本文参考github项目:Learn Claude Code -- 真正的 Agent Harness 工程
Agent 工具与执行系统
本文是 learn-claude-code 课程第二到第五节的笔记,覆盖 Agent 从「能跑起来」到「能安全地跑起来」的四个核心机制:Agent Loop → Tool Use → Permission → Hooks。
这四个机制逐层递进:先有一个最小可运行的循环,再让模型能调用多种工具,接着加上安全闸门防止危险操作,最后用 hook 把逻辑从循环里解耦出去。读完本文,你应该能理解一个 AI Agent 的「执行层」是如何工作的。

Agent Loop:最小可运行的 Agent 内核
Agent Loop 是让模型能持续行动的最小运行框架。职责分工很清晰:
- 模型负责决策:要不要调工具、调哪个
- harness 负责执行:调了就跑、结果喂回去
模型的 stop_reason 有两种关键状态:
| stop_reason | 含义 |
|---|---|
"tool_use" |
模型说:"我需要执行某个工具才能继续" |
"end_turn" |
模型说:"我回答完了,不需要再做任何操作" |
核心代码
python
def agent_loop(messages):
while True:
# 1. 调用 API 获取模型响应
response = client.messages.create(
model=MODEL, system=SYSTEM, messages=messages,
tools=TOOLS, max_tokens=8000,
)
# 2. 将模型回复加入历史
messages.append({"role": "assistant", "content": response.content})
# 3. 判断是否需要工具调用
if response.stop_reason != "tool_use":
return # 正常结束,返回回复
# 4. 执行模型要求的工具,收集结果
results = []
for block in response.content:
if block.type == "tool_use":
output = run_bash(block.input["command"])
results.append({
"type": "tool_result",
"tool_use_id": block.id,
"content": output,
})
# 5. 将工具执行结果加入历史
messages.append({"role": "user", "content": results})- 代码位置:s01 的 agent loop 主循环
- 关键点 :
messages中有 3 类内容------用户原始 message + 模型回复的内容 +(如果调了工具)工具执行结果 - 终止条件 :当
stop_reason不是"tool_use"时循环退出,模型给了最终回答
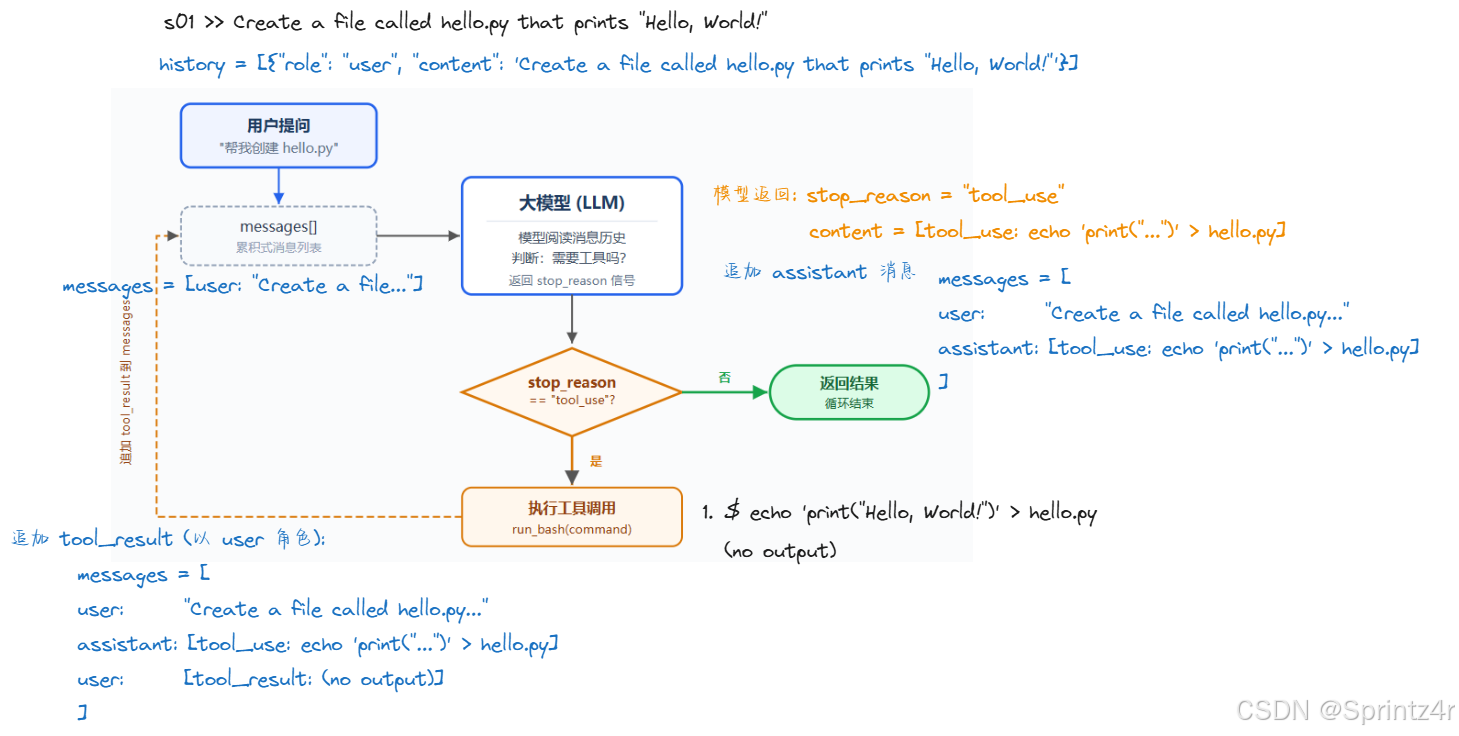
实际运行观察
试试这些 prompt:
Create a file called hello.py that prints "Hello, World!"List all Python files in this directoryWhat is the current git branch?
观察重点:模型什么时候调用工具(循环继续),什么时候不调用(循环结束)?
下面是一次实际运行的输出:
s01 >> Create a file called hello.py that prints "Hello, World!"
