博主介绍:程序喵大人
- 35 - 资深C/C++/Rust/Android/iOS客户端开发
- 10年大厂工作经验
- 嵌入式/人工智能/自动驾驶/音视频/游戏开发入门级选手
- 《C++20高级编程》《C++23高级编程》等多本书籍著译者
- 更多原创精品文章,首发gzh,见文末
- 👇👇记得订阅专栏,以防走丢👇👇
😉C++基础系列专栏
😃C语言基础系列专栏
🤣C++大佬养成攻略专栏
🤓C++训练营
👉🏻个人网站
上一章讲了 relaxed:它只保证原子变量自身的原子性和单对象修改顺序,不建立任何跨线程同步。我们特意用了一个反例来演示------用 relaxed 标记的标志位去通知另一个线程"数据已经准备好了",结果消费者读到标志位翻转之后,去拿数据却拿到了旧值甚至未初始化的内容。
这个问题的根源很清楚:relaxed 不保证普通变量的可见性传递。生产者写完数据再翻标志位,但编译器和 CPU 有权把这两件事的顺序打乱,或者让标志位的写入先于数据的写入刷到其他核心可见的缓存里。消费者看到标志位变了,但数据还没到。
那怎么办?这就是 memory_order_release 和 memory_order_acquire 登场的时刻。
安全发布到底在发布什么
在多线程工程里,"安全发布"这个词出现的频率很高,但它到底指什么,很多人的理解停留在模糊的直觉层面。我们把它拆清楚。
所谓安全发布,指的是一个线程把一批数据准备好,然后通过某种机制让另一个线程能安全地读取这批数据。这里面有两个东西需要传递:
数据本身------可能是一个 std::string,一个 Config 对象,一组初始化好的索引结构,甚至只是几个普通的 int。这些数据通常不是原子变量,就是普通的内存写入。
"数据已经好了"这个信号------通常是一个原子变量充当标志位,比如一个 std::atomic<bool> ready。
安全发布要解决的问题是:消费者在收到信号之后去读数据,能保证读到的是生产者写好的完整内容,而不是半成品、旧值、或者未初始化的垃圾。
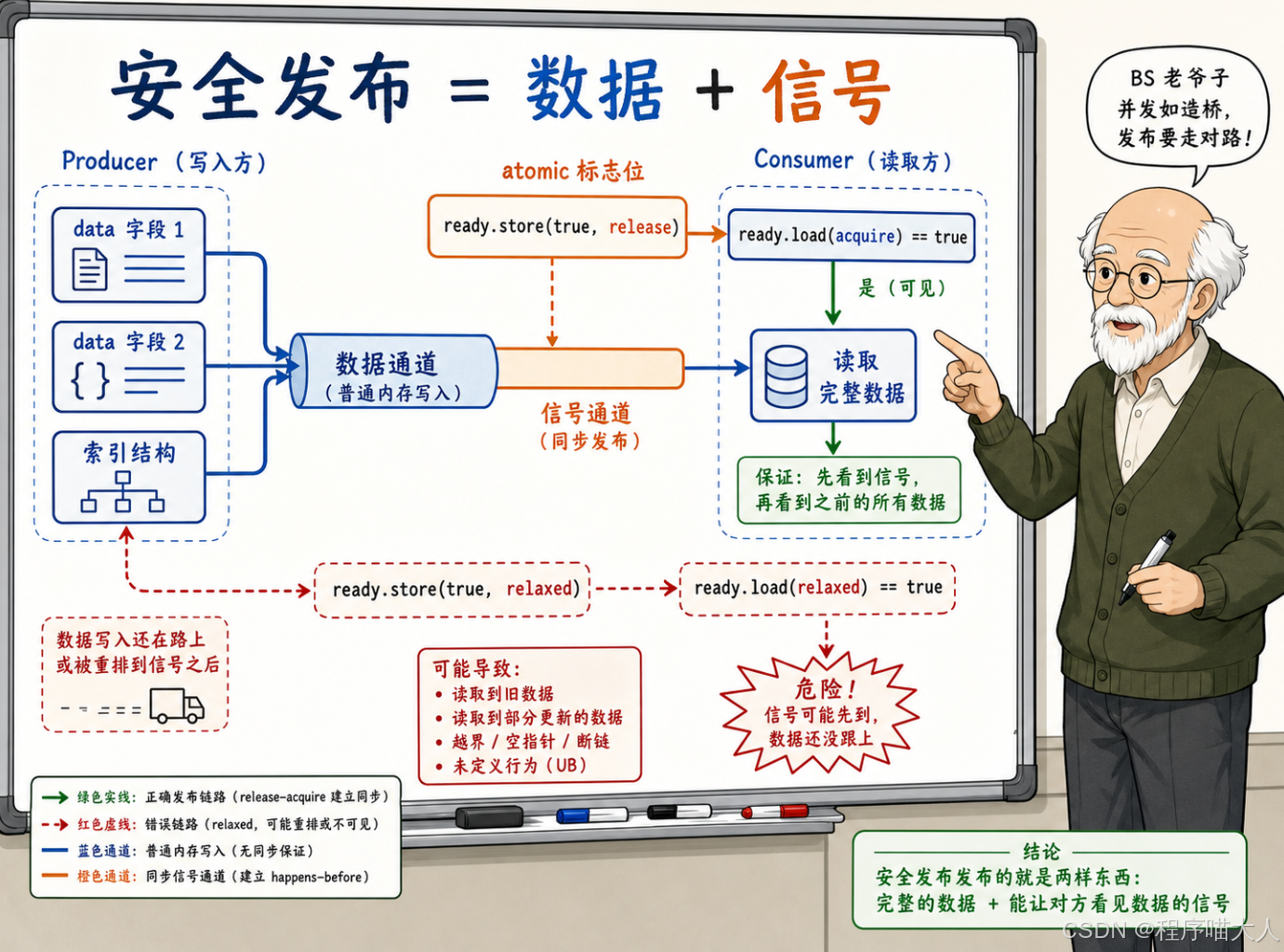
上一章已经证明了 relaxed 做不到这件事。seq_cst 能做到(因为它自带 release/acquire 语义),但 seq_cst 会给所有原子操作排一条全局顺序,开销偏重。如果你的场景只是"一个生产者写好数据,通知一个消费者来读",不需要全局顺序,那 release/acquire 就是最精确的工具。
release store:把前面的写入全部封印
先看生产者这边。
cpp
#include <atomic>
#include <string>
std::string data;
std::atomic<bool> ready{false};
void Producer() {
data = "new-config"; // (1) 普通写入
ready.store(true, std::memory_order_release); // (2) 发布动作
}memory_order_release 对 ready.store(true) 施加了一个约束:在这次 store 之前的所有内存写入------不管是原子变量还是普通变量------都不允许被重排到这次 store 之后。
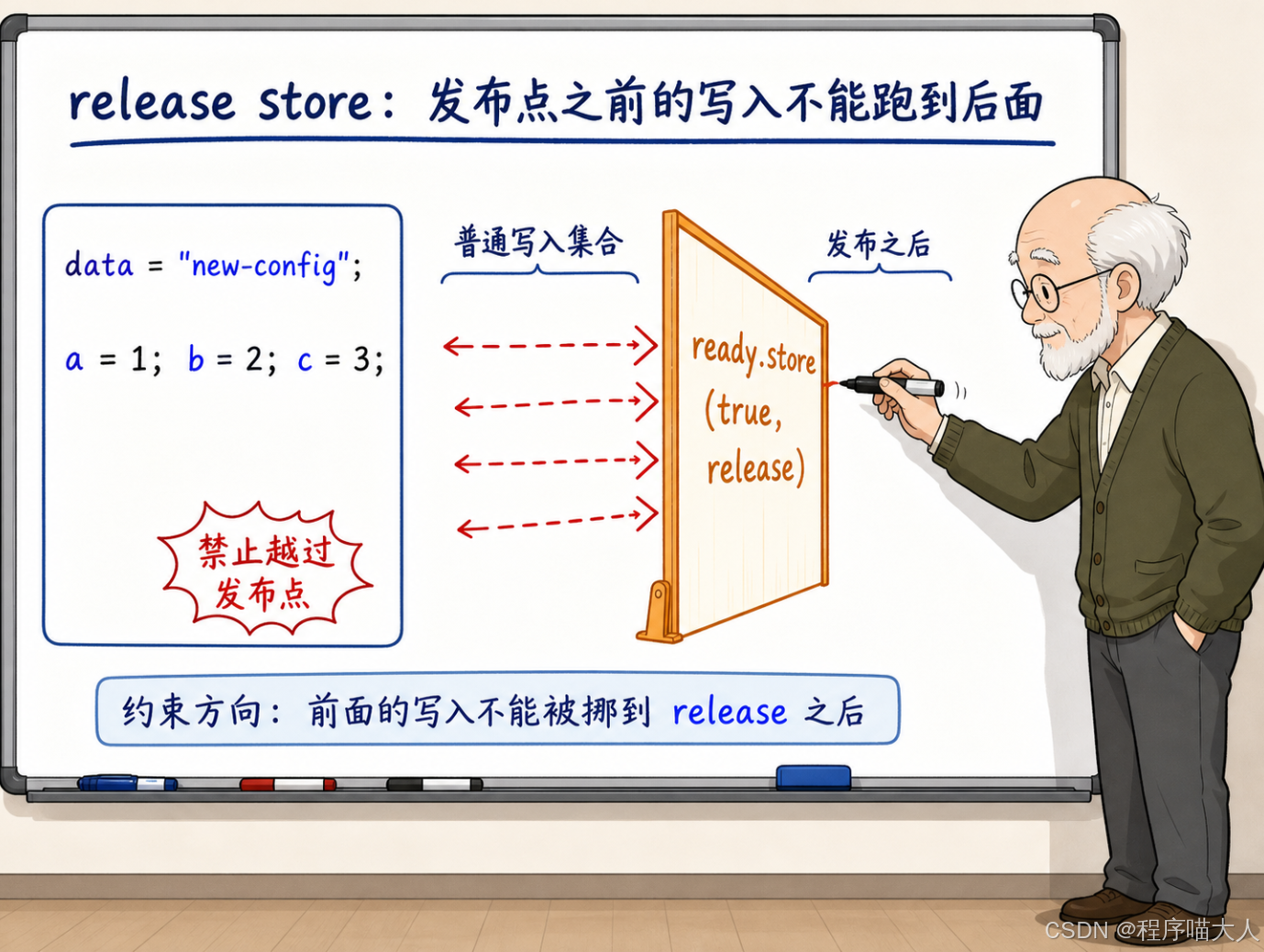
这个约束同时作用在两个层面。在编译器层面,编译器不会把 data = "new-config" 挪到 ready.store(true, release) 后面去。在硬件层面,CPU 在执行这次 store 的时候,会确保前面所有的写入已经从写缓冲区刷出去了(或者至少保证了在对外可见性上的顺序)。
