目录
[一、回顾 B+ 树索引](#一、回顾 B+ 树索引)
[1. B+ 树索引体系回顾](#1. B+ 树索引体系回顾)
[1. 聚簇索引](#1. 聚簇索引)
[2. 非聚簇索引](#2. 非聚簇索引)
[3. 查找流程与回表查询](#3. 查找流程与回表查询)
[三、MyISAM 与 InnoDB 索引实现](#三、MyISAM 与 InnoDB 索引实现)
[1. MyISAM 的 B+ 树实现](#1. MyISAM 的 B+ 树实现)
[2. InnoDB 的 B+ 树实现](#2. InnoDB 的 B+ 树实现)
[1. 查看索引](#1. 查看索引)
[2. 创建主键索引](#2. 创建主键索引)
[3. 创建唯一索引](#3. 创建唯一索引)
[4. 创建普通索引](#4. 创建普通索引)
[5. 创建全文索引](#5. 创建全文索引)
[6. 删除索引](#6. 删除索引)
[五、Explain 执行计划](#五、Explain 执行计划)
[1. Explain 的定义与基本使用](#1. Explain 的定义与基本使用)
[2. 控制字段解剖](#2. 控制字段解剖)
[3. 判定是否命中索引](#3. 判定是否命中索引)
[1. 联合索引的底层 B+ 树结构](#1. 联合索引的底层 B+ 树结构)
[2. 最左匹配原则](#2. 最左匹配原则)
[七、 覆盖索引](#七、 覆盖索引)
[1. 什么是覆盖索引](#1. 什么是覆盖索引)
[1. 哪些字段适合建立索引](#1. 哪些字段适合建立索引)
[2. 哪些字段不适合建立索引](#2. 哪些字段不适合建立索引)
一、回顾 B+ 树索引
在理解了 B+ 树的底层物理 page 结构与多级目录路由机制后,我们已经掌握了数据库高效检索的理论。然而,在实际的生产工程中,仅仅了解 B+ 树的抽象模型是不够的
不同的存储引擎(如 InnoDB 与 MyISAM)对 B+ 树的物理实现有着本质的差异;而在复杂的业务场景下,如何设计多列索引、如何避免索引失效、如何通过执行计划分析慢查询,才是决定系统性能的关键
1. B+ 树索引体系回顾
