目录
[二、MySQL - mysql-connector 驱动](#二、MySQL - mysql-connector 驱动)
[三、PyMySQL 驱动](#三、PyMySQL 驱动)
[Socket 对象(内建)方法](#Socket 对象(内建)方法)
[使用 threading 模块创建线程](#使用 threading 模块创建线程)
[1. ElementTree](#1. ElementTree)
[3.DOM(Document Object Model)](#3.DOM(Document Object Model))
[Python 使用 ElementTree 解析 xml](#Python 使用 ElementTree 解析 xml)
[解析 XML](#解析 XML)
[遍历 XML 树](#遍历 XML 树)
[创建 XML](#创建 XML)
[修改 XML](#修改 XML)
[Python 使用 SAX 解析 xml](#Python 使用 SAX 解析 xml)
[ContentHandler 类方法介绍](#ContentHandler 类方法介绍)
[Python 编码为 JSON 类型转换对应表:](#Python 编码为 JSON 类型转换对应表:)
[JSON 解码为 Python 类型转换对应表:](#JSON 解码为 Python 类型转换对应表:)
[json.dumps 与 json.loads 实例](#json.dumps 与 json.loads 实例)
[Time 模块](#Time 模块)
一、CGI编程
CGI(Common Gateway Interface),通用网关接口,它是一段程序,运行在服务器上如:HTTP服务器,提供同客户端HTML页面的接口。
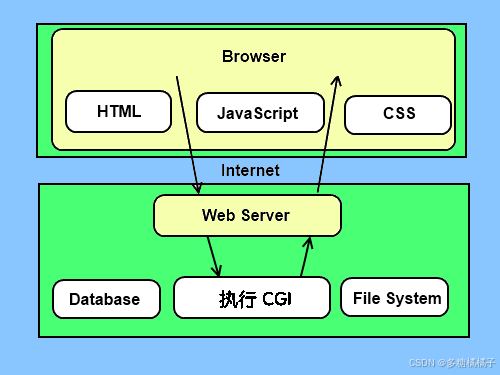
Web服务器支持及配置
设置好CGI目录:
python
ScriptAlias /cgi-bin/ /var/www/cgi-bin/所有的HTTP服务器执行CGI程序都保存在一个预先配置的目录。这个目录被称为CGI目录,并按照惯例,它被命名为/var/www/cgi-bin目录。
CGI文件的扩展名为.cgi,python也可以使用.py扩展名。
默认情况下,Linux服务器配置运行的cgi-bin目录中为/var/www。
如果你想指定其他运行CGI脚本的目录,可以修改httpd.conf配置文件,如下所示:
python
<Directory "/var/www/cgi-bin">
AllowOverride None
Options +ExecCGI
Order allow,deny
Allow from all
</Directory>简单的url实例:GET方法
python
/cgi-bin/hello_get.py?name=菜鸟教程&url=http://www.runoob.com
python
#!/usr/bin/python3
# CGI处理模块
import cgi, cgitb
# 创建 FieldStorage 的实例化
form = cgi.FieldStorage()
# 获取数据
site_name = form.getvalue('name')
site_url = form.getvalue('url')
print ("Content-type:text/html")
print ()
print ("<html>")
print ("<head>")
print ("<meta charset=\"utf-8\">")
print ("<title>菜鸟教程 CGI 测试实例</title>")
print ("</head>")
print ("<body>")
print ("<h2>%s官网:%s</h2>" % (site_name, site_url))
print ("</body>")
print ("</html>")二、MySQL - mysql-connector 驱动
mysql-connector 是 MySQL 官方提供的驱动器。
我们可以使用 pip 命令来安装 mysql-connector:
python
python -m pip install mysql-connector创建数据库连接
python
import mysql.connector
mydb = mysql.connector.connect(
host="localhost", # 数据库主机地址
user="yourusername", # 数据库用户名
passwd="yourpassword" # 数据库密码
)
print(mydb)插入数据
python
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database="runoob_db"
)
mycursor = mydb.cursor()
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = ("RUNOOB", "https://www.runoob.com")
mycursor.execute(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
print(mycursor.rowcount, "记录插入成功。")
python
import mysql.connector
mydb = mysql.connector.connect(
host="localhost",
user="root",
passwd="123456",
database="runoob_db"
)
mycursor = mydb.cursor()
sql = "INSERT INTO sites (name, url) VALUES (%s, %s)"
val = [
('Google', 'https://www.google.com'),
('Github', 'https://www.github.com'),
('Taobao', 'https://www.taobao.com'),
('stackoverflow', 'https://www.stackoverflow.com/')
]
mycursor.executemany(sql, val)
mydb.commit() # 数据表内容有更新,必须使用到该语句
print(mycursor.rowcount, "记录插入成功。")三、PyMySQL 驱动
PyMySQL 是在 Python3.x 版本中用于连接 MySQL 服务器的一个库,Python2 中则使用 mysqldb。
PyMySQL 遵循 Python 数据库 API v2.0 规范,并包含了 pure-Python MySQL 客户端库。
以下实例链接 Mysql 的 TESTDB 数据库:
python
#!/usr/bin/python3
import pymysql
# 打开数据库连接
db = pymysql.connect(host='localhost',
user='testuser',
password='test123',
database='TESTDB')
# 使用 cursor() 方法创建一个游标对象 cursor
cursor = db.cursor()
# 使用 execute() 方法执行 SQL 查询
cursor.execute("SELECT VERSION()")