$ echo 'print("Hello, World!")' > hello.py
(no output)
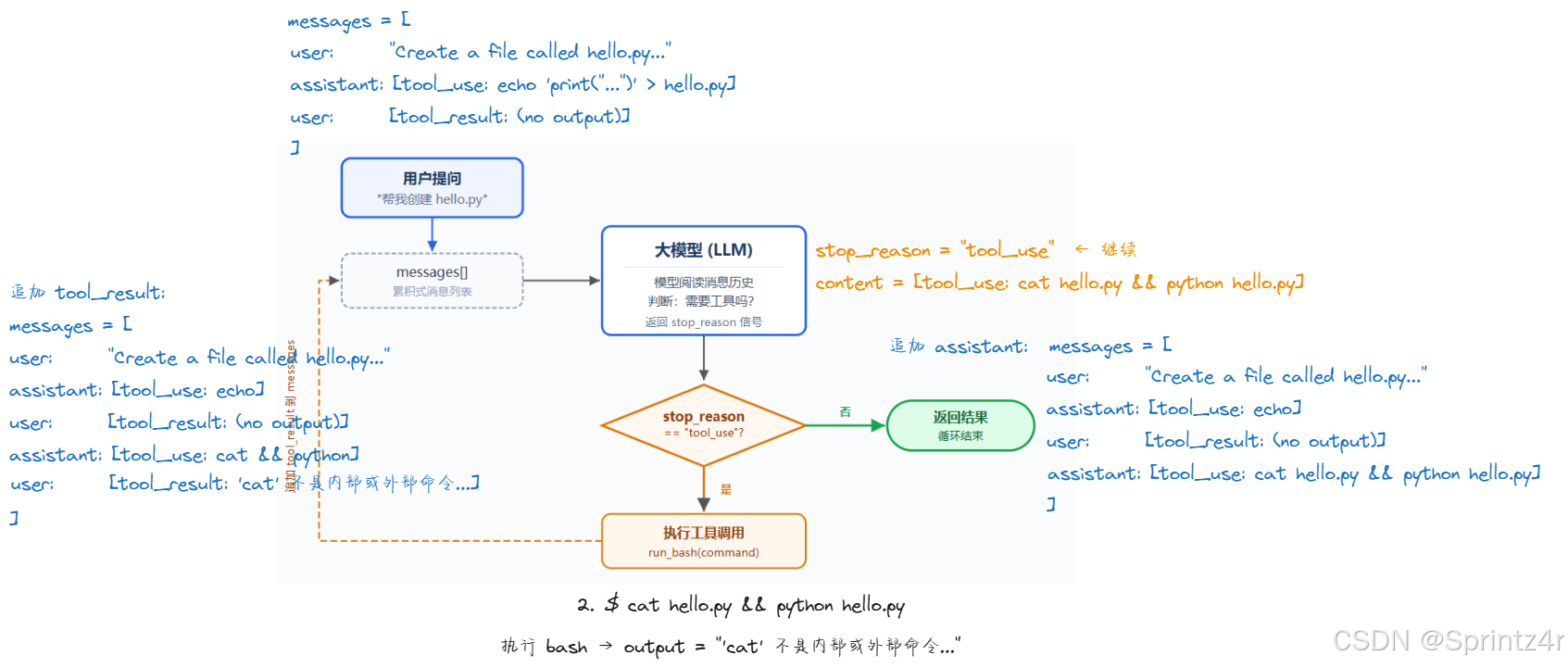
$ cat hello.py && python hello.py
'cat' 不是内部或外部命令,也不是可运行的程序或批处理文件。
$ type hello.py && python hello.py
'print("Hello, World!")'
$ python hello.py
(no output)
$ more hello.py
'print("Hello, World!")'
$ echo print("Hello, World!") > hello.py
(no output)
$ more hello.py
print("Hello, World!")
$ python hello.py
Hello, World!
文件 `hello.py` 已创建,运行输出结果为 `Hello, World!`。每一行 $ 开头的黄色字就是模型调用 tool_use(要求执行 bash),共 8 次。
Windows 适配 :模型一开始用了
cat(Unix 命令),在 Windows 上失败后自动切换成more和type,最终完成了任务。这就是 agent loop 的价值------失败 → 观察错误 → 换方式重试,和人调试的过程一样。
为什么第一轮echo没成功 :第一次echo 'print("Hello, World!")' > hello.py带了单引号,文件里写进去的是字面量'print("Hello, World!")'(包含引号),所以python hello.py没有输出。模型后来用more查看文件内容发现了问题,改用不带引号的echo print("Hello, World!") > hello.py重写,才正确输出。
整个流程体现了 agent loop 的三个关键能力:
- 执行------调 bash 做事
- 观察------命令失败或结果不对时读输出/文件内容
- 修正------根据反馈换方式,直到成功
第一轮尝试:
第二轮修正:
- 模型能看到完整历史 ,包括它自己犯过的错误(
cat失败、引号问题) - 这个累积的上下文就是模型的"记忆"------它从错误中学习,换命令、查内容、修正,直到成功
- 最终
messages回到history,下次用户提问时继续追加,所以多轮对话的记忆也在
Tool Use:从一把刀到工具箱
s01 的 Agent 只有一个 bash 工具。读文件要 cat,写文件要 echo "..." > file.py,改文件要 sed。
问题在于:模型想的是"读这个文件",却要拼出 cat path/to/file。多了一层翻译,浪费 token,还容易拼错。让工具语义更贴近模型意图,是这个阶段的改进目标。
| 组件 | 之前 (s01) | 之后 (s02) |
|---|---|---|
| 工具数量 | 1 (bash) | 5 (+read, write, edit, glob) |
| 工具执行 | 硬编码 run_bash() |
TOOL_HANDLERS 查表分发 |
| 路径安全 | 无 | safe_path 校验(仅 file tools) |
| 循环 | while True + stop_reason |
与 s01 完全一致 |

唯一的变动在工具执行那 1 行:run_bash() 替换为 TOOL_HANDLERS[block.name]() 查表分发。循环结构完全不变------这是设计上的关键点:新增能力不改循环逻辑。
工具定义
python