为了承上启下,我们首先归纳 B+ 树索引能够将检索效率提升数万倍的底层核心物理逻辑:
-
全局有序性:无论是叶子节点的数据行,还是非叶子节点的目录项,在页面内部通过逻辑链表、在页面之间通过双向链表,均严格维持主键键值的升序排列。这奠定了二分查找的基础
-
非叶子节点扇出度:索引页不存放业务行数据,只存放密集的目录项(主键 + 页号),使得单个 16KB 页面可映射上千个子页面
-
低矮拓扑结构:高扇出度直接将千万级数据的 B+ 树高度压制在 3 层左右。这意味着定位任意随机记录,其物理磁盘 I/O 次数被严格锁定在 2~3 次以内,实现了 O(log N) 的对数级时间复杂度
二、聚簇索引与非聚簇索引
在 MySQL 中,根据叶子节点存储内容的物理组织形式 ,索引被划分为聚簇索引(Clustered Index)与非聚簇索引(Secondary Index,亦称二级索引或辅助索引)
1. 聚簇索引
定义与特性
聚簇索引并不是一种单独的索引类型,而是一种数据存储方式 。它的核心特征是:B+ 树的叶子节点完整存放了整张表的实际行记录数据 。也就是说,索引结构与物理数据文件是交织在一起的
在 InnoDB 存储引擎中,聚簇索引的构建遵循以下原则:
-
如果表定义了主键,InnoDB 会自动选择该主键作为聚簇索引
-
如果未定义主键,InnoDB 会在表中检索第一个定义的 UNIQUE 且 NOT NULL 的列作为聚簇索引
-
如果以上条件均不满足,InnoDB 会在底层自动生成一个 6 字节的隐式自增列来构建聚簇索引
**架构原则:**正因为数据行只能按照一种顺序存储在磁盘上,所以一张 MySQL 表有且只能有一个聚簇索引
2. 非聚簇索引
定义与特性
当我们在业务中对非主键列建立索引时,生成的全都是二级索引。其物理特征与聚簇索引截然不同:二级索引的叶子节点并不包含实际的数据行,而是仅包含当前索引列的键值以及对应的聚簇索引键值(即主键值值)
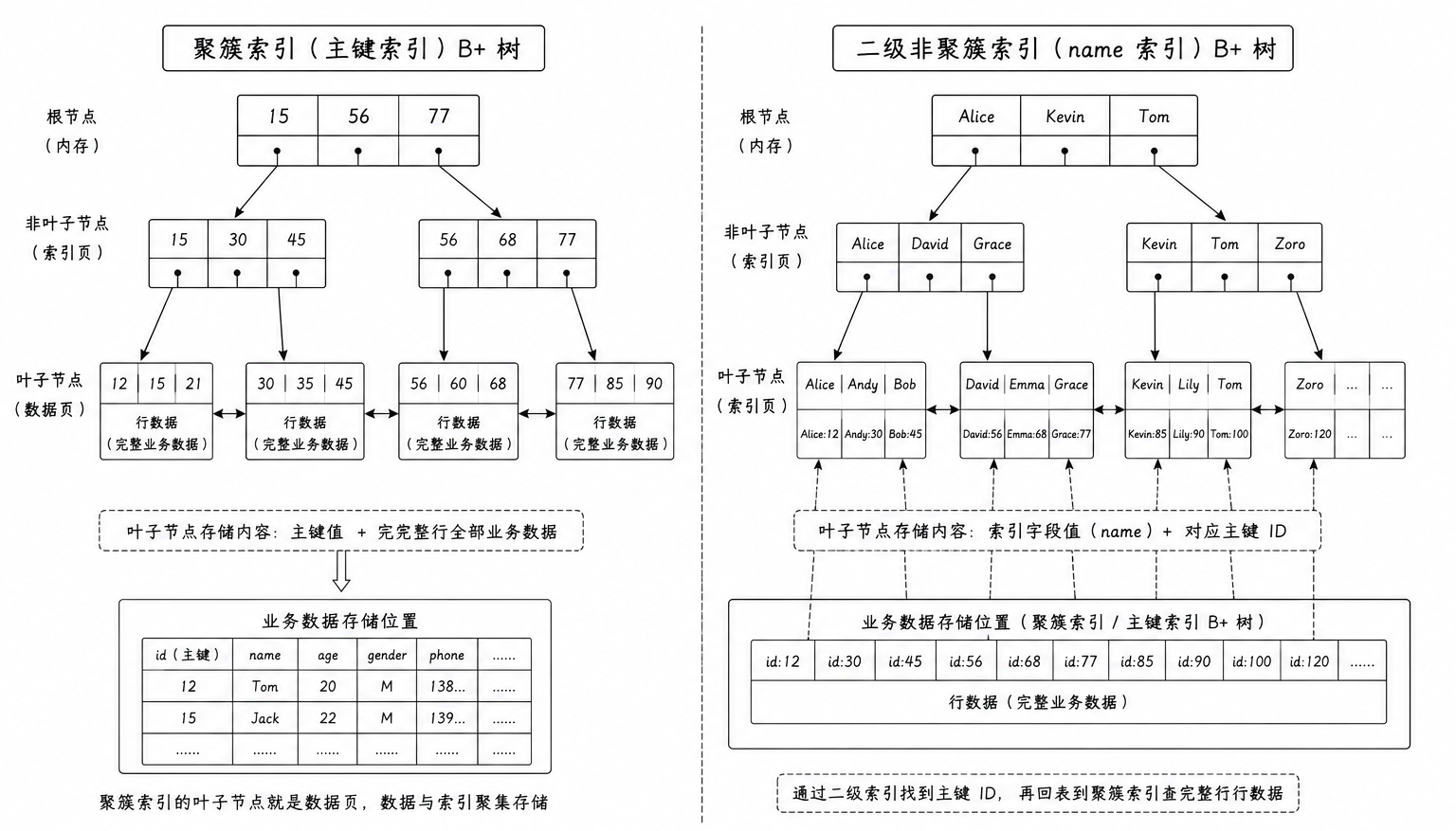
3. 查找流程与回表查询
基于上述物理拓扑,我们拆解两条不同查询语句的底层执行路径:
路径 A:基于主键的查询
sql
