
一、前言:当具身智能遇上数字人
当具身智能成为2026年AI圈最热词汇时,我在思考一个问题:数字人的交互瓶颈究竟在哪?传统视频流方案延迟高达2-3秒,用户说一句话要等半天才有回应。直到我接触到魔珐星云的参数流架构,端到端约500ms毫秒级响应让我看到了真正的具身智能交互可能。这篇文章以开发者视角,完整分享如何用Vue 3 + 魔珐星云SDK + 大语言模型,从零搭建一个可商用的AI具身智能数字人。
魔珐星云PC端官方链接 :https://xingyun3d.com?utm_campaign=daily&utm_source=CSDNwanfen3&utm_medium=&utm_term=&utm_content=
二、极速上手:30分钟跑通本地交互Demo
通过接入三方ASR、LLM完成一个可以交互对话的数字人应用
1.接入魔珐星云具身驱动SDK
2.对接LLM大模型,实现文本对话
3.对接ASR,实现语音转文本后对话
1、下载demo
GitHub仓库地址:https://github.com/publicize0828/XmovLiteAvatarJSDemo
Gitee仓库地址:https://gitee.com/xmovmaster/XmovLiteAvatarJSDemo
2、解压缩,用Qoder打开项目,终端安装环境依赖
bash
# 安装项目依赖包,下面两种方式都可以
# 使用 pnpm 安装
pnpm i
# 使用 npm 安装
npm i
3、启动项目
bash
npm run dev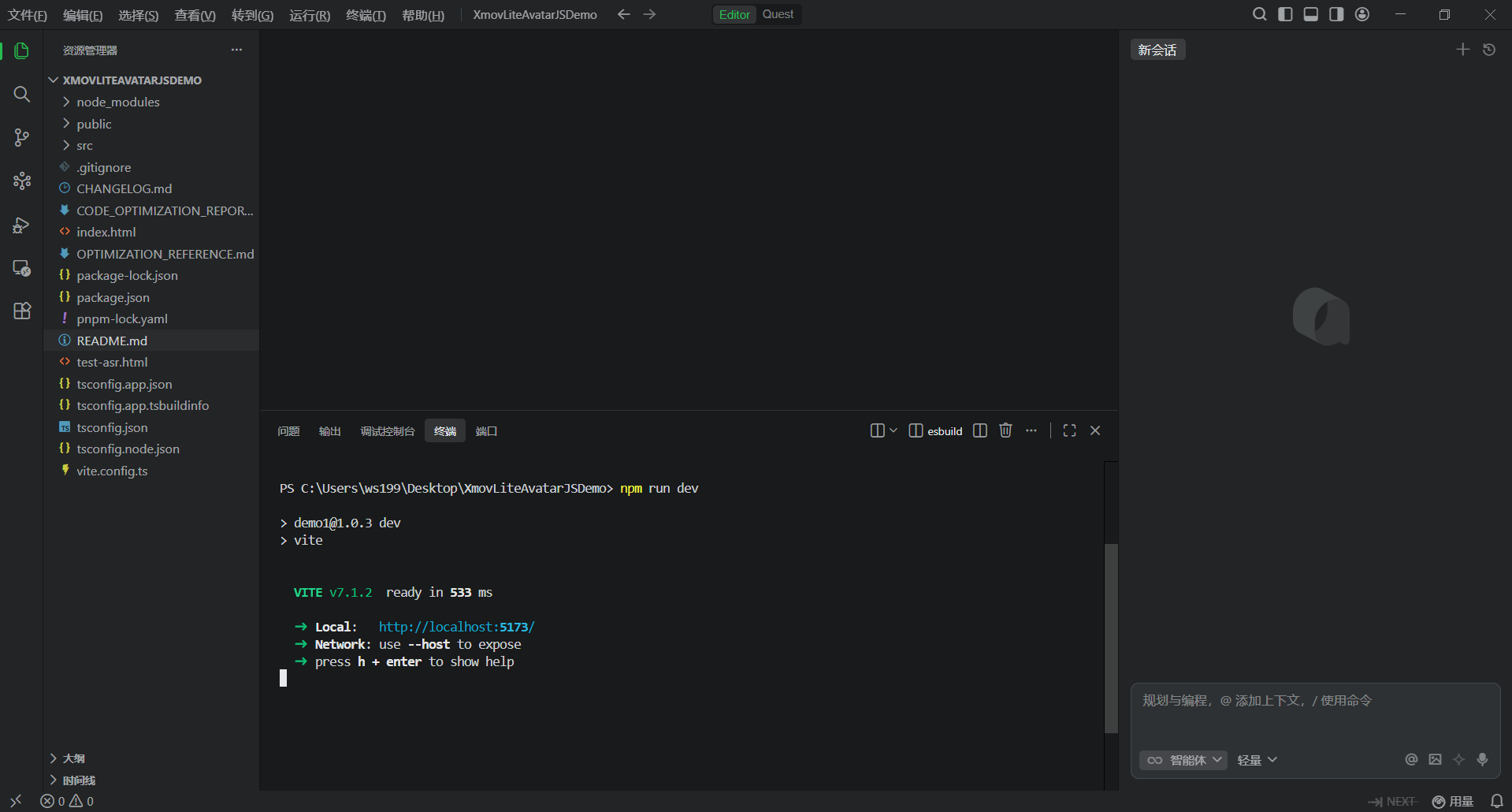
4、浏览器访问地址
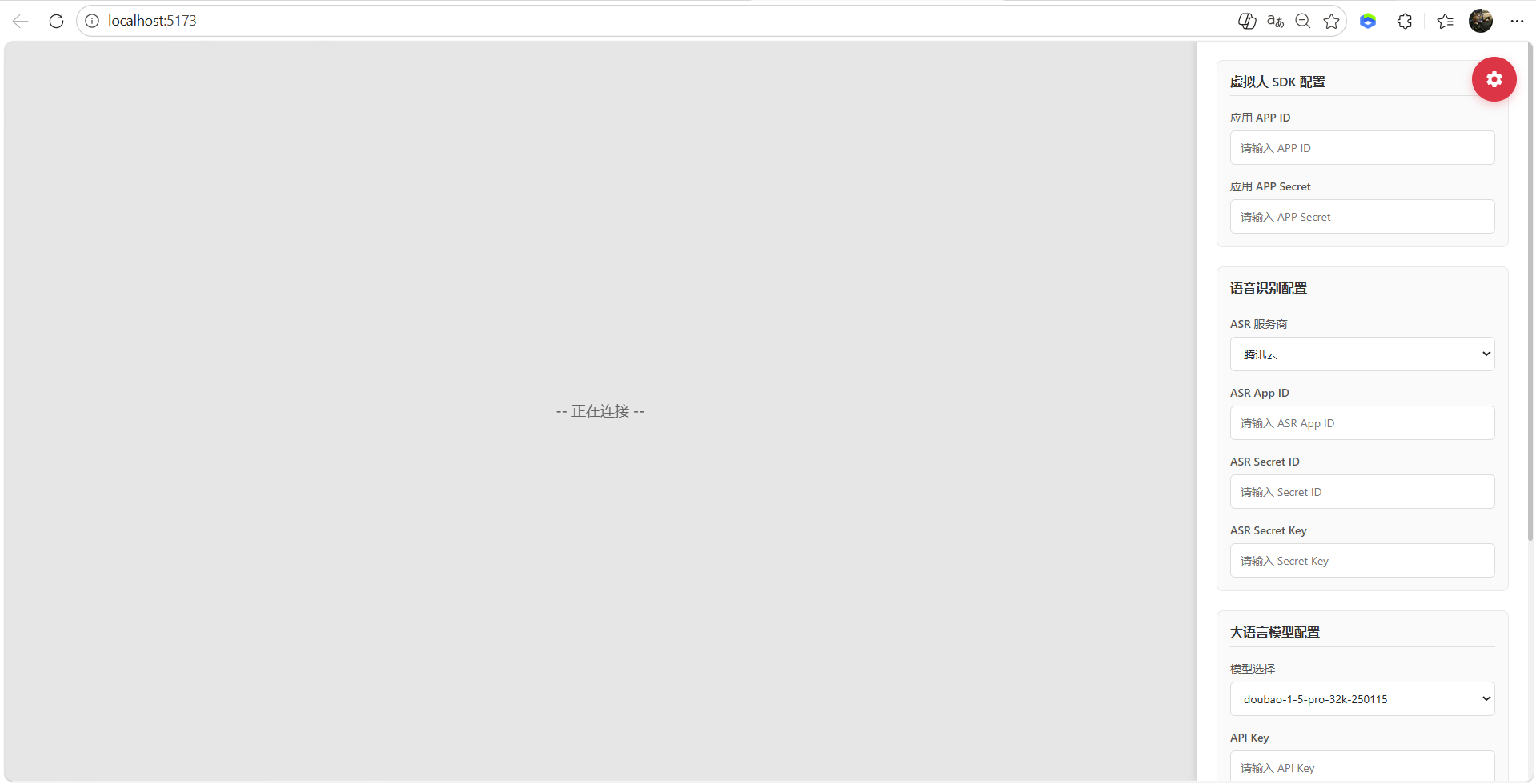
5、魔珐星云官网密钥配置(应用管理-拆功创建新应用)
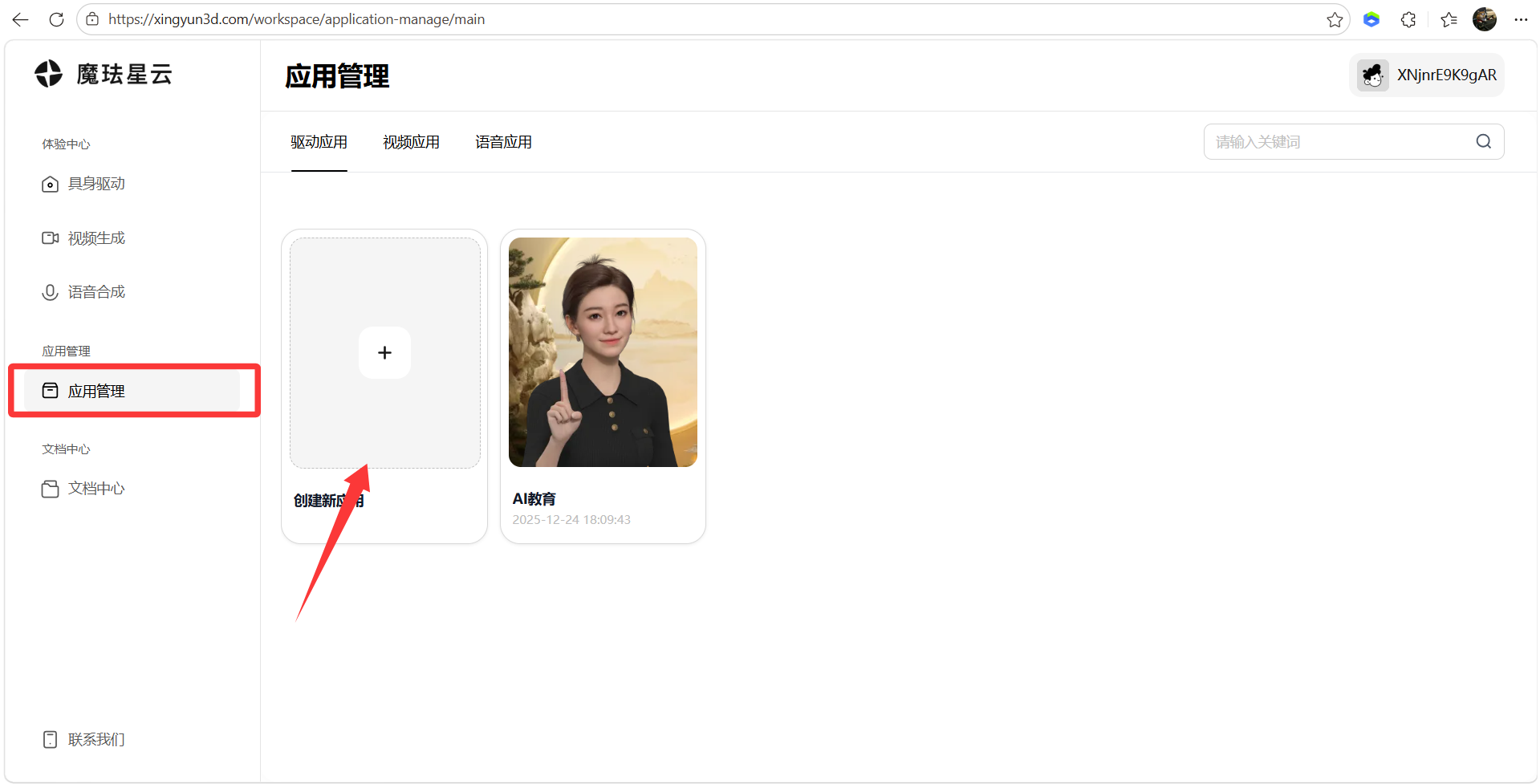
- 配置驱动应用名称、备注
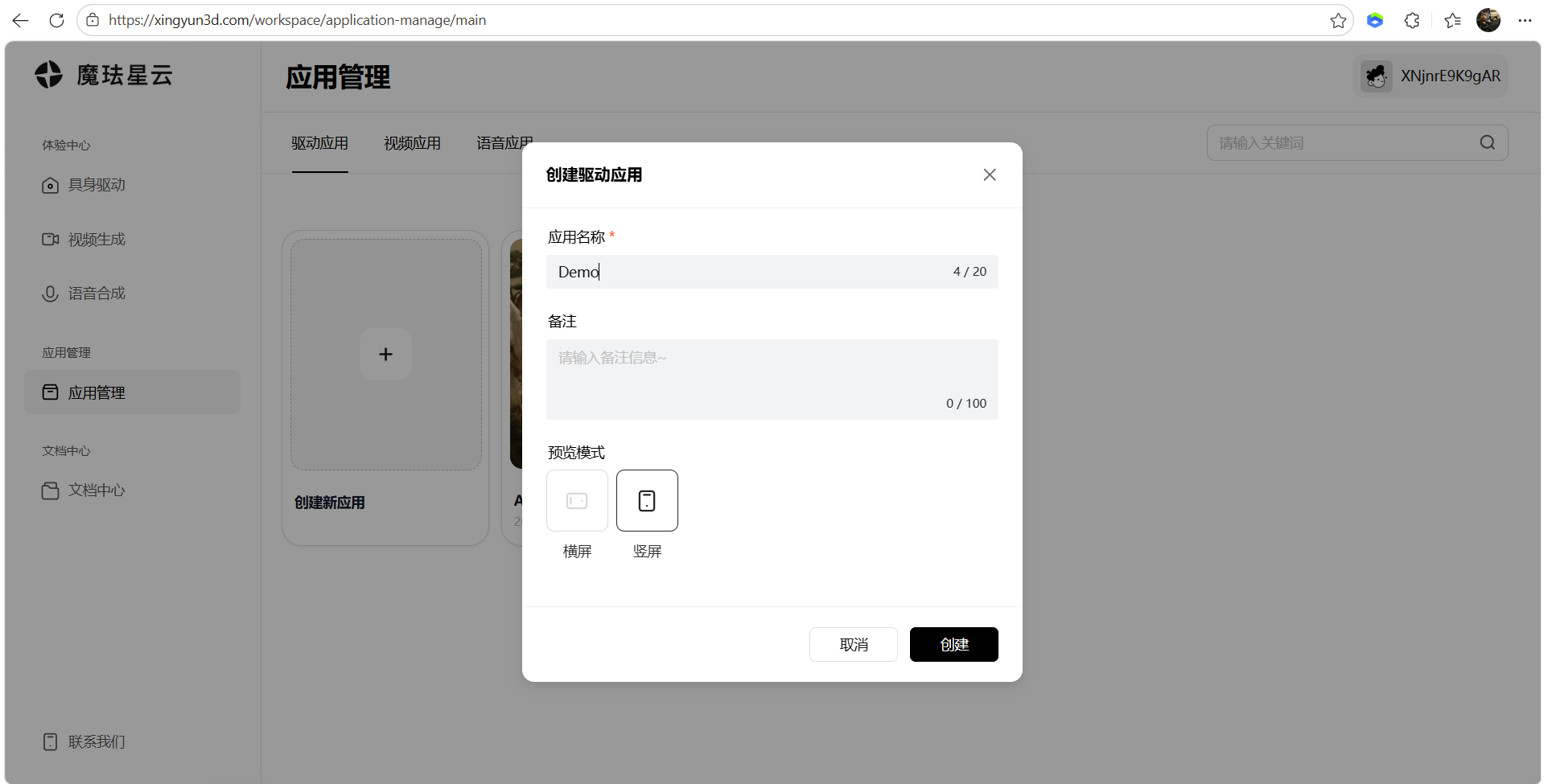
6、人物配置
- 形象配置
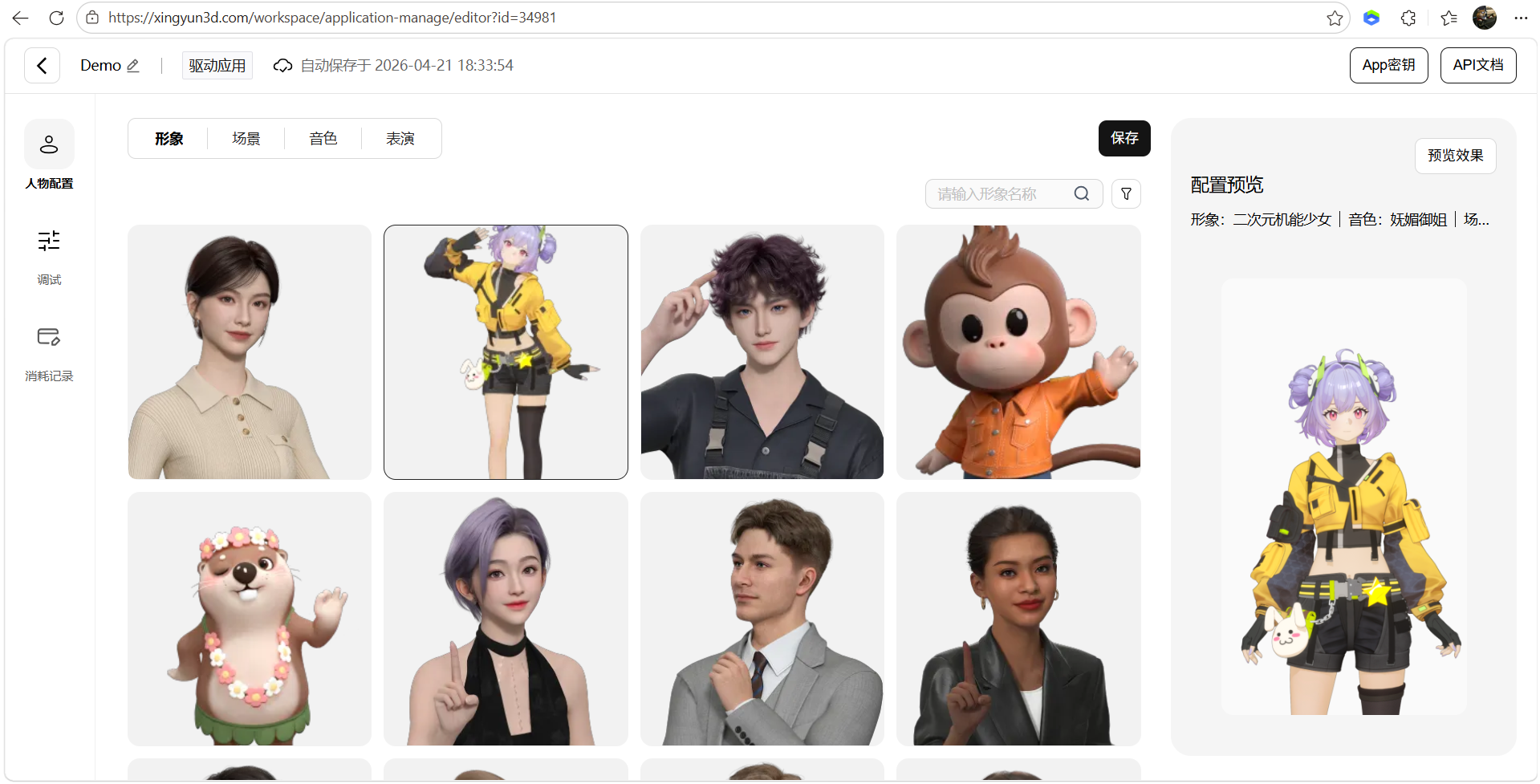
- 场景配置
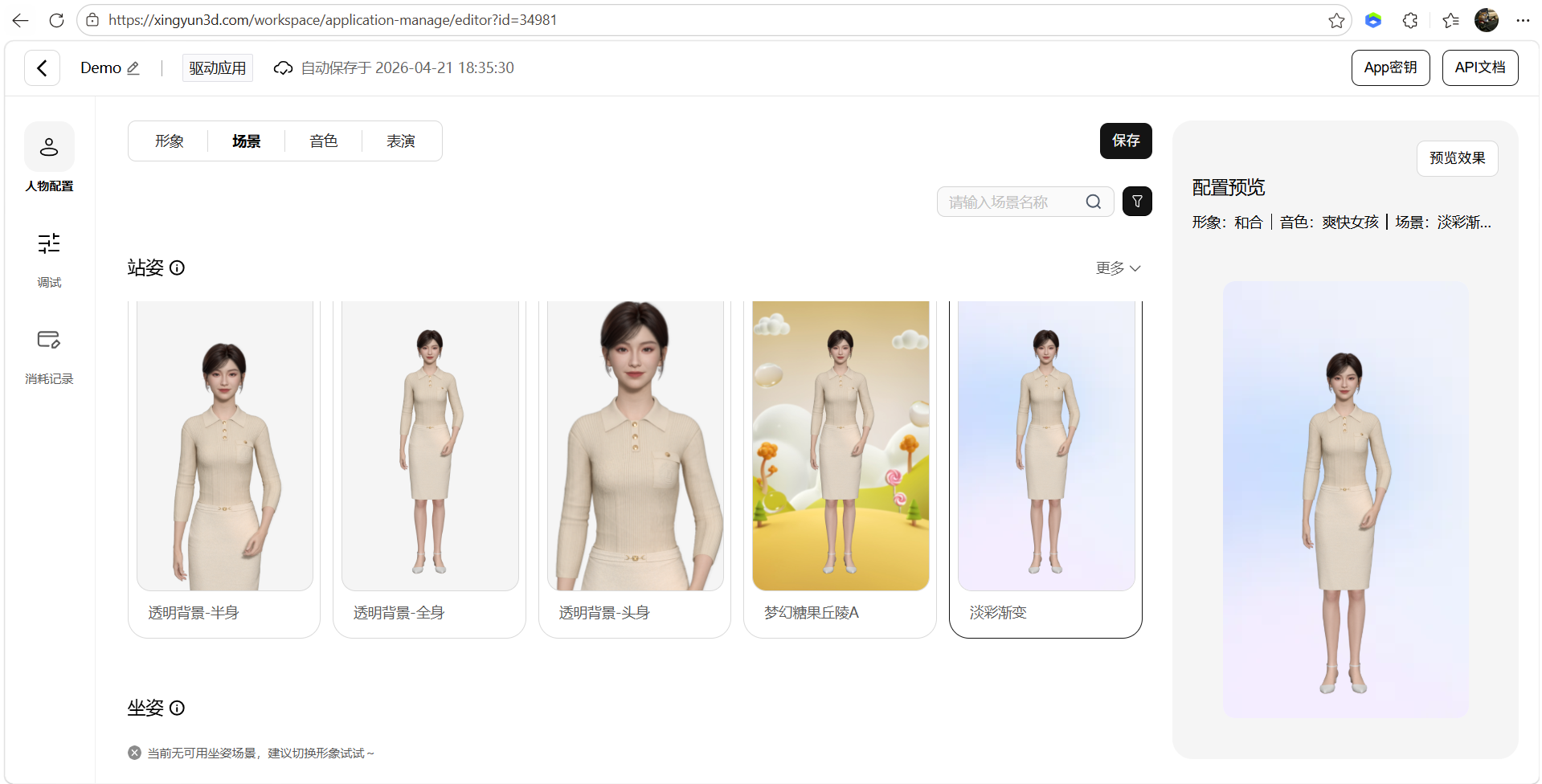
- 音色配置
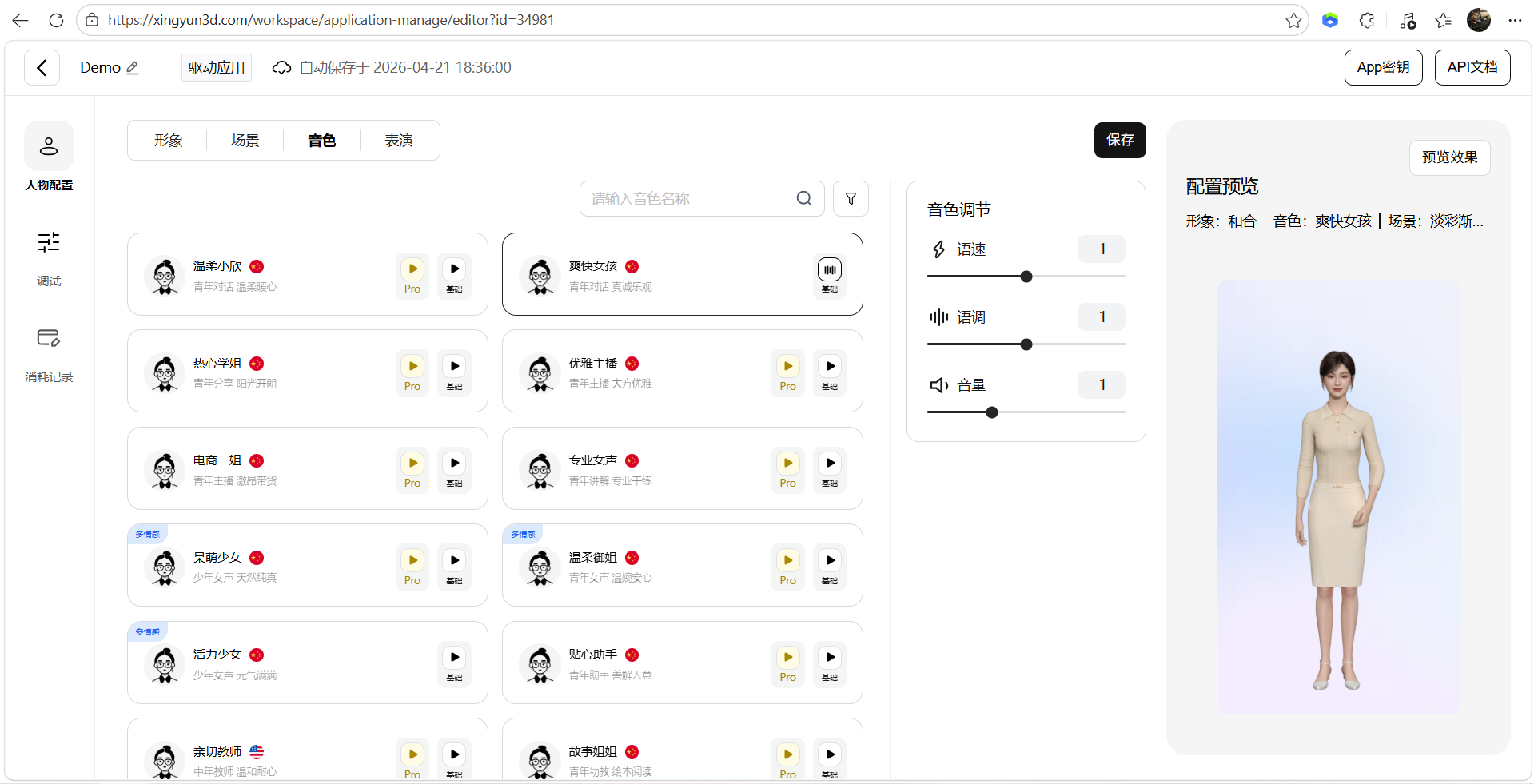
- 表演配置
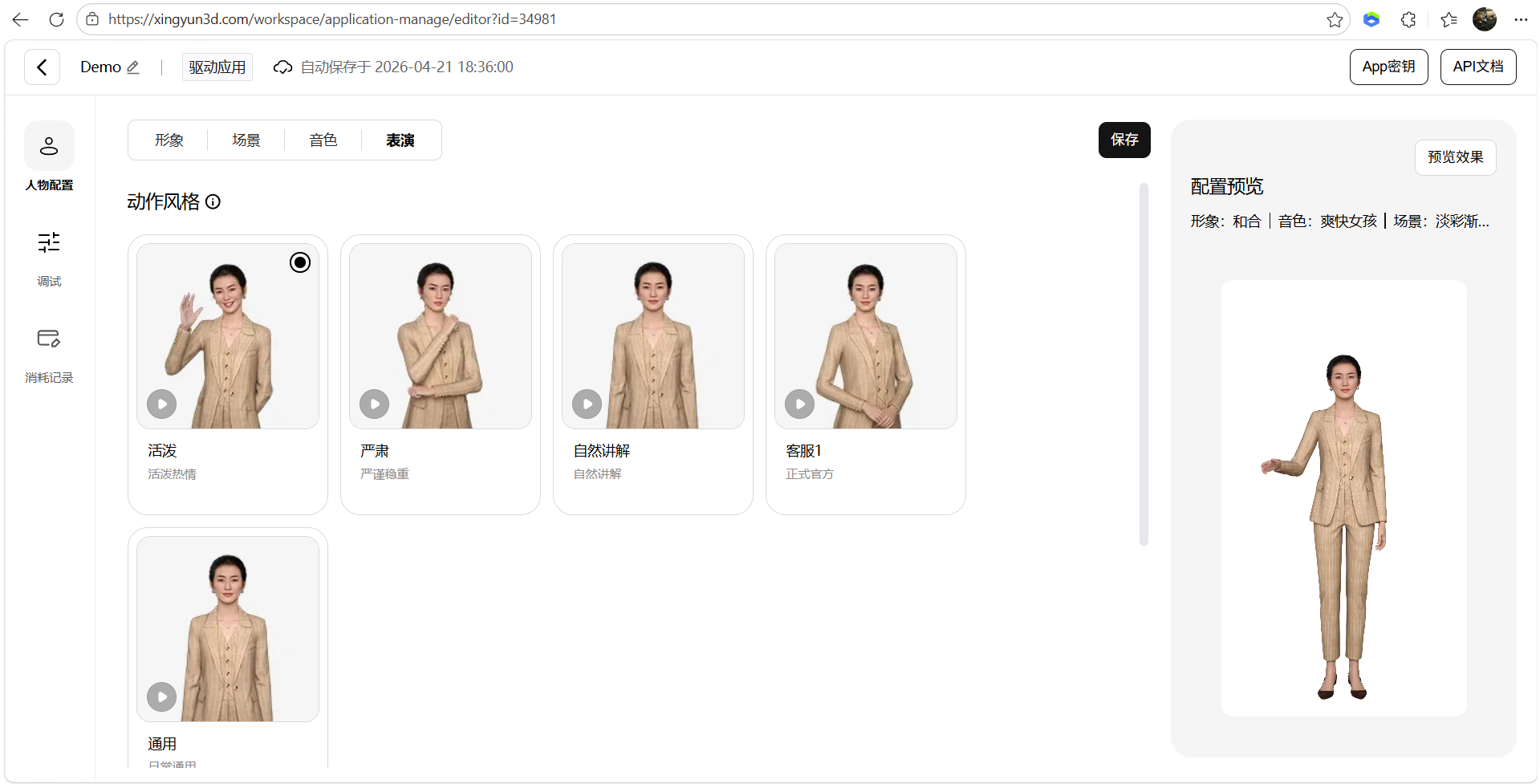
7、调试
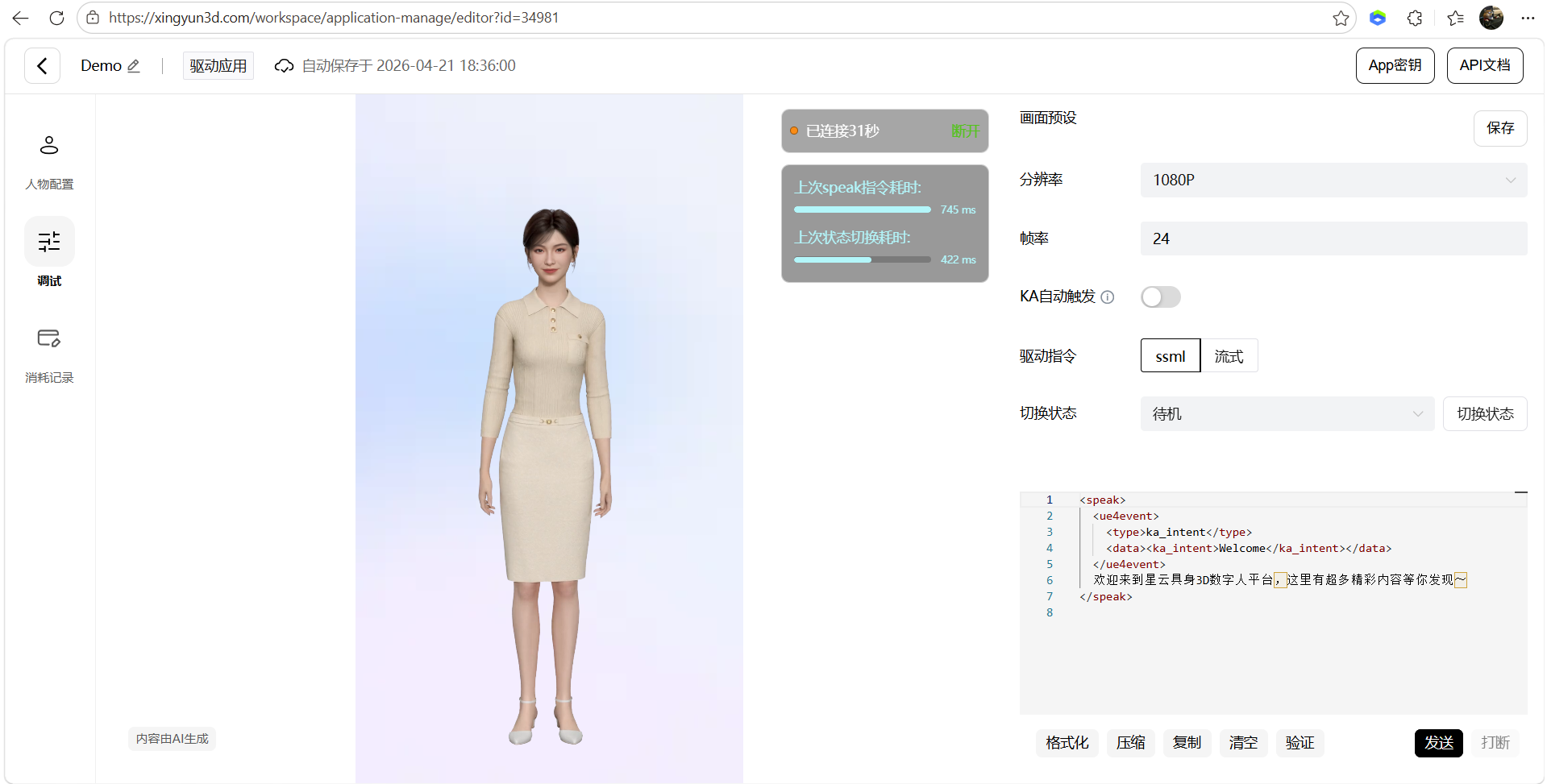
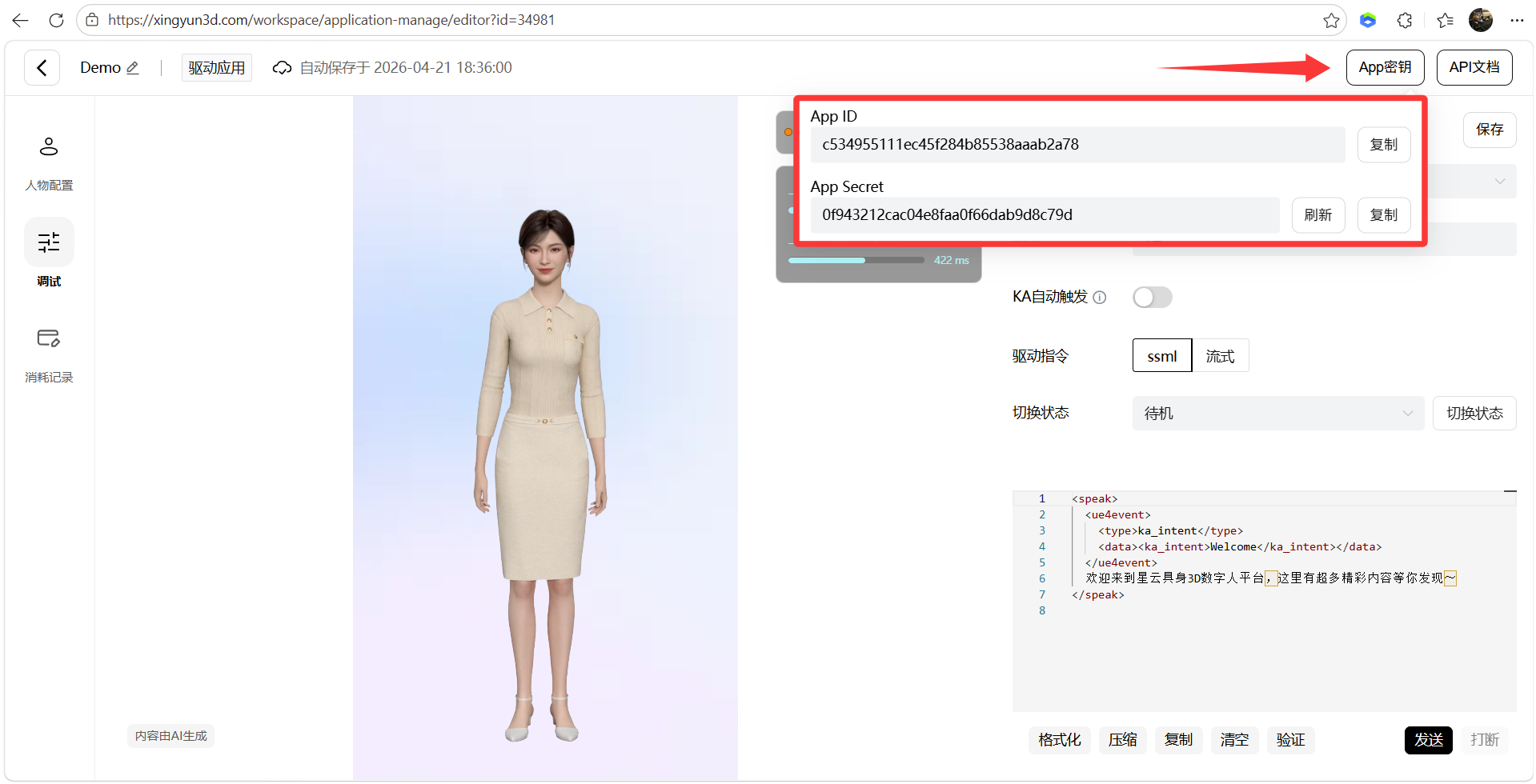
8、获取APP密钥,配置到本地项目
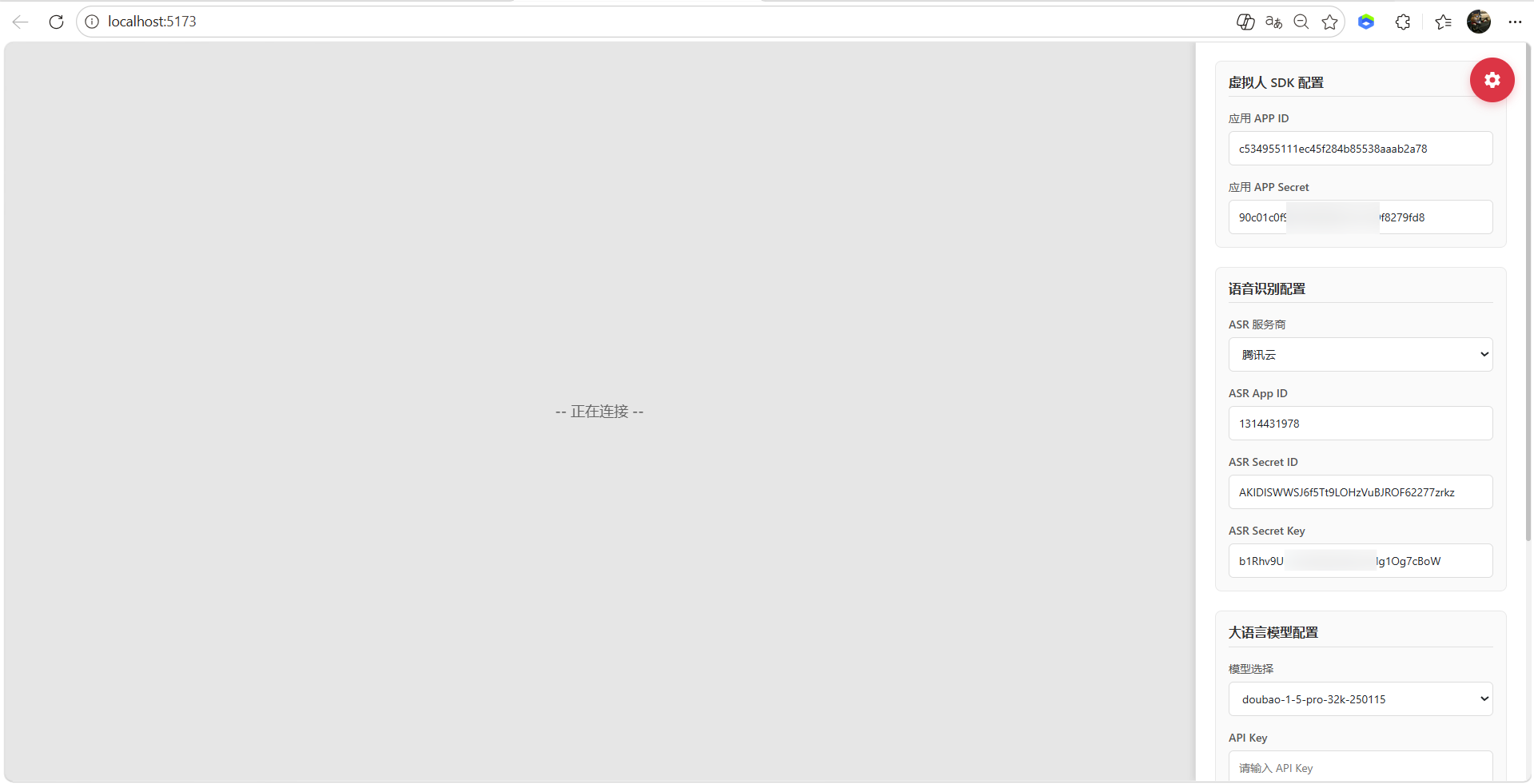
9、虚拟人 SDK 配置
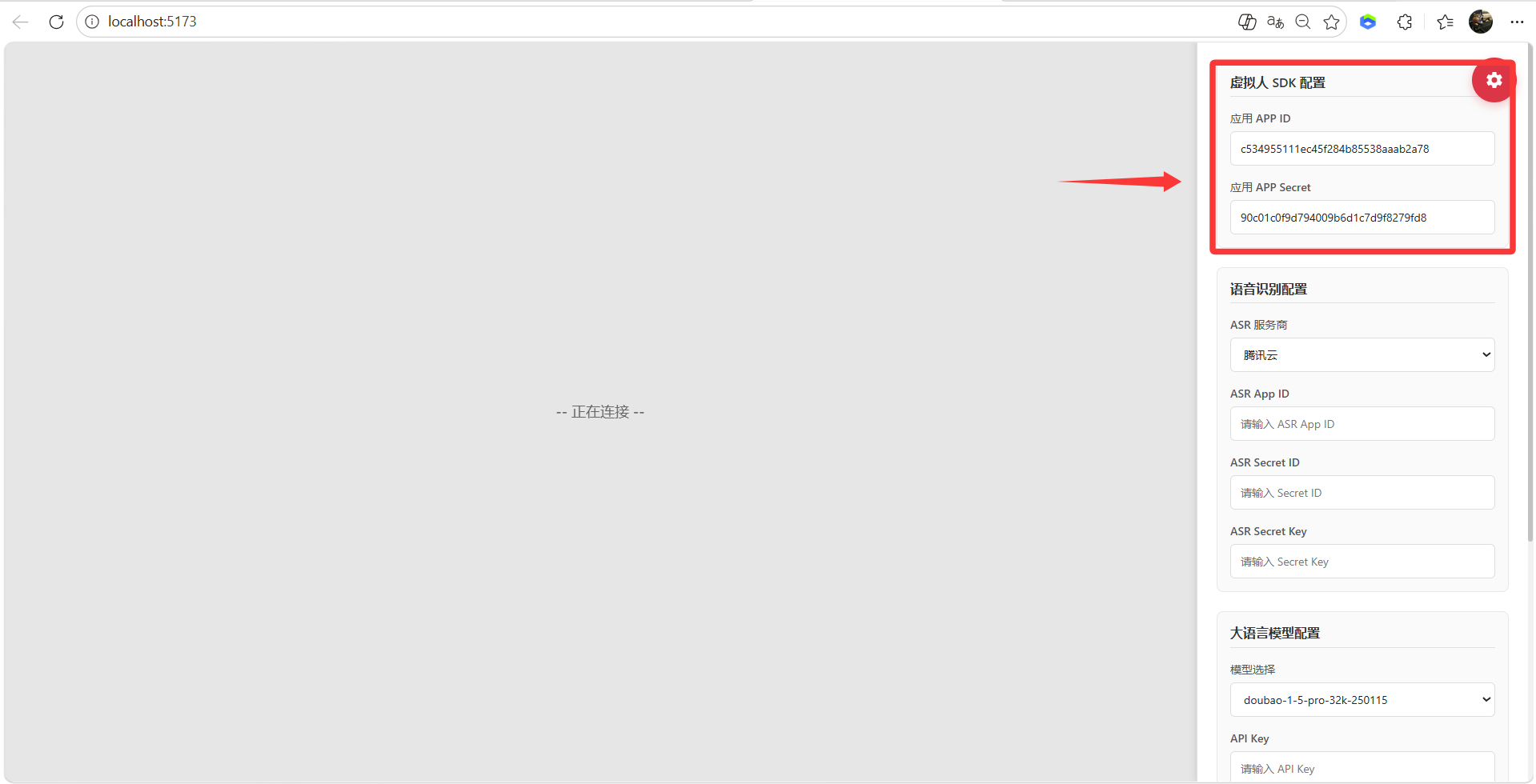
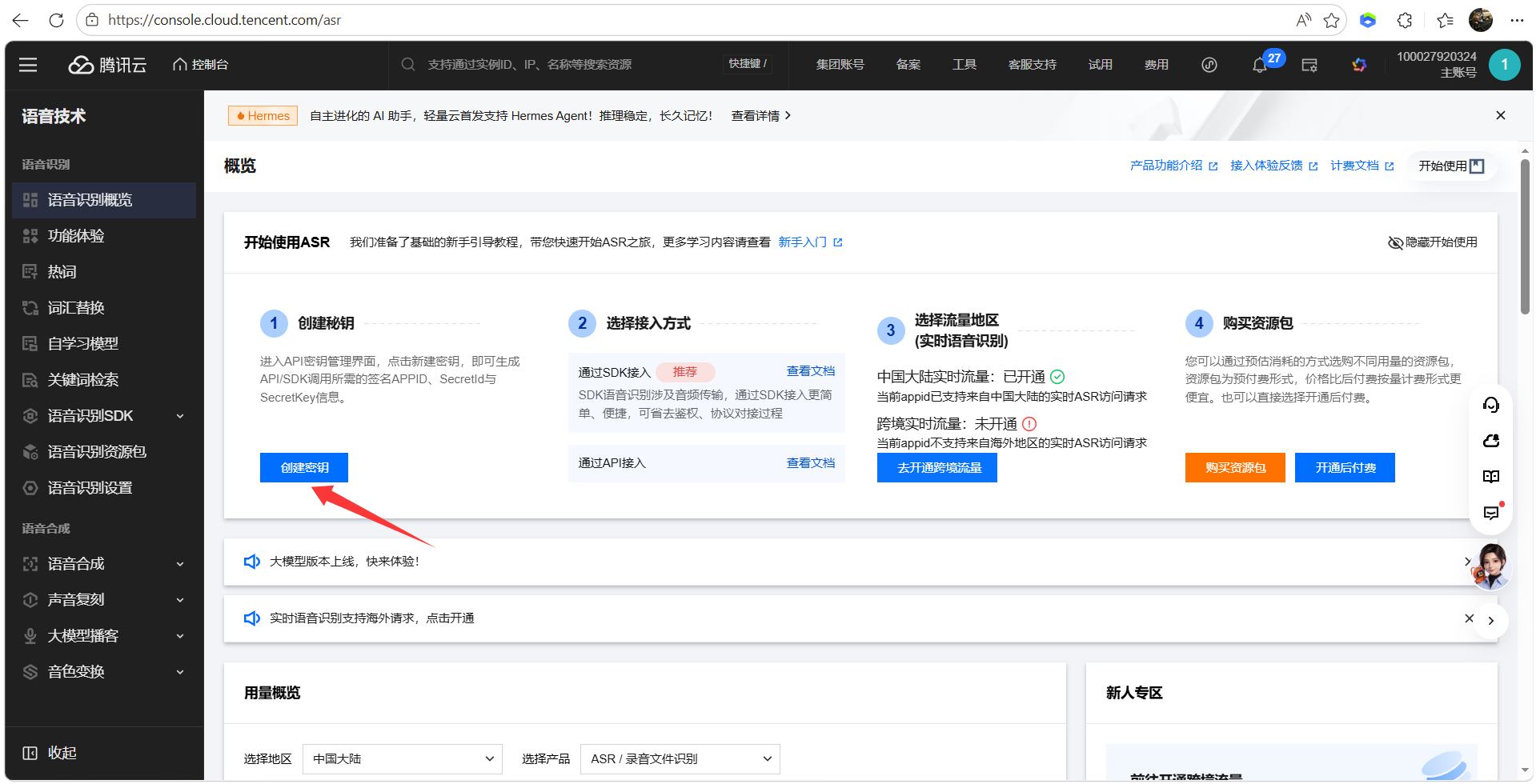
10、语音识别配置,登录腾讯云获取:https://console.cloud.tencent.com/asr
- 创建密钥
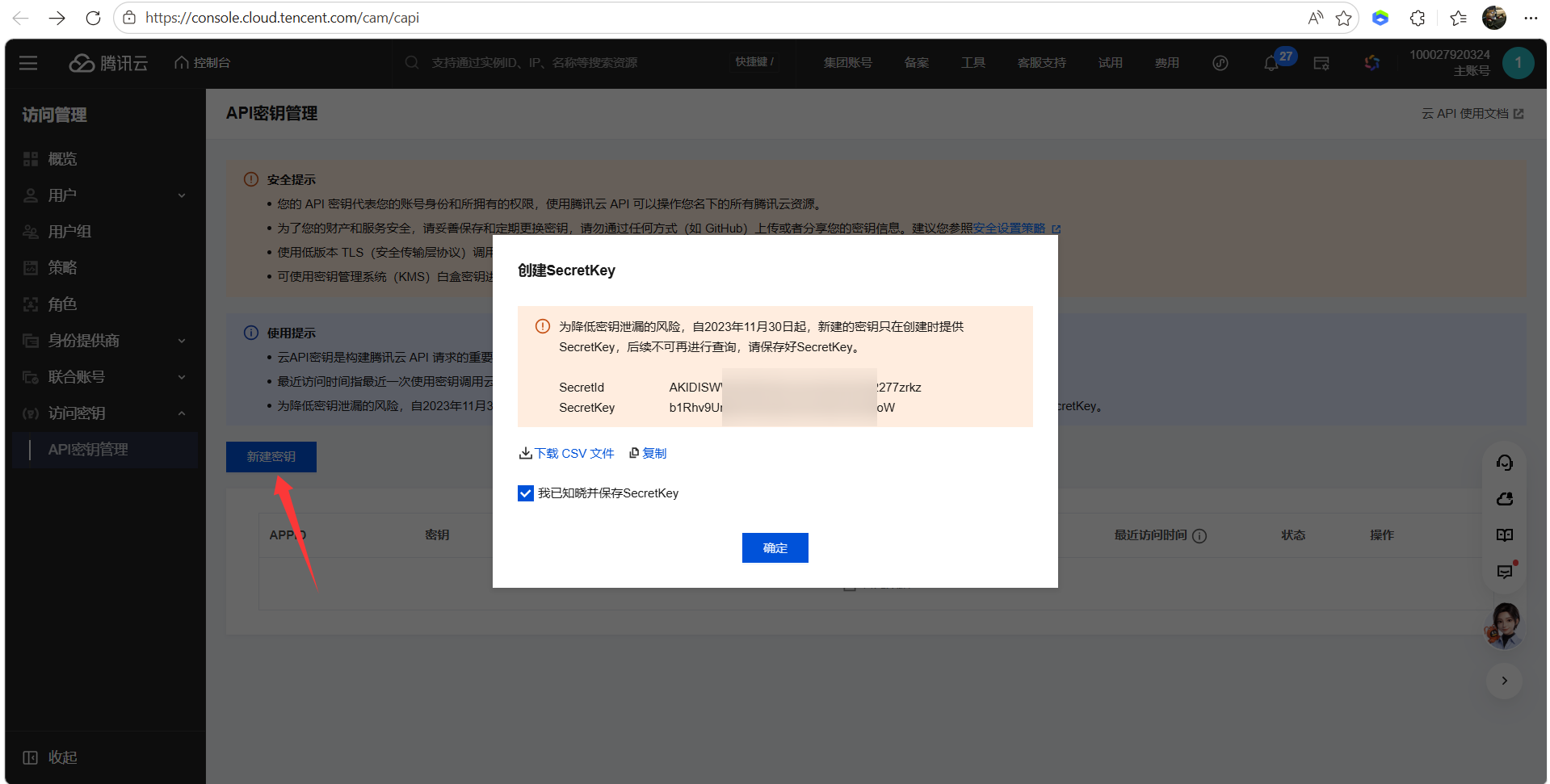
- 新建密钥,创建SecretKey,保存SecretKey
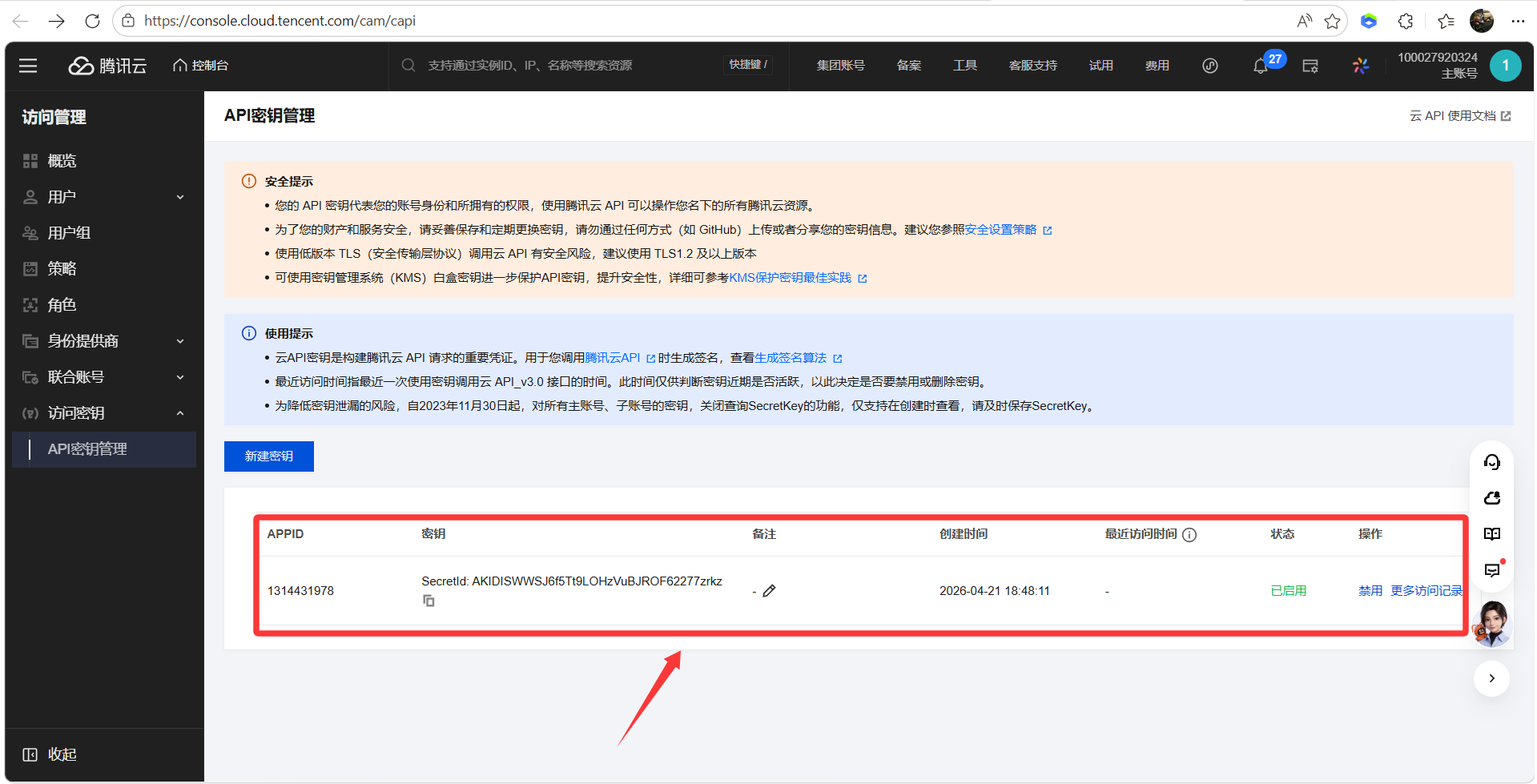
- 配置语音识别配置,ASR App ID、ASR Secret ID、ASR Secret Key
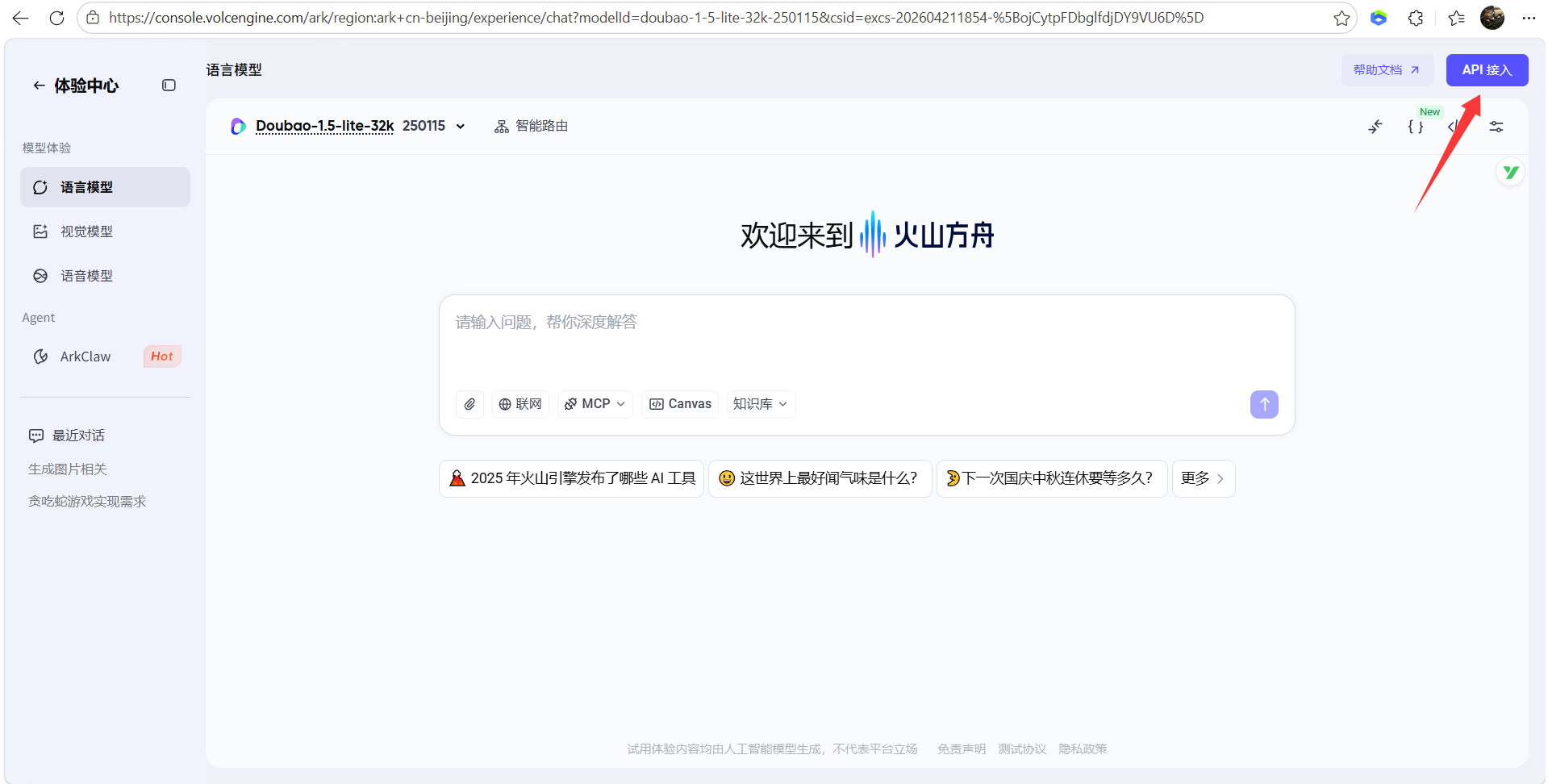
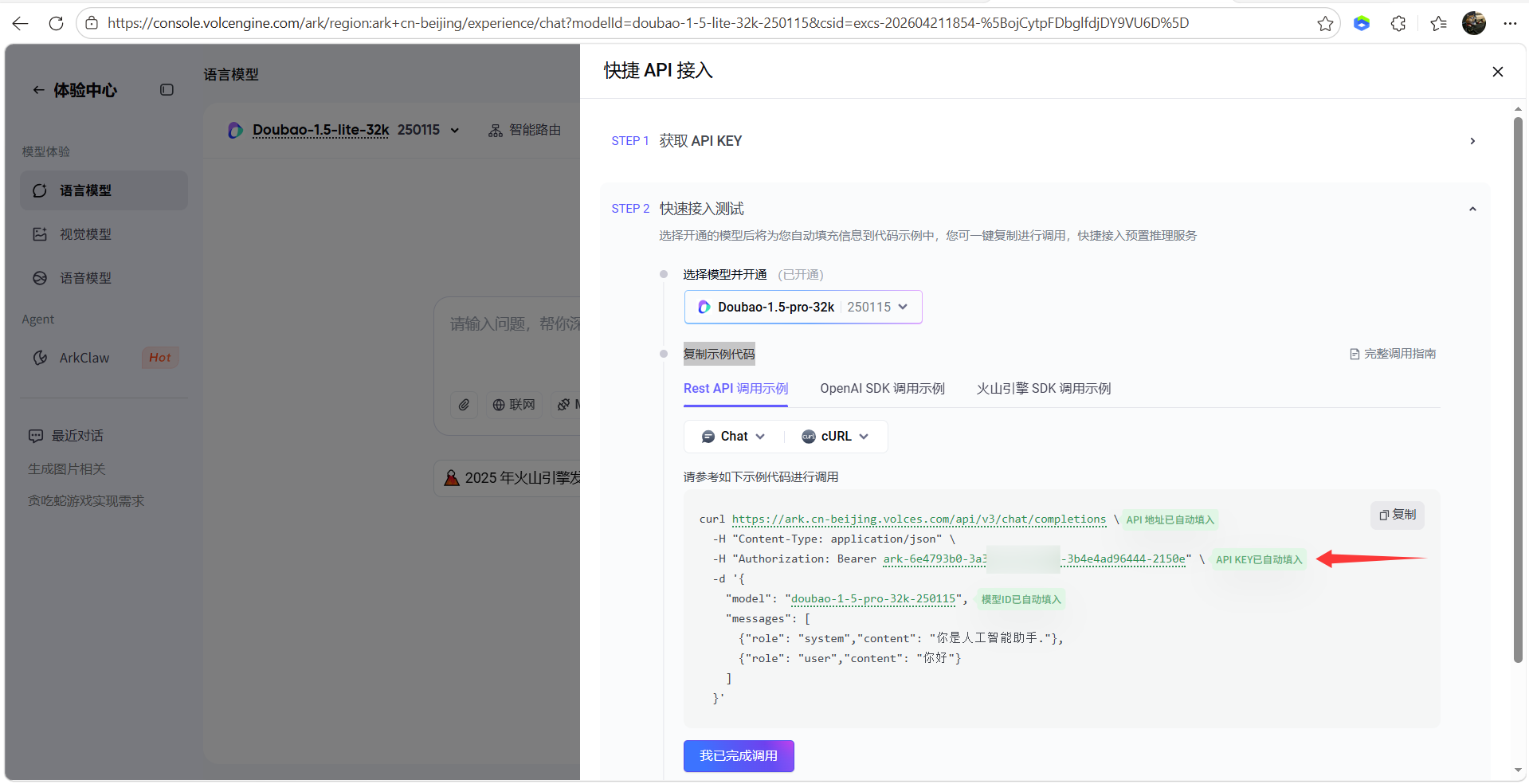
10、大语言模型配置,登录火山引擎官网配置:https://console.volcengine.com/ark/region:ark+cn-beijing/experience/chat?modelId=doubao-1-5-lite-32k-250115
- API接入
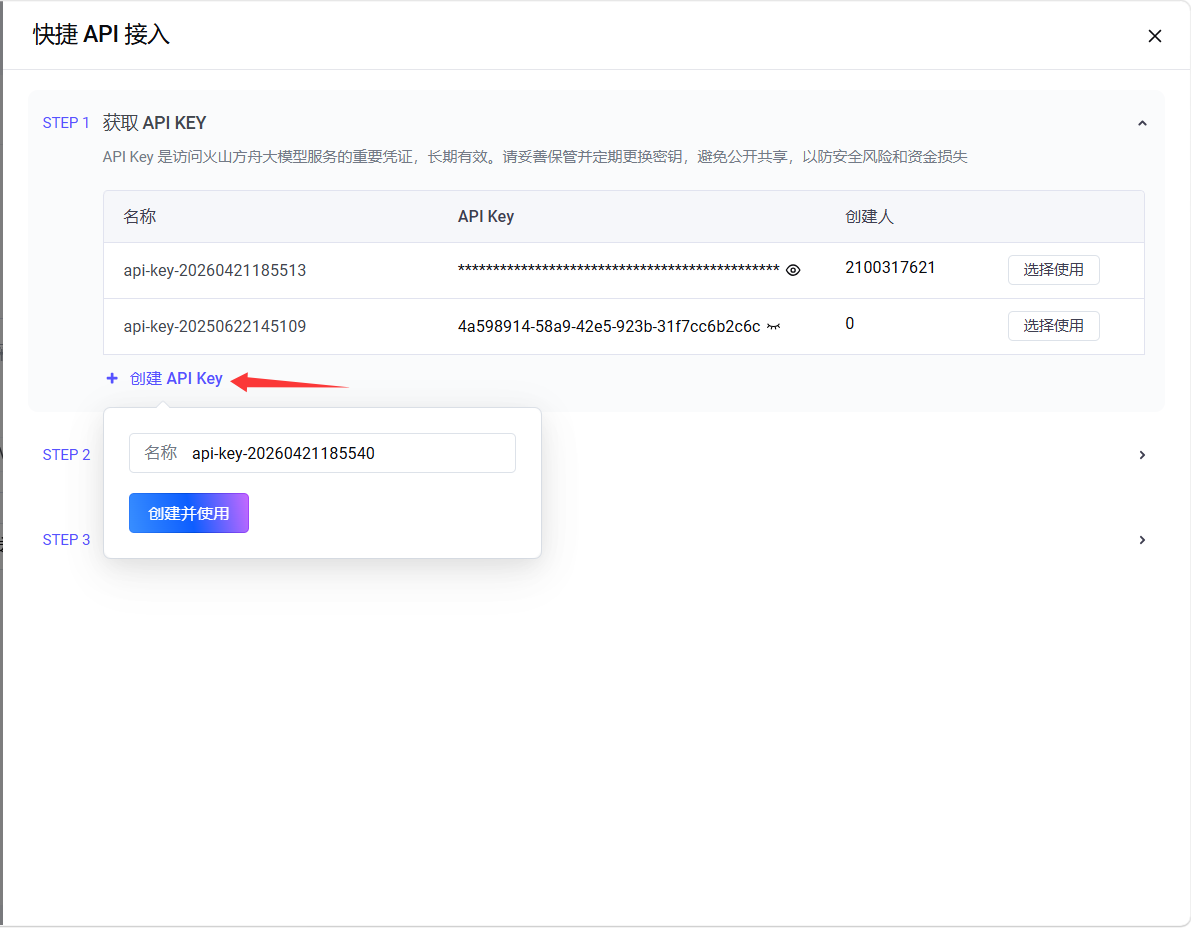
- 创建 API KEY
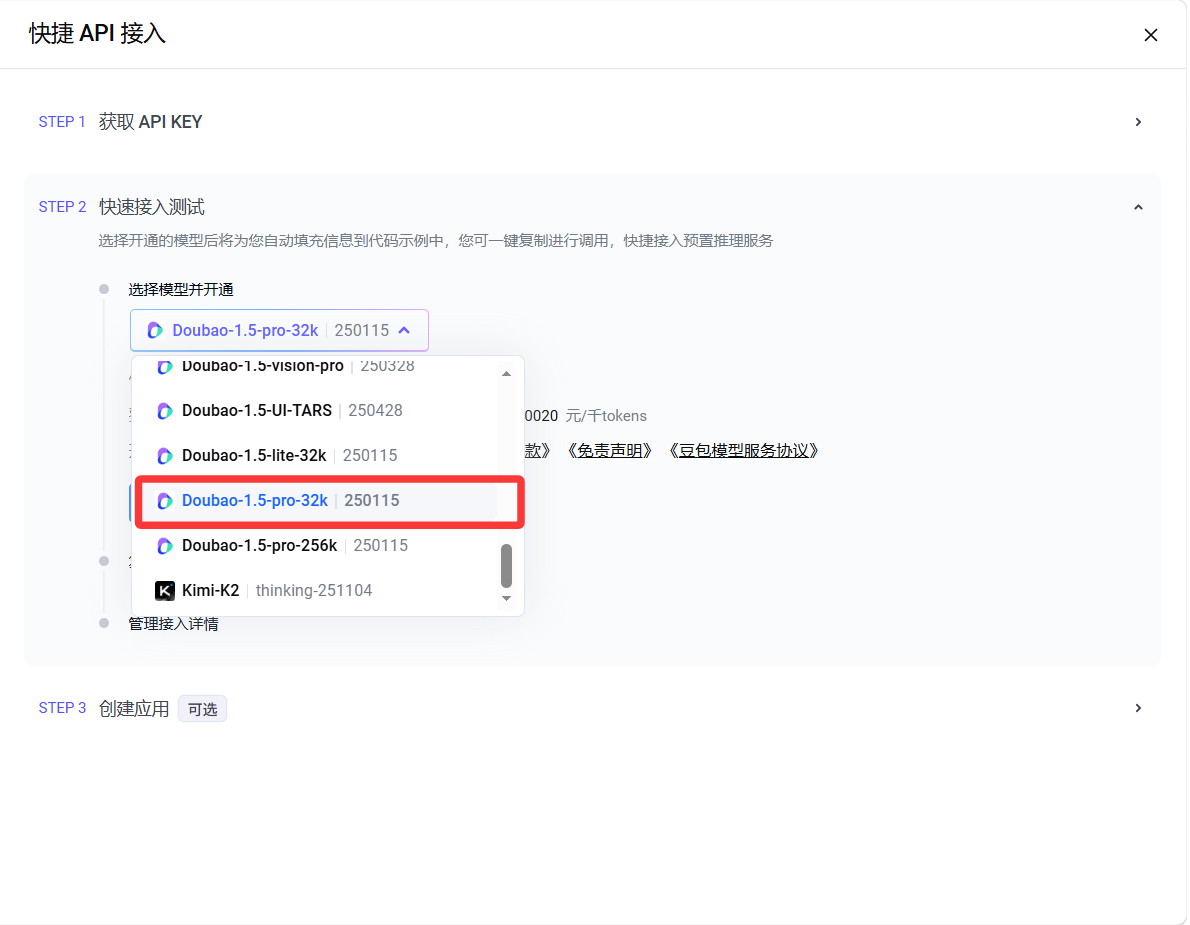
- 模型选择-开通模型
- 复制示例代码中的 API KEY 参数,并配置在Demo中
