目标:
1.了解什么是用户态,什么是内核态
2.可重入函数的认识
3.volatile的认识
4.知道SIGCHLD信号的作用
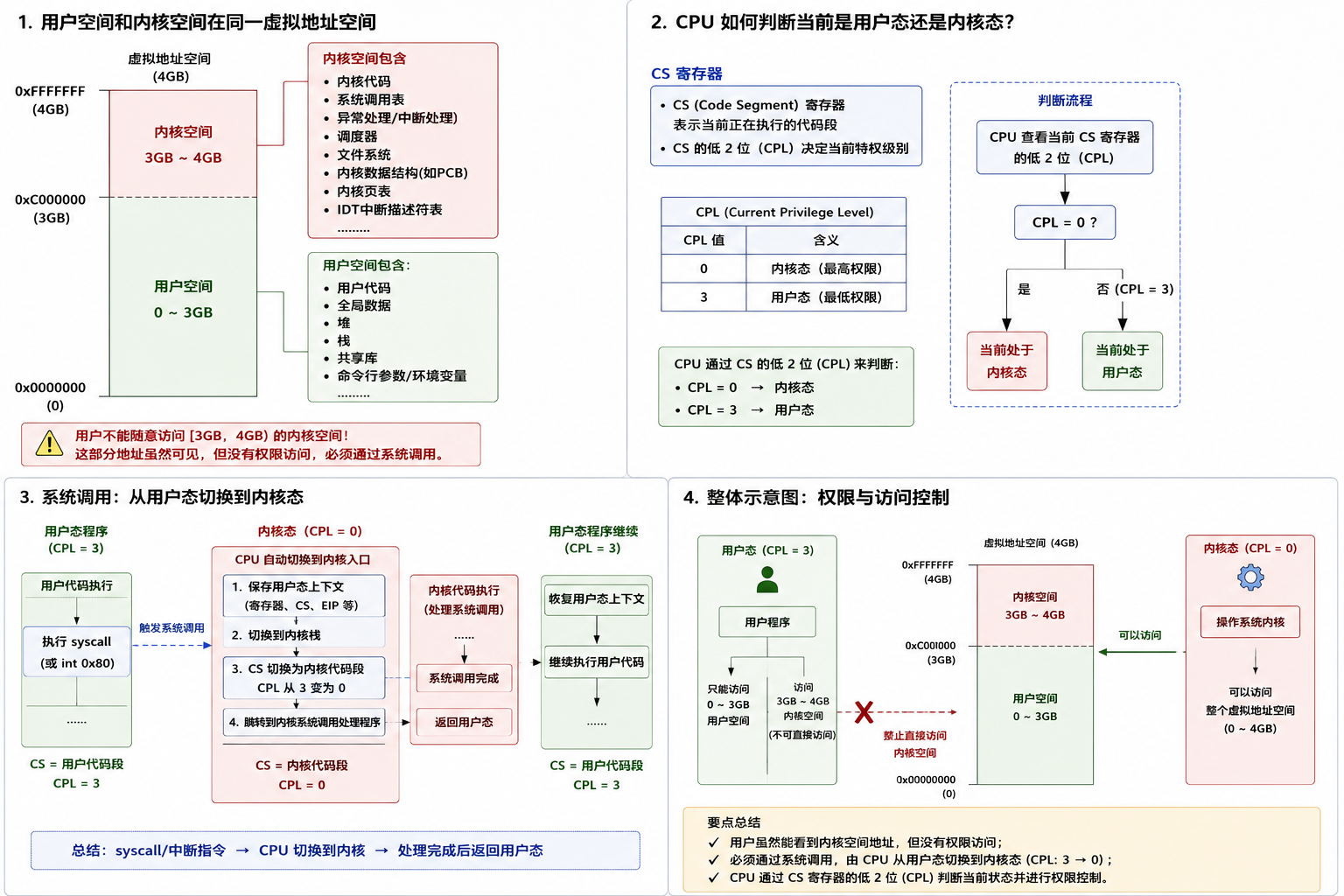
一.用户态和内核态
通过对信号的多方面认识,我们已经了解了什么是信号,信号保存和信号捕获,那么本篇就要解决一些细节问题,首先看图:
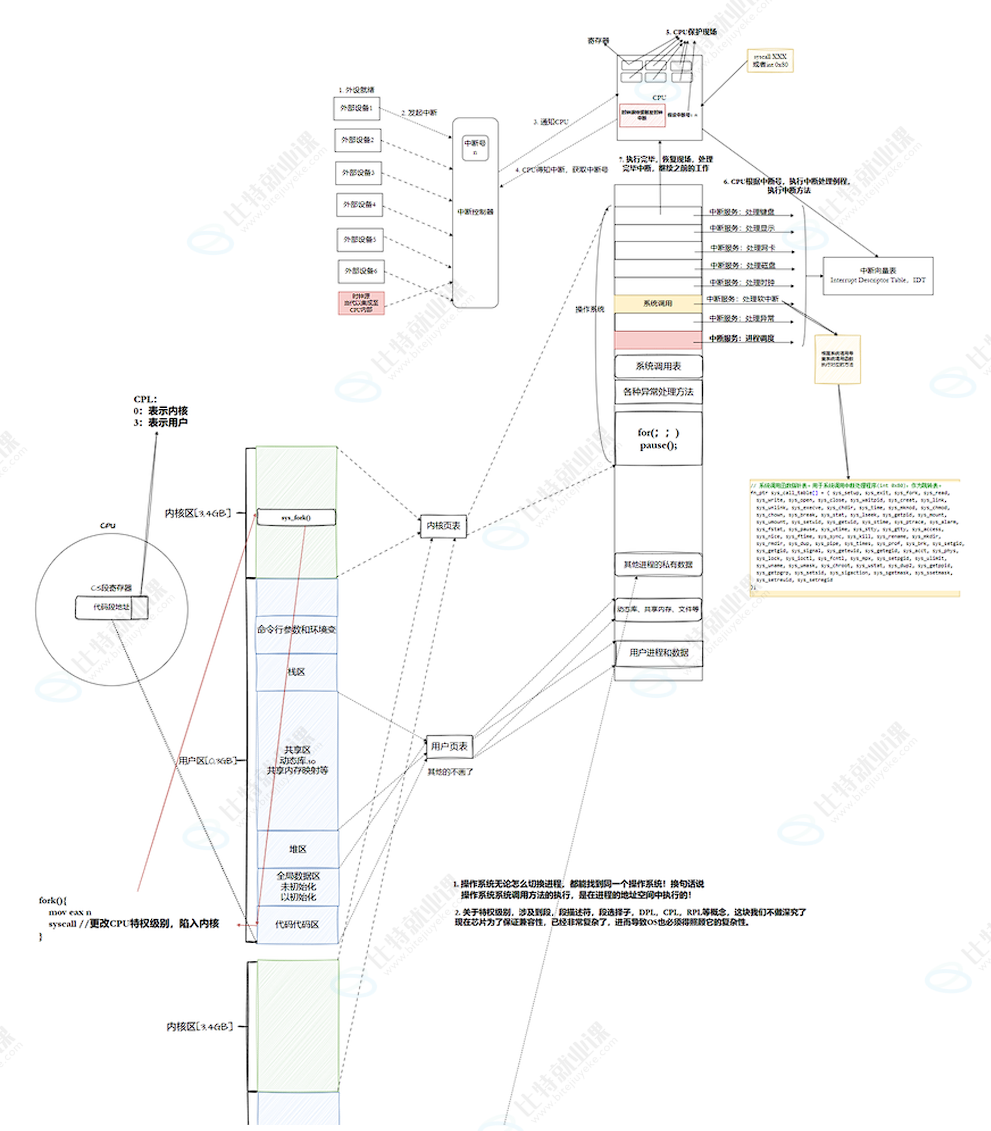
解释:
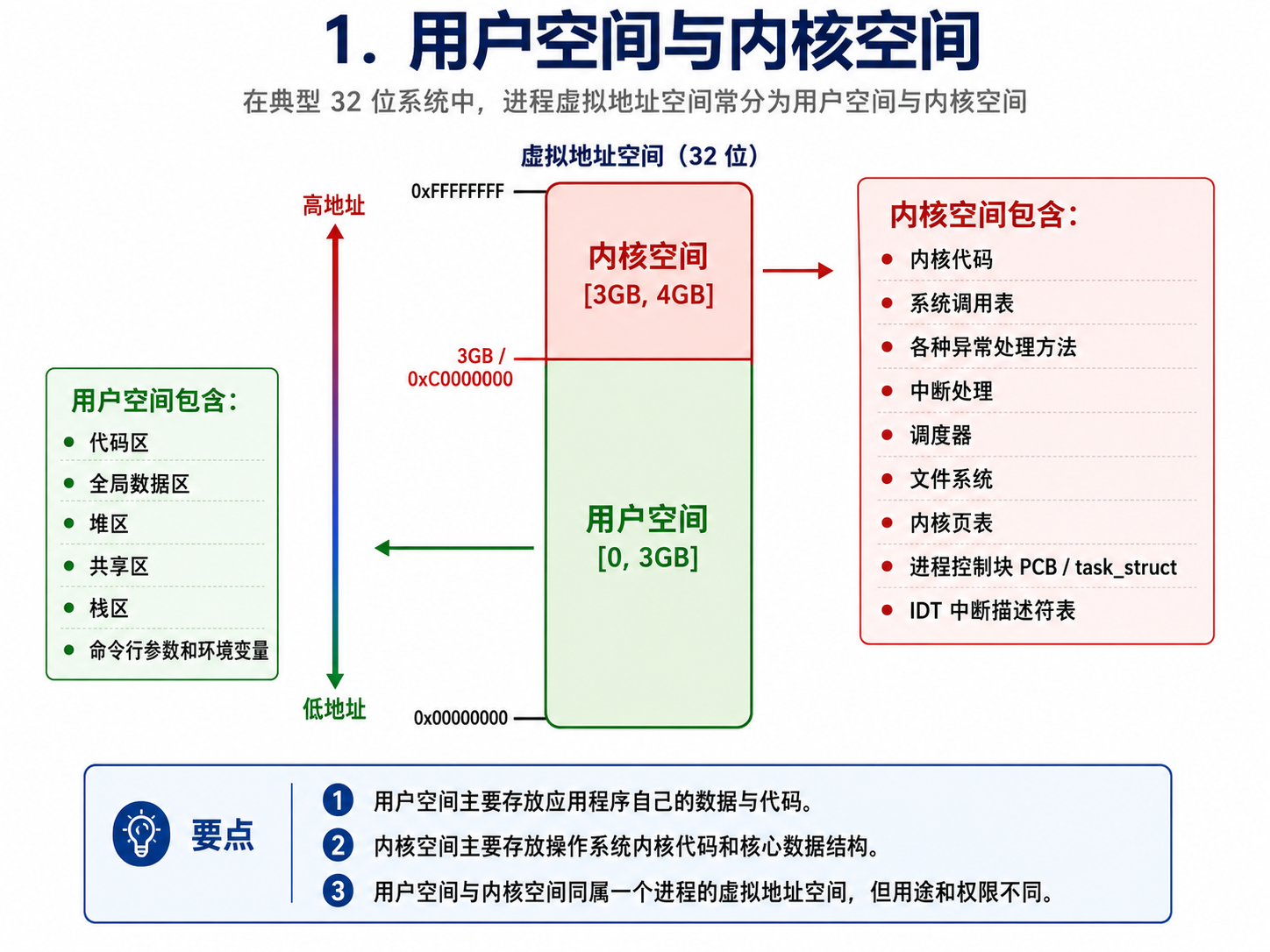
1.用户空间与内核空间
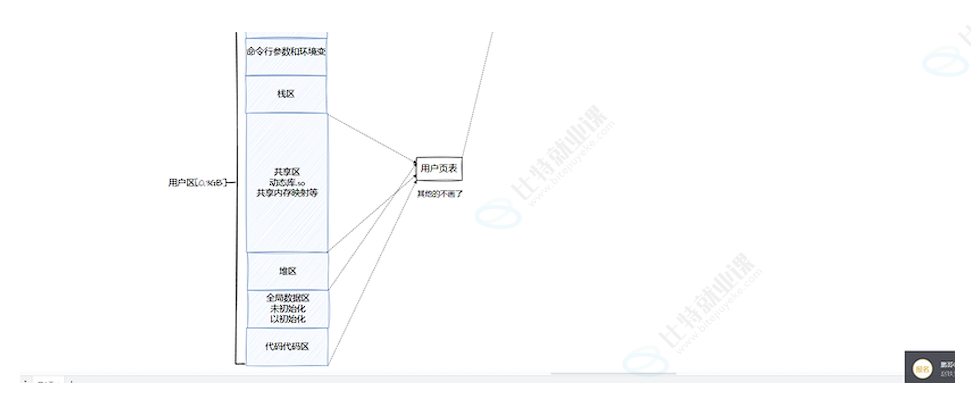
虚拟地址空间中0-3GB 是属于用户空间的,里面包含:
