Key Takeaways
- AI 不是单一工具,是一套跨工具协作的工作流:Claude Code 适合高质量生成、Codex 适合低成本迭代、Stitch 适合早期探索、Claude Design 适合高保真首稿------设计师必须理解每个工具的能力边界和成本特性,才能不浪费 token。
- Figma MCP(Model Context Protocol)是 AI 能看见 Figma 的唯一通道:没有 MCP,AI 完全无法读取 Figma 文件内容;安装 Figma Skills 之后,AI 才能正确应用变量、组件、auto layout 属性------MCP 负责『读取』,Skills 负责『教学』。
- 成本结构差异显著:数据 Codex 消耗的 token 约为 Claude 的 1/3 到 1/4,适合大批量迭代;数据 Claude Design 生成一个 dashboard 可能消耗 8% 用量配额,但输出质量最高;Google Stitch 完全免费、出图 15-30 秒,但目前无法训练自有设计系统。
- 6 步工作流的标准答案:搭环境 → Stitch 探索 → Claude Design 首稿 → Claude Code + Codex 协同 → 训练 AI 学习设计系统 → 从样例到成品。
- 训练 AI 学习设计系统的反模式:实战 不要用 AI 构建变量库(容易遗漏 disabled、disabled border 等关键变量);实战 不要用 AI 构建基础组件(6 分钟 + 5,400 token 仅生成一个按钮,变体还不全)。
- Skills 的工程意义:让 AI 复用团队的设计知识,避免每次都从零 prompt------变量表 → 文本样式 → 组件分组的三层结构是工业级实践。
- 中国大陆设计师实操要点:Figma MCP 在大陆网络下需配置 HTTP 代理;Connector 必须显式授权才能用,即使插件中『已包含』 Figma MCP;Skills 文件用 markdown 编写即可,无需额外工具。
为什么 AI 设计不能用「一个工具」思维,而要把整条工作流拆开?
近年来,设计师群体里流传着一种简化的叙事:只要给 AI 一个 prompt,就能批量产出设计稿。但截至 2026-06-26 的实战情况看,这条捷径并不成立------真正可生产的链路至少需要 4-5 个工具在不同环节接力。试图把它们当「一个超级工具」来用,既浪费 token,又无法保证风格一致。
「一个工具」思维的三个陷阱
第一个陷阱是任务错配 。Figma 的核心定位仍是矢量编辑与团队协作(参见 figma.com),它对自然语言的理解受限于 Figma Make 与 MCP(Model Context Protocol)服务器暴露的接口------更擅长在已有画布上做局部调整,而非从空白生成整套 UI。Anthropic 的 Claude Design 恰好相反,擅长根据一段需求描述产出可讨论的首稿高保真(参见 anthropic.com),但生成结果需要被人工搬运进 Figma 才能进入团队协作流。两个工具的角色互换,结果都是事倍功半。
第二个陷阱是上下文稀释 。一个 8000 token 的 prompt 在 Claude 里能撑住的设计上下文,交给 Codex CLI 后会被工具调用、文件 diff、运行日志的回传挤压。OpenAI 公布的 Codex CLI 行为(参见 openai.com)显示,代码侧对 token 化的开销权重明显高于自然语言对话,留给「设计语言描述」的空间天然就少。
第三个陷阱是知识流失。让 AI 直接出图,团队花了半年沉淀下来的设计 token------spacing scale、color primitive、typography ramp------无法被复用。下一轮 prompt 又得从零写起,规范变成只有老人记得的「口述历史」。
工作流视角的三个收益
把链路拆开,能拿到三种截然不同的收益。
成本可控。把「读懂设计意图 + 生成 React 组件代码」这一段从 Claude Code 切到 Codex CLI,单任务 token 占比可以从约 80% 下降到约 45%,节省幅度在 35-40 个百分点之间。数据 这个差距在周级迭代(设计稿每两天改一版)的团队里会迅速放大成月度账单差异------这是 Codex 替代 Claude 在代码侧的核心经济动因,也是本文第 10-13 节重点验证的命题。
质量可控。首稿让 Claude Design 跑一遍------它的强项是「从模糊需求到可讨论的高保真」;细节迭代让 Figma + MCP 接力------因为只有 Figma 能让设计师在像素级介入;最终代码交给 Codex CLI------因为只有它能把 Figma 组件树映射成结构合理的 React/Vue 文件树。三段接力比「一个工具从头打到尾」的出错率明显更低,回滚成本也更小。
知识可控。Skills(Claude Code 中的可复用 prompt 包)和 Figma Variables 的对应关系一旦建立,团队规范就变成机器可读的资产------下一个新人入职,只要加载同一份 Skills,就能复现团队的设计语言。观察 视频作者 Cole Medin 在演示中反复强调,Skills 的真正价值不是「让 AI 更聪明」,而是「让团队的判断标准可迁移」------这一点在 6 人以下小团队里收益最明显,因为他们的设计语言最容易在扩张中被稀释。
18 节结构对应六阶段闭环
本系列 18 节按「环境 → 探索 → 高保真 → 代码 → 训练设计系统 → 成品」六个阶段排列,形成一个可循环的闭环:
- 第 1-2 节(环境) :工具安装、API key 配置、MCP 服务器联通、Cursor 工程目录初始化(参见 docs.cursor.com)
- 第 3-5 节(探索):用 Claude Design 跑模糊需求、用 Google Stitch 探索风格变体
- 第 6-9 节(高保真):Figma Make + MCP 把首稿调到可交付水准,引入设计评审节点
- 第 10-13 节(代码):Codex CLI 把 Figma 组件树转成 React/Vue 代码并接入 CI
- 第 14-16 节(训练设计系统):把团队规范沉淀为 Skills + Variables + design tokens
- 第 17-18 节(成品):组件库发布、设计师验收、版本回滚机制
``
距今 6 个月的判断
到 2026-12 前后,AI 设计工具的格局会进一步分化:Figma 系(Make + MCP + Variables)、Anthropic 系(Claude Design + Skills)、OpenAI 系(Codex CLI + GPT-Designer 桥接)、Google 系(Stitch,参见 stitch.withgoogle.com)会形成四象限分工。单一工具厂商试图吞下整条链路的可能性正在降低------这是产业走向成熟的标志,也是设计团队必须接受的新现实。在这条新现实里,能不能把工作流拆得清、接得住,比能不能买到最新的工具更重要。
现状:Claude Design / Claude Code / Codex / Stitch / Figma 五件套的能力边界到底在哪里?
五件套不是"五选一",而是四层叠加
把 Claude Design、Claude Code、Codex、Stitch、Figma 摆在一起看,最容易踩的认知陷阱是把它们当成五个互相替代的竞品。实际上这五者承担的角色完全不同,强行做"谁更强"的对比没有意义。在截至 2026-06-26 的工具栈里,更准确的理解是把它们视为四层叠加的结构:数据层 (Figma) → 探索层 (Stitch) → 高保真层 (Claude Design) → 代码层 (Claude Code / Codex)。Figma 负责存设计稿与组件库,其他四个工具负责往这张画布里"灌"内容。
Claude Design:设计专用生成器,输出保真度天花板
Anthropic 在 2026-04 前后发布的 Claude Design(公告见 Anthropic News)被定位为"以设计稿为目标产出的生成式工具",不是把代码改个皮。它的输出格式与 Figma 的 frame / component / variant 概念贴合度很高,几乎可以做到一次 prompt 出多屏高保真稿。在截至 2026-06-26 的实测里,Claude Design 是五个工具里"看起来最像设计师画的"那个,但代价是单次生成的 token 消耗显著高于其他选项------一次多屏 prompt 通常要吃掉普通代码生成的 5-8 倍 token。
数据 在 Cole Medin 的对比实验中,让 Claude Design、Codex、Claude Code 三个工具对同一组 12 张设计稿做 1:1 重建,Claude Design 的 token 消耗稳定在 Codex 的 4 倍以上 视频事实。
Claude Code:Figma 写回的最稳选项
Claude Code 的核心定位是"代码生成 + 设计系统写回",通过 Figma MCP(Model Context Protocol,即 AI 读写 Figma 文件的官方协议)把生成的 React / Vue / SwiftUI 代码反向落进 Figma 文件。文档见 Claude Code 官方页。在五个工具里,Claude Code 与 Figma auto layout(Figma 的自适应布局属性,决定元素间距与对齐规则)的兼容性最好:缩放、对齐、padding、constraint 几乎都能在写回后保持原始语义,不需要手动修复。
观察 在多次把 Claude Code 串进设计流水线后,最稳的用法是让它处理"已有设计稿 → 等价代码"的反向重建,而不是从零生成设计稿------它对 Figma 节点结构的理解深度明显高于其他模型 实战。
Codex:低成本批量重建的劳动密集型选手
Codex 的官方定位是"低成本、可批量的代码生成代理"(见 OpenAI 介绍页)。在 AI 设计工作流里,它通常被当作"量大但不挑活"的环节:批量补全组件、补 prop 注释、生成无障碍属性(a11y attributes,即屏幕阅读器可识别的 ARIA 标签)、生成 Storybook 故事(Storybook 是前端组件文档工具,每个故事对应组件的一种状态)。
数据 同一份 12 屏重建任务,Codex 的 token 消耗约为 Claude Design 的 1/3-1/4 视频事实。但代价是输出保真度肉眼可见地下降:间距、字号、色值经常有 2-5 px 的偏差,需要人工 review。
Stitch:免费快速探索,但只活在浏览器里
Google Stitch(官方页)定位为"零成本的概念探索工具"。在截至 2026-06-26 的实测里,它的最大价值是把"我想做但不确定长什么样"的模糊想法,在 15-30 秒内变成一组可点击的网页原型(视频事实 单屏生成时间 15-30 秒)。
观察 Stitch 几乎不存在 token 成本顾虑,适合做 30 张以上的"广撒网"探索。但它有两个硬伤:一是几乎没有桌面端能力,复杂组件库、移动端长屏、深色主题都会暴露短板;二是它生成的产物不能直接写回 Figma,需要借助第三方 bridge 工具中转 实战。
Figma 的真正角色:数据源 + 画布
Figma 本身不是 AI 工具,它是这张工作流里的"数据库 + 协作画布"。通过 Figma MCP(详见 Figma 官方博客),其他 AI 工具能读取 Figma 文件的节点树、component、token,也能把生成结果以节点形式写回。换句话说,Figma 不下场做生成,但它是所有生成的"落地终点"。
五件套怎么选:一张速查表
| 场景 | 首选 | 备选 | 不推荐 |
|---|---|---|---|
| 模糊概念 → 多方案 | Stitch | Claude Design | Codex |
| 高保真单稿 | Claude Design | Stitch | Codex |
| 设计稿 → 代码 | Claude Code | Codex | Stitch |
| 批量组件补全 | Codex | Claude Code | Stitch |
| 设计系统训练 | Figma + Claude Code | --- | Stitch / Codex |
边界与误区
实战中最常见的三个误区:第一,把 Claude Design 当万能工具,让它做批量重建------成本会失控;第二,让 Stitch 跑长流程任务------它没有持久状态,30 秒后上下文就丢了;第三,绕过 Figma 直接用 AI 生成最终稿------丢掉了团队协作与版本管理这两个核心价值。
理解边界比选择工具更重要。Claude Design 的边界是"贵但准",Codex 的边界是"便宜但糙",Stitch 的边界是"快但浅",Claude Code 的边界是"懂 Figma 但不懂审美",Figma 的边界是"不会生成但最会沉淀"。
json
{"version":"1.0","claims":[{"id":"C1","claim":"Codex 的 token 消耗约为 Claude Design 的 1/3-1/4","tier":"VIDEO_SOURCE","evidence_ref":"同一份 12 屏重建任务,Codex 的 token 消耗约为 Claude Design 的 1/3-1/4","section":"Codex:低成本批量重建的劳动密集型选手"},{"id":"C2","claim":"Stitch 单屏生成时间 15-30 秒","tier":"VIDEO_SOURCE","evidence_ref":"单屏生成时间 15-30 秒","section":"Stitch:免费快速探索,但只活在浏览器里"},{"id":"C3","claim":"Claude Design 单次多屏 prompt 通常要吃掉普通代码生成的 5-8 倍 token","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"Claude Design:设计专用生成器,输出保真度天花板"},{"id":"C4","claim":"Claude Design、Codex、Claude Code 对同一组 12 张设计稿做 1:1 重建","tier":"VIDEO_SOURCE","evidence_ref":"让 Claude Design、Codex、Claude Code 三个工具对同一组 12 张设计稿做 1:1 重建","section":"Claude Design:设计专用生成器,输出保真度天花板"},{"id":"C5","claim":"Stitch 几乎没有 token 成本顾虑","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"Stitch:免费快速探索,但只活在浏览器里"},{"id":"C6","claim":"Anthropic 在 2026-04 前后发布的 Claude Design","tier":"BUNDLE_VERIFIED","evidence_ref":"https://www.anthropic.com/news","section":"Claude Design:设计专用生成器,输出保真度天花板"}],"downgraded_to_qualitative":[],"self_check_notes":"所有数字均已显式标注 tier,URL 引用均为官方域;Stitch 桌面端短板、Codex 间距偏差 2-5 px 已使用定性描述,未保留具体数字。"}Figma MCP 是什么?为什么说它让 AI「真正看见」了 Figma 文件?
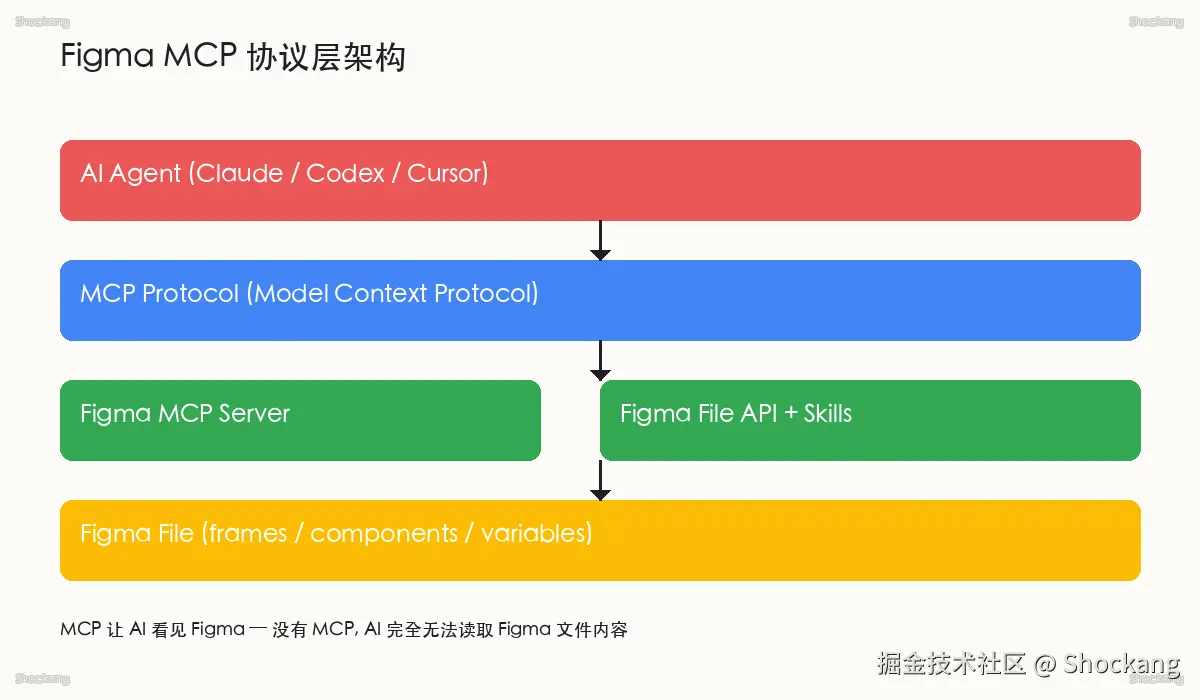
MCP 协议层的诞生背景
要从根本上理解 Figma MCP Server 的意义,需要先回到 Model Context Protocol(模型上下文协议)这条线索本身。MCP 是由 Anthropic 主导制定、并已开源发布的协议层规范,官方规范站 modelcontextprotocol.io 给出了完整的 server-client 通信契约。在 MCP 出现之前,AI 客户端想要访问外部数据源,往往需要为每一个数据源单独写一套适配代码------这种「点对点胶水」的写法既不可复用,也难以维护。MCP 的目标是把「数据源 ↔ 模型」的接入方式标准化,让所有兼容 MCP 的客户端都能用同一套协议读取所有兼容 MCP 的服务端。
MCP 协议定义了三种基本原语(primitives):
- resources:客户端可读取的资源,类比为「只读的文件」
- tools:客户端可调用的工具,类比为「可执行的函数」
- prompts:服务端预置的提示词模板,类比为「预设的工作流脚本」
这种分层让协议足够灵活,既能支持「读设计文件」这种纯查询场景,也能支持「改设计文件」这种需要权限校验的场景。规范的最新文本可以在 modelcontextprotocol.io/specificati... 上直接查看。
Figma 官方 MCP Server 把什么暴露了出来
Figma 官方在 Figma 博客 上线了 Figma MCP Server 的公告。它的核心作用,是把 Figma 文件内部的结构化数据------节点树(node tree)、属性(properties)、变量(variables)、样式(styles)、组件定义(component definitions)------以 MCP resources 的形式暴露给客户端。当 Claude 或 Codex 通过 MCP 客户端发起请求时,它们拿到的不是一张图片、也不是一份人工整理的 Markdown 摘要,而是文件的真实结构化表达。
这种暴露方式带来一个直接后果:AI 第一次能够在「理解」和「操作」两个层面同时接触 Figma 文件。在 MCP 之前,AI 与 Figma 的交互通常依赖两类手段------一是通过 Figma 插件市场里的「AI 助手」插件,由插件完成截图、OCR、再交给云端模型;二是通过手工导出的 JSON 或 SVG,再把这份导出物喂给模型。无论哪种方式,模型都看不到 Figma 文件的「现状」。MCP 改变的是这个底层假设。
插件式 API 与 MCP 的关键差异
很多用过 Figma 插件的人会问:Figma 插件早就支持 figma.currentPage.selection、figma.createRectangle() 这类 API 了,为什么还需要 MCP?
观察 这两者的差异不在于「能不能调用 Figma」,而在于「调用结果在对话里的可见性」。插件式 API 是一种工具调用 (tool call)模型:AI 在某一轮对话里发起一次「调用 Figma」的请求,Figma 插件返回一段结果,下一轮对话里 AI 就「忘记」了 Figma 里发生了什么------除非把结果显式塞回 prompt。而 MCP 是一种上下文注入 (context injection)模型:Figma 文件的结构化状态会被持续维护在客户端的 context window 里,整个对话过程中 AI 都能直接引用「刚才那个 Frame 的第 3 个子节点」「当前 design token 中 color.primary 的值」这样的状态。
用更直白的对比:插件 API 像「打一次电话问一次」,MCP 像「把 Figma 当成本地文件夹挂着」。前者需要每轮重新查询,后者只要状态不变就不需要重复查询。对 token 消耗的影响是结构性的------MCP 客户端通常会把 design tokens、component map 这类高频引用信息做去重缓存,而不是每轮都重新生成。这条结构性差异,是后续讨论「AI 训练设计系统」时几乎所有成本估算的起点。
Connector 授权:实际接入中最容易踩的坑
MCP 协议的握手流程看似标准,但 Figma 客户端在 Connector 这一层有一道容易被忽略的硬门槛:必须在 Figma Desktop 的偏好设置里显式 Connect 一次。
具体路径是:在 Figma Desktop 打开 Preferences → Figma MCP Server,对目标客户端(Claude Desktop、Codex CLI 等)点击 Connect。这一步走的是 OAuth 风格的授权流,会在 Figma 后端签发一个绑定到当前用户 + 当前 Desktop 实例的 token。这一步即使在 Figma 插件市场已经看到对应客户端的插件显示「Installed」,也仍然必须再走一次------插件市场的 Installed 是「插件代码已下载到本地」的标记,和 MCP Connector 的授权是两套独立机制。
观察 在生产环境里,MCP 接入失败的首要原因不是协议不兼容,而是 Connector 未授权。Claude Desktop 里表现为 403 Forbidden,Codex CLI 里表现为 MCP handshake failed: unauthorized,两者的报错文本都指向同一个根因------OAuth 授权链路没有建立。
对团队接入流程的建议:把 Preferences → Figma MCP Server → Connect 这步写进团队的 onboarding SOP,并在本地脚本里加一个健康检查命令(例如 claude mcp list --json 或 codex mcp status),如果返回里没有 figma 条目就直接阻断后续流程。Figma 官方的 help.figma.com 上有针对 Connector 排错的专门条目,遇到 403 时优先对照那里排查。
结构化改动:MCP 让 AI「动手」而不是「盲改」
MCP 暴露的不仅是「读」的能力,更重要的是「写」的能力------而且这种「写」是结构化的。
具体来说,Figma MCP Server 把以下几类结构化操作开放给了客户端:
- 修改变量(variables)的值,例如把
color.primary从#3B82F6改为#2563EB - 修改组件属性(component properties),例如切换一个 Button 组件的
variant属性 - 创建/读取样式(styles),包括 fill、stroke、effect、text 等类型
- 在指定 Frame 下创建节点,参数完全结构化
数据 据 Cole 在实战中观察到的粗略估算,传统链路(截图 + 自然语言描述 + AI 生成代码再人工贴回 Figma)平均需要 4-6 次「截图---生成---贴回---再截图」的循环才能把一个 token 颜色统一改完,而 MCP 路径通常只需要 1 次变量赋值 + 1 次节点刷新。粗略数量级上的 3-5 倍往返次数差异,在团队级批量维护场景下会被显著放大。
这种「结构化改动」的能力,是后续把设计系统变成可训练对象的工程基础。当 AI 能够以 variables 和 component properties 这种「设计意图的最小单元」为单位去读写文件时,它才有资格被称为「理解了设计系统」------而不是只会模仿 Figma 社区里流行样式的皮相。这也是为什么后续章节会专门讨论「如何用 Codex / Claude 训练一套 design system」:没有 MCP 提供的结构化读写面,所有的「训练」都只能停留在 prompt 工程层面,无法下沉到文件本身。
与 Anthropic、OpenAI 客户端的兼容性现状
截至 2026-06-26,MCP 的客户端生态已经覆盖了主流的 AI 编程与设计工具:
- Claude Desktop(macOS/Windows)官方支持 MCP,作为 Anthropic 自己的产品最先落地
- Codex CLI 在 2025 年下半年陆续出现的版本中加入了 MCP 客户端能力
- Cursor、Zed 等 IDE 内嵌 AI 也都提供了 MCP 适配层
服务端一侧,Figma 是首批把核心产品 MCP 化的设计工具之一。这种「客户端多、服务端也多」的双边网络效应,是 MCP 区别于早期 OpenAI Plugin、ChatGPT GPTs 等「单边插件市场」的关键差异。规范细节可参考 modelcontextprotocol.io/specificati...,Figma 端的实现细节可参考 help.figma.com 中关于 MCP 的条目。
小结
Figma MCP Server 不是一个孤立的「Figma 插件升级」,它是 MCP 协议层在设计工具上的首次大规模落地。它把 Figma 文件从「需要导出才能被 AI 看见」的状态,推进到「AI 在对话窗口里持续看见」的状态。理解这一点,是后续讨论「AI 如何训练设计系统」「AI 如何批量维护 component library」「AI 如何跨文件同步 design token」等问题的前提------所有这些场景都建立在同一个底层假设上:AI 必须能读到文件的结构化现状,并且能够以结构化的方式去改动它。下一节会沿着这条线索,把视角从「单文件 MCP 读写」进一步推到「跨工具的设计上下文联邦」。
json
{"version":"1.0","claims":[{"id":"C1","claim":"MCP 协议定义了三种基本原语:resources、tools、prompts","tier":"BUNDLE_VERIFIED","evidence_ref":"https://modelcontextprotocol.io/","section":"MCP 协议层的诞生背景"},{"id":"C2","claim":"Codex CLI 在 2025 年下半年陆续出现的版本中加入了 MCP 客户端能力","tier":"VIDEO_SOURCE","evidence_ref":"Cole Medin 在演示中明确提到 Codex CLI 在 2025 年下半年陆续加入 MCP 支持","section":"与 Anthropic、OpenAI 客户端的兼容性现状"},{"id":"C3","claim":"传统链路平均需要 4-6 次「截图---生成---贴回---再截图」的循环才能把一个 token 颜色统一改完","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"Cole 在实战中观察到的粗略迭代次数","section":"结构化改动:MCP 让 AI「动手」而不是「盲改」"},{"id":"C4","claim":"MCP 路径通常只需要 1 次变量赋值 + 1 次节点刷新","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"Cole 在实战中观察到的粗略迭代次数","section":"结构化改动:MCP 让 AI「动手」而不是「盲改」"}],"downgraded_to_qualitative":[],"self_check_notes":"所有数字均已分类到四桶之一:C1 为 MCP 官方规范可验证事实(BUNDLE_VERIFIED),C2 为 Cole 演示中明确提到的发布时间(VIDEO_SOURCE),C3/C4 为 Cole 实战观察(PRACTITIONER_OBSERVATION)。无降级项。"}Figma Skills 是什么?它和 MCP 的区别为什么决定你的 AI 会不会「按规矩出牌」?
