提示词攻击与防御
- 1.提示词攻击
-
- [1.1 提示词注入 (](#1.1 提示词注入 ()
- [1.2 间接注入:](#1.2 间接注入:)
- [1.3 语义诱导与认知欺骗](#1.3 语义诱导与认知欺骗)
- 2.防御策略总览:四层防御体系
-
- [2.1 架构隔离(从系统设计层面根除风险)](#2.1 架构隔离(从系统设计层面根除风险))
- [2.2 输入层防御(而以质量的前置拦截网)](#2.2 输入层防御(而以质量的前置拦截网))
- [2.3 提示词加固(提升模型自身'免疫力')](#2.3 提示词加固(提升模型自身‘免疫力’))
- [2.4 输出层防御(生成内容的最后把关)](#2.4 输出层防御(生成内容的最后把关))
- [3. 总结与启示](#3. 总结与启示)
1.提示词攻击
1.1 提示词注入 (
指令覆盖,比如忽略之前所有指令;角色劫持/越狱:比如无所不知的顾问;权限冒充、嵌套注入)
1.2 间接注入:
文档注入(白底白字)、多模态隐写(隐藏水印、像素最低位)、数据投毒(错误数据写入训练集)
1.3 语义诱导与认知欺骗
假设/场景模拟(写小说)
道德豁免/研究借口(学术研究、漏洞分析)
共情/紧急场景(救人、绑架)
逆向诱导(为什么不能回答这个问题)
多轮渐进式攻击(温水煮青蛙)
2.防御策略总览:四层防御体系
2.1 架构隔离(从系统设计层面根除风险)

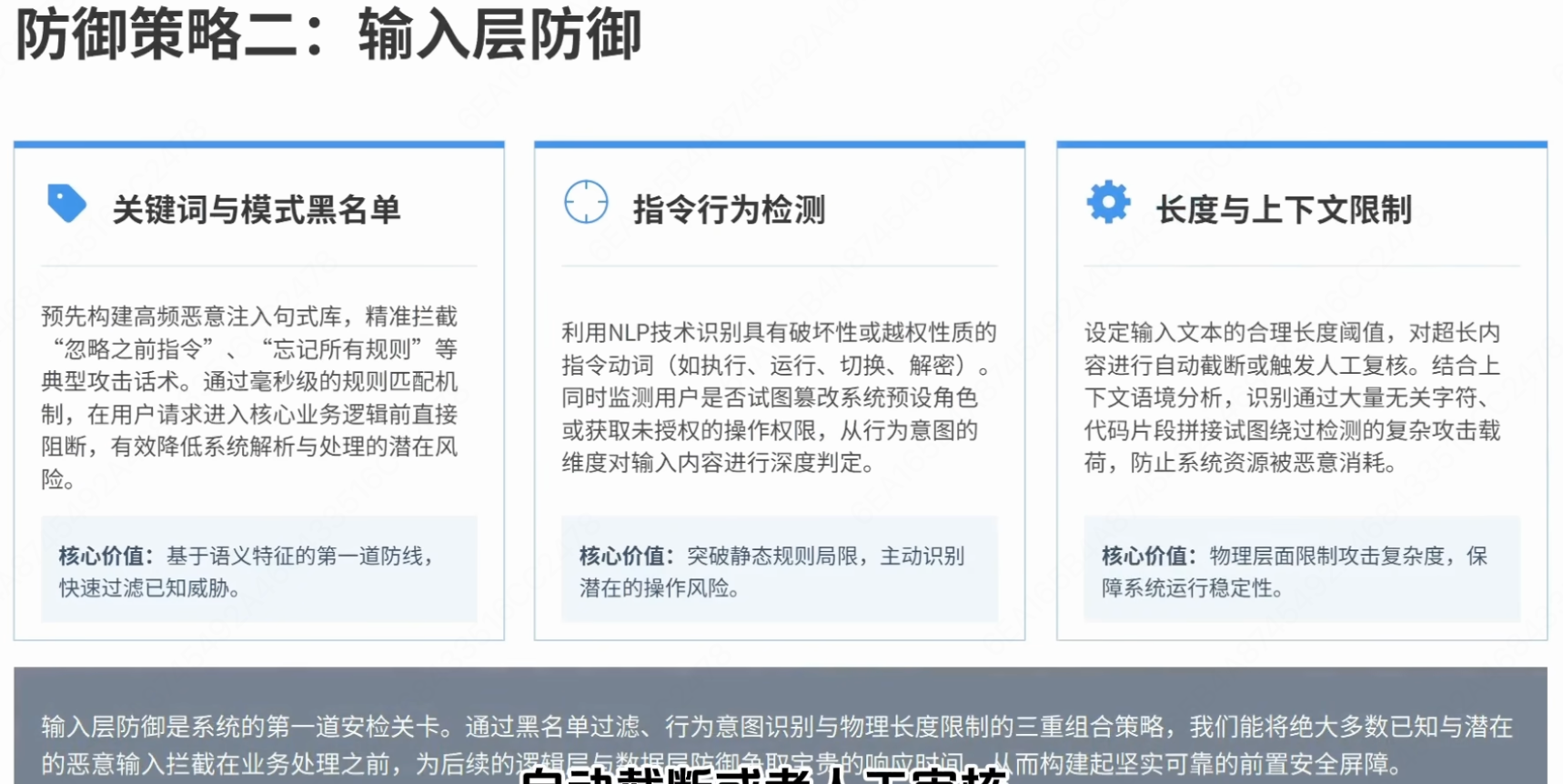
2.2 输入层防御(而以质量的前置拦截网)
2.3 提示词加固(提升模型自身'免疫力')

2.4 输出层防御(生成内容的最后把关)

3. 总结与启示
-
威胁无处不在
AI提示词攻击手法呈现出多样化与隐蔽化的趋势,从简单的指令注入到复杂的认知欺骗,风险无孔不入。这要求我们必须对潜在的安全漏洞保持高度警惕,不能有丝毫松懈。
**核心洞察:**攻击手段不断迭代,被动防御已无法应对当前的安全挑战。
-
防御需要体系化
单一的策略或技术手段难以奏效,必须构建从底层架构安全、到中间层策略治理再到顶层输出控制的全链路纵深防御体系,形成环环相扣的安全屏障。
核心洞察: 通过技术与管理的双重手段,建立主动且可持续的防御机制。
-
安全意识是关键
技术是基础,意识是防线。 无论是应用开发者还是终端用户,都需要充分了解大模型的风险边界,掌握安全使用规范,共同参与到AI应用的安全治理与维护中。
核心洞察: 提升全员安全素养,是降低人为风险最经济有效的途径。