SELECT * FROM user WHERE id = 2;执行逻辑:引擎直接检索主键聚簇索引的 B+ 树,当下探到叶子节点时,直接在该物理页内获取到整行数据。整个过程只需遍历一棵树
路径 B:基于二级索引的查询
sql
SELECT * FROM user WHERE name = '悟空';执行逻辑:
-
引擎首先扫描 name 列对应的二级索引 B+ 树,在其叶子节点中查找到 name = '悟空' 的记录,并提取出其关联的主键值 id = 2
-
拿到主键 id = 2 后,引擎必须转而跳转到主键聚簇索引的 B+ 树,重新执行一次自上而下的下探检索
-
在聚簇索引的叶子节点中抓取到完整的物理行记录并返回
什么是回表查询(Lookup)
上述路径 B 中,先通过二级索引找到主键值,再用主键值去聚簇索引中检索完整行记录的过程,在数据库工程中被称为回表查询
回表查询意味着系统需要先后遍历两棵独立的 B+ 树,这会引发额外的页面加载与磁盘随机 I/O 开销,是导致二级索引查询性能劣化的主要诱因
三、MyISAM 与 InnoDB 索引实现
不同的存储引擎对上述索引模型的实现有着本质差别。我们重点对比 MySQL 最核心的两种引擎:InnoDB 与 MyISAM
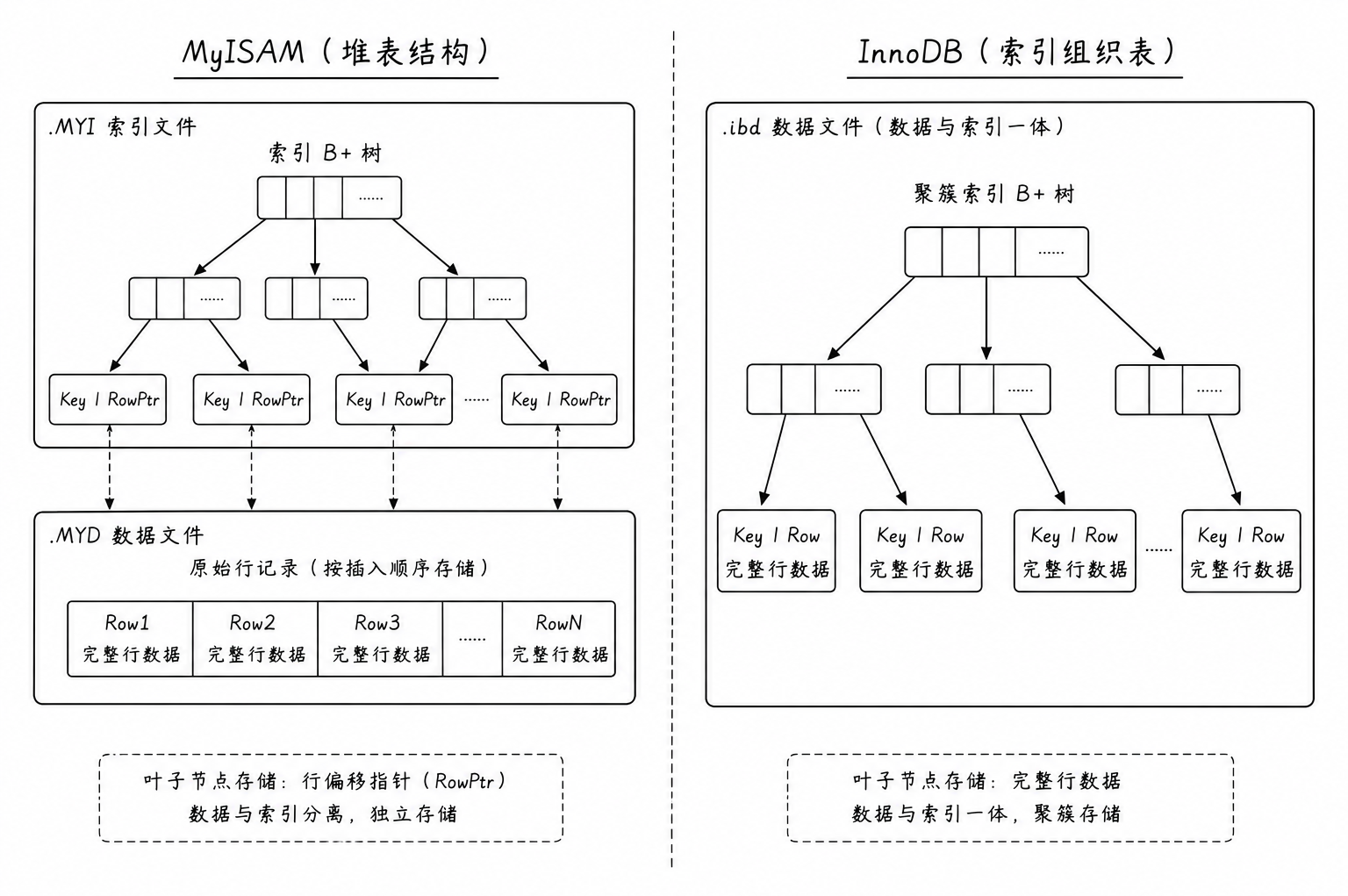
1. MyISAM 的 B+ 树实现
MyISAM 引擎采用的是非聚簇索引架构,其物理文件和索引文件是完全分离的:
-
.MYD 文件:专门存放数据行,数据按照插入顺序追加写入,行与行之间属于堆表关系
-
.MYI 文件:专门存放索引树结构
在 MyISAM 中,主键索引与二级索引在结构上没有任何本质区别 。它们的叶子节点内部存储的都不是完整的行数据,而是指向 .MYD 文件中该行记录的物理文件偏移量指针。 即使通过主键查询,MyISAM 也需要先在 .MYI 文件中找到指针,再到 .MYD 文件中读取数据,其物理本质全部属于非聚簇架构
2. InnoDB 的 B+ 树实现
InnoDB 引擎采用的是索引组织表架构,数据文件 .ibd 本身就是一棵巨大的聚簇索引树
为什么 InnoDB 坚持选择聚簇索引?