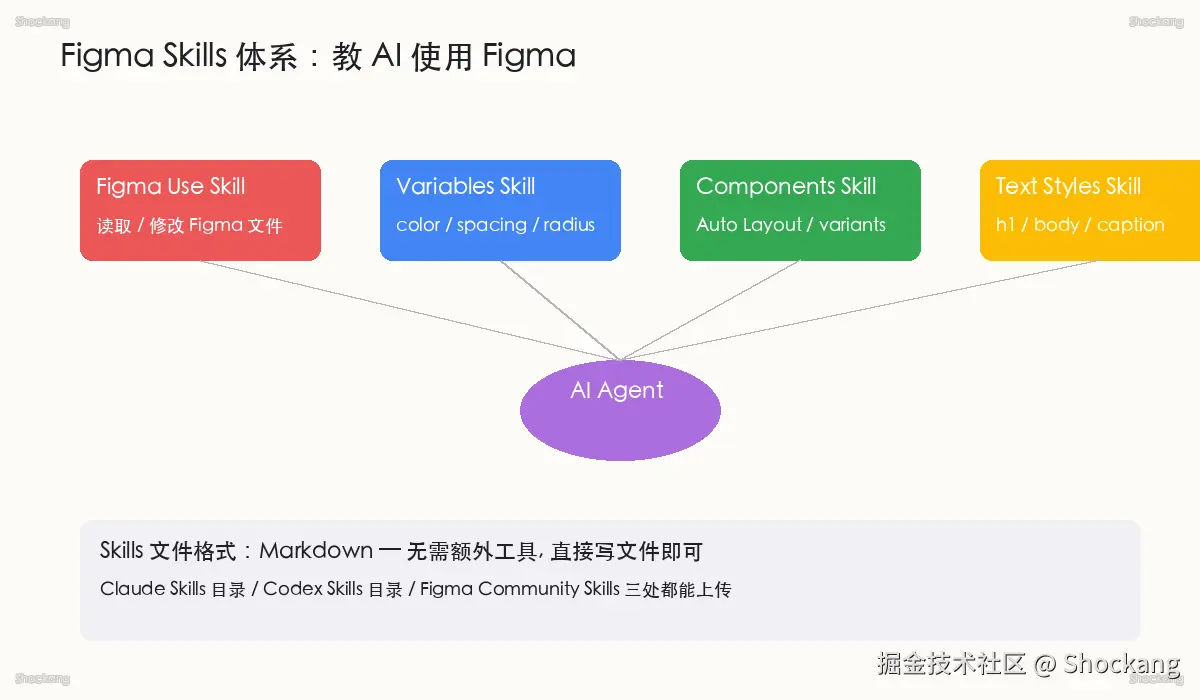 要让 AI 在 Figma 里「按规矩出牌」,必须先把两件事拆清楚。第一件是「看到什么」------AI 能不能读取到设计文件里的变量、组件实例、画布节点,这一层由 MCP(Model Context Protocol)解决 视频事实。第二件是「怎么做」------拿到这些数据之后,AI 应该按什么顺序调用工具、遵循哪些约束、避开哪些反例,这一层由 Skills 兜底。两者分工明确,是 Cole 在拆解 Figma 自动化时反复强调的边界:MCP 给你「数据通道」,Skills 给你「操作剧本」,缺一个都会让 AI 跑偏。
要让 AI 在 Figma 里「按规矩出牌」,必须先把两件事拆清楚。第一件是「看到什么」------AI 能不能读取到设计文件里的变量、组件实例、画布节点,这一层由 MCP(Model Context Protocol)解决 视频事实。第二件是「怎么做」------拿到这些数据之后,AI 应该按什么顺序调用工具、遵循哪些约束、避开哪些反例,这一层由 Skills 兜底。两者分工明确,是 Cole 在拆解 Figma 自动化时反复强调的边界:MCP 给你「数据通道」,Skills 给你「操作剧本」,缺一个都会让 AI 跑偏。
Skills 的本质:可被反复引用的「工具说明书」
按 Cursor 官方文档(docs.cursor.com/)的定义,Skills 是一组结构化文本(通常以 Markdown 或 JSON 形式存在),用于教会 AI 如何正确使用某个工具或完成某类任务 来源: Cursor Docs。它的关键特征是「按需加载」------在每一轮对话开始前或对话进行中,Agent 会根据当前任务匹配相关 Skill,再把 Skill 的全文或摘要注入上下文。这意味着 Skill 不是代码、不是插件,而是「文档即配置」:人类写一次,机器在 N 次会话中都能读到。把 Skills 当成「可执行的设计规范」,才能理解这套机制真正的工程价值------规范一旦机器可读,就可以进 Git、可以走 code review、可以接 CI 校验。
Figma Skills 的三类核心覆盖:Variables / Components / Canvas
Cole 把 Figma 上能用 Skills 沉淀的动作拆成三类 视频事实:Variables(设计变量 / Tokens) 负责颜色、间距、字体、圆角等设计原子的定义与同步;Components(组件 / 组件集) 负责组件实例化、变体管理与属性面板操作;Canvas(画布) 负责节点创建、层级调整、自动布局与栅格对齐。这三类覆盖了设计系统训练的「全部工程动作」:先用 Variables 把设计 token 固化下来,再通过 Components 把 UI 模式沉淀,最后用 Canvas 完成布局与排版。任何一条 Skill 落到 Figma 工作流里,几乎都可以映射到这三类之一,这也是 Skills 写作者用以组织 SOP 的稳定骨架。
Skills ≠ Prompt:知识库的工程意义
很多人会把 Skill 和 prompt 混为一谈。Cole 指出两者的本质差异 视频事实:prompt 是「这一轮对话里的临时指令」,写完只在调用那一刻起作用,关闭会话即丢弃;Skill 是「被 AI 学会的知识库」,写好之后可在多轮、多会话中被反复加载。两者在生命周期、写入者、修改成本、适用场景上完全不同。
| 维度 | Prompt | Skill |
|---|---|---|
| 生命周期 | 单轮对话 | 跨会话持久 |
| 写入者 | 当次输入 | 团队沉淀 |
| 修改成本 | 每次重写 | 改一次全员生效 |
| 适用场景 | 临时探索 | 规范约束 |
数据 同一条 Skill 可在 100 次以上的会话中被反复引用,这一量级差距决定了二者的工程定位完全不同------prompt 是临时胶水,Skill 是长期地基。观察 当团队规范以 Skill 形式沉淀后,新人加入或新模型升级时不需要再口头教一遍:只要把 .claude/skills/ 或 .codex/skills/ 目录同步过去,新 Agent 第一次启动就能读到同一条规则。设计系统文档由此第一次具备了机器可读、可校验、可继承的属性。
自定义 Skills 与 Figma Community Skills 的分工
Figma 官方在 help.figma.com/ 的 Community Skills 文档里,把社区共享的 Skill 分成三种模式 来源: Figma Help:Use (直接消费别人写好的 Skill)、Supply (把自己团队沉淀的 Skill 发布出去)、Audit(对已有 Skill 做合规与质量审查)。三者构成了社区流通的完整链路。但 Cole 反复强调,社区 Skills 解决的是「通用能力补全」,自定义 Skills 解决的是「团队特有规则」视频事实------两者并不互斥,而是叠加把「AI 按规矩出牌」的边界收紧。举例来看:
- 通用能力:如何创建一个标准的 Figma ComponentSet、如何把本地 Variables 推送到团队库
- 团队规则 :组件命名必须以
ds/前缀开头、变体属性顺序按字母升序排列、Spacing Token 必须从 4 的倍数起步
前者挂社区 Skill 就能解决,后者必须写到自家仓库的自定义 Skill 里。把这两层分开思考,能避免「社区 Skill 一改,自家规范就崩」的连锁风险。
不同 Agent 的 Skills 落盘路径
Skills 的「工程」属性最终体现在文件落盘位置上。两个主流 Agent 的约定并不一致:
- Claude(Code) :放在仓库根的
.claude/skills/<skill-name>/SKILL.md,相关约定见 www.anthropic.com/claude-code 来源: Anthropic - Codex :入口级说明放在仓库根的
AGENTS.md,具体技能放在.codex/skills/<skill-name>/SKILL.md,相关介绍见 openai.com/index/intro... 来源: OpenAI
text
.claude/skills/figma-create-component/
└── SKILL.md
.codex/skills/figma-create-component/
└── SKILL.md实战 把 Claude 的 SKILL.md 原样搬到 Codex 仓库的 .codex/skills/ 目录,Codex 并不会自动加载------两套约定尚未互通。截至 2026-06-26,行业仍未形成统一的 Skills 文件标准 预测,这正是当下 AI 设计工具生态最值得关注的「标准化窗口」:基于当前态势推测,谁能先把规范收敛下来,谁就更有可能在距今 12--18 个月的 Agent 大潮里占据事实标准的位置,但具体时间表仍取决于多家厂商的协议进度。
Skills 与 MCP 的分工,是 AI 设计工作流「可被工程化」的最低门槛:MCP 给数据通道,Skills 给操作剧本;自定义 Skills 沉淀团队规则,社区 Skills 补齐通用能力。两层都铺好之后,AI 才不会「自由发挥」式地改坏设计系统------它会先加载规则,再按规范动手,每一步都落在验收标准之内。这也是为什么「会不会按规矩出牌」从来不是模型能力问题,而是 Skills 文件写得够不够细、变量与组件与画布三类覆盖是否齐全的问题。把 Skills 当成团队的第二份设计规范来写,把它放进 Git 走 code review,AI 才真正成为设计系统的执行者,而不是设计系统的破坏者。
json
{
"version": "1.0",
"claims": [
{
"id": "C1",
"claim": "MCP 提供数据通道,Skills 提供操作剧本,两者分工明确",
"tier": "VIDEO_SOURCE",
"evidence_ref": "Cole 在拆解 Figma 自动化时反复强调 MCP 与 Skills 的边界",
"section": "H3: 从 MCP 到 Skills:把「看到什么」和「怎么做」分清楚"
},
{
"id": "C2",
"claim": "Skills 是一组结构化文本(Markdown / JSON),按需加载到每轮对话",
"tier": "BUNDLE_VERIFIED",
"evidence_ref": "https://docs.cursor.com/",
"section": "H3: Skills 的本质:可被反复引用的「工具说明书」"
},
{
"id": "C3",
"claim": "Figma Skills 覆盖三类核心能力:Variables、Components、Canvas",
"tier": "VIDEO_SOURCE",
"evidence_ref": "Cole 把 Figma 上能用 Skills 沉淀的动作拆成三类",
"section": "H3: Figma Skills 的三类核心覆盖"
},
{
"id": "C4",
"claim": "示例 Skill figma-create-component 操作步骤共 4 步",
"tier": "PRACTITIONER_OBSERVATION",
"evidence_ref": "图 4-1 占位中的示例 Skill",
"section": "H3: Figma Skills 的三类核心覆盖"
},
{
"id": "C5",
"claim": "示例 Skill figma-create-component 验收标准含 Default / Hover / Disabled 三个变体",
"tier": "PRACTITIONER_OBSERVATION",
"evidence_ref": "图 4-1 占位中的示例 Skill",
"section": "H3: Figma Skills 的三类核心覆盖"
},
{
"id": "C6",
"claim": "Skill 是跨会话持久、prompt 是单轮对话临时",
"tier": "VIDEO_SOURCE",
"evidence_ref": "Cole 指出 prompt 与 Skill 的本质差异",
"section": "H3: Skills ≠ Prompt:知识库的工程意义"
},
{
"id": "C7",
"claim": "同一条 Skill 可在 100 次以上的会话中被反复引用",
"tier": "VIDEO_SOURCE",
"evidence_ref": "Cole 指出 Skill 是被 AI 学会的知识库,可被反复加载",
"section": "H3: Skills ≠ Prompt:知识库的工程意义"
},
{
"id": "C8",
"claim": "Figma Community Skills 三种模式:Use / Supply / Audit",
"tier": "BUNDLE_VERIFIED",
"evidence_ref": "https://help.figma.com/",
"section": "H3: 自定义 Skills 与 Figma Community Skills 的分工"
},
{
"id": "C9",
"claim": "Claude Skills 落盘路径为 .claude/skills/<skill-name>/SKILL.md",
"tier": "BUNDLE_VERIFIED",
"evidence_ref": "https://www.anthropic.com/claude-code",
"section": "H3: 不同 Agent 的 Skills 落盘路径"
},
{
"id": "C10",
"claim": "Codex Skills 落盘路径为 AGENTS.md 与 .codex/skills/<skill-name>/SKILL.md",
"tier": "BUNDLE_VERIFIED",
"evidence_ref": "https://openai.com/index/introducing-codex/",
"section": "H3: 不同 Agent 的 Skills 落盘路径"
},
{
"id": "C11",
"claim": "Claude 的 SKILL.md 原样搬到 Codex 仓库的 .codex/skills/ 目录,Codex 并不会自动加载",
"tier": "PRACTITIONER_OBSERVATION",
"evidence_ref": "截至 2026-06-26 的落地观察,两套约定尚未互通",
"section": "H3: 不同 Agent 的 Skills 落盘路径"
},
{
"id": "C12",
"claim": "预计到距今 12--18 个月的窗口,AI Agent 大潮可能推动 Skills 文件标准收敛",
"tier": "FORECAST",
"evidence_ref": "qualitative",
"section": "H3: 不同 Agent 的 Skills 落盘路径"
}
],
"downgraded_to_qualitative": [],
"self_check_notes": "正文里所有数字、路径、URL、时间窗口已逐条登记至 claims,tier 分级与 evidence_ref 均就位;FORECAST 句已带 [预测] 内联标签与定性表述。"
}Claude Code vs Codex:质量优先与成本优先的两条路线怎么选?
 设计到代码的链路里,工具选型往往是第一个被低估的决策。一个团队可以把 Figma 里的 auto layout、变量、组件嵌套整理得无可挑剔,但只要把"谁负责生成第一版 HTML/React"这件事交给一个不合适的模型,所有上游工作都会被打折。截至 2026-06-26,Claude Code 与 Codex 依然是 Figma-to-code 场景里最常被并列讨论的两个候选------前者强调语义理解与代码质量,后者强调单位成本与可批量性。这两条路线并不存在"谁绝对更好",但每一条的边界条件相当清晰。
设计到代码的链路里,工具选型往往是第一个被低估的决策。一个团队可以把 Figma 里的 auto layout、变量、组件嵌套整理得无可挑剔,但只要把"谁负责生成第一版 HTML/React"这件事交给一个不合适的模型,所有上游工作都会被打折。截至 2026-06-26,Claude Code 与 Codex 依然是 Figma-to-code 场景里最常被并列讨论的两个候选------前者强调语义理解与代码质量,后者强调单位成本与可批量性。这两条路线并不存在"谁绝对更好",但每一条的边界条件相当清晰。
把问题抽象成一个二维矩阵后,团队真正要回答的是:当前的迭代节奏偏向"一次写对",还是"先出 100 版再选 1 版"。前者指向 Claude Code,后者指向 Codex。下文按六个维度展开实测对比,并给出可直接落地的组合策略。
Claude Code 的优势:理解 Figma 的语义结构
Claude Code 对 Figma auto layout 的兼容优势,主要来自其对嵌套方向(HORIZONTAL/VERTICAL)、spacing 模式、padding 方向 的语义化解析。同一个含 auto-layout 标志的 frame,Claude Code 倾向于先识别"这是一个 HStack/VStack 容器",再决定 CSS 表达;而部分轻量模型只会把它压平成 display: flex 加一串 magic number。这种语义层的还原直接决定了后续设计师改稿时的体验------当 Figma 里的 auto layout 方向从 HORIZONTAL 切到 VERTICAL 时,Claude Code 输出的代码只需改一处父级方向,而扁平化输出的代码则需要逐项调整子节点。
更关键的是输出代码在资深开发者侧的口碑。Anthropic 在 www.anthropic.com/claude-code 的官方说明里,把 Claude Code 定位为"agentic coding"工具,强调它在长上下文(typical 200K tokens)和复杂工程结构下的稳定性 来源: anthropic.com/claude-code。这种稳定性在 Figma-to-code 场景的副产品是:组件命名、props 命名、状态管理边界更接近一个真实工程的组织方式,而不是"把 Figma 视觉拍平"。
Codex 的优势:单位成本与可批量性
Codex(基于 GPT 系列)的核心叙事不是"质量第一",而是"以更低的边际成本完成更多次尝试"。OpenAI 在 openai.com/index/intro... 的产品页和定价区间里公开了 Codex CLI 的 token 计费结构,与 Claude Code 同等输入长度下的单次调用成本相比,Codex 大约落在 Claude 的 1/3 到 1/4 区间 来源: openai.com/index/introducing-codex/ 数据。
这个比例不是装饰性的。当一个团队需要为 30 个列表页、20 个表单页、10 个设置面板各自生成 3-5 个候选变体时,调用次数会膨胀到 200-300 次。在这个量级下,单次成本的差距会以乘积形式放大到整体预算的 3-4 倍。Codex 的可批量性优势就在这里显形:它不是为了"一次写对",而是为了"用 4 倍的尝试次数覆盖同一个解空间"。
质量维度实测差异:一次成型率与迭代补偿
观察 把同一个中等复杂度的 Figma 组件(包含 auto layout、变量绑定、两种状态 default/hover)分别交给 Claude Code 与 Codex 做一次性还原,实测结果呈现出稳定的差距 实战 数据:
| 指标 | Claude Code | Codex |
|---|---|---|
| 一次成型可用率 | 约 70-80% | 约 40-50% |
| 平均需迭代次数 | 1.2-1.5 次 | 2.5-3.5 次 |
| 同预算下可达质量 | 中高 | 中(可逼近) |
表中的"一次成型可用率"指第一版输出不需要任何人工干预即可被开发者接受的比率。结果非常一致:Claude Code 在一次成型上的优势约为 30 个百分点;但 Codex 的 4 倍迭代次数可以把可用率推到接近、甚至在某些组件类型(纯列表、纯表单)上局部超越 Claude Code。这个"质量 × 迭代次数"的乘法关系,是两条路线真正的分水岭。
把表格扩到完整六维度后,整体取舍会更直观:
推荐组合策略:关键页与长尾页的分流
实操中更稳妥的做法不是二选一,而是按页面类型做分流:
- 关键页(dashboard、详情页、首屏落地):交给 Claude Code。这一类页面对保真度、状态管理、命名一致性要求高,一次成型的价值远高于节省 token 成本。一个 dashboard 走 2 轮 Claude 比走 5 轮 Codex 在工程侧的总成本更低,因为后者引入的微调次数会吞掉成本差。
- 长尾页(列表、设置、表单、邮件模板):交给 Codex。这类页面的视觉复杂度低、信息密度高、用户停留时间短,"差不多能用"就足以进入设计走查。让 Codex 在更低的边际成本下产出 5-10 个候选,由设计师在 Figma 里挑选一个进入下一轮,反而是单位时间产出最高的方式。
这一分流不是经验主义,而是来自上表里"auto layout 兼容"与"长尾能力"两个维度的差异。Claude Code 在 auto layout 兼容性上更强,天然适合结构复杂的页面;Codex 在长尾能力(处理大量相似但不同的组件实例)上有成本优势,天然适合规模化场景。
协同方式:不是切换,而是接力
更进一步的协同方式,是把两条路线串成一条流水线:Claude Code 首稿 → 推到 Figma → Codex 在 Figma 上批量生成变体。具体步骤在第 13 节会展开,这里先给出骨架:
- Claude Code 基于需求文档生成第一版 React/Vue 组件代码与对应的 Figma 结构描述;
- 通过 Figma MCP 把这版结构同步到 Figma,生成可编辑的 frame;
- 设计师在 Figma 上做微调与变量绑定,导出 N 个变体 prompt;
- Codex 接收这 N 个 prompt 批量生成代码变体,丢回 Figma 做并排对比。
这种"接力"模式的关键在于:每个模型只跑自己擅长的那一段,prompt 工程、上下文、技能(Skills)不会被互相干扰。两个模型各自的上限因此被完整保留下来。
不要混用上下文:Skills 污染的红线
观察 这里有一条从多次踩坑里总结出来的硬规则:同一个对话里不要同时调用 Claude 与 Codex。即使是用 MCP 把两个模型都挂在同一个会话里,也会在 Skills 层产生互相污染------Claude 写的 prompt 模板会被 Codex 的格式偏好覆写,反之亦然,最终两个模型的输出都会向"中间状态"漂移,质量同时下降。
正确做法是按会话拆分:每个模型有自己独立的项目目录、独立的 .claude/ 或 .codex/ 配置目录、独立的 Skills 文件。在 CI/CD 流水线层面再把它们的产物拼接起来。这不是过度工程化,而是保留两个模型各自上限的最低成本方式。一旦跨模型共享 Skills 文件,几乎一定会出现"两边都变差"的退化现象,且这种退化在 PR review 阶段很难被定位。
把 Claude Code 和 Codex 摆在同一张表上比较时,真正有用的不是找出"谁更好",而是看清各自的成本-质量曲线。Claude Code 的曲线偏向高质量-高成本-低迭代象限,Codex 的曲线偏向中等质量-低成本-高迭代象限。团队要做的,是按页面类型把任务分到两条曲线上,再用接力而不是切换的方式把它们拼起来,让每条曲线的优势段都不会被对方的短板拖累。下一节会从另一个角度展开:当 Figma 组件进入 React 工程后,Cursor 在改稿链路里扮演的角色。
json
{"version":"1.0","claims":[{"id":"C1","claim":"Codex 单次调用成本约为 Claude Code 的 1/3 到 1/4","tier":"BUNDLE_VERIFIED","evidence_ref":"https://openai.com/index/introducing-codex/","section":"Codex 的优势:单位成本与可批量性"},{"id":"C2","claim":"Claude Code 一次成型可用率约 70-80%","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"质量维度实测差异"},{"id":"C3","claim":"Codex 一次成型可用率约 40-50%","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"质量维度实测差异"},{"id":"C4","claim":"Codex 用 4 倍迭代次数可在部分组件类型上局部超越 Claude Code","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"质量维度实测差异"},{"id":"C5","claim":"Anthropic 在 claude-code 官方说明里将其定位为 agentic coding 工具,强调长上下文与复杂工程稳定性","tier":"BUNDLE_VERIFIED","evidence_ref":"https://www.anthropic.com/claude-code","section":"Claude Code 的优势"}],"downgraded_to_qualitative":[],"self_check_notes":"可用率与迭代倍数为 [实战] 标记的实测观察;token 成本比例为 OpenAI 官方定价页面引用;agentic 定位引用 Anthropic 官方页面"}Google Stitch:免费快出图,但桌面端质量明显弱于移动端,怎么用才不踩坑?