# 使用 fetchone() 方法获取单条数据.
data = cursor.fetchone()
print ("Database version : %s " % data)
# 关闭数据库连接
db.close()四、网络编程
Python 提供了两个级别访问的网络服务。:
- 低级别的网络服务支持基本的 Socket,它提供了标准的 BSD Sockets API,可以访问底层操作系统Socket接口的全部方法。
- 高级别的网络服务模块 SocketServer, 它提供了服务器中心类,可以简化网络服务器的开发。
socket()函数
Python 中,我们用 socket() 函数来创建套接字,语法格式如下:
python
socket.socket([family[, type[, proto]]])Socket 对象(内建)方法
| 函数 | 描述 |
|---|---|
| 服务器端套接字 | |
| s.bind() | 绑定地址(host,port)到套接字, 在AF_INET下,以元组(host,port)的形式表示地址。 |
| s.listen() | 开始TCP监听。backlog指定在拒绝连接之前,操作系统可以挂起的最大连接数量。该值至少为1,大部分应用程序设为5就可以了。 |
| s.accept() | 被动接受TCP客户端连接,(阻塞式)等待连接的到来 |
| 客户端套接字 | |
| s.connect() | 主动初始化TCP服务器连接,。一般address的格式为元组(hostname,port),如果连接出错,返回socket.error错误。 |
| s.connect_ex() | connect()函数的扩展版本,出错时返回出错码,而不是抛出异常 |
| 公共用途的套接字函数 | |
| s.recv() | 接收TCP数据,数据以字符串形式返回,bufsize指定要接收的最大数据量。flag提供有关消息的其他信息,通常可以忽略。 |
| s.send() | 发送TCP数据,将string中的数据发送到连接的套接字。返回值是要发送的字节数量,该数量可能小于string的字节大小。 |
| s.sendall() | 完整发送TCP数据。将string中的数据发送到连接的套接字,但在返回之前会尝试发送所有数据。成功返回None,失败则抛出异常。 |
| s.recvfrom() | 接收UDP数据,与recv()类似,但返回值是(data,address)。其中data是包含接收数据的字符串,address是发送数据的套接字地址。 |
| s.sendto() | 发送UDP数据,将数据发送到套接字,address是形式为(ipaddr,port)的元组,指定远程地址。返回值是发送的字节数。 |
| s.close() | 关闭套接字 |
| s.getpeername() | 返回连接套接字的远程地址。返回值通常是元组(ipaddr,port)。 |
| s.getsockname() | 返回套接字自己的地址。通常是一个元组(ipaddr,port) |
| s.setsockopt(level,optname,value) | 设置给定套接字选项的值。 |
| s.getsockopt(level,optname.buflen) | 返回套接字选项的值。 |
| s.settimeout(timeout) | 设置套接字操作的超时期,timeout是一个浮点数,单位是秒。值为None表示没有超时期。一般,超时期应该在刚创建套接字时设置,因为它们可能用于连接的操作(如connect()) |
| s.gettimeout() | 返回当前超时期的值,单位是秒,如果没有设置超时期,则返回None。 |
| s.fileno() | 返回套接字的文件描述符。 |
| s.setblocking(flag) | 如果 flag 为 False,则将套接字设为非阻塞模式,否则将套接字设为阻塞模式(默认值)。非阻塞模式下,如果调用 recv() 没有发现任何数据,或 send() 调用无法立即发送数据,那么将引起 socket.error 异常。 |
| s.makefile() | 创建一个与该套接字相关连的文件 |
简单实例
我们使用 socket 模块的 socket 函数来创建一个 socket 对象。socket 对象可以通过调用其他函数来设置一个 socket 服务。
现在我们可以通过调用 bind(hostname, port) 函数来指定服务的 port(端口)。
接着,我们调用 socket 对象的 accept 方法。该方法等待客户端的连接,并返回 connection 对象,表示已连接到客户端。
python
#!/usr/bin/python3
# 文件名:server.py
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
serversocket = socket.socket(
socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
port = 9999
# 绑定端口号
serversocket.bind((host, port))
# 设置最大连接数,超过后排队
serversocket.listen(5)
while True:
# 建立客户端连接
clientsocket,addr = serversocket.accept()
print("连接地址: %s" % str(addr))
msg='欢迎访问菜鸟教程!'+ "\r\n"
clientsocket.send(msg.encode('utf-8'))
clientsocket.close()
python
#!/usr/bin/python3
# 文件名:client.py
# 导入 socket、sys 模块
import socket
import sys
# 创建 socket 对象
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 获取本地主机名
host = socket.gethostname()
# 设置端口号
port = 9999
# 连接服务,指定主机和端口
s.connect((host, port))
# 接收小于 1024 字节的数据
msg = s.recv(1024)
s.close()
print (msg.decode('utf-8'))五、多线程
Python3 线程中常用的两个模块为:
- _thread
- threading(推荐使用)
thread 模块已被废弃。用户可以使用 threading 模块代替。所以,在 Python3 中不能再使用"thread" 模块。为了兼容性,Python3 将 thread 重命名为 "_thread"。
参数说明:
- function - 线程函数。
- args - 传递给线程函数的参数,他必须是个tuple类型。
- kwargs - 可选参数。
python
#!/usr/bin/python3
import _thread
import time
# 为线程定义一个函数
def print_time( threadName, delay):
count = 0
while count < 5:
time.sleep(delay)
count += 1
print ("%s: %s" % ( threadName, time.ctime(time.time()) ))
# 创建两个线程
try:
_thread.start_new_thread( print_time, ("Thread-1", 2, ) )
_thread.start_new_thread( print_time, ("Thread-2", 4, ) )
except:
print ("Error: 无法启动线程")
while 1:
pass使用 threading 模块创建线程
可以通过直接从 threading.Thread 继承创建一个新的子类,并实例化后调用 start() 方法启动新线程,即它调用了线程的 run() 方法:
python
#!/usr/bin/python3
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, delay):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.delay = delay
def run(self):
print ("开始线程:" + self.name)
print_time(self.name, self.delay, 5)
print ("退出线程:" + self.name)
def print_time(threadName, delay, counter):
while counter:
if exitFlag:
threadName.exit()
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print ("退出主线程")线程同步
使用 Thread 对象的 Lock 和 Rlock 可以实现简单的线程同步,这两个对象都有 acquire 方法和 release 方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到 acquire 和 release 方法之间。如下:
多线程的优势在于可以同时运行多个任务(至少感觉起来是这样)。但是当线程需要共享数据时,可能存在数据不同步的问题。为了避免这种情况,引入了锁的概念。
锁有两种状态------锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。
经过这样的处理,打印列表时要么全部输出0,要么全部输出1,不会再出现一半0一半1的尴尬场面。
python
#!/usr/bin/python3
import threading
import time
class myThread (threading.Thread):
def __init__(self, threadID, name, delay):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.delay = delay
def run(self):
print ("开启线程: " + self.name)
# 获取锁,用于线程同步
threadLock.acquire()
print_time(self.name, self.delay, 3)
# 释放锁,开启下一个线程
threadLock.release()
def print_time(threadName, delay, counter):
while counter:
time.sleep(delay)
print ("%s: %s" % (threadName, time.ctime(time.time())))
counter -= 1
threadLock = threading.Lock()
threads = []
# 创建新线程
thread1 = myThread(1, "Thread-1", 1)
thread2 = myThread(2, "Thread-2", 2)
# 开启新线程
thread1.start()
thread2.start()
# 添加线程到线程列表
threads.append(thread1)
threads.append(thread2)
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")线程优先级队列
Python 的 Queue 模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。
这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。
Queue 模块中的常用方法:
- Queue.qsize() 返回队列的大小
- Queue.empty() 如果队列为空,返回True,反之False
- Queue.full() 如果队列满了,返回True,反之False
- Queue.full 与 maxsize 大小对应
- Queue.get(block\[, timeout])获取队列,timeout等待时间
- Queue.get_nowait() 相当Queue.get(False)
- Queue.put(item) 写入队列,timeout等待时间
- Queue.put_nowait(item) 相当Queue.put(item, False)
- Queue.task_done() 在完成一项工作之后,Queue.task_done()函数向任务已经完成的队列发送一个信号
- Queue.join() 实际上意味着等到队列为空,再执行别的操作
python
#!/usr/bin/python3
import queue
import threading
import time
exitFlag = 0
class myThread (threading.Thread):
def __init__(self, threadID, name, q):
threading.Thread.__init__(self)
self.threadID = threadID
self.name = name
self.q = q
def run(self):
print ("开启线程:" + self.name)
process_data(self.name, self.q)
print ("退出线程:" + self.name)
def process_data(threadName, q):
while not exitFlag:
queueLock.acquire()
if not workQueue.empty():
data = q.get()
queueLock.release()
print ("%s processing %s" % (threadName, data))
else:
queueLock.release()
time.sleep(1)
threadList = ["Thread-1", "Thread-2", "Thread-3"]
nameList = ["One", "Two", "Three", "Four", "Five"]
queueLock = threading.Lock()
workQueue = queue.Queue(10)
threads = []
threadID = 1
# 创建新线程
for tName in threadList:
thread = myThread(threadID, tName, workQueue)
thread.start()
threads.append(thread)
threadID += 1
# 填充队列
queueLock.acquire()
for word in nameList:
workQueue.put(word)
queueLock.release()
# 等待队列清空
while not workQueue.empty():
pass
# 通知线程是时候退出
exitFlag = 1
# 等待所有线程完成
for t in threads:
t.join()
print ("退出主线程")六、XML解析
Python 有三种方法解析 XML:ElementTree、SAX 以及 DOM。
1. ElementTree
xml.etree.ElementTree 是 Python 标准库中用于处理 XML 的模块,它提供了简单而高效的 API,用于解析和生成 XML 文档。
2.SAX (simple API for XML )
Python 标准库包含 SAX 解析器,SAX 用事件驱动模型,通过在解析 XML 的过程中触发一个个的事件并调用用户定义的回调函数来处理 XML 文件。
3.DOM(Document Object Model)
将 XML 数据在内存中解析成一个树,通过对树的操作来操作 XML。
例如:
XML
<collection shelf="New Arrivals">
<movie title="Enemy Behind">
<type>War, Thriller</type>
<format>DVD</format>
<year>2003</year>
<rating>PG</rating>
<stars>10</stars>
<description>Talk about a US-Japan war</description>
</movie>
<movie title="Transformers">
<type>Anime, Science Fiction</type>
<format>DVD</format>
<year>1989</year>
<rating>R</rating>
<stars>8</stars>
<description>A schientific fiction</description>
</movie>
<movie title="Trigun">
<type>Anime, Action</type>
<format>DVD</format>
<episodes>4</episodes>
<rating>PG</rating>
<stars>10</stars>
<description>Vash the Stampede!</description>
</movie>
<movie title="Ishtar">
<type>Comedy</type>