相比 MyISAM 的指针回表,InnoDB 选择聚簇索引具备压倒性的优势:
-
主键查询性能极致化:在企业级高并发读写中,基于主键的单表/多表关联查询占比极高。聚簇索引使主键查询免去了读取物理数据文件的二次指针寻址,数据局部性极强
-
辅助缓存效率:由于数据与主键紧凑排列在 16KB 页内,当该页被加载进 Buffer Pool 后,大量相邻行记录同时常驻内存。这使得范围查询能够触发高效的内存连续顺序访问,彻底规避了机械磁盘的随机寻道
两种存储引擎索引对比
| InnoDB 存储引擎 | MyISAM 存储引擎 | |
|---|---|---|
| 主架构类型 | 索引组织表 | 堆表(Heap Table) |
| 物理文件构成 | .ibd(结构、索引与数据一体化) | .frm(表结构)、.MYD(数据)、.MYI(索引) |
| 主键叶子节点内容 | 存储完整的物理业务行记录 | 存储物理文件的偏移量指针 |
| 二级索引叶子节点内容 | 存储索引键值 + 关联的主键值 | 存储索引键值 + 物理文件的偏移量指针 |
| 主键查询性能 | 极高(一步到位,无需二次物理寻址) | 较高(需解析索引,再根据指针跨文件读取) |
| 物理行移动(如页分裂)的影响 | 二级索引无需修改(因为绑定的是主键值) | 所有索引均需重写指针(因为物理偏移量改变) |
四、索引操作
在理解了物理存储差异后,我们需要在数据库定义语言(DDL)层面熟练掌握索引的操作方法。在实际开发中,正确的创建和删除规范能够最大程度减少对线上生产业务的冲击
1. 查看索引
在对数据表进行结构调整或查询优化前,必须首先探查其现有的索引拓扑结构
sql
SHOW INDEX FROM table_name;
输出解析
执行该命令后,结果集会输出以下关键控制字段:
-
Table:当前查询的数据表名称
-
Non_unique:若为 0,代表该索引是唯一索引或主键索引;若为 1,代表该索引是允许键值重复的普通二级索引
-
Key_name:索引的名称。主键索引固定显示为 PRIMARY
-
Column_name:当前索引项所绑定的数据列名称
-
Seq_in_index:该列在索引中的序列号。在单列索引中固定为 1;在多列联合索引中,按照定义的先后顺序从 1 开始递增
-
Cardinality :基数。估计该索引列中包含多少个不同(Unique)的值。该数值通常由存储引擎通过采样算法计算得出。基数越高,代表该列的数据区分度越好,MySQL 优化器也越倾向于选择该索引
2. 创建主键索引
主键索引在物理层直接决定了 InnoDB 聚簇索引的组织结构
方式一:在创建表时直接指定
sql
CREATE TABLE sys_user (
user_id BIGINT AUTO_INCREMENT,
username VARCHAR(50) NOT NULL,
PRIMARY KEY (user_id) -- 显式声明主键
) ENGINE=InnoDB;方式二:通过修改表结构追加
sql
ALTER TABLE sys_user ADD PRIMARY KEY (user_id);注意:对于已经存放有海量数据的表,执行 ALTER TABLE 会触发全表重组与数据页分裂,导致长时间锁表,应绝对避免在业务高峰期操作