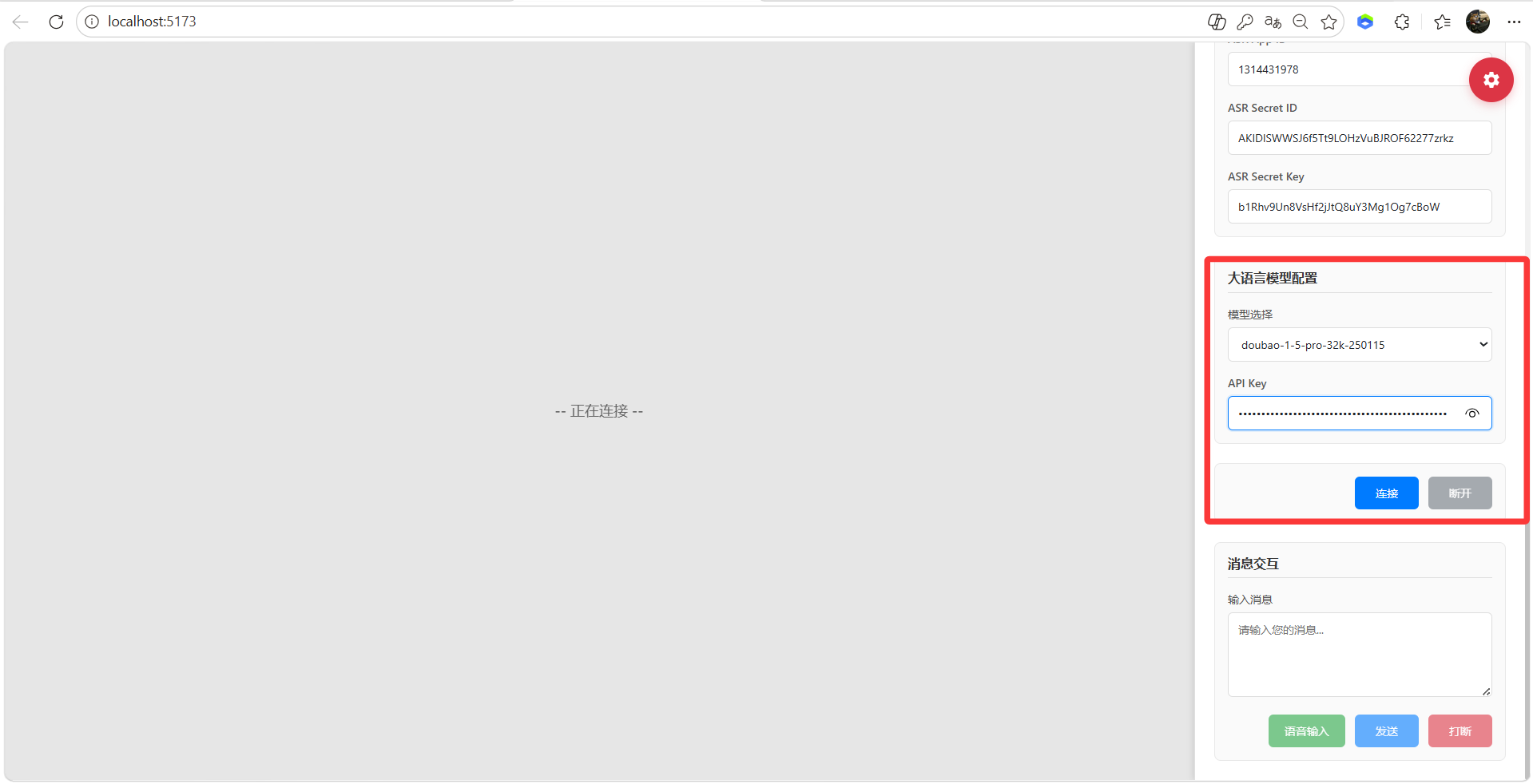
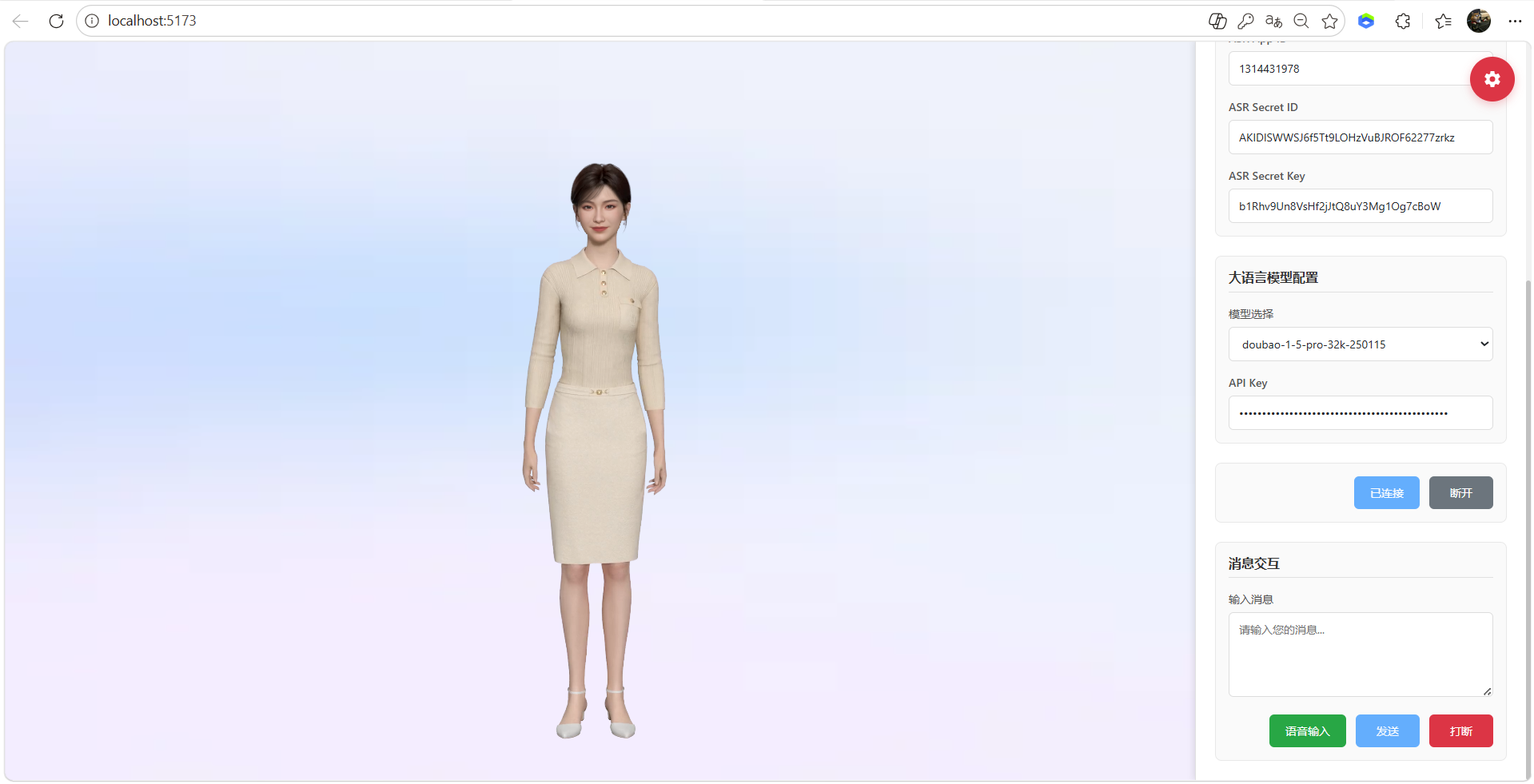
11、点击连接即可显示连接成功
- 支持文字输入交流,语音输入交流,魔珐星云官网更改配置等操作
三、场景聚焦:政企展厅的人形机器人实践
在本次开发中,我主要使用了Qoder作为AI编程工具,配合豆包大模型(doubao-1-5-pro-32k)进行代码生成和逻辑优化。整个项目的核心思路是:用参数流技术替代传统视频流,实现真正的实时交互。
3.1 魔珐星云平台具身驱动配置
1、魔珐星云平台创建人形机器人具身驱动
2、创建驱动应用配置相关信息
3、选择人物形象:灵犀机器人
4、选择灵犀机器人场景
5、选择灵犀机器人音色
6、选择灵犀机器人动作风格
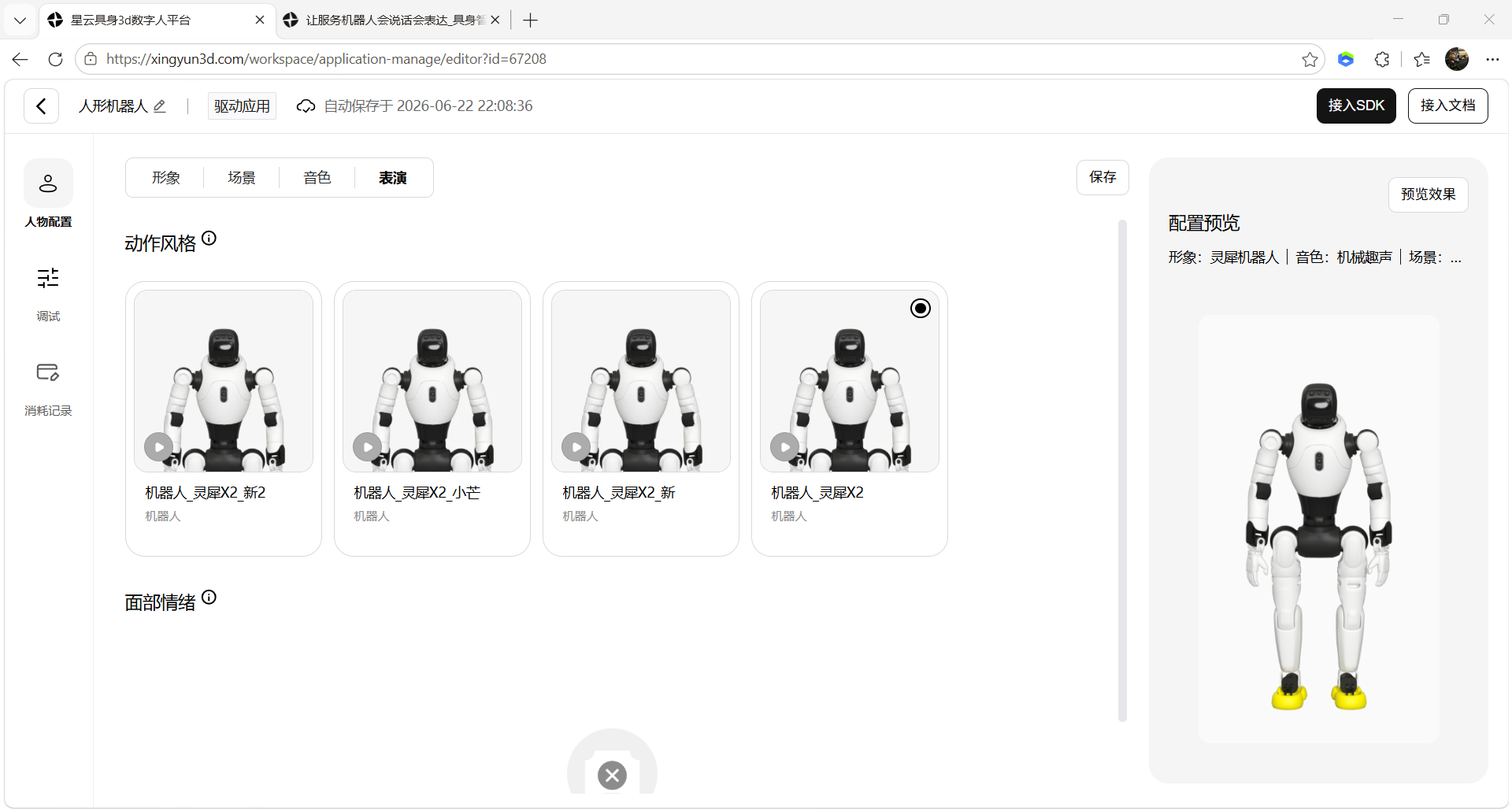
7、保存并接入SDK,复制对应App ID和App Secret
8、项目代码替换App ID和App Secret,并且让Qoder基于项目Demo开发灵犀人形机器人风格页面,如下是我的Prompt
bash
左侧深色功能栏展示智能问答、任务协助等四大核心能力,配有文字输入、语音说话、打断交互控件与使用说明;右侧画布呈现站立的蓝白配色 3D 人形数字机器人模型,背景为涂鸦砖墙,顶部标注系统在线状态,底部标注系统版本 V1.0,实现文字 + 语音和 3D 数字机器人实时对话交互,数字人页面大小调整适应浏览器页面大小,整体风格人形机器人风格
3.2 核心模块实现:四大关键技术
3.2.1 数字人渲染服务(avatar.ts)
这是项目的核心模块,负责与魔珐星云SDK交互。参数流技术的关键在于:云端只传输驱动参数(骨骼、表情、口型坐标),客户端本地解算渲染。
服务类初始化
typescript
class AvatarService {
private containerId: string
constructor() {
this.containerId = generateContainerId() // 生成唯一容器ID
}
getContainerId(): string {
return this.containerId
}
}
export const avatarService = new AvatarService()代码讲解:
- 使用 class 定义 AvatarService 类,采用单例模式避免多实例冲突
- containerId 动态生成唯一标识,确保页面多个数字人不冲突
- 导出单例 avatarService,全局共享同一连接
SDK连接流程
typescript
async connect(config: AvatarConfig, callbacks: AvatarCallbacks): Promise<any> {
const { appId, appSecret } = config
const { onSubtitleOn, onSubtitleOff, onStateChange } = callbacks
// 1. 检查容器是否存在
const containerEl = document.getElementById(this.containerId)
if (!containerEl) {
throw new Error(`容器 #${this.containerId} 不存在`)
}
// 2. 构建网关URL(参数流入口)
const url = new URL(SDK_CONFIG.GATEWAY_URL)
url.searchParams.append('data_source', SDK_CONFIG.DATA_SOURCE)
url.searchParams.append('custom_id', SDK_CONFIG.CUSTOM_ID)
// 3. Promise管理连接状态
let resolve: (value: boolean) => void
let reject: (reason?: any) => void
const connectPromise = new Promise<boolean>((res, rej) => {
resolve = res
reject = rej
})
// 4. 构建SDK配置选项