可以把 release store 想成一道单向闸门:闸门前面的写入全部被"封印"在闸门这一侧,不允许越过闸门跑到后面去。闸门后面的操作则不受约束------release 不管"后面的写入能不能跑到前面来"。
在 x86 上,release store 通常不需要额外的指令,因为 x86 的 TSO 模型天然禁止 Store-Store 重排。但在 ARM 上,编译器会生成 stlr(Store-Release)指令,这条指令自带了必要的屏障语义。
acquire load:让后面的读取站在接收点之后
再看消费者这边。
cpp
void Consumer() {
while (!ready.load(std::memory_order_acquire)) { // (3) 接收动作
}
Use(data); // (4) 读取数据
}memory_order_acquire 对 ready.load() 施加了另一个方向的约束:在这次 load 之后的所有内存读取,都不允许被重排到这次 load 之前。
这同样是两个层面的事。编译器不会把 Use(data) 提到 ready.load(acquire) 前面去执行。CPU 也不会在 ready.load 完成之前就提前预读 data 的内容。
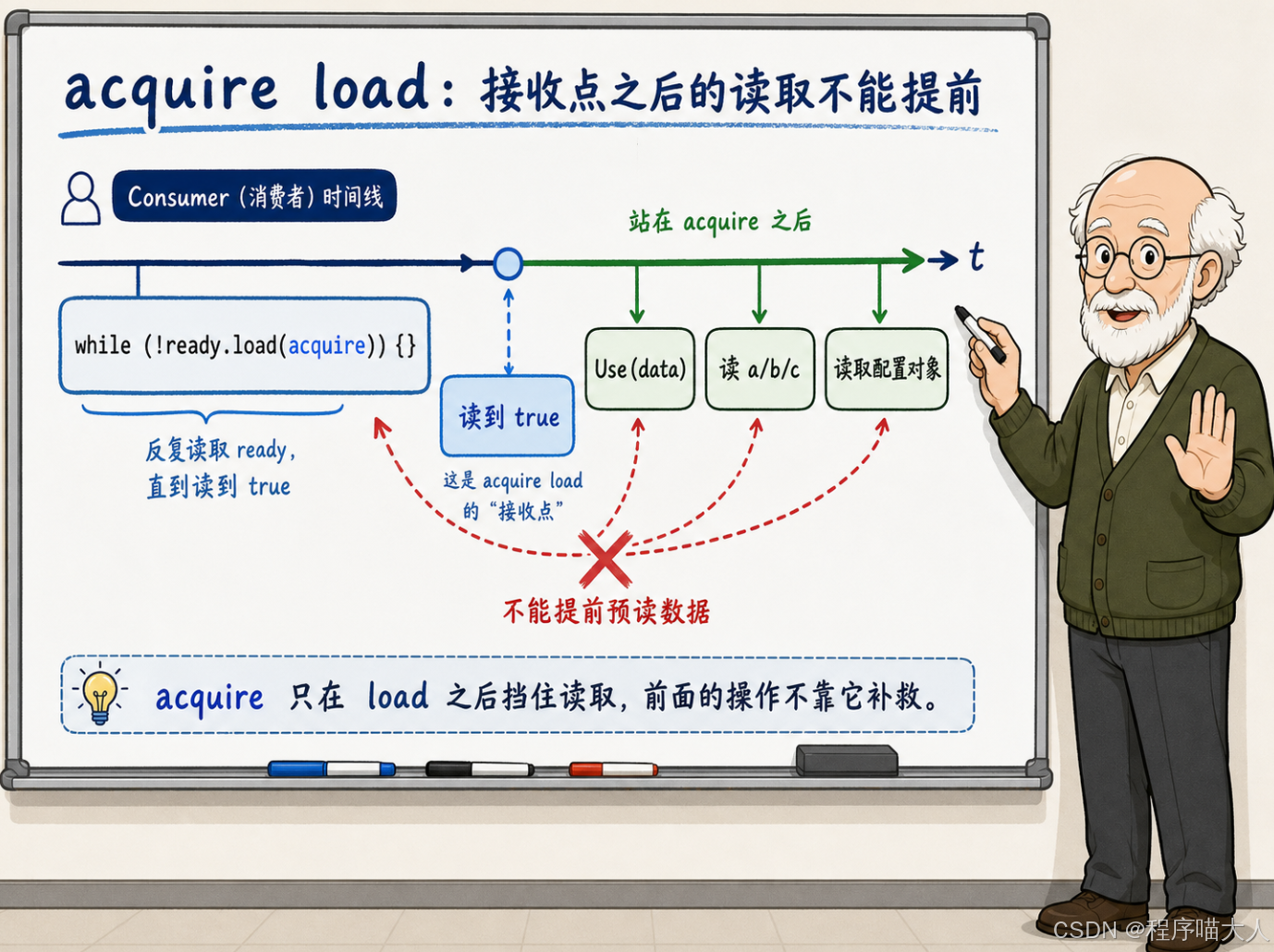
acquire load 也是一道单向闸门,但方向反过来:闸门后面的读取全部被"挡住",不允许越过闸门跑到前面去。闸门前面的操作则不受约束------acquire 不管"前面的读取能不能跑到后面来"。
在 x86 上,acquire load 也几乎免费------x86 天然禁止 Load-Load 重排和 Load-Store 重排。在 ARM 上,编译器会生成 ldar(Load-Acquire)指令。
两道闸门合在一起:synchronizes-with
光有一道闸门不够。release 封住了生产者前面的写入,acquire 挡住了消费者后面的读取,但这两道闸门分属不同线程,怎么接上?
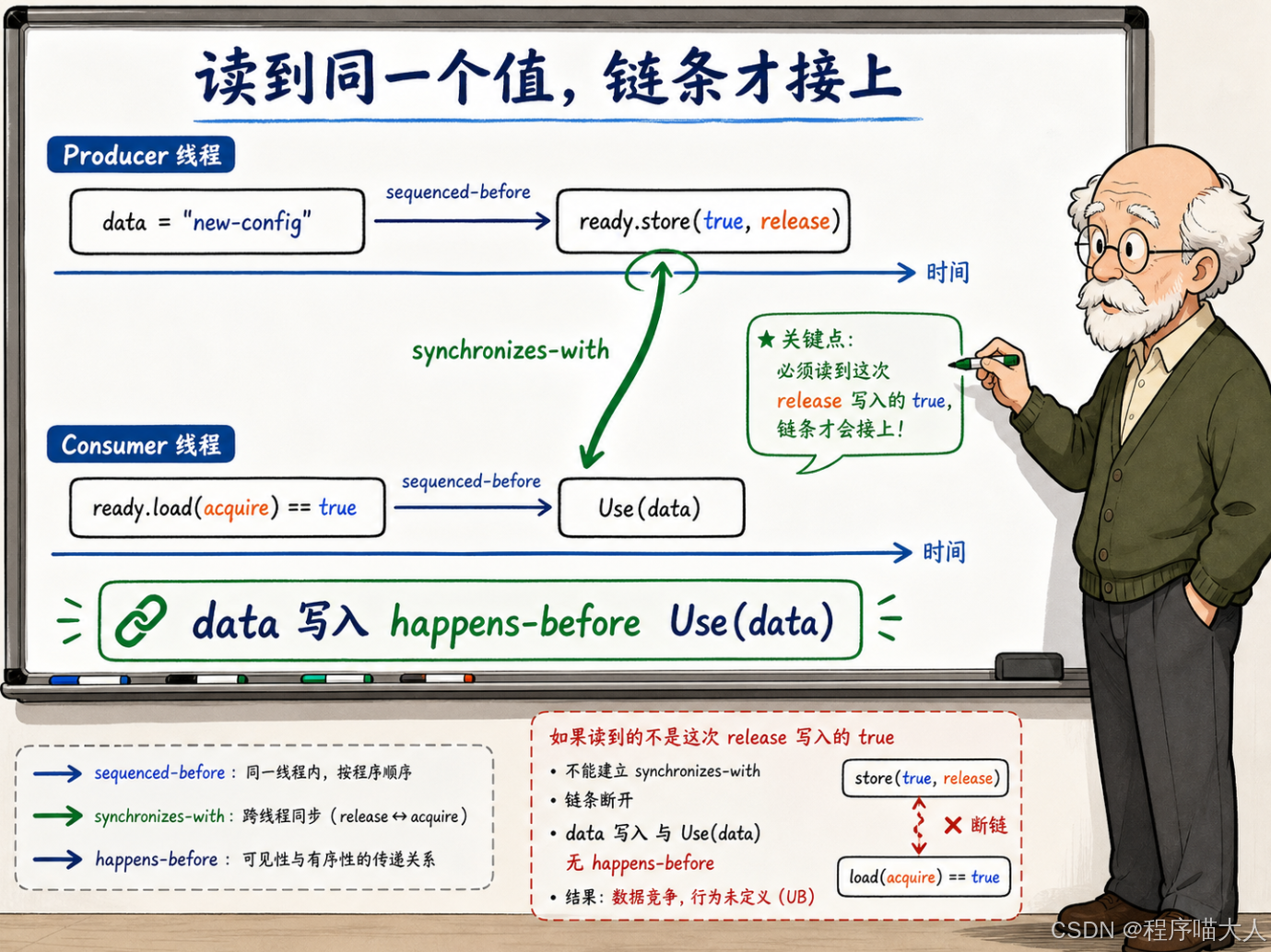
接上的条件只有一个:消费者的 acquire load 必须读到生产者的 release store 写入的那个值。
在我们的例子里,当 Consumer 的 ready.load(acquire) 返回 true------而这个 true 恰好是 Producer 的 ready.store(true, release) 写入的------两者之间就建立了一条 synchronizes-with(同步于)关系。
这条同步关系一旦建立,它的含义是:生产者在 release store 之前做的所有写入,对消费者在 acquire load 之后的所有读取都可见。
把完整的链路画出来:
text
Producer 线程:
data = "new-config" ──── sequenced-before ────▶
ready.store(true, release) ──── synchronizes-with ───▶
Consumer 线程:
ready.load(acquire) == true ──── sequenced-before ────▶
Use(data) // 此时 data 一定是 "new-config"四步串成一条 happens-before 链:data = "new-config" happens-before ready.store(true, release)(同线程内的 sequenced-before),ready.store(true, release) happens-before ready.load(acquire) == true(跨线程的 synchronizes-with),ready.load(acquire) == true happens-before Use(data)(同线程内的 sequenced-before)。链条上游的写入对链条下游的读取可见。