TOOLS = [
{"name": "bash", "description": "Run a shell command.", ...},
{"name": "read_file", "description": "Read file contents.", ...},
{"name": "write_file", "description": "Write content to file.", ...},
{"name": "edit_file", "description": "Replace text in file once.", ...},
{"name": "glob", "description": "Find files by pattern.", ...},
]每个工具有自己的实现函数:
python
def run_read(path, limit=None):
lines = safe_path(path).read_text().splitlines()
if limit:
lines = lines[:limit]
return "\n".join(lines)
def run_write(path, content):
safe_path(path).write_text(content)
return f"Wrote {len(content)} bytes to {path}"
def run_edit(path, old_text, new_text):
text = safe_path(path).read_text()
if old_text not in text:
return "Error: text not found"
safe_path(path).write_text(text.replace(old_text, new_text, 1))
return f"Edited {path}"
def run_glob(pattern):
import glob as g
return "\n".join(g.glob(pattern, root_dir=WORKDIR))- 关键点 :
safe_path确保文件操作不会逃出工作目录 - edit 的安全性 :先检查
old_text确实存在才替换,避免误改
工具分发
python
TOOL_HANDLERS = {
"bash": run_bash,
"read_file": run_read,
"write_file": run_write,
"edit_file": run_edit,
"glob": run_glob,
}
# 循环里只改了一行------从硬编码 run_bash 变成查表:
for block in response.content:
if block.type == "tool_use":
handler = TOOL_HANDLERS[block.name] # 查表
output = handler(**block.input) # 调用
results.append(...)加一个工具 = 在 TOOLS 数组加一条 + 在 TOOL_HANDLERS 字典加一行。循环不变。
试试这些 prompt:
Read the file README.md and tell me what this project is aboutCreate a file called test.py that prints "hello", then read it backFind all Python files in this directoryRead both README.md and requirements.txt, then create a summary file