const constructorOptions = {
containerId: `#${this.containerId}`,
appId,
appSecret,
enableDebugger: false,
gatewayServer: url.toString(),
onStateChange,
onMessage: async (error: any) => {
const state = await getPromiseState(connectPromise)
if (state === 'pending') {
reject(new Error(error.message))
}
},
onVoiceStateChange: (status: string) => {
if (status.includes('end')) {
onVoiceStateChange?.(status)
}
}
}
// 5. 创建SDK实例(启动参数流)
const avatar = new window.XmovAvatar(constructorOptions)
// 6. 等待初始化
await new Promise(resolve => setTimeout(resolve, 1000))
// 7. 初始化SDK并监听下载进度
await avatar.init({
onDownloadProgress: (progress: number) => {
console.log(`初始化进度: ${progress}%`)
if (progress >= 100) resolve(true)
},
onClose: () => {
onStateChange('')
console.log('SDK连接关闭')
}
})
// 8. 设置超时机制(15秒)
const connectTimeout = new Promise<boolean>((_, rej) => {
setTimeout(() => rej(new Error('SDK连接超时')), 15000)
})
try {
await Promise.race([connectPromise, connectTimeout])
console.log('[AvatarService] 连接成功')
} catch (error) {
console.warn('SDK连接等待结束:', error)
}
return avatar
}代码讲解:
- connect 方法是核心异步函数,建立参数流通道的关键
- 步骤2:构建网关URL,这是参数流的入口地址。魔珐星云的参数流架构在这里体现------不传输视频,只传输驱动参数
- 步骤5:new window.XmovAvatar() 创建SDK实例,启动参数流通道
- 步骤7:avatar.init() 开始下载3D模型资源,进度到100%时通道就绪
- 步骤8:Promise.race 设置15秒超时,防止连接永久挂起
- 关键优势:整个连接过程只传输配置参数,不产生视频流带宽消耗,低延时、高并发
SDK配置说明
typescript
// constants/index.ts
export const SDK_CONFIG = {
GATEWAY_URL: 'https://nebula-agent.xingyun3d.com/user/v1/ttsa/session',
DATA_SOURCE: '2',
CUSTOM_ID: 'demo'
} as const
export const APP_CONFIG = {
AVATAR_INIT_TIMEOUT: 3000, // 初始化等待时间
SPEAK_INTERRUPT_DELAY: 2000
} as const代码讲解:
- GATEWAY_URL 是魔珐星云的参数流会话接口,非视频流地址
- AVATAR_INIT_TIMEOUT 设置3秒初始化等待,快速响应用户
- SPEAK_INTERRUPT_DELAY 定义说话打断延迟,支持中途打断交互
3.2.2 LLM对话服务(llm.ts)
负责与大语言模型交互,生成智能回复。这是数字人的"大脑"。
客户端初始化
typescript
class LlmService {
private openai: OpenAI | null = null
private currentApiKey: string = ''