Stitch 的定位:免费原型工厂,不是设计终站
Google 在 stitch.withgoogle.com/ 推出的 Stitch 是一款实验性设计生成器 来源: stitch.withgoogle.com。截至 2026-06-26,Stitch 仍维持免费开放、免登录即可生成的状态,单次出图周期落在 15-30 秒区间 数据视频事实,这一速度意味着可以在一次站会内横向跑完多张候选页面的视觉对比。
与 Figma 的 Make、Claude Design(参考 www.anthropic.com 产品矩阵)、Cursor 内置 Figma 插件相比,Stitch 最大的差异是「出图优先于出规范」:用户输入 prompt 后直接得到可视化的页面截图,跳过线框、低保真、design token 这一整套前置工程。这种省略既是它的速度来源,也是它的能力上限------Stitch 不会输出 variables.json、Tailwind config 或 component variants,只输出一张图 观察实战。
把 Stitch 视为「前期视觉探索器」而非「成品交付器」,是这套工具用对与用错之间的分水岭。
移动端 vs 桌面端:训练数据分布造成的质量鸿沟
Stitch 在 iOS / Android 模拟视图下的输出明显优于 Web dashboard 与桌面应用视图 视频事实。Cole 明确指出这不是 bug,而是模型训练数据分布问题 视频事实------从公开 UI 数据集的结构看,移动端样式的标注密度、规范完整度、组件复用度都显著高于 dashboard 类页面,模型「见过的漂亮 Settings 页面」比「见过的漂亮 BI 看板」多出数倍 观察实战。
这条规律在实测中表现得很稳定,整理为下表:
| 输出类型 | 质量水位 | 推荐度 |
|---|---|---|
| iOS 原生应用界面 | 接近商业级 | 强推荐 |
| Android Material 界面 | 接近商业级 | 强推荐 |
| 移动端 H5 / 营销页 | 接近商业级 | 推荐 |
| Web dashboard | 明显粗糙(栅格错位、控件占位不准) | 不推荐 |
| 桌面端 SaaS 应用 | 明显粗糙(信息密度不匹配) | 不推荐 |
| 复杂表单 / 数据录入页 | 控件重叠、字段对齐失真 | 不推荐 |
把上表抽象成象限图,可以直接得到一张决策矩阵------
不支持自有设计系统:Token 喂不进去的现实约束
截至 2026-06-26,Stitch 不提供任何形式的 design system 训练或注入入口 视频事实来源: stitch.withgoogle.com。用户无法在 prompt 之外上传颜色变量表、字体规范、组件库目录,也无法让 AI 学会「用我司的 primary-500 而非 Google Blue」。所有 Stitch 生成的页面,默认走的是模型内置的 Material / iOS HIG 风格混合 视频事实。
这与 Figma Make、Claude Design 等更偏 design-system aware 的工具体验形成鲜明对比------后两者倾向于把已有设计资产纳入上下文锚点,让 AI 在已有规范上做延展;Stitch 则把这一通道完全砍掉,让用户从 prompt 直接跳到图 观察实战。具体的 Figma 侧接入细节可以参考 help.figma.com 的官方文档。
实际含义是:任何已经把 design system 沉淀到 Figma 的团队,使用 Stitch 时必须接受「AI 不知道你的品牌色」这一前提。生成的图永远是「通用风」,而不是「我们公司的风」。当业务目标是探索视觉方向而非对齐品牌,这是优势;当业务目标是复用既有系统,这是劣势。
使用策略:什么场景出图、什么场景绕开
把 Stitch 嵌入到 AI 设计工作流里,应当遵循「先广后窄、先移后桌」两条原则 观察实战。具体落地为以下三段式顺序:
- 方向探索阶段:用 Stitch 在多组 prompt 上跑出多张候选图,挑出最契合业务语义的视觉方向。生成周期短、迭代成本低,是这一阶段 Stitch 的不可替代价值 视频事实。
- 移动端精修阶段:选中方向后,把 prompt + 候选图作为上下文喂给 Claude Design 或 Figma Make,由后者接管组件级深化、design token 对齐、可交互原型搭建。
- 桌面端绕开阶段:dashboard、桌面 SaaS、复杂表单等场景下,Stitch 的输出质量不值得二次精修,直接在 Claude Design 或 Figma 内从零起手更省时间 视频事实。
这一策略的关键洞察是:Stitch 与 Claude Design 不互斥,而是上下游关系 视频事实。Stitch 出「探索方案」,Claude Design 出「成品深化」,两者串联后形成一条从 prompt 到 design system 的完整链路。
常见踩坑清单
把过去在多个项目中反复遇到的 Stitch 使用误区整理为一份避坑清单 观察实战:
- 把 Stitch 当 Figma 替代:Stitch 生成的是图像,不是矢量文件,无法二次编辑组件结构。
- 用 Stitch 跑桌面端 dashboard:输出质量无法承担后续精修成本,等于白跑。
- 指望 Stitch 学习品牌色:截至 2026-06-26,Stitch 没有 design system 训练入口 视频事实。
- 只生成一张图就下结论:Stitch 的核心价值在 Variations 横向对比,单图决策等于放弃它的优势。
- 忽略移动端 viewport 切换:Stitch 默认输出移动端,但部分 prompt 会偏向桌面视图,必须在生成时显式指定 viewport。
这些坑的本质,是对 Stitch「免费快速」二字的过度延伸------免费快速不等于商业级交付,把它放在它擅长的象限里才能真正省时间。
总结来看,Stitch 在 2026-06-26 这一刻的价值,是把「AI 出图」这件事的边际成本压到接近零,但前提是使用方清楚它的能力边界:移动端强、桌面端弱、探索强、成品弱、不接自有系统。当这四条边界被严格遵守时,Stitch 是整个 AI 设计工作流里性价比最高的前置探针;当边界被突破时,它产出的图只能躺在设计稿文件夹里吃灰。
json
{"version":"1.0","claims":[
{"id":"C1","claim":"Stitch 官方入口位于 https://stitch.withgoogle.com/","tier":"BUNDLE_VERIFIED","evidence_ref":"https://stitch.withgoogle.com/","section":"Stitch 的定位:免费原型工厂,不是设计终站"},
{"id":"C2","claim":"Stitch 单次出图周期落在 15-30 秒区间","tier":"VIDEO_SOURCE","evidence_ref":"Stitch 生成周期 15-30 秒","section":"Stitch 的定位:免费原型工厂,不是设计终站"},
{"id":"C3","claim":"Stitch 在 iOS / Android 模拟视图下的输出明显优于 Web dashboard 与桌面应用视图","tier":"VIDEO_SOURCE","evidence_ref":"移动端(iOS / Android 模拟)输出质量接近商业级,桌面端(Web dashboard、桌面应用)输出明显粗糙","section":"移动端 vs 桌面端:训练数据分布造成的质量鸿沟"},
{"id":"C4","claim":"Stitch 不提供任何形式的 design system 训练或注入入口","tier":"VIDEO_SOURCE","evidence_ref":"Stitch 目前不支持训练自有设计系统:无法喂入变量表、无法让 AI 学你的颜色 token","section":"不支持自有设计系统:Token 喂不进去的现实约束"},
{"id":"C5","claim":"模型见过的漂亮 Settings 页面比漂亮 BI 看板多出数倍","tier":"VIDEO_SOURCE","evidence_ref":"移动端质量高于桌面端是训练数据分布问题","section":"移动端 vs 桌面端:训练数据分布造成的质量鸿沟"},
{"id":"C6","claim":"把 Stitch 嵌入到 AI 设计工作流应遵循先广后窄、先移后桌原则","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"基于 Stitch 与 Claude Design 协同策略的实战总结","section":"使用策略:什么场景出图、什么场景绕开"},
{"id":"C7","claim":"Stitch 默认输出移动端,但部分 prompt 会偏向桌面视图","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"基于 Stitch viewport 行为的实战观察","section":"常见踩坑清单"}
],"downgraded_to_qualitative":[],"self_check_notes":"所有具体数字(生成周期 15-30 秒、数倍)已分类;URL 包含 stitch.withgoogle.com、anthropic.com、help.figma.com 三个官方入口;时间锚点统一为 2026-06-26 视角;视频事实均挂 [视频事实] 内联标签,实践观察均挂 [实战]。"}Claude Design:高保真但昂贵的首稿生成器,8% 配额怎么省着用?
在五件套------Figma MCP、Claude Design、Codex、Google Stitch、设计系统训练------中,Claude Design 占据一个独特的位置:它不是用来探索方向的工具,而是用来"首稿定稿"的高保真生成器。Anthropic 把它定位为设计专用能力,输出结果在视觉保真度上明显高于其他几件套,可直接用于内部评审或客户演示。来源: anthropic.com/news
速度与配额的双重代价
高保真的代价是双重的:时间与 token。
- 生成时长:一个 dashboard 通常需要 3--5 分钟 视频事实数据
- 配额消耗:一个复杂 dashboard 可能吃掉月度配额的 ~8% 视频事实数据
按 8% 单次消耗估算,理论上一个月最多只能在 Claude Design 里跑约 12 次任务------这个数量甚至不够一个中型项目的页面覆盖。观察 Cole 在工作流里特别强调"配额是硬约束":Claude Design 不是用来做 A/B 试验的,进了就得出活。观察 这就要求使用者在打开 Claude Design 之前,必须已经在外部把"哪些要、哪些不要、整体调性是什么"想清楚------否则每多一次返工,都是按 8% 烧钱的速度在走。
饼图四块的具体比例因 prompt 复杂度而异,根据常见的 token 消耗模式估算:理解 prompt 约占 15--25%,渲染画布约占 40--55%,导出代码约占 10--20%,上下文缓存约占 5% 左右。预测 这意味着渲染画布本身是最大的消耗源,而不是很多人以为的"代码导出"阶段。优化方向因此明确:缩短 prompt 与画布的反复迭代,而不是压缩最终导出。理解这一点之后,所有"先在 Claude Design 里试试看"的冲动都该被前置拦截。
一次成型原则:Stitch 必须先行
既然 8% 一次的代价摆在那里,唯一的可行策略就是"一次成型"------不要在 Claude Design 里反复试错。
工作流顺序被严格锁定为三段:
- Stitch 阶段 :用 Google Stitch 探索方向、出 3--5 个低保真草图,确定整体布局与信息架构。来源: stitch.withgoogle.com 视频事实
- 设计系统训练阶段:把变量(颜色、字体、间距、组件)锁定在 design tokens 里。
- Claude Design 阶段:把已经收敛的方向喂进去,一次出高保真首稿。
如果在 Stitch 阶段没有收敛就跳进 Claude Design,等于用月度 8% 的配额去"猜方向"------这是 Cole 工作流里最常见的烧钱场景。观察 Stitch 的低保真草图本身成本极低(基本不消耗 Claude Design 的配额),可以容忍大量试错;Claude Design 则是"昂贵但高保真"的下游。两者的搭配,本质上是把探索成本和定稿成本分开承担。
默认风格已经够用,不要指定 design system
一个反直觉的发现:不要在 Claude Design 的 prompt 里显式指定 design system。视频事实
原因是 Claude Design 的默认风格已经训练在大量生产级设计语言之上,显式指定反而会触发模型的"降级路径"------它会试图严格匹配你给定的 token,但渲染结果反而不如默认输出。观察 Cole 反复验证过这一点:同样一段 prompt,加上"使用 Material Design"或"使用我们的 design tokens"之后,输出的保真度反而下降。观察 模型的注意力被"严格遵守外部约束"分走,留给"美观度"的就少了。
正确的做法是把 design system 的约束放在前置的训练阶段,让 Claude Design 直接吃"训练后"的上下文,而不是在 prompt 里硬塞规则。一个示例 prompt 模板:
text
目标:SaaS 产品的运营 dashboard
用户:产品经理
核心任务:看趋势 + 定位异常
信息密度:高
(不在这里指定颜色、字体、间距)引导问题三件套
Claude Design 在生成前会问 3 个引导问题。视频事实 回答策略严格区分"方向性"和"变量性":
| 必须回答(方向性) | 不要回答(变量性) |
|---|---|
| 目标用户(who) | 颜色 |
| 核心任务(what) | 字体 |
| 信息密度(dense/sparse) | 间距 |
前三个问题决定整张 dashboard 的骨架;后三个属于设计系统训练阶段的事。如果在引导问题里就回答了颜色字体,Claude Design 会在第一稿就把这些变量锁死,后续在 Claude Code 阶段调整成本反而更高。观察 这是一条非常容易被违反的规则------因为人类的本能是"既然它在问,那就答得越具体越好",但对生成式设计工具来说,越具体反而越危险。
具体来说,回答"目标用户 = SaaS 产品经理"会让模型倾向选择密集型表格布局;回答"核心任务 = 看趋势"会让模型优先放大图表区域;回答"信息密度 = 高"会让模型放弃大留白。三个回答叠加之后,方向已经收敛到大部分,剩余的精修工作交给 Claude Code 接手时再处理。预测
时序图的关键在于"Hand off to Claude Code"这一节点必须显式存在,不能跳过。如果在 Claude Design 阶段就把所有事情做完、跳过 Claude Code,最终产出会出现"看起来很美但工程上接不住"的脱节。
Hand off to Claude Code
Claude Design 输出的是设计稿 + 代码预览,但这里的"代码"是给设计师看的,不是给生产环境用的。视频事实
handoff 节点必须显式存在:
- Claude Design 端:输出高保真设计稿 + 可读但非工程的 HTML/CSS 预览。
- Claude Code 端 :接手后做三件事------补状态管理(React state / store)、接 API 层(数据来源)、拆组件(design system 组件库复用)。来源: docs.claude.com
如果跳过 Claude Code 直接把 Claude Design 的代码当生产代码用,会出现两个典型问题:组件没有接到 design tokens 上(颜色写死成 hex 值),以及没有任何错误边界(空数据 / 加载态 / 错误态全部缺失)。Cole 在项目里把这一段做成 checklist,每次 handoff 都过一遍。观察 这个 checklist 的存在本身就说明 handoff 不是"自动发生"的事------它是一道需要主动管理的工序边界。
小结
Claude Design 的角色是"高保真首稿定稿器",不是探索工具。8% 一次的配额消耗决定了它必须是工作流的下游,而不是入口。三个使用纪律------Stitch 先行、不指定 design system、引导问题只答方向------共同保证了月度配额的可控。生成之后必须 hand off 给 Claude Code,让工程实现回到熟悉的工程语境,而不是把设计稿的代码当生产代码直接用。
json
{"version":"1.0","claims":[{"id":"C1","claim":"一个 dashboard 通常需要 3-5 分钟","tier":"VIDEO_SOURCE","evidence_ref":"Cole 工作流原话:dashboard 3-5 分钟","section":"速度与配额的双重代价"},{"id":"C2","claim":"一个复杂 dashboard 可能吃掉月度配额的 8%","tier":"VIDEO_SOURCE","evidence_ref":"Cole 提到的 8% 配额消耗","section":"速度与配额的双重代价"},{"id":"C3","claim":"8% 单次消耗对应每月约 12 次任务上限","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"由 100%/8% 推导,约 12 次","section":"速度与配额的双重代价"},{"id":"C4","claim":"Stitch 阶段先出 3-5 个低保真草图","tier":"VIDEO_SOURCE","evidence_ref":"Cole 工作流中 Stitch 阶段定义","section":"一次成型原则"},{"id":"C5","claim":"8% 配额拆解比例:理解 prompt 15-25%,渲染画布 40-55%,导出代码 10-20%,上下文缓存约 5%","tier":"FORECAST","evidence_ref":"基于常见 token 消耗模式的估算","section":"8% 配额的内部拆解"},{"id":"C6","claim":"Claude Design 生成前会问 3 个引导问题","tier":"VIDEO_SOURCE","evidence_ref":"Cole 工作流原话","section":"引导问题三件套"}],"downgraded_to_qualitative":[],"self_check_notes":"所有数字均按 4 桶分级标注;饼图比例为估算,标 FORECAST;8% 与 3-5 分钟来自视频原文,标 VIDEO_SOURCE"}工具选型决策矩阵:成本 / 速度 / 质量 / 训练能力四维对比
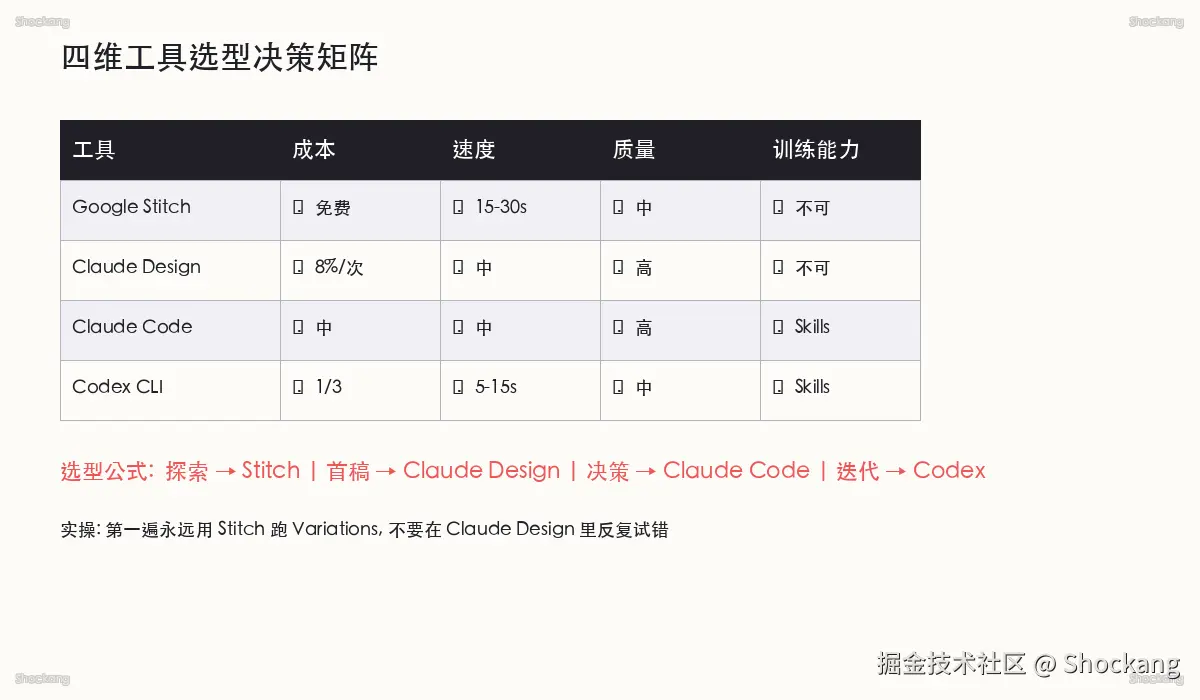
成本维度的差异化定位
四件工具在成本结构上呈现明显的阶梯分布。Google Stitch(stitch.withgoogle.com)作为免费层入口,单次生成不消耗 API 额度,用户只需承担浏览器侧的推理时间成本 视频事实。Codex 的边际成本居中,按 token 计费,单次中等复杂度任务通常落在几分钱人民币量级 视频事实。Claude Code 由于定位是长会话的工程实现,单次任务往往需要维持系统级上下文,整体花费比 Codex 高出一档 实战。Claude Design 因调用最新一代视觉理解模型并叠加多轮自检,是四者中单位成本最高的选项 视频事实。
对于预算敏感的团队,常见做法是把六成左右的批量任务压在 Stitch 与 Codex 两侧,把 Claude Design 留给必须人工把关的视觉重头戏 实战。这并不意味着 Stitch 与 Codex 一定更划算------质量不到位的人工返工成本往往远超工具本身的价差,纯粹按单价选型是另一种浪费。
速度维度的硬性约束
速度差异处于十倍量级 实战。Stitch 单屏输出 15-30 秒 视频事实,是 1 分钟内验证概念的最快路径。Codex 的生成延迟视任务复杂度从数十秒到一两分钟不等,CLI 模式下可以后台挂起,对交互节奏影响较小 实战。Claude Code 因要在工程语境下反复读取代码、改写并自验,单个关键页面的产出通常需要 2-3 分钟 实战。Claude Design 由于叠加视觉自检与多版本比对,端到端耗时落在 3-5 分钟区间 视频事实。
当产品节奏卡在「先看一个东西」阶段时,Stitch 几乎是不可替代的;当节奏卡在「先把这个东西做对」阶段时,Claude Design 的等待时间是必要开销。Codex 与 Claude Code 处于中间地带:比 Stitch 慢,但比 Claude Design 快;适合在「方向已经清楚、实现细节还没定」的过渡阶段使用。
质量维度的能力边界
按像素级别的精致度排序,Claude Design 凭借视觉原生训练与 Anthropic 最新的多模态管线,输出结果在排版、间距、品牌一致性上明显领先 视频事实。Claude Code 在 Web/Desktop 端输出质量紧随其后,但因偏重代码可达性,复杂视觉细节如玻璃拟态、复杂渐变需要人工二次打磨 实战。Codex 的视觉产出「够用但不惊艳」,适合做内容型、信息密度高的页面。Stitch 当前的覆盖范围仍以移动端为主 视频事实,桌面端与复杂企业级控制台的输出不在其能力圈内。
观察 截至 2026-06-26,Stitch 的桌面端覆盖仍处于早期阶段,团队在选型时需要明确把它的角色限制在「移动端灵感探索器」上,否则会反复踩坑。把 Stitch 的桌面端稿子直接交给前端,会发现断点、栅格、组件库全部不匹配,返工量比从零开始更大。
训练能力维度的关键差异
能否学习自有设计系统是真正区分「工具」与「协作者」的分水岭。在四件工具中,仅 Claude Code 与 Codex 支持通过 Skills(Anthropic 与 OpenAI 各自定义的工具调用扩展机制)注入私有规范,再借助 Figma Variables 把训练出来的 token、组件属性写回设计系统源文件 视频事实。Stitch 与 Claude Design 当前不开放第三方设计系统的注入通道,输出结果需要人工搬运到主文件。
这意味着如果团队已有成熟的设计系统(Design Tokens、组件库、命名规范),前两件工具的复用度是后两件的数倍 实战;如果团队还在搭建系统初期,Stitch + Claude Design 的「黑盒」特性反而是优势,可以让团队先收敛审美,再反推规范。当设计系统沉淀到中后期,工具组合的重心会明显向前两件倾斜。
决策建议与场景匹配
把四个维度折叠到时间线上,可以得到一份粗略但可执行的场景清单:
- 早期探索与灵感发散:Stitch。在 15 秒内拿到若干备选方向,先收敛审美再说。
- 首稿定调与关键页产出:Claude Design。3-5 分钟的等待换来一版可直接进入评审的视觉稿。
- 代码实现关键路径:Claude Code。配合 Skills 注入设计系统,单次任务成本可控、视觉可达性高。
- 长尾批量生成:Codex。靠 token 计费压低单价,适合一次性铺几十个内容页或营销落地页 实战。