这就是 release/acquire 完成安全发布的全部机制。没有黑魔法,就是两道方向相反的单向闸门通过同一个原子变量的读写接在了一起。
顺带提一下 memory_order_acq_rel。有些场景下,一个线程需要对原子变量做读-改-写操作(比如 fetch_add、exchange、compare_exchange),而这个操作同时扮演了"接收上一轮数据"和"发布本轮数据"的双重角色。这时候,单独的 release 或 acquire 都不够,你需要两者兼备。memory_order_acq_rel 就是干这个的:它在读的一侧提供 acquire 语义,在写的一侧提供 release 语义。典型的例子是引用计数的递减操作:你需要 acquire 来看到之前所有线程释放的副作用,同时需要 release 来把自己的副作用发布出去。不过 acq_rel 的适用场景相对窄,大部分安全发布的需求用 release + acquire 的配对就能解决。
release/acquire 不只是保护一个变量
有人可能会有一个疑问:release store 封住的到底是 data 这一个变量,还是所有前面的写入?
答案是所有。release 不看你写的是什么变量,它只看执行顺序------在这次 release store 之前发生的所有写入,全部被封住。
cpp
int a = 0;
int b = 0;
int c = 0;
std::atomic<bool> ready{false};
void Producer() {
a = 1;
b = 2;
c = 3;
ready.store(true, std::memory_order_release);
}
void Consumer() {
while (!ready.load(std::memory_order_acquire)) {}
// 此时 a == 1, b == 2, c == 3 都有保证
Use(a, b, c);
}a、b、c 三个普通变量的写入全部在 ready.store(release) 之前,所以它们全部被封印在 release 这一侧。消费者通过 acquire load 接上同步关系之后,三个变量的值都能安全读到。
这个性质非常有用,在实际工程中,我们经常要发布的不是一个变量,而是一整批关联数据:配置文件解析完的多个字段、索引结构初始化好的多个数组、一个对象的所有成员变量。release/acquire 一次性把它们全部带过去,不需要每个变量单独做同步。
配对必须通过同一个原子变量
release/acquire 有一个容易被忽视的硬性条件:同步关系的建立,必须通过同一个原子变量上的 store 和 load。生产者在变量 A 上做 release store,消费者必须在同一个变量 A 上做 acquire load,并且读到了那次 release store 写入的值,同步关系才成立。
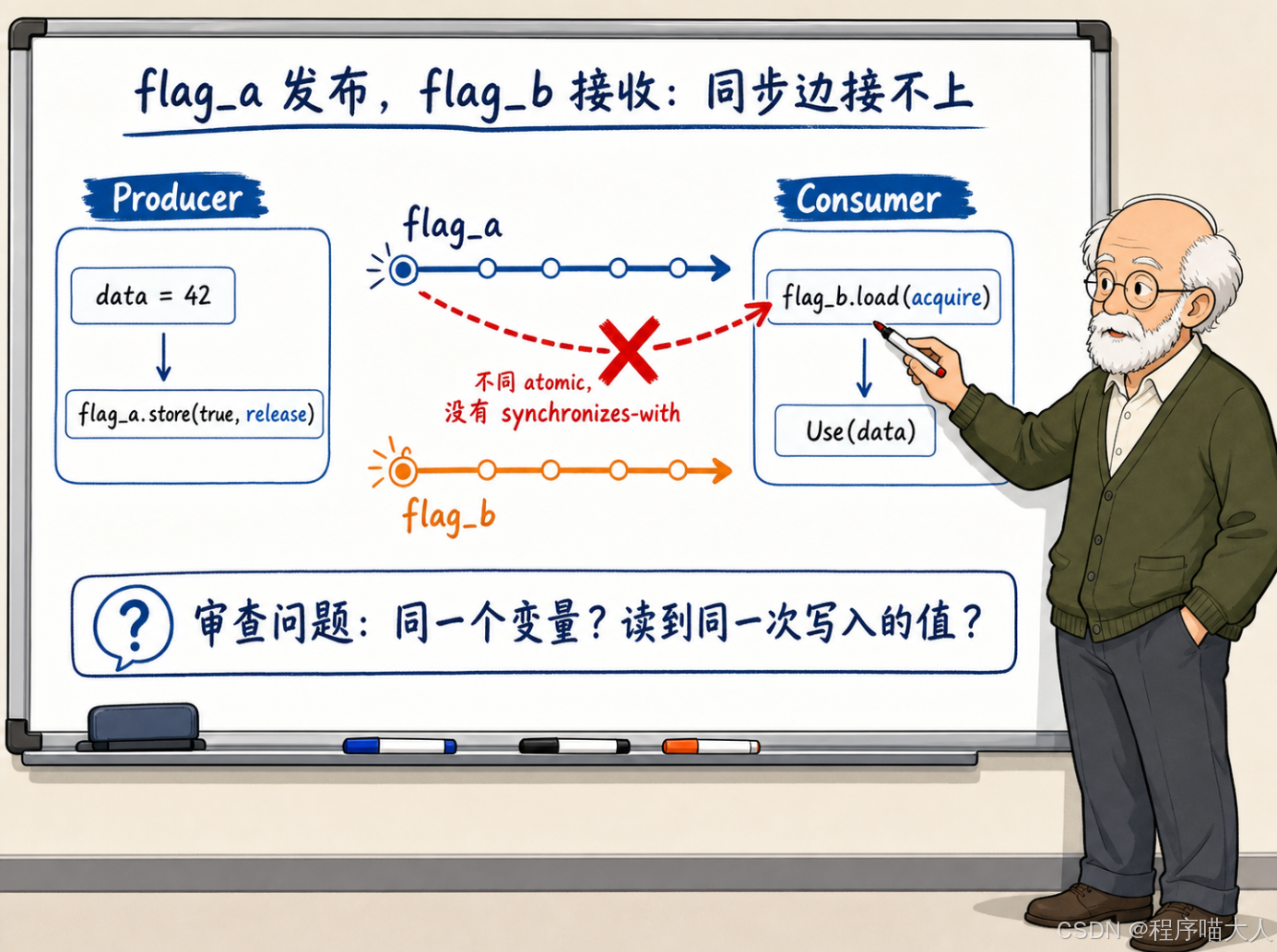
如果生产者和消费者用的是两个不同的原子变量,同步关系就建立不起来。
cpp
#include <atomic>
int data = 0;
std::atomic<bool> flag_a{false};
std::atomic<bool> flag_b{false};
void Producer() {
data = 42;
flag_a.store(true, std::memory_order_release); // 在 flag_a 上 release
}
void Consumer() {