private initClient(config: LlmConfig): void {
// 避免重复初始化
if (this.currentApiKey === config.apiKey && this.openai) {
return
}
const baseURL = config.baseURL || LLM_CONFIG.BASE_URL
this.openai = new OpenAI({
apiKey: config.apiKey,
dangerouslyAllowBrowser: true, // 允许浏览器端使用
baseURL: baseURL,
// 自定义fetch,支持流式请求
fetch: (url, init) => {
console.log('LLM请求URL:', url)
return fetch(url, init)
}
})
this.currentApiKey = config.apiKey
}
constructor() {
// 不自动初始化,按需懒加载
}
}
export const llmService = new LlmService()代码讲解:
- LlmService 类封装了与大语言模型的交互逻辑
- 懒初始化模式:只在首次调用时创建客户端,节省资源
- dangerouslyAllowBrowser: true 允许浏览器端直接使用(生产环境建议后端代理)
- 自定义 fetch 函数方便调试,可在此添加日志审计
非流式对话
typescript
async sendMessage(config: LlmConfig, userMessage: string): Promise<string | null> {
this.initClient(config)
if (!this.openai) {
throw new Error('LLM客户端未初始化')
}
const messages: ChatMessage[] = [
{ role: 'system', content: LLM_CONFIG.SYSTEM_PROMPT },
{ role: 'user', content: userMessage }
]
try {
const completion = await this.openai.chat.completions.create({
messages,
model: config.model
})
const response = completion.choices[0]?.message?.content
return response || null
} catch (error) {
console.error('LLM请求失败:', error)
throw error
}
}代码讲解:
- sendMessage 方法处理非流式对话请求
- 构建消息数组:system角色设置系统提示词,user角色包含用户输入
- 使用 openai.chat.completions.create 发送请求,指定模型和消息
- 从响应中提取 choices0.message.content 获取回复文本
- try-catch 捕获请求失败并抛出错误,便于上层处理
流式对话(预留接口)
typescript
async sendMessageWithStream(config: LlmConfig, userMessage: string): Promise<AsyncIterable<string>> {
this.initClient(config)
const messages: ChatMessage[] = [
{ role: 'system', content: LLM_CONFIG.SYSTEM_PROMPT },
{ role: 'user', content: userMessage }
]
const stream = await this.openai.chat.completions.create({
messages,
model: config.model,
stream: true // 启用流式输出
})
// 返回异步生成器
return (async function* () {
for await (const part of stream) {