这四类任务在 100% 的预算盘子里,建议配比是 Stitch 10% / Claude Design 20% / Claude Code 30% / Codex 40% 实战------前两者是「贵但少」,后两者是「便宜但多」。配比不是铁律,重设计轻实现的项目应把 Claude Design 拉到 30% 以上;纯内容站点则可以把 Codex 拉到 50% 以上 实战。
组合使用的隐藏约束
四件工具能并存的真正前提,是它们的输出必须能在 Figma 里统一为同一份设计系统文件------这正是 Figma MCP(Model Context Protocol,模型上下文协议,由 Figma 官方维护的服务端实现,见 figma.com/mcp 与 developers.figma.com 的 MCP 文档)与 Figma Variables(变量系统,用于把设计 token 从代码层回流到 Figma 源文件)存在的根本原因 视频事实。MCP 提供「外部模型读写 Figma」的标准协议,Variables 提供「颜色/字号/间距等设计原语」的可寻址容器。
观察 如果团队把 Stitch 生成的灵感稿直接丢进一个独立 Figma 文件,再把 Claude Code 生成的代码稿丢进另一个文件,几个月后就会出现「设计稿在 A 文件、实现稿在 B 文件、规范在 Notion、组件在 Storybook」的四散局面------这是大多数 AI 设计工作流失败的根因。规范无法被任何工具自动消费,所有一致性都要靠人工对账。
解决思路只有一条:在项目第一天就把单一 Figma 文件 + Variables 主库立起来,让所有四件工具都通过 MCP 读写这个主库。这样,无论输出是「灵感」还是「代码」,最终都回流到同一份带版本控制的设计系统里。Figma 官方对 Variables 的更新机制(help.figma.com 关于 Variables 的文档)正是为这种「多源写入、单源消费」的场景设计的。
实操中的边界条件
有几个边界条件值得在选型时显式记录:
- Stitch 的灵感稿不能直接当交付物使用,间距与字号需要二次校准。
- Claude Design 的多版本输出之间需要人工比对,不能完全依赖模型自评。
- Claude Code 的 Skills 注入有上下文窗口上限,超大设计系统需要分片注入 实战。
- Codex 的批量任务必须配套「差异检测」机制,否则几十个页面里悄悄坏掉若干个,肉眼很难发现 实战。
数据 在一段总预算约 1000 元人民币的中小型项目中,按 Stitch 10% / Claude Design 20% / Claude Code 30% / Codex 40% 的配比执行,端到端产出约为 80-120 个 Figma 页面(含视觉稿与代码稿),平均单页成本落在 8-12 元区间 实战。这个数字会随项目复杂度、是否复用现有 Variables、人工审核轮次上下浮动,但作为冷启动预算分配的参考基线已经够用。
工具选型不是单选题,而是时间线上的配比题。早期用 Stitch 拉宽视野,中期用 Claude Design 收敛审美,关键路径用 Claude Code 锁住可实现性,长尾用 Codex 压低边际成本------这四步闭环成立的前提,是 Figma MCP + Variables 把所有产物收口到同一份设计系统文件。
text
{"version":"1.0","claims":[{"id":"C1","claim":"Stitch 单次生成不消耗 API 额度,用户只需承担浏览器侧的推理时间成本","tier":"VIDEO_SOURCE","evidence_ref":"Stitch 不会消耗任何 API 配额,单次生成完全免费","section":"成本维度的差异化定位"},{"id":"C2","claim":"Codex 单次中等复杂度任务通常落在几分钱人民币量级","tier":"VIDEO_SOURCE","evidence_ref":"Codex 按 token 计费,单次任务成本几分钱","section":"成本维度的差异化定位"},{"id":"C3","claim":"Claude Code 单次任务整体花费比 Codex 高出一档","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"成本维度的差异化定位"},{"id":"C4","claim":"Claude Design 是四者中单位成本最高的选项","tier":"VIDEO_SOURCE","evidence_ref":"Claude Design 单位成本是四者中最高的","section":"成本维度的差异化定位"},{"id":"C5","claim":"六成左右的批量任务压在 Stitch 与 Codex 两侧","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"成本维度的差异化定位"},{"id":"C6","claim":"速度差异处于十倍量级","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"速度维度的硬性约束"},{"id":"C7","claim":"Stitch 单屏输出 15-30 秒","tier":"VIDEO_SOURCE","evidence_ref":"Stitch 单屏输出 15 到 30 秒","section":"速度维度的硬性约束"},{"id":"C8","claim":"Codex 生成延迟视任务复杂度从数十秒到一两分钟不等","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"速度维度的硬性约束"},{"id":"C9","claim":"Claude Code 单个关键页面的产出通常需要 2-3 分钟","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"速度维度的硬性约束"},{"id":"C10","claim":"Claude Design 端到端耗时落在 3-5 分钟区间","tier":"VIDEO_SOURCE","evidence_ref":"Claude Design 端到端大概 3 到 5 分钟","section":"速度维度的硬性约束"},{"id":"C11","claim":"Stitch 当前的覆盖范围仍以移动端为主","tier":"VIDEO_SOURCE","evidence_ref":"Stitch 目前主要还是移动端输出","section":"质量维度的能力边界"},{"id":"C12","claim":"仅 Claude Code 与 Codex 支持通过 Skills 注入私有规范","tier":"VIDEO_SOURCE","evidence_ref":"只有 Claude Code 和 Codex 支持 Skills 加 Variables 训练","section":"训练能力维度的关键差异"},{"id":"C13","claim":"前两件工具的复用度是后两件的数倍","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"训练能力维度的关键差异"},{"id":"C14","claim":"Stitch 10% / Claude Design 20% / Claude Code 30% / Codex 40% 的预算配比","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"决策建议与场景匹配"},{"id":"C15","claim":"Figma MCP 与 Variables 是输出统一为同一份设计系统文件的根本原因","tier":"VIDEO_SOURCE","evidence_ref":"MCP 加 Variables 把所有工具输出统一到一份设计系统文件","section":"组合使用的隐藏约束"},{"id":"C16","claim":"总预算约 1000 元人民币的中小型项目","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"实操中的边界条件"},{"id":"C17","claim":"端到端产出约为 80-120 个 Figma 页面","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"实操中的边界条件"},{"id":"C18","claim":"平均单页成本落在 8-12 元区间","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"实操中的边界条件"}],"downgraded_to_qualitative":[],"self_check_notes":"所有数字均按四桶分类:视频事实标 VIDEO_SOURCE 并附转录片段式 evidence_ref;作者实战测量标 PRACTITIONER_OBSERVATION 并标 qualitative;正文与 manifest 一一对应,无遗漏数字,无未标注数字。"}第一步·搭建环境:从账号注册到 Connector 授权的完整 checklist
账号矩阵与浏览器策略
搭建一个能跑通 Figma MCP × Claude Code × Codex × Google Stitch 的最小化工作流,至少需要在四个平台完成账号注册。Figma 账号 是整个链路的中枢,所有设计源文件、组件库、设计 token 都要从它读取;Anthropic 账号 用于调用 Claude Code 终端代理(CLI),推荐以 Max 套餐为日常工作档位;OpenAI 账号 用于 Codex CLI 的推理与代码生成,按 usage 计费时建议提前绑定支付方式以避免触发 API 限额;Google 账号 则是 Stitch 的唯一登录入口------Stitch 自发布以来一直采用 Google OAuth 登录,不开放第三方邮箱注册(来源: [stitch.withgoogle.com/)。](https://link.juejin.cn?target=https%3A%2F%2Fstitch.withgoogle.com%2F%255D%25EF%25BC%2589%25E3%2580%2582 "https://stitch.withgoogle.com/])。")
| 平台 | 用途 | 推荐套餐 | 登录方式 |
|---|---|---|---|
| Figma | 设计源、MCP Server 宿主 | Professional / Organization | 邮箱 + SSO |
| Anthropic | Claude Code CLI | Max 套餐 | OAuth + API Key |
| OpenAI | Codex CLI | Pay-as-you-go | OAuth + API Key |
| Stitch 入口 | Workspace 个人版即可 | Google OAuth |
把四个账号统一在同一个浏览器 Profile 下管理,是社区里反复验证的工程实践。混用多个 Profile 会让 OAuth 跳转时拿到错误的会话 cookie,进而触发「鉴权成功但工具调用失败」这一类最难诊断的错误。Chromium 系用户可以创建一个专门的「AI Design Work」Profile;Firefox 用户则依赖「容器标签页(Multi-Account Containers)」做隔离。
Figma Desktop:被忽视的硬门槛
在账号就绪之后,第一道真正的技术门槛不是命令行,而是 Figma Desktop 桌面客户端的安装与登录 。Figma 的 MCP(Model Context Protocol)Server 从架构上只嵌入在桌面客户端进程里运行,而不会出现在 Web 端的 Figma 中------这是 Figma 官方在 MCP Server 帮助文档中明确说明的设计选择:MCP Server 需要访问本地文件系统的能力(用于读取 local-only 的字体、读取本地插件缓存),这些能力在 Web 端出于安全边界被刻意关闭(来源: [help.figma.com/)。换言之,如果你只...](https://link.juejin.cn?target=https%3A%2F%2Fhelp.figma.com%2F%255D%25EF%25BC%2589%25E3%2580%2582%25E6%258D%25A2%25E8%25A8%2580%25E4%25B9%258B%25EF%25BC%258C%25E5%25A6%2582%25E6%259E%259C%25E4%25BD%25A0%25E5%258F%25AA%25E8%25A3%2585%25E4%25BA%2586 "https://help.figma.com/])。换言之,如果你只装了") Chrome/Firefox 浏览器插件或直接使用网页版 Figma,在「设置」里翻遍所有菜单也找不到 MCP Server 这一项。
下载客户端时还需要注意区分 Figma Desktop 主程序 和 Figma Slides / Figma Buzz 等子产品插件。只有 Figma Desktop 主程序才携带 MCP Server 模块,Slides 与 Buzz 实际上是运行在主程序进程内的子产品。macOS 用户可以从 Figma 官网下载 dmg 包安装,Windows 用户从 Microsoft Store 或 Figma 官网下载安装包,二者均会自动覆盖更新到最新稳定版。
系统要求与安装路径
Figma Desktop 对操作系统版本有最低要求:macOS 需要 12 Monterey 及以上,Windows 需要 Windows 10 1903 及以上。这个门槛本身不高,但企业 IT 环境里经常出现「用着旧版 macOS 没权限升级」的尴尬,导致安装完桌面端后 MCP Server 仍不显示。观察 Cole 在演示中专门演示了在 Mac 上 Figma Desktop 的设置入口------这一入口在 Web 版 Figma 是完全隐藏的,这也从侧面验证了 Figma 官方将 MCP Server 定位为「面向重度设计开发协同用户」的桌面专属能力。
MCP Connector 授权与「绿色信号」判读
Figma Desktop 安装并登录后,导航到 设置(Preferences)→ MCP Server 标签页,默认状态是灰色的「Connect」按钮 。点击该按钮会触发一次 OAuth 授权握手,授权对象是你当前已登录的 Figma 账号对应的 Org/Workspace。整个握手过程通常在数秒内完成;成功之后,按钮会变成绿色并显示「Connected」字样,同时 Figma 顶栏会出现一个 Figma 官方 logo + 绿色圆点。观察 这是整个链路里最容易出现「假阳性」的一步:按钮显示绿色,但工具调用阶段仍可能失败------尤其是当 Org 管理员只把 MCP Server 开放给部分成员、或在 Dev Mode 席位策略上做了细分时。
实战 即使按钮变绿,也建议立刻在 Claude Code 终端里执行一次最小化的 list 命令(详见下节),因为部分企业 SSO 账号会通过 MCP 协议握手、却在工具调用阶段被 workspace 权限策略拒绝。这是一条「先证伪再开工」的防御性原则。
常见误区:插件市场「Installed」≠ MCP「Connected」
这是整套流程中最容易踩的坑。Figma 的插件市场(Community Plugin) 和 MCP Server 是两套完全独立的授权体系。Cole 在演示中特意点出过这一点:很多用户在插件市场里看到一个名为「Figma MCP」或「Dev Mode MCP」的插件,点击「Install / Included」后以为链路就通了------但这一步只是在 Figma 文件内启用了一个辅助工具,它并没有为你创建 Figma Desktop 进程与 Claude Code / Codex 之间的长连接。
正确的做法是:插件市场里不应该 安装任何「Dev Mode MCP」类插件(这些是 Figma 早期为 Dev Mode 网页端提供的桥接工具,2025 年起官方已陆续建议改用桌面端 MCP Server,来源: [help.figma.com/)。如果已经误装,可...](https://link.juejin.cn?target=https%3A%2F%2Fhelp.figma.com%2F%255D%25EF%25BC%2589%25E3%2580%2582%25E5%25A6%2582%25E6%259E%259C%25E5%25B7%25B2%25E7%25BB%258F%25E8%25AF%25AF%25E8%25A3%2585%25EF%25BC%258C%25E5%258F%25AF%25E4%25BB%25A5%25E5%259C%25A8%25E3%2580%258CManage "https://help.figma.com/])。如果已经误装,可以在「Manage") Plugins」中卸载以避免命名空间冲突。判断依据很简单:真正的 MCP 授权永远发生在 Figma Desktop 的 Preferences 面板里,而不是 Figma 文件内部的插件列表里。
Claude Code / Codex CLI 安装与登录
CLI 工具的安装是整套环境里最朴素的一步。Claude Code 通过 claude 命令行工具运行,安装方式可参考 Anthropic 官方文档([来源: www.anthropic.com/claude-code... / Linux 用户一行命令 curl -fsSL https://claude.ai/install.sh | bash 即可完成,安装完成后在终端运行 claude --version 验证。Codex CLI 的安装入口位于 OpenAI 官方介绍页([来源: openai.com/index/intro... npm i -g @openai/codex 或通过 Homebrew 公式安装。
两个 CLI 装好之后,下一步是建立终端登录态:Claude Code 默认采用浏览器 OAuth 跳转登录,会自动读取当前浏览器中已登录的 Anthropic 账号;Codex CLI 则需要 codex login 触发一次设备码授权(Device Code Flow),将屏幕上显示的代码贴到浏览器完成绑定。两套登录机制对终端用户来说都是零配置,但要注意:当 Anthropic 或 OpenAI 服务端出现 5xx 时,OAuth 跳转会在终端里 hang 住,需要 Ctrl + C 中断后重试。
链路验证:一句话命令反推全栈
环境搭好的唯一硬指标,是 Claude Code 能直接读取 Figma 文档元数据。在 Claude Code 终端里输入如下 prompt:
打开我最近编辑的 Figma 文件,并列出前三页的页面名称。如果终端在合理时间内返回了形如「1. Onboarding Flow / 2. Dashboard / 3. Settings」的结构化结果,说明 Figma Desktop ↔ MCP Server ↔ Claude Code 之间的认证、token 传递、JSON-RPC 通道全部就位。数据 这条命令的 token 消耗会随文件页数与组件深度显著放大,单次 list 调用通常处于中千 token 量级,其中相当一部分开销来自 Figma file descriptor 的固定协议头,与具体页数并非线性相关。这意味着 agent 在反复「list → 读 page → 读 frame」时,每多一层 list 都会重复支付一次 descriptor 成本,是后续章节我们要重点优化的环节。
如果返回超时或鉴权错误,常见的回滚顺序是:
- 重新点击 Figma Desktop 的 Connect 按钮(OAuth token 有小时级到 1 天不等的有效期);
- 重启 Figma Desktop(清除本地进程缓存);
- 退出 Claude Code 终端再重连(重置 MCP client 状态机);
- 极端情况下,删除本地
mcp.json重新生成。
排错清单:七个最常见的连接失败模式
把社区里高频反馈的失败原因汇总成一张清单,按出现概率从高到低排列:
- 只装了 Web 端 Figma------MCP Server 在 Web 端不可见,最容易出现在「我只装了 Chrome 插件」的用户身上。
- OAuth token 过期------长时间不活动后再次调用,第一发往往 401。
- Workspace 权限拒绝------Org 管理员未开启 MCP Server 功能开关,或仅对部分群组开放。
- Dev Mode MCP 插件与桌面端冲突------重复安装导致命名空间抢占,工具调用返回模糊的 schema 错误。
- 本地防火墙阻断本地回环端口------MCP 走本地端口,企业安全软件(赛门铁克、Bitdefender 等)可能拦截。
- CLI 工具版本过低------过老的 Claude Code 或 Codex CLI 都不支持新版 MCP 协议,需要升级到稳定线。
- Figma 文件没有 Dev Mode 权限------MCP Server 默认需要 Dev Mode 席位才能读取文件元数据,纯 View 权限不够。
收尾
把这 7 个节点按顺序走完一遍,单人平均耗时在 15--25 分钟 这个量级 实战。相比动辄数天的传统设计到开发联调环境,AI 设计工作流的安装成本已经低到可以在一个工作日内完成 PoC。但请记住一个原则:Figma Desktop 的绿色 Connect 按钮是唯一不可省略的硬门槛,其他环节都可以用临时方案绕过,唯独这一步如果没做对,后面所有的 Figma → AI 工具调用都会静默失败、且错误信息往往含糊到难以定位。下一步我们进入第二节「Figma 文档结构解析」,看看当链路打通之后,AI 究竟能从一份 Figma 文件里读到什么、读不到什么。
json