while (!flag_b.load(std::memory_order_acquire)) {} // 在 flag_b 上 acquire
Use(data); // data 的值没有保证!
}Producer 在 flag_a 上做了 release,Consumer 在 flag_b 上做了 acquire。两者操作的不是同一个原子变量,之间不存在 synchronizes-with 关系。Consumer 读到 flag_b == true(假设有某个第三方线程设置了它),也不能推出 data = 42 已经对自己可见。
这个错误在真实代码里通常不会出现得这么明显。更常见的情况是隐蔽的:比如一个系统里有一个 version 原子变量和一个 ready 原子变量,生产者在 version 上做了 release store,消费者却在 ready 上做 acquire load。两个变量的名字不一样,review 的时候如果不仔细追同步对象,就可能漏过去。
在做代码审查的时候,看到 release/acquire 组合,第一件事就是追问:这两个操作落在同一个原子变量上吗?消费者 acquire load 读到的值,是生产者 release store 写入的那个值吗?这两个问题都确认了,同步关系才算接上。
不是所有 load 都能建立同步
还有一个微妙的点:消费者的 acquire load 必须读到生产者 release store 写入的那个特定值,同步关系才成立。如果消费者读到的是一个更早的值(比如初始值),那同步关系就没有建立。
回到我们的例子:
cpp
void Consumer() {
while (!ready.load(std::memory_order_acquire)) {
}
Use(data);
}Consumer 在 while 循环里反复读 ready。只要读到的是 false(初始值),就说明 Producer 的 release store 还没发生,或者发生了但 Consumer 还没看到。这些读取没有建立同步关系,Consumer 也不会去读 data。
只有当 ready.load(acquire) 返回 true------这个 true 是 Producer 的 ready.store(true, release) 写入的------同步关系才建立。这时候 Consumer 跳出循环,可以安全地读 data。
这就是为什么安全发布代码里通常会有一个 while 循环或者 if 判断:消费者要确认自己读到的是生产者那次 release store 的值,而不是某个无关的旧值。
release/acquire 与 seq_cst 的区别
release/acquire 和 seq_cst 都能完成安全发布,但它们的同步强度不同。
seq_cst 给所有 seq_cst 原子操作排了一条全局顺序,任何线程看到的这些操作的先后关系都是一致的。release/acquire 没有这条全局顺序------它只在配对的 store 和 load 之间建立局部的同步关系。
在单生产者-单消费者的发布场景下,两者的效果一样。你用 seq_cst 来 store 和 load,和用 release/acquire 来 store 和 load,消费者都能安全地读到数据。区别在于 seq_cst 额外保证了"所有 seq_cst 操作排在同一条全局队列里",而 release/acquire 不保证这一点。
什么时候这个区别会产生实际影响?当系统里有多个独立的原子变量、多个线程在互相观察彼此的操作顺序时。第 06 章那个经典的双变量例子------Thread1 写 x 读 y,Thread2 写 y 读 x------在 seq_cst 下 r1 == 0 && r2 == 0 不可能出现,但在 release/acquire 下这个结果是合法的(因为没有全局顺序的约束)。