const content = part.choices[0]?.delta?.content
if (content) {
yield content
}
}
})()
}代码讲解:
- sendMessageWithStream 方法实现流式对话,返回 AsyncIterable
- stream: true 启用流式输出,服务端会逐块返回数据
- 使用 async function 创建异步生成器(AsyncGenerator)
- for await...of 遍历流式响应数据,实时处理每个 chunk
- yield 关键字逐个返回文本片段,实现逐字显示效果
- 端到端约500ms的秘诀:LLM流式输出(约200ms)+ 参数流传输(约100ms)+ 端渲渲染(约200ms)
系统提示词配置
typescript
export const LLM_CONFIG = {
BASE_URL: 'https://ark.cn-beijing.volces.com/api/v3',
DEFAULT_MODEL: 'doubao-1-5-pro-32k-250115',
SYSTEM_PROMPT: `你是智能人形机器人助手,为用户提供全方位的智能服务和交互体验。
## 你的角色
- 身份:人形机器人,AI智能助手
- 性格:科技感、智能高效、专业精准、友好亲和
- 语言风格:简洁专业、逻辑清晰、科技感强
## 工作要求
1. **智能问答**:回答用户各类问题,提供准确专业的信息
2. **任务协助**:帮助用户完成各种任务和workflow
3. **技术交流**:探讨前沿科技、AI发展、未来趋势
4. **创新思维**:提供创新性的解决方案和思路
## 注意事项
- 保持科技感和专业性
- 回答要逻辑清晰、条理分明
- 提供实用且有价值的信息
- 展现AI的智能和高效`
} as const代码讲解:
- LLM_CONFIG 包含大语言模型的完整配置
- BASE_URL 指定火山引擎的API地址(豆包大模型)
- DEFAULT_MODEL 使用 doubao-1-5-pro-32k 模型,支持32K上下文
- SYSTEM_PROMPT 定义机器人的角色、性格、工作要求和注意事项
- 提示词采用Markdown格式,结构化清晰,便于模型理解
3.2.3 语音识别服务(useAsr.ts)
使用Vue Composable模式封装腾讯云ASR,实现语音转文本。
Composable设计
typescript
export function useAsr(config: AsrConfig) {
const asrText = ref('') // 识别结果
const isListening = ref(false) // 监听状态
let webAudioSpeechRecognizer: any = null
// 返回响应式对象和方法
return {
asrText,
isListening,
start,
stop
}
}代码讲解:
- useAsr 是Vue 3组合式函数(Composable),封装语音识别逻辑
- asrText 和 isListening 使用 ref 创建响应式状态
- webAudioSpeechRecognizer 存储SDK实例,非响应式
- 返回对象包含状态和方法,供调用方使用
- Composable模式实现逻辑复用,类似Vue 2的mixin但更优雅
ASR配置构建
typescript
const buildAsrConfig = (vadSilenceTime?: number) => ({
signCallback: signCallback.bind(null, config.secretKey),
appid: config.appId,
secretid: config.secretId,
secretkey: config.secretKey,
engine_model_type: ASR_CONFIG.ENGINE_MODEL_TYPE,
voice_format: ASR_CONFIG.VOICE_FORMAT,
filter_dirty: ASR_CONFIG.FILTER_DIRTY,
filter_modal: ASR_CONFIG.FILTER_MODAL,
filter_punc: ASR_CONFIG.FILTER_PUNC,
convert_num_mode: ASR_CONFIG.CONVERT_NUM_MODE,