<format>VHS</format>
<rating>PG</rating>
<stars>2</stars>
<description>Viewable boredom</description>
</movie>
</collection>Python 使用 ElementTree 解析 xml
xml.etree.ElementTree 是 Python 标准库中用于处理 XML 的模块。
以下是 xml.etree.ElementTree 模块的一些关键概念和用法:
ElementTree 和 Element 对象:
- ElementTree: ElementTree 类是 XML 文档的树形表示。它包含一个或多个 Element 对象,代表整个 XML 文档。
- Element: Element 对象是 XML 文档中元素的表示。每个元素都有一个标签、一组属性和零个或多个子元素。
解析 XML
fromstring() 方法: 使用 fromstring() 方法可以将包含XML数据的字符串转换为 Element 对象:
python
import xml.etree.ElementTree as ET
xml_string = '<root><element>Some data</element></root>'
root = ET.fromstring(xml_string)parse() 方法: 如果XML数据存储在文件中,可以使用 parse() 方法来解析整个 XML 文档:
python
tree = ET.parse('example.xml')
root = tree.getroot()遍历 XML 树
find() 方法: 使用 find() 方法可以查找具有指定标签的第一个子元素:
python
title_element = root.find('title')findall() 方法: 使用 findall() 方法可以查找具有指定标签的所有子元素:
python
book_elements = root.findall('book')访问元素的属性和文本内容
attrib 属性: 通过 attrib 属性可以访问元素的属性:
python
price = book_element.attrib['price']text 属性: 通过 text 属性可以访问元素的文本内容:
python
title_text = title_element.text创建 XML
Element() 构造函数: 使用 Element() 构造函数可以创建新的元素:
python
new_element = ET.Element('new_element')SubElement() 函数: 使用 SubElement() 函数可以创建具有指定标签的子元素:
python
new_sub_element = ET.SubElement(root, 'new_sub_element')修改 XML
修改元素的属性和文本内容: 直接修改元素的 attrib 和 text 属性。
删除元素: 使用 remove() 方法可以删除元素:
python
root.remove(title_element)Python 使用 SAX 解析 xml
SAX 是一种基于事件驱动的API。
利用 SAX 解析 XML 文档牵涉到两个部分: 解析器 和事件处理器。
解析器负责读取 XML 文档,并向事件处理器发送事件,如元素开始跟元素结束事件。
而事件处理器则负责对事件作出响应,对传递的 XML 数据进行处理。
- 1、对大型文件进行处理;
- 2、只需要文件的部分内容,或者只需从文件中得到特定信息。
- 3、想建立自己的对象模型的时候。
在 Python 中使用 sax 方式处理 xml 要先引入 xml.sax 中的 parse 函数,还有 xml.sax.handler 中的 ContentHandler。
ContentHandler 类方法介绍
characters(content) 方法
调用时机:
从行开始,遇到标签之前,存在字符,content 的值为这些字符串。
从一个标签,遇到下一个标签之前, 存在字符,content 的值为这些字符串。
从一个标签,遇到行结束符之前,存在字符,content 的值为这些字符串。
标签可以是开始标签,也可以是结束标签。
startDocument() 方法
文档启动的时候调用。
endDocument() 方法
解析器到达文档结尾时调用。
startElement(name, attrs) 方法
遇到XML开始标签时调用,name 是标签的名字,attrs 是标签的属性值字典。
endElement(name) 方法
遇到XML结束标签时调用。
以下方法创建一个新的解析器对象并返回。
python
xml.sax.make_parser( [parser_list] )以下方法创建一个 SAX 解析器并解析xml文档:
python
xml.sax.parse( xmlfile, contenthandler[, errorhandler])参数说明:
- xmlfile - xml文件名
- contenthandler - 必须是一个 ContentHandler 的对象
- errorhandler - 如果指定该参数,errorhandler 必须是一个 SAX ErrorHandler 对象
parseString 方法创建一个 XML 解析器并解析 xml 字符串:
python
xml.sax.parseString(xmlstring, contenthandler[, errorhandler])解析XML实例
python
#!/usr/bin/python3
import xml.sax
class MovieHandler( xml.sax.ContentHandler ):
def __init__(self):
self.CurrentData = ""
self.type = ""
self.format = ""
self.year = ""
self.rating = ""
self.stars = ""
self.description = ""
# 元素开始调用
def startElement(self, tag, attributes):
self.CurrentData = tag
if tag == "movie":
print ("*****Movie*****")
title = attributes["title"]
print ("Title:", title)
# 元素结束调用
def endElement(self, tag):
if self.CurrentData == "type":
print ("Type:", self.type)
elif self.CurrentData == "format":
print ("Format:", self.format)
elif self.CurrentData == "year":
print ("Year:", self.year)
elif self.CurrentData == "rating":
print ("Rating:", self.rating)
elif self.CurrentData == "stars":
print ("Stars:", self.stars)
elif self.CurrentData == "description":
print ("Description:", self.description)
self.CurrentData = ""
# 读取字符时调用
def characters(self, content):
if self.CurrentData == "type":
self.type = content
elif self.CurrentData == "format":
self.format = content
elif self.CurrentData == "year":
self.year = content
elif self.CurrentData == "rating":
self.rating = content
elif self.CurrentData == "stars":
self.stars = content
elif self.CurrentData == "description":
self.description = content
if ( __name__ == "__main__"):
# 创建一个 XMLReader
parser = xml.sax.make_parser()
# 关闭命名空间
parser.setFeature(xml.sax.handler.feature_namespaces, 0)
# 重写 ContextHandler
Handler = MovieHandler()