所以工程上的判断标准是:如果你的场景只是单向的数据发布------生产者准备数据、打标记、消费者收标记、读数据------release/acquire 足够了,不需要 seq_cst 的全局顺序开销。如果你的正确性依赖于"所有线程对多个原子变量的操作顺序达成共识",那你需要 seq_cst。
审查 release/acquire 代码的实战思路
release/acquire 写起来不难,难的是审查别人写的 release/acquire 是否正确。很多并发 bug 都藏在"协议看起来对、但同步边没接上"的缝隙里。这里给几条实战中好用的审查路径。
第一步,找到所有的 release store,画出它们前面的写入集合。生产者在 release store 之前写了哪些普通变量、哪些其他原子变量?这些就是要被"发布"出去的数据。如果有遗漏------比如某个字段的初始化被不小心挪到了 release store 之后------那就是一个隐性的 bug。
第二步,找到对应的 acquire load,确认它读的是同一个原子变量,并且确实能读到 release store 写入的那个值。特别要注意的是:acquire load 读到的是不是初始值?如果消费者可能在生产者的 release store 之前就执行了 acquire load,它读到的是初始值,同步关系没有建立,后面的读取就是在裸奔。
第三步,追踪 acquire load 之后的读取路径。消费者读了哪些变量?这些变量是否全部在生产者的 release store 之前被写入?如果消费者在 acquire load 之后读了一个"不在发布集合内"的变量(比如另一个线程写入的、不在这条 happens-before 链上的数据),那这个读取同样没有保证。
这三步走下来,基本上能覆盖 release/acquire 最常见的错误模式。在 code review 的时候,把这三步当成检查清单来用,比靠直觉判断"这段代码看起来没问题"要靠谱得多。
和 mutex 的关系
讲到同步机制,必须说清楚 release/acquire 和 std::mutex 的关系,因为 mutex 才是多数工程师日常打交道最多的同步工具。
mutex 的 unlock 自带 release 语义,lock 自带 acquire 语义。一个线程在持锁期间写入的数据,对后续拿到同一把锁的线程一定可见。这和 release/acquire 的原理完全一样,只不过 mutex 把同步关系封装在了 lock/unlock 的接口背后,使用者不需要手动指定 memory_order。
cpp
#include <mutex>
#include <string>
std::mutex config_mutex;
std::string config;
void UpdateConfig(std::string new_config) {
std::lock_guard<std::mutex> lock(config_mutex);
config = std::move(new_config);
}
std::string ReadConfig() {
std::lock_guard<std::mutex> lock(config_mutex);
return config;
}这段代码里,UpdateConfig 在持锁期间修改了 config,lock_guard 析构时自动 unlock(release)。ReadConfig 调用 lock 获取锁(acquire),只要它拿到的锁是在 UpdateConfig 释放之后的,那 config 的新值一定可见。
那什么时候用 mutex,什么时候用 release/acquire?