3. 创建唯一索引
唯一索引(Unique Index)要求索引列的所有值必须唯一,但允许存在 NULL 值,且一个表中可以存在多个 NULL 值
语法格式
sql
-- 方式一:直接创建
CREATE UNIQUE INDEX idx_uniq_email ON sys_user (email);
-- 方式二:修改表结构追加
ALTER TABLE sys_user ADD UNIQUE INDEX idx_uniq_email (email);4. 创建普通索引
普通二级索引没有任何唯一性约束,其唯一使命是加速对指定列的条件检索
语法格式
sql
-- 方式一:直接创建
CREATE INDEX idx_username ON sys_user (username);
-- 方式二:修改表结构追加
ALTER TABLE sys_user ADD INDEX idx_username (username);5. 创建全文索引
全文索引主要用于解决形如 LIKE '%keyword%' 这种前后双百分号模糊查询导致的索引失效问题。它的底层不再是标准的 B+ 树,而是倒排索引结构
语法格式
sql
-- 修改表结构追加全文索引(假定对文章内容字段建立)
ALTER TABLE sys_article ADD FULLTEXT INDEX idx_full_content (content)
WITH PARSER ngram;注意:在涉及中文全文检索时,建议附加 WITH PARSER ngram 插件,以便 MySQL 能够正确地对中文字符串进行分词切片
6. 删除索引
当某个索引不再被业务查询命中(成为冗余索引),或者需要对其进行结构重建时,应予以删除以释放磁盘空间并降低数据变更时的索引维护开销
语法格式
sql
-- 方式一:标准的 DROP INDEX 语法
DROP INDEX idx_username ON sys_user;
-- 方式二:通过 ALTER TABLE 语法删除
ALTER TABLE sys_user DROP INDEX idx_username;
-- 方式三:专门用于删除主键索引(无需指定索引名)
ALTER TABLE sys_user DROP PRIMARY KEY;五、Explain 执行计划
在实际开发中,编写出 SQL 语句只是第一步。由于 MySQL 内部存在一个复杂的组件------优化器,它会根据各索引列的基数统计信息,自主计算并决定最终采用何种路径去检索数据
为了观察优化器的物理选择,避免盲目猜测性能,必须借助 MySQL 提供的官方诊断工具------EXPLAIN(执行计划)
1. Explain 的定义与基本使用
什么是 Explain
Explain 是用于分析查询语句执行效率的关键字。通过在 SELECT、DELETE、INSERT 或 UPDATE 语句的最前端附加 EXPLAIN,MySQL 不会真正运行该业务语句,而是会直接输出该语句在底层的执行方案拓扑图
基本语法
sql
EXPLAIN SELECT * FROM sys_user WHERE user_id = 1;
2. 控制字段解剖
执行 EXPLAIN 后,MySQL 会返回一张包含多个字段的结构矩阵。在索引优化领域,以下 4 个字段具有决定性的诊断价值