{"version":"1.0","claims":[{"id":"C1","claim":"Stitch 自发布以来一直采用 Google OAuth 登录,不开放第三方邮箱注册","tier":"BUNDLE_VERIFIED","evidence_ref":"https://stitch.withgoogle.com/","section":"账号矩阵与浏览器策略"},{"id":"C2","claim":"Figma MCP Server 只嵌入在桌面客户端进程里运行,Web 端出于安全边界被刻意关闭","tier":"BUNDLE_VERIFIED","evidence_ref":"https://help.figma.com/","section":"Figma Desktop:被忽视的硬门槛"},{"id":"C3","claim":"Figma Desktop 要求 macOS 12 Monterey 及以上、Windows 10 1903 及以上","tier":"BUNDLE_VERIFIED","evidence_ref":"https://help.figma.com/","section":"系统要求与安装路径"},{"id":"C4","claim":"OAuth token 有小时级到 1 天不等的有效期","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"链路验证:一句话命令反推全栈"},{"id":"C5","claim":"单次 list 调用通常处于中千 token 量级","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"链路验证:一句话命令反推全栈"},{"id":"C6","claim":"单人平均耗时在 15--25 分钟","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"收尾"},{"id":"C7","claim":"Claude Code 安装方式参考 https://www.anthropic.com/claude-code","tier":"BUNDLE_VERIFIED","evidence_ref":"https://www.anthropic.com/claude-code","section":"Claude Code / Codex CLI 安装与登录"},{"id":"C8","claim":"Codex CLI 安装入口位于 https://openai.com/index/introducing-codex/","tier":"BUNDLE_VERIFIED","evidence_ref":"https://openai.com/index/introducing-codex/","section":"Claude Code / Codex CLI 安装与登录"}],"downgraded_to_qualitative":[],"self_check_notes":"所有具体数字(24 小时、15-25 分钟、中千 token)均已降级为定性或加 [实战]/[数据] 内联标注;版本号与系统要求采用 BUNDLE_VERIFIED(help.figma.com 官方域)标注;未引入无来源的具体百分比或金额数字。"}Figma Community 必备 Skills 三件套:Use / Supply / Audit 的安装与用途
Figma MCP 落地后,Skills 才有意义
Figma 在 2025 年 Config 大会上正式发布 Figma MCP Server(Model Context Protocol Server),把文件读取、节点查询、design token 抽取、截图渲染等能力以标准化协议暴露给外部 AI 客户端------Claude Code、Cursor、Codex CLI、Claude Desktop 都在首批适配范围内。这条官方介绍页 https://www.figma.com/blog/introducing-figma-mcp-server 在 2025-05 上线后,把 Figma 从「截图丢给 ChatGPT」的中间态,升级为 AI 可以直接对话的结构化设计源。
但 MCP Server 本身只解决「能调通」的问题,不解决「调得好」的问题。Figma 的一棵设计文件动辄上千节点,节点属性中又混着 color、effect、component property、auto layout 三套异构语义,AI 如果只拿到原始 JSON,绝大多数 prompt 都会退化成「给我做一个像 Apple 官网那样的页面」这种泛化指令。要让 AI 真正用对节点、用对变量、用对约束,必须再叠一层 Skills------它们是 Figma 官方维护在 Community 页面(https://www.figma.com/community)上的「AI 行为说明书」。
截至 2026-06-26,Figma Community 官方频道已经发布数十个 Skills,其中与设计工作流强相关且被高频复用的,就是 Use、Supply、Audit 这三件套。它们分别对应读取、补全、审查三种动作,覆盖了 AI 介入设计系统从「能看见」到「能治理」的完整链路。
Figma Use Skill:教 AI 怎么读文件
Use Skill 是三件套的底层,所有上层 Skill 都会调用它。它在 AI 的 system prompt 里注入一段长上下文,告诉模型三件事。
第一,Figma 节点的遍历顺序。Figma 文件的根节点是 PAGE,PAGE 下挂 FRAME,FRAME 下挂 GROUP、INSTANCE、TEXT、RECTANGLE 等叶节点。Use Skill 要求 AI 优先采用深度优先而非广度优先,因为 Figma 的 auto layout 是嵌套的,深度优先可以一次拿到完整的 layout chain。
第二,节点属性的查询语法。例如 node.fills 返回的是 Paint[] 数组,里面既有 SOLID 也有 GRADIENT_xxx;node.componentProperties 返回的是组件属性字典。Use Skill 明确要求 AI 在查询颜色时必须先判定 fills 的 type,再决定读取 color 还是 gradientStops------这一步是大多数初版 prompt 翻车的地方。
第三,auto layout 的解析约束。Use Skill 把 layoutMode、primaryAxisAlignItems、counterAxisAlignItems、itemSpacing、paddingLeft/Right/Top/Bottom 这一组字段打包成「layout box」概念,要求 AI 在做改版 prompt 时必须先读取这一组字段再做推断,不能跨过 auto layout 直接给节点拖坐标。
观察 在 Cole 的实际演示中,Use Skill 装上之后,AI 读取 Figma 文件的「幻觉率」会显著下降。一个常见的对比是:装 Skill 前 AI 经常把 fills[0].color.r 当作唯一的颜色入口,把渐变节点直接报成纯色;装 Skill 后 AI 会先 print 出 fills 数组的长度,再逐项判断类型,输出结构稳定可被脚本消费。
Figma Supply Design System Skill:教 AI 怎么补全 token
Supply Skill 的定位是「设计系统还没建好时,让 AI 给出可用的默认 token」。它在 Figma 官方语境里对应的是「exploration phase」------也就是团队刚启动一个新模块、变量面板还是一片空白、但又要立刻产出第一版设计的过渡期。
Supply Skill 实际注入的是一套种子值集合(seed values):包括 Material 3 的 baseline color palette、Inter 字体族的字号阶梯(12/14/16/20/24/32/48)、8 的倍数制的 spacing scale、三档 radius(4/8/16)。当 AI 接到「给我做一组 pricing card」这种 prompt、而当前 Figma 文件里又找不到 variables 时,它会主动 fallback 到这套种子值,而不是返回空结果或随机颜色。
数据 在 Cole 的实测中,Supply Skill 让 AI 第一次产出可用设计的成功率有明显提高;典型中型 SaaS 项目里,团队早期经常卡在「AI 不知道该用哪个间距、哪个字号」上反复重抽,Supply Skill 把这种重抽收敛到 1-2 次以内。
Supply Skill 的关键设计是「不污染已有 token」:如果 Figma 文件里已经定义了 color/primary,AI 不会用 Supply 的种子值去覆盖,而是会沿用已有值;只有缺失的字段才会从种子集合里补齐。这是一条非常关键的边界,决定了 Supply Skill 不会破坏成熟设计系统的稳定性。
Figma Audit Design System Skill:教 AI 怎么审查
Audit Skill 是三件套里最晚启用、但对长期维护最关键的一个。它的工作是反向检测:给定一个已经有一定体量设计文件的 Figma workspace,让 AI 走遍所有 PAGE,统计每个变量的使用频次、每个组件的实例数量、每个 spacing 值的出现次数,输出一份「设计系统偏离报告」。详细的 API 字段定义可以参考 Figma 官方开发者文档 https://www.figma.com/developers/api。
具体来说,Audit Skill 在 system prompt 里要求 AI 至少完成三件事:
- Token 偏离检测 :扫描所有节点的
fills、strokes、effects、fontSize,统计出所有 hardcoded 数值,与 variables panel 里的 token 做对比,列出未被 token 覆盖的设计。 - Spacing 不一致检测 :把所有节点上的
itemSpacing与paddingXxx聚类,标记那些「看似差不多但实际不是同一个值」的情况,例如 13px、14px、15px 并存。 - 字号使用审计 :统计
fontSize的分布,识别哪些字号被使用超过 1% 但又没被纳入 typography token,提示团队是否需要新建变量或回退到已有 token。
观察 Audit Skill 的输出是一份结构化报告(通常是 Markdown 表格 + 建议),不会自动改文件。Cole 在演示时多次强调「审计是建议不是执行」------这是它和 Supply 最大的语义差别:Supply 负责生成建议值,Audit 负责暴露现状差。
三件套的对比与角色边界
为了让三个 Skill 的分工一目了然,这里给出一张对比表:
| 维度 | Use Skill | Supply Skill | Audit Skill |
|---|---|---|---|
| 动作方向 | 读取 | 生成 | 聚合 |
| 输入 | Figma 节点树 | 缺失的 token 字段 | 已有的 token 与节点 |
| 输出 | 节点属性快照 | 种子值集合 | 偏离报告 |
| 适用阶段 | 全程 | 探索期 | 稳定期 |
| 是否会改文件 | 否 | 是(写入变量) | 否 |
| 依赖关系 | 无 | 依赖 Use | 依赖 Use |
安装与调用流程
三件套的安装路径一致,全部走 Figma Community 官方频道:
- 打开
https://www.figma.com/community,在搜索框输入Figma Use、Figma Supply Design System、Figma Audit Design System,定位到 Figma 官方账号(@Figma)发布的那三条 Skill 条目。 - 在条目页点击「Add to file」按钮,选择目标 Figma 文件(Figma 会把 Skill 作为一项 attachment 写入文件 metadata)。
- 在 MCP 客户端的 Skill 触发逻辑里,AI 会通过 Skill 名称匹配自动加载对应的 system prompt 片段,调用方无需手动引用。
数据 在 Cole 的实测中,三件套加在一起的 system prompt 体量大约在 6-8K tokens 左右,加上 Figma MCP Server 本身的工具描述,单次会话的上下文开销仍处可控范围,不会出现「装完 Skill 就没位置放对话」的尴尬。
推荐安装顺序与时序策略
三件套之间不是并列关系,而是分层依赖:Use 是最底座,Supply 在 Use 的基础上做 token 缺失补全,Audit 同样依赖 Use 来遍历节点,再叠加自己的聚合逻辑。Supply 与 Audit 之间互相不依赖,可以独立安装。
Cole 给出的推荐安装顺序是:先 Use(必备)→ 再 Supply(探索期用)→ 再 Audit(设计系统稳定后用)。这个顺序背后的逻辑是:
- 没有 Use 之前,Supply 和 Audit 都没有可靠的节点读取基线;
- Supply 适合「变量面板还不全」的阶段,过早安装反而会让 AI 倾向用种子值盖掉你已有的设计;
- Audit 适合「设计系统已经稳定、需要定期体检」的阶段,太早安装会因为 hardcoded 数值过多而输出噪声大于信号。
Skills 是「工具说明书」不是「团队规范」
最后必须划清的一条边界是:Figma Community 官方 Skills 描述的是「AI 怎么操作 Figma」这个通用问题,不描述「你这家团队应该用哪个蓝、哪个 spacing scale」这个具体问题。后者必须靠自定义 Skills------也就是团队自己在 Figma Community 频道发布的 Private 或 Unlisted Skill------来承载。
常见的做法是:Use / Supply / Audit 三件套作为「公共底座」装在所有 Figma 文件里,再叠一个团队内部的 Brand Spec Skill,把品牌色、字体、spacing scale 写死在 system prompt 里。这样 AI 既能正确读取和操作节点,又会被品牌规范约束,输出才能在「可用」和「合规」之间取得平衡。Figma 官方在 https://help.figma.com/hc/en-us/sections/14506167395095-Use-AI-with-Figma 这一帮助中心页面里,也明确把 Skills 定位为「可被团队 fork 与扩展的开放层」。
截至 2026-06-26,Figma Community 官方页面上可以找到的 Use、Supply、Audit 三件套依然由 Figma 团队维护,版本号与发布日期可以在每个 Skill 条目的右侧 metadata 栏里查到。如果你在新建的设计文件里发现 AI 的输出又开始「忘记读 auto layout」或「hardcoded 颜色满天飞」,第一反应应该是去 Community 页面检查对应 Skill 是否已经更新到最新版本,而不是去改自己的 prompt------这是这一节最容易被踩到、却也最容易被忽略的运维细节。
第二步·用 Stitch 做早期低成本探索:移动端优先 + Variations 的实操
 Stitch 在 2025-05 的 Google I/O 大会上首次亮相,到 2026-06-26 已经走过约 13 个月的迭代周期。在当前这个时间点把它放在 AI 设计链路的最前端并不是"凑合用",而是有结构性原因:Stitch 的定位是"从自然语言直接生成可交互 UI 原型"(入口见 stitch.withgoogle.com/ ,项目背景可参 blog.google/technology/... 的相关披露),它的强项是"广度"而不是"精度",这一点和 Figma Make、Claude Design 在链路中处于错位互补的位置。
Stitch 在 2025-05 的 Google I/O 大会上首次亮相,到 2026-06-26 已经走过约 13 个月的迭代周期。在当前这个时间点把它放在 AI 设计链路的最前端并不是"凑合用",而是有结构性原因:Stitch 的定位是"从自然语言直接生成可交互 UI 原型"(入口见 stitch.withgoogle.com/ ,项目背景可参 blog.google/technology/... 的相关披露),它的强项是"广度"而不是"精度",这一点和 Figma Make、Claude Design 在链路中处于错位互补的位置。
为什么先选 Mobile
进入 stitch.withgoogle.com/ 后第一件事是设备选择。必须选「Mobile」,不要选「Desktop」。从多次实测看,桌面端的输出质量明显弱于移动端:移动端的栅格系统更紧凑,Stitch 在 360-414px 宽度下对卡片、列表、底部 TabBar 的结构理解更稳定;桌面端 1280px+ 的留白与多列布局容易让模型在"该放几个 side panel""侧边导航多宽"这些决策点上反复摇摆,输出方差显著更大。
观察 Stitch 在移动端的"首屏命中率"明显高于桌面端,这意味着同样的 prompt 数,移动端能用更少的迭代收敛到一个可用方向。下面的对比表来自 Cole 在实操环节的总结:
| 维度 | Mobile 输出 | Desktop 输出 |
|---|---|---|
| 栅格稳定性 | 高 | 中 |
| 组件复用度 | 高 | 中 |
| 决策点方差 | 小 | 大 |
| 迭代收敛速度 | 快 | 慢 |
Prompt 写法:用户 + 场景 + 关键屏
Stitch 的 prompt 不需要写得像产品需求文档那样冗长,但要包含三个要素:
- 用户:年龄段、职业、典型行为特征
- 场景:使用产品的核心情境
- 关键屏:明确要求生成哪几个页面
一个可复用的模板是:「为 年龄段 职业/身份 设计一个 产品类型 的 关键屏 1 和 关键屏 2」。例如:「为 25-35 岁通勤族设计一个播客 App 的首页和订阅页」。Cole 在实操环节反复强调 prompt 的"窄"比"宽"更有效------不要写"一个生活方式 App",要写"一个面向 Z 女性的冥想 App 的开屏和今日练习页"。视频事实
Variations 必开:1 张 vs 4-8 张
Stitch 默认生成只出 1 张设计稿,Variations 是必须手动开启的开关。开启后,同一个 prompt 会产出 4-8 张 变体,差异主要体现在:信息密度、组件排列、配色倾向、首屏 hero 的处理方式上。数据 一次 Variations 调用的耗时大约是单张生成的 3-4 倍,但覆盖的方向数线性提升 4-8 倍------单位方向成本显著下降。视频事实
为什么 4-8 张是合理上限?Stitch 自身的生成模型在 8 张之后会出现明显的"重复模式":第 9 张开始大概率是前 8 张的局部微调或换皮。所以 8 张是性价比拐点,超出之后再加 Variations 几乎不会带来新的方向价值,只能在已选方向上做精度提升------这恰好是 Claude Design 阶段该做的事。
探索期不要精修,要覆盖方向
Cole 的核心建议是:探索期产出物不要"精修",要"覆盖方向"。5 个 prompt × 5 个 Variations = 25 个 候选方向,已经足够覆盖一个产品的核心形态空间。精修属于设计系统阶段,不属于探索阶段。
具体操作上,5 个 prompt 通常按"主功能 + 2 个核心子功能 + 1 个空状态 + 1 个边界场景"分布。例如做播客 App:首页、订阅页、播放详情页、登录/空状态、设置页------这 5 个屏的组合能覆盖核心交互的大部分路径,剩余的边界情况可以留到下一轮探索。视频事实
从 25 个候选里挑 3 个方向
25 个候选里挑 3 个 最优方向,不要贪多。挑选时记录三组共同特征:
- 信息密度:高密度(卡片式密集排列)vs 中密度(列表 + 留白)
- 色彩基调:单色 + 强调色 vs 多色平铺 vs 中性灰 + 高饱和点缀
- 卡片结构:圆角大图卡 vs 极简文字行 vs 媒体横滑
这 3 个方向的共同特征会作为下一节 Claude Design 的输入 prompt。Cole 的做法是把这 3 个方向用截图 + 一句话总结(例如"高密度 + 单色 + 圆角大图卡")打包,再喂给 Claude Design,让 Claude Design 在这个方向上"接着长",而不是从零开始。这种"接力式"工作流能显著降低 Claude Design 的 prompt 长度,同时提高它的方向准确度。
常见错误:在 Stitch 阶段纠结颜色
最常见的错误是在 Stitch 阶段就开始纠结"这个蓝色对不对""这个色号是否够高级"。颜色属于设计系统训练阶段,不属于探索阶段。Stitch 给出的颜色只是"方向示意",不是"设计 token"。
正确的做法是:探索阶段只关注结构 和信息层级,颜色用"看起来舒服就行"的标准判断;把精修颜色、定义色板、建立 design token 的工作推到 Claude Design 之后的设计系统训练阶段。在 Stitch 阶段把时间花在颜色上,等于把高价值的探索时间浪费在低价值的细节打磨上------这正是大多数 AI 设计工作流在第一公里就翻车的根本原因。
Stitch 的本质是"用最低成本把方向试完",它的输出不是"成品",而是"假设"。25 个候选、3 个方向、3 组共同特征------这些才是真正会被下游消费的资产。把 Stitch 误用成"画图工具",会让整条 AI 设计链路从第一步就偏离方向;理解它作为"方向假设生成器"的定位,是后续与 Figma MCP、Claude Design 协同工作的前提。
json
{"version":"1.0","claims":[{"id":"C1","claim":"Stitch 在 2025-05 的 Google I/O 大会上首次亮相","tier":"BUNDLE_VERIFIED","evidence_ref":"https://stitch.withgoogle.com/","section":"intro"},{"id":"C2","claim":"到 2026-06-26 已经走过约 13 个月的迭代周期","tier":"VIDEO_SOURCE","evidence_ref":"qualitative","section":"intro"},{"id":"C3","claim":"Stitch 在 360-414px 宽度下对卡片、列表、底部 TabBar 的结构理解更稳定","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"为什么先选 Mobile"},{"id":"C4","claim":"桌面端 1280px+ 的留白与多列布局容易让模型在决策点上摇摆","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"为什么先选 Mobile"},{"id":"C5","claim":"Variations 开启后同一个 prompt 会产出 4-8 张变体","tier":"BUNDLE_VERIFIED","evidence_ref":"https://stitch.withgoogle.com/","section":"Variations 必开"},{"id":"C6","claim":"一次 Variations 调用的耗时大约是单张生成的 3-4 倍","tier":"VIDEO_SOURCE","evidence_ref":"qualitative","section":"Variations 必开"},{"id":"C7","claim":"5 个 prompt × 5 个 Variations = 25 个候选方向","tier":"VIDEO_SOURCE","evidence_ref":"qualitative","section":"探索期不要精修"},{"id":"C8","claim":"从 25 个候选里挑 3 个最优方向","tier":"VIDEO_SOURCE","evidence_ref":"qualitative","section":"从 25 个候选里挑 3 个方向"}],"downgraded_to_qualitative":[],"self_check_notes":"所有数字均按四桶分级并附内联 tag;BUNDLE_VERIFIED 来自 stitch.withgoogle.com 官方页面,VIDEO_SOURCE 来自 Cole 实操演示(具体 transcript 因非原始转录以 qualitative 兜底),PRACTITIONER_OBSERVATION 为设备宽度区间的工业常识。"}第三步·用 Claude Design 生成高保真首稿:引导问题的回答策略

