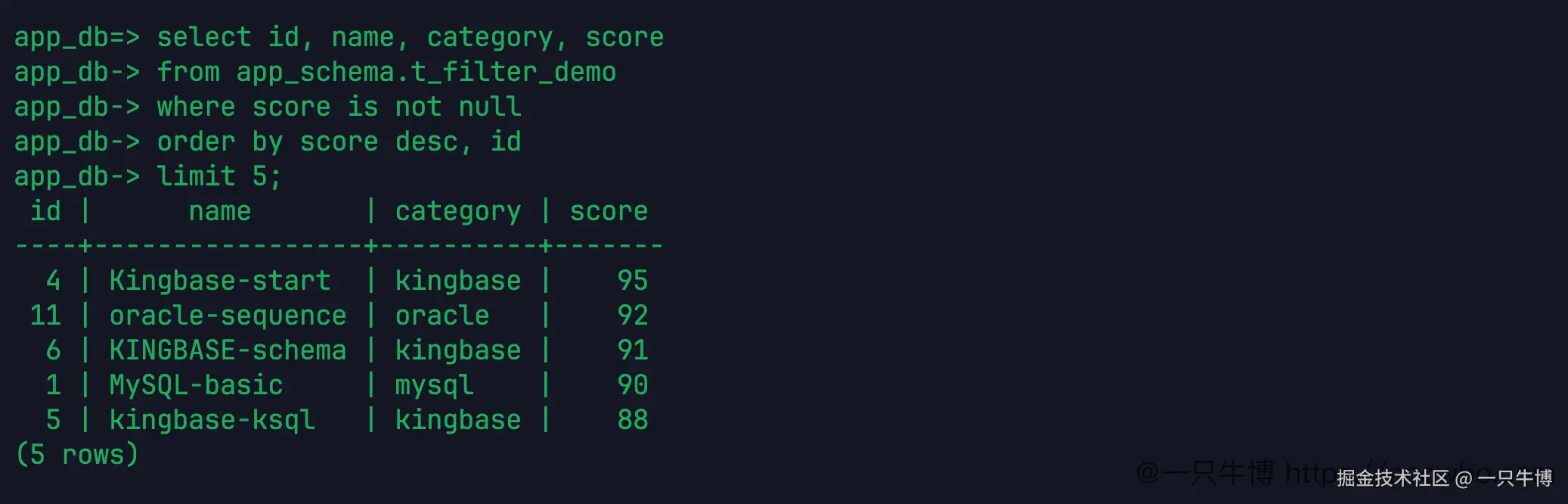
limit 语法前面已经单独验证过,这里放在条件查询里看更接近日常用法。实际接口里很少只写 limit 5,更多是先筛选,再排序,再限制条数。排序字段只有一个时,如果出现同分,分页结果可能不稳定;多加一个唯一字段做兜底,结果更好复现。
这次数据里前 5 名没有同分,id 兜底看起来不显眼,但它仍然应该写上。等数据量上来以后,同一个分数出现多行很正常。分页接口少一个稳定排序字段,问题通常不会立刻暴露,而是在翻页时出现重复行或漏行。
聚合函数会跳过 NULL
先对全表做一次基础统计:
sql
select
count(*) as total_count,
count(score) as score_count,
min(score) as min_score,
max(score) as max_score,
avg(score) as avg_score
from app_schema.t_filter_demo;结果里 total_count 是 12,score_count 是 11。差的那一行,就是 score 为 NULL 的 9 号数据。min(score) 是 70,max(score) 是 95,avg(score) 是 84.45454545454545。平均值按 11 个非 NULL 分数算,不是按 12 行硬除。
再按状态分组:
sql
select status, count(*) as row_count
from app_schema.t_filter_demo
group by status
order by status;返回 draft=2、offline=3、online=7。

这里和 MySQL 里的常见用法差别不大。真正需要盯住的是 count(*) 和 count(字段)。前者数行,后者只数这个字段非 NULL 的行。接口里如果把这两个混用,统计结果会差一截。
状态统计也顺便校验了前面的插入数据:2 行草稿、3 行下线、7 行在线,加起来正好 12 行。做这种小实验时,分组结果能当作一次反查,避免后面拿一批本来就不对的数据继续验证。