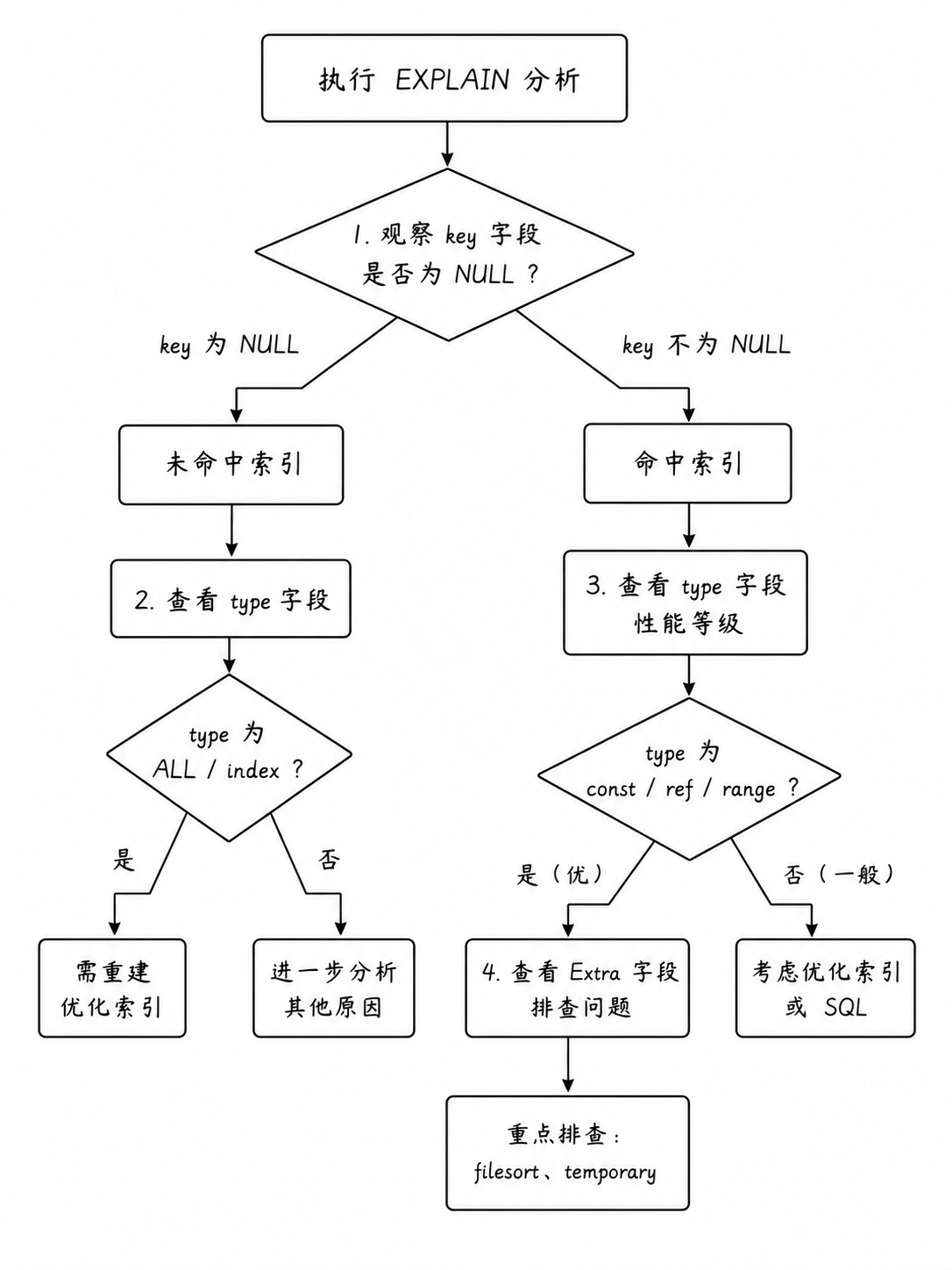
type 字段(访问类型)
type 字段直接反应了 MySQL 是以何种物理手段在表中查找数据的。它是判定查询性能好坏的最核心指标。其取值从优到劣的经典排序如下:
| type 值 | 物理含义与底层行为 | 性能评级 |
|---|---|---|
| system | 表中只有一行记录(系统表特例)。通常不需要触发磁盘 I/O | 极致 |
| const | 通过主键索引或唯一索引进行等值匹配。由于键值唯一,优化器直接将其转化为常量处理,查找仅需下探一次 B+ 树 | 优秀 |
| eq_ref | 在进行多表连接(JOIN)时,驱动表的关联字段正好是被驱动表的主键或唯一索引,对于驱动表的每一行,被驱动表只有一行匹配 | 优秀 |
| ref | 通过非唯一性的二级索引进行等值匹配。可能会匹配到多条满足条件的有序记录 | 良好 |
| range | 检索二级索引树的某个指定范围。常见于使用了 >, <, BETWEEN, IN, LIKE 的查询 | 合格 |
| index | 全索引扫描。MySQL 遍历了整棵二级索引树,虽然避免了读取数据文件,但依然属于 O (N) 遍历(此处 N 为索引树的节点总数) | 较差 |
| ALL | 全表扫描。不触发任何索引,直接从磁盘首字节开始遍历 .ibd 数据文件。时间复杂度为 O (N) | 灾难 |
注意:在生产环境中,线上业务的 SQL 查询其 type 字段至少应达到 range 级别,在高并发核心链路上则必须争取达到 ref 或 const 级别。如果出现 ALL 或 index,通常意味着系统存在重大性能隐患
key 字段与 possible_keys 字段
-
possible_keys:显示在此次查询中,有哪些索引可能被选用。它反映的是候选索引池
-
key :显示 MySQL 优化器在经过成本计算后,最终实际决定使用的索引名称。若该字段为 NULL,则代表本次查询没有命中任何索引
rows 字段
-
含义 :MySQL 根据统计信息预估出来的、为了找到目标数据所必须读取并检查的行数
-
调优:rows 的数值越小,意味着执行引擎需要扫描的物理 Page 越少,磁盘 I/O 损耗也就越低。该字段是衡量 SQL 优化前后效果最直观的量化尺
Extra 字段(附加状态信息)
Extra 字段包含了不适合在其他列中展示、但对判定性能至关重要的追加内部状态。以下三类是最常见的输出结果:
-
Using index :极优 。表明查询所需要的全部字段,直接在一棵二级索引树上就能够全部获取,完全不需要执行回表查询
-
Using where:表明 MySQL 在从存储引擎层获取到数据后,还需要在 Server 二次过滤
-
Using filesort :高危。表明 MySQL 无法利用索引自带的有序性完成 ORDER BY 的排序操作,必须在内存或磁盘中启用专用的排序缓冲区进行二次物理排序
-
Using temporary :高危。表明 MySQL 在处理 GROUP BY 或 DISTINCT 时,由于无法利用索引分组,不得不创建一张内部的临时表来辅助去重聚合,极其消耗内存与 CPU