cpp
代码区
全局数据区
堆区
共享区
栈区
命令行参数和环境变量然后3GB-4GB 是属于内核空间的,里面包含:
cpp
内核代码
系统调用表
各种异常处理方法
中断处理
调度器
文件系统
内核页表
进程控制块 PCB / task_struct
IDT 中断描述符表示意图:
2.内核区
我们知道每个进程都有自己的虚拟地址空间,例如有两个A进程 和 B进程:
cpp
进程 A 的虚拟地址空间
┌────────────────────┐
│ 用户区 A │ ← A 自己的代码、堆、栈
├────────────────────┤
│ 内核区 │ ← 映射操作系统内核
└────────────────────┘
进程 B 的虚拟地址空间
┌────────────────────┐
│ 用户区 B │ ← B 自己的代码、堆、栈
├────────────────────┤
│ 内核区 │ ← 映射操作系统内核
└────────────────────┘A 和 B 的用户区空间是互相隔离,但它们的内核区通常映射到同一份物理内存 ,也就是同一套操作
系统内核代码和核心数据结构,所以:
cpp
进程 A 的内核区 ─┐
├── 映射到同一个操作系统内核
进程 B 的内核区 ─┘结论:操作系统无论怎么切换进程,都能找到同⼀个操作系统!换句话说操作系统系统调用方法的执行, 是在进程的地址空间中执行的!
示意图:
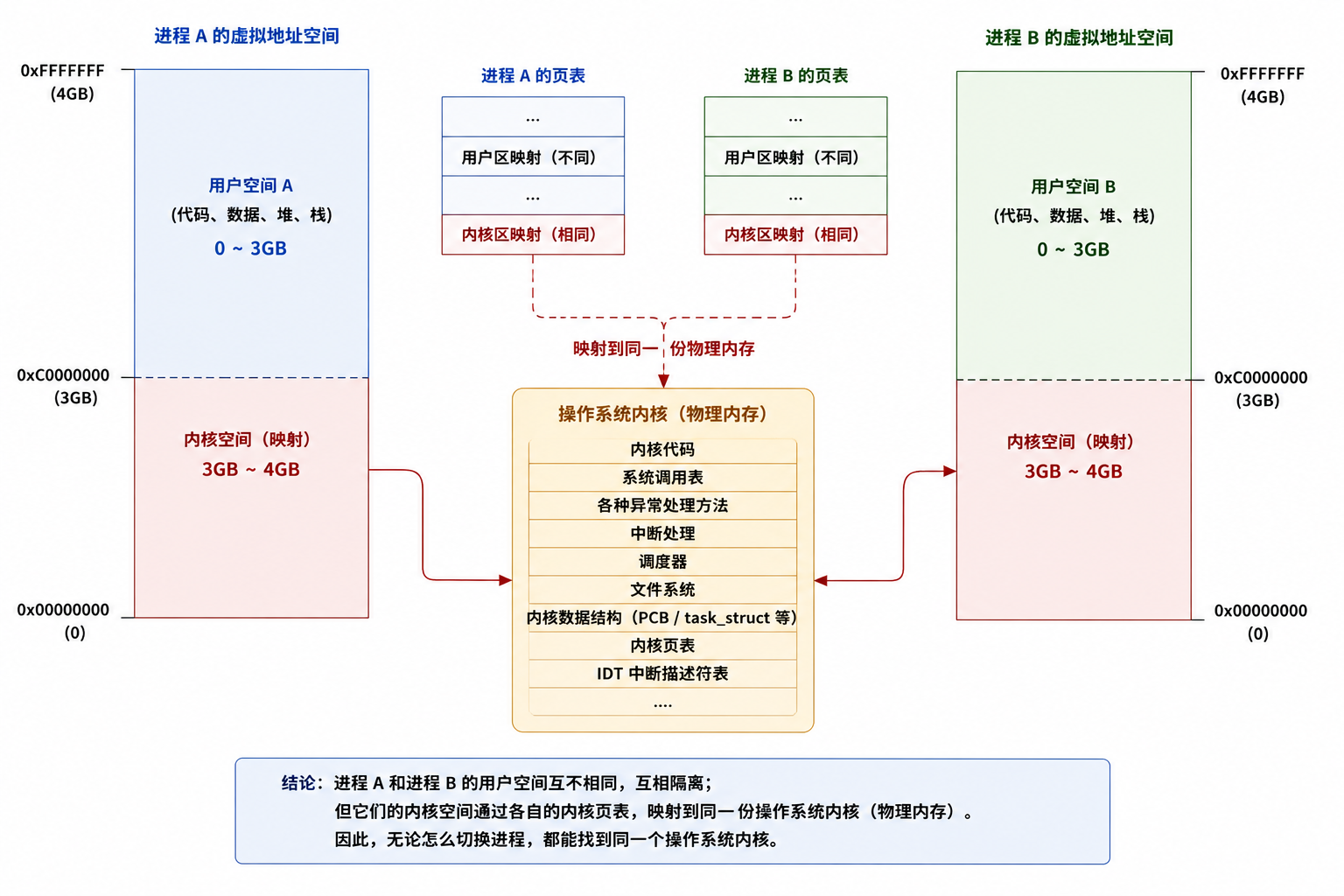
3.为什么切换进程后还能找到同一个操作系统?