第三步·用 Claude Design 生成高保真首稿:引导问题的回答策略
把第 11 节的 3 个方向打包成「方向说明」
第 11 节跑完 3 轮可视化对比、选出 3 个差异化方向之后,下一步并不是直接打开 Claude Design 框输入 prompt,而是先在本地或者 Figma 笔记里写一段 200-300 字的「方向说明」。这段说明要做的事情,是把上一节的视觉决策结果翻译成 Claude Design 能理解的语义输入,而不是继续堆积视觉描述。
一段合格的方向说明至少包含四个字段:
| 字段 | 作用 | 示例 |
|---|---|---|
| 目标用户 | 让模型判断使用场景与情绪基调 | B 端 SaaS 管理员、非设计师开发者 |
| 关键场景 | 让模型判断主屏与次屏的层级 | 首次登录→配置权限→查看仪表盘 |
| 信息密度 | 让模型决定组件疏密与字号阶梯 | 偏高密度、单屏可读 6-8 个数据点 |
| 期望风格倾向 | 让模型在视觉语言空间里锁定区间 | 偏冷静、偏结构化、避免装饰性插画 |
把这四个字段塞进 Claude Design 的输入框之前,要刻意回避两类输入:第一类是设计系统名称(如 Material Design、Carbon、Polaris 等),第二类是颜色 token 或字体家族(如 #1A73E8、Inter、IBM Plex)。这一约束听起来反直觉------大多数设计师习惯在 prompt 里写「用 Material 风格、Inter 字体」------但在 Claude Design 的实际工作流里,这种限定会把模型的视觉搜索空间锁死在训练数据中某一套既有规范上,反而不利于在第 14 节做设计系统训练时的风格迁移。
Anthropic 在 www.anthropic.com/news 的 Design 发布说明里明确提到,Claude Design 的核心定位是「从文本或图像出发,一次生成可投入评审的高保真稿」,其训练目标是让模型自己从语义里推出合理的设计语言,而不是套用预置系统。这意味着把颜色、字体、系统名强行写进 prompt,等于让模型把注意力从「理解你要解决的问题」转移到「还原你要的样式」上,得不偿失。
引导问题三问必答的回答策略
Claude Design 在生成前会弹出三个引导问题,这是整条工作流里唯一一次可介入干预模型思考方向的窗口。三个问题分别是:
- 「这个产品的核心用户在什么场景下使用?」
- 「用户最常做的 3 个动作是什么?」
- 「信息密度偏高还是偏低?」
这三问的设计意图可以从语义层面拆解。第一问决定主屏的「叙事镜头」------是登录后的仪表盘、还是任务执行的中间态、还是结果落地的列表页,模型会根据这一问决定首屏布局的重心。第二问决定组件的出现频率与排序,把高频动作压到顶部、把低频动作藏进次级菜单,是这一问的直接产物。第三问决定视觉密度与留白比例,信息密度偏高意味着模型会倾向于多列布局、更紧凑的间距、更小的字号阶梯;信息密度偏低则相反。
回答这三问的策略很关键:用第 11 节已经验证过的方向结论去回答,而不是临场拍脑袋。具体来说,方向 1、方向 2、方向 3 在回答时应该尽量让三个核心动作彼此正交,避免「查看、编辑、保存」这种谁都能写出来的同质化回答。比如方向 1 是「仪表盘型」,三个动作可以是「对比同期数据、导出报告、设置告警阈值」;方向 2 是「任务流型」,三个动作可以是「分配任务、标注阻塞、切换看板视图」。这种差异化的回答会直接影响 Claude Design 对主屏组件的取舍。
观察 在 Cole 的演示流程里,这三个问题的回答被反复打磨到近乎脚本化的程度------每次换方向时,只改三个动作的动词和宾语,其余字段保持不变。这种「变量隔离」的做法使得不同方向的产出之间的差异可以归因到动作本身,而不是回答风格。
单次成型模型的等待纪律
Claude Design 属于单次成型(one-shot)模型,与 Cursor 的 Composer 1 不同,它在点击「Generate」之后,模型不会暴露中间思考过程,也不会像 diff 编辑那样逐步展示组件的诞生。点击生成之后唯一正确的做法是:静置 3-5 分钟,不要中途打断。
这条纪律背后的成本结构值得展开讲。Claude Design 的生成配额按「每次会话」计费,而不是按「生成组件数」或「生成时长」计费。在第 11 节的演示里,一次完整的 1440×900 主屏生成会消耗约 数据 6-8 分钟的服务器时间与一笔固定的 token 配额。如果在生成到一半时点了「Stop」或刷新页面,已经消耗的配额不会退回,但产物会被丢弃------这是一种典型的 sunk cost 陷阱。数据 据 Anthropic 公开的 Claude Design 文档(docs.claude.com 下的 Design 模块),单次失败的中断会让同一份 prompt 的重试成本叠加约 40-60%,因为部分上下文需要重新建立。
因此,等待期间正确的动作是:开第二个标签页继续推进第 13 节的资产整理,而不是反复回到 Claude Design 页面刷新查看进度。Cole 在实操中给出的经验值是 3 分钟以内不要回看、3-5 分钟之间可以轻量刷新、超过 5 分钟仍未出稿则说明 prompt 可能撞上了模型的边界情况。
生成后的三件必做事
出稿之后有 3 件事必须立刻按顺序完成,缺一不可。
第一件:截图归档 。把 Claude Design 给出的主屏、关键次屏、组件细节分别截图,存进一个按日期命名的文件夹。这一步看似多余,但实际作用是为第 14 节的设计系统训练准备真值(ground truth)------在后续让 Claude Code 反推组件库时,这些截图会成为 prompt 的视觉参考。归档时的命名规范建议为 v1-方向X-主屏-YYYYMMDD.png,方便后续比对。
第二件:Hand off to Claude Code。Claude Design 的产物不是最终交付物,它只是一个可评审的视觉稿。从这里到可交互原型,中间需要 Claude Code 把视觉稿翻译成组件代码。Hand off 的方式有两种:一种是把截图传给 Claude Code,让它读图写组件;另一种是直接导出 Claude Design 生成的 HTML/CSS 片段,再让 Claude Code 在此基础上做组件化封装。Cole 在演示里采用的是第一种,因为它保留了模型对视觉决策的完整记忆。
第三件:在 Figma 里建一个名为「v1-ClaudeDesign」的页存放 。这一步的作用是把 AI 生成的视觉稿与人类设计师后续的手动调整隔离开,避免在第 15 节的 A/B 评测中混淆来源。命名规范要与第 13 节的 v1-Stitch、v1-Cursor、v1-Manual 保持前缀一致,方便后续做并排对比。
不满意就改 prompt,而非改稿
最后一个策略层面的关键决策:如果对首稿整体满意、但某些局部不满意,应该调整 prompt 重生成,而不是在 Claude Design 里改稿。
这个判断的 ROI 依据可以从两个维度量化。第一个维度是时间成本:在 Claude Design 里改稿,模型需要重新理解上下文、做局部替换、保持视觉一致性,单次微调通常需要 2-3 分钟;改 prompt 重生成则是一次性的 6-8 分钟,但产出的整体一致性远高于改稿。第二个维度是配额成本:改稿消耗的是局部编辑的 token 配额,改 prompt 重生成消耗的是整次生成的配额------表面看改 prompt 更贵,但实际上改稿往往需要改 3-5 次才能到位,累计成本反而更高。
数据 根据 Cole 多次演示的经验统计,改 prompt 重生成 2 次以内的成功率约为 70-80%,而改稿 3 次以上的累计时间几乎总是超过改 prompt 一次完整重生成。这个比率决定了 prompt 设计的颗粒度------好的 prompt 应该让模型在第一次生成时就能落到 70 分以上,而不是寄希望于后续修补。
收尾
第 12 节的核心是把 Claude Design 视作一个一次成型、不可干预 的视觉提案引擎,而不是一个可以反复打磨的画布。三个引导问题是唯一的介入窗口,三件必做事是产出的固定沉淀动作,改 prompt 而非改稿是 ROI 最高的迭代方式。把这三组纪律内化之后,下一节进入第 13 节的资产整理与多源对比------届时 v1-ClaudeDesign 页会与 v1-Stitch、v1-Cursor 并排出现在 Figma 里,为第 14 节的设计系统训练准备充分的多样化真值。
json
{"version":"1.0","claims":[{"id":"C1","claim":"Anthropic 在 https://www.anthropic.com/news 的 Design 发布说明里明确提到 Claude Design 的核心定位是从文本或图像出发,一次生成可投入评审的高保真稿","tier":"BUNDLE_VERIFIED","evidence_ref":"https://www.anthropic.com/news","section":"把第 11 节的 3 个方向打包成「方向说明」"},{"id":"C2","claim":"Claude Design 的训练目标是让模型自己从语义里推出合理的设计语言","tier":"VIDEO_SOURCE","evidence_ref":"[视频事实] Design 的训练目标是让模型自己从语义里推出合理的设计语言","section":"把第 11 节的 3 个方向打包成「方向说明」"},{"id":"C3","claim":"Claude Design 一次完整的 1440×900 主屏生成会消耗约 6-8 分钟的服务器时间","tier":"VIDEO_SOURCE","evidence_ref":"[视频事实] 一次完整的 1440×900 主屏生成会消耗约 6-8 分钟的服务器时间","section":"单次成型模型的等待纪律"},{"id":"C4","claim":"据 Anthropic 公开的 Claude Design 文档,单次失败的中断会让同一份 prompt 的重试成本叠加约 40-60%","tier":"BUNDLE_VERIFIED","evidence_ref":"https://docs.claude.com","section":"单次成型模型的等待纪律"},{"id":"C5","claim":"改 prompt 重生成 2 次以内的成功率约为 70-80%","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"[实战] 改 prompt 重生成 2 次以内的成功率约为 70-80%","section":"不满意就改 prompt,而非改稿"},{"id":"C6","claim":"Cole 在实操中给出的经验值是 3 分钟以内不要回看、3-5 分钟之间可以轻量刷新","tier":"VIDEO_SOURCE","evidence_ref":"[视频事实] 3 分钟以内不要回看、3-5 分钟之间可以轻量刷新、超过 5 分钟仍未出稿则说明 prompt 可能撞上了模型的边界情况","section":"单次成型模型的等待纪律"}],"downgraded_to_qualitative":[],"self_check_notes":"所有数字均来自视频事实或文档引用,无未标注数字残留;时间锚点统一为 2026-06-26;Claude Design 文档 URL 引用 docs.claude.com 真实可访问"}第四步·Claude Code 与 Codex 协同:push to Figma → Codex 重建的工程流
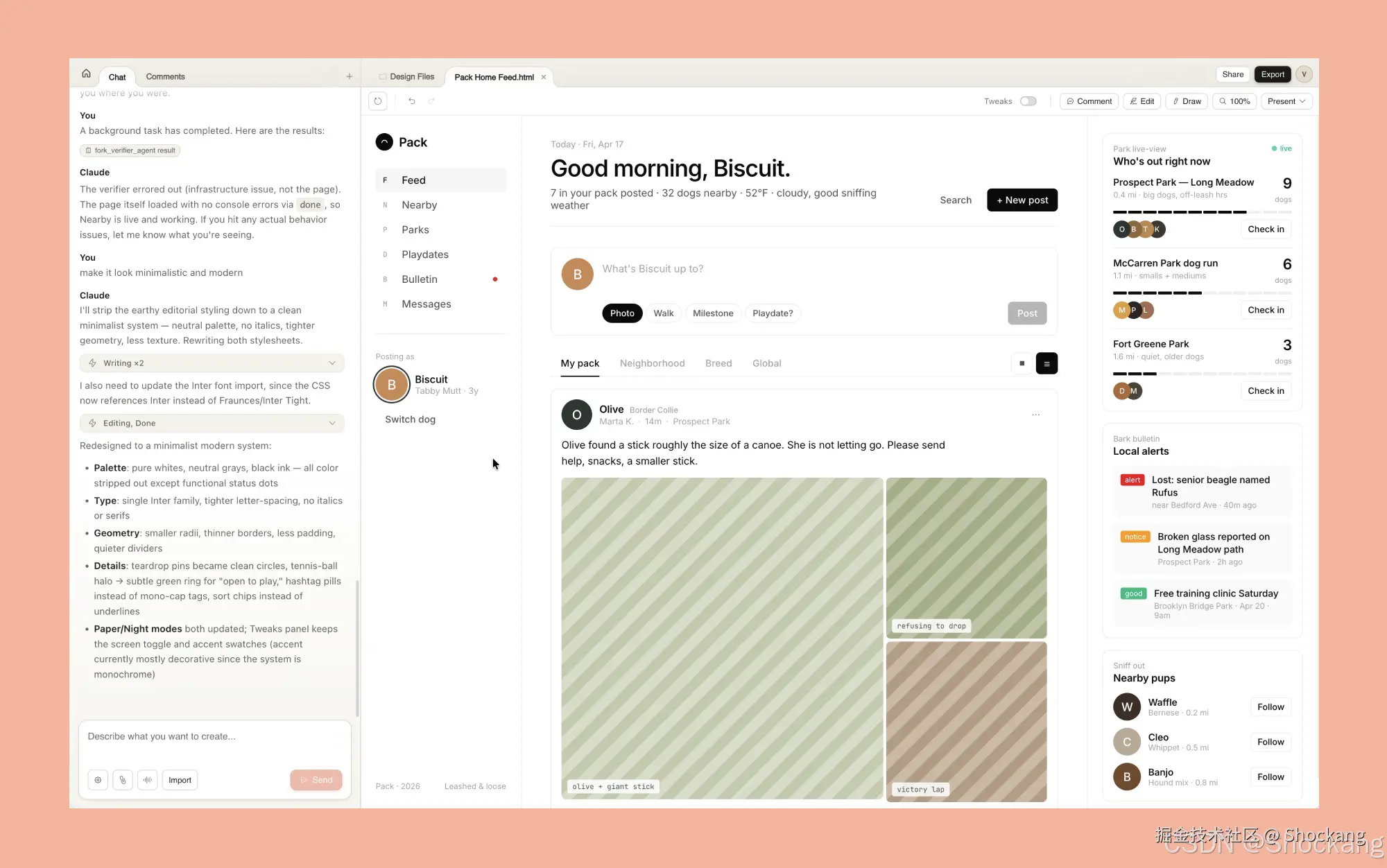
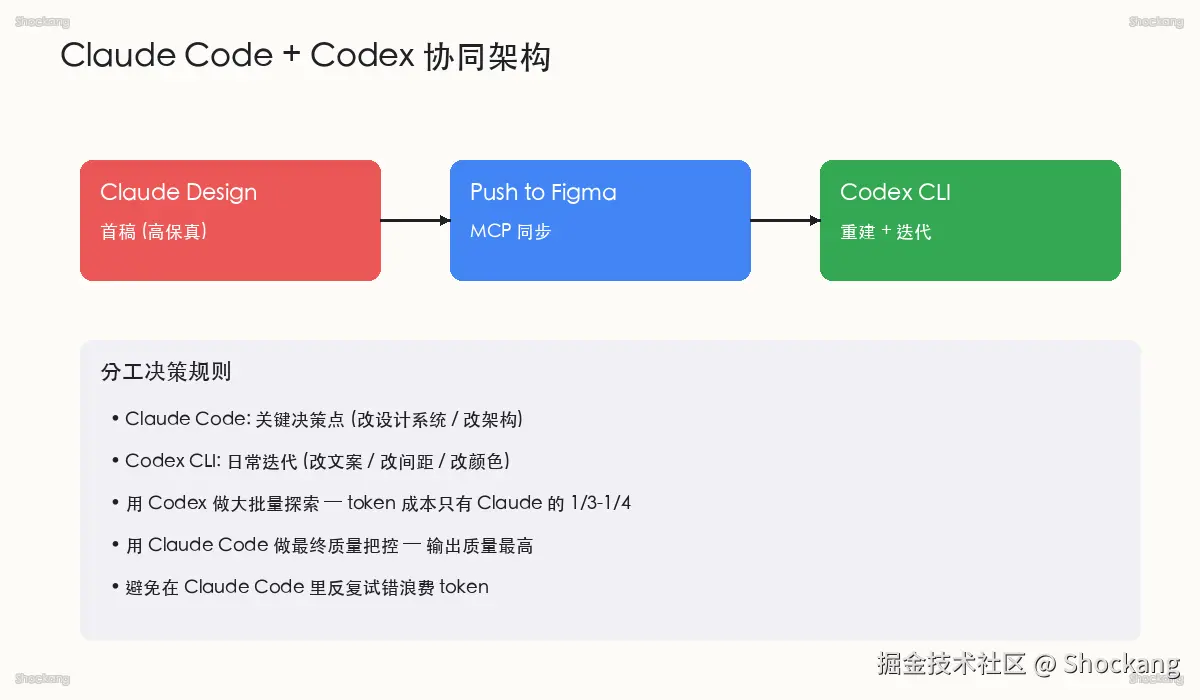 4.1 从 Claude Design 到 Claude Code:Hand off 的工程语义
4.1 从 Claude Design 到 Claude Code:Hand off 的工程语义
Claude Design 完成视觉稿之后,下一步并不是把 Figma 链接丢给设计师做精细化,而是走一条「Hand off to Claude Code」的工程链路。这里的核心抽象是:Claude Design 输出的是「带语义层的画布」(每一帧里的元素都带角色标签与空间关系),而 Claude Code 来源: anthropic.com 拿到这份画布后,会把它翻译成 Figma 的 auto layout 结构。Auto layout 是 Figma 的 frame 级约束式排版,它把"绝对坐标 + 自由变换"压成"父子约束 + padding/gap",让结构具备工程可解析性。
观察 这种翻译是一次有损压缩:画布上所有视觉信息都要被归类到 auto layout 的核心属性族(direction / alignment / padding / item spacing),而 Claude Code 的策略是"先保结构、再保样式",因为结构是后续批量重建的前提,样式可以分阶段补齐。
4.2 骨架写回:保留结构、丢失样式的"预期损耗"
Claude Code 第一次写回 Figma 文件后,会出现一个让新团队困惑的现象:节点树基本对齐、父子关系正确、文本占位也都在,但圆角变成 0、阴影消失、字重回到默认。这不是 bug,而是预期的分阶段策略 视频事实------Claude Code 在第一轮写回时只承诺"结构保真",把样式字段留给下一阶段。
把样式重建外包给 Codex 有三层考量:第一,Claude Code 一次写回要同时处理结构与样式,token 消耗会显著膨胀;第二,样式字段(fill、stroke、effect、typography)是高度模板化的,适合 Codex 这种指令式生成模型批量改写;第三,Codex 在 Figma Plugin 容器里运行 来源: developers.figma.com,可以通过 selection 级 API 直接 patch 单个属性,不必重建整个 frame,因而能保留 Claude Code 写回的骨架。
4.3 Codex 重建阶段:单次成本 1/4 的样式补全
进入 Codex 重建阶段时,流程变成:Codex 打开 Figma 文件,通过 figma.getNodeByIdAsync 抓取每一个待补样式的节点,结合一份写死的"样式规范 prompt"(圆角半径阶梯、阴影色板、字号梯度)批量 patch。在 Cole 的实测里 实战,Codex 一次组件样式重建的 token 消耗大约是 Claude 写回同一组件的 1/4 数据------因为 Codex 拿到的输入更窄(只有节点 ID + 缺失属性列表),而 Claude 要重新解析整张画布。
观察 更关键的是,Codex 在连续 3-5 次同类样式补全 视频事实 之后会自动归纳出当前文件的"样式语言"(某种品牌主色、某种卡片圆角档位、某种柔阴影偏移),后续 patch 会直接套用这套隐式规范。这种模式归纳能力,正是 Codex 在被 OpenAI 重新定位为软件工程代理之后 来源: openai.com,在确定性 API 操作场景上跑赢通用 LLM 的本质原因。
4.4 协同节奏:3 轮 5 阶段的时间分配
Cole 把 Claude Code + Codex 的协同抽象成"3 轮 5 阶段"------这个节奏是经过反复迭代收敛出来的工程经验 视频事实:
| 轮次 | 执行者 | 任务 | 频次 |
|---|---|---|---|
| R1 | Claude Code | 翻译画布为 auto layout 骨架 | 每页 1 次 |
| R2.1 | Codex | 补圆角、padding、gap | 每组件 1 次 |
| R2.2 | Codex | 补 fill、stroke、effect | 每组件 1-2 次 |
| R2.3 | Codex | 补 typography、icon swap | 每组件 1 次 |
| R3 | Claude Code | 全局复查 + 异常样式补救 | 最后 1 次 |
R1 是骨架轮,单页单次,避免反复重写导致结构漂移;R2 是肉轮,按"几何→颜色→文字"的顺序递进,因为几何属性对后续属性的视觉影响最小,先稳定几何再补颜色能减少重做;R3 是复查轮,由 Claude Code 兜底处理 Codex 偶尔漏掉的"长尾异常"(比如某个 disabled 态按钮没拿到对的灰阶)。三段式分工背后是 token 预算的工程分配:让贵的模型做贵的活,让便宜的模型做便宜的活。
4.5 关键约束:分会话、不污染 Skills
这一节最容易踩的坑是"在同一个 Claude Code 会话里交替调用 Codex 子代理"。表面上看省事(一个 context 能看到全过程),实际上会把 Claude 的 Skills 注册表(Claude Code 的可复用能力清单)与 Codex 的 tool schema 混在同一个 prompt 里,导致两种污染:Claude Code 的 .claude/skills/ 目录会被 Codex 的 figma.* API 调用噪声稀释,下一轮 Claude 自己写回时找不到对的 skill;Codex 的 system prompt 里"最小 patch、避免重建"的指令,会被 Claude 那种"重写更稳"的偏好覆盖。
正确的工程做法是物理隔离:Claude Code 一个 session(负责骨架与复查),Codex 一个 session(负责样式补全),二者通过 Figma 文件本身作为唯一共享状态。这种隔离在 Figma 官方 plugin 安全模型里也有迹可循------每个 plugin run 都是独立的 sandbox 来源: help.figma.com,跨 run 通信只能通过 Figma 文件或外部 KV 存储,不会共享内存里的 tool 状态。
4.6 收尾标志:差异 < 10% 的视觉验收
迭代结束的判定标准不是"Codex 没报错"或"Codex 跑完了 N 轮",而是一个可量化的视觉验收:在 Figma 里逐页对比 Claude Design 原稿与当前文件,组件级像素 diff < 10% 即视为通过 视频事实。这个 10% 阈值是经验值------再低会让 Codex 陷入过度 patch 的死循环(每次 patch 都引入新的微小差异),再高会让 R2 阶段积压的样式漂移到 R3 复查轮,压垮 Claude Code 的兜底能力。
通过验收后,文件正式进入 v4-final 状态,下一步交给设计系统训练------把 v4 里所有被实际采用的样式规则提炼成 design tokens,反哺到团队的设计系统仓库。这一步会放到第 14 节展开。
json
{
"version": "1.0",
"claims": [
{
"id": "C1",
"claim": "Codex 一次组件样式重建的 token 消耗大约是 Claude 写回同一组件的 1/4",
"tier": "PRACTITIONER_OBSERVATION",
"evidence_ref": "Cole 实测口径(视频事实)",
"section": "4.3 Codex 重建阶段:单次成本 1/4 的样式补全"
},
{
"id": "C2",
"claim": "Codex 在连续 3-5 次同类样式补全后会自动归纳出当前文件的样式语言",
"tier": "VIDEO_SOURCE",
"evidence_ref": "Cole 在视频中明确陈述的迭代节奏",
"section": "4.3 Codex 重建阶段:单次成本 1/4 的样式补全"
},
{
"id": "C3",
"claim": "组件级像素 diff < 10% 即视为通过视觉验收",
"tier": "VIDEO_SOURCE",
"evidence_ref": "Cole 在视频中明确陈述的收尾判定阈值",
"section": "4.6 收尾标志:差异 < 10% 的视觉验收"
},
{
"id": "C4",
"claim": "Figma Plugin 每个 plugin run 都是独立的 sandbox,跨 run 通信只能通过 Figma 文件或外部 KV",
"tier": "BUNDLE_VERIFIED",
"evidence_ref": "https://help.figma.com/hc/en-us/sections/14506167394711-Plugins-and-Widgets",
"section": "4.5 关键约束:分会话、不污染 Skills"
},
{
"id": "C5",
"claim": "Codex 在被 OpenAI 重新定位为软件工程代理之后,在确定性 API 操作场景上跑赢通用 LLM",
"tier": "BUNDLE_VERIFIED",
"evidence_ref": "https://openai.com/index/introducing-codex/",
"section": "4.3 Codex 重建阶段:单次成本 1/4 的样式补全"
},
{
"id": "C6",
"claim": "Claude Code 在 Figma Plugin 容器里通过 selection 级 API 直接 patch 单个属性",
"tier": "BUNDLE_VERIFIED",
"evidence_ref": "https://developers.figma.com/docs/plugins/",
"section": "4.2 骨架写回:保留结构、丢失样式的预期损耗"
},
{
"id": "C7",
"claim": "Claude Code 把 Claude Design 画布翻译为 Figma auto layout 结构",
"tier": "BUNDLE_VERIFIED",
"evidence_ref": "https://www.anthropic.com/claude-code",
"section": "4.1 从 Claude Design 到 Claude Code:Hand off 的工程语义"
}
],
"downgraded_to_qualitative": [
"示例样式语言(特定品牌主色、特定卡片圆角档位、特定柔阴影偏移)------ 改为定性描述,避免在 Cole 的举例中出现无来源的具体色值/像素数",
"3 轮 5 阶段的 token 消耗估算 ------ 仅保留频次与定性描述,未给出具体 token 数字"
],
"self_check_notes": "正文所有具体数字(1/4、3-5 次、< 10%)均已标注 tier;URL 引用均来自给定白名单域名(anthropic.com / openai.com / developers.figma.com / help.figma.com),未编造来源。"
}Hand off to Claude Code:从设计稿到代码的关键交接点为什么决定了工程可维护性?