release/acquire 适合的场景通常有这些特征:同步的方向是单向的(生产者到消费者),共享的数据在发布之后不再被修改(或者有明确的版本管理),代码路径比较短且清晰。典型的例子是初始化发布(一个线程初始化好一个对象,其他线程只读使用)、配置热加载(生产者原子地替换一个指针,消费者通过指针读取)、或者无锁数据结构内部的节点发布。
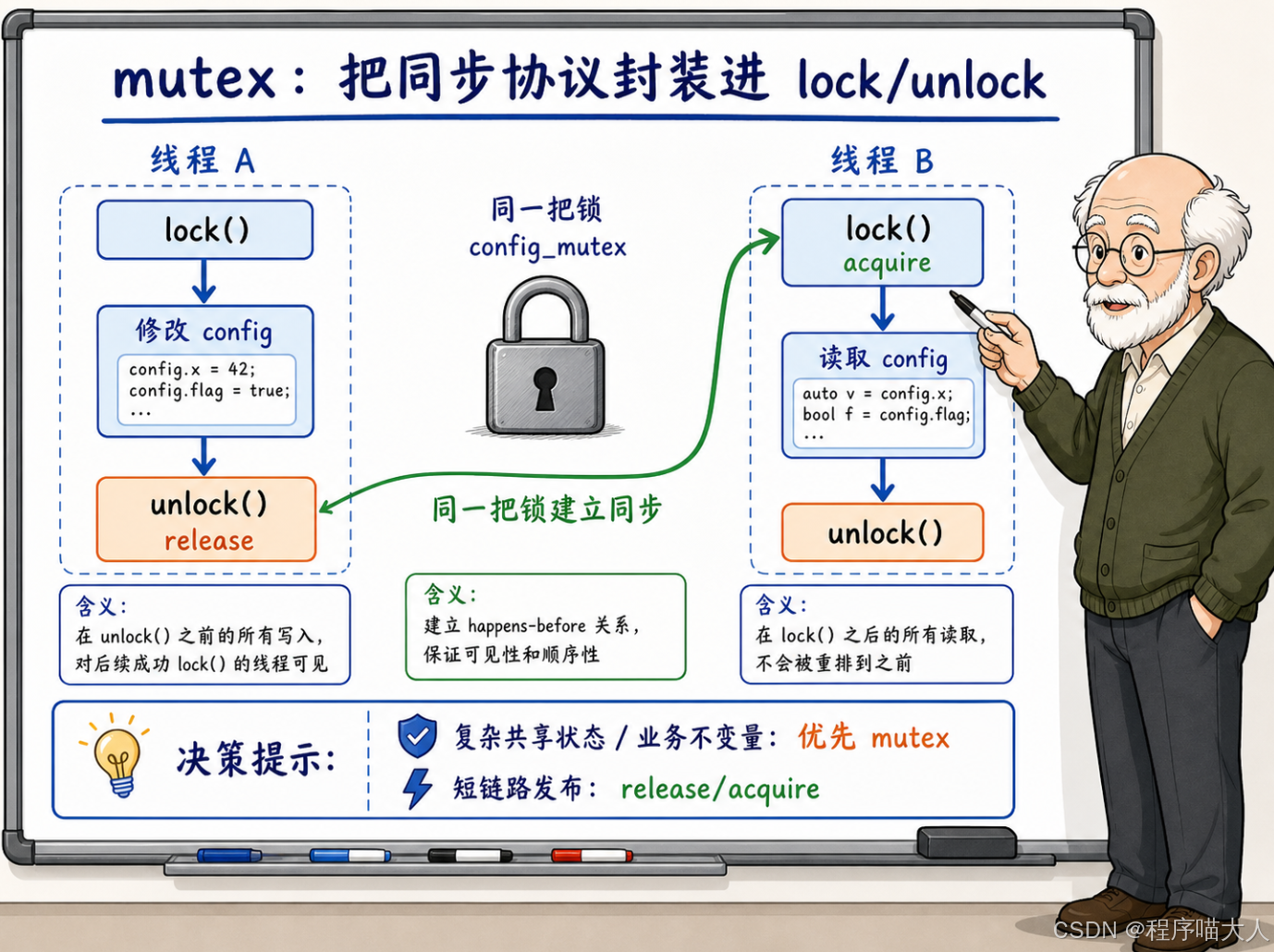
mutex 适合的场景更广泛:共享状态包含多个互相关联的字段(需要保护业务不变量),读写路径都可能修改数据(不是单向的),有异常处理路径(lock_guard 的 RAII 保证了异常安全),或者逻辑复杂到人脑很难追清楚所有的 happens-before 链条。
一条务实的工程原则:先用 mutex 写正确,再在有数据支撑的性能瓶颈面前考虑降级到 release/acquire。 不要一上来就追求"无锁",mutex 在多数场景下已经足够快了,而它提供的正确性保证比手工搭建 release/acquire 协议容易维护得多。
发布指针:生命周期也要一起处理
在实际工程中,release/acquire 最常见的用法之一是发布一个指针------生产者在堆上构造好一个对象,然后把指向它的指针原子地发布出去,消费者通过这个指针来访问对象。
这个模式带来了一个 release/acquire 本身管不了的问题:对象的生命周期。
如果用裸指针来发布,消费者拿到指针之后开始读对象,但生产者或者某个清理线程可能在消费者还在读的时候就把对象 delete 了。这就变成了悬空指针访问------属于 use-after-free,是比数据竞争更直接的灾难。
C++20 引入了 std::atomic<std::shared_ptr<T>>,把指针的原子发布和生命周期管理结合在了一起。
cpp
#include <atomic>
#include <memory>
#include <string>
struct Config {
std::string endpoint;
int timeout_ms = 0;
};
std::atomic<std::shared_ptr<const Config>> current_config;
void PublishConfig() {
auto config = std::make_shared<Config>();
config->endpoint = "10.0.0.1";
config->timeout_ms = 3000;
current_config.store(config, std::memory_order_release);
}
std::shared_ptr<const Config> LoadConfig() {
return current_config.load(std::memory_order_acquire);
}生产者先在堆上构造好完整的 Config 对象,所有字段都赋好值,然后用 release store 把 shared_ptr 发布出去。消费者用 acquire load 取得一个 shared_ptr 的拷贝。
这段代码里有几个值得注意的细节。
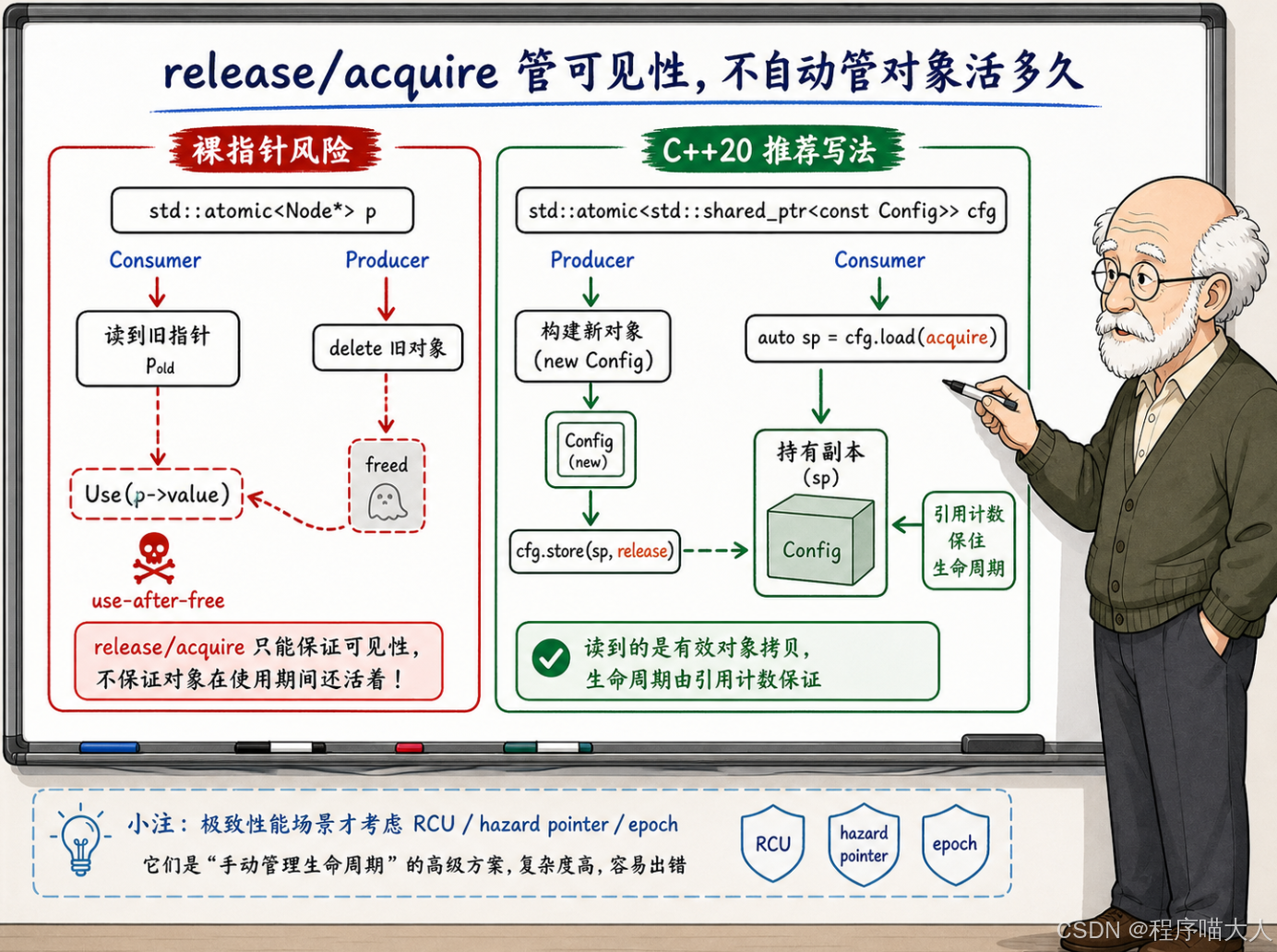