进程切换时,CPU 会切换页表。比如从进程 A 切到进程 B:
进程 A 页表 → 进程 B 页表切换页表后,用户区映射变了:
A 的用户区消失,换成 B 的用户区但是内核区映射通常保持一致:
A 的内核区地址 0xFFFF... → 内核物理内存
B 的内核区地址 0xFFFF... → 同一份内核物理内存所以虽然换了进程,内核在虚拟地址空间中的位置仍然一样。
可以理解成:
每个进程都有一本自己的地图。
地图下半部分:每个人自己的家,不一样。
地图上半部分:国家机关的位置,一样。
无论你拿的是谁的地图,都能找到同一个政府大楼。这里:
用户区 = 每个进程自己的家
内核区 = 操作系统内核
页表 = 地址地图
系统调用 = 去政府办事注意:用户页表在一个进程里面可以存在多份,但是内核页表系统提供一份,由所有的进程共享。
4.身份切换
我们已经知道了,用户空间和内核空间都在同一个虚拟地址空间上,如果用户随便拿一个虚拟地址在3GB,4GB的范围内的,那用户不就可以随便访问内核的代码和数据了吗?
答案:这个不被允许的,操作系统为了保护自己,不相信任何人,必须采用系统调用的方式访问,
用户态:以用户身份访问0,3GB,内核态以内核身份,通过系统调用的方式访OS3GB,4GB,
也就是说这个地址是可以看到的,但是内容是没有权限访问的。
但是在操作系统中,用户/OS是如何知道当前是处于用户身份,还是内核态、身份的呢?
CPU 里有一个寄存器叫 CS,表示:
CPU 当前正在执行哪一段代码CS 里面不仅有代码段信息,还带着权限级别。
这个权限级别就是 CPL:
CPL = CS 的低 2 位通常:
CPL = 0 → 内核态
CPL = 3 → 用户态所以可以这样理解:
CPU 看当前 CS 的权限级别
↓
如果 CPL = 3,就认为当前在用户态
↓
如果 CPL = 0,就认为当前在内核态所以当用户程序执行系统调用 ,比如 syscall:
用户态程序
↓
执行 syscall
↓
CPU 自动切换到内核入口
↓
CS 被切换成内核代码段
↓
CPL 从 3 变成 0于是 CPU 进入内核态。
流程图:
二.可重入函数
1.概念
先看一张图片:
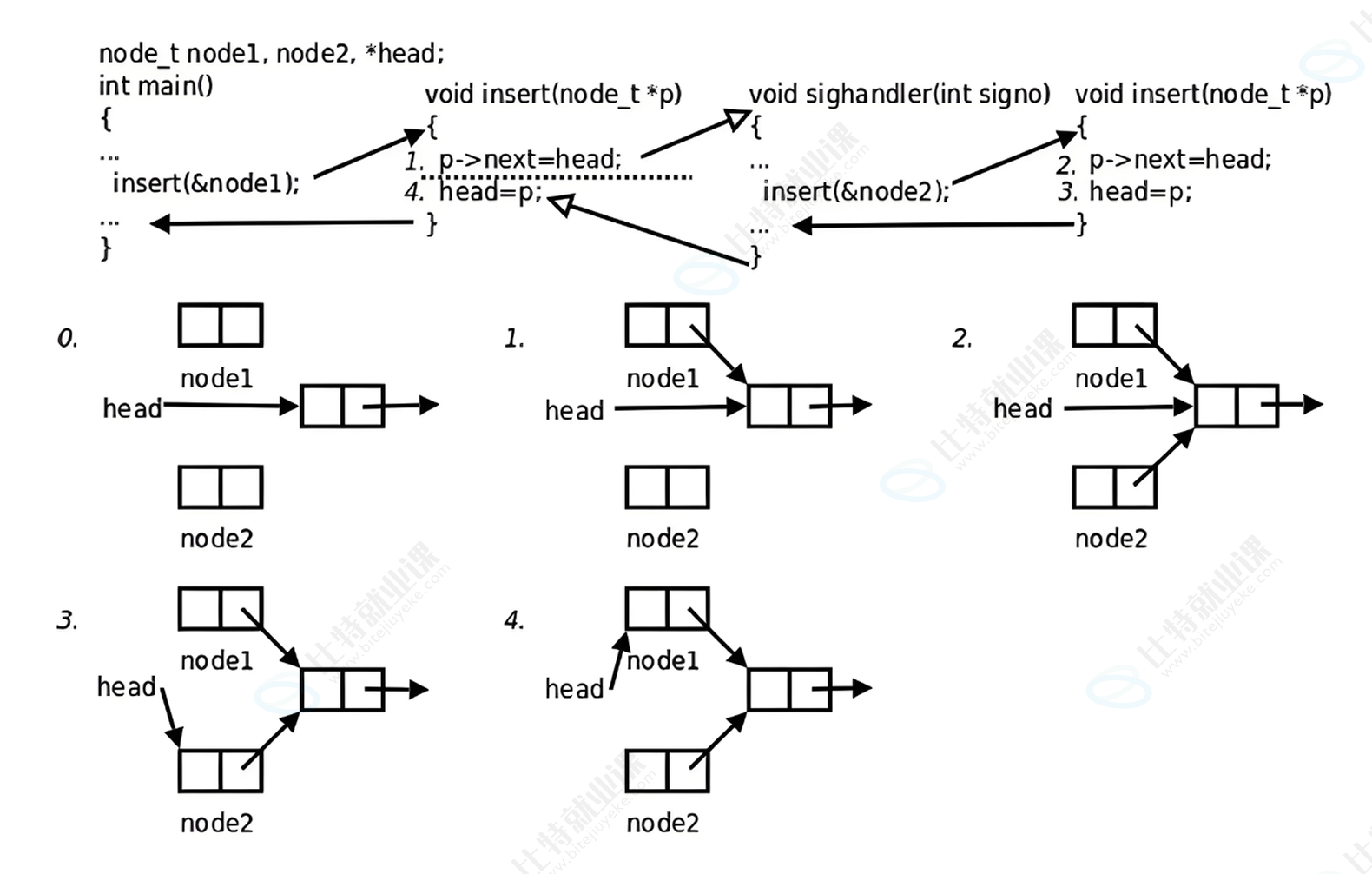
解释:
main函数调用insert函数向⼀个链表head中插⼊节点node1,插⼊操作分为两步,刚做完第⼀步的 时候,因为硬件中断 使进程切换到内核,再次回用户态之前检查到有信号待处理,于是切换到 sighandler函数,但是sighandler也调用insert函数向同⼀个链表head中插入节点node2, 插入操作的两步都做完之后从sighandler返回内核态,再次回到用户态就从main函数调用的insert函数中继续 往下执行,先前做第⼀步之后被打断 ,现在继续做完第⼆步,那么 结果是,main函数和sighandler先后向链表中插⼊两个节点,而最后只有⼀个节点真正插⼊链表中了,但是这也导致了一个问题,当我们销毁链表时,不就造成内存泄漏了吗?
像上例这样,insert函数被不同的控制流程 调用,有可能在第⼀次调⽤还没返回时就再次进入该函 数 ,这称为重入, insert函数访问⼀个全局链表,有可能因为重入而造成错乱 ,像这样的函数称为不可重⼊函数, 反之,如果⼀个函数只访问自己的局部变量或参数,则称为可重⼊函数。
注意:大部分的函数都是不可重入的,也不建议信号处理函数里不要调用这种非可重入函数。信号处理函数应该尽量简单些。
2.例子
这里举个更详细的例子,帮助理解:
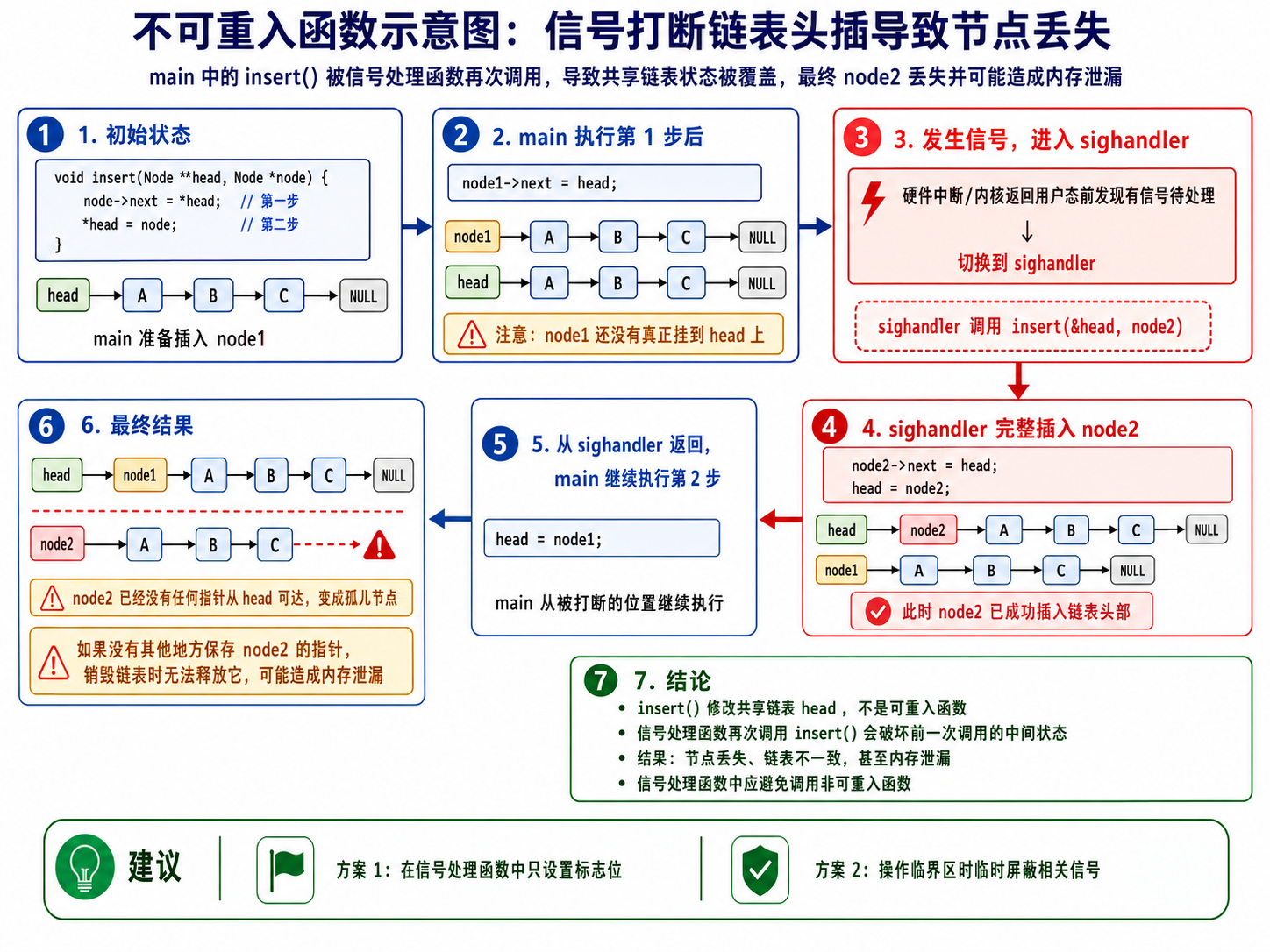
假设 insert 是头插法,代码类似:
void insert(Node **head, Node *node)
{
node->next = *head; // 第一步
*head = node; // 第二步
}初始链表:
head → A → B → Cmain 准备插入 node1。
执行第一步后:
node1->next = head;此时状态是:
node1 → A → B → C
head → A → B → C注意:node1 还没有真正挂到 head 上。
然后发生信号,进入 sighandler,它也调用:
insert(&head, node2);信号处理函数完整执行完两步:
node2->next = head;
head = node2;链表变成:
head → node2 → A → B → C
node1 → A → B → C然后信号处理函数返回,main 继续执行它刚才没做完的第二步:
head = node1;于是链表变成:
head → node1 → A → B → C这时 node2 怎么样了?
node2 → A → B → C但是已经没有任何指针从 head 指向 node2 了。
所以结果是:
node2 曾经插入成功,但后来被 main 中断前未完成的插入操作覆盖掉了。node2 从链表中丢失,如果程序也没有别的指针保存它,那它就泄漏了。