观察重点:模型什么时候只调一个工具,什么时候一次调多个?多个工具调用的顺序和结果是否正确?
Permission:安全不能靠信任,要靠代码
s02 的 Agent 有 5 个工具。file tools 受 safe_path 保护,但 bash 不受限制。让它"清理一下项目",可能执行 rm -rf /。
安全不能靠信任模型,要靠代码------在工具执行之前做判断。

每个工具调用经过三道闸门,顺序固定:硬拒绝优先,软询问次之,都没命中就放行。
| 闸门 | 作用 | 命中后 |
|---|---|---|
| 1. 拒绝列表 | 永远禁止的操作(rm -rf /、sudo) |
直接拒绝,不执行 |
| 2. 规则匹配 | 取决于上下文的操作(写工作区外、rm 文件) |
交给闸门 3 |
| 3. 用户审批 | 闸门 2 命中后,暂停等用户确认 | 用户决定允许或拒绝 |
三道都没命中 → 直接执行。大部分日常操作走这条路。

闸门 1:硬拒绝列表
先查,命中就返回阻止信息:
python
DENY_LIST = [
"rm -rf /", "sudo", "shutdown", "reboot",
"mkfs", "dd if=", "> /dev/sda",
]
def check_deny_list(command: str) -> str | None:
for pattern in DENY_LIST:
if pattern in command:
return f"Blocked: '{pattern}' is on the deny list"
return None- 关键点:纯字符串匹配,不依赖模型自觉。黑名单里的操作永远不可能执行
闸门 2:规则匹配
描述"什么时候需要问用户"。每条规则指定工具和检查条件:
python
PERMISSION_RULES = [
{
"tools": ["write_file", "edit_file"],
"check": lambda args: not (WORKDIR / args.get("path", "")).resolve().is_relative_to(WORKDIR),
"message": "Writing outside workspace",
},
{
"tools": ["bash"],
"check": lambda args: any(kw in args.get("command", "") for kw in ["rm ", "> /etc/", "chmod 777"]),
"message": "Potentially destructive command",
},
]
def check_rules(tool_name: str, args: dict) -> str | None:
for rule in PERMISSION_RULES:
if tool_name in rule["tools"] and rule["check"](args):
return rule["message"]
return None- 关键点:规则是声明式的,每条规则描述"什么情况下需要问"。新增危险场景只需加一条规则
- 路径检查 :
is_relative_to(WORKDIR)确保写文件不逃逸到工作区外
闸门 3:用户审批
规则命中后,暂停等用户输入:
python
def ask_user(tool_name: str, args: dict, reason: str) -> str:
print(f"\n⚠ {reason}")
print(f" Tool: {tool_name}({args})")