parser.setContentHandler( Handler )
parser.parse("movies.xml")
python
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Year: 2003
Rating: PG
Stars: 10
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Year: 1989
Rating: R
Stars: 8
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Stars: 10
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Stars: 2
Description: Viewable boredom使用xml.dom解析xml
文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。
一个 DOM 的解析器在解析一个 XML 文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后你可以利用DOM 提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。
Python 中用 xml.dom.minidom 来解析 xml 文件,实例如下:
python
#!/usr/bin/python3
from xml.dom.minidom import parse
import xml.dom.minidom
# 使用minidom解析器打开 XML 文档
DOMTree = xml.dom.minidom.parse("movies.xml")
collection = DOMTree.documentElement
if collection.hasAttribute("shelf"):
print ("Root element : %s" % collection.getAttribute("shelf"))
# 在集合中获取所有电影
movies = collection.getElementsByTagName("movie")
# 打印每部电影的详细信息
for movie in movies:
print ("*****Movie*****")
if movie.hasAttribute("title"):
print ("Title: %s" % movie.getAttribute("title"))
type = movie.getElementsByTagName('type')[0]
print ("Type: %s" % type.childNodes[0].data)
format = movie.getElementsByTagName('format')[0]
print ("Format: %s" % format.childNodes[0].data)
rating = movie.getElementsByTagName('rating')[0]
print ("Rating: %s" % rating.childNodes[0].data)
description = movie.getElementsByTagName('description')[0]
print ("Description: %s" % description.childNodes[0].data)
python
Root element : New Arrivals
*****Movie*****
Title: Enemy Behind
Type: War, Thriller
Format: DVD
Rating: PG
Description: Talk about a US-Japan war
*****Movie*****
Title: Transformers
Type: Anime, Science Fiction
Format: DVD
Rating: R
Description: A schientific fiction
*****Movie*****
Title: Trigun
Type: Anime, Action
Format: DVD
Rating: PG
Description: Vash the Stampede!
*****Movie*****
Title: Ishtar
Type: Comedy
Format: VHS
Rating: PG
Description: Viewable boredom七、JSON数据解析
Python3 中可以使用 json 模块来对 JSON 数据进行编解码,它包含了两个函数:
- **json.dumps():**对数据进行编码。
- **json.loads():**对数据进行解码。
Python 编码为 JSON 类型转换对应表:
| Python | JSON |
|---|---|
| dict | object |
| list, tuple | array |
| str | string |
| int, float, int- & float-derived Enums | number |
| True | true |
| False | false |
| None | null |
JSON 解码为 Python 类型转换对应表:
| JSON | Python |
|---|---|
| object | dict |
| array | list |
| string | str |
| number (int) | int |
| number (real) | float |
| true | True |
| false | False |
| null | None |
json.dumps 与 json.loads 实例
python
#!/usr/bin/python3
import json
# Python 字典类型转换为 JSON 对象
data = {
'no' : 1,
'name' : 'Runoob',
'url' : 'https://www.runoob.com'
}
json_str = json.dumps(data)
print ("Python 原始数据:", repr(data))
print ("JSON 对象:", json_str)
python
#!/usr/bin/python3
import json
# Python 字典类型转换为 JSON 对象
data1 = {
'no' : 1,
'name' : 'Runoob',
'url' : 'http://www.runoob.com'
}
json_str = json.dumps(data1)
print ("Python 原始数据:", repr(data1))
print ("JSON 对象:", json_str)
# 将 JSON 对象转换为 Python 字典
data2 = json.loads(json_str)
print ("data2['name']: ", data2['name'])
print ("data2['url']: ", data2['url'])
python
# 写入 JSON 数据
with open('data.json', 'w') as f:
json.dump(data, f)
# 读取数据
with open('data.json', 'r') as f:
data = json.load(f)v八、日期和时间
Python 提供了一个 time 和 calendar 模块可以用于格式化日期和时间。
时间间隔是以秒为单位的浮点小数。
每个时间戳都以自从 1970 年 1 月 1 日午夜(历元)经过了多长时间来表示。
Python 的 time 模块下有很多函数可以转换常见日期格式。如函数 time.time() 用于获取当前时间戳, 如下实例:
python
#!/usr/bin/python3
import time # 引入time模块
ticks = time.time()
print ("当前时间戳为:", ticks)
python
当前时间戳为: 1459996086.7115328获取格式化的时间
python
#!/usr/bin/python3
import time
localtime = time.asctime( time.localtime(time.time()) )
print ("本地时间为 :", localtime)
python
本地时间为 : Thu Apr 7 10:29:13 2016我们可以使用 time 模块的 strftime 方法来格式化日期:
python