3. 判定是否命中索引
在实际调优时,不能孤立地看某个字段,而是应当遵循以下逻辑来断定索引的健康状态:
六、联合索引与最左匹配原则
在实际业务开发中,复杂的查询往往需要依赖多个筛选条件(例如:WHERE age = 18 AND status = 1)。如果为每一个列单独建立单列索引,MySQL 优化器通常只能选择其中一个区分度最高的索引,而另一个条件则不得不依赖 Server 层的二次过滤,性能提升有限
为了应对多条件组合检索,数据库引入了联合索引 。联合索引并不是简单地将多个单列索引叠加,它在底层有着严密的复合排序逻辑,并直接推导出了关系型数据库中至关重要的最左匹配原则
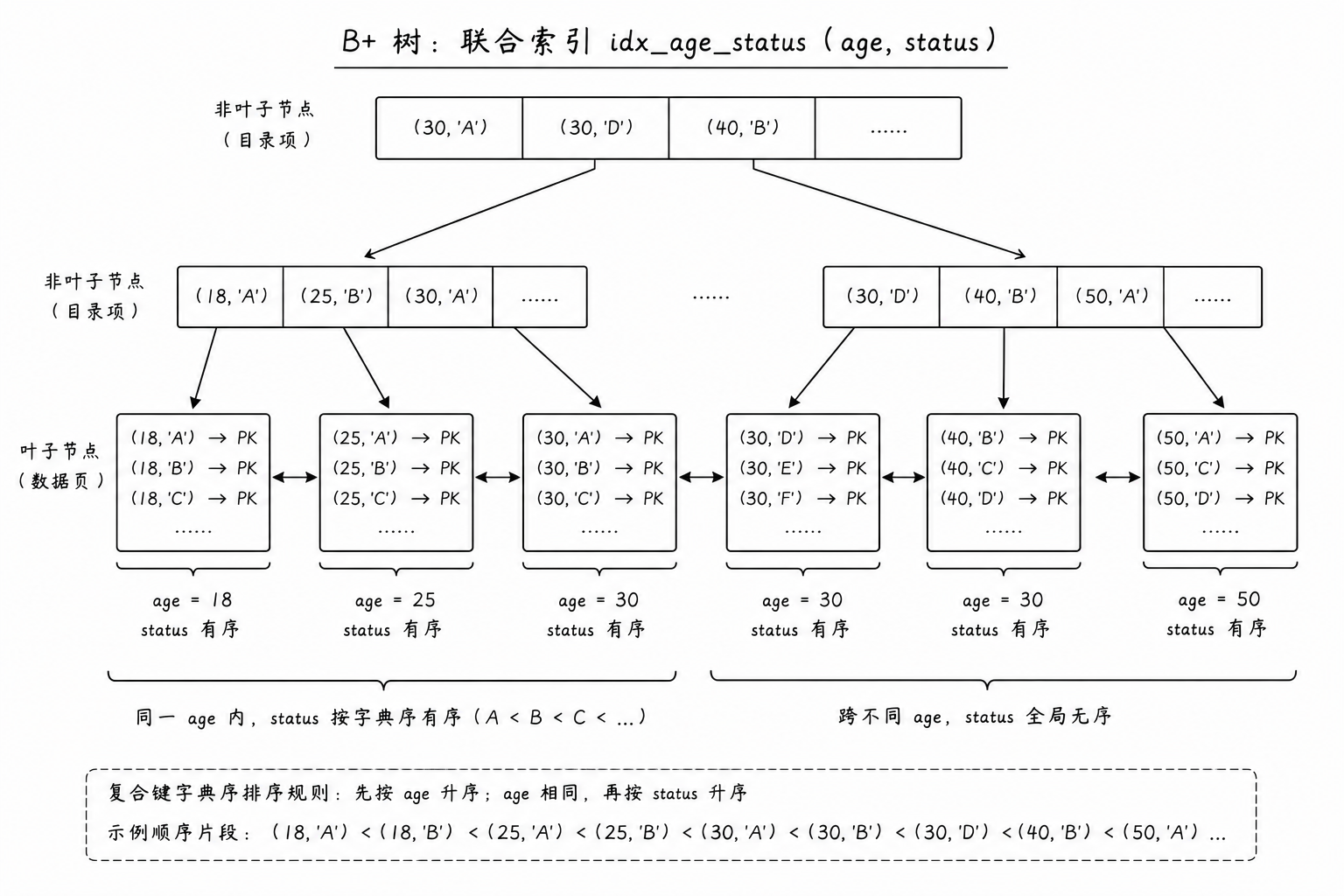
1. 联合索引的底层 B+ 树结构
联合索引在底层的物理本质依然是一棵 B+ 树,其核心差异在于非叶子节点的目录项和叶子节点的数据项,其键值是由多个列的值复合而成的元组
假设我们对一张表建立了一个联合索引:INDEX idx_age_status (age, status)。 底层 B+ 树在构建时,会遵循全局严格的字典序(Lexicographical Order)进行排列:
-
首列全局有序:所有记录首先严格按照 age 列的值从小到大进行全局排序
-
次列局部有序:只有当 age 列的值完全相同时,内部记录才会按照 status 列的值从小到大进行局部排序
-
次列全局无序:如果脱离了 age 列的依赖,孤立地观察整棵树中的 status 列,其数值表现为:1, 0, 2, 1, 0,在全局维度是彻底无序的
2. 最左匹配原则
基于联合索引 "首列全局有序,次列局部有序" 的物理特性,MySQL 优化器在解析 SQL 时会严格遵循最左匹配原则:查询条件必须从索引的最左列开始,并且不能跳过中间的列
案例分析(以联合索引 (a, b, c) 为例)
| 查询语句示例 | 索引命中 | 底层行为 |
|---|---|---|
| WHERE a = 1 AND b = 2 AND c = 3 | 全额命中 | 完美契合字典序。引擎利用 a 快速收敛范围,再利用 b 和 c 在局部有序空间内进行对数级下探 |
| WHERE b = 2 AND c = 3 | 完全失效 | 未命中索引。由于查询跳过了最左列 a,而在全局视角下 b 和 c 是杂乱无序的,B+ 树无法利用二分查找定位,被迫退化为全表扫描 |
| WHERE a = 1 AND c = 3 | 部分命中 | 仅 a 列命中索引。引擎可以通过 a = 1 快速定位到目标页面,但由于中间断开了 b 列,在 a = 1 的局部空间内 c 是无序的,因此 c 条件无法用于树形下探,只能由 Server 层进行逐行过滤 |
| WHERE a > 1 AND b = 2 | 部分命中 | 仅 a 列命中范围检索。一旦最左列 a 触发了范围查询(如 >, <, BETWEEN),其右侧的所有列(如 b)将彻底丧失索引定位能力。因为在 a> 1 的巨大跨度下,多个不同 a 值所夹杂的 b 值在全局上是无序的 |
七、 覆盖索引
我们已经清楚了 "回表查询" 的概念:当通过二级索引查找到主键值后,需要二次折返到聚簇索引中抓取整行数据。回表操作会引发大量的磁盘随机 I/O,是拖慢查询效率的核心瓶颈