HAVING 是分组后的过滤
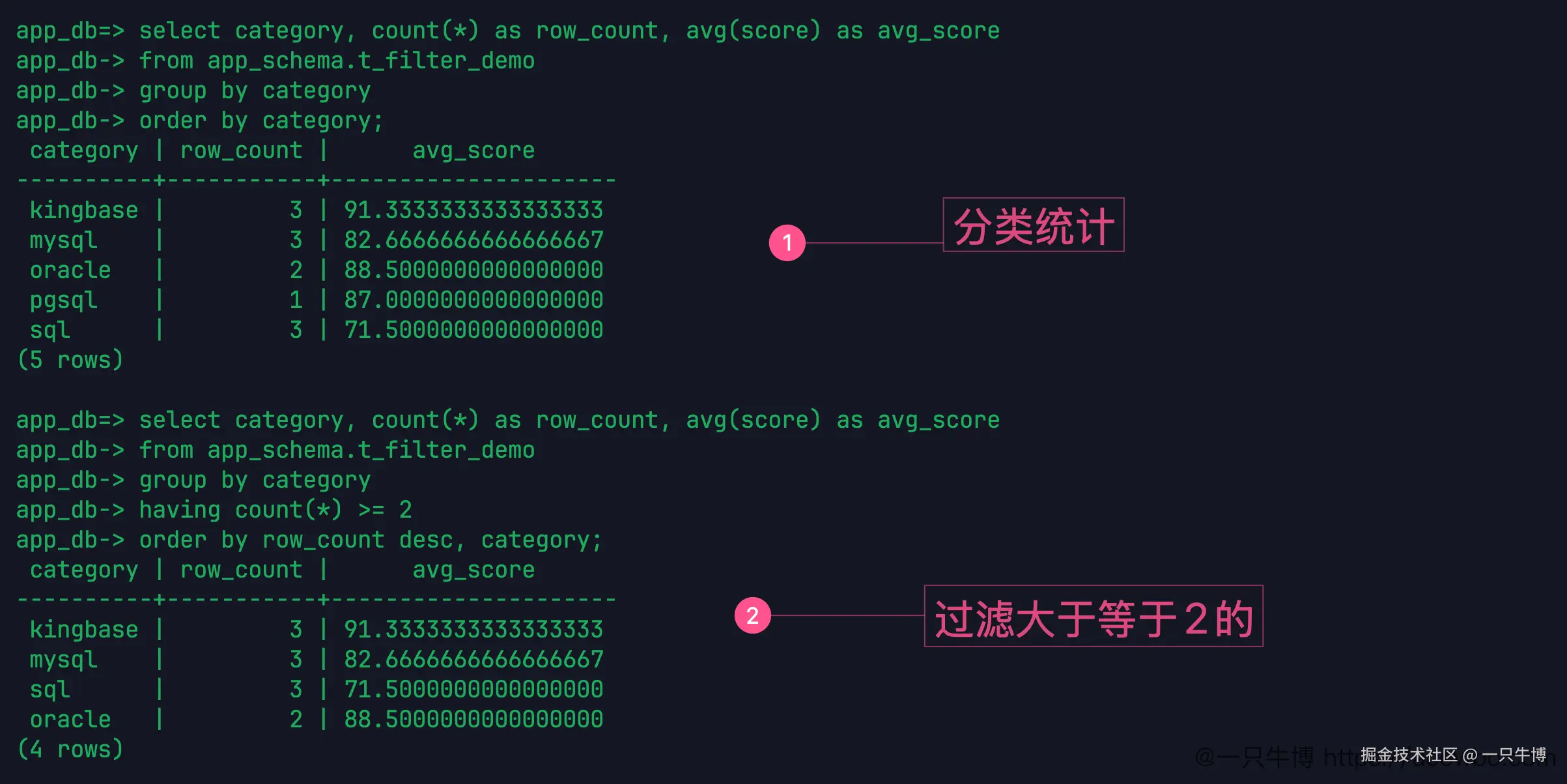
最后按分类统计:
sql
select category, count(*) as row_count, avg(score) as avg_score
from app_schema.t_filter_demo
group by category
order by category;结果有 5 类:kingbase 3 行,平均分约 91.33;mysql 3 行,平均分约 82.67;oracle 2 行,平均分 88.50;pgsql 1 行,平均分 87;sql 3 行,平均分 71.50。sql 分类里有一行 score 是 NULL,所以平均分只按 70 和 73 算。
再加上:
sql
having count(*) >= 2pgsql 被过滤掉,只剩下行数大于等于 2 的分类。where 是分组前过滤明细行,having 是分组后过滤聚合结果,这个区别在报表 SQL 里很常见。
这组查询跑完以后,日常 WHERE 条件基本有了底。等值、不等值、and/or、like、in、between、NULL 判断、排序、限制条数、聚合和 having,在当前 V009R001C010 环境里都能按预期工作。真正需要单独标记的有三点:当前实例大小写不敏感,所以 LIKE 和 category = 'Kingbase' 的表现不能脱离环境复述;NULL 只能用 is null / is not null;聚合函数处理 NULL 时要看清楚 count(*) 和 count(字段) 的差别。
having count(*) >= 2 过滤的是分组后的行数,所以 sql 分类虽然有一个分数为 NULL,仍然保留下来;它有 3 行明细。avg(score) 只按非 NULL 分数算,行数和平均值各算各的,这一点从 sql 的 3 行、平均分 71.50 能看出来。
把这些基础条件先跑明白,再去看 JOIN、子查询、窗口函数或者备份恢复,心里会踏实很多。SQL 迁移最怕的不是语法多,而是基础判断没有实测就默认"差不多"。