time.strftime(format[, t])
python
#!/usr/bin/python3
import time
# 格式化成2016-03-20 11:45:39形式
print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()))
# 格式化成Sat Mar 28 22:24:24 2016形式
print (time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()))
# 将格式字符串转换为时间戳
a = "Sat Mar 28 22:24:24 2016"
print (time.mktime(time.strptime(a,"%a %b %d %H:%M:%S %Y")))
python
2016-04-07 10:29:46
Thu Apr 07 10:29:46 2016
1459175064.0python中时间日期格式化符号:
- %y 两位数的年份表示(00-99)
- %Y 四位数的年份表示(000-9999)
- %m 月份(01-12)
- %d 月内中的一天(0-31)
- %H 24小时制小时数(0-23)
- %I 12小时制小时数(01-12)
- %M 分钟数(00=59)
- %S 秒(00-59)
- %a 本地简化星期名称
- %A 本地完整星期名称
- %b 本地简化的月份名称
- %B 本地完整的月份名称
- %c 本地相应的日期表示和时间表示
- %j 年内的一天(001-366)
- %p 本地A.M.或P.M.的等价符
- %U 一年中的星期数(00-53)星期天为星期的开始
- %w 星期(0-6),星期天为星期的开始
- %W 一年中的星期数(00-53)星期一为星期的开始
- %x 本地相应的日期表示
- %X 本地相应的时间表示
- %Z 当前时区的名称
- %% %号本身
获取某月日历
Calendar 模块有很广泛的方法用来处理年历和月历,例如打印某月的月历:
python
#!/usr/bin/python3
import calendar
cal = calendar.month(2016, 1)
print ("以下输出2016年1月份的日历:")
print (cal)Time 模块
| 序号 | 函数及描述 | 实例 |
|---|---|---|
| 1 | time.altzone 返回格林威治西部的夏令时地区的偏移秒数。如果该地区在格林威治东部会返回负值(如西欧,包括英国)。对夏令时启用地区才能使用。 | 以下实例展示了 altzone()函数的使用方法: >>> import time >>> print ("time.altzone %d " % time.altzone) time.altzone -28800 |
| 2 | time.asctime(tupletime) 接受时间元组并返回一个可读的形式为"Tue Dec 11 18:07:14 2008"(2008年12月11日 周二18时07分14秒)的24个字符的字符串。 | 以下实例展示了 asctime()函数的使用方法: >>> import time >>> t = time.localtime() >>> print ("time.asctime(t): %s " % time.asctime(t)) time.asctime(t): Thu Apr 7 10:36:20 2016 |
| 3 | time.clock() 用以浮点数计算的秒数返回当前的CPU时间。用来衡量不同程序的耗时,比time.time()更有用。 | 实例 由于该方法依赖操作系统,在 Python 3.3 以后不被推荐,而在 3.8 版本中被移除,需使用下列两个函数替代。 time.perf_counter() # 返回系统运行时间 time.process_time() # 返回进程运行时间 |
| 4 | time.ctime(secs) 作用相当于asctime(localtime(secs)),未给参数相当于asctime() | 以下实例展示了 ctime()函数的使用方法: >>> import time >>> print ("time.ctime() : %s" % time.ctime()) time.ctime() : Thu Apr 7 10:51:58 2016 |
| 5 | time.gmtime(secs) 接收时间戳(1970纪元后经过的浮点秒数)并返回格林威治天文时间下的时间元组t。注:t.tm_isdst始终为0 | 以下实例展示了 gmtime()函数的使用方法: >>> import time >>> print ("gmtime :", time.gmtime(1455508609.34375)) gmtime : time.struct_time(tm_year=2016, tm_mon=2, tm_mday=15, tm_hour=3, tm_min=56, tm_sec=49, tm_wday=0, tm_yday=46, tm_isdst=0) |
| 6 | time.localtime(secs 接收时间戳(1970纪元后经过的浮点秒数)并返回当地时间下的时间元组t(t.tm_isdst可取0或1,取决于当地当时是不是夏令时)。 | 以下实例展示了 localtime()函数的使用方法: >>> import time >>> print ("localtime(): ", time.localtime(1455508609.34375)) localtime(): time.struct_time(tm_year=2016, tm_mon=2, tm_mday=15, tm_hour=11, tm_min=56, tm_sec=49, tm_wday=0, tm_yday=46, tm_isdst=0) |
| 7 | time.mktime(tupletime) 接受时间元组并返回时间戳(1970纪元后经过的浮点秒数)。 | 实例 |
| 8 | time.sleep(secs) 推迟调用线程的运行,secs指秒数。 | 以下实例展示了 sleep()函数的使用方法: #!/usr/bin/python3 import time print ("Start : %s" % time.ctime()) time.sleep( 5 ) print ("End : %s" % time.ctime()) |
| 9 | time.strftime(fmt,tupletime) 接收以时间元组,并返回以可读字符串表示的当地时间,格式由fmt决定。 | 以下实例展示了 strftime()函数的使用方法: >>> import time >>> print (time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) 2016-04-07 11:18:05 |
| 10 | time.strptime(str,fmt='%a %b %d %H:%M:%S %Y') 根据fmt的格式把一个时间字符串解析为时间元组。 | 以下实例展示了 strptime()函数的使用方法: >>> import time >>> struct_time = time.strptime("30 Nov 00", "%d %b %y") >>> print ("返回元组: ", struct_time) 返回元组: time.struct_time(tm_year=2000, tm_mon=11, tm_mday=30, tm_hour=0, tm_min=0, tm_sec=0, tm_wday=3, tm_yday=335, tm_isdst=-1) |
| 11 | time.time( ) 返回当前时间的时间戳(1970纪元后经过的浮点秒数)。 | 以下实例展示了 time()函数的使用方法: >>> import time >>> print(time.time()) 1459999336.1963577 |
| 12 | time.tzset() 根据环境变量TZ重新初始化时间相关设置。 | 实例 |
| 13 | time.perf_counter() 返回计时器的精准时间(系统的运行时间),包含整个系统的睡眠时间。由于返回值的基准点是未定义的,所以,只有连续调用的结果之间的差才是有效的。 | 实例 |
| 14 | time.process_time() 返回当前进程执行 CPU 的时间总和,不包含睡眠时间。由于返回值的基准点是未定义的,所以,只有连续调用的结果之间的差才是有效的。 |
Time模块包含了以下2个非常重要的属性:
| 序号 | 属性及描述 |
|---|---|
| 1 | time.timezone 属性time.timezone是当地时区(未启动夏令时)距离格林威治的偏移秒数(>0,美洲;<=0大部分欧洲,亚洲,非洲)。 |