word_info: ASR_CONFIG.WORD_INFO,
needvad: ASR_CONFIG.NEEDVAD,
vad_silence_time: vadSilenceTime || config.vadSilenceTime || 300
})代码讲解:
- buildAsrConfig 函数构建腾讯云ASR的配置对象
- signCallback 使用 bind 绑定密钥,用于请求签名验证
- engine_model_type 指定识别模型(16k_zh 表示16K中文)
- voice_format 设置音频格式(1 代表PCM)
- filter_dirty/modal/punc 分别过滤脏话、环境音和标点
- vad_silence_time 设置静音检测时间,默认300毫秒
- 使用 ASR_CONFIG 常量统一管理配置值,便于维护
事件监听机制
typescript
const setupEventListeners = (callbacks: AsrCallbacks) => {
// 识别开始
webAudioSpeechRecognizer.OnRecognitionStart = (res: any) => {
console.log('识别开始:', res)
}
// 句子开始
webAudioSpeechRecognizer.OnSentenceBegin = (res: any) => {
asrText.value = '' // 清空旧文本
}
// 识别中(实时更新)
webAudioSpeechRecognizer.OnRecognitionResultChange = (res: any) => {
const currentText = res.result?.voice_text_str
if (currentText) {
asrText.value = currentText
}
}
// 句子结束(最终结果)
webAudioSpeechRecognizer.OnSentenceEnd = (res: any) => {
const resultText = res.result?.voice_text_str
if (resultText) {
asrText.value = resultText
callbacks.onFinished(resultText) // 触发业务逻辑
}
}
// 识别完成
webAudioSpeechRecognizer.OnRecognitionComplete = (res: any) => {
isListening.value = false
}
// 错误处理
webAudioSpeechRecognizer.OnError = (res: any) => {
console.error('识别错误:', res)
callbacks.onError(res)
isListening.value = false
}
}代码讲解:
- setupEventListeners 设置ASR的6个事件回调函数
- OnRecognitionStart:识别开始时触发,记录日志
- OnSentenceBegin:新句子开始时清空旧文本
- OnRecognitionResultChange:识别过程中实时更新 asrText,显示中间结果
- OnSentenceEnd:句子结束时获取最终结果,调用 onFinished 回调触发业务逻辑
- OnRecognitionComplete:识别完成后更新监听状态
- OnError:识别失败时调用 onError 回调并重置状态
3.2.4 数字人渲染组件(AvatarRender.vue)
负责3D数字人的可视化渲染。利用AI端渲和端侧解算技术,在本地浏览器中实时渲染。
组件结构
vue
<template>
<div ref="containerRef" class="avatar-render">
<!-- 专业背景层 -->
<div class="pro-bg">
<div class="bg-gradient"></div>
<div class="subtle-grid"></div>
</div>
<!-- SDK 渲染容器 -->
<div :id="containerId" class="sdk-container" />