首先,Config 用的是 const 修饰------shared_ptr<const Config>。这是一个很好的工程实践:发布出去的配置对象是只读的,消费者不能修改它。如果需要更新配置,生产者重新 make_shared 一个新对象再发布,旧对象在所有消费者释放 shared_ptr 之后自动销毁。这种"读时复制"的模式天然适合 release/acquire。
其次,shared_ptr 的引用计数管理了对象的生命周期。即使生产者发布了新版本的配置,旧版本的配置对象不会被立即释放------只要还有消费者持有指向它的 shared_ptr,对象就不会被销毁。这解决了裸指针方案里最棘手的生命周期问题。
最后,std::atomic<std::shared_ptr<T>> 是 C20 才正式引入的。在 C20 之前,你需要用 std::atomic_load 和 std::atomic_store 这对独立函数来操作 shared_ptr,或者干脆用 mutex 保护 shared_ptr 的读写。如果你的项目还停留在 C++17 或更早的标准上,不要试图自己用 reinterpret_cast 之类的手段来绕过这个限制------那条路布满了未定义行为。
在一些对读取性能极端敏感的场景里(比如每秒数百万次的配置读取),shared_ptr 的引用计数本身也会成为瓶颈------每次拷贝 shared_ptr 都要对引用计数做一次原子递增,析构时还要递减。这时候工程上会转向 RCU(Read-Copy-Update)风格的方案:生产者用 release store 发布裸指针,消费者用 acquire load 读取指针并在一个受保护的"读侧临界区"内使用它,旧对象的释放由一个专门的回收机制(比如 epoch-based reclamation 或 hazard pointer)来处理。这些方案的复杂度远高于 shared_ptr,属于系统级基础设施的范畴,在普通业务代码里几乎不会直接使用。
多生产者场景要格外谨慎
到目前为止,我们讨论的都是单生产者的场景:一个线程写数据、发布标志,另一个线程收标志、读数据。但在真实系统中,多个生产者并发发布的情况并不少见。
当多个生产者同时往同一个原子变量上做 release store 时,只有一个值会最终"活下来"(原子变量同一时刻只有一个值)。消费者做 acquire load 时读到的是修改顺序中最新的那个值,而 synchronizes-with 关系只和那一次 release store 配对。
cpp
#include <atomic>
std::atomic<int> version{0};
int data_v1 = 0;
int data_v2 = 0;
void ProducerA() {
data_v1 = 100;
version.store(1, std::memory_order_release);
}
void ProducerB() {
data_v2 = 200;
version.store(2, std::memory_order_release);
}
void Consumer() {
int v = version.load(std::memory_order_acquire);
if (v == 1) {
// 与 ProducerA 的 release store 配对
// data_v1 == 100 有保证
Use(data_v1);
} else if (v == 2) {
// 与 ProducerB 的 release store 配对
// data_v2 == 200 有保证
Use(data_v2);
}
// 注意:如果 v == 2,data_v1 的值有保证吗?