也就是说,销毁链表时:
head → node1 → A → B → C只能释放 node1、A、B、C。
但是 node2 已经不在链表里了:
node2 变成孤儿节点如果没有其他地方记录 node2,就释放不到它,造成内存泄漏。
流程图:
三.volatile关键字
该 关键字在C++当中我们可能有所涉猎,今天我们站在信信角度重新理解⼀下
首先写个代码:
cpp
#include <stdio.h>
#include <signal.h>
int flag = 0;
void handler(int sig)
{
printf("chage flag 0 to 1\n");
flag = 1;
}
int main()
{
signal(2, handler);
while(!flag)
{
sleep(1);
printf("process quit normal\n");
}
return 0;
}makefile中,
cpp
test:test.cpp
g++ -o $@ $^ -std=c++11 -g
.PHONY:clean
clean:
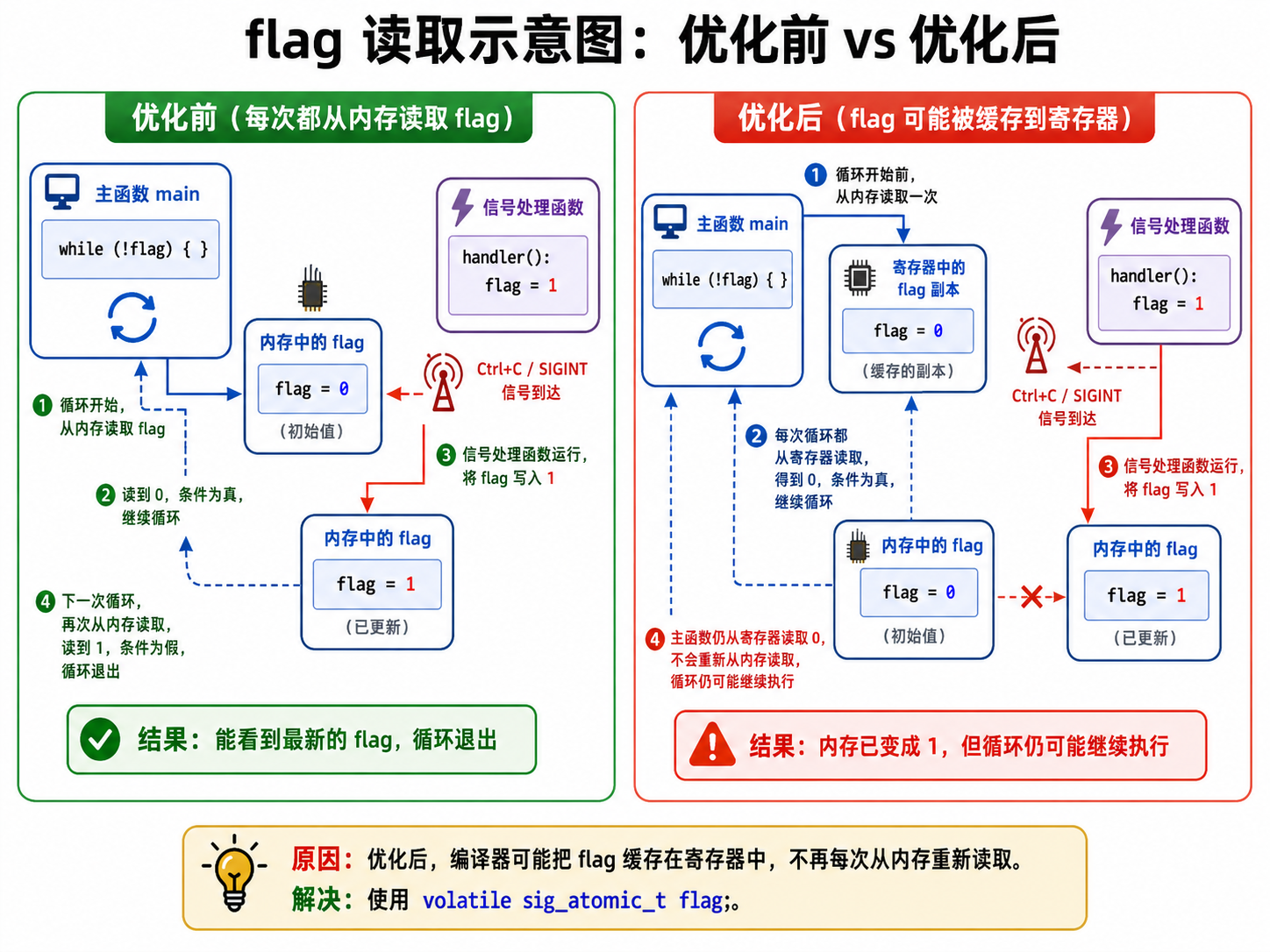
rm -rf test 标准情况下,按下 ctrl+c ,2号信号被捕捉,执⾏自定义动作,修改 flag = 1 ,while条件不满⾜,退出循环,进程退出。
但是在优化情况下,键入 CTRL-C ,2号信号被捕捉,执行⾃定义动作,修改 flag = 1 ,但是while条 件依旧满足,进程继续运行!但是很明显flag肯定已经被修改了 ,但是为何循环依旧执行?
这是因为优化后,编译器可能把 flag 的值放到某个寄存器里反复使用。
比如原来逻辑是:
while (!flag) {
}未优化时可能类似:
每次循环:
去内存读取 flag
判断 flag 是否为 0优化后编译器可能认为:循环体里没有修改 flag,所以 flag 的值不会变。
于是可能变成:
一开始:
从内存读取 flag 到寄存器
后面循环:
一直判断寄存器里的值
不再反复读取内存中的 flag也就是类似:
内存中的 flag:已经被信号处理函数改成 1
寄存器中的 flag 副本:还是 0
while 判断用的是寄存器里的 0
所以循环继续执行所以问题不是 handler 没有修改成功,而是 main 循环没有重新从内存里取最新的 flag。
所以加上 volatile 后:
cpp