| 2 | time.tzname 属性time.tzname包含一对根据情况的不同而不同的字符串,分别是带夏令时的本地时区名称,和不带的。 |
日历(Calendar)模块
| 序号 | 函数及描述 |
|---|---|
| 1 | calendar.calendar(year,w=2,l=1,c=6) 返回一个多行字符串格式的 year 年年历,3 个月一行,间隔距离为 c。 每日宽度间隔为w字符。每行长度为 21* W+18+2* C。l 是每星期行数。 |
| 2 | calendar.firstweekday( ) 返回当前每周起始日期的设置。默认情况下,首次载入 calendar 模块时返回 0,即星期一。 |
| 3 | calendar.isleap(year) 是闰年返回 True,否则为 False。 >>> import calendar >>> print(calendar.isleap(2000)) True >>> print(calendar.isleap(1900)) False |
| 4 | calendar.leapdays(y1,y2) 返回在Y1,Y2两年之间的闰年总数。 |
| 5 | calendar.month(year,month,w=2,l=1) 返回一个多行字符串格式的year年month月日历,两行标题,一周一行。每日宽度间隔为w字符。每行的长度为7* w+6。l是每星期的行数。 |
| 6 | calendar.monthcalendar(year,month) 返回一个整数的单层嵌套列表。每个子列表装载代表一个星期的整数。Year年month月外的日期都设为0;范围内的日子都由该月第几日表示,从1开始。 |
| 7 | calendar.monthrange(year,month) 返回两个整数。第一个是该月的星期几,第二个是该月有几天。星期几是从0(星期一)到 6(星期日)。 >>> import calendar >>> calendar.monthrange(2014, 11) (5, 30) (5, 30)解释:5 表示 2014 年 11 月份的第一天是周六,30 表示 2014 年 11 月份总共有 30 天。 |
| 8 | calendar.prcal(year, w=0, l=0, c=6, m=3) 相当于 print (calendar.calendar(year, w=0, l=0, c=6, m=3))。 |
| 9 | calendar.prmonth(theyear, themonth, w=0, l=0) 相当于 print(calendar.month(theyear, themonth, w=0, l=0))。 |
| 10 | calendar.setfirstweekday(weekday) 设置每周的起始日期码。0(星期一)到6(星期日)。 |
| 11 | calendar.timegm(tupletime) 和time.gmtime相反:接受一个时间元组形式,返回该时刻的时间戳(1970纪元后经过的浮点秒数)。 |
| 12 | calendar.weekday(year,month,day) 返回给定日期的日期码。0(星期一)到6(星期日)。月份为 1(一月) 到 12(12月)。 |
九、内置函数
常见分类
-
数值计算:
abs()、round()、min()、max()、sum() -
类型转换:
int()、float()、str()、list()、tuple() -
迭代与函数式: code>map()、
filter()、zip()、enumerate() -
反射与对象:
type()、isinstance()、getattr()、setattr() -
输入输出:
print()、input()、open()
函数速查表
|---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|---|
| | 内置函数 ||||| |-----------------------------------------------------------------------------------------------|-----------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------|--------------------------------------------------------------------------------------------------| | abs() | dict() | help() | min() | setattr() | | all() | dir() | hex() | next() | slice() | | any() | divmod() | id() | object() | sorted() | | ascii() | enumerate() | input() | oct() | staticmethod() | | bin() | eval() | int() | open() | str() | | bool() | exec() | isinstance() | ord() | sum() | | bytearray() | filter() | issubclass() | pow() | super() | | bytes() | float() | iter() | print() | tuple() | | callable() | format() | len() | property() | type() | | chr() | frozenset() | list() | range() | vars() | | classmethod() | getattr() | locals() | repr() | zip() | | compile() | globals() | map() | reversed() | import() | | complex() | hasattr() | max() | round() | reload() | | delattr() | hash() | memoryview() | set() | | | |
| | |
| | |
十、urllib
Python urllib 库用于操作网页 URL,并对网页的内容进行抓取处理。
本文主要介绍 Python3 的 urllib。
urllib 包 包含以下几个模块:
- urllib.request - 打开和读取 URL。
- urllib.error - 包含 urllib.request 抛出的异常。
- urllib.parse - 解析 URL。
- urllib.robotparser - 解析 robots.txt 文件。
urllib.request
urllib.request 定义了一些打开 URL 的函数和类,包含授权验证、重定向、浏览器 cookies等。
urllib.request 可以模拟浏览器的一个请求发起过程。
我们可以使用 urllib.request 的 urlopen 方法来打开一个 URL,语法格式如下:
python
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- timeout:设置访问超时时间。
- cafile 和 capath:cafile 为 CA 证书, capath 为 CA 证书的路径,使用 HTTPS 需要用到。
- cadefault:已经被弃用。
- context:ssl.SSLContext类型,用来指定 SSL 设置。
python
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
print(myURL.read())read() 是读取整个网页内容,我们可以指定读取的长度:
python
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
print(myURL.read(300))除了 read() 函数外,还包含以下两个读取网页内容的函数:
- readline() - 读取文件的一行内容
python
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
print(myURL.readline()) #读取一行内容readlines() - 读取文件的全部内容,它会把读取的内容赋值给一个列表变量。
python
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
lines = myURL.readlines()