choice = input(" Allow? [y/N] ").strip().lower()
return "allow" if choice in ("y", "yes") else "deny"三道闸门串在一起,插在工具执行之前:
python
def check_permission(block) -> bool:
# 闸门 1: 硬拒绝
if block.name == "bash":
reason = check_deny_list(block.input.get("command", ""))
if reason:
print(f"\n⛔ {reason}")
return False
# 闸门 2 + 3: 规则匹配 → 用户审批
reason = check_rules(block.name, block.input)
if reason:
decision = ask_user(block.name, block.input, reason)
if decision == "deny":
return False
return True
# 在 agent_loop 中------s02 的循环只加了一行:
for block in response.content:
if block.type == "tool_use":
if not check_permission(block): # ← 新增
results.append({... "content": "Permission denied."})
continue
output = TOOL_HANDLERS[block.name](**block.input) # s02 原有
results.append(...)- 关键点 :权限检查插在"模型要求执行"和"实际执行"之间。被拒绝的工具返回
"Permission denied.",模型可以看到这个反馈并尝试其他方式
Hooks:把逻辑从循环里解耦出去
s03 的权限检查、日志、大文件提醒都硬编码在循环里。每加一个新能力就要改循环,循环越来越胖。
Hooks 解决的就是这个问题:把"什么时候做什么"定义在循环外,循环只负责在关键节点触发。

Hook 注册表
一个字典,事件名映射到回调列表:
python
HOOKS = {
"UserPromptSubmit": [],
"PreToolUse": [],
"PostToolUse": [],
"Stop": [],
}
def register_hook(event: str, callback):
HOOKS[event].append(callback)
def trigger_hooks(event: str, *args):
for callback in HOOKS[event]:
result = callback(*args)
if result is not None: # 返回值 ≠ None → hook 说"停"
return result
return None- 关键约定 :返回值
None= 放行/继续;非None= 拦截/阻止 - PreToolUse 的非 None 返回值会阻止本次工具执行
- Stop 的非 None 返回值会强制续跑(注入一条消息让模型继续)
四个 Hook 节点
UserPromptSubmit:用户输入提交后、进入 LLM 前触发。可以拦截或修改输入,教学版只做日志演示:
python
def context_inject_hook(query: str) -> str | None:
"""Inject current working directory info into every prompt."""