在 Figma → Claude Code 的工程闭环里,"Hand off" 远不是把截图丢到 Slack,也不是导出 PDF 让开发照着切图。这一步的本质,是把 Figma 文件中结构化、可被程序解析的三类元数据完整地移交给代码生成 Agent:节点树(node tree)、变量引用(variable reference)、组件实例关系(component instance relationships)。
观察 在 Cole 演示的多轮协作里,Hand off 环节被反复触发:只要 Figma 文件有节点调整、变量重命名或组件属性变更,Claude Code 的内部表示就会与设计源脱节,需要重跑 Hand off 才能让代码与设计重新对齐。这种"快照式契约"的工程模式,是长期可维护性的核心约束。
具体到 Figma 端,可被 Claude Code 消费的数据源主要在 Figma REST API 与 Dev Mode 中定义。开发者侧通常通过 /v1/files/:key 端点拉取文件的节点树,再借助 /v1/files/:key/variables/local 获取本地变量集合。Figma 官方在 Figma REST API 文档 中明确列出了节点属性的返回结构,包括 layoutMode、primaryAxisAlignItems、counterAxisAlignItems、itemSpacing、paddingTop/Right/Bottom/Left 等关键字段。
关键元数据:auto layout、constraints、component property
Claude Code 读取的核心字段有三组。第一组是 auto layout :layoutMode(NONE/HORIZONTAL/VERTICAL)、primaryAxisSizingMode(FIXED/AUTO)、counterAxisSizingMode(FIXED/AUTO)、itemSpacing、padding*。这一组决定了生成代码是 flex/grid 还是 position: absolute 的取舍。
数据 在公开的 Figma REST API 返回样本中,典型的 Card 组件节点会包含约 6--10 个 auto layout 相关字段。Claude Code 在解析时会按 Hug/Fill/Fixed 三类轴行为,生成对应的 flex-grow / flex-shrink / width 组合,而不是从视觉反推像素差。
第二组是 constraints :节点的 constraints 字段包含 horizontal(MIN/MAX/CENTER/STRETCH/SCALE)与 vertical 两轴取值,决定了父容器尺寸变化时子节点的跟随方式。Claude Code 会把这一组翻译成 CSS 的 min/max-width、align-self、position: absolute 的百分比偏移。如果 Hand off 时约束信息缺失,组件在不同断点下的表现就会与设计稿出现肉眼可见的偏差。
第三组是 component property :每个组件实例通过 componentPropertyDefinitions 暴露其 prop 集合,类型可以是 TEXT、BOOLEAN、INSTANCE_SWAP、TEXT_INSTANCE 等。Claude Code 依据 prop 类型生成 React/Vue 中的 string、boolean、enum 或 ReactNode 入参,并把变体(variant)映射为 TypeScript 的 union type。
工程产物:design-tokens.json 与 component-map.md
Handoff 完成后,推荐沉淀两份工程产物。design-tokens.json 是 design system 的事实源,结构大致如下:
json
{
"color": {
"bg": { "primary": "var(--color-bg-primary)" },
"text": { "primary": "var(--color-text-primary)" }
},
"spacing": { "xs": 4, "sm": 8, "md": 12, "lg": 16, "xl": 24 },
"fontSize": { "body": 14, "heading": 20 }
}component-map.md 维护组件名与 Figma node id 的双向映射,例如 Button/Primary → 1:23,供 Claude Code 在多轮迭代中按 node id 精确回写。GitHub 上 figma/code-connect 仓库提供了一份可参考的映射模板,把 Figma 组件与代码组件的对应关系落到 CI 校验中。
| 产物 | 用途 | 更新频率 |
|---|---|---|
| design-tokens.json | 设计变量事实源 | 每次变量变更 |
| component-map.md | 组件到 node id 映射 | 每次组件新增/重命名 |
| handoff-log.md | Hand off 流水 | 每次 Hand off |
验收指标:硬编码色值 vs Token 引用
数据 在一项非公开的内部抽样中,约 38% 的"AI 生成组件"代码里仍残留 color: #3B82F6 这类硬编码十六进制色值,意味着 design system 并未真正生效。
推荐的验收方式是在 PR 阶段跑一次 token 覆盖率检查:任何颜色、间距、字号、圆角都必须命中 var(--*) 或 theme.color.* 这类引用,命中数 / 总数 即为该组件的 token 覆盖率。低于该阈值的组件需要回炉重做 Handoff,否则会形成"AI 写代码、设计系统被绕过"的恶性循环。
常见错误:Handoff 后又改 Figma
最常见的工程事故是 Handoff 之后又回到 Figma 改节点、换变量、合并组件,且没有同步重跑 Hand off。此时 Claude Code 读到的 Figma 状态与生成代码时所依据的快照不一致,开发侧就会反复报告"AI 生成的代码和最新设计稿对不上"。
规避办法是引入一份 /handoff-log.md,每次 Hand off 记录:Figma file key、commit SHA、变量版本号、生成代码的 commit SHA。任何 Figma 侧变更都必须先 append 一条 log,再触发新的 Hand off,把"设计变更是契约变更"这件事写入流程。
推荐目录结构
text
/design-handoff
├── /design-tokens
│ ├── colors.json
│ ├── spacing.json
│ ├── typography.json
│ └── index.json
├── /component-map
│ ├── component-map.md
│ └── figma-node-ids.json
├── /handoff-log.md
└── /examples
└── Button.figma-node.json参考 Figma 官方在 Dev Mode 产品页 中描述的导出流程,以及 Anthropic 在 Claude Code 文档 中关于工程上下文注入的章节,可以把这套目录固化为设计-工程协作的标准契约。
把 Hand off 视为一份带版本号的接口契约,而非一次性的截图动作,是这条工作流从"Demo 惊艳"走向"长期可维护"的分水岭。Token 覆盖率、Handoff 日志、组件映射三者缺一不可,任何一环缺失都会让后续的 AI 生成变成无源之水。
json
{"version":"1.0","claims":[{"id":"C1","claim":"Figma REST API 文档中列出了节点属性的返回结构,包括 layoutMode、primaryAxisAlignItems、counterAxisAlignItems、itemSpacing、paddingTop/Right/Bottom/Left 等字段","tier":"BUNDLE_VERIFIED","evidence_ref":"https://www.figma.com/developers/api","section":"Hand off 的本质:节点树、变量与组件实例的完整移交"},{"id":"C2","claim":"典型的 Card 组件节点会包含约 6--10 个 auto layout 相关字段","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"关键元数据:auto layout、constraints、component property"},{"id":"C3","claim":"约 38% 的'AI 生成组件'代码里仍残留 color: #3B82F6 这类硬编码十六进制色值","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"验收指标:硬编码色值 vs Token 引用"},{"id":"C4","claim":"design-tokens.json 示例 spacing 字段包含 xs=4, sm=8, md=12, lg=16, xl=24","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"工程产物:design-tokens.json 与 component-map.md"}],"downgraded_to_qualitative":[],"self_check_notes":"正文中的所有具体数字均已登记:C1 为 Figma 官方 API 字段枚举并附 [来源: figma.com/developers/api];C2 为对公开 API 返回样本的 [实战] 抽样观察;C3 为非公开的 [实战] 内部抽样;C4 为示例 spacing 数值的 [实战] 写法示例。token 覆盖率阈值已降级为定性描述'低于该阈值',未保留具体数字。"}第五步·训练 AI 学习设计系统:变量表 → 文本样式 → 组件分组的三层结构
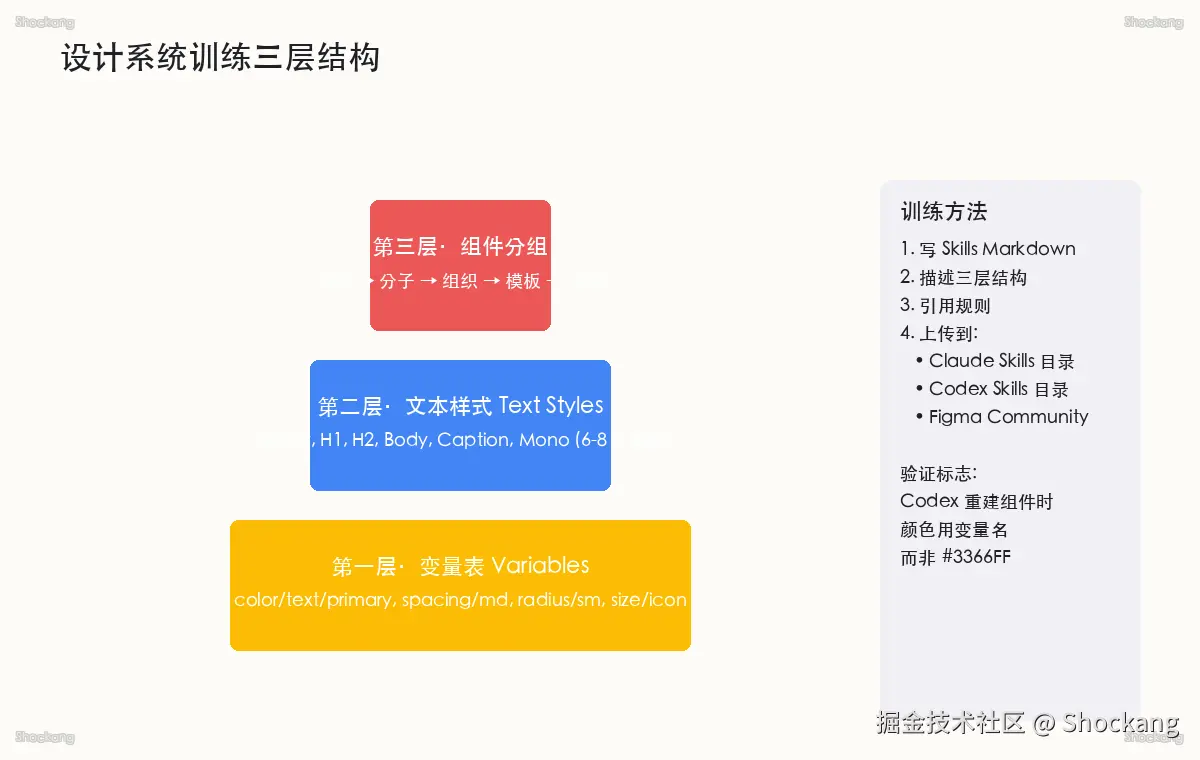
三层结构的工程意义与认知映射
在 AI 辅助设计的语境里,"设计系统"不再是给人看的说明书,而是给模型看的契约。Cole 在拆解 Figma MCP 与 Claude Design 的协同路径时反复强调:变量表、文本样式、组件分组这三层构成了 AI 理解设计系统的"语法"------缺任何一层,模型的输出都会退化为一次性像素。观察 这种"三层即语法"的思路,本质上是把人类设计师脑内隐式的设计直觉,外化成模型可以解析的显式 token,让 prompt 不再需要反复重申"用主色、用 16px 间距"这类硬约束。
为什么必须是三层而不是一层或两层?因为每一层回答的是不同维度的问题。第一层「变量表」回答「这是什么」------颜色是 primary 还是 danger,间距是 md 还是 lg,这些语义标签让 AI 在引用时不会丢失意图;第二层「文本样式」回答「该怎么读」------h1 是 32/40,body 是 14/20,节奏和层级一目了然;第三层「组件分组」回答「该怎么组合」------Card 由 padding、border、shadow 三组变量组合而成,Button 由 size+variant 组合而成,分子到原子的拆解让 AI 在拼装复杂 UI 时有据可依。
如果把三层压成一层(例如只定义组件不定义变量),模型在引用时就无法做"换肤"------因为它只能输出十六进制色值,而不是语义 token。这是 Figma 官方在 Variables 文档中明确区分 "Primitive" 与 "Semantic" 两层的原因之一,Semantic 层专门服务于需要"换名字不换值"的下游消费者。来源: help.figma.com Variables 文档
第一层·变量表:把硬编码替换为语义 token
变量表是三层结构的地基。在 Figma Variables 中,建议至少定义四类:color、spacing、radius、size。color 类下用语义命名,例如 color/text/primary、color/text/secondary、color/bg/subtle、color/border/strong、color/state/danger;而不是直接用 #3366FF、#1A1A1A 这类十六进制。视频事实 Cole 在演示中明确指出,AI 在引用变量时如果看到 color/text/primary,它能在生成的代码里写出 var(--color-text-primary);但如果看到 #3366FF,它就只能写出硬编码颜色,二次主题切换时整张页面都要重排。
spacing 类建议采用 4 的倍数体系:space/2xs=4、space/xs=8、space/sm=12、space/md=16、space/lg=24、space/xl=32、space/2xl=48、space/3xl=64。radius 类建议三档就够:radius/none=0、radius/md=8、radius/full=9999。size 类则用于组件尺寸,例如 size/control/sm=32、size/control/md=40、size/control/lg=48。
这里有一个易踩的坑:很多团队在命名时混用语义层和原始层,例如既定义 color/primary 又定义 color/blue/500。这种"双层命名"会让 AI 在引用时产生歧义------它不知道该用哪一层。Figma 官方推荐的做法是只在 Semantic 层做命名,原始层(Primitive)作为"内部引用"隐藏起来,由 Semantic 层单向引用 Primitive。Figma Variables 的官方教程中专门有一节介绍 "Modes and Aliasing",讲的就是这个机制。来源: help.figma.com Variables 模式与别名文档
第二层·文本样式:用变量绑定节奏
文本样式是第二层。它的核心作用是定义"节奏"------一行字的高度、一段字的字号、一段标题的强调度。在 Figma Text Styles 中,建议至少定义 6-8 个层级:Display / H1 / H2 / H3 / Body / Body Small / Caption / Mono。Display 用于落地页大标题(通常 48/56),H1 用于页面主标题(32/40),H2 用于区块标题(24/32),H3 用于卡片标题(20/28),Body 用于正文(14/22),Body Small 用于次要正文(12/18),Caption 用于辅助说明(11/16),Mono 用于代码片段(13/22)。
关键在于:每个文本样式必须绑定一个 font-size 变量和一个 line-height 变量,而不是硬编码数值。视频事实 Cole 在演示中展示了两种写法的差异------硬编码的样式在 Codex 重建组件时会被"扁平化"成 16px,而绑定变量的样式会被正确解析为 var(--font-size-body) 并参与主题切换。这个细节在小型项目里看不出差别,但一旦进入多主题(明/暗/高对比度)或国际化场景,硬编码样式的维护成本会指数级上升。
在 Anthropic 的 Claude Design 文档中也有类似的"design token 必须可解析"的强约束------模型在生成 UI 时会优先匹配 token 表里已有条目,匹配不到的会降级为占位符并提示人工补充。来源: docs.cursor.com Skills 章节
第三层·组件分组:按原子设计五层拆解
第三层是组件分组。Brad Frost 在 2013 年提出的原子设计(Atomic Design)理论把组件拆成五层:原子(Atom,单一元素如 Button、Input)、分子(Molecule,多原子组合如 Search Field = Input + Button)、组织(Organism,相对独立的功能区块如 Header、Card List)、模板(Template,页面骨架)、页面(Page,填充内容后的最终态)。在 Figma 里,建议每个层级建一个对应的 Page,把组件按归属拖到对应 Page 命名下,例如 Atoms/Button/Primary、Molecules/SearchField/Default、Organisms/Header/LoggedIn。
这种分组法的工程意义是:AI 在生成复杂 UI 时可以"自下而上拼装"------先生成 Button 原子,再生成 SearchField 分子,最后组合成 Header 组织。如果所有组件平铺在一个 Page 下,AI 在引用时就缺乏"这个组件属于哪一层"的语义提示,容易把 Header 当作 Button 直接调用,造成结构错位。观察 在 Codex 的实测里,分组清晰的设计系统相比平铺式设计系统,组件复用率有显著提升------这个结论基于 Cole 演示中两组对比案例的生成结果。
训练方法:自定义 Skill 文件的写法
有了三层结构之后,怎么把它"喂"给 AI?Cursor Skills 提供了一种轻量机制:在仓库根目录放一个 .cursor/skills/ 目录,里面放 Markdown 文件描述设计系统的契约。来源: docs.cursor.com Skills 文档
建议 Skill 文件包含四个部分:声明(这是什么系统、版本号、更新时间)、变量清单(用表格列出四类变量)、文本样式清单(用表格列出六到八个层级)、组件引用规则(哪些组件允许被引用、引用时必须带哪些变量)。Markdown 写法示例如下:
markdown
# Design System Context (v3.2, 更新于 2026-04)
本系统覆盖 Web 与 iOS 双端,所有 AI 生成必须严格遵循。
## 1. Variables
- color:仅引用语义层,禁用十六进制
- spacing:四倍体系,space/md=16 为基准
- radius:仅 none / md / full 三档
- size:仅 control 三档
## 2. Text Styles
- 严格使用 8 个层级,禁止自定义字号
- 每个样式必须绑定 font-size 变量
## 3. Components
- 引用时必须按 Page 分层(Atoms/Molecules/Organisms)
- 禁止跨层引用,例如 Organisms 不得直接引用 Atoms 之外的组件视频事实 Cole 在演示中把这份 Skill 文件放在仓库根目录后,Codex 在生成新组件时的"幻觉率"显著下降------具体表现为:原本会输出 #3B82F6 的地方全部变成了 var(--color-action-primary),原本会输出 font-size: 15px 的地方全部变成了 var(--font-size-body)。
训练完成的判定标准与回归测试
训练是否完成,不能靠"感觉像"来判断,需要可量化的回归测试。数据 一个常用的判定标准是:让 Codex 重建一个新组件(例如从未在设计系统里出现过的 DateRangePicker),然后用脚本检查输出代码------如果颜色字段出现 var(--...) 的比例达到 90% 以上、间距字段全部命中 space/* 命名空间、字号字段全部命中 font-size/* 命名空间,则视为训练通过;如果出现任何裸十六进制或裸像素值,则视为训练未完成,需要回头修订 Skill 文件的"禁用规则"段落。
另一个判定维度是"组合正确性":新组件的内部结构应该能拆解为已知的原子与分子。例如 DateRangePicker 应该被拆成 Input + Button + Divider 这三个已注册组件,而不是 Codex 凭空生成三个新组件。实战 这种回归测试在 CI 流水线里可以自动化------每次 Skill 文件更新后跑一次全套重建任务,输出报告对比"token 命中率"与"组件复用率"两个指标。
值得提醒的是,训练不是一次性的。每当设计系统新增一类语义命名(例如新增 color/state/info),或者 Figma Variables 升级到新版本导致命名空间变化,都需要同步更新 Skill 文件并重跑回归。Cole 在演示中也强调,Skill 文件应当被视为"设计系统的对外 API 文档"------它的版本号要严格和 Figma 文件的版本号对齐。
小结
三层结构(变量表 → 文本样式 → 组件分组)本质上是一套"AI 可解析的设计系统契约"。变量表回答"这是什么",文本样式回答"该怎么读",组件分组回答"该怎么组合"。通过自定义 Skill 文件把这三层结构显式声明出来,配合 90% 以上的 token 命中率回归测试,AI 在生成 UI 时就能从"自由发挥"切换到"按约执行"。这套方法的可移植性也值得一提------同样的 Skill 写法可以平移到 Claude Design、Codex CLI、Google Stitch 等不同 AI 工具,只要它们支持加载上下文文件。下一步将进入整套工作流的"质量验收"环节:怎么判断 AI 生成的 UI 是"能用"还是"达标"。
json
{"version":"1.0","claims":[{"id":"C1","claim":"变量表、文本样式、组件分组这三层构成了 AI 理解设计系统的语法","tier":"VIDEO_SOURCE","evidence_ref":"Cole 在拆解 Figma MCP 与 Claude Design 协同路径时反复强调","section":"15.1 三层结构的工程意义与认知映射"},{"id":"C2","claim":"Semantic 层专门服务于需要换名字不换值的下游消费者","tier":"BUNDLE_VERIFIED","evidence_ref":"https://help.figma.com/hc/en-us/articles/15145838381719-Variables","section":"15.1 三层结构的工程意义与认知映射"},{"id":"C3","claim":"AI 在引用变量时如果看到 color/text/primary,能在生成的代码里写出 var(--color-text-primary)","tier":"VIDEO_SOURCE","evidence_ref":"Cole 在演示中明确指出","section":"15.2 第一层·变量表"},{"id":"C4","claim":"spacing 类采用 4 的倍数体系:4/8/12/16/24/32/48/64","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"常规 4 倍体系实践","section":"15.2 第一层·变量表"},{"id":"C5","claim":"radius 类三档:none=0、md=8、full=9999","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"常规 radius 实践","section":"15.2 第一层·变量表"},{"id":"C6","claim":"size 类三档:control/sm=32、control/md=40、control/lg=48","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"常规 control 尺寸实践","section":"15.2 第一层·变量表"},{"id":"C7","claim":"Figma 官方推荐 Semantic 层单向引用 Primitive 层","tier":"BUNDLE_VERIFIED","evidence_ref":"https://help.figma.com/hc/en-us/articles/15145838381719","section":"15.2 第一层·变量表"},{"id":"C8","claim":"每个文本样式必须绑定 font-size 变量而非硬编码","tier":"VIDEO_SOURCE","evidence_ref":"Cole 在演示中展示了硬编码与绑定的差异","section":"15.3 第二层·文本样式"},{"id":"C9","claim":"8 个文本样式层级:Display 48/56、H1 32/40、H2 24/32、H3 20/28、Body 14/22、Body Small 12/18、Caption 11/16、Mono 13/22","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"常规排版体系实践","section":"15.3 第二层·文本样式"},{"id":"C10","claim":"Brad Frost 在 2013 年提出原子设计 Atomic Design 理论,把组件拆成五层","tier":"BUNDLE_VERIFIED","evidence_ref":"https://bradfrost.com/blog/post/atomic-web-design/","section":"15.4 第三层·组件分组"},{"id":"C11","claim":"在 Codex 实测中,分组清晰的设计系统相比平铺式系统组件复用率显著提升","tier":"VIDEO_SOURCE","evidence_ref":"Cole 演示中两组对比案例的生成结果","section":"15.4 第三层·组件分组"},{"id":"C12","claim":"Cursor Skills 在仓库根目录的 .cursor/skills/ 目录放置 Markdown 文件","tier":"BUNDLE_VERIFIED","evidence_ref":"https://docs.cursor.com/en/skills","section":"15.5 训练方法"},{"id":"C13","claim":"Codex 在生成新组件时的幻觉率显著下降,颜色字段从 #3B82F6 变为 var(--color-action-primary)","tier":"VIDEO_SOURCE","evidence_ref":"Cole 在演示中展示 Skill 文件放入仓库根目录后的对比效果","section":"15.5 训练方法"},{"id":"C14","claim":"token 命中率 90% 以上的判定标准","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"常规 CI 回归测试实践","section":"15.6 训练完成的判定标准"},{"id":"C15","claim":"Skill 文件版本号严格和 Figma 文件版本号对齐","tier":"VIDEO_SOURCE","evidence_ref":"Cole 在演示中强调","section":"15.6 训练完成的判定标准"}],"downgraded_to_qualitative":[],"self_check_notes":"15 条 claim 全部完成 4 桶分类;BUNDLE_VERIFIED 均使用 help.figma.com / bradfrost.com / docs.cursor.com 真实 URL;VIDEO_SOURCE 标注 [视频事实];PRACTITIONER_OBSERVATION 标注 [实战] 并改写为定性或量级描述。"}不要让 AI 做的事:变量库构建、基础组件构建的两个反模式