for line in lines:
print(line) 我们在对网页进行抓取时,经常需要判断网页是否可以正常访问,这里我们就可以使用 getcode() 函数获取网页状态码,返回 200 说明网页正常,返回 404 说明网页不存在:
python
import urllib.request
myURL1 = urllib.request.urlopen("https://www.runoob.com/")
print(myURL1.getcode()) # 200
try:
myURL2 = urllib.request.urlopen("https://www.runoob.com/no.html")
except urllib.error.HTTPError as e:
if e.code == 404:
print(404) # 404如果要将抓取的网页保存到本地,可以使用 Python3 File write() 方法 函数:
python
from urllib.request import urlopen
myURL = urlopen("https://www.runoob.com/")
f = open("runoob_urllib_test.html", "wb")
content = myURL.read() # 读取网页内容
f.write(content)
f.close()URL 的编码与解码可以使用 urllib.request.quote() 与 urllib.request.unquote() 方法:
python
import urllib.request
encode_url = urllib.request.quote("https://www.runoob.com/") # 编码
print(encode_url)
unencode_url = urllib.request.unquote(encode_url) # 解码
print(unencode_url)模拟头部信息
我们抓取网页一般需要对 headers(网页头信息)进行模拟,这时候需要使用到 urllib.request.Request 类:
python
class urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=False, method=None)- url:url 地址。
- data:发送到服务器的其他数据对象,默认为 None。
- headers:HTTP 请求的头部信息,字典格式。
- origin_req_host:请求的主机地址,IP 或域名。
- unverifiable:很少用这个参数,用于设置网页是否需要验证,默认是 False。
- method:请求方法, 如 GET、POST、DELETE、PUT等。
urllib.error
urllib.error 模块为 urllib.request 所引发的异常定义了异常类,基础异常类是 URLError。
urllib.error 包含了两个方法,URLError 和 HTTPError。
URLError 是 OSError 的一个子类,用于处理程序在遇到问题时会引发此异常(或其派生的异常),包含的属性 reason 为引发异常的原因。
HTTPError 是 URLError 的一个子类,用于处理特殊 HTTP 错误例如作为认证请求的时候,包含的属性 code 为 HTTP 的状态码, reason 为引发异常的原因,headers 为导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
对不存在的网页抓取并处理异常:
python
import urllib.request
import urllib.error
myURL1 = urllib.request.urlopen("https://www.runoob.com/")
print(myURL1.getcode()) # 200
try:
myURL2 = urllib.request.urlopen("https://www.runoob.com/no.html")
except urllib.error.HTTPError as e:
if e.code == 404:
print(404) # 404urllib.parse
python
urllib.parse.urlparse(urlstring, scheme='', allow_fragments=True)urlstring 为 字符串的 url 地址,scheme 为协议类型,
allow_fragments 参数为 false,则无法识别片段标识符。相反,它们被解析为路径,参数或查询组件的一部分,并 fragment 在返回值中设置为空字符串。
python
from urllib.parse import urlparse
o = urlparse("https://www.runoob.com/?s=python+%E6%95%99%E7%A8%8B")
print(o)
python
ParseResult(scheme='https', netloc='www.runoob.com', path='/', params='', query='s=python+%E6%95%99%E7%A8%8B', fragment='')从结果可以看出,内容是一个元组,包含 6 个字符串:协议,位置,路径,参数,查询,判断。
我们可以直接读取协议内容:
python
from urllib.parse import urlparse
o = urlparse("https://www.runoob.com/?s=python+%E6%95%99%E7%A8%8B")
print(o.scheme)https
完整内容如下:
| 属性 | 索引 | 值 | 值(如果不存在) |
|---|---|---|---|
scheme |
0 | URL协议 | scheme 参数 |
netloc |
1 | 网络位置部分 | 空字符串 |
path |
2 | 分层路径 | 空字符串 |
params |
3 | 最后路径元素的参数 | 空字符串 |
query |
4 | 查询组件 | 空字符串 |
fragment |
5 | 片段识别 | 空字符串 |
username |
用户名 | None |
|
password |
密码 | None |
|
hostname |
主机名(小写) | None |
|
port |
端口号为整数(如果存在) | None |
urllib.robotparser
urllib.robotparser 用于解析 robots.txt 文件。
robots.txt(统一小写)是一种存放于网站根目录下的 robots 协议,它通常用于告诉搜索引擎对网站的抓取规则。
urllib.robotparser 提供了 RobotFileParser 类,语法如下:
python
class urllib.robotparser.RobotFileParser(url='')这个类提供了一些可以读取、解析 robots.txt 文件的方法:
-
set_url(url) - 设置 robots.txt 文件的 URL。
-
read() - 读取 robots.txt URL 并将其输入解析器。
-
parse(lines) - 解析行参数。
-
can_fetch(useragent, url) - 如果允许 useragent 按照被解析 robots.txt 文件中的规则来获取 url 则返回 True。
-
mtime() -返回最近一次获取 robots.txt 文件的时间。 这适用于需要定期检查 robots.txt 文件更新情况的长时间运行的网页爬虫。
-
modified() - 将最近一次获取 robots.txt 文件的时间设置为当前时间。
-
crawl_delay(useragent) -为指定的 useragent 从 robots.txt 返回 Crawl-delay 形参。 如果此形参不存在或不适用于指定的 useragent 或者此形参的 robots.txt 条目存在语法错误,则返回 None。
-
request_rate(useragent) -以 named tuple RequestRate(requests, seconds) 的形式从 robots.txt 返回 Request-rate 形参的内容。 如果此形参不存在或不适用于指定的 useragent 或者此形参的 robots.txt 条目存在语法错误,则返回 None。
-
site_maps() - 以 list() 的形式从 robots.txt 返回 Sitemap 形参的内容。 如果此形参不存在或者此形参的 robots.txt 条目存在语法错误,则返回 None。