volatile int flag = 0;意思就是告诉编译器:
这个变量可能会被当前代码看不见的地方修改,比如信号处理函数、中断、硬件等,所以每次使用
它都要从内存重新读取,不要只用寄存器缓存值。
示意图:
四.SIGCHLD信号
1.基本认识
在进程一章中我们介绍了使用wait和waitpid函数处理僵尸进程的方法。父进程可以选择两种方式:
一种是阻塞等待子进程结束 ,另一种是非阻塞地轮询检查是否有子进程需要清理。第一种方式会导
致父进程无法执行自身任务 ,而第二种方式虽然不会阻塞父进程,但需要定期轮询检查,增加了程
序实现的复杂度。
其实当子进程终止时 ,它是会向父进程发送SIGCHLD信号 。该信号的默认处理方式是忽略,但父
进程可以自定义其处理函数 。这样父进程就能专注于自身任务,无需主动关注子进程。子进程终止
时会主动通知父进程,父进程只需在信号处理函数中调用wait清理子进程即可。
例如,我们写个:父进程通过 fork() 创建子进程后,子进程调用 exit(2) 终止运行。此时父进程会收到 SIGCHLD 信号,并在其自定义的信号处理函数中调用 wait() 获取子进程的退出状态,最终打印该状态信息的代码,
cpp
#include <stdio.h>
#include <stdlib.h>
#include <signal.h>
#include <sys/types.h>
#include <sys/wait.h>
#include <unistd.h>
void handler(int sig)
{
pid_t id;
while ((id = waitpid(-1, NULL, WNOHANG)) > 0) {
printf("wait child success: %d\n", id);
}
printf("child is quit! %d\n", getpid());
}
int main()
{
signal(SIGCHLD, handler);
pid_t cid = fork();
if (cid == 0) { // child
printf("child: %d\n", getpid());
sleep(3);
exit(1);
}
while (1) {
printf("father proc is doing some thing!\n");
sleep(1);
}
return 0;
}感兴趣的可以自己验证一下。
2.细节处理
1.那么为什么SIGCHLD信号默认处理动作是忽略呢?