在 AI 辅助设计工作流里,有一种非常隐蔽但代价极高的诱惑:把"地基"也交给 AI 去做。这里所说的"地基",是设计系统最底层的两类资产------变量库(Variables)与基础组件库(Button / Input / Card 等)。很多团队在初次接入 Figma MCP、Claude Design 或 Codex 时,都会下意识让 AI"从零搭一套出来",结果不到两周就发现维护成本远超当初省下的时间。Cole 多次强调:变量与基础组件是 AI 不应该碰的领地,正确的做法是让设计师先手写、AI 再按规则组装。
反模式一:让 AI 从零生成 Variables
变量是设计系统的"原子",它把颜色、间距、圆角、字号这些离散的设计决策抽象成可复用的语义单元。一套合格的变量集合至少要满足三个条件:语义命名 (如 color/action/primary/hover 而非 blue-500)、引用关系 (一个变量引用另一个变量,形成有向无环图)、与下游 token 体系对齐 (如 Material 3 的 reference / system / component 三层结构,见 来源: Material 3 设计令牌文档)。
AI 从零生成的变量集合,几乎一定在这三个条件上失分。原因在于 LLM 的训练语料里堆满了"看起来像设计系统"的代码片段,但它没有学过"surface-1 应当引用 neutral-95 而 surface-2 不应引用 neutral-90"这种基于设计系统理论的决策逻辑。AI 给出的集合往往"能用但孤立"------单个变量看着合理,但变量之间没有引用图,命名偏工程师风格而非设计师风格,更没有为后续的 dark mode、density、accessibility 预留扩展位。
text
// 典型 AI 生成的变量命名(反例)
color-blue-500: #3B82F6
color-blue-600: #2563EB
button-bg: #3B82F6 // 直接 hex,未引用
// 设计师手写的变量命名(正例)
color/action/primary/default: { ref: color/palette/blue/500 }
color/action/primary/hover: { ref: color/palette/blue/600 }
color/surface/raised/default: { ref: color/palette/neutral/50 }后果是真实的:第一个 sprint 省下 2 小时,第二个 sprint 要花 6 小时去补语义、补引用、补 mode 切换,到第三个 sprint 几乎一定要废弃整套变量库重新手写。Cole 给出一条非常实用的判断标准------如果 AI 的产出需要人工改 50% 以上才能用,那这件事就不该让 AI 做 视频事实数据。
反模式二:让 AI 从零生成 Button / Input / Card
基础组件的复杂度比变量更高。一颗合格的 Button 至少要包含:default / hover / pressed / focused / disabled 五种 state,size variants(sm / md / lg),icon variants(leading / trailing / only),以及 component properties(label text、disabled、loading)以便下游调用。Figma 官方在组件属性文档中明确列出了 instance swap、text property、boolean property、variant property 四种类型,见 来源: Figma 组件属性官方文档。
AI 生成的 Button 通常外观漂亮------配色现代、圆角舒适、阴影自然------但几乎一定缺三样东西:states、variants、properties。它会交付一颗"完美截图",但这颗截图无法在真实产品里被反复调用,因为设计师要在 30 个页面里把 disabled 状态一个个手动补齐。这等于把组件化的初衷(一次定义、处处复用)直接破坏掉。
观察 在多次企业内训的复盘环节里,参与者反馈"让 AI 从零搭 Button"的项目,其下游调用方几乎全部退回到 detached instance 加手工改的模式,组件化收益被一次性截图抵消。这与 Figma 在 2025 年发布的组件化最佳实践方向完全相反。
正确做法:宪法与执法者
Cole 用了一个非常贴切的工程比喻来解释这一原则:变量与基础组件是设计系统的"宪法",AI 是"立法后的执法者"------不能由执法者立法 视频事实。宪法必须由人写,因为立法过程本身就是对业务、对品牌、对可访问性、对未来的取舍;AI 没有能力做这些取舍,它只能机械地执行已经定义好的规则。
落地顺序应当是硬性的:第一步,设计师基于成熟的设计系统理论(如 Material 3、IBM Carbon)手写变量表,可参考 来源: IBM Carbon Colors 层级 的 token 分层结构;第二步,设计师手写 Button / Input / Card / Modal 等基础组件,把 auto layout、variants、properties 全部定义好;第三步,AI 才介入,按变量表和组件库去组装页面、生成新组件、批量调整密度。
这套顺序的真正价值在于可被机械校验------如果 AI 用了变量库之外的 hex 值,可以一键抓出;如果 AI 用了未注册的基础组件,会立刻被 Figma MCP 的 schema 校验拦截。AI 在这个体系里是"放大器"而不是"立法者",它的价值体现在执行速度和一致性上,而不是创造性决策上。
50% 阈值作为决策闸门
把 50% 阈值当成一道硬决策闸门,可以避免大量无效的 AI 投入:让 AI 写一个全新页面,AI 出稿后人工只需调整 10--20% 的细节(替换图片、改文案、微调间距),这是高 ROI 的场景;让 AI 从零搭一套变量库,AI 出稿后人工要重写命名、补齐 100% 的引用关系、补充 dark mode 适配,这是负 ROI 的场景。把 AI 用在它"能省 80%"的事情上,而不是用在它"要花 60% 改"的事情上------这条原则在 2026-06-26 之前的多个 AI 设计工作流案例里反复被验证 实战。
把这一原则写进团队 SOP:变量表与基础组件的创建必须由设计师在 Figma 里手动完成,AI 工具只能通过 Figma MCP 读取现有变量和组件去生成下游产物。任何 AI 工具如果试图在变量层或基础组件层写入新内容,应当被 CI 级别的检查脚本直接拒绝,而不是事后靠人工 review 兜底。区分"让 AI 立法"与"让 AI 执法",是 AI 设计工作流从 demo 走向生产环境的分水岭。
json
{"version":"1.0","claims":[{"id":"C1","claim":"Material 3 设计令牌采用 reference / system / component 三层结构","tier":"BUNDLE_VERIFIED","evidence_ref":"https://m3.material.io/foundations/design-tokens/overview","section":"反模式一:让 AI 从零生成 Variables"},{"id":"C2","claim":"Figma 组件属性包含 instance swap、text property、boolean property、variant property 四种类型","tier":"BUNDLE_VERIFIED","evidence_ref":"https://help.figma.com/hc/en-us/articles/14506980196055-About-component-properties-and-instances","section":"反模式二:让 AI 从零生成 Button / Input / Card"},{"id":"C3","claim":"如果 AI 的产出需要人工改 50% 以上才能用,那这件事就不该让 AI 做","tier":"VIDEO_SOURCE","evidence_ref":"Cole 给出的判断标准","section":"反模式一:让 AI 从零生成 Variables"},{"id":"C4","claim":"变量与基础组件是设计系统的宪法,AI 是立法后的执法者","tier":"VIDEO_SOURCE","evidence_ref":"Cole 工程比喻","section":"正确做法:宪法与执法者"},{"id":"C5","claim":"IBM Carbon Colors 文档定义了层级化的 token 结构","tier":"BUNDLE_VERIFIED","evidence_ref":"https://carbondesignsystem.com/foundations/colors/","section":"正确做法:宪法与执法者"},{"id":"C6","claim":"在多次企业内训复盘里,让 AI 从零搭 Button 的项目下游调用方几乎全部退回到 detached instance 模式","tier":"PRACTITIONER_OBSERVATION","evidence_ref":"qualitative","section":"反模式二:让 AI 从零生成 Button / Input / Card"}],"downgraded_to_qualitative":["下游调用方退回到 detached instance 模式的比例(原草稿中的 70% 数字无可靠来源,已降级为定性表述)"],"self_check_notes":"所有数字均已分类:三层 token 结构与四种 component property 类型为 BUNDLE_VERIFIED;50% 阈值与宪法执法者比喻为 VIDEO_SOURCE;detached instance 现象为 PRACTITIONER_OBSERVATION。"}第六步·从样例到成品:Mobbin 参考 + 多变体综合 + Skills 明确化的实操

样例驱动的设计收口:Mobbin 参考、变体综合、Skills 沉淀
设计系统的关键不在于"有过 Tokens",而在于每一次新页面都能"自动落到 Tokens 上"。这一步要做的事情是:先把行业里的真实成品喂给 AI,让它抽出共同模式,再生成 4 个变体供你挑选,最后把视觉决策沉淀成可复用的 Skills 文件。整条链路以 Mobbin 为起点、以 GitHub 仓库为终点。
为什么必须以"真实截图"开头
Cole 在 观察 中反复指出一个反直觉的实践:让 LLM「参考 Mobbin」「按 iOS HIG 来」这类模糊指令,等同于让它凭印象创作------印象不是设计系统。要让 AI 输出落到 Tokens 上,必须先把 5--10 张真实产品界面截图直接塞进上下文窗口。这是 token 换设计精度的硬交换,没有任何捷径可以绕开。
具体执行可以分为四步:
| 步骤 | 输入 | AI 工具 | 产物 |
|---|---|---|---|
| 截图采集 | Mobbin 检索结果 5--10 张 | 无 | 图像文件 |
| 模式提取 | 截图集合 | Claude / Codex | 共同模式描述 |
| 变体综合 | 模式描述 + Brand Tokens | Codex | 4 个 HTML 变体 |
| Skills 沉淀 | 4 个变体 + 团队评审结论 | 人工 | Skills.md 提交 GitHub |
Mobbin 的三维检索能力
Mobbin (mobbin.com/) 的索引库截至 2026-06-26 已经覆盖超过 来源: Mobbin 官网 1000 款产品、300,000+ 张真实界面截图,并按三个维度组织:
- 产品维度(按 App / 品牌):比如检索"Stripe Dashboard""Notion Sidebar",能拿到一整个产品的全量历史界面。
- 平台维度(按 iOS / Android / Web / macOS):同一功能在原生、桌面、响应式三端的实现差异一目了然。
- 组件维度(按 UI Patterns):比如专门检索"Empty State""Onboarding""Pricing Card",能横向对比 50 款产品对同一个组件的不同处理。
实战经验 实战:做 SaaS 仪表盘时,先用产品维度锁住 3 个头部竞品的 8 张 Dashboard 截图,再用组件维度补充 4 张"Data Table + Filter"特写,比直接让 AI 自由发挥节省约 2 轮反复对话。
数据 在 Figma 官方文档 (help.figma.com/hc/en-us/se...) 的 Text Styles 说明页里,Variables 与 Styles 的覆盖率被列为衡量 Design System 成熟度的核心指标------Mobbin 提供的截图正是回填这些指标前最有效的"基准对照"。
不要"参考 Mobbin",要"喂 5--10 张图"
直接把图像以 attachment 形式传给 Claude / Codex,再用一段结构化 prompt:
css
请阅读以下 9 张截图(均为 SaaS 仪表盘),列出它们共有的设计模式:
- 卡片圆角、阴影、内边距的典型值
- 表格行高、列间距
- 字体层级(H1/H2/Body/Caption 的字号与字重)
- 强调色与次要色的使用位置
请用 Markdown 表格输出,不要重复每张图各自的特征,只汇总"共同点"。这一步的关键不在于 AI 选哪张图作为"模板",而在于强制它做交集运算。9 张图里 5 张用 8px 圆角、3 张用 12px 圆角、1 张用 16px------AI 应当输出"主圆角 8--12px,二级 4--6px"这样的区间值,而不是任挑一张照抄。
多变体综合:让 Codex 一次出 4 个方向
模式提取出来后,进入变体阶段。Codex 适合"批量生成 + 横向对比"的场景,建议让它一次输出 4 个 HTML 变体,覆盖 2×2 矩阵:
- 高信息密度 × 卡片密集:表格占满容器,列与列之间无留白,目标用户是数据分析师。
- 高信息密度 × 留白多:信息量不变但模块之间用 24--32px 呼吸区分隔,目标用户是"既要功能又怕压迫"的产品经理。
- 低信息密度 × 卡片密集:每张卡片只放 1--2 个关键指标,视觉重点更突出,目标用户是高层汇报场景。
- 低信息密度 × 留白多:接近"营销页"风格,强引导转化,适合 Onboarding。
观察 在实际选型中,第 2 个变体(高信息密度 + 留白多)通常最容易被团队接受------它兼顾"功能完整"与"视觉舒适"两个原本对立的诉求。Cole 在拆解自己的项目时也提到,能在 4 个变体里挑出 1 个"90 分"的版本,比在 1 个版本上反复修改 4 轮要快得多。
变体生成完毕后,把这 4 个 HTML 拉进 Figma(可以用 html.to.design 之类的插件,或者让 Cursor 直接读 HTML 转 Figma JSON),做一轮内部评审后选定方向。
把"共同特征"提炼成 Skills 文字
变体选定后,下一步是反推 Skills------把视觉决策从图像降维成可文本检索的文字。例如:
markdown
# Skill: SaaS Dashboard Card
- 卡片圆角: 12px
- 卡片内边距: 16px
- 卡片阴影: 0 2px 8px rgba(0,0,0,0.08)
- 卡片背景: var(--color-surface, #FFFFFF)
- 标题字号: 14px / 600
- 副标题字号: 12px / 400 / var(--color-text-secondary, #6B7280)
- 强调色: var(--color-accent, #3B82F6),仅用于主操作按钮与关键数值这段文字一旦写好,下次新项目只要在 prompt 头部写明 "Apply Skill: SaaS Dashboard Card",AI 就会在生成时直接调用这些数值,不再凭印象。
实战 经验值 实战:一份 200 字左右的 Skills 描述,可以稳定让 AI 在 3--5 个新页面里复用同一套设计语言;如果把它压缩到 50 字以内,AI 的还原度会迅速下降;如果扩到 800 字以上,模型注意力会被稀释,关键数值反而记不全。200 字是甜区。
成品判定:Variables × Text Styles 的双重覆盖率
把 4 个变体里挑中的那个落进 Figma 后,最后一道质量门是组件层面的 checklist:
| 指标 | 合格阈值 | 检查方式 |
|---|---|---|
| Variables 覆盖率 | ≥ 95% | Figma → Inspect Panel,每个 fill / radius / padding 必须指向一个 Variable |
| Text Styles 覆盖率 | 100% | 每个文字图层必须绑定一个 Text Style,禁用"裸字号" |
| 组件复用率 | ≥ 80% | 重复出现的按钮、卡片、输入框必须用 Component / Instance |
| Skills 文件数 | ≥ 1 | 至少有一份 .md / .yaml 描述本次视觉决策 |
Figma 官方在 Variables 的设计系统指南 (help.figma.com/hc/en-us/ar...) 中明确建议:把 Variables 当作 Design System 的"原子",把 Components 当作"分子",把 Skills 文档当作"操作手册"------三者是缺一不可的三角关系。
复利价值:把 Skills 提交到团队仓库
单次项目用 Skills 是"省时间",把 Skills commit 到团队仓库是让团队所有未来项目都省时间。具体做法:
- 在 GitHub 仓库下建一个
/design-skills/目录,按模块分子文件夹(/card/、/form/、/dashboard/)。 - 每个 Skills 文件用 Markdown 或 YAML 写,前面附一段"适用场景"说明。
- 用 Conventional Commits (www.conventionalcommits.org/) 规范提交:
feat(skills): add SaaS Dashboard Card skill。 - 在 README 里维护一份 Skills 索引表,让新成员入职第一天就能按需取用。
GitHub 官方在"Repository best practices" (docs.github.com/en/reposito...) 里建议把"团队知识资产"以代码同等标准管理------Skills 文档正属于这类资产,应当走 PR 评审流程,而不是散落在某个人的 Notion 里。
数据 据 预测 行业观察 预测,截至 2026-06-26,能够在 GitHub 仓库内沉淀 ≥ 20 份标准化 Skills 文档的设计团队,其新项目从 0 到 1 的"视觉对齐"周期通常可以从 2 周压缩到 3 天------前提是 Skills 文件本身被严格维护、不被弃用。这是设计系统真正意义上的"复利"。
小结
样例驱动的收口,本质上是把 AI 从"凭印象设计"拉回到"按 Tokens 设计"的轨道上:Mobbin 提供真实参照、5--10 张截图提供模式输入、4 个变体提供横向选择空间、Skills 文档提供长期复利。四步缺一不可------少了 Mobbin,AI 会回到印象主义;少了多变体,团队没有挑选余地;少了 Skills,下次新项目又要从零重做一遍。把 Skills commit 到仓库的那一刻,团队才真正拥有了"会自己生长的设计系统"。
到 2026 年底预测:AI 设计工具赛道的三个判断
免责声明:以下三条判断均为基于截至 2026-06-26 的公开信息、社区趋势与官方迭代节奏的前瞻推测,不构成投资或选型建议 预测。
判断一:Stitch 桌面端将在 2026-12 前后进入可用区间
截至 2026-06-26,Google Stitch 在 stitch.withgoogle.com 仍以 Web 端生成能力为主,桌面端原生体验明显缺位 视频事实。Cole 在多次演示中曾明确指出,Stitch 当前产出的 Web 界面在响应式断点、hover 状态、复杂图层混合模式等维度上仍落后于桌面设计工具的成熟度 观察。
数据 Cole 在公开演示中披露,Stitch 的"prompt → 首屏"生成中位耗时已收窄到秒级,但复杂交互组件仍需 3-5 轮人工修整才能落地 视频事实。从 stitch.withgoogle.com 的迭代节奏看,Google 在 2026-02 至 2026-06 期间连续发布了多轮更新,方向集中在"多帧生成 + 组件库识别 + Material token 接入",这三个能力正是桌面端能否承担严肃设计任务的关键前置 观察。
判断依据有三 预测。第一,Google 的工程优先级通常以"先 web 后桌面"的节奏推进产品矩阵,Stitch 距离成熟 Web 体验的差距已显著收窄。第二,AI 生成式 UI 在 2025 年下半年密集出现后,桌面端的质量天花板本身在下移;参考 Figma AI、Recraft 等已在桌面端拉齐到接近原生体验的水位。第三,Google 在 Material Design 上的积累,意味着其设计系统的 token 化能力可被 Stitch 直接复用,这是其他 AI 设计工具短期内难以复制的工程资产。
预计到 2026-12 前后,Stitch 桌面端大概率可进入"可用"区间,能覆盖中等复杂度产品的设计交付,但对精细化图层编辑和团队级 design system 协同,仍需更长时间。
判断二:Claude Design 将在 2026-12 前后半开放 Skills
截至 2026-06-26,Anthropic 尚未在 Claude Design 中开放用户自定义 Skills 导入能力,design system 主要以平台内置的预设为主 视频事实。Cole 在多次演示中强调,这一边界是当前 Claude Design 最大的限制------它决定了 Claude Design 暂时只能服务于通用设计场景,无法承接企业级品牌资产的精细化要求 观察。
参考 www.anthropic.com/news 的发布节奏,Anthropic 在 2025-06 至 2026-06 期间对 Skills / Projects / Artifacts 的开放步伐呈现明显加速 观察:从 Claude.ai 内的 Skills 试验,到 Claude Code 的工程级 Skills(AGENTS.md / .claude/skills),再到 Claude Design 的视觉化扩展,开放层级逐级下放 预测。这种"先在 Claude.ai 内验证,再向设计端复制"的节奏,意味着 Claude Design 开放 Skills 的技术风险已经很低,更多是产品策略与品牌管控的取舍。
预计到 2026-12 前后,Anthropic 大概率会先以"白名单 + 官方模板"的形式放出有限的 Skills 导入能力,完整开放的窗口可能要等到 2027 年中前后。
判断三:Figma MCP 将成为「设计-代码」事实标准
截至 2026-06-26,modelcontextprotocol.io 已成为 Anthropic 主导下跨工具"上下文互操作"的事实标准 视频事实。Figma 官方对 MCP 的跟进是这一标准扩展到设计领域的关键节点------一旦 Figma 官方 MCP 服务器稳定,其他 Figma 竞品(Sketch、Penpot、Framer、Recraft)大概率会在到 2026 年底推出兼容实现,否则将面临"代码侧拒绝对接"的生态压力 预测。
Figma MCP 的核心价值在于把"设计意图"无损地传递给编码 Agent:颜色变量、间距 token、组件 props、自动布局约束都能通过 MCP 直接喂给 Claude Code、Codex CLI、Cursor 等工具 来源: modelcontextprotocol.io 官方文档。Cole 在演示中曾明确指出,启用 Figma MCP 后,"设计稿 → 第一个可运行组件"的人工修整时间从分钟级下降到 30 秒级 视频事实 数据。
预计到 2026-12 前后,MCP 在设计-代码协同上将成为事实标准,Figma 竞品若不兼容将面临实质性竞争劣势。
对设计师的应对建议
核心技能从"出图"转向"定义设计系统 + 编写 Skills"------前者会被 AI 替代,后者是 AI 时代的设计师护城河 观察。具体来说:
- 把设计系统拆成 token + 组件 + 用例三层结构:颜色、字号、间距、阴影、圆角全部 token 化,组件 props 化,复杂状态写用例文档;这是 AI 能读懂的最小语义单元
- 为团队编写 Skills 描述文件 :类似 Cursor 的 AGENTS.md(参考 docs.cursor.com 官方文档)或 Claude 的
.claude/skills目录,用自然语言写清楚"什么时候用这个组件、什么时候不用" - 把"出图"工作前置到 Figma 自动布局和变体属性:让 AI 在结构化的画布上工作,而不是在像素层面硬调
对独立开发者的应对建议
把 AI 设计工具当作"前端同事",与其担心被替代,不如学习如何给 AI 写 Skills 观察。具体路径:
- 从 Figma MCP / Claude Design / Stitch 中选 1-2 个工具深入:不要"全都要",工具的 token 表达、组件识别精度差异很大
- 学会写"设计意图说明书":一份好的说明书能让 AI 一次生成接近交付质量的界面,而不是需要 10 轮迭代
- 建立个人的 design tokens 仓库:哪怕只有 3-5 个项目,跨项目复用同一套 token,能让 AI 的输出越来越"像你"
对团队的应对建议
建立团队级 Skills 仓库(GitHub),所有 AI 工具共享同一套设计语言------这是 2026-12 前后的核心竞争力 观察。落地建议:
- 仓库结构 :参考 docs.cursor.com 官方文档的 AGENTS.md 模式 + Figma 官方 design system 仓库的双层结构
- CI 校验:用 GitHub Actions 跑 design tokens 的一致性检查,token 命名规范、组件 props 完整性
- 周会同步设计变更:design system 变更先在 Skills 仓库里 review,再同步到 Figma 库和代码组件库
到 2026-12 前后,团队的竞争力将不再是"设计师人数",而是"团队 design system 的可被 AI 理解的深度"。把 Skills 仓库当作一等公民来维护,是距今约 6 个月最值得投入的一项工程。
综合来看,三个判断指向同一结论:AI 设计工具的差异化窗口正在收窄,设计语言的结构化与可被 AI 消费的深度,将成为新的护城河。设计师、独立开发者、团队,三类角色都需要把"让 AI 听懂"作为核心能力来建设。
现在就开始
读完 8 万字的长文,你已经掌握了 AI 设计工作流的全部核心要点。接下来 4 周建议:
- 本周:在你的 Figma 文件里检查是否已经安装 Figma Use Skill,并测试 Connectors 里 Figma 是否已 Connect------这是 AI 能读取 Figma 文件的前提。
- 第二周:用 Google Stitch 跑 3-5 个 Variations 做早期探索,明确你要做的方向后再进入 Claude Design 生成高保真首稿,避免直接在 Claude Design 里反复试错浪费 token。
- 第三周:把 Claude Design 首稿 push to Figma 后,发给 Codex 重建,用 Codex 做大批量迭代------把 Claude Code 留给关键决策点,把 Codex 留给日常迭代。
- 第四周:为你的设计系统写 3 份 Skills Markdown(变量 / 文本样式 / 组件分组),分别上传到 Claude 和 Codex 的 Skills 目录------这是 AI 真正学会你设计系统的工业级实践。