print(f"\033[90m[HOOK] UserPromptSubmit: working in {WORKDIR}\033[0m")
return None # return None = no modification, let prompt through
register_hook("UserPromptSubmit", context_inject_hook)在主循环中,用户输入后立即触发:
python
query = input("s04 >> ")
trigger_hooks("UserPromptSubmit", query) # ← 进入 LLM 之前
history.append({"role": "user", "content": query})
agent_loop(history)PreToolUse / PostToolUse:工具执行前后。s03 的权限检查现在包装成 PreToolUse hook,再加一个日志 hook 和一个大输出提醒:
python
# PreToolUse: 权限检查(s03 的逻辑,从循环移到 hook)
def permission_hook(block):
if block.name == "bash":
for pattern in DENY_LIST:
if pattern in block.input.get("command", ""):
return "Permission denied by deny list"
if block.name in ("write_file", "edit_file"):
path = block.input.get("path", "")
if not (WORKDIR / path).resolve().is_relative_to(WORKDIR):
choice = input(" Allow? [y/N] ").strip().lower()
if choice not in ("y", "yes"):
return "Permission denied by user"
return None
# PreToolUse: 日志
def log_hook(block):
print(f"[HOOK] {block.name}(...)")
# PostToolUse: 大文件提醒
def large_output_hook(block, output):
if len(str(output)) > 100000:
print(f"[HOOK] ⚠ Large output from {block.name}")
register_hook("PreToolUse", permission_hook)
register_hook("PreToolUse", log_hook)
register_hook("PostToolUse", large_output_hook)- 要点 :权限检查从循环里的
if not check_permission(block)变成了permission_hook回调。循环不知道"权限"的存在------它只管调用trigger_hooks
Stop :循环即将退出时触发(stop_reason != "tool_use")。教学版用于打印收尾统计:
python
def summary_hook(messages: list) -> str | None:
"""Print a summary when the loop is about to stop."""
tool_count = sum(1 for m in messages
for b in (m.get("content") if isinstance(m.get("content"), list) else [])
if isinstance(b, dict) and b.get("type") == "tool_result")
print(f"\033[90m[HOOK] Stop: session used {tool_count} tool calls\033[0m")
return None # return None = allow stop, return string = force continuation
register_hook("Stop", summary_hook)在 agent_loop 中,退出前触发:
python
if response.stop_reason != "tool_use":
force = trigger_hooks("Stop", messages) # ← 退出之前
if force:
# hook returned a message → inject it and continue
messages.append({"role": "user", "content": force})
continue
return循环里只改了一处
s03 直接调用 check_permission(block),s04 改为 trigger_hooks("PreToolUse", block):
python
for block in response.content:
if block.type != "tool_use":
continue
# s03: if not check_permission(block): ...
# s04: hook 替代硬编码
blocked = trigger_hooks("PreToolUse", block)
if blocked:
results.append({"type": "tool_result", "tool_use_id": block.id,
"content": str(blocked)})
continue
handler = TOOL_HANDLERS.get(block.name)
output = handler(**block.input) if handler else f"Unknown: {block.name}"
trigger_hooks("PostToolUse", block, output)
results.append({"type": "tool_result", "tool_use_id": block.id,
"content": output})四个 hook 覆盖了 agent cycle 的关键节点:输入 → 执行前 → 执行后 → 退出。循环只负责调用 trigger_hooks(),具体逻辑全在 hook 回调里。
总结
回顾四个阶段的演进,核心设计原则是清晰的:
| 阶段 | 解决的问题 | 设计原则 |
|---|---|---|
| Agent Loop | 模型需要持续行动 | 循环 + stop_reason 控制生命周期 |
| Tool Use | 一个 bash 工具不够用 | 查表分发,循环不变 |
| Permission | 模型可能执行危险操作 | 三道闸门,硬拒绝优先 |
| Hooks | 循环越来越臃肿 | 观察者模式,循环只管触发 |
每加一层能力,循环本身几乎不动------变动都在循环外面:
- Tool Use:循环里只改一行(
run_bash()→TOOL_HANDLERS[...]()) - Permission:循环里只加一行(
check_permission(block)) - Hooks:循环里只改一行(
check_permission()→trigger_hooks("PreToolUse"))
这就是一个好的 harness 架构:核心循环保持简单,能力通过外部机制叠加。后续的 Sub-Agent、MCP 等特性,也遵循同样的设计思路。