}这段代码里有一个微妙的问题。如果 Consumer 读到 v == 2,说明它和 ProducerB 的 release store 建立了同步关系,data_v2 == 200 有保证。但 data_v1 呢?
要看 ProducerA 的 version.store(1, release) 是否 happens-before ProducerB 的 version.store(2, release)。如果 ProducerA 先执行(在 version 的修改顺序中,1 排在 2 前面),那么 ProducerA 的 release store happens-before ProducerB 的 release store(因为 ProducerB 必须先"看到"version 从 1 变到 2 才能覆盖它),再 happens-before Consumer 的 acquire load。这条链串起来,data_v1 == 100 也有保证。
但如果两个 Producer 几乎同时写入,ProducerB 直接把 version 从 0 覆盖成了 2,ProducerA 的 version.store(1) 在修改顺序中排在 version.store(2) 之后(然后又被 2 覆盖回去了),那情况就复杂了。
这些细节说明一个问题:多生产者场景下,release/acquire 的推理难度急剧上升。消费者不能简单地假设"我读到了最新版本号,所以所有老版本的数据都对我可见"------你必须仔细分析修改顺序和 happens-before 链条。
工程上,多生产者并发更新同一份共享数据时,通常有几种更稳妥的方案。一是用 compare_exchange(CAS)来竞争更新权,确保每次只有一个生产者成功写入;二是用 mutex 保护整个更新路径;三是结合版本号和指针发布,让每个生产者发布独立的对象,消费者根据版本号选择读哪个。这些方案我们在第 10 章讲 CAS 和无锁编程的时候会展开。
还有一种在实践中容易忽视的情况:消费者不止一个。当多个消费者同时做 acquire load 读取同一个原子变量时,每个消费者都能独立地和最近一次 release store 建立同步关系。这本身没有问题------release/acquire 的同步关系是一对多兼容的。但如果消费者在读到数据之后还要写回某些共享状态(比如更新一个"已处理"计数器、或者回写计算结果到共享数组),那消费者之间就需要额外的同步------这已经超出了 release/acquire 这个简单协议的管辖范围了。这时候要么给消费者之间加锁,要么用 CAS 来做竞争写入。
release/acquire 的硬件代价
说了这么多语义层面的东西,最后看一下 release/acquire 在硬件上到底要付出多少代价。
在 x86-64 上,release store 和 acquire load 几乎是免费的。x86 的 TSO 模型天然保证了 Store-Store 不会重排(release store 所需),Load-Load 和 Load-Store 不会重排(acquire load 所需)。编译器唯一需要做的是阻止自己的重排优化------具体说就是在 release store 前面、acquire load 后面插入一个编译器屏障,禁止编译器把指令挪过去。但不需要插入任何额外的 CPU 指令。所以在 x86 上,release/acquire 和 relaxed 生成的汇编往往一模一样,性能差距几乎为零。
在 ARM64 上,情况不同。release store 会被编译成 stlr(Store-Release)指令,acquire load 会被编译成 ldar(Load-Acquire)指令。这两条指令比普通的 str/ldr 多了硬件级别的屏障语义,执行开销更大------但比 seq_cst 所需的全屏障(dmb ish)要便宜。
所以 release/acquire 的性能定位是:比 seq_cst 轻量(尤其在弱内存模型架构上),比 relaxed 重一些(但在 x86 上几乎无差别),正好覆盖了"需要跨线程同步但不需要全局顺序"这个最常见的工程需求。
release/acquire 的适用边界
把这一章的内容收拢一下,release/acquire 最适合的场景是"定向发布":一方写好数据,打标记;另一方收标记,读数据。它的核心优势是提供了精确到一对 store/load 的同步关系,不像 seq_cst 那样给所有原子操作排全局队列。
使用 release/acquire 时需要紧盯三件事。第一,release store 和 acquire load 必须操作同一个原子变量。第二,acquire load 必须读到 release store 写入的那个值。第三,被发布的数据的写入必须在 release store 之前完成,数据的读取必须在 acquire load 之后发生。三个条件全部满足,同步链才成立。
release/acquire 解决的是局部的同步问题。当系统变得复杂------多个生产者竞争、数据需要分版本管理、对象的生命周期跨越多个线程------你往往需要把 release/acquire 和 CAS、引用计数、条件变量甚至 mutex 组合使用。
下一章看 memory_order_consume。在 C++11 的设计里,consume 试图用一种比 acquire 更弱的约束来处理指针发布的场景------它只跟踪"数据依赖链",而不是像 acquire 那样拦住所有后续的读取。想法很精妙,但工程现实里几乎没人直接用它,编译器也基本把它当 acquire 来实现。下一章来看看这到底是怎么回事。
码字不易,欢迎大家点赞,关注,评论,谢谢!