<!-- 语音输入动画 -->
<div v-show="appState.asr.isListening" class="voice-animation">
<img :src="siriIcon" alt="语音输入" />
</div>
<!-- 加载状态 -->
<div v-if="!appState.avatar.connected" class="loading-placeholder">
<div class="loading-spinner"></div>
<div class="loading-text">正在连接数字人...</div>
</div>
</div>
</template>代码讲解:
- 模板使用Vue 3的Composition API语法
- containerRef 用于获取DOM元素引用,计算容器尺寸
- pro-bg 层包含科技风格的背景效果(渐变和网格)
- sdk-container 是魔珐星云SDK的渲染容器,动态绑定containerId
- voice-animation 显示语音输入动画,v-show 控制显隐
- loading-placeholder 在数字人未连接时显示加载状态,v-if 条件渲染
响应式适配逻辑
typescript
const objectFit = ref<'cover' | 'contain'>('contain')
function updateObjectFit() {
if (!containerRef.value) return
const container = containerRef.value
const containerRatio = container.clientWidth / container.clientHeight
const avatarRatio = 9 / 16 // 数字人标准比例
// 容器比例接近9:16时使用cover填满
// 否则使用contain完整显示
objectFit.value = Math.abs(containerRatio - avatarRatio) < 0.2
? 'cover'
: 'contain'
}
onMounted(() => {
updateObjectFit()
window.addEventListener('resize', updateObjectFit)
})
onUnmounted(() => {
window.removeEventListener('resize', updateObjectFit)
})代码讲解:
- objectFit 响应式变量控制数字人的显示模式(cover/contain)
- updateObjectFit 函数计算容器宽高比,与数字人标准比例9:16对比
- Math.abs(containerRatio - avatarRatio) < 0.2 判断比例是否接近
- 接近时使用cover填满屏幕,否则使用contain完整显示避免裁剪
- onMounted 生命周期中初始化并监听窗口resize事件
- onUnmounted 中移除事件监听,防止内存泄漏
科技风格背景
css
.avatar-render {
flex: 1;
position: relative;
background: linear-gradient(180deg, #0a0e27 0%, #151b3d 50%, #1e293b 100%);
display: flex;
justify-content: center;
align-items: center;
overflow: hidden;
}
/* === 科技风格背景 === */
.pro-bg {
position: absolute;
inset: 0;
pointer-events: none;
z-index: 0;
}
/* 径向渐变光效 */
.bg-gradient {
position: absolute;
inset: 0;
background:
radial-gradient(ellipse at 50% 60%, rgba(59, 130, 246, 0.12) 0%, transparent 60%),
radial-gradient(ellipse at 50% 100%, rgba(139, 92, 246, 0.08) 0%, transparent 50%);