为了斩断回表的链路,数据库设计者提出了覆盖索引(Covering Index)的设计思想
1. 什么是覆盖索引
覆盖索引并不是一种新的物理索引结构,而是一种利用现有二级索引树实现零回表的查询应用模式
如果一个查询语句中,SELECT 子句所需要获取的全部列,全部包含在当前所使用的二级索引树中 ,那么执行引擎在完成二级索引的下探后,就已经拿到了所需的全部业务数据。此时,系统会直接将结果集返回给客户端,不再触发任何回表操作
sql
[ 二级索引树 (username) ]
|
v 下探到叶子节点
[ 键值: "张三" | 主键ID: 99 ] ===> (由于只需获取 username 和 id) ===> 立即返回结果 (零回表)八、索引创建原则
索引虽然能够大幅度提升检索速度,但它在物理上是有代价的:
-
存储代价:索引本身需要占用磁盘空间(.ibd 文件会成倍膨胀)
-
计算代价:每当对表执行 INSERT、UPDATE、DELETE 时,InnoDB 为了维持 B+ 树的全局有序性,必须实时执行复杂的页分裂、页合并以及链表指针重组,这会直接拉低写性能
因此,索引的设计必须克制且精准,遵循以下工业级创建原则
1. 哪些字段适合建立索引
-
高频出现在 WHERE 条件、JOIN 关联字段、ORDER BY 或 GROUP BY 中的列
-
列的基数极高、数据区分度好的字段
-
区分度计算公式:区分度 = COUNT(DISTINCT column) / COUNT(*)
-
区分度越接近 1(例如手机号、身份证号、唯一准考证号),索引的过滤效率越高;如果区分度极低(例如性别列,无论数据量多大都只有 "男/女" 两个值),建立索引不仅无法提速,反而会加剧系统回表负担
-
-
长字符串列建议采用前缀索引
- 如果对一个 VARCHAR(255) 的长文本建立全额索引,会导致二级索引的目录项体积过大,降低 16KB 页面的扇出度,推高树高。建议仅提取前缀字符构建索引:ALTER TABLE table ADD INDEX idx_title (title(20))
2. 哪些字段不适合建立索引
-
数据频繁变更、读写比严重的字段(例如账户余额、验证码时效计数器)。高频的 B+ 树物理重组会导致严重的磁盘写入瓶颈
-
参与无序追加或高重复度的字段(如上述的性别、状态机标志位)
-
不要在非空字符比例极低的字段上盲目建索引
总结
综上所述,我们从索引的使用方式出发,深入学习了聚簇索引、非聚簇索引、联合索引以及覆盖索引等核心概念,并结合 EXPLAIN 执行计划分析了索引对查询效率的影响
通过本篇内容可以发现,索引本质上是一种以空间换时间的策略。合理地设计索引,不仅能够显著降低查询的数据访问量,还能够避免全表扫描,从而大幅提升数据库的查询性能。但与此同时,索引并非越多越好,不合理的索引设计同样会增加维护成本,影响数据的插入、更新与删除效率
至此,我们已经理解了 MySQL 为什么能够实现高效查询。不过,仅仅查询得快还不足以支撑一个真正的数据库系统。在多用户同时访问数据库的场景下,还需要保证数据操作的正确性、一致性以及可靠性
因此,在下一篇中,我们将正式进入 MySQL 事务专题,深入理解事务的本质、ACID 特性以及数据库如何保证并发环境下数据的一致性