因为很多父进程并不需要立刻处理子进程退出事件。
如果每个子进程退出都强制打断父进程,父进程的逻辑会很混乱。
所以系统设计成:
SIGCHLD 默认不打扰父进程
父进程如果关心子进程退出,就自己注册 handler 或调用 wait/waitpid也就是说,默认忽略是为了:不让子进程退出事件默认干扰父进程
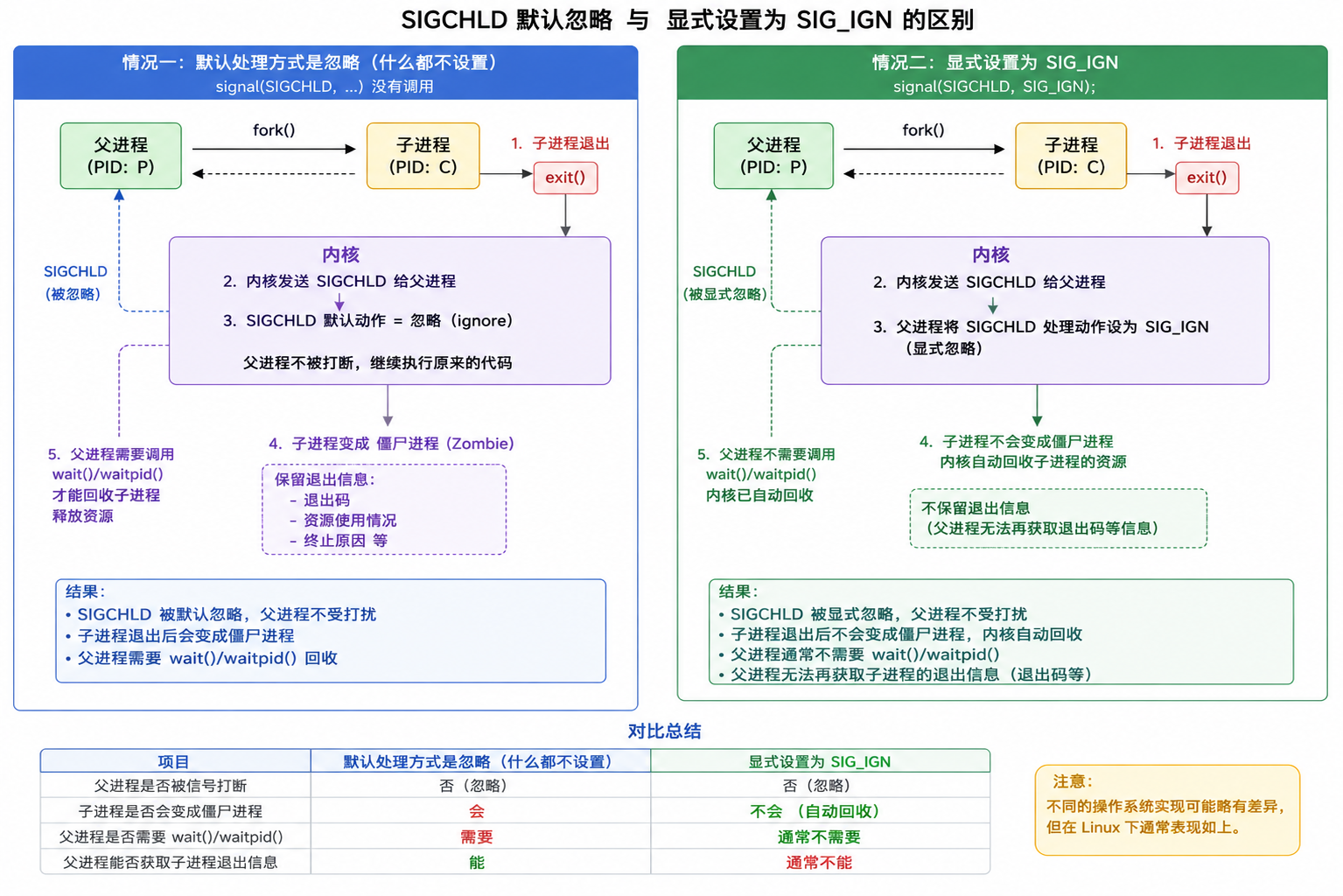
2.SIGCHLD信号默认处理方式是忽略,和利用signal将这个 SIGCHLD的处理动作置为SIG_IGN的区别?
<1>.默认处理方式是忽略
也就是你什么都不写:
// 没有 signal(SIGCHLD, ...)子进程退出时:
子进程退出
↓
内核给父进程发送 SIGCHLD
↓
父进程默认忽略这个信号
↓
但是子进程仍然会变成僵尸进程
↓
需要父进程 wait / waitpid 回收所以:
默认忽略 SIGCHLD:
只是父进程不会被这个信号打断或终止;
不代表子进程自动回收。<2>.显式设置为 SIG_IGN
也就是你写:
signal(SIGCHLD, SIG_IGN);这表示你明确告诉操作系统:我不关心子进程退出状态,不需要 wait 获取退出码。
在 Linux 中,通常效果是:
子进程退出
↓
内核不给它保留僵尸状态
↓
子进程自动被回收
↓
父进程之后 wait / waitpid 可能会失败也就是说:
显式设置 SIGCHLD 为 SIG_IGN:
不仅忽略 SIGCHLD,
还可能让子进程退出后自动回收,不产生僵尸进程。注意:系统默认的忽略动作和用户用signal函数自定义的忽略通常是没有区别的,但这是⼀个特例,但是此方法对于Linux可用,但不保证在其它UNIX系统上都可用。
示意图:
总结:
用户态和内核态体现的是 CPU 权限身份的不同;信号会打断正常执行流,因此信号处理函数中要注意可重入问题;而 volatile 解决的是编译器优化导致变量不被重新读取的问题;SIGCHLD 则用于通知父进程子进程状态变化,帮助父进程回收子进程,避免僵尸进程。