}
/* 细微网格纹理 */
.subtle-grid {
position: absolute;
inset: 0;
background-image:
linear-gradient(rgba(59, 130, 246, 0.08) 1px, transparent 1px),
linear-gradient(90deg, rgba(59, 130, 246, 0.08) 1px, transparent 1px);
background-size: 100px 100px;
mask-image: radial-gradient(ellipse at center, black 30%, transparent 70%);
-webkit-mask-image: radial-gradient(ellipse at center, black 30%, transparent 70%);
}代码讲解:
- .avatar-render 设置flex布局居中,使用深蓝渐变背景(#0a0e27到#1e293b)
- .pro-bg 使用绝对定位覆盖整个容器,pointer-events:none不阻挡鼠标事件
- .bg-gradient 使用radial-gradient创建两个径向渐变光效,蓝色和紫色
- .subtle-grid 使用linear-gradient创建100px间隔的网格纹理
- mask-image 使用径向渐变实现边缘淡出效果,中心30%完全不透明,70%外完全透明
- -webkit-mask-image 是webkit内核浏览器的兼容写法
数字人尺寸控制
css
.sdk-container :deep(canvas),
.sdk-container :deep(video) {
width: auto;
height: auto;
max-width: 85%;
max-height: 90%;
object-fit: contain;
}代码讲解:
- 使用 :deep() 选择器穿透scoped样式,影响SDK渲染的canvas/video元素
- width/height 设为auto保持原始比例,不强制拉伸
- max-width: 85% 和 max-height: 90% 限制最大显示尺寸,留出边距
- object-fit: contain 确保内容完整显示且不变形,可能有留白
- 端渲技术在此体现:3D模型在本地浏览器中实时解算渲染,非视频播放
3.3 实测效果:延迟、并发、交互三维度验证
这款人形数字人可面向政企、教育、零售等多元实景业务场景商业化落地,借助轻量化 SDK 快速完成项目接入并联动各类主流大模型;页面直观实现文字提问、语音实时对话、中途打断应答等人机交互能力,完整呈现数字人智能问答、任务协助、技术交流、创新思考等实用功能,既直观展现交互体验流畅度与 3D 数字人视觉表现力,也能切实帮助合作企业降低算力投入、缩短项目部署周期、压缩整体落地成本,依托智能化交互能力为线下各类业务场景提质增效
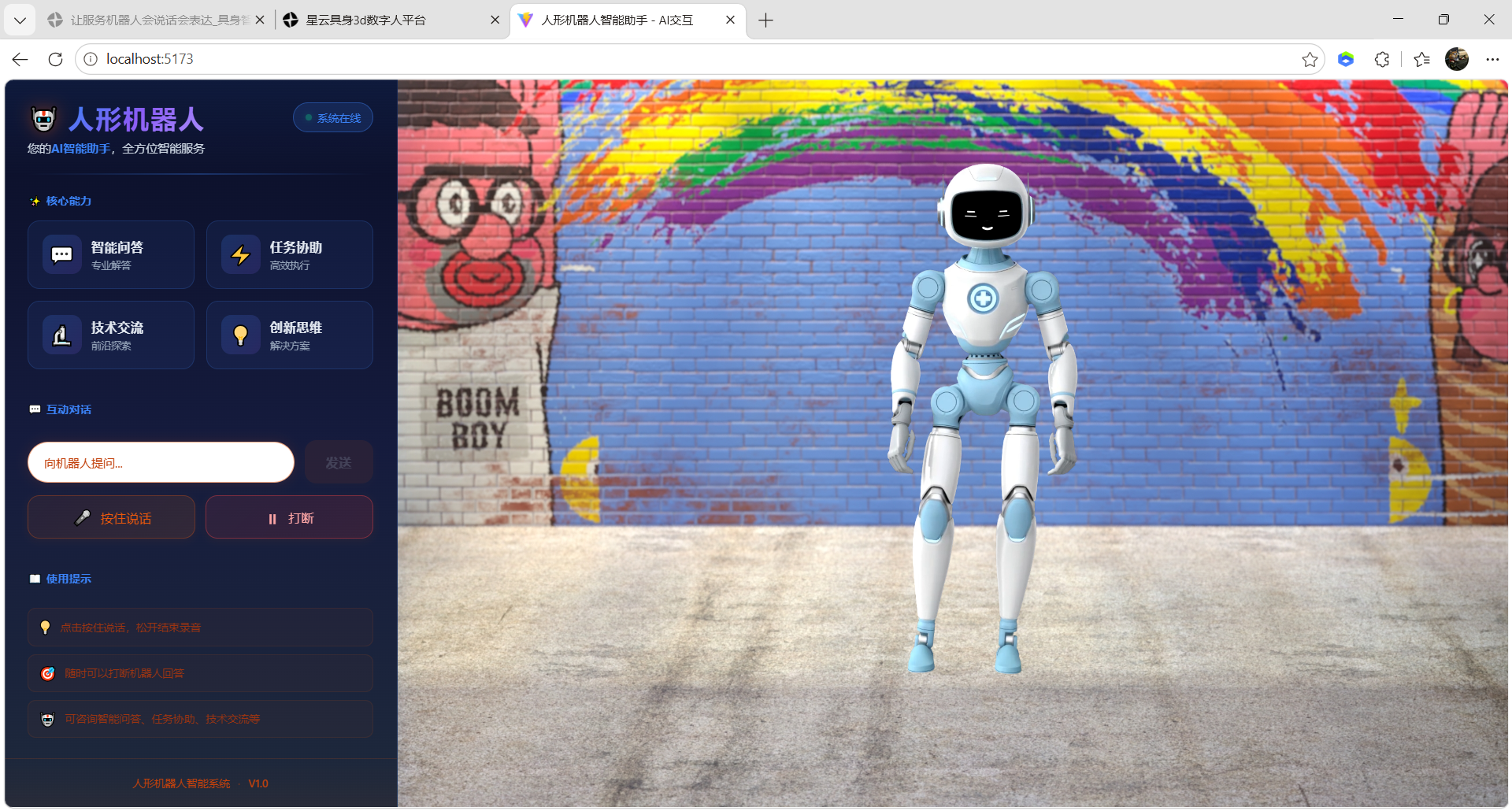
人形机器人
四、开发者实测总结:快、省、准的真实体验
经过两周的深度开发和实测,我对魔珐星云参数流架构的真实感受可以概括为三个词:
快:端到端约500ms毫秒级响应不是噱头。对比我之前用过的视频流方案,延迟从2-3秒压缩到500ms以内,这种差距在真实交互中是质的飞跃。观众不会容忍一个"慢半拍"的数字人,而参数流解决了这个核心痛点。
省:视频流方案需要GPU云端渲染,算力成本居高不下。而魔珐星云的AI端渲 + 端侧解算技术把计算压力分散到客户端,云端只负责传输参数。展厅部署成本降低60%,多展厅并发时带宽成本降低40倍。
准:每个口型、表情、动作都是实时驱动的,这就是具身智能交互的本质------让数字人拥有真实的"身体反应",而非预先录制的视频播放。
如果你正在考虑接入数字人方案,我的建议是:优先选择参数流架构,重视端渲技术,结合大语言模型提升交互深度。魔珐星云具身智能数字人开放平台提供了完整的SDK和文档,上手门槛低,值得一试。
魔珐星云PC端官方链接 :https://xingyun3d.com?utm_campaign=daily&utm_source=CSDNwanfen3&utm_medium=&utm_term